Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
11-1-1998
The Effects of the architectural design, replacement
algorithm, and size parameters of cache memory in
uniprocessor computer systems
Eric Berzofsky
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
THE EFFECTS OF THE ARCHITECTURAL
DESIGN, REPLACEMENT ALGORITHM, AND SIZE
PARAMETERS OF CACHE MEMORY IN
UNIPROCESSOR COMPUTER SYSTEMS
by
Eric Benjamin Berzofsky
A Thesis Submitted
In
Partial Fulfillment of the
Requirements for the Degree of
MASTER OF SCIENCE
In
Computer Engineering
Approved by:
Principle
Advisor:
_
Roy S. Czernikowski, Professor and Department Head
Committee Member:
-Muhammad E. Shaaban, Assistant Professor
Date: __
tv_o_V_'_~-+1
99
X'
)
Date:
_11_-_6_"_'3_~
Committee
Member:.
_
Kenneth W. Hsu, Professor
Department of Computer Engineering
College of Engineering
Rochester Institute of Technology
Rochester, New York
November 1998
RELEASE PERMISSION FORM
Rochester Institute of Technology
The Effects of the Architectural Design, Replacement Algorithm, and Size
Parameters of Cache Memory in Uniprocessor Computer Systems
I, Eric Benjamin Berzofsky, hereby grant permission to any individual or organization to
reproduce this thesis in whole or in part for non-commercial and non-profit purposes only.
Eric Benjamin Berzofsky
11-
0 (,;,
q&
ABSTRACT
To investigate
the effects of cachecoherency
on multiprocessors,it
is
helpful
tofirst
explore
coherency
issues
within uniprocessors,working
with a small part of abig
problem
instead
ofattacking
thebig
problemfrom
the start.This
thesis willinvestigate
the
design
andimplementation
of threedifferent
cachedesigns,
varying
themapping
strategy, replacement algorithm, and size parameters to
determine
the effects eachhave
onthecache missratio, coherency, andaverage
memory
accesstime.VHDL
is
used to create software models of each cachedesign
investigated,
so thatparameter values can
be easily
changed, and so that nomoney
ortimeis
wastedby
first
prototyping
the cachedesign in
actualhardware. These VHDL implementations
arepresented,
along
with several test-bench programs thatwere used tonotonly
validate theperformance of the
VHDL
implementation,
but
also to explore the program-dependentperformance
factors
and coherency.Several
snoopy
cache coherence protocols arepresented at the end of the
thesis, in
order to suggestfuture
researchinto
theVHDL
TABLE OF
CONTENTS
LIST OF FIGURES V
LIST OF TABLES VI
LIST OF EQUATIONS VIII
GLOSSARY IX
1 THEMEMORY HIERARCHY 1
l.l
Inclusion,
Coherence,
andLocality 21.1.1 Inclusion 3
1.1.2Coherence 3
1.1.3
Locality
32 INTRODUCTION TOCACHE MEMORY 5
2.1 TypesofCache Memories 5
2.1.1 Direct Mapped 6
2.1.2
Fully
Associative 62.1.3 Set Associative 6
2.1.4 The Effect ofAssociativityontheCache Performance 6
2.2FindingaBlock WithintheCache 7
2.3 Writingto theCache 7
2.3.1 Write-Through 7
2.3.2 Write-Back 8
2.3.3 Write-Once 8
2.3.4
Comparing
theStrategies 92.3.5
Writing
to theCacheon aCache Write Miss 92.3.5.1 Write-Allocate 9
2.3.5.2No- Write-Allocate 10
2.4 SourcesofCache Misses 10
2.4.1
Compulsory
Cache-Misses 102.4.2
Capacity
Cache-Misses 102.4.3 Conflict Cache Misses 10
2.4.4 The Overall Effect ofThe Three C'sontheDesign ofCache
Memory
112.4.5
Reducing
theEffect ofThe Three C's 122.5 ReplacingaBlockon aCache-Miss 14
2.5.1 RandomReplacement 75
2.5.2 Least
Recently
Used(LRU)
152.5.3First In First Out
(FIFO)
752.5.4 Pseudo-Random Replacement 75
2.5.5
Comparing
theReplacementSchemes 163 IMPLEMENTING UNIPROCESSOR CACHEMEMORIESIN VHDL 17
3.1 WHATISVHDL? 17
3.2 Why Use VHDLtoImplementCache Memory? 18
3.3DescriptionofSpecialFunctions UsedThroughouttheVHDL Implementations 18
3.3.1 Log_Base_2 18
3.3.3 IvJoJnteger 19
3.4VHDL Implementationof aMemoryUnit 20
3.4. 1 Description oftheConstantsandTypes Used Throughoutthe VHDL Implementation ofa
Memory
Unit 213.4.2 Description ofSignals Used Withinthe
Memory
UnitImplementation 223.4.3InitializationProcess 24
3.4.4
Memory
Process 243.4.5
Modify
Process 253.4.6
Modify
Process 253.4.7
Modify
Process 253.5 VHDL Implementationof theFIFO Replacement Algorithm 26
3.6 VHDL Implementationof theLRU Replacement Algorithm 26
3.7 VHDL Implementationof theCache Architectures 27
3. 7.1 Description oftheConstantsandTypes Used ThroughouttheVHDL Implementation ofaCache27
3.7.2 Description ofthe VHDL Implementation ofaWrite-ThroughCache
Using
No-Write-Allocateon aWrite-Miss 32
3.7.2.1 DescriptionoftheSignalsUsed WithintheWrite-ThroughCacheImplementations 32
3.7.2.2 Read_or_Write Process 34
3.7.2.3 Read_Write_Miss Process 35
3.7.2.4Direct_Mapped_Add,Fully_Associative_Add,andSet_Associative_Add Processes 36
3.7.2.5
Dump
Process 373. 7.3 Description ofthe VHDL Implementation ofaWrite-Back Cache
Using
Write-Allocateon aWrite-Miss 37
3.7.3.1 DescriptionoftheSignals Used WithintheWrite-BackCacheImplementations 38
3.7.3.2 ReadorWrite Process 39
3.7.3.3 Read_Write_Miss Process 40
3.7.3.4Direct_Mapped_Add,Fully_Associative_Add,andSet_Associative_Add Processes 40
3.7.3.5
Dump
Process 423.7.4Description oftheVHDL Implementation ofaWrite-OnceCache 42 3.7.4.1DescriptionofSignals Used WithintheImplementationof aWrite-OnceCache 43
3.7.4.2 ReadorWriteProcess 44
3.7.4.3 Read_Write_Miss Process 45
3.7.4.4Direct_Mapped_Add,Fully_Associative_Add,andSetAssociativeAddProcesses 46
3.7.4.5
Dump
Process 474 CACHE AND PROCESSORPERFORMANCE PARAMETERS 49
4.1 CPUTIME 49
4.2 Average Memory Access Time 51
4.3Keeping Trackof theMemory Accessesin theVHDL Implementations 5 1
4.4Keeping Trackof theCache Performance 5 1
5 TESTING THE VHDL CACHE IMPLEMENTATIONS 53
5.1 The Read Test 54
5.2The Write Test 54
5.2.1 Write-BackCache Implementations 55
5.2.2 Write-OnceCache Implementations 56
5.2.3 Write-Through Cache Implementations 56
5.3 TheRead-Write-Write-Read
(RWWR)
Test 565.3.7 Write-BackCache Implementations 57
5.3.2 Write-Once CacheImplementations 59
5.3.3 Write-ThroughCache Implementations 60
5.4TheSumTest 61
5.4. 1 Write-Back DirectCache ImplementationandFully-Associative CacheImplementationwith
5. 4. 2 Write-Back Fully-Associative Cache ImplementationwithLRU Replacement Algorithm 64
5.4.3 Write-BackSet-Associative Cache Implementation 65
5.4.4 Write-Once DirectCacheImplementationandFully-Associative Cache Implementationwith
FIFO Replacement Algorithm 66
5.4.5Write-Once Fully-Associative Cache ImplementationwithLRUReplacement Algorithm 67
5.4.6Write-OnceSet-Associative CacheImplementation 68
5.4.7 Write-Through DirectCacheImplementationandFully-Associative CacheImplementationwith
FIFOReplacement Algorithm ~0
5. 4. 8 Write-Through Fully-AssociativeCacheImplementationwithLRU ReplacementAlgorithm 71
5.4.9 Write-Through Set-Associative Cache Implementation 72
5.5 Summaryof theCoherency BetweentheCacheandMain MemoryforAllof the
Test-Benches 74
6 IMPROVING CACHE MEMORY PERFORMANCE 75
6.1 ReducingtheMissRatebyIncreasingtheAssociativityof theCache 76
6.2 ReducingtheMissRatebyUsing VictimCaches 82
