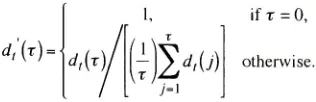Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
2006
Nonverbal Vocal Interface
Michael J. Murdoch
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please [email protected].
Recommended Citation
G0GGOOOOQ G080Q
OG0000080
Michael J. Murdoch
June
29, 2006Master
's thesis submitted to the faculty of the B. Thomas
Golisano College of Computing and Information Sciences in
partial fulfillment of the requirements for the degree of
Master of Science in Computer Science.
Chair
Joe Geigel
Reader
Warren Carithers
Observer Carl Reynolds
Copyright2006 Michael J. Murdoch. Allrightsreserved.
Thesis/Dissertatio Author Permission Statement
Title of thesis or dissertation: _ _
-L...I'--'
tJ.
e.LL=--
~
--'---"
6
""
bJ
'-"
(
'---"--
~
-'="
t}(
'---""-=--
I
_
~
"--'---~---'---~'-""=
~
_ _ _ _ _ _Name of
authO"
~
&h
E
.
~d.J,
Degree:
J1
b~=--
-Program: v <:':: ~ L.L.
College:
<1
Cc I3
I understand that I must submit a print copy of my thesis or dissertation to the RIT Archives, per current RIT guidelines for the completion of my degree. I hereby grant to the Rochester Institute of Technology and its agents the non-exclusive license to archive and make accessible my thesis or dissertation in whole or in part in all forms of media in perpetuity. I retain all other ownership rights to the copyright of the thesis or dissertation. I also retain the right to use in future works (such as articles or books) all or part of this thesis or dissertation.
Print Reproduction Permission Granted:
I,
Michael J. Murdoch
, hereby grant permission to the Rochester Institute
Technology to reproduce my print thesis or dissertation in whole or in part. Any reproduction will not be for commercial use or profit.Signature of Author: _ _
....:.M..:..:.:.:ic::..:.h.:..:a::..::e:..:.I..::.J.:...:. Mc..:...:..:::u::..:.r..:::d...:::o...:::c.:...:h _ _ _ _ _ _ _
Date: _ _ _ _ _Print Reproduction Permission Denied:
I, , hereby deny permission to the RIT Library of the Rochester Institute of Technology to reproduce my print thesis or dissertation in whole or in part.
Signature of Author: _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ Date: _ _ _ _ _ _
Inclusion in the
RIT
Digital Media Library Electronic Thesis & Dissertation (ETD) Archive
I,
Michael
JMurdoch
, additionally grant to the Rochester Institute of Technology
Digital Media Library (RIT DML) the non-exclusive license to archive and provide electronic access to my thesis or dissertation in whole or in part in all forms of media in perpetuity.I understand that my work, in addition to its bibliographic record and abstract, will be available to the world-wide community of scholars and researchers through the RIT DML. I retain all other ownership rights to the copyright of the thesis or dissertation. I also retain the right to use in future works (such as articles or books) all or part of this thesis or dissertation. I am aware that the Rochester Institute of Technology does not require registration of copyright for ETDs.
ooooooeo
Nonverbal vocal interface, meaning the use of non-speech vocal sounds such as "oooh"
and
"ahhh"
asinputtoacomputer,provides an
interesting
and usefulinput modality for a graphical user interface. Nonverbal vocal interface is a novel improvementover speech-basedsolutionsbecausevoicedsoundsmaybesmoothlymodulated, meaningtheyarewellsuitedto control ofcontinuousvariables such as cursorposition, while spoken commands are
inherently
discrete. Agraphicaluser interface isan excellent environmentforvocal inputbecause instantaneous visual feedback is crucial to usability, enabling users to see the results of their vocalizations and learn the interface very quickly. Continuously voiced sounds maybe easilyandindependently
modulatedindimensions such asvolume, pitch, and vowel. Thesedimensions may beusedtoaugment afamiliar input devicesuch asthe mouse,addinganotherdegreeoffreedomto theinteraction. Forexample, a mouse-basedpaintingprogrammaybe improvedby
usingvocal volumetocontrol brush size while painting. Vocal input may alternatively be used without other inputdevices,forexampleto controlthecursorintwodimensions. Thisoffers an opportunity to improve access to computing forusers unableto operate a mouse. In this thesis, the use of nonverbal vocal interface for graphical interaction is explored. Vocal dimensionsofvolume, pitch, andvowelare detected inrealtimeOGOOOOOOOOGOOOOO
Iwould liketo thankProfessorJoe Geigel for supportingthisworkand giving me thefreedomtoexplore a crossroads offieldsof study. IadditionallythankWarren
Carithers and Carl Reynolds fortheir service on my committee. Without
listing
names, Iexpress mygratitude to the volunteers whosubmitted themselves to my vocal pitch/vowel experiment. Theirtimeandfeedbackwereinvaluable.
Mostimportantly, Ithank mywife, Meredith, for her patience with the extended
oooooooo
l INTRODUCTION 13
1.1 User Interface 13
1.2 Vocal Input 14
2 DISCUSSION 15
2.1 Multimedia Art 15
2.1.1 Audiovisual Relationships 15
2.1.2 Audio Interactions 16
2.2 Human-Computer Interaction 17
2.2.1 Vocal Interface 18
2.2.2 EvaluatingCursor Control 18
2.3 PitchandVoice Analysis 19
2.3.1 Volume Detection 19
2.3.2 PitchDetection 20
2.3.3 VowelDetection 22
2.4
Summary
233 HYPOTHESIS 24
4 EXPERIMENTS 26
4.1 Experiment1 26
4.1.1 Description 26
4.1.2 Implementation 27
4.2 Experiment2 27
4.2.1 Description 27
4.2.2 Pitch Detection 28
4.2.3 VowelDetection 29
4.2.4 UserTest 30
5 RESULTS 33
5.1 Experiment1 33
5.2 Experiment2 34
6 CONCLUSION 39
6.1 Experiments 39
6.2 Future Work 40
6.3 FinalThoughts 40
7 BIBLIOGRAPHY 43
A IMPLEMENTATION 45
A.i Experiment1 45
A.2.1 Pitch Detection 46
A.2.2 Vowel Detection 48
A.2.3 User Test 49
A.2.4 NotesonSpeed 5
B CODE 51
B.i Experiment1: soundVolDraw2 51
B.2 Experiment2: sound_analysis2 53
B.3 Experiment2: cursorTest 58
ooooooo
o
oooooo
Figurel: Analysisofmedium-frequency
"oooh."
28 Figure 2: Analysisof
low-frequency
"oooh."
29 Figure3: Analysisofmedium-frequency
"ahhh."
