Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
11-1-1984
Non-linear principal component analysis
(approximation by a second-order Taylor series)
John Viggiano
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
.
Recommended Citation
NON-LINEAR
PRINCIPAL
COMPONENT ANALYSIS
Approximation
by
aSecond-Order Taylor
Series
by
John
Anthony
Stephen Viggiano
A
thesis
submittedin
partialfulfillment
ofthe
requirementsfor
the
degree
ofMaster
ofScience
in
Statistics
atthe
Center
for
Quality
andApplied
Statistics
ofthe
College
ofContinuing
Education
of
the
Rochester
Institute
ofTechnology
November,
1984
Thesis Advisor:
Professor
Nicholas
Zaino
NON-LINEAR PRINCIPAL COMPONENT ANALYSIS
(APPROXIMATION BY A SECOND ORDER TAYLOR SERIES)
I, JOHN ANTHONY STEPHEN VIGGIANO, grant permission to
the Wallace Memorial Library of Rochester Institute of
Technology, to reproduce my thesis in whole or in part.
Any reproduction will not be for commercial use or
profit.
John Anthony Stephen viggiano
profit.
G^
b^
ACKNOWLEDGEMENTS
The
author receivedthe
help
of many peoplein
the
preparation ofthis
thesis.
Many
individuals
cometo mind,
andI
wouldlike
to
thank
them
for
their
assistance.In
particular:Mrs Lynn Tessar
ofthe
Ridgewood, NJ,
Library,
for
her
assistance
in
locating
the
authorities citedherein.
The
author
naturally
assumes all responsibilityfor
anyinaccuracies
and omissionsthat
there
maybe;
Dr Austin
Bonis,
late
chairman of graduate statistics atRIT,
for
his
initial
encouragement and assistance;The
authorsfamily
andfriends,
some of whomI
mighthave
depended
on alittle
too
much,
andto
some of whomI
mayhave
been
perhaps alittle
more eccentricthan
usual;
and;
Professor Nicholas
Zaino,
the
author's advisor, who wasvery
tolerant
ofthe
author'sidiosyncrasies,
and workedhard
atachieving
ahigh
level
of rapportthroughout
the
duration
ofthis
project.DEDICATION
This
thesis
is dedicated
to
the
family
andfriends
ofthe
author's,
for
EPIGRttl
Look
around,
mylittle
friend:
Jubilation
in
the
land
When
Johnny
strikesup
the
band
-Warren
Zevon
When
it
hits
you,
you'llholla
"Yes,
indeed!"ABSTRACT
Linear
Principal
Component
Analysis
(LPCA)
has been
appliedin
multi variate analysisbecause
ofi ts
many
optimality properties.However,
when appliedto
locate
singularitiesin
a set ofdata,
LPCA
is
only
ableto
locate
linear
singularities.If
the
problembeing
consideredtends
to
produce variables with
non-linearrelationships,
such as with non-linearregression,
LPCA
is
necessarily
oflimited
utilityin
identifying
singularities.
Non-linear
generalizations ofPCA have
been
suggestedin
the
literature.
Essentially,
these
involve
augmenting
the
data
withhigher-order
terms,
in
particular square and cross productterms,
andrunning
aLPCA
onthe
augmented
data
set.The
problem withthis
approachis
that
the
fundamental
property of parsimonyis
violatedbecause
the
number of principal componentsis
greaterthan
the
number of original variates.Further,
the
dimensionality
ofthe
augmenteddata
setincreases
quadrat
ical
ly
with respectto
the
number of original variates.This
greatly
increases
the
computationalload for
practical-sized problems.A
new methodis
proposedin
this
thesis.
It
involves writing the
general non-linear model as aTaylor
Series
andtruncating
afterthe
second-orderterms.
The
data
are centered abouttheir means,
andthe
square and cross-product values are computed.The
covariance matrixfor
the
augmented problem
is
computed.The
non-linear singularities(or
near singularities) are obtainedby
running
a canonical regressionusing
the
'original*and "added* sets as partitions.
The
advantagehere
is
that
no more principal componentsmay
be
extractedhere
than
there
are variatesin
the
originaldata
set,
sothe
principle ofparsimony
is
upheld.TABLE
OF CONTENTS
Chapter
One
-Introduction
...1
Purpose
1
Scope
1
History
andBackground
1
Non-Linear
Principal
Component
Analysis
2
A New Approach
5
Other
Approaches
6
Chapter Two
-A Model
for Non-Linear
Principal
Components
7
The Model
for
Linear
Principal
Components
7
A Model
for Non-Linear
Principal
Components
. .7
The Taylor
Series for
One Variable
8
The Taylor
Series for
Several
Variables
8
A
Practical
Model
for Non-Linear
Principal
Component Analysis.
8
Chapter Three
-Determination
of
the
Coefficients
10
Canonical
Regression
10
Problems
withthe
Canonical
Correlation
Approach
11
Square Terms have
high
correlation withcorresponding
1 inear
terms
11
The
number of "added" variablesbecomes
too
large
12
A
singularity
in
either partition stopsthe
process12
General
Procedure
for Non-Linear
Principal
Component Analysis.
. .14
Chapter
Four
-Experimental
Method
15
Chapter
Five
-Experimental
Results
17
Gnanadesikan/Wi Ik
Problem
17
Non-Linear
Regression
Example
19
Vectors
in
the
null space ofB
24
Chapter
Six
-Summary
26
Conclusions
andRecommendations
26
Recommendations
26
Suggestions for
Further
Investigation
27
Notes
29
LIST OF
TABLES
Table
1.
Data from
2-variate
Gnanadesikan-Wi Ik
Example
3
Table
2.
Covariance
Matrix
from Gnanadesikan-Wi Ik
Example.
...4
Table
3.
Eigenanalysis
for
Gnanadesikan-Wi Ik
Example
4
Table
4.
Dimensionality
ofthe Augmented Data Set
5
Table 5.
Orthogonal
Polynomials
12
Table
6.
Dimensionality
ofMatrices for
Old
andNew Methods
13
Table
7.
Rotation
for
Gnanadesikan/Wi Ik
Problem
16
Table
8.
Matrices
A
andB for
Gnanadesikan/Wi Ik
Problem
16
Table
9.
Non-Linear
Principal
Component Analysis
of
Gnandesikan/Wilk
Problem
18
Table
10.
Data
for
2-parameter Non-Linear
Regression
Problem
19
Table
11.
Covariance Matrix
for Non-Linear
Regression
Problem
20
Table
12.
Rotation
for Non-Linear
Regression
Problem
21
Table
13.
Matrices A
andB for Non-Linear
Regression
Problem
21
Table
14.
Non-Linear
Principal
Component Analysis
of
Non-Linear
Regression
Problem
23
Table
IS.
Least
Significant Principal
Components
andVectors
in
the Null
Space
ofB
25
LIST
OF
FIGURES
Figure
1.