6.3 ReducingtheMiss RatebyUsing Hardware PrefetchingofData 82
6.4 ReducingtheMiss RatebyUsing Compiler Optimizations 83
6.5 ReducingtheMiss PenaltybyGivingPrioritytoReadMisses Over Writes 85
6.6 ReducingtheMissPenalty By Using Sub-block Placement 86
6.7 ReducingtheMiss PenaltybyUsing Early RestartandCritical Word First Methods...88
6.8 ReducingtheMiss PenaltybyUsing Second Level Caches 88
6.9 ReducingtheHit Time ByUsingaSmallandSimple Cache Design 92
6.10Cache Optimization Summary 92
7 INTRODUCTIONTO SHARED-MEMORY MULTIPROCESSORS 95
7.1 The Cache Coherence Problem 95
7.2 The General CategoriesofSolutionsto theCache Coherence Problem 96
7.2.1
Disallowing
PrivateCaches 977.2.2
Allowing
Private Caches 977.2.3 Non-Cacheable Shared Writeable Data 97
7.2.4
Allowing
Shared Writeable Data 987.2.5 Bus-Oriented Multiprocessors 98
7.2.6 Examples ofCache Coherence Solutions in
Existing
Multiprocessors 998 SNOOPY CACHE COHERENCE PROTOCOLS FOR MULTIPROCESSORS 100
8.1 Write Through Protocol 100
8.2 Write Back Protocol 100
8.3 Comparing Write BacktoWrite Through 101
8.4 Write Once Protocol 101
8.5 Comparing Write OncetoWrite BackandWrite Through 103
8.6 Papa's Protocol 104
8.7 Read Broadcast Protocol 105
8.8 Read Write Broadcast Protocol 108
8.9 BerkeleyOwnershipProtocol Ill
8. 10 Comparisonof theBerkeley Ownership Protocolto theWrite OnceProtocol 112
8.11 Firefly Protocol 113
8.12 AdvantagesandDisadvantagesoftheFirefly Protocol 114
9 FUTURE WORK 116
9.1 Implementing MultiprocessorCache Coherence SolutionsinVHDL 116
9.2 UsingtheExistingVHDL Codeas aTeachingAide 118
LIST
OF
FIGURES
Figure1. DesignofaFive-Level Memory Hierarchy [HwangI
993,
p.189]
1 Figure 2. The InclusionPropertyandData Transfers BetweenAdjacent LevelsofaMemoryHierarchy.[Hwang
1993,
page191]
4Figure 3. NumberofMemory Accessesvs.DegreeofAssociativityfor theWrite-Back Cache78 Figure4. NumberofMemory Accessesvs.DegreeofAssociativityfor theWrite-Once Cache78 Figure5. NumberofMemoryAccessesvs.DegreeofAssociativityfor theWrite-Through
Cache 79
Figure 6. Miss Ratesvs.DegreeofAssociativityfor all of theCacheImplementations 80
Figure 7. Average Memory Access Time Versus DegreeofAssociativity. 81
Figure 8. Placementof theVictim Cachein theMemory Hierarchy[Hennessy
1996,
p.398]
82 Figure 9. The Sub-block Placement Strategy[Hennessy1996,
p.413]
87Figure 10. Write Once Protocol[Hwang1993p.
354]
103Figure1 1.Papa's Protocol 105
Figure12. RB (Read
Broadcast)
Protocol[Rudolph1984]
108Figure 13. RWB (ReadandWrite
Broadcast)
Protocol[Rudolph1984]
110LIST OF TABLES
Table 1.Memory CharacteristicsofaTypical Mainframe
[Hwang1993,
p.190]
2 Table 2. The IncreaseofAccessTimeandDecreaseinBandwidthasOneMovesAwayfrom theCPU
[HENNESSY1996,
P.41] 5Table3.The Total Miss RateforEach CacheSizeandPercentageofEach Accordingto the
ThreeC's
[Hennessy1996,
P.391]
11Table4. Design Target Miss Ratiosfor aUnified Cache[Smith
1987]
13 Table 5. ActualMiss Rate Versus Block SizeforFive Different-Sized Caches [Hennessy1996,
p.
394]
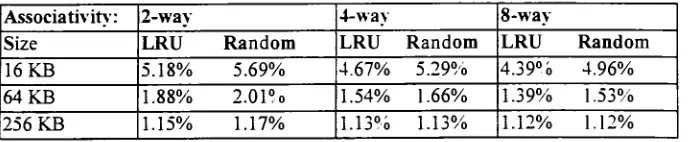
13Table6. Miss Rates Comparing LRUtoRandom ReplacementforSeveral Cache Sizesand
Associativities
[Hennessy1996,
p.379]
16Table 7. Descriptionof thePerformanceof the lv_to_integerFunction 20 Table 8. Descriptionof theConstantsandTypes Usedin theVHDL Implementationof a
Memory Unit 21
Table9. Descriptionof theSignalsused in theVHDL Implementationof aMemoryUnit 23 Table 10. Descriptionof theConstantsandTypes Usedin theVHDL Implementationof a
Cache 29
Table 11. Data Analysisof theRead Test 54
Table 12. Data Analysisof theWrite Test 55
Table 13. Data Analysisof theRWWR Test 57
Table 14. Decsriptionof theCacheandMain Memory Performancefor theRWWR Teston the
Write-BackCache Implementations 58
Table15. Descriptionof theCacheandMain Memory Performancefor theRWWR Teston the
Write-OnceCache Implementations 59
Table1 6. Descriptionof theCacheandMain Memory Performancefor theRWWR Teston the
Write-ThroughCache Implementations 61
Table 17.Data Analysisof theSum Test 62
Table 18. Descriptionof theCacheandMain Memory Performancefor theSum Teston the
Write-BackDirect-MappedandFully-Associative MappedwithFIFO Replacement
AlgorithmCache Implementation 63
Table 19. Descriptionof theCacheandMain Memory Performancefor theSum Teston the
Write-BackFully-Associative MappedwithLRU Replacement Algorithm Cache
Implementation 64
Table 20. Descriptionof theCacheandMain Memory Performancefor theSum Teston the
Write-Back Set-AssociativeMapped Cache Implementation 65
Table2 1. Descriptionof theCacheandMainMemory Performancefor theSum Teston the
Write-OnceDirect-Mapped Cache ImplementationandFully-Associative Mappedwith
FIFO Replacement Algorithm Cache Implementation 66
Table 22. Descriptionof theCacheandMain Memory Performancefor theSum Teston the
Write-OnceFully-Associative MappedwithLRUReplacement AlgorithmCache
Implementation 68
Table 23. Descriptionof theCacheandMainMemoryPerformancefortheSum Testonthe
Write-Once Set-Associative Mapped CacheImplementation 69
Table 24. Descriptionof theCacheandMain MemoryPerformancefor theSum Teston the
Write-ThroughDirect-Mapped Cache ImplementationandFully-AssociativeMappedwith
FIFO Replacement AlgorithmCacheImplementation 70
Table25.Descriptionof theCacheandMain MemoryPerformancefor theSum Teston the
Write-ThroughFully-AssociativeMappedwithLRU ReplacementAlgorithm Cache
Table 26. Descriptionof theCacheandMain MemoryPerformancefor theSum Teston the
Write-ThroughSet-AssociativeMapped CacheImplementation 73
Table 27. The Coherency StatusofEach Test-BenchonEach CacheArchitecture 74 Table28.AverageMemoryAccess TimeforDifferent CacheSizesandAssociativities
[HENNESSY1996,
P.397]
76Table29. CacheandMain MemoryPerformanceoftheSumTestforDifferent Degreesof
Associativity 77
Table30.Miss Ratesfor theVarying DegreesofAssociativity 79
Table 31. Average Memory Access TimeforVarying DegreesofAssociativity. 81 Table 32. Typical ValuesandParametersofaSecond-Level Cache[Hennessy
1996,
p.471]
91 Table 33. SummaryofCacheOptimizationsandImpacton theThree AspectsofCacheLIST
OF
EQUATIONS
Equation1. Thenumber of bitsneededfor addressing mainmemory 22
Equation 2. AddressBitsNeededin aDirect-Mapped Cache 30
Equation 3. Address Bits NeededintheSet-AssociativeMappedCache 31 Equation 4.ConvertingtheAddress Portionof aCacheBlockin aDirect-Mapped Cacheto
Compareto theRequested Address 34
Equation 5.ConvertingtheAddress Portionof aBlockin aSet-AssociativeCachetoCompare
to theRequested Address 35
Equation 6. CPU Time[Hennessy
1996,
p.385]
49Equation 7. Memory Stall CyclesperRead-MissandWrite-Miss Separately [Hennessy
1996,
p.386]
49Equation 8. Memory Stall CyclesperMemory Access [Hennessy
1996,
p.386]
50 Equation 9. CPU TimeinTermsofMemory AccessesperInstruction [Hennessy1996,
p.386]
50 Equation 10. Miss RateinTermsofMissesperInstruction[Hennessy1996,
p.386]
50 Equation 1 1. CPU Time UsingtheMiss RateinTermsofMissesperInstruction[Hennessy 1996,
P.