30
Figure4: Usertestpractice screenfromcursorTest program 31
Figure5: Example
drawing
usingvocal volumetocontrolbrushwidth 33 Figure 6: Exampledrawing
usingvocalvolumetocontrolbrushwidth 34 Figure7: Usertesttimesover a series oftestsshowingthelearning
curve 36 Figure 8: User category averages for the first two test, excluding extremes,shownas afunctionof spatialdirection 37
O OOOOOOOGOOOO
1.1
User Interface
User interface is a critical component of modern computer systems; it is the
windowthroughwhich a user simultaneouslyexpressescommandsto the machine
and receives feedback about how those commands are
being
interpreted.Commonly, user interface combines mechanical input with visual feedback, as is
the case with mouse pointer input. The metaphor ofthe computer screen as a
planardesktop,whichmay be navigatedintwodimensionswith a mouse or other
pointingdevice, isubiquitous, easilyunderstood,and effective. Inputdevicessuch
as a mouse, trackpad, thinkpad,joystick, or
drawing
tablet, are all extremelywell suitedfor controllinga pointerinatwo-dimensional environment. However, theyarelimited
by
theirtwo-dimensionality.Often,auser needs morethantwodimensionsofcontrol, forexample, tocontrola
third spatialdimension. Or, athirdorfourth degree offreedom may beuseful to
control other aspects of the user interface. Navigating a map, for example, is
primarilyatwo-dimensionaltask, whichmaybe easily done usinga mousetopan in the cardinal directions, but more control is useful. Otherdegrees offreedom,
such as zoom orrotation, require additionaldimensionsof userinputthatare not
typicallyprovided
by
themouse, exceptwith modifierkeys, scrollwheels, or other controls. Drawing programs provide another example suited to two dimensions but improvedby
more. The mouse pointer canlocate abrushtoolon thescreen,and the mouse button provide
binary
input to draw or not draw, but another degree offreedom to controlbrush pressure,line width, or opacitywould be verybeneficial.
Some users unfortunately maybe physicallyunable touse a mouse at all,
forcing
them to struggle to find alternative means to command a computer. Whether
adding degrees of freedom to those provided
by
the mouse or presenting theprimarymeans of controlto animpaireduser, theneedforadditionaldimensions
1.2
Vocal Input
Perhapsthisneedforalternativeoradditionaldimensionsof userinterfacecontrol
may be met through the user's voice. Speech recognition has a long history in computerscience,and itoffersthewonderful promise of aconversational, natural
language userinterface. However,thisdreamremainsdistant, andcurrent speech
recognition systems often have limited vocabulary or require calibration to the
voice of agiven user. Mostimportantly, regardlessifthesesignificanthurdlesare
overcome, speech recognitionisnot well suitedto thelow-leveluserinterfacetasks
described above. Speech recognition lends itself to dictation and discrete
commands, notcontinuous variableslikepointernavigationandbrushsize.
Amore
interesting
proposal is touse nonverbal, meaningnon-speech, vocalinputfor user interface. The human voice is wonderfully controllable and, just as
important, continuously variable. Voice volume may be modulated, up or down,
slowly or quickly, and a vocalized tone can be interrupted
by
tonguing or other staccato sounds. Consider a lengthened voiced vocalization, a sustained soundlike "oooh"
or
"ahhh."
The vocal pitch, or fundamental frequency, is easily
modulatedupanddown,heldconstant,or wavered with vibrato. Alternatively,the
vowel sound maybe modified, among
"oooh," "ahhh," "eeee," "ohhh"
and others.
All ofthese modulations canbe considered degreesoffreedom, andsignificantly,
they are for the most part each independent, meaning, for example, that a vocalization can change pitch regardless of whether it is changing vowel at the
oooooooooo
Considering
the context of nonverbal vocal interface requires review of work inseveral different fields. Voice and pitch detection, human-computer interaction,
and multimedia art, at least, are relevant to the study of nonverbal vocal user
interfacedesign, implementation, andtesting.
2.1
Multimedia
Art
Usingnonverbal vocal cues and inputfor computerinteraction is not an entirely new concept; however, most of the existing examples of such work lie in the
conceptual and artistic realm. Here, they are effective, interesting, and fun, but often not as pragmatically useful as they potentially could be. Nonetheless, a reviewis informative.
2.1.1
Audio Visual Relationships
A fun example to begin with is a performance art piece
by
[LEVI 03], furtherdescribed in [LEVI 04]. Using a combination of computer vision and
speech/sound analysis, they provided an audiovisual performance in which vocalizations are visualized in real time on a projection screen behind the
performer. This allows a series ofinteractive segments in which theirvoices are
"shown"
invarious ways. Mostoftheperformance segments provide visualization
of the
performers'
vocalizations, i.e., showing on the screen an emanation from their mouths as they proceed to speak or sing. Sound is visualized as waves, clouds,bubbles, and othersimiles. In one portion ofthe performance,vocal pitch
is used to control the direction of a paintbrush on the screen, with
descending
pitchturningthe brushclockwise, andascending counter-clockwise.The result is ratherchaotic, butan
interesting
tidbitinthissegmentis the use ofasharp"shh"
toerasethepainting. Theauthors speakof synesthesia andphonesthesia,inwhich
phonemes,orbasicelementsofspeech,are perceivedas
having
color orshape, asabasis fortheirworkandmotivationforthestudyof speechvisualization.
Other metaphors and sound/vision relationships are discussed in [EDMO 04], which presents avariety of artists and examples who have combined synthesized
music and computer graphics in various ways. They present some
interesting
visual, such as betweencolors and sounds andbetweentone intervalsand colors.
TheyciteJewanski,whostudiedperceptualdifferences betweencolorsandsounds. For example, "dissonance in musicis more unpleasant than dissonance in color; two colors creates a new unit, while two tones does not create a new tone;
perception of sound is normally relative, while perception of color is more absolute."
There ismention oftimbreas
being
relatedtocolor,butnoinformationabout specific relationships. The authors list all the ways that audio and visual
parameters can be or have been linked: mathematically, metaphorically, intuitively, or randomly. Unfortunately, this leaves the entire world open and doesn't provide any true insight as to which works well and whichworks poorly. Thefocusisreallyonperformance, art,andinteraction.
Several audiovisual artists and examples oftheir work are described
by
[EDMO04]. Adriano Abbado uses graphical visualizationforhissynthesized sounds, and uses filtered noise to synthesize sounds. Also, he produced an interactive
arrangementwherein
users'
motions relativetofloor-mountedsensors cancontrol
independentlyan aural stream and a projected visual stream. JackOx,while part of COSTART, created a timbre-based vowel/color system for vocal changes. YasunaoTonesynthesized soundrepresentationsofChinesecharacters, and setup a softboardinstrumentthatdetectscharacters
being
drawnandproduces sound.2. 1
.2Audio
InteractionsNot all artistic examples combine the visual with the audio. An interesting exampleof anentirelyauralinteractionisprovided
by
[BOHL04] and[BOHL05]. The authors implement a ratherwacky system, the Universal Whistling Machine(UWM), that responds to human whistles and replies with similar sounds, as if
engaging in conversation. They mention elSilbo, a whistled vocabulary used on Islade laGomera, intheCanaryIslands,as well asKuskoy,usedinTurkey. Each is a "reduced
language,"
simpler thantrue speech but still containing vocabulary and grammar: with prosody but without phonemes. This is
interesting
background, but intruththeUWMdoes notimplement anykindoflanguagewith itswhistlinginteraction.The responses ofthe UWM to humanwhistles are described as entirely random,
drawing
fromalong
list oftransformationsofthe human's input. The longertheback-and-forth interaction, the more complex the transformations become. In
termsofimplementationoftheUWM,audioinput,sampled at 44.1kHz, isfedtoa FFT-based pitch tracker, then it is analyzed in statistical moments
-standard deviation, kurtosis,and median
-to determineif it isawhistle
deserving
response. Whistle synthesisis basedonsubtraction,startingwithwhite noise, thenlow-passfiltering followed
by
tuned band-passfiltering
to select the desired frequency,Reactive transformations of human whistles include pitch translation, contour
inversion,time stretching, compression,andinversion.