First Non-Linear
Principal
Component
24
COPTER
ONE
INTRODUCTION
PURPOSE
The
purpose ofthis
thesis
willbe
to discuss
a generalization ofthe
Principal
Component
modelto
the
non-linear case.This
particular generalization
differs
from
the
one previously presentedin
the
literature
in
that
the
new method producesthe
same number<rather
than
more) ofprincipal components as
there
are variates.SCOPE
This
thesis
willdiscuss
a generalization ofLinear
Principal
Component
Analysis
(LPCA)
to
a non-linear model.For
expediency,
aTaylor
seriesexpansion will
be
used.This
thesis
willbe
limited
to
discussion
of models withtruncation
after nohigher
than
the
second-orderterms.
Methods
for
the
computation ofthe
coefficients willbe
discussed.
One
ofthese,
Canonical
Regression,
willbe
examinedin
somedetail,
inclu
ding
numerical examples.Another method,
Maximum
Likelihood,
willbe
discussed
in
less detail.
The
conclusions and recommendations ofthe
author,
as well as suggestionsfor
further
research,
willbe
presented.HISTORY
AND
BACKGROUND
In
a1901
paper entitled"On
Lines
andPlanes
ofClosest
Fit.
.CU
Karl
Pearson
spawned abranch
of statisticsthat
is
purely multivariatethat
is,
having
no univariate analog.This
paper was precursorto
workby
Hotelling, Thurstone,
etalii,
in
whathas
generally
become
known
as
Principal
Component
Analysis.
Pearson's
1901
paperdiscussed
an alternativefor
ordinaryleast
squares.Ordinary
least
squares(ala
Gauss
andLegendre)
pre-supposesthat
any
erroris
strictly containedin
the
responsevariable;
the
predictor variablebeing
error-free.With
correlationdata,
however,
withboth
predictor and response variablescoming from
a commonbi-variate
distri
bution,
this
assumptionis
violatedthere
is
nolonger
a cleardis
tinction
between
independent
anddependent
variables.Linear
Principal
Component
Analysis
(LPCA)
is
useful when several correlated
variables are underinvestigation.
Some
ofits
applications1.
Variate
Peduction
through
parsimonyof
description
2.
Transformation
to
a set of uncorrelatedvariates
(spher
ic i
zati
on)3.
Identification
oflinear
singularities(or
near singularities)4.
Orthogonal
Regression
While
the
first
pair are of general application,the
second pair areuseful only when an
underlying
relationship
between
and amongstthe
variates(i.e.,
singularity)is
linear
(or
nearly so).When
this
is
notthe
case,
LPCA
is
necessarily oflimited
value.When
anon-1
i
near singul ari
ty exists,
LPCA
willbe
unableto
locate
it.
This
problembecomes
moreimportant
asthe
number of variatesbecomes
large.
Gnanadesikan
andWilk
give an examplein
3
variates which, whilebeing
perfectly
related(on
a paraboloidin
3-space)
do
not appearto
have
anyinterrelationship
when plotted pairwise.C3]
Practically
speaking,
this
situation will arisein
Non-linear
Regression
Analysis,
wherethe
parameter estimates willhave
non-linear relationsboth
to
the
response andamong
themselves.
This
maybe
extendedto
the
partialderivatives
ofthe
modelfrom
whichthe
increments
for
the
parameter estimates aredetermined.
It
seems worthpointing
outthat
whilefor
linear
regressionthe
linear
relationships are of primaryinterest,
in
non-linear regressionthe
non-linear relationships arenec-essarilly of consequence.
NON-LINEAR
PCA-Gnanadesikan
and
Wilk
proposed an extension ofthe
LPCA
techniaue
to
include
alsothe
case of singularitiesin
the
data
containing
second-orderterms.
C41
They
included
anexample,
withthe
underlying
relationship
Y
=2
+4X
?4XX,
whichis
presentedhere
in
Tables
1-3.
Essentially,
this
methodinvolved
augmenting
the
originaldata
set withall second-order
terms
(squares
and cross-products ofthe
original vari ates) andperforming
aLPCA
onthe
augmenteddata
set.This
is
similarto
techniques
recommendedby
others(e.g.,
Roderick
McDonald,
"A
generalXX
XY
YY
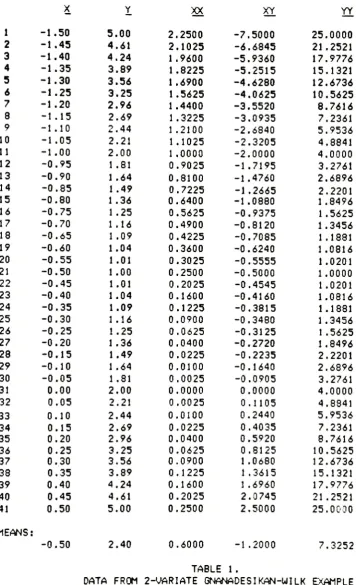
1
-1.505.00
2.2500
-7.500025.0000
2
-1.454.61
2.1025
-6.684521.2521
3
-1.404.24
1.9600
-5.936017.9776
4
-1.353.89
1.8225
-5.251515.1321
5
-1.303.56
1.6900
-4.628012.6736
6
-1.253.25
1.5625
-4.062510.5625
7
-1.202.96
1.4400
-3.55208.7616
8
-1.152.69
1.3225
-3.09357.2361
9
-1.102.44
1.2100
-2.68405.9536
10
-1.052.21
1.1025
-2.32054.8841
11
-1.002.00
1.0000
-2.00004.0000
12
-0.951.81
0.9025
-1.71953.2761
13
-0.901.64
0.8100
-1.47602.6896
14
-0.851.49
0.7225
-1.26652.2201
15
-0.801.36
0.6400
-1.08801.8496
16
-0.751.25
0.5625
-0.93751.5625
17
-0.701.16
0.4900
-0.81201.3456
18
-0.651.09
0.4225
-0.70851.1881
19
-0.601.04
0.3600
-0.62401.0816
20
-0.551.01
0.3025
-0.55551.0201
21
-0.501.00
0.2500
-0.50001.0000
22
-0.451.01
0.2025
-0.45451.0201
23
-0.401.04
0.1600
-0.41601.0816
24
-0.351.09
0.1225
-0.38151.1881
25
-0.301.16
0.0900
-0.34801.3456
26
-0.251.25
0.0625
-0.31251.5625
27
-0.201.36
0.0400
-0.27201.8496
28
-0.151.49
0.0225
-0.22352.2201
29
-0.101.64
0.0100
-0.16402.6896
30
-0.051.31
0.0025
-0.09053.2761
31
0.00
2.00
0.0000
0.0000
4.0000
32
0.05
2.21
0.0025
0.1105
4.8841
33
0.10
2.44
0.0100
0.2440
5.9536
34
0.15
2.69
0.0225
0.4035
7.2361
35
0.20
2.96
0.0400
0.5920
8.7616
36
0.25
3.25
0.0625
0.8125
10.5625
37
0.30
3.56
0.0900
1.0680
12.6736
38
0.35
3.89
0.1225
1.3615
15.1321
39
0.40
4.24
0.1600
1.6960
17.9776
40
0.45
4.61
0.2025
2.0745
21.2521
41
0.50
5.00
0.2500
2.5000
25.0000
MEAN
S:
-0.50
2.40
0.6000
-1.20007.3252
TABLE
1.