386]
50Equation 12. Average Memory Access Time [Hennessy
1996,
p.384]
51 Equation 13. AverageMemory Access Time Broken DownintoMemory Accesses DuetoInstructionandMemory Accesses DuetoData [Hennessy
1996,
p.385]
51 Equation 14. Average Memory Access TimeforTwo-LevelCache [Hennessy1996,
p.417]
89 Equation 15. Miss Penaltyof theFirst LevelofCache[Hennessy1996,
p.417]
89 Equation 16. Expanded Average Memory Access Time FormulaforTwo-Level CacheGLOSSARY
2to1cache rule ofthumb
Amain ruleofcachememorywhich statesthatadirect-mappedcache of sizeNhasaboutthesame miss
rateas a
2-way
set-associative cache of sizeN/2 12accesstime
Thetotal timeittakes toaccesstheCPUfromtheith levelofthememory
hierarchy
1addressincache
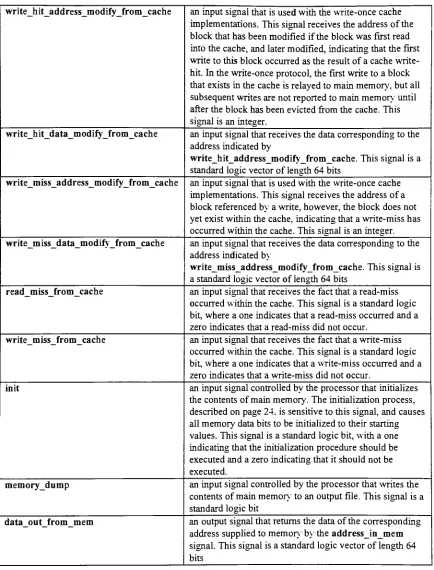
Aninputsignal
indicating
theaddress referencedby
theprocessor 33 addressinmemAninputsignal controlled
by
theprocessorthatdenoteswhichaddresshas beenreferencedby
theprocessor 22
addressneededincache
Anoutput signalthatissenttomainmemorywhich containstheaddressthatwasreferenced
by
theprocessor,butwhichdoesnot existinthecache 33
addresstoevict
Anoutputsignal senttomainmemorywhich containstheaddress of a
dirty
blockthatwas evictedfromthecache 38
addresstoevictfromcache
An inputsignalthatreceivestheaddressthatwasevictedfromthecache 22
averagememoryaccesstime
Aperformance parameterthatisa measure ofthehit time,missrate,and misspenaltyassociated with
thecache 51
B
bandwidth
Therate at whichinformation istransferredbetweentwolevelsofthememory
hierarchy
1Berkeley
Ownership
cache coherence protocolAcache coherence protocol which uses ownership-based multiprocessor cacheconsistencyprotocol. 1 1 1
BLOCKS_PER_
SETA VHDLconstantstoringthenumber ofblocksperset,orthedegreeofassociativity 28 byte
Aunitof measurethatmeasures8bits 2
cacheblock
Theunit oftransferbetweenthecacheand mainmemory 3
cache coherence problem
Aproblemthatoccursinashared-memorymultiprocessor whentwoor more processors eachhave a
local copyof adatavalue,and one oftheprocessors changesthedatavalue withinits localcache,as
partof aninstructionthatisexecutedin itsprogram 95
cacheflush
Invalidating
thecontents ofthecache.This usuallyoccursafter a critical sectionhas been leftduring
theexecutionof program on a processor 98
cacheinterrogatesignal
Asignal usedtoobtainexclusiveownershipof a sharedblocksothatmodificationsofthisblockcanbe
performed without
jeopardizing
thecoherencyofthisblockwith respecttoother processorsthatmayshareitsvalue 98
Asmall,
fast,
memoryunitthatis usuallyplacedbetweentheCPUand mainmemoryand which stores themostrecentlyuseddatavalues oftheprogramexecutingontheCPU 5CACHE_ BLOCK_DATA_
BITSA VHDLconstantstoringthenumber ofbitsusedfor data 28
CACHE_BLOCK_STATUS_BITS
AVHDLconstantstoringthenumberofstatusbitstouse withthecache architecture 28 cachedump
Aninputsignal controlled
by
theprocessorthatrequeststhat thecontents ofthecache,andtheFIFO queue orLRUarraywhereapplicable,bewritten,or"dumped,"toafile 33 CACHE_SIZEA VHDLconstantstoringthecache sizeinunits ofkilobytes 28
cache-miss
Whena referencedblock isnot presentinthecache 10
capacitycache-miss
Atypeof cache missthatoccurs whenthecacheisnot capable ofstoringall ofthedataneeded within a cacheblock
during
theexecutionoftheprogram ontheCPU 10 centralized globaltableAtable thatisusedtostorethestatus of eachblock inthecachethatisshared
by
morethanone cache.98 coherencepropertyAfundamental propertyofthememory
hierarchy
whichstatesthatcopies ofthesameinformationitem athigher levelsofthememoryhierarchy
mustbeconsistent withthoseofthelower levels 3 coherentAscenarioinwhicheveryread
by
anyprocessoralways returnsthevalueproducedby
thelastpreviouswrite,no matter which processor performedthewrite 95
cold start miss See compulsorycache miss.
collisionmisses Seeconflict cache miss
compulsorycache-miss
Atypeof cache missthatoccurs whenthevery firstaccesstoa neededblockresultsina miss 10 conflictcache-miss
Atypeof cache missthatoccurs when ablock is discarded inordertomake roomforanotherblockthat
mapsto thesamelocationor same set.Thistypeof cache miss canonlyoccur within a set-associative
ordirect-mappedcache 10
copy back Seewritebackcache
costperbyte
Thecost perbyteoftheith levelofthememory hierarchy. This quantity is usuallyestimated asthe
productofthecost andthesize ofthememory level 1
CPI
Cycles Per Instruction. Ameasure ofthenumber ofCPUcycles requiredtoexecutetheinstruction.50
CPU
Central
Processing
Unit. Thepart ofthecomputerthatperformstheexecution of a program onthecomputer.
Also,
thehighest levelofthememoryhierarchy
1CPUtime
Aperformance parameterthatisa measure ofthe totalnumber of clock cyclesthattheCPUspends executing itsprogram,andthetimethattheCPU isspentwaitingforamemoryaccesstoreturn with
thenecessarydata 49
critical wordfirst
Acacheimprovementtechniqueinwhichtherequired wordisreadintothecache
first,
senttotheCPU,
andthen therest oftheblockisreadintothecache 88
D
data_in_cache
Aninputsignal
indicating
thedataassociated withtheaddress specifiedby
theaddress_in_cachesignal.data_in_from_mem
An inputsignalthatreceivesthedatacontentsfrommainmemoryofthecorresponding blockinmain memorythatisindicated
by
theaddress_in_cache signal 33 datainmemAn inputsignalcontrolled
by
theprocessorthatdenotesthedatatowriteto thecacheblock 22 data_out_from_memAnoutputsignalthatreturnsto thecachethedata correspondingtotheaddress suppliedtomemoryin
theaddressinmem signal 23
data_read_out_cache
Anoutput signalthatreturnstherequesteddatacontentsto theprocessor 33 datatoevict
Anoutput signal senttomainmemorythatcontainsthedatacorrespondingto theevictedblockwhose
addressisaddress_to_evict 43
datatoevictfromcache
Aninputsignaltomainmemorythatreceivesthedata correspondingtotheevicted cacheblockwhose
addressisaddress_to_evict_from_cache 22
datatowritefromcache
Anoutput signalthatissenttomainmemorywhich containsthedatatowritetoablock inmain
memorywhen an update of ablockmustbeperformed 33 degreeofassociativity
n-wayset associative See
designtargetmiss ratio
Acachedesignparameterthatisusedtoachieve a rough estimate oftheexpected miss ratioas a
functionofthecache size 12
directmappedcache
Atypeof cachemapping strategy inwhichthereis onlyone placethata referencedblockcould reside. 6
DIRECT_ CACHE_ BLOCK_ ADDRESS_
BITSAVHDLconstantstoringthenumberof addressbitstouseinadirect-mappedcache 28
DIRECT_ CACHE_
BLOCK_SIZEA VHDLconstantstoringthesize of ablock inadirect-mappedcache 28
directcacheblock
A VHDLsub-type usedtodescribea cacheblockinadirect-mappedcache 28
directcacheunit
A VHDLtypeusedtodescribeadirect-mappedcache 29 directmappedaddprocess
A VHDLprocess usedwithinthecacheimplementationsofthethesistohandletheaddingof ablockto
adirect-mappedcache 36
dirty
Astateinthewrite-once cacheinwhichtheblockhasbeen
locally
modified morethanonce, andhence its datavalueisinconsistentwiththatinmainmemory 9dirty
bitAbitthatisusedtodeterminethestatusof ablock inthecache.Ifthisbit isaone,theblockisclean.If
itisazero,theblock is
dirty
8dirty
blockAblockina cachethathas beenwrittentoanditsmodificationhasnot yetbeenreportedtomain
memory 8
DRAM
Dynamic Random Access Memory. Adesign
technology
usingdynamic memorycellsinthe designof a memoryunit.Inadynamic memorycell,thecontents mustbe occasionallyrefreshed sothatits contents are notlost.Usually
used withthedesignof a mainmemoryunit 2dump
processearlyrestart
Acacheimprovementtechniqueinwhichtherequested wordissentto theCPUas soon asitarrivesinto
thecache sothat theCPUmaycontinue withitsexecution as soon as possible 88 ECL
EmitterCoupledLogic. Adevice
technology
usedinthedesignofCPU'sand other computerhardware2exclusive-modifiedstate
Astate usedin Papa'sprotocolthatindicatesthatno other cachehasthisblockandthat thedata inthe block is inconsistentwiththatinmainmemorysincethedata has been
locally
modified 104 exclusive-unmodifiedstateAstate usedinPapa'sprotocolthatindicatesthatno other cachehasthis
block,
andthat thedataintheblockisconsistentwiththatinmainmemory 104
fetchon write Seewrite-allocate
FIFOreplacementstrategy
FirstIn First Out. Areplacement methodinwhichthefirstblockthatwas placedintothecacheisthe
firsttobeevictedfrom it 15
Firefly
cache coherence protocolAcache coherence protocol which allows multiple cachestocontain a writeable cacheblock
simultaneously,with no-pre-arrangement requiredfora processortowritetoa sharedlocation 113
firstreference miss See compulsorycache miss.