The UWM system uses basic computer vision to recognize the presence of a
person, andthenwhistles toattract attention. Once the person responds withhis
own whistle, the game begins, andthesystem samplesand modifies therecorded
whistle and replies. This continues until the person becomes bored, which is
apparentlyasurprisingly
long
time, butwhat appearstobe a conversationis truly muchlessthanthat. Theauthorsdescribe whistlingas alow-level,low-bandwidth form ofcommunication, and call ahuman interactionwiththe UWM a"precursorto languaging." However, nothing is conveyed to either party, and nothing productive, beyond the person's amusement, comes from the interaction. The UWM is an
interesting
toy with which to study human-machine interaction, especiallyby
watching people try to "fool thesystem"
and see what they get in response.
Amorefocused interaction, albeit still without much productivity, is suggested
by
[OLIV 97], inwhich a vocalinputresultsinauralfeedback.The authorsdescribea
singing interface foraninteractive environment, theSingingTree, whichis part of a larger effort called the Brain Opera. The system responds to vocal input
-positively ifthe singer holdsa constantpitch, and negatively ifthe singer wavers. Therewardforconstant pitchisauralfeedback in
harmony
with angelic voices andsynthesized instruments, while thepenalty forwandering pitchis dissonance and
ugly rhythm. The system uses a real time DSP tool kit for pitch detection and vowel formant analysis,
focusing
ondetecting
changes in either rather thanabsolute pitch or vowel. Velocity,thus, ismoreimportantthanabsolute value. No detail isprovidedonthepitch or voweldetection,unfortunately.
The authors state that nonverbal input and aural feedback will be important to
future "smart"
application interfaces, yet their
lofty
goals are only meeklyapproached. Having such a simple goal of constant pitch makes for a rather
narrow user interface, though perhaps in the context ofthe entire Brain Opera it becomesinteresting.
2.2
Human-Computer Interaction
Therehasbeensome worktoemployvocalinputtomore productiveendsthanart
provides. Ofcourse, speech recognition is awell-establishedfield, andit is atthe
edges ofthe speech recognition literature that appear an
interesting
non-speechexample and an analysis of how appropriate speech-based solutions may be to
2.2. 1
Vocal Interface
[IGAR01]describesan
interesting
add-onto aspeechrecognition systeminwhichnonverbal sounds are used to control variable parameters. They suggest that nonverbal vocal cues can be used for three types of control: first, "control
by
continuous
voice,"
in which theuser makes a continuous sound foras longas he
wants to continue activating a control. Their example forthis is avolume knob,
where theuser says "volumeup,"
then says
"ahhh"
whiletheknob turns, stopping
whenthe knob has turned as faras is desired. Second is "rate-basedparameter
control
by
pitch,"
which is essentiallyan extension ofthe first interaction. They
provide an example of scrolling, in which a user says, "move
up,"
then makes a
continuous
"ahhh"
whose pitch determinesthe speed ofthe resulting motion. As
in theformer continuous voice control, the interaction stops whenthe userstops
vocalizing. The third interaction proposed is "discrete control
by
tonguing," in
which a parameteris changed indiscretesteps via hard-tonguedvocalizations. A
user who says "channel up, ta, ta,
ta,"
will see the channel change three steps
upward. Theymention"breathed
sound"
as aless tiringandlessannoying wayto interface,but don'texplain whattheymean.
The authors discuss several implementation details. The input audio signal is
digitized to 16 bits at 22 kHz, and the FFT is computed using a 2024-sample
Hanning window. Frequencies below 375 Hz are removed to avoidbackground
noise,and athresholdamplitudeisusedtodetectvoicing. Pitchchangeis detected
using dot products of12 msec time-shifted,
+/-43 Hz frequency-shifted spectra.
They comment that absolute pitch is not computed, and that some
users'
pitch
changesare notrobustlydetected.
This paper isveryimportant to thepresentdiscussion. Theauthors recognize the
immediacyand simplicityofinterpreting nonverbalvocalizations, buttheirvision
islimitedsomewhat,
focusing
onthe complementaryuse of speech recognition andnonverbal vocal interface. They mention
having
implemented their controls invideo games as well as the potential applications for
hands-busy
immersiveinteractionssuchascar navigation while
driving
as well as handicappedaccess. Inall ofthese cases, especiallyinthe examples theydescribe, real-time audio/visual feedback is crucial to the success of the vocal interface. For example, in the
volume-control example, the user simplystops saying
"ahhhh"
when the volume
reacheshissatisfaction. While providingagoodstart,theydon'tmakethe
jump
toeliminate speechinputentirely.
2.2.2
Evaluating
CursorControl
There is plenty of evidence that graphical user interface tasks are not especially
isratherdifficult; however,an
interesting
attempt atdoing
so is describedin [DAI04]. In their implementation, the authors divide an interface screen into a 3x3
grid ofboxes, numbered one through nine in row-major order. The user, whose
goal istoselect anicon onthe screen, speaks the number oftheboxthat contains
theicon,then thatbox is recursivelydividedintoa3x3 grid. Forexample, theuser
says, "Six,"
andthelinesare redrawntosubdivide what wasbox6. Thiscontinues
twoor three timesto reachtheproper spatial resolution, and the user eventually
says "Select
five,"
or something, which results in a mouse-click on the
disambiguated icon inbox 5. Additional commands move the whole grid in four
directionsorbackupa recursionlevel iftheusermakes a mistake.
Interestingly, theauthorsofthegrid approachdescribeausability studyperformed
with 24testsubjects familiarwith mouseand/orkeyboard based navigation. The
grid-based speech recognition program was implemented using Visual Basic and
IBM'sViaVoiceprogramfor speech recognition. The subjects were giventraining
tasksand
finally
testedforspeedinselectingon-screentargets. Their testinvolvesnavigating fromthe center ofthe screento each of a ring oftarget icons. Lotsof
results areprovided,but,notably, theaveragetime toselect atargetusingthe
grid-based program was nearly 8 seconds. This is cited to be 33% faster than other
speech-based navigation methods but is obviously much slower than using a
mouse. However, it is exceedinglyusefulifamouseis not an option. Theauthors
conclude
by
recognizingthat"it is generallyacceptedthatspeechisnottheoptimal solutionfornavigation-oriented activitiesifother modalities canbeused."
2.3
Pitch
andVoice Analysis
Alternative modalities, such as nonverbal vocal interface, require the tools to
analyze audiodataand computerelevant characteristics. Volume,pitch, and vowel
have been identified as vocal dimensions that may be modulated
by
a user and detectedby
a computer system. Priorworkdescribeseach oftheseveryneatly.2.3. 1
Volume Detection
The amplitudeof a periodic, orwavelike, signal maybe estimatedbased on either
its peak value or its root-mean-square (RMS) value over a given interval.