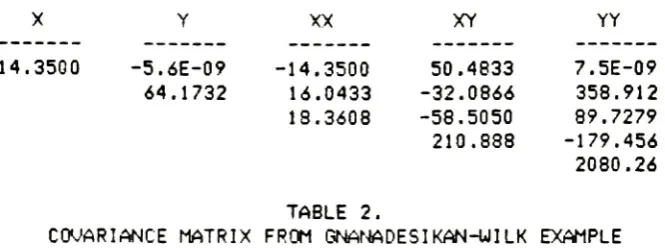
[image:12.533.58.415.71.657.2]X
Y
XX
XY
YY
14.3500
-5.6E-09 -14.350050.4833
7.5E-09
64.1732
16.0433
-32.0866358.912
[image:13.533.95.428.70.194.2]18.3608
-58.5050210.888
89.7279
-179.4562080.26
TABLE 2.
COVARIANCE
MATRIX
FROM GNANADESIKAN-WILK EX^IPLE
(Note:
Gnanadesikan
andWilk
usedthe
sum-of-squaresmatrix,
ratherthan
the
covariance matrix.The
covariance matrix maybe
obtainedby
multiplying
the
sum-of-squares matrixby
the
reciprocal ofthe
number ofdegrees
offreedom.
In
orderto
permit moredirect
comparison,
the
sum-of-squares matrix will
be
used ratherthan
the
covariance matrixin
this
thesis.)
2163.63
219.915
EIGENVALUES
2.258
2.223
0.000009
EIGENVECTORS
-0.002513
0.169321
0.
0
44843
-0.094253
0.980015
0.246077
0.011882
-0.2431060.932909
0.099425
0.508757
0.758811
0.319056
-0.212548 -0.135640 -0.4424450.604229
0.593499
0.274991
-0.1062390.696310
-0.1740760.696311
0.0000004
0.0000003
TABLE
3.
EIGENANALYSIS
FOR
GNANADESIKAN-WILK
EXAMPLE.
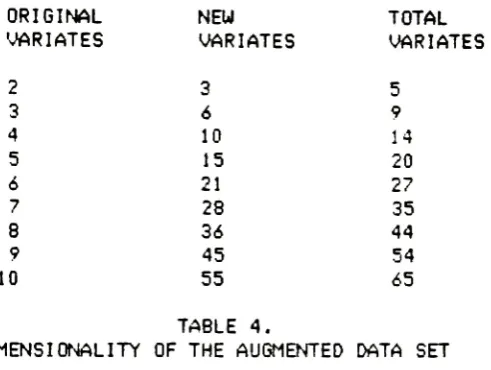
In
a p-variateproblem,
there
willbe
p(p-D/2 cross products andp
squared
terms,
augmenting
the
originaldata
setby
p(p*l)/2 variatesto
p(p+3)/2 variates.
Table
4
containsthe
number of variatesin
the
aug
mented
data
setfor
p
=2,3
10.
Note
that
the
number of variatesin
the
augmenteddata
setincreases
quadratical
ly
with respectto
the
numberof variates
in
the
originaldata
set.Immediately,
two
disadvantages
to
this
approachbecome
apparent:1)
As
the
number of"original"
variates
approaches a size
for
whichPCA
mightbe
considered,the
number of variatesin
the
augmenteddata
setincreases
withquadrat
ic
rap idi
ty-2)
The
number ofresulting
principalcomponents will always
be
larger
than
the
[image:13.533.75.431.292.465.2]The
first
ofthese
problemsis
unattractive particularlyfrom
a practicalpoint of view.
Not
only
will vast amounts of computer storagebe
necessary,
but
the
matricesinvolved
willbe
of sohigh
an orderthat
computation
willbe
sloweddown
considerably.ORIGINAL
NEW
TOTAL
VARIATES
VARIATES
VARIATES
2
3
5
3
6
94
10
14
5
15
20
6
21
27
7
28
35
8
36
44
9
45
54
[image:14.533.127.373.157.342.2]10
55
65
TABLE 4.
DIMENSIONALITY
OF
THE AUGMENTED DATA SET
A
double
penalty
is
extracted asthe
price oftaking
this
approach,
for
not onlydoes
the
effortinvolved
in
the
eigenanalysis
increase
cubically with respectto
the
total
number ofvariates,
but
the
total
number ofvariates
in
the
ei
genanalysisincreases
quadrati
cal1
y with respectto
the
original number of variates.This
yields an overall quintic effect.The
second problemis
objectionablefrom
anintuitive
point of view.The
principle of parsimony
(which
Ted Jackson
describes
as"the
name ofthe
game"
in
PCA
[61)
mandatesthat
fewer
(not
more!) principal componentsbe
used
than
the
original number of variates.The
fact
that
for
all ournumber
crunching
we obtain aless
parsimonioussolution,
ratherthan
amore parsimonious
one,
makesthis
approach unattractive.A
NEW
APPROACH-If
it
is
assumedthat
whatis
ofinterest
is
the
relationships
between
andamong
the
variates,
Canonical
Correlation
maybe
used
to
studvthese
relationships.Once
again,
the
data
matrix canbe
augmented
by
additionalterms
ofhigher
order(squares
and cross-productsfor
a second-ordermodel),
andthe
covariance matrix computed.A
canonical correlation can
be
performed onthe
augmenteddata
set,
putting
the
original variates
in
onepartition,
andthe
"added"variates
in
the
other.
The
first
canonical correlationfunction
wouldindicate
the
best
linear
relationship
between
these
two
sets of variates.This
approachhas
several advantages.First,
recallthat
there
are no more canonical correlationfunctions
asthere
are variatesin
eitherpartition.
Because
there
willbe
more variatesin
the
"added*partition
than
in
the
original,
the
number of canonical correlationfunctions
willto
the
dimensionality
property
ofLPCA
(number
of principal componentsdoes
not exceedthe
number of variates).This
is
necessaryfor
the
property
of parsimony.Secondly,
the
function
ofinterest
the
first
vectorto
be
extracted,
ratherthan
the
last,
as withthe
Gnanadesikan-Wi Ik
approach.The
advantages
to
this
include
faster
results andimproved
numerical accuracy.In
addition,
the
matrices willbe
of more manageablesize,
both
physically
(in
terms
ofdimension)
and algebraically(in
terms
of rank).For
example,
for
afive
variateproblem,
a5x5
matrix and a15x15
matrix ofrank
5
willbe
analyzed, as opposedto
a complete analysis of a20x20
for
the
Gnanadesikan/Wi Ik
approach.(A
schemefor
further
reducing
the
sizeof
the
larger
matrix,
say,
for
this
example,
to
a8x8
or9x9,
willbe
discussed.)