first-write
Astate usedintheRWBprotocolthatindicatesthefirstwritetoablock inthecache 109
fully
associative cacheAcachemapping strategy inwhich a referencedblockcould reside anywhere withinthecache 6 fuIly_associative_add
A VHDLprocess used withinthecacheimplementationsofthethesistohandletheaddingof ablockto
afully-associativemapped cache 36
FULLY_CACHE_
BLOCK_SIZEA VHDLconstantstoringthesize of ablock inafully-associativemapped cache 28 fullycacheblock
A VHDLsub-type usedtodescribea cacheblock inafully-associativemapped cache 28
FULLY_CACHE_BLOCK_ ADDRESS_
BITSA VHDLconstantstoringthenumber of addressbitstouseinafully-associativemapped cache 28 fullycacheunit
A VHDLtypeusedtodescribeafully-associativemapped cache 29
fusing
The
joining
oftwoloopsthataccessthesamearraywiththesameloops,
butperformdifferentcomputations onthecommondata inordertoreducethenumber ofmemoryaccesses requiredto
performthecalculations specifiedintheloops 84
GbyteorGB
Gigabyte. Aunitof measurethatmeasures
2A30,
or1073741824bytes 2global miss rate
Thenumber of missesinthecachedivided
by
thetotalnumber ofmemoryaccessesgeneratedby
theCPU 89
/
InstituteofElectricalandElectronics Engineers.The governing
body
thedeterminedthestandardsforVHDL 17
inclusion property
A fundamental propertyofthememory
hierarchy
which statesthatallinformationcontainedinleveli isalso presenti level i+1 3
init
Aninputsignal controlled
by
theprocessorthatinitializesthecontentsof mainmemory 23initialization process
A VHDLprocess used withinthethesistoinitializethecontents ofthemainmemory 24
integer_to_lv function
Afunctionusedwithinthethesisthattakes anintegerand writesin
binary
19 invalidstateAstateinthewrite-once cacheinwhichtheblockcontainsnodata 8 K
KbytesorKB
Kilobytes. Aunit of measuremeasuring
2A10,
or 1024bytes 2localconfiguration
Aconfiguration usedintheRBprotocolthatindicatesthata variableXthatis localtoprocessing
elemnetiwillbe inthelocalstateincacheiandintheinvalidstatein anyother cachecontaining variableX. Thisconfiguration allows cachei tohaveexclusiveownershipof
X,
inordertobeabletomodifythecontents ofit 106
localmissrate
Thenumberof missesinthecachedivided
by
the totalnumber ofmemoryaccessesto thecache 89 localstateAstate used withtheRBprotocolthatindicatesthat thedatainthecacheblockcanbereador writtento
locally,
causingnobus activity 106log_base_2function
A functionused withinthe thesis thatreceivesanintegeranddeterminesthenumberofbitsneededto
expressit in
binary
18LRUreplacement algorithm
Least
Recently
Used. Areplacementmethodinwhichtheblockthathasnotbeenusedinthelongestamountoftimeisevictedfromthecache 15
lvtointeger
A functionused withinthethesisthattakesa standardlogicvector andconvertsittoitsdecimal integer
equivalent 19
M
MbytesorMB
Megabytes. Aunitof measurethatmeasure
2A20,
or1048576bytes 2 memorysizeThenumber ofbytesin level iofthememory
hierarchy
1 memorystall cyclesAperformanceparameterthatisa measure oftheread misses per program andthewrite misses per
program,andthepenaltyassociated with each 49
memoryaccess process
A VHDLprocess usedwithinthe thesis tohandle basicqueriesfromthecache aboutdifferent locations
inmainmemory 24
memory_block
A VHDLconstant usedtostorethenumber ofbitsinthememoryblockthatare usedforaddressing... 21 MEMORY_BLOCK_DATA_BITS
A VHDLconstant usedtostorethenumber ofbits inthememoryblockthatare usedfor data 21 MEMORY_BLOCK_SIZE
AVHDLconstant usedtostorethesize of ablock inmainmemory,inunits ofbits 21 MEMORY_SIZE
A VHDLconstant usedtostorethevalueofthesize of mainmemoryinunits ofblocks 21 MEMORY_TYPE
A VHDLpackageused withinthe thesiswhich storestheconstants usedtoimplementamemoryunit.2 1 memoryunit
A VHDLtypeusedtodescribeamemoryunit 22
miss-ratio
Aratio ofthenumber of cache missesthatoccurintheprogramto thenumber ofmemoryreferencesin
theprogram 6
modifyevict process
A VHDLprocess used withinthethesis tohandleupdates ofmemoryblockswhen ablock has been
evictedfromthecache 25
modifywritehit process
A VHDLprocess used withinthe thesis tohandleupdatesofmemory blockswhenablockismodified
forthefirsttimeina write-once cache 25
modifywritemiss process
AVHDLprocess used withinthe thesis tohandletheupdate ofmemory blockswhen a write-miss occursinthewrite-once cacheforthefirstwrite ofthereferencedblock 25 ms
Millisecond. Aunitof measurethatmeasures 10A-3seconds 2
multi-levelinclusion propertyof second-level caches
Theinclusionprinciple ofthememory
hierarchy
thatrequiresthesecond-level cachetocontain all ofthedatathatappearsinthefirst-levelcache 91
TV
no-write-allocate
Acachedesignoptioninwhich,on awrite-miss,thereferencedblockismodified
directly
inmainmemorywithouttheblock
being
bought intothecachefirst 10ns
Nanosecond. Aunit of measurethatmeasures 10A-9seconds 2
NUMBER_OF_
SETSA VHDLconstantstoringthenumber of setsinthecache 28
n-wayset associative
Anotation usedtodenotethenumber ofblockswithin a set.Nrepresentsthenumber ofblocksineach
set ofthecache 6
O
Owned
Exclusively
stateAstate usedinthe
Berkeley Ownership
protocolthatindicatesthattheowningcacheholdstheonlycachedcopyoftheblock.Updatescan occur
locally
withoutfirstinforming
theother caches 1 1 1 OwnedNonExclusively
stateAstate usedinthe
Berkeley Ownership
protocolthatindicatesthatother cacheshaveacopyofthecache blockand mustbeinformedastoanychanges madelocally
ina cachethatcontainstheblock Ill ownership-basedmultiprocessor cacheconsistencyprotocolAcachecoherencyprotocolinwhich a processor must own ablockofmemorypriorto
being
allowedtopackage
AtermusedinVHDLtodescribeafilethatcontains
frequently
usedfunctionsand parameters.Instead oftyping
thesame codein everyfile,
thecodeistypedonce,thefunction isgiven aname,andthe packageis instantiatedinallfilesthatwill usethefunction 18 pagesTheunit oftransferbetweenexternaldisksand mainmemory 3 Papa'scache coherence protocol
Acache coherence protocol whose goalistoreducebustrafficandthusdecreasethewaittime thata
processor must waitpriortoaccessingthebus 104
PE
Processing
Element 106pseudo-random replacementalgorithm
Areplacementalgorithm used withintheset-associative cacheimplementationsofthisthesis.A block is
randomlychosen,
however,
some guidelines arefollowed 16Q
queueAVHDLtypeusedtodescribetheLRU arrayorFIFOqueue 29
queueentry
A VHDLsub-type usedtodescribeanentry ineithertheLRU arrayorFIFOqueue 28 R
random replacement algorithm
Areplacement methodinwhich ablock inthecacheis randomlychosentobeevicted whenthecacheis
full 15
Read Broadcast
(RB)
cache coherence protocolAcachecoherence protocol whichis basedonthewrite onceprotocol,butusesthebus broadcast capabilities moreefficientlyforboth dataand event
broadcasting
105 readtestAtest-benchprogramdesignedtoverifytheread operation ofthecacheimplementations 54 Read WriteBroadcast
(RWB)
cache coherence protocolAcache coherenceprotocol,similarto theRBprotocol,inwhich all ofthecaches readthedataonthe
busonboth busreadsandbuswrites 108
readmissfromcache
Aninputsignaltomainmemorythatreceivesthefactthata read-miss occurred withinthecache 23 readmissout
Anoutput signalthatissenttomainmemorywhichindicatesthata read-miss occurredinthecache... 33 readnotwrite
Aninputsignal
indicating
whethera read or a write occurredintheprogram executedby
theprocessor. 33readorwriteprocess
AVHDLprocess used withinthecacheimplementationsofthethesis toperform either a read or a write
of ablockinthecache 34
readwritemissprocess
A VHDLprocess used withinthecacheimplementationsofthe thesistoreportread-misses,