Generally,it is more robusttocompute RMSamplitude,asthistakes intoaccount
all ofthe samples rather than simply the extremes. Peak estimation, especially
with sparse samples, is error-prone and
likely
to fluctuate with noise or othervariables. It is assumed that RMS amplitude is a well-known concept, and no
researchwas doneto extendthisbasiccomputation. Infact, most audiolibraries
includeamplitude orvolume-detectionfunctionality,presumablyRMS-based, as a
23.2
Pitch
Detection
Pitch is a perceptual quantity that is generally simplified and equated with f-mdarrierital frequency-. Detectio:: of fundamental frequency, the inverse of fundaniental period, is a topic with a rich
history
in speech recognition and computer musicTwo
interesting
methods are strmmarizedby
[MJDD 03]. The first, harmonicproduct spectrum (HPSj, works withthe Fourierfrequencyspectrum of an audio signal. The FFT signal is multiplied
by
downsampledversions ofitself, andthe resultis asinglepeakindicating
thefuncLamental frequency. Thismethod is not discussedmuchelsewhere,perhapsbecauseofthelimitationslistedby
the author,induding
asensith.it;.*toshortwindowsizesduetoquantization ofthefrequencies.
The second method, or
family
of methods, discussedby
[MfDD 03], is autocorrelation, which roughly involves comparing a signal to variously time-shiftedversions ofitself The time-sriifted copyof an audio signal and thesignalitselfare compared
by
computing theirproduct as afunction of shift The timeshiftat whichthe autocorrelationfunction(ACF) isrniiximized is indicativeofthe period ofthesample, winchis inverselyrelatedtoitsfrequency. Thefundamental
periodistypicallythefirstmaximum ofthe autocorrelationfunction Themethod
is rather brute-force, and
detecting
the extremes relies on differentiation andsearching for sign changes. The author describes several shortcuts to autocorrelation Forexample, pitch is generallydetectedformultiple windows of samplesthatare temporallycorrelated, inwhich casethe entire windowneed not
besearchedfrom leftto rightbuttheperioddetectedintheprevious windowmay be used as a starting guess, and the search proceeding from there. Also, he suggestsquittingafter
finding
thefirstminimum, ormayimnm, asthatistypically indicativeofthefundamentalfrequency.Autocorrelationis ubiquitouslymentioned asthesimplestwaytodetectperiodicity
in audio signals. Manyvariations on the(ACF) arefoundinthe literature. Inan
early paper, [ROSS 74] introduces the average magnitude difference function (AMDF),whichistheabsolute value ofthe differenceoftheoriginal signal andits
time-shiftedself. Ofcourse, theAMDF generallyapproaches zerowhere theACF shows apeak. Pitchdetectionfor humanvoicesusingeitherdetectionmethodmay
be simplified through intelligent constraints. Typical values for time shift, or period, fall between3and 15ms,whichcorrespondtofrequenciesbetween70 and 300Hz. Further, the shifted signal may be shortened even further, to two pitch periodsforthelowestexpectedfrequency,forexample 100Hzfor amalespeaking
voice. These constraints, though dated and perhaps less crucial with current
speech, theypresumably are similarly useful with otherhuman utterances,verbal
or nonverbal.
Some more unusual pitch-detection algorithms are presented in [SOOD 04] and
[TERE 02]. The lattersuggests arather
interesting
twistonACF-liketimeshifting,in which three dimensions, or "state
variables," are formed from time-shifted
copies ofthe original signal. For example, dimension one is the original signal,
dimensiontwoistimedelayed 12 samples,anddimensionthreeis timedelayed24
samples. The method for elucidating fundamental period is rather unclear but
involvescomputingaEuclidean distance inthe3-Dstate variablespace.
A much better explained fundamental
frequency
detection algorithm based on avariant of AMDF is shown in [CHEV 02]. In this paper, de Cheveigne and
Kawahara describe alist of simple but effective improvements beyond basicACF
andpresent afull methodcalledYIN. First, theyaddress theproblems withACF.
A distinction is made between actual autocorrelation, which uses a fixed
rectangular window size, and "modified autocorrelation,"
or covariance, which
shrinks the window as the time shift increases. The ACF is prone to choosing a
too-high period, while the covariance function is prone to choosing the zero-lag
peak when not constrained
by
a threshold. As a baseline for their laterimprovements, the authors found a 10% error rate for pitch detection using the
ACF with a speech database.
Concluding
that the ACF is too error-prone, theymovetoa differencefunction inwhichthesum ofthe squared absolutedifference
(SSADF) is computed. This function has minima wherethe ACFhasmaxima, but
therelationship isnot simpleinversion. Thedifferencefunction islesssensitiveto
signal amplitude changes than is the ACF, providing a 1.95% error rate with the
speechdatabase,whichisquite animprovementover10%.
Several further incremental improvements are offered. First is the use of the
cumulative mean normalized difference function (CMNDF), which divides the
SSADF
by
the cumulative average ofitselfat shorterlag
values. This function isunity at zero lag, which prevents period errors at this point. A further improvement isto use parabolic interpolation when
detecting
the minima oftheCMNDF. Thisgets aroundtheintegerquantization thatshift computations allow,
providing accuracygreater thanhalfthesamplingperiod. This may allow coarser
sampling without loss of accuracy, which means less computation. A final
improvement uses a two-step estimation process, which is similar to median
smoothing the result, presumably on the time axis, using period estimates from
neighboring timevaluestohonetheperiod estimate atthepresenttime.
The YINalgorithm is presented with practicalconstraints and ranges in mind. It
requires no upperlimitforthe fundamental frequency,which maybe more useful
must be at least as
long
as the longest expected period. Further, fundamentalfrequency
estimation requires enough signal duration: two times the longest expected period. Authors used a 25 msec window with 25 msec period searchrange,
implying
40 Hz lowerfrequency
bound. A low pass filter was used to remove highfrequency
noise: convolutionwith a 1 msec squarewindow, implyingzero signal at 1 kHz. In all, this discussion of pitch detection, failure modes, and
smartimprovementsprovides anexcellentplatformfor furtherwork.
2.3.3
Vowel Detection
Voweldetectionisamorenuancedchallenge thanpitchdetection. The differences
between "ahhh"
and
"oooh"
areveryapparent inthe mouthofthe vocalist,butthe
sampled sounds may have the same pitch and the same volume. The difference
between thevowelslies in the pattern ofthe waveform. Viewed in thefrequency
domain, the relative spectral heights beyond the fundamental frequency
distinguishthem.
Anonlineresource,[CHIT 03] describesthe detectionofformants,or peaks inthe
Fourier
frequency
spectrum, and how they may be used to identify vowelsby
comparing the measuredformants to prototypical vowelformants. Formants are
caused
by
physical vibrationsin thevocaltract, anddifferentvowels showclearly differentfrequency
distributions. Formant analysis may be used for theidentification of phonemes, which are the atoms of vocal speech, and of course
vowel sounds comprise a subset of phonemes. Detected formant characteristics
are comparedtothose offiverecorded ground-truthvowels, andthrough a series
ofthresholds, assignedto one or more ofthem. Due to the number ofthresholds
involved and the ground-truth requirement ofthe sampled vowels, this seems a
rather tenuous method. However, thebasic idea of
identifying
vowels based on theirspectral characteristicsissound.Another vowel recognition method, shown in [SENA 05], again compares
measured vowel data to prototypical data, but the transformation involved is
rather unique. The authors point out that vowel sounds made
by
different speakers and at different frequencies have similar waveforms, but differentfrequency
distributions due inparttopitchdifference. Thewaveformsaresimilarbut not
linearly
related, meaning that the difference is notdescribedby
a simple timescaling. The authorsbegintheiranalysisintheFourierdomainandcomputethe spectralenvelope usinga cepstrumtransformation,whichessentiallytakes the
inverse Fouriertransformofthe
log
ofthe realpart ofthe Fourierspectrum,usingalow-pass filtertosmooththeresult. Thespectral envelopeisthenmodifiedusing
the scale transform, an evolution of the Mellin transform, which
basically
introduces scale invariance, meaning to the problem at hand that it removes
Once in the scale-invariant space, the transformed spectral envelopes are
comparedwiththose ofmodeled, prototypicalvowels,and adecisionis made asto
whichvowelbest fitsthemeasureddata. The authorsusea modeledvocal tract to
create thevowelprototypes, afactthatisn'tcrucial to the algorithm andwhichis,
say, intractablewithout some speech-synthesis infrastructure. The time involved
inthe multipleFFTtransformationsto reachthescale-invariant spectral envelope
is almost certainly too great for a real-time implementation; however, the basic
ideaofFFTspectralshapecomparisonissound.