Five
vectors,
ratherthan
20,
will completethe
analysis.OTHER
APPROACHES-If
the
problemis
not so much
identification
ofthe
relationships
among
the
variates,
but,
rather,
transforming
the
original variatesto
a new variate spacehaving
the
optimality
properties ofLinear
Principal
Components,
another approach maybe
useful.This
involves
the
maximization of alikelihood function.
If
we stipulatethat
the
(as
yet undetermined) non-linear principal components come
from
a gaussianpopulation,
we could selectthose
coefficients
for
the
first NLPC
which maximizethe
liklihood
ofthe
first
NLPCA
having
been
drawn
from
a gaussianpopulation;
the
second set would maxi mizethe
likelihood,
subjectto
orthogonalityrestrictions,
etc.Natu
rally,
no more principal components wouldbe
taken
than
wehave
variates.However,
this
thesis
willdiscuss
primarillythe
first
approachbased
onCanonical
Correlation.
This
choice was madebecause
of software availability,
ratherthan
the
advantages anddisadvantages
inherent
to
both
CHAPTER TWO
A
MODEL
FOR NONLINEAR PRINCIPAL COMPONENTS
THE MODEL FOR LINEAR
PRINCIPAL
COMPONENTS-The
adjective "linear*
derives
from
the
modelfor
the
principal componentsin
the
classic(linear)
case:where
zi
representsthe
i-th
linear
principalcomponent,
andthe
x'srepresent
the
values ofthe
original(observed)
variatesfrom
a particular
experimental unit.This
modelis
as general as one canhope
to
getin
the
linear
case-it
is
alinear
combination of allthe
variates!The
coefficientsvij
are usually selectedto
maximizethe
variance of zfor
a vectorv*
of unit euclideanlength.
(It
canbe
demonstrated
that
this
also maximizesthe
likelihood
ofz1,
having
been
drawn
from
a gaussian
population.)Additionally,
the
restrictionthat
a vectorv^_
mustbe
orthogonal
to
allpreceeding
vectorsis
imposed.
The
simplest modelfor
linear
principal componentsis
alsothe
mostgeneral!
This
happy
fact
is
something
that
is
"bought"by
imposing
the
restriction of
linearity
onthe
model.As
aresult,
only one model needbe
consideredfor
any given number of variates.A MODEL FOR
NON-LINEAR
PRINCIPAL
COMPONENTS-Unfortunately,
there
are aninfinite
number of modelsto
considerfor
the
non-linear case.It
is
notpossible
to
empiricallybuild
a modelbased
onthe
response asis
done
in
non-linear
regression,
because
in
princpal component analysisthe
repsonse
is
notknown
untilthe
end ofthe
analysis!Therefore,
somegeneral non-linear model
is
needed.Some
species of general models one might consider arethose
ofthe
infi
nite series genre.
These
include:
1.
Fourier
Series
2.
Asymptotic
Series
3.
Exponential
Series
4.
Taylor
Series
The
first
ofthese
is
particularly suitedfor
periodicdata.
The
secondprecludes
inclusion
ofthe
origin,
and may also provide poor resolutionfar
from
the
origin.The
last
two
are of more generalapplication,
withthe
latter
having
receivedthe
most attentionin
mathematicalliterature.
The
properties ofthe Taylor
Series
are wellknown,
soit
willbe
chosenThe
Taylor
Series
for
One Variable:
The
infinite Taylor
Series for
onevariable
is:
(2)
CO
j-o
where
the
coefficientfor
eachterm
is:
(3)
a:
=<&<*
)
The
Taylor
Series
for
Several
Variables-The Taylor
Series
has
been
generalized
for
the
case of many variables.This
involves
not only allthe
partialderivatives
ofthe
function,
but
also allthe
mixed partialderivatives.
This
is
conveniently
written:lM,A'^k)^)
with
the
powers ofthe
partialdifferential
operatorsdenoting
the
order ofthe
derivative
ofthe
function,
and products of partialdifferential
operatorsdenoting
a mixture of partialdifferentiation.
Once
the
coefficientsfor
this
model areobtained,
the
principal components may
be
computed,
andthen
they
maybe
modelled asfunctions
ofthe
original variatesdesi
red.for
a closed-formnon-1
i
nearas
solution,
if
A
Practical
Model
for
NLPCA-Obviously,
a model with aninfinite
number ofterms
is
entirelyimpractical
for
usein
a practical problem.The
infinite series
is
usuallytruncated
after a number ofterms
to
providean approximation.
Obviously,
the
moreterms
truncated
from
the
series,
the
cruderthe
degree
of approximation.(This
rationaleis
usedby
people
to
justify
running
polynomial regressions with alarge
number ofterms. )
If
wetruncate
afterthe
first
term,
ding
means,
we obtainand se
t
the
^'s
to
the
correspon-(5)
1-1
'which
is
the
modelfor
linear
PCA.
are
retained,
the
modelbecomes:
If
the
:6)
f,c)-
c^i^rN
**
c^k^rN^-f^^)
j1
j=f
fe--<
which
may
be
re-written:(7)
fctt-
SK*-/)
+^(r-pOHi<*-/rVwhere
^.is
the
gradientvector,
andH*.
is
the
Hessian
matrix,
ofthe
i-th
principal component with respect
to
the
originalvariates,
evaluated atthe
poi nt7
=jju
Naturally,
the
z's maybe
written as polynomialsin
the
x's.In
the
caseof
(7),
it
shouldbe
rememberedthat
this
form
(the
sum of a vectordot
product and a quadratic
form)
is
equivalentto
a second-order polynomialin
the
x's,
containing
in
general allthe
square and cross-productterms.
Because
the
simple polynomialis
easierto
workwith,
this
thesis
willuse
the
polynomial equivalentto
(7),
withthe
understanding
that
this
polynomial
may
be
transformed
into
the
form
of(7)
by
the
simple exerciseof
completing
squares.Higher
order approximations are of course possible,but
this
thesis
willlimit
itself
to
discussion
ofthose
seriestruncated
afterthe
10
CHAPTER
THREE
DETERMINATION
OF THE COEFFICIENTS
Having
settled on a modelfor
NLPCA,
atleast
untilthe
non-linear prin cipalcomponents
canbe
observed,
it
remainsto
solvefor
the
coefficients
in
the
model.The
coefficientsfor
the
linear
modelsatisfy
anumber of criteria:
[7]
1.
Maximum
Variance
(proportion
oftrace)
for
avector of given
length
2.
Gives
components maximumlikelihood
ofhaving
been
drawn
from
a gaussian sample3.
Last
vectors representbest
linear
relationshipsbetween
variates.4.