write-misses,and updatestomainmemory 35
readable state
Astate usedwiththeRBprotocolthatindicatesthatthecontents ofthecacheblockarevalid and
consistentwithmemory 106
Read-For-Ownership
operationAbusoperationusedinthe
Berkeley Ownership
protocolthatissimilartoa normalread,exceptthat the requestingcachebecomestheexclusiveowner afterthereadcompletes,and all othercachesRead-Sharedoperation
Abusoperation usedinthe
Berkeley
Ownership
protocolthatisa conventional readthatgivesthecacheanUnOwnedcopyoftheblock 112
read-write-write-read
(RWWR)
testAtest-benchprogramdesignedtoverifytheoperationofthecacheimplementationswhen reads are followed
by
writestodifferentlocations,
which areinturnfollowedby
writestotheblocksthatwere firstread,which arefinally
followedby
reads oftheblocksthatwerefirstwrittento 56 requested wordfirstcritical wordfirst See
reservedstate
Astateinthewrite-oncecacheinwhichtheblockhas been
locally
modifiedexactlyonce andtheresultsofthismodificationhavebeenreportedtomainmemory 8
S segments
Theunitof storage ofinformation inthe
back-up
storagedevice 3 sequentiallocality
Afundamentalpropertyofthememory
hierarchy
whichstatesthattheexecution of a programtends tofollowa certain sequential order 3
set associative cache
Acachemapping strategy inwhicha referencedblock is firstmappedtoa set andthencan reside
anywhere withintheboundsofthatset 6
set_associative_add
A VHDLprocess used withinthecacheimplementationsofthe thesis tohandletheaddingof ablockto
afully-associativemapped cache 36
SET_CACHE_ BLOCK_ ADDRESS_
BITSA VHDLconstantstoringthenumberof addressbitstouseina set-associative mapped cache 28
SET_CACHE_
BLOCK_SIZEAVHDLconstantstoringthesize of ablock ina set-associative mapped cache 28 setcacheblock
AVHDLsub-type usedtodescribea cacheblock ina set-associative mapped cache 28 set_cache_unit
A VHDLtypeusedtodescribea set-associative mapped cache 29
shared configuration
Aconfiguration usedintheRBprotocolthatimpliesthat theshared, read-onlyvariableY is inthe
readable stateinall cachesthatcontainit.Thisallowsanycachetoreadthedatavalue associated with Yandbeensuredthatit is receivingthemost up-to-date value 106 shared-memorymultiprocessors
Acomputer systemthatconsists of atleasttwoindependentprocessor modulesexecutingeither a small
taskof alargerprogram,orcompletelyindependentprograms.Alloftheprocessors make references
toinstructionsanddatathatresideina mainmemorymodulethatissharedamongtheprocessors... 95
shared-unmodified state
Astate usedin Papa'sprotoclthatindicatesthatsome othercache(s) mayhavethisblockandthatthe
data intheblock isconsistent withthatinmainmemory 104 snoopycache coherence protocol
Acache coherence protocolthatrequiresthat theresponsibilityofmaintainingcachecoherenceis
distributedamongthelocalcaches 100
snoopycache controller
A
bus-watching
mechanism usedinshared-memorymultiprocessorsthatwatchesthe communicationbus forall actionsaffectingshareddata 98
spatial
locality
A fundamental propertyofthememory
hierarchy
which statesthata processtends toaccessitemswhoseSRAM
StaticRandom Access Memory. Adesign
technology
usingstaticmemorycellsinthedesignof a memoryunit.Ina staticmemory cell,thecontents are retained until poweriseliminated,andthecontents storedinthememorycell arelost.
Usually
used withthedesignof a cachememoryunit 2 standardlogicvectorAVHDLtermusedtodescribeanarrayofbits intheformof a
binary
number.Eachbit inthearraycanbe
individually
accessed 19storeback Seewritebackcache
storethrough Seewritethroughcache
sub-block placement
Acacheimprovementstrategy inwhich a cacheblockisdividedintoseveral smaller
blocks,
calledsub-blocks,
anda validbit isassociated with each ofthesesub-blocks 87 subtypeA VHDLtermusedtodescribea user-defined variabletype thatwill
help
describeanother user-definedtype 22
sumtest
Atest-benchprogramdesignedas a sample applicationthatcouldberunontheprocessor.Thisprogram findsthecumulative sum of allthedatavaluesinmainmemory 61 Synopsys
AsynthesizerthatacceptsVHDLcode and returns a gate-level schematicperformingthefunctionsof
theVHDLcode 18
T bytesorTB
Terabytes. Aunitof measurethatmeasures
2A40,
or 109951 1627776bytes 2temporal
locality
Afundamental propertyofthememory
hierarchy
which statesthatrecentlyreferenceditemstend toreferencedagaininthenearfuture 3
thrashing
Whentheupper-levelofmemory ismuchsmallerthanwhatisneededforaprogram,causingtheCPU torun closeto thelower-level memoryspeed,sincethatiswhere most ofthedatareferenced resides.
12
transferbandwidth
Therate at whichinformation istransferredbetweenlevels iandi+1ofthememory
hierarchy
1type
A VHDLtermusedtodescribeuser-defined variablesthat
help
theprogrammerimplementthegoals ofhis/herprogram 22
U
unit oftransfer
Thegrain sizeforadatatransferfromlevelito i+1 1
UnOwnedstate
Astate usedinthe
Berkeley Ownership
protocolthatindicatesthatseveral cachesmayhavecopies ofthisblock.Theblockcontains validdatathatispossiblysharedamongothercaches Ill
valid state
Astateinthewrite-once cacheinwhichthecacheblockcontainsdatawhichhas beenreadfrommain
memory,but hasnot yetbeenmodified 8
VHDL
VHSIC Hardware DescriptionLanguage. An
industry
standardlanguageusedtodescribe hardware fromtheabstracttotheconcretelevel 17
Very
High Speed Integrated Circuitprogram.ThepredecessortoVHDL 17 victim cacheAsmallfully-associativecache placedbetweenthemaincacheand mainmemorythatcontainsonly blocksthatare evictedfromthecache,inordertogivethena"secondchance"
toremaininthecache
priorto
being
reportedinmainmemory 82W
wrappedfetch
critical wordfirst See
write around Seeno-write-allocate
writebackcache coherence protocol
Acache coherence protocolinwhichthecontents ofthecacheblockare writtentomainmemory only whentheblock isrequested
by
anotherCPUanditscontentshavebeenmodified 100 writebufferAdeviceaddedto thedesignofthecache which storesblocksthatneedtobewrittentomainmemoryso
thattheCPUcan resumetheexecution ofitsprogram 8
write once cache coherence protocol
Acache coherence protocolthatrequiresthefirstwritetoanycacheentrytobewrittenthrough tomain
memory,usingthewritethrough protocol,andanysubsequent writetobereportedtomemoryafter
theblock isevictedfromthecache,usingthewritebackprotocol 101
Writeoperation
Abusoperation usedinthe
Berkeley
Ownership
protocolthatisa conventional writethatcauses mainmemorytobeupdatedand all cached copiestobe invalidated 112
write stall
WhentheCPUis halted dueto thecache
having
tocontinuouslywritetomainmemory 8writetest
Atest-benchprogramdesignedtoverifythewrite operation ofthecacheimplementations 54
writethroughcache coherence protocol
Acache coherence protocolinwhich all cache updates are reportedtomainmemory 100
WRITE_BACK_CACHE_TYPE
AVHDLpackage used withinthe thesis tostorethe parameters used withintheimplementationsof a
write-backcache 27
writehitaddressmodify
Anoutput signalsenttomainmemorythatcontainstheaddress of ablockthatis
being
modifiedforthe firsttimeastheresult of a write-hitina write-once cache 43writehitaddressmodifyfromcache
An inputsignaltomainmemorythatisused withthewrite-once cacheimplementations.Thissignal receivestheaddressoftheblockthathasbeenmodifiediftheblockwasfirstreadintothecache,and latermodified,
indicating
that thefirstwriteto thisblockoccurred astheresult of a cache write-hit. 23 writehitdatamodifyAnoutput signal senttomainmemorythatcontainsthedataassociated withtheblockaddressed
by
thewritehitaddressmodifysignal 43
writehitdatamodifyfromcache
Aninputsignalthatreceivesthedata correspondingtotheaddressindicated
by