2.4
Summary
The work described in these disparate fields comprises the basic components
necessarytocreateand evaluate a nonverbal vocalinterface. Volume detectioncan
beapproached via simple andwell-known RMScomputations. Pitchdetectionhas beenstudiedinvariousways,andthemethoddescribedin [CHEV02] showsgreat
promise for its robustness and accuracy. Vowel detection, while somewhat less
robust that pitch detection, has been shown in a few different implementations. Theconcept ofFourierspectral shapeanalysis seemsquite promising.
Thus, whilethe use of nonverbal vocalinput in a graphical user interface hasnot
beenshownbefore,the necessaryelementsfor
detecting
vocal variableshave beendevelopedseparatelyandessentiallyneedtobe pulledtogetherand adaptedto the
task. Oncethisis done,evaluation oftheusabilityand usefulness ofthenonverbal
vocalinterface maybe made
by implementing
a cursor control system andusingaO 000000000
Based on the array oftechniques that have been developed for analyzing speech
andsong signals, it isworthaskingthequestion ofhowthese may beextendedto
respondto nonverbal vocalinput and usedto provide a novel user interface. To
review, there are at least three degrees of freedom in a continuously voiced
vocalization; inorder of
increasing
detection complexity, these are volume, pitch,and vowel shape. One, two, or all of these together should be usable as independent dimensionsof user-controlledinputtoa userinterface.
Optimal mapping ofthese vocal dimensions to graphical user interface controls will depend on the specifics of a given application or environment, but many
possibilities appear
intuitively
useful. Volume has connotations of intensity,strength, size,andpressure, andthereforeshouldbemost useful tocontrol similar
aspects, such as pen size or brush pressure in a painting program. Absolute
volume is
fairly
easy forpeopleto distinguish andproduce, andmaybe adequate for controlling the interface. Alternatively, volume change, crescendo anddiminuendo, could be used for control. The derivative of amplitude can be computedtodescribethedirectionof volume change.
Pitchhasconnotations ofheight, distance, andsize,andthusshouldbewell suited
to control a vertical spatial dimension orlocation, a zoom factor, or perhaps pen
size or brush pressure. People are generally good at
detecting
or producingchanges in pitch, and they are less capable ofproducing or
identifying
absolutelevelsofpitch,soitmakes intuitivesensefortheuserinterfacetorespondtopitch
change ratherthanpitchlevel.
Vowel sound, the difference between "oooh" and
"ahhh,"
for example, does not
intuitively
correlate with spatialdimensionsor other variables. Becauseofthe waythe mouth moves to produce these sounds, opening and closing, respectively,
perhaps a zoom factor would make sense as a user interface response.
Interestingly, however,vowel soundis bothacontinuous anddiscrete variable. A
user can modulate smoothly between
"oooh" and
"ahhh,"
making a sound like
"oowahh,"
or simply vocalize one or the other, meaning that as a user input, it
couldbeusedtocontrola variable or selectfromaset. Acontinuous variablelike
zoomfactormaybe controlledusingsmoothtransitionsbetweenvowels. Discrete
choices, suchasselecting among
drawing
toolslikepen, pencil, orbrush,
couldbeto map vowel shape to a non-intuitively-matched dimensions of input, except
perhapsthat theuser will requiremore instructionto learnthecorrelation. Thus, vowelshapecanbeusedto controlthe "other"dimensioninvarious situations: for
example,whilepitch controlsverticalmotion,vowel can controlhorizontalmotion.
Feedback isanimportantfeatureofanyinterface design. Auser of a conventional
mouse would notbeverygood atselectingan absolute position withoutseeingthe
cursor on the screen andwatching it respond to the action ofthe mouse. Seeing
the response allows real-time corrections to be applied. Likewise, pitch change,
when visualized
by
cursor movement or other feedback, can be calibrated andcontrolled
by
the user in a relative sense. While this is taken for granted fortraditional devices likea mouse, evidence ofthe importanceoffeedback forvocal input is shown in [OLIV97], inwhich aural feedback is givento the user. Thus,
tyingthe inputto theeffect it produces, withoutlatency, seemsveryimportant to thesuccess ofinputmodalities.
It is hypothesizedthat a userinterface canbe made to detect one or more ofthe
user input dimensions of vocal volume, pitch, and vowel. These can then be mapped to a variety of control dimensions, singly or in combination, to either
augment aconventional
O
OOGOOOOOOO
Totest thehypothesisthatnonverbalvocalinputcanbeusedtocontrolsome or all
dimensions of a user interface, a pair of experimental user interface
implementations has been designed. Each provides insight into the validity and
robustness of aspects of the hypothesis. Experiment 1 aims to augment a two-dimensional mouse-driven input ina paintingprogram, using the mouse to paint
andusingvocal volumetocontrolthe size ofthebrush. Experiment2 is designed
toeliminatethemousealtogetherand replaceitwith vocalinputforcursor control.
Vocal pitch is mapped to vertical direction and vocal vowel is used to control
horizontal direction. Eachexperimenthas been implementedandwillbeanalyzed
indepth.
4.1
Experiment
1
4.1.1
Description
The first experiment is designed to showthat a low complexity vocal dimension
can be used in tandem with the most familiar two-dimensional input device, the
mouse. Specifically, vocal volume is mapped to brush size in the context of a
simple paintingprogram. This meansthat thebrushposition is controlledintwo
spatial dimensions using a conventional mouse while the simultaneous vocal
volume controls the size or thickness of the brush, thereby adding a third
dimensionof control.
The painting program example lends itself to nonverbal vocal control for two distinct reasons. First, the variable
being
controlled, brush size, must be variedcontinuously, ratherthandiscretely. For this reason, acontinuousvocaldegreeof
freedom is suitable. Discrete speech commands would be rather unwieldy.
Second, real-time visual response providesthe userinstantaneousvisual feedback
to guide his or her use of the vocal volume input, enabling simple and intuitive
interaction that is easily learned
by
the user. The user can quicklydevelop
acalibration ofhisorhervocalinputtothevisual results seenonthescreen.
Experiment l is meant to be a proof of concept for nonverbal vocal interface,
meaningitis designedtoshowthat theidea isrobust andthat thesystem responds
inaqualitativelycorrectfashion. Inotherwords,it isatoy
usefulforprovingtheconceptissound
-sotospeak.
Quantifying
theperformanceoraccuracyofapaintingprogramis unnecessarygiventhesatisfying
immediacy
ofvisualfeedback.