Vectors
form
an orthogonalbasis for
originalvar
i
ates.It
is
naturally
desirable
to
incorporate
these
features
into
the
nonlinear
components,
sothe
methodfor
determining
the
coefficients shouldbe
selected withthese
propertiesin
mind.If
the
interrelationships between
the
variatesis
ofprimary
interest
(for
variablereduction,
perhaps),
then
the
method of canonical regression
may
be
used.This
providesthe
function
ofinterest
immediately,
rather
than
atthe
end ofthe
analysis.Some
specific problems withthis method,
and strategiesfor
mitigating
these
problems,
willbe
discussed.
CANONICAL
REGRESSION-When
the
best
linear
relationshipbetween
two
groups of variatesis
desired,
the
technique
of canonical regression maybe
applied.Briefly,
the
covariance matrixfor
the
union ofthe
two
variate setsis
partitioned
into
the
covariance matrixfor
the
first
group
(.7L*0.
the
covariance matrix
for
the
secondgroup
(Z,b),
andthe
matrixcontaining
the
covariancesbetween
the
a's andb's
("Sab>
^e
^es*
linear
relation-ship
is
determined from
the
dominant
eigenvectors ofthe
following
matrices:
[81
(8)
For
the
a-coeff icients:
A"
O^
^ay,
^t
^**.J
ay,
^i
-1
<9>
For
the
b-coeff
icients:
\}
-Z/
j,
Crab
2*a
2^Afe
Incidentally,
the
Doolittle
Algorithm
maybe
appliedto
advantageto
determine
the
matrices
Z^Z^u
and^b^of
These
two
matrices canthen
11
If,
withoutloss
ofgenerality,
we assumethat
the
number of variatesin
the
a-partitiondoes
not exceedthe
number of variatesin
the
fa-partition,
then
the
rank ofboth
these
matrices cannot exceedthe
dimen
sionality
ofthe
a-partition.With
regardto
our specificapplication,
the
"original*variates may go
in
the
first
<"a*)
partition,
andthe
'augmented*variates
(i.e.,
the
squares and cross-productterms)
may
gointo
the
second.From
the
startwe
know
that
the
ranks ofboth
matricesfrom
whichthe
canonical regression coefficients are computed
do
not exceedthe
dimensionality
ofthe
original variable space.
In
otherwords,
we onlyhave
as many vectorsto
extract as we
had
original variates.This
is
particularly
important
from
the
standpoint of parsimony.PROBLEMS WITH THE
CANONICAL
CORRELATION
APPROACH-However,
the
canonical correlation approachis
not withoutits
own problems.
The
author wouldlike
to
take
sometime
here
to discuss
some ofthe
anticipatedproblems,
as well as solutions which may prove usefulin
mitigating
the
effects ofthese
problems.-1 .
Square
terms
have
high
correlation withcorresponding
linear
terms.
-This
is
asampling problem,
which will arisein
situations wherethe
data
are not neatly
arranged,
with equally spaced abscissas.Because
we wouldrarely
be
interested
in
running
aPCA
onthe
factor
matrix of a neatlydesigned
factorial
experiment,
this
situation would seemto
crop
up
fairly
frequently.
(If
higher-order
terms
arecarried,
the
danger
here
is
even greater.)In
caseslike
this,
there
is
alwaysthe
possibility
of'forcing
the
data
to
confess."[9]
Such
"third-degree"tactics
will causethe
resultsto be
swamped with only
the
incredibly
obvious-for
example,
the
high
correlation
between
x and x-squaredbetween
-5 and100;
whilethe
realj;
results,
the
"meat"
of
the
investigation,
are obscuredhalfway
to
obi
i
vi
on.A
possible solutionis
to
codethe
variablesusing
orthogonal polynomials.
For
instance,
the
linear
terms
canbe
representedby
Pl(x),
the
second order
terms
by
P2(x),
etc.To
getthe
coefficients,
it
willbe
necessary
to decode
back,
into
the
original variable space.The
choice of orthogonal polynomialfor
each variable shouldbe
deter
12
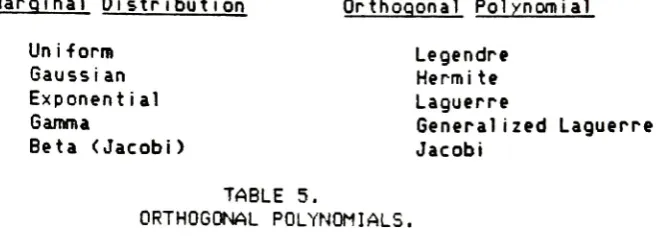
Maroinal
Distribution
Orthooonal
Polynomial
Uniform
Legendre
Gaussian
Hermite
Exponential
Laguerre
Gamma
Generalized Laguerre
Beta
(Jacobi)
Jacobi
TABLE
5.
ORTHOGONAL POLYNOMIALS.
However,
this
approach might proveto
be
morebother
than
it
is
worth.The
investigator
mustfirst
selectthe
proper set ofpolynomials,
recodethe
data,
performthe
analysis,
then
de-code
back
into
the
originalvariable space.
Nonetheless,
it
should provide ahigh
degree
oflinear
independence
between
the
powers ofthe
same variable.(Complete
orthog
onality
is
not necessary.)-2.
The
number of "added*variables
becomes
too
large.-While
the
variables are partitioned
into
two
sets(original
andadded),
andhopefully
each partitionis
of more manageable sizethan
withthe
oldapproach,
nevertheless we areleft
with alarge
number oftotal
variables,
asindicated
in
Table
4.
The
major objectionto
this
problemis
of coursethe
enormous computationalload for
aNLPCA
of a practical size.-3.
A
singularity
in
either partition stopsthe
process.-In
Equations
(8)
and(9)
we seethat
the
covariance matricesfor
both
partitions mustbe
inverted
to
obtainthe
matricesfrom
whichthe NLPCA
coefficients aredetermined.
When
machine computationis
used,
a singular covariancematrix
from
eitherthe
original or added partitions will cause"MATRIX
SINGULAR
-CAWOT
INVERT"or some similar epithet
to
be
printed out -andthe
computer runhalted.
It
is
necessary,
then,
to
eliminatethe
singularities
in
advance,
before
applying
Equations
(8)
and(9).
Preliminary
Rotation
on each Partition-To
solvethis,
together
withthe
problem
discussed
in
point2
above,
the
author recommendsrunning
a preliminarylinear
principal component analysis on each partition.This
not only allows
the
removal ofthe
singularitiesfrom
the
matricesto be
inverted,
but
also allowsthe
principal of parsimonyto
be
applied.Naturally,
a complete canonicaldecomposition
ofthe
covariance matrixfor
the
originaldata
wouldbe
performed.If
any
linear
singularitiesshould
arise,
they
would naturallybe
ofinterest.
The
remaining
principal components would
then
form
the
"original"partition
for
the
canonical regression.