writehitaddressmodifyfromcache 23
writemissaddressmodify
Anoutput signal senttomainmemorythatcontainstheaddress of ablockthatis
being
modifiedforthefirsttimeas a result of a write-missina write-once cache 43 write_miss_address_modify_from_cache
An inputsignalthatisused withthewrite-once cacheimplementations.Thissignal receivestheaddress ofablockreferenced
by
awrite,however,
theblock doesnot yet exist withinthecache,indicating
thata write-misshasoccurred withinthecache 23
Anoutput signal senttomainmemorythatcontainsthedataassociated withtheblockaddressed
by
thewrite_miss_address_modifysignal 44
write_miss_data_modify_from_cache
Aninputsignalthatreceivesthedata correspondingto theaddressindicated
by
write_miss_address_modify_from_cache 23
writemissfromcache
Aninputsignaltomainmemorythatreceivesthefactthata write-miss occurred withinthecache 23 writemissout
Anoutput signalthatissenttomainmemorywhichindicatesthata write-miss occurredinthecache.. 33 WRITE_ONCE_CACHE_TYPE
A VHDLpackage used withinthethesistostoretheparameters used withintheimplementationsofa
write-oncecache 27
WRITE_THROUGH_CACHE_TYPE
AVHDLpackage used withinthe thesistostoretheparameters used withintheimplementationsof a
write-throughcache 27
write-allocate
Acachedesignoptioninwhich, on awrite-miss,theneededblock is bought intothecache and modified
without mainmemory
being
informedofthemodification 9write-back cache
Acachedesign inwhichinformationon a writeiswrittenonlytothecache 8 Write-For-Invalidationoperation
Abusoperation usedinthe
Berkeley Ownership
protocolthatisa quick version oftheconventional write,but doesnot reportthemodification ofthedatavaluetomainmemory 1 12 write-missAneventthatoccursinthecache whentherequireddatablockneedstobemodified,but isnot resident
inthecache 9
write-once cache
Acachedesign inwhichthefirstwritetoablock inthecacheisreportedtomainmemory,butall subsequent writesto thisblockare not reportedtomainmemoryuntiltheblockisevictedfromthe
cache 8
write-throughcache
Acachedesign inwhichinformationon a writeiswrittentoboththecache andtomainmemory 7 Write-Without-Invalidationoperation
Abusoperationinthe
Berkeley
Ownership
protocolthatcauses mainmemorytobeupdated withthe1
The
Memory Hierarchy
When
discussing
the interactions between a cache and main memory, it is importantto understand theconcept ofthe memory
hierarchy
andthe properties thatjustify
the different levelsthat thehierarchy
is broken into. Oncethememoryhierarchy
is explained,and itsrules arepresented,notonlycan onebetterunderstand the communications between the cache and main memory, but those ofthe entire memory structure.
The memory
hierarchy
basically
consists offive levels:theregistersintheCentralProcessing
Unit(CPU),
thecache, themainmemory,adiskstorage
device,
andbackup
units,such as magnetictapes. Theselevelsare shownin Figure 1.
Increasein capacity andaccess
time
Level
4\
Tape Units (Magnetic tapes, Opticaldisks)
/
Level 3
\
Disk Storage (Solidstate,magnetic)/
Level 2
\
MainMemory
(dRAMS)
/
Level 1 Cache
(sRAMS)
Level 0
Registersin CPU
Increasein cost perbit
[image:24.553.53.470.294.499.2]Capacity
Figure 1. Designof aFive-Level
Memory
Hierarchy
[Hwangl993,
p.189]Thereare alsofiveparametersthat
help
characterizethe levels:the accesstime(ti),
memorysize(si),
costperbyte
(a),
the transferbandwidth(bi),
and the unitoftransfer (xt).The access timeis thetotal time it takesto accesstheCPU fromtheithlevelofthememoryhierarchy. The memorysizereferstothenumberofbytesin leveliofthememoryhierarchy. Thecostoftheith level is usually estimated asthe cost per
byte,
or Cis;.Thebandwidth istherate at whichinformation istransferredbetween levels iandi+1.Finally,
theunit oftransferrefers to the grain size foradatatransfer from level i to i+1. As a general rule, the
more expensive per
byte,
have a higherbandwidth,
and use a smaller unit oftransfer as compared with thoseat ahigher levelofthememoryhierarchy
pyramid[Hwangl993,
p. 188]. Insymbolicterms,wehavethefollowing:
ti-i <ti accesstimeincreasesas onemovesupthememory
hierarchy
pyramidsi-i < si sizeincreasesas one movesupthememory
hierarchy
pyramiden > ci cost perbit decreasesas one movesupthememory
hierarchy
pyramid bi-i>bi bandwidthdecreasesas one movesupthememoryhierarchy
p\Tamidxi-i <xi unit oftransferincreasesas one movesupthememory
hierarchy
pyramidTheserelationships arebetterunderstood
by
thevaluesdepicted in Table 1.Memory
Level Characteristics Level 0 CPU Registers Level 1 Cache Level 2 MainMemory
Level 3 Disk StorageLevel 4 Tape
Storage Device
technology
ECL 256K-bit SRAM 4M-bit DRAM 1-Gbyte magnetic diskunit 5-Gbyte magnetic tapeunit Accesstime,fc 10ns 25-40ns 60-100ns 12-20ms 2-20min(searchtime)
Capacity,
si(inbytes)
512by.es 128Kbytes 512
Mbytes
60-228
Gbytes
512Gbytes-2Tbvtes
Cost,
ci(incents/KB)
18,000 72 5.6 023 0.01
Bandwidth,
bi (inMB/s)
400-800 250-400 80-133 3 to5 0.18-0.23
Unitoftransfer, Xi
4-8bytesper word 32bytes perblock 0.5-1 Kbytesper page 5-512 Kbytes perfile
Backup
storage Allocation Management Compiler Assignment Hardware controlOperating
systemOperating
system/userOperating
system userTable 1.
Memory
Characteristicsof aTypical Mainframe[Hwangl993,
p.190]
1. 1
Inclusion,
Coherence,
andLocality
When
discussing
issueswithinthememoryhierarchy,
it is importanttounderstandthethree fundamentalconcepts of
inclusion,
coherence, and locality. In thefollowing
sections, it is assumed that the cachememoryisthe lowest levelMiand communicates
directly
withthe CPUanditsregisters, labeledMo. The highestlevelis labeledM_,
andcontains all oftheinformation words storedin thememoryhierarchy,
as1.1.1
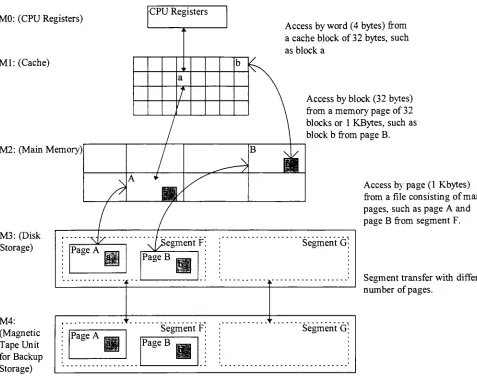
Inclusion
The inclusion property is stated as Mi c M> c Ms ... c Mn. This property implies thatall information
itemsareoriginallystoredinthehighest level Mn.
During
theexecution of aprogram, portions,or subsets ofMnare copiedintoMn-i,
and portions ofMn-i arefurthercopiedtolevelMn-2.Thus,
ifa wordisfound in levelM,
itwill also be found in levelM+i, M-_,
and so on upthechain, until the highest level Mn isreached. Awordmiss occurs when a wordis searchedforin level
M,
but is not found. Ifa word miss occursin levelM,
italso meansthata word miss occurredinalllower levelsMi-i, M-2,
... Mi.Anotherconcept associated withinclusion inthememory
hierarchy
is themethodofinformationtransfer between two levels ofthehierarchy. The CPU and cache communicatethrough words(typically
4 or 8 byteseach). Duetotheinclusionprinciple, the size of a cacheblockmustthen be biggerthan thesize of the memoryword, and is typically 32bytes,
or 8 words. The cache and main memory communicate through blocks. The main memory is divided into pages(typically
128 bytes). Pages are the units of informationtransferbetweenthediskand main memory. Atthehighest levelofthememoryhierarchy,
thepages ofthe main memory are stored as segments in the
back-up
storage device. These terms, and the principleofinclusion,
areillustrated in Figure 2.1.1.2
Coherence
Thecoherencepropertyrequiresthatcopies ofthe sameinformation itemathigher levels ofthememory
hierarchy
be consistent. This impliesthatifa word ismodified in the cache, forexample, copies ofthat word mustbeupdatedeitherimmediately
(write-through method)oreventually (write-back method)at all higherlevelsofthememory hierarchy.1.1.3
Locality
The memory
hierarchy
was developed based on a behavior characteristic observed within the CPU thatMO:(CPU
Registers)
Ml:
(Cache)
CPU Registers
*.