4. 1
.2Implementation
Implemented inthelanguage Processing [FRY06], theexperimenttakes the form
ofa simple
drawing
programcalled soundVolDraw2. Itbeginswith ablankwhitewindowandcontinuouslycomputesvocal volumefrom themicrophone input. To aidtheuser's understandingoftheimpactofhervocalvolume,a
dummy
brushin the upper-left corner of the window reacts to the volume input, regardless ofwhether the mouse button is pressed and the pointer-driven brush is actually
painting,toshowthebrushsize.
When themouse button ispushed, a randomcoloris selected, meaningthateach
new stroke has a different color. While the mouse is dragged, a line is drawn whose width is scaled
by
the computed volume value. Further details on the implementationmaybefoundin AppendixA;codemay befoundin Appendix B.4.2
Experiment
2
4.2. 1
Description
In thesecondexperiment, themouse isreplacedentirely
by
vocal input. Asimplegraphical userinterface was implemented with a cursor whose vertical positionis
controlled
by
vocal pitch and whose horizontal position is controlledby
vowelsound. Thevariables, pitchandvowel, maybeindependentlymodulated, allowing
formotionin any directionwhen changedintandem. Visualfeedback is
inherently
part of this experiment, as the input audio is processed real-time, and cursor motionis synchronizedto theuser'sinput.
Rather than absolute pitch and vowel, changes in either vocal variable result in
cursor movement. In an intuitive fashion, upward pitch change causes upward cursormotion, anddownwardpitch change causesdownwardmotion. Aseries of
upward-moving vocalizations (perhaps the same sound pattern repeated) will
sequentiallymovethecursorfurtherupthescreen.
Vowel
directionality
is assigned somewhat arbitrarily-"oooh"
is designated left,
and
"ahhh"
is designated right
-and again, change in vowel sound results in
cursor movement. Thus, an opening sound like
"oowah"
will movethe cursorto theright,while aclosing soundlike
"aaoooh"
with pitch, the rate of change of vowel affects the speed of the cursor motion,
allowingprecise control.
In orderto evaluate the
feasibility
ofthe cursor control in Experiment 2, a shortuser test was implemented in which test subjects move the cursor to a series of
icons onthe screen. It was hypothesized that vocalists, or singers, who are more
adept at fine vocal control and familiar with pitch modulation, would perform
betterthannonvocalists. Further,itwas assumedthatusers wouldlearnthevocal interfacerelatively quickly
-thateveniftheirfirsttrywas
fairly
dismal, itwouldn'ttakemuchpracticetoimprovetheirperformance significantly.
Experiment 2 was implemented using the language Processing. Volume, pitch,
pitch velocity, vowel, and vowel velocity are computed continuously from the
microphoneinput, andtheresults are usedtodirectthecursor onthescreen. The
user test program, called cursorTest, wraps this
functionality
with a controlschemetopresenttargeticonsonthescreen and recordhow
long
ittakeseach usertoreachthem.
4.2.2
Pitch Detection
Thepitchdetection methoddraws
heavily
on[CHEV 02]. Thealgorithm worksin the time domain andmaybe categorized as an autocorrelation method, meaningthat it compares a section ofthe audio signal to a time-shifted copy ofitself to
determine what time shift value x provides the best match. The periodicity of
voiced vocalizations, generally with a fundamental period and a variety of
harmonics, makesthispossible. Usually,the fundamentalperiodis thelongest of
the possible solutions, meaning the lowest in frequency,
implying
the shorterperiod solutions are
higher-frequency
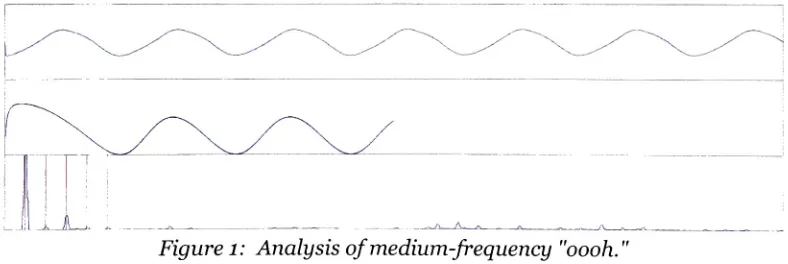
harmonics.Figure1: Analysis ofmedium-frequency "oooh."
Figure 1 shows three plots relatedto an input medium-frequency "oooh" sound.
The top plot shows the sound signal on a time axis, showing a characteristic
periodicitythat, fora simple
"oooh,"
[image:28.502.54.448.437.569.2]Thesecond plot showsthepitch detection functionon a shiftxaxis. The firstxat
whichthisfunction hasa minimumisthefundamentalperiod,whichistheinverse
of fundamental
frequency,
or pitch. Similar plots for alower-frequency
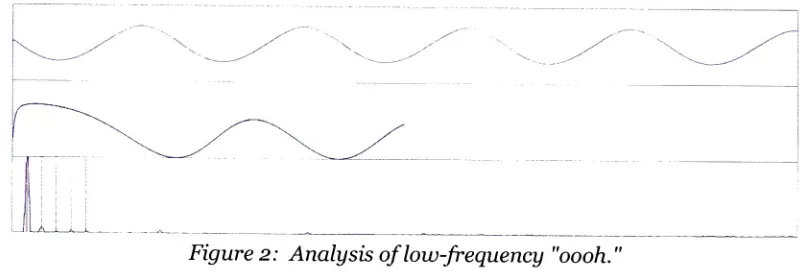
"oooh"sound are givenin Figure 2, anditisclearthat thefundamentalperiodindicatedis
longerthan thatin Figure1,showing qualitativelycorrectbehavior.
Figure2: Analysisof
low-frequency
"oooh."Fundamental
frequency,
or pitch, is computed as the inverse of fundamentalperiod, and pitch velocity is computed
by
comparing the current pitch value to previous values. The pitchvelocity isusedtomovethecursorintheydirectionby
aproportional amount. More detailonthepitchcomputations,
including
relevantformulae,maybe foundin AppendixA; codemay befoundin Appendix B.
4.2.3
Vowel Detection
Avowel detection andvowelvelocity algorithm was implemented to differentiate
clearlybetweenthe "oooh" and
"ahhh"
sounds and provide a continuous range of values betweenthose two end points. This is usedto control the cursor inthex
direction.
The vowel detection algorithm was implemented in the
frequency
domain. Asimple algorithmwasdevelopedthatdrawsthematicallyonthat in [SENA05]. It
wasobservedthatthe overallshape ofthe Fourier
frequency
spectrumisdifferentfor various vowel sounds. Specifically, the nearly pure sine wave of
"oooh"
provides a singlestrongpeakinthe
frequency
domain,whilethemore open"ahhh"
sound results in strong peaks at the fundamental pitch as well as several
harmonics. The vowel detection method analyzes the relative heights of the fundamental
frequency
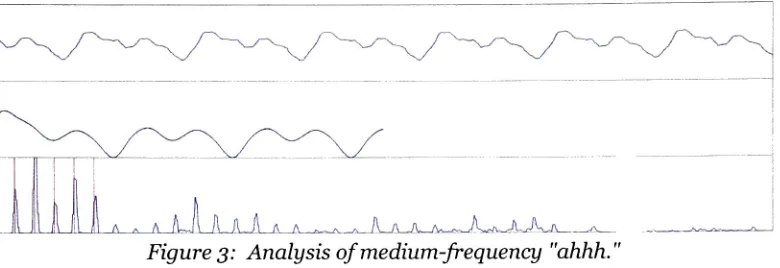
andthenextfour harmonics. Thebottomplotin Figure 3showsthe Fourier
frequency
histogram ofa vocalized"ahhh,"
overlaid with lines
[image:29.502.50.453.126.264.2]The five computed harmonic strength values, represented
by
a 5-D vector, are comparedwithprototypical vowels. Thetwovowels ofinterest inimplementation are"oooh"
and
"ahhh,"
which providevery different relative harmonic strengths, as can be seen
by
comparing the bottom plot in Figure 1 with that in Figure 3.Basedontheappearance ofplotslike these,thevowel
"oooh"
isrepresented
by
theprototypevectorp., (1, o, o, o, o), andthevowel
"ahhh"
isrepresented
by
p_, (1, 1, 1, 1, 1).Figure3: Analysis of medium-frequency
"ahhh."