The
augmented variables wouldbe
examinedfor
singularities similarly.However,
because
it
was already pointed outthat
there
arebound
to
be
near singularities
in
the
augmented partitionanyway,
these
singularities
[image:21.533.127.458.90.208.2]13
course
be
when a perfectsingularity
occured,
which wouldbe
indicated
by
a
determinant
of zero.In
orderto have
atleast
asmany
non-linear principal components asthere
were originalvariates,
it
is
necessaryto
extract atleast
asmany
vectorsfrom
the
covariance matrixfor
the
added variables asthere
are
linearly
independent
columns ofthe
covariance matrix ofthe
original variables.This
is
because
the
number offunctions
possiblefrom
a canonical regressionis
limited
by
the
size ofthe
smallest partition.If
there
werep
original variatesin
the
problem,
then,
atleast
p
vectors should
be
extractedfrom
the
covariance matrix ofthe
addedvar
iables.
Perhaps
a good rule ofthumb
for
greaterthan
2
original variates wouldsimply
be
to double
this number,
so2p
linear
principal componentsbe
extracted
from
the
covariance matrix ofthe
added variables.This
wouldproduce partitions sized no
larger
than
p
and2p
.The
largest
size ofthese
partitionsis
presentedin
Table
6,
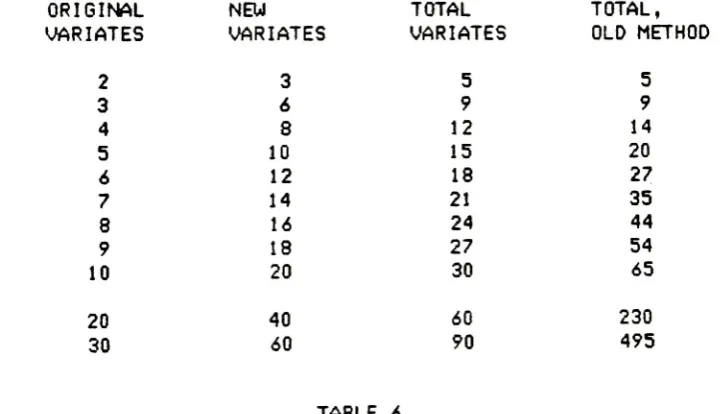
along
withthe
size ofthe
matrix
to be
reckoned with underthe
oldmethod,
for
comparison purposes.ORIGINAL
NEW
TOTAL
TOTAL,
VARIATES
VARIATES
VARIATES
OLD METHOD
2
3
5
5
3
6
9
9
4
8
12
14
5
10
15
20
6
12
18
27
7
14
21
35
8
16
24
44
9
18
27
54
10
20
30
65
20
40
60
230
30
60
90
495
TABLE
6.
COMPARISON
OF
DIMENSIONALITY
OF
MATRICES
FOR
OLD
AND NEW
METHODS.
It
is
interesting
to
notethat
the
total
size ofthe
problemincreases
linearly
with respectto
the
number of originalvariates,
whilethe
sizeof
the
problemfor
the
old methodincreases
quadratical
1y.
This
becomes
especiallyimportant
asthe
number of original variates reaches apractical size
(say,
20
or30).
Using
linear
principal component analysisin
this
way as a precursorto
the
non-linear principal component analysis would seemto
makethe
use of [image:22.533.83.445.326.533.2]14
In
computing
the
covariance matrixfor
the
transformed
variables,
it
should
be
rememberedthat
the
upperleft-hand
corner(the
covariancematrix
for
the
transformed
original variables) willbe
adiagonal
matrix,
because
ofthe
orthogonality
ofthe
linear
principal components.Further,
these
diagonal
elements aresimply
the
eigenvectors corresponding
to
the
vectors extracted.ESTIMATING
THE
MULTIPLICATIVE
CONSTttfT-Once
the
vectorsdefining
the
canonical variateshave
been
determined,
it
is
necessaryto
determine
a multiplicative constantfor
each vector.The
method used
to
estimatethe
relative contribution of each partition onthe
non-linear principal componentdepends
on whatthe
componentis
to
be
used
for.
If
we areconsidering
the
vectorsfirst
extractedfrom A
andB,
we arelooking
for
relationshipsamong
the
variables,
and orthogonal regressionshould
be
used.However,
for
the
subsequentfunctions (if
extracted),
the
first
linear
principal component shouldbe
usedinstead
to
providemaximum variance.
GENERAL
PROCEDURE
FOR NON-LINEAR
PRINCIPAL
COMPONENT
ANALYSIS-At
this point,
it
seemsthat
a general procedurefor
non-linear principalcomponent analysis can
be
presented:1.
Augment
the
original variables
with
higher
orderterms
(square
and cross-product
terms)
2.
Compute
covariance matricesfor
both
original and added variables3.
Perform
linear
principal component analysis on each partition.-Complete analysis on original variate set
-At
least
p
vectors(preferably
2p)
from
added set4.
Compute
covariance matrixfor
newtransformed
variables5.
Partition
into
original and added sets6.
Obtain
canonical correlation coefficients7.
Transform
back
into
original variate space8.
Run
Orthogonal
Regression
onfunctions
defined
by
canonicalvariates
to
determine
multiplicative constants15
CHAPTER FOUR
EXPERIMENTAL
METHOD
While
it
wouldbe
desirable
to
test
this
new approach with actualdata
from
a non-linear regression problemcontaining
alarge
number ofpredictors,
or some other practicalproblem,
time
and space constraintsmake
this
type
of experiment unreasonable.Therefore,
we shalllimit
the
experiment
here
to
two
orthree
small problems.The
first
problemto
be
analyzed viathe
new method willbe
the
Gnanadesikan/Wi Ik
problem presentedin
Chapter
1
ofthis
thesis,
in
Tables
1,
2,
and3.
This
will provide adirect
comparisonbetween
the
old and new approaches.
(In
orderto
prevent confusionbetween
the
analysis of
the
Gnanadesi kan/Wi Ik
data
by
the
new method andthe
examplealready published
by
Gnanadesikan
andWilk,.
the
analysisby
the
newmethod will
be
referredto
as a solution ofthe
'Gnanadesikan/Wi Ik
Problem",
ratherthan
the
"Gnanadesikan/Wi Ik
Example",
as was usedfor
their
solution.)The
second problemthe
author wouldlike
to
analyzej_s be
atwo
parameternon-linear regression problem.
The
two
variates which wouldform
the
basis
for
that
study wouldbe
the
partialderivatives
ofthe
model withrespect
to
the
two parameters,
evaluated atthe
least-squares
estimatesof
the
parameters.Two
partialderivatives
wouldbe
computed,
then,
for
each experimental unit
in
the
regression problem.The
regression modelwould
be
E(w)
= v[l-exp(-ut)],
whichhas
particular significancein
the
author's endeavors
in
ink
film
thickness
to
opticaldensity
conversions.The
significance ofrunning
a non-linear principal component analysis onthe
derivatives
of a non-linear regression problem can probablybest
be
illustrated
by
pointing
outthe
analogiesbetween
linear
and non-linearregression.
In
linear
regression,
the
covariance matrix ofthe
parameterestimates
is
obtainedby
multiplying
the
inverse
ofthe X'X
matrixby
the
residual mean-squares
for
residuals.In
non-linearregression,
the
covariance matrix
for
the
parameter estimatesis
approximatedby
multiplying
the
inverse
ofthe
X'X
matrixby
the
mean-sauaresfor
residuals.