'r
b
a
/
i rM2: (Main
Memory)
M3: (Disk
Storage)
M4:
(Magnetic
Tape Unit
for
Backup
Storage)
Access
by
word(4bytes)
from a cacheblockof32bytes,
suchasblocka
Access
by
block (32bytes)
fromamemorypage of32blocksor 1
KBytes,
suchasblockbfrompageB.
Access
by
page(1Kbytes)
fromafile consistingofmany
pages,such as pageAand
pageBfromsegmentF.
[image:27.553.32.509.66.442.2]Segmenttransferwithdifferent numberof pages.
Figure 2. The Inclusion
Property
andData TransfersBetween Adjacent Levelsof aMemory
Hierarchy.
[Hwangl993,
page191]
In
designing
a certain level ofthe memoryhierarchy,
the above dimensions oflocality
offer some suggestionsto an effective design. Thetemporallocality
dimensionwould leadto the popular use oftheLeast
Recently
Used(LRU)
replacement algorithm and wouldhelp
determine the size ofmemory at successivelevelsofthememory hierarchy. Thespatiallocality
dimensionassistsindetermining
thesize ofIntroduction to
Cache
Memory
Cache memory is a small,
fast,
memoryunit thatis usually placed between the CPU andthe physicalmemory.It
typically
storesthemostrecentlyusedinstructionsand/ordataundertheassumptionthat these instructions/datawillbeused again shortly. Since instructions arerarely writtento, this thesiswill solely dealwith accessestodataresidinginthecache.Thecachememoryis fastertoaccessthan thephysical memory.Ascanbeseenin Table2.as one moves furtherandfurtherawayfromthe
CPU,
thesize ofthememorystorage unitincreasesas wellastheaccesstime.
Thus,
memoryunits closeto theCPU,
suchastheinternalregisters andthecache,requirelesstimetoaccessthanthephysicalmemoryand externaldiskstoragedevices.
Level 1 2 3 4
Called Registers Cache Main
Memory
Disk StorageTypicalsize <1KB <4MB <4GB >1 GB
Implementation
Technology
Custom memory with multipleports, CMOSorBiCMOS
On-chip
or off-chip CMOS SRAMCMOS DRAM Magneticdisk
Accesstime(in ns) 2-5 3-10 80-400 5000000
Bandwidth (in
MB/sec)
4000-32000 800-5000 400-2000 4-32Managed
by
Compiler HardwareOperating
System
Operating
Systemand User
[image:28.553.64.474.277.432.2]Backed
by
Cache MainMemory
Disk TapeTable 2. The IncreaseofAccessTimeandDecrease in BandwidthasOne Moves
Away
fromthe CPU[Hennessy
1996,
p.41]2. 1
Types
ofCache Memories
Withinthe cache memory, there mustbe a way forthe CPU to knowwhere the necessary information
resides. This enforces a mapping on the data/instruction blocks in the cache. There are three general formats for the mapping of a block into the cache:
direct-mapped,
fully-associative mapped, and2.1.1
Direct
Mapped
Inadirect-mappedcache,eachblock has onlyoneplacethatitcan go.
Thus,
whentheCPUneedsa certaindata
block,
there is only one placethat it could possibly reside inthe cache. Ifit is not there,then theneeded blockmustbe fetched from the higher level ofthe memory
hierarchy,
and the block that waspreviouslyinthisposition inthecache mustbeevicted. In orderto determinewherethe blockresides in
thecache,theblock frameaddressis divided
(modulo)
by
thenumber ofblocksinthecache. Theresultofthisintegerdivisiongivesthepositioninthecache wheretherequesteddatablockwould reside.
2.1.2
Fully
Associative
Inafully-associativecache, thereare no restrictions astowheretheblockcanbeplaced. WhentheCPU
needs a certaindata
block,
itmust check eachblockthatresides inthecache todetermine ifthe requiredinformation ispresentinthe cache. A blockis only evictedfroma fully-associative cache ifthe cache is full.
2.1.3
Set Associative
Ina set-associativecache,thedata block isrestrictedtoa certain set of places.Asetconsists of agroupof
twoor moreblocks inthecache.When placingablock frommainmemory intothecache,theblockisfirst
mappedtoaset, andthen theblock is freeto go anywhere withinthatset.
Thus,
set-associativemapping combinesthe featuresofbothdirect-mapping
and fully-associative mapping in thatthe block isdirectly
mappedtoaset, andthenis
fully
associative withinthatset. To determinethesetthat theblockshouldbeplaced
in,
the block frame address is divided(modulo) by
the number of setsthat are inthe cache. Theresult ofthis integerdivision gives the set number
(starting
from zero and going until one minus thenumber ofsets)that therequestedblockwouldbemappedto.Acacheissaidtobe n-wayset associativeif thereare nblocksineach set.
2.1
.4The
Effect
ofAssociativity
onthe
Cache
Performance
Most caches today are set-associative, and
increasing
the degree of associativity has the effect ofdecreasing
the miss-ratio since moreblocksare allowedintothe cachebefore one needstobe evictedinorder to make more room in a set [Smith1987]. The highest miss ratios are thus observed in direct mapping,inwhichthereisonlyoneblockthatcanbemappedtoeach set.
Two-way
associativity is slightlybetter
by
allowingtwoblockswithin each set, and,asassumed,three-way
associativity is betterthantwo-way [Smithl987].
Eventually
a pointisreached wherefurther increases intheassociativity hasnoeffectonIncreasing
the degree of associativity also has some disadvantages. First of all, the normal parallel implementationofacache requiresthat thenumber of comparators anddatareadout paths equalthedegreeof associativity. As the degree ofassociativity isthus
increased,
the hardware costs ofimplementing
it increases and becomes very expensive [Smithl987]. A study onincreasing
the degree ofassociativitywithina cache was performedinthis thesisandis discussedon page76.
2.2
Finding
aBlock Within
the
Cache
Whenthe CPUneeds a certainmemory
block,
it shouldfirst checkthe cacheto see ifthe block residesthere.
Accessing
the neededblock fromthe cachememorywill be fasterthanretrieving it from ahigher levelofthememory hierarchy.To determine ifthe blockresidesinthecache, eachblock inthe cache includes an addresstagthat gives
the block frame address. Each appropriate tag in the cache is checked in order to see if the block it
corresponds to contains the information needed. These tags can be checked in parallelto speed up the
memoryaccess. Notethatinadirect-mappedcache, only oneblockneedstobechecked, whileina
set-associativecache, allblockswithinthe set needtobechecked. Theworse caseiswith a fully-associative
cache, where all the blocks in the cache must be checked to determine ifthey contain the requested
information,
however,
oncetherequestedblock isfound,
theremaining blocks donot needtobechecked.2.3
Writing
to the
Cache
WhentheCPUneedstomodifythe value of adata
block,
the requestedblockshouldfirstbe checkedtoseeifitisinthecache.Ifit
is,
threeschemes existforwriting datato thecache: write-through, write-back,andwrite-once.Theseschemes also representthe threedifferentcache architecturesthatwereimplemented
inthis thesis.
2.3.1
Write-Through
Ina write-through cache(alsoknownas storethrough),the information iswrittenbothto theblock inthe
cache andto the correspondingblock inmain memory. In
implementing
this strategy, boththe cache and mainmemorycontaintheupdated value. This is importantwhenworking with external input and outputOneproblem withthewrite-through cacheisthattheCPU couldhavetowaitforallofthewritestomain
memorytofinish before continuingwiththeexecution ofitsprogram.Whenthe CPU ishalteddueto the cache
having
towritethe updateddatavalueto mainmemory, a write stallhas occurred. To reducethe effect of writestalls, a write buffer is usually included inthe design of a cache. Thewritebuffer storesblocks thatneedto bewrittentomainmemory sothat theCPUcan resume the execution ofits program
whilethewritebufferwrites itscontentsbacktomainmemory inparallel withthe execution ofthe CPU. Write buffers of different sizes have been implemented in various cache designs,
however,
theirimplementationis beyondthescope ofthis thesis.