The vowel detection algorithm compares relative heights ofthe harmonics ofthe measured sound withptandp2todeterminehowsimilarit istoeach. Ofcourse,it can computeintermediatevaluesbetweenthese two end pointsbasedon which is more similar.
Similarto thepitchvelocitycalculation,vowelvelocityiscomputedusingprevious
vowel values. Thevowelvelocitydetection algorithmis rather noisyascompared with pitch detection so some temporal smoothing is employed to add some robustness atthe expense of some responsiveness. As a result, left-right motion
feels slower compared to up-down motion, and the user must repetitively voice
something like "oowahh,
oowahh"
to move the cursor across the screen to the
right.
4.2.4
User Test
To evaluate the effectiveness of the implementation of Experiment 2, a user test was constructedto time how
long
ittakeseach usertomovethe cursor,using onlyhis or hervoice, to a variety of on-screen icons. [DAI 04] presents an excellent
summary of a user test constructed to evaluate a speech-based cursor control
scheme. While theircursor control method was
discarded,
the core oftheir user testwas used as abasis forthepresent usertest.The test involves a set of eight target icons drawn in a ring, and the user was
[image:30.502.59.449.156.290.2]arrangement is shown in Figure 4, which is a screen-capture from the program
cursorTest. The radius ofthe ring oficons is 200 pixels, or about 2 inches on a
typical monitor. Inthe upper-left cornerofthescreen, five plots appear, showing
computed values as a function oftime. These are volume, pitch, pitch velocity,
vowel, andvowel velocity. These are present for diagnostic reasons, notbecause the user is expected to understand them or use them for navigation. It is worth
noting that the four lower plots turn red when the volume is below threshold,
indicating
that theprogramisignoring
too-quietinputand notmovingthecursor.Volume
phi s
-iWij1-iWk1V1ooftr III 1 I
A. -vowerveloisity..
?
?
?
?
?
?
?
?
The testconsistsofmovingthecursortoeach olthe boxes. Pressspacetobegin1
Figure4: Usertestpractice screenfromcursorTest program.
The usertestprocedure is quite simple. The screen in Figure 4appears whenthe
[image:31.502.53.449.166.564.2]vowel change movesthe cursorleftandright. Vocal examples areprovided, with
the testproctor
demonstrating
soundsthatmove thecursorineach ofthe cardinaldirections and showing the results on the screen. Further, the proctor explains
that diagonals and curves are obtained when pitch and vowel changes are
combined, and some examples shown. The user is then given command ofthe
microphoneandallowedtopracticeforafewminutes, untilcomfortable.
Several more hints are provided as the training session continues. First, the important thing is change. Simply vocalizing different pitches will not result in
motion,buta smoothsweep fromalowpitchtoahighpitch will. Second,because oftemporal smoothing, a longervocalization is alwaysbetter than a shorter one.
Thismeansthatalong,slow pitch changeis betterthanashort,quickone, tomove
the cursor a short distance. Third, moving straight up and down using pitch modulation alone is relatively easy, but moving straight left and right is more
difficult due to people's tendency to change pitch while vocalizing a sound like "oowahh."
Itis helpfulto practice a constant-pitch vowel changeto move straight fromsidetoside.
Oncetheuseris satisfied withhisorherpractice, the testbegins. Theuser moves
thecursortoatarget icon, andthe timernotes whenthe usersuccessfullygetsthe
cross-hair intothebox. This continuesfor each oftheeighticons, and thetest is
O
G0O0OOO
5.1
Experiment
1
Experiment 1 was extremely successful. While no attempt was made to collect
quantitative data, qualitatively it worked perfectly. The simultaneous input of positionusing themouse andbrushsize usingthemicrophone provedsimple and
intuitive, and very little practice was required before the visual results were
satisfactoryto theuser. Beloware screen-captured examples of paintings created
usingsoundVolDraw2. Figure5shows astylizedhibiscus flower
drawing
inwhichline width was modulated to accentuate the petals. The line width variation has
some unintended fluctuations, but overall the results are representative of the
intendedeffect.
Figure5: Example
drawing
using vocal volumetocontrolbrushwidth.Figure 6 illustrates thelevel ofcontrol and repeatability that is possible to create
quickly with the program. The line weights in the text were varied to mimic a
classic seriftypeface, and whiletheend result isnosubstitutefora renderedfont,
it is
fairly
good, and much more interesting that it would be with constant line [image:33.502.125.380.313.508.2]Sam!
Figure 6: Example
drawing
usingvocal volumetocontrolbrushwidth.Several people volunteered to spend some time
fiddling
with this program, andthey all were pleased and amused with the results. As simple as the implementationis,thevolunteerswereverypleasedtoseethevisualresult oftheir
voice ina waythatwas newandentertaining. Some people were methodical and
experimental with their trial, probing the response of the new input modality.
Otherswereunabashedlysquawking and
hooting
atthe computer,laughing
attheresults,
drawing
scribbledpictures,andsimplyenjoying it likeatoy.5.2
Experiment 2
The realization of Experiment 2 met all expectations. The pitch detection
algorithmisrobust andaccurate, andthevoweldetection,while alittle lessrobust
than ideal, works amazingly well given its simplicity. The user test proved very
successful and provided qualitativeinsightas well asdataonusabilityand
learning
curve.
Twelve users took the test, in addition to the author. Of the twelve, one was
discarded because his voice wastoo raspy and nasalto provide good control over
the cursor,
leading
tofrustrationand scores an order ofmagnitudeworsethan therest. The other eleven were categorized
by
gender as well as in vocalist ornonvocalist categories. To qualify as avocalist, a user had some sort of singing
experience or training, preferably in a choral setting that requires vowel quality
and clarity. Three users were categorized as vocalists and eight as nonvocalists. Six ofthe users are female, and five are male. Two users were tested multiple
Each user was tested twice successively, as eachtest consists ofonly eight target
icons and there was some variability. Because some users"got lost" alittle bit or otherwise performed significantly worse on one of their icons, and others "got
lucky"
occasionally
by fortuitously
nailing a bullseye with an unintendedvocalization,thehighestandlowestofthe eight scoresforeachtestweredropped.
The average time for the remaining twelve target icons (six for each of the two
tests) isshownin Table l.
Table1: Averageusertimesforthefirsttwo testswith extremes excluded.
Male
Voc.