The
X'X
matrixin
non-linear regressionis
computedfrom
the
derivatives
ofthe
model with respectto
the
parametersto be
estimated.Just
as alinear
principal component analysis wouldbe
run onthe
predictors
in
alinear
regression,
a non-linear principal component analysiswould
be
run onthe
derivatives
in
a non-linear regression.For
this
secondproblem,
it
shouldbe
pointed outthat
nodata
needbe
collected;
this
problem concernsitself
purely withthe
choice ofparameter values and ordinates.
The
primary goal ofthis
phase ofthe
study would
be
to
demonstrate
how
the
method ofNLPCA
by
canonical cor16
Additionally,
it
wouldbe
desirable
to
obtain somehandle
onthe
significance of
the
second and subsequentfunctions
to
be
extracted.Because
ofthe
nature ofNLPCA,
the
functions
should notbe
expectedto
reconstructthe
data.
The
plethora of second-degreeterms
would makesolving for
the
original variables given
the
principal components aformidable
task.
Also,
do
the
vectorsin
the
null space ofthe
B
matrixhave
any17
CHAPTER FIVE
EXPERIMENTAL RESULTS
GNANADESIKAN/WILK
PROBLEM-The
data
analyzedby Gnanadesikan
andWilk,
presented earlierhere
in
Table
1,
was analyzed viathe
new methodby
way of comparison.The
first
step
in
the
analysis wasthe
rotation ofthe
partitionsto
two
sets ofvariables
that
areinternally
orthogonal-so
their
covariance matrices arediagonal.
The
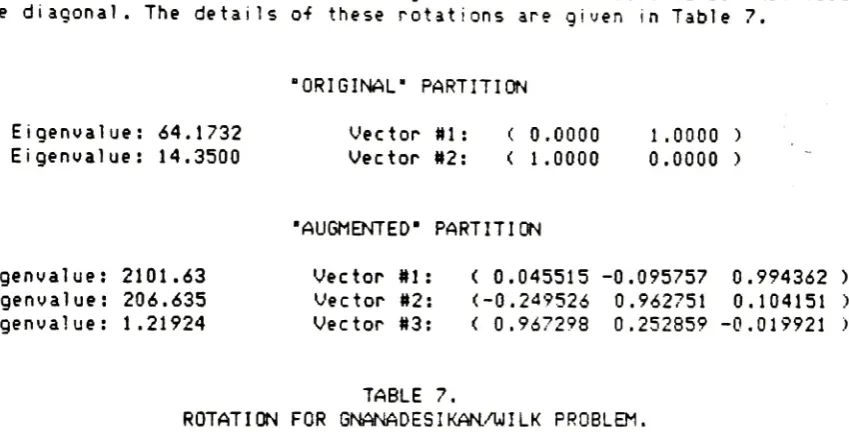
details
ofthese
rotations are givenin
Table
7.
'ORIGINAL"
PARTITION
Eigenvalue:
64.1732
Eigenvalue:
14.3500
Vector
Vector
Ml:
tt2:
0000
0000
1.0000
)
0.0000
)
AUGMENTED*PARTITION
Eigenvalue:
2101.63
Eigenvalue:
206.635
Eigenvalue:
1.21924
Vector
Ml:
(
0.045515
-0.0957570.994362
)
Vector
2:
(-0.249526
0.962751
0.104151
)
Vector
3:
(
0.967298
0.252859
-0.019921)
TABLE
7.
ROTATION FOR
GNANADESIKAN/WILK PROBLEM,
The A
andB
matrices(Equations
(8)
and(9))
werethen
computedusing
the
happy
expediency ofthe
orthogonality ofthe
rotations,
which yieldeddiagonal
covariance matrices and , which were easyto
invert.
See
Table
8
for
the
matricesA
andB.
A
rttTRIX[
0.965934
0.038164
-0.00850.9904S5
341
35J
B MATRIX
0.965633
-0.0289521.527215
-0.0028470.918823
-3.3191630
.000886 -0 .0195850
.071963TABLE
8.
[image:26.533.42.467.188.404.2] [image:26.533.114.378.497.670.2]18
These
two
matrices werethen
canonically
decomposed
to
yieldthe
canonical variate
pairs,
which werethen
transformed back
into
the
unrotatedvariables
by
multiplying
the
vectorsby
the
transpose
ofthe
rotationmatrices.
A
small orthogonal regression was run onthe
first
canonicalvariate pair
to
obtainthe
multiplicative constants.The
second non-linear principal component was extractedfrom
the
trans
pose of
the
matricesA
andB.
Recall
that
the
linear
principal componentsare orthogonal
to
each other.The
situation analogousto
this
in
the
nonlinear
case wouldbe
the
orthogonality
ofthe
gradient vectors(see
Equation
(7)).
Unfortunately,
the
eigenvectors of matricesA
andB,
whilelinearly
independent,
will notbe
orthogonal,
because
A
andB
are notreal symmetric.
The
second non-linear principal component shouldbe
chosen so
that
the
second set of vectorsbe
orthogonalto
the
first
set.Fortunately,
the
"left
hand"eigenvectors of a matrix
(the
eigenvectors ofthe
transpose)
have
a property called"bi-orthogonal i
ty"with
the
regular
("right
hand")
eigenvectors,
which meansthat
the
i-th
left
hand
eigenvector of a matrix will
be
orthogonalto
allthe
right-hand eigenvectors except
the
i-th.
10]
This
wouldtend
to
indicate
that
the
second non-linear principal component would comefrom
the
transpose
ofthe
matr
ices
A
andB.
Further,
the
multiplicative constants shouldbe
estimatedby
alinear
principal component analysis ofthe
2
canonical variates obtainedfrom
the
second eigenvectors ofthe
transpose
ofthe
matricesA
andB.
The
two
non-linear principal
components,
together
withthe
vectorin
the
nullspace of
B,
arein
Table
9.
It
shouldbe
notedthat
the
vectors presentedin
Table
9
have
alreadybeen
transformed back
into
the
"untransf
ormed*variable space of
X
andY,
and
XX,
XY,
andYY,
ratherthan
in
the
rotated variables obtainedby
the
linear
Drincipal component analysis on each partition.It
wasfelt
that
if
the
vectors originallyextracted,
in
the
"transformed"
variable
space,
were
to be
reportedalso,
this
would unnecessarily clutterthe
table.
An
eigenvalue of1.000036
is
reportedfor
the
firs* non-linear princioalcomponent.