2.3.2
Write-Back
Ina write-backcache(alsoknownascopy
back,
or storeback),
theinformationiswrittenonlyto theblock inthecache.Thus,
themodified value willbewrittentomainmemory onlywhenthisblockisevictedfrom thecache,if iteveris. Whilethismodifiedblockstill residesinthe cache,it isreferredtoas adirty
block,
meaning that theblockhas beenmodified while itwas inthe cache, but its contents have not yet been
writtenbacktomain memory.Thestatus of ablock is usually determined
by
adirty
bitwhichtellswhether the cache data block is clean (the contents ofthe cache arethe same as that in memory) ordirty
(thecontents ofthe cache differ fromthat in memory). Ifthe block is clean, there is no need to report its
contentstothehigher level ofmemorywhen it is evicted since its contents have not been changed. The
dirty
bit featureis especially attractive tomultiprocessors since it speeds up the memory accessby
notrequiring everywritetogo
directly
tothemainmemory[HennessyT996,
p. 380].2.3.3
Write-Once
The write-onceprotocol, proposed
by
John Goodman[Goodmanl983],
combines the write-through and write-back protocolsintoone, inordertogetthebenefitsofboth. Thewrite-once protocol requiresthefirstwrite to any cache entry to be writtenthrough to main memory, usingthe write-through protocol.
Any
subsequent writetothatcacheblockwillbe donelocally
inthe cache, butthe modifications willonly be writtentomainmemoryaftertheblockisevictedfromthecache,hencetheuse ofthewrite-back protocol.To implement the write-once protocol, two bits are associated with each cache block. The two bits distinguishamongthefourstatesthata cacheblockmay residein:
invalid,
valid, reserved,ordirty. Intheinvalidstate,the cacheblockcontains nodata. Inthevalidstate,thecacheblock contains datawhichhas
been read from main memory and has not yetbeen modified.
Hence,
the cache and main memory areconsistent with respecttothisblock. Thereserved stateindicatesthat theblock has been
locally
modifiedstate,
dirty,
indicatesthat thecacheblock hasbeenmodified morethanonce sinceit hasbeen brought intothe cache,andthelatestchangehasnot yetbeentransferredtomain memory.Inthis state, thecache and
mainmemoryareinconsistentwith respectto thiscacheblock.
2.3.4
Comparing
the
Strategies
Thewrite-throughprotocolhas beenthemost common approach sinceitissomewhat simplertoimplement
than thewrite-backprotocol,and also sinceitisnevernecessarytoreportanythingtomemoryafterablock
is evicted from the cache. Another advantage ofthe write-through protocol is that the cache and main
memory are always consistent with each other, whereas in the write-back protocol, the most up-to-date
copy mayresideinthecache.This advantagemay beusefulin shared-memorymultiprocessors, discussed
on page95.
Despitethe above advantages ofthe write-through protocol overthe write-backprotocol, the write-back
protocolisstartingtobecomeverypopularduetoitsprevention ofthebandwidth bottleneckofthe write-through protocol [Smith1987]. Since not every write to the cache is
immediately
broadcast to mainmemory inthe write-backprotocol, as is done inthe write-through protocol, considerable cacheto main
memory bandwidth is preserved, thus making the write-back protocol preferable in shared-memory
multiprocessorsin ordertoreducethe traffic tomain memory from each processor.
However,
the writeback protocol suffers from the cache coherence problem, described later in this thesis. Hence
shared-memory multiprocessors would want a write-through cache in order to
keep
the cache and memoryconsistent.Multiprocessorcachecoherence protocols willbe discussedon page96.
2.3.5
Writing
to the
Cache
on aCache Write Miss
The algorithms presented above onlywork when the memory block needed is in the cache. When the
desired blockisnotinthecache,a write-misshasoccurred, andthecachehastwooptions of
dealing
withit:writeallocate or no-write allocate.
2.3.5.1
Write-AIIocate
Ina write-allocate cache(alsoknownasfetchonwrite), theneededblockis loaded intothecachefromthe
mainmemory, andthenewdatavalue iswrittento theblockwhile itis in the cache. Themodified data
value isnot reportedtomainmemoryuntiltheblockisremovedfromthecache and writtenbacktomain
2.3.5.2
No-Write-AIIocate
Ina no-write-allocate cache(also knownas writearound),theblock ismodified
directly
inmainmemoryand notfirst brought intothe cache. This scheme is generallyused withthewrite-through cache scheme
sincethetwostrategies areverysimilar.
2.4
Sources
ofCache Misses
Ifa neededblock isnotfoundwithin acache, a cache-miss occurs andtheneededblockmustbeobtained
from main memory. It is importantto investigate the reasons for cache-misses occurring so that future
cache designs can incorporatethese scenarios into the designs of more optimal cache architectures. The
threemain sourcesof cache-misses areknownasThe Three C's:compulsory,capacity,andconflict.
2.4.1
Compulsory
Cache-Misses
A compulsorycache-miss meansthat thevery firstaccessto theneededblockresultsina miss. Underthis
typeofcache-miss, the neededblockmust be broughtinto the cache from main memory. This type of
cache-missisalsoknownas cold start miss orfirstreferencemiss.
2.4.2
Capacity
Cache-Misses
During
the executionof alargeprogram orprocess,it may be impossible forthe cacheto contain alltheblocks needed
during
its execution.Therefore,
a capacitymiss occurs when the needed blockhas beenrecentlyevictedfromthecachetomake roomforanotherblockand now mustbeplacedback inthecache
since it isneeded a^ain.
2.4.3
Conflict Cache
Misses
Conflict misses only occur in set-associative or direct-mapped caches, since these are the only cache
architecturesinwhichablockis evictedinordertomake roomforanotherblock intheset.
Thus,
ifaset-associative ordirect-mapped placement strategy is used, conflict misses, in additionto compulsory and
capacitymisses,will occur sincetoomanyblockswillbemappedtoaset,or a particular position. Conflict
2.4.4
The Overall Effect
ofThe Three C's
onthe
Design
ofCache
Memory
Todeterminethe overall effect ofthe Three C's on a cache memory, a simulation was performed on acache with32-byte blocksandusing anLRU replacementscheme on aDECstation 5000 computer. The
results ofthesimulation arereportedin
[Hennessy
1996,
p.391]
and are showninTable 3.CacheSize Degreeof
Associativity
Total
Miss-Rate
Compulsory Capacity
Conflict1 KB
1-way
0.133 0.002 1% 0.080 60% 0.052 39%1 KB
2-way
0.105 0.002 2% 0.080 76% 0.023 22%1 KB
4-way
0.095 0.002 2% 0.080 84% 0.013 14%1 KB
8-way
0.087 0.002 2% 0.080 92% 0.005 6%2KB
1-way
0.098 0.002 2% 0.044 45% 0.052 53%2KB
2-way
0.076 0.002 2% 0.044 58% 0.030 39%2KB
4-way
0.064 0.002 3% 0.044 69% 0.018 28%2KB
8-way
0.054 0.002 4% 0.044 82% 0.008 14%4KB
1-way
0.072 0.002 3% 0.031 43% 0.039 54%4KB
2-way
0.057 0.002 3% 0.031 55% 0.024 42%4KB
4-way
0.049 0.002 4% 0.031 64% 0.016 32%4KB
8-way
0.039 0.002 5% 0.031 80% 0.006 15%8KB
1-way
0.046 0.002 4% 0.023 51% 0.021 45%8KB
2-way
0.038 0.002 5% 0.023 61% 0.013 34%8KB
4-way
0.035 0.002 5% 0.023 66% 0.010 28%8KB
8-way
0.029 0.002 5% 0.023 79% 0.004 15%16KB
1-way
0.029 0.002 7% 0.015 52% 0.012 42%16KB
2-way
0.022 0.002 9% 0.015 68% 0.005 23%16KB
4-way
0.020 0.002 10% 0.015 74% 0.003 17%16KB
8-way
0.018 0.002 10% 0.015 80% 0.002 9%32KB
1-way
0.020 0.002 10% 0.010 52% 0.008 38%32KB
2-way
0.014 0.002 14% 0.010 74% 0.002 12%32KB
4-way
0.013 0.002 15% 0.010 79% 0.001 6%32KB
8-way
0.013 0.002 15% 0.010 81% 0.001 4%64KB
1-way
0.014 0.002 14% 0.007 50% 0.005 36%64KB
2-way
0.010 0.002 20% 0.007 70% 0.001 10%64KB
4-way
0.009 0.002 21% 0.007 75% 0.000 3%64KB
8-way
0.009 0.002 22% 0.007 78% 0.000![Figure 1. Design of a Five-Level Memory Hierarchy [Hwangl993, p.189]](https://thumb-us.123doks.com/thumbv2/123dok_us/118691.11495/24.553.53.470.294.499/figure-design-level-memory-hierarchy-hwangl-p.webp)
![Table 2. The Increase of Access Time and Decrease in Bandwidth as One Moves Away from theCPU [Hennessy1996, p.41]](https://thumb-us.123doks.com/thumbv2/123dok_us/118691.11495/28.553.64.474.277.432/table-increase-access-decrease-bandwidth-moves-thecpu-hennessy.webp)

![Table 4. Design Target Miss Ratios for a Unified Cache [Smithl987].](https://thumb-us.123doks.com/thumbv2/123dok_us/118691.11495/36.553.54.501.50.224/table-design-target-miss-ratios-unified-cache-smithl.webp)