Female
Vocalist Male Nonvocalist Female Nonvocalist
User 1 2 3 4 5 6 7 8 9 10 11
Time 10.7 17.0 23.9 18.8 25.9 22.8 24.6 19.2 27.8 30.6 35.6
The average time over all eleven users on their first two tests is 23.4 seconds,
which is somewhat
disappointingly
long, but not abad start. Itshould be notedthat user 5 took the test only once due to an oversight, sohis initial testresult is reported where everyone else's first two test results are averaged. User performancedidnotvary widelybetweentheirfirstand secondtests, sothismild
inconsistency
maybe ignored. The data may be broken down inseveralways, forexample in the vocalist vs. nonvocalist and male vs. female categories mentioned
above,as showninTable2.
Table2: Usercategoryaveragesforthefirsttwo testswith extremes excluded.
Vocalist Nonvocalist
Male 10.7 23.0
Female 20.4 28.3
Here, the hypothesis that vocalists would outperform nonvocalists is verified
by
their significantly better performance. Qualitatively, this difference was clear whenthe testswereadministered; thevocalists
invariably
hadmuchmore comfort withthevocalcontrolnecessaryforthe taskand requiredlesstrainingtimebeforetheyfeltreadyto takethetest.
Additionally, in each category the male users outperformed their female
counterparts. Thiswas unanticipated andmayindicatetheexistence of somesort
ofbias built in unintentionally as the pitchand vowel detection algorithms were
implementedand optimized using themale author'svoice. Optimized is astrong
word, because there really aren't any empirical thresholds or other optimized variables
likely
tocausethis.However, a couple ofdetails may introduce accuracybiases. The quantizationof
[image:35.502.53.452.165.223.2]detection algorithm leads to coarser pitch computation for short fundamental
periods, which correspond to higher frequencies. It is perhaps possible that the
modulation of
higher-frequency
female voices is not as well discerned as that oflower-frequency
malevoices. Swaying the oppositedirection, thequantization inthe
frequency
domain in the FFT computation means that low frequencyvowelsare morecoarselycomputed. Thiscouldleadtoless discernment intheharmonic
peak-height computations for
lower-frequency
voices than for higher-frequencyvoices. Neitherofthese tendencieswere studied well enoughto saydefinitivelyif
theyaretruly
introducing
bias,butthepotentialfor differenceexists.25
\
\ -Expert
\
\
- -
-Female Nonvoc
Male Nonvoc
\
\
.^
/ "^ -^
%
/
tes!2 tesl'J test4 tests
Figure7: Usertesttimesovera seriesoftestsshowingthe
learning
curve.The users'
practice sessions and first tries at the test were successful, but
sometimes
frustratingly
slow. Fortunately,withimmediatevisualfeedback, peoplelearn quickly and the users who took the test multiple times showed rapid
improvement. Users 7 and 8, one male and one female, both nonvocalists, were
testednine consecutivetimes inordertocharacterizetheir
learning
curves. Figure7shows the resulting data,
indicating
a quickimprovement overthe first four orfivetestsandthen
leveling
off. Also shownis datafromthe author, referredto astheexpert userbecauseofhis
familiarity
withthe testand extensive practice whilewriting the algorithms. The expert baseline, representative of well-practiced
competence, averagesjustover4secondsper targeticon. Overthecourse ofnine
tests taken in a single half-hour, the male user reached a plateau around 13
[image:36.502.61.445.185.423.2]each user's
learning
curve would continueto trend towardfastertimesifgiventhe time topractice.Another
interesting
waytolookattheusertestdata is toconsiderthedependenceon direction.
Moving
in the cardinal directions, up, down, left, and right, seemsintuitively
simpler than moving in diagonal directions. The cardinals can bereached with pitch or vowel changes on their own, while the diagonals require a
composite vocalization with both pitch and vowel changes. Most users did not
attempttocombine pitch changeand vowel changeinasinglevocalization,instead
stair-stepping in the cardinal directions to reach the diagonal target icons.
However, some users mastered combined vocalizations quickly, and one of the
female vocalistswas much more comfortable with gently-curving diagonals than
with straight left and right movements. In the author's experience, J shapes
proved comfortable and convenient with a little practice. Directional data are
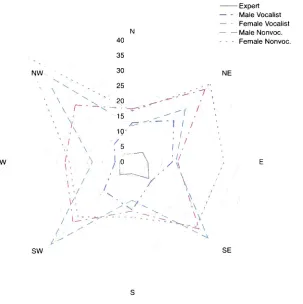
summarized in Figure 8, using compass directions in a logical map sense where
northisup.
Expert
MaleVocalist
-FemaleVocalist
N MaleNonvoc.
40 FemaleNonvoc.
35
NW , s
30
NE
, \"
<''-. 25 -
-\
\V-v"-- '\
*
VI * \
f-
?
r. /
. / .
v.
w
15
10'
^.<-"i '/ /
V
}tZ
1%.
-A:
SW SE
Figure8: User categoryaveragesforthefirsttwotest,excludingextremes,
[image:37.502.106.409.284.588.2]The general trend of diagonals taking more time to reach than the cardinals is
clear, though it is not exactly consistent across user categories. The expert user data makethebestapproximation ofacircle, meaningthat proficiencywas gained
nearly equivalently in all directions. The most inconsistentusers fall inthe male
nonvocalists category, for whom diagonals took two to three times more time to
reach than cardinals. Both vocalist categories are more even, cardinal directions
compared to
diagonals,
than the nonvocalistcategories. Complete user testdatamaybe foundin Appendix C.
User reaction to the nonverbal vocal interface implementation varied, but was
generallypositive andinsome casesquiteenthusiastic. Somewere embarrassedto
be singingand
howling
toa computerwith another personinthe room, and otherswere too
busy
entertaining themselves to notice another person's presence.Several users suggested a game implementation using vocal input for control,
whichis certainlyafeasibleidea. Manyusers envisioned with amusement an office full of cubicle-dwelling employees, all cooing in cacophony to their computers.
One user, after
demonstrating
relatively adept control ofher voice to move thecursor, pushed herchair back andsaid, "That was the weirdest thing I have ever
done."
O 0OO0O0OOOO
Thenonverbalvocalinterfaceconceptisan
interesting
confluence and extension ofprior work in signal processing, graphics, and human-computer interaction. By
combining existing ideasand algorithms with some modification andoptimization,
a novel method of user interface is created. It is shown that the concept of
nonverbalvocalinterfacemaybeutilizedintandemwith atraditionalinputdevice suchasamouseorusedtoreplacethe mouse altogether. Ordinaryusers aswell as
those physically unable to manipulate a traditional input device canbenefit from
thisfoundation.
6.1
Experiments
The success ofthe two simple experiments is quite gratifying. Experiment l, in which vocal volume controlsbrush size ina paintingprogram, shows thata vocal variable canbe simultaneouslytied to mouse-driven cursor controlvariables,and
itshowsthatthisextension of user control wasintuitiveandeasilylearnedwiththe
visual feedback provided. Additionally, and most interesting, it previews the usefulnessof suchmixed-modalityinput,both forprecise,productive controlas an artist or engineer might employ as well as for entertainment as a game or toy
interface. Applying this crude experimental interface to any of these end uses
wouldbesimple and effective.
Experiment2 proves the hypothesisthata completelyvocal interface canbe used
to supplant a mouse for two-dimensional control of a graphical environment.
Despite the simplicity and small subject pool ofthe user test, valuable data were collected showing the ease of use of the implementation of and illustrating the
rapid impro