This
wouldtend
to
indicate
rounding
error,
for
the
maximumpossible
is
one,
which correspondsto
a unit squared canonical correlation
coefficient.However,
a singularityis
postulatedby
the
very1
owvariance of
the
first
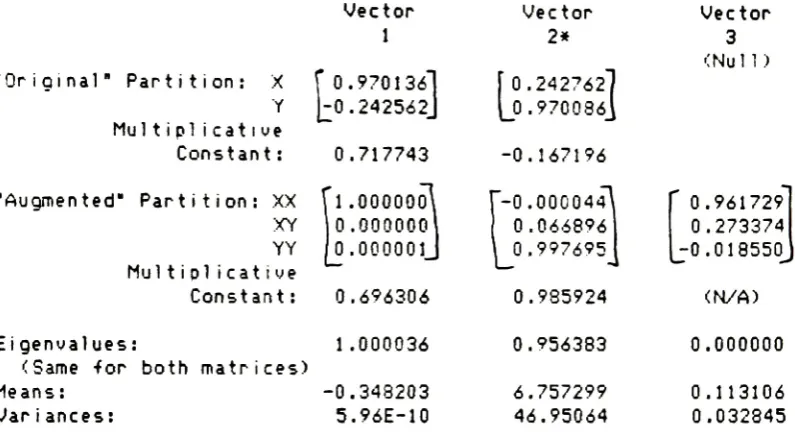
non-linear principal component.Note
that
the
function
obtained via canonical regressionis
very closeto
the
true
model4X
-Y
+4XX
+2=0.The
extremely small valuefor
the
variance of
this
function
tends
to
indicate
an almost exactfit.
As
was pointed outbefore,
the
second non-linear principal comoonent is of ratherlimited
utility,
because
non-linear principal componentsare,
by
their
nature,
notin
general reconstructive ofthe
originaldata.
However,
the
second non-linear principal componenthas
been
presented19
Finally,
the
third
vector ofthe
B
matrixis
presented.Because
the
rank ofB
is
two,
the
third
eigenvalueis
necessarily
zero,
sothe
third
eigenvector comesfrom
the
null space ofB.
Note
that
a near singularityexists
here
also,
asindicated
by
the
relatively
small variance ofthis
function,
comparedto
the
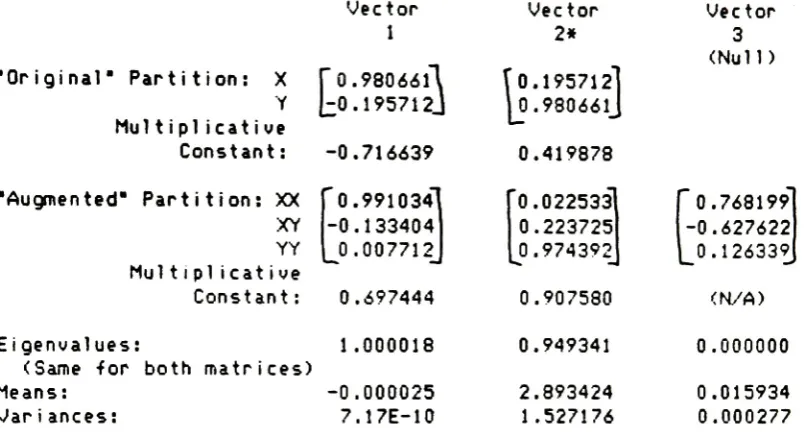
original variances.Vector
1
Original"
Partition:
X
fo.
9701361
Y
[^0.242562]
Multiplicative
Constant
: Augmented"Partition:
XX
XY
YY
Mul t i
piicat
i
veConstant
:0.717743
l.ooooool
0.000000
0.000001J
0.696306
1.000036
Eigenvalues:
(Same
for
both
matrices)Means:
-0.348203Variances:
5.96E-10
Vector
2*
'0.242762]
L0.970086J
Vector
3
(Null)
-0.167196 -0.000044\0.066896
0.997695J
'0.961729
0.273374
j-0.018550.
0.985924
(N/A)
0.956383
0.000000
6.757299
46.95064
0.113106
0.032845
*2nd
vectors arefrom
the
transposes
ofA
andB
to
provide orthogonality.FIRST
NON-LINEAR
PRINCIPAL
COMPONENT
Function:
0.696308
X
-0.174097
Y
?0.696306
XX
+0.348203
=0
Variance:
5.96
E-10
SECOND
NON-LINEAR
PRINCIPAL
COMPONENT
0.000043
XX
+0.065954 XY
Function:
Z
= -0.040589X
-0.162194
Y
?
0.983651
YY
-6.757299
Variance:
46.95064
TABLE
9.
NON-LINEAR
PRINCIPAL
COMPONENT
ANALYSIS
OF
GNANADESIKAN/WILKPROBLEM.
NON-LINEAR
REGRESSION
EXAMPLE-The
derivatives
in
non-linear regression problems constitute an examole [image:28.533.50.448.166.382.2]20
most
from
the
technique
presentedhere,
so a problem ofthis
genre willbe
addressedby
the
newtechnique.
The
model(10)
E(w)
= v[l-exp(-ut)]
is
particularlyimportant
in
ink-film
thickness
to
opticaldensity
conversions as
the Tol
lenaar-Ernst model,
in
electricity(RL
andRC
time
curves),
physiology(spirometer
curves),
andin
many other physicalprocesses.
It
is
atwo-parameter
model,
withthe
first
parameter vthe
"saturation
value"
for
the
response,
w.The
secondparameter,
u,
indicates
the
rateat which
the
saturation valueis
reached asthe
independent
variable,
t,
is
increased.
XX
XY
YY
0.0
0.000000
0.000000
0.000000
0.000000
0.000000
0.5
0.095163
0.452419
0.009056
0.043053
0.204683
1.0
0.181269
0.818731
0.032859
0.148411
0.670320
1.5
0.259182
1
.1112270.067175
0.288010
1.234826
2.0
0.329680
1.340640
0.108689
0.441982
1.797316
2.5
0.393469
1
.5163270.154818
0.596628
2.299247
3.0
0.451188
1
.6464350.203571
0.742852
2.710748
3.5
0.503415
1.738049
0.253426
0.874959
3.020813
4.0
0.550671
1
.7973160.303239
0.989730
3.230344
4.5
0.593430
1.829563
0.352160
1.085718
3.347302
5.0
0.632121
1
.8393970.399576
1.162721
3.383382
5.5
0.667129
1.830791
0.445061
1.221374
3.351796
6.0
0.698806
1.807165
0.488330
1.262858
3.265846
6.5
0.727463
1.7714570.529210
1.288678
3.138059
7.0
0.753403
1.7261790.567616
1.300508
2.979693
7.5
0.776870
1
.6734760.603527
1.300073
2.800523
8.0
0.798103
1.615172
0.636969
1.289075
2.608781
8.5
0.817316
1.552810
0.668006
1.269137
2.411219
9.0
0.834701
1.487690
0.696726
1.241776
2.213222
9.5
0.850431
1.420902
0.723234
1.208380
2.018962
MEi^S
0.545691
1.448787
0.362162
0.887796
2.334354
TABLE
10.
[image:29.533.80.459.278.633.2]21
As
mentioned,
the
two
variatesto form
the
basis for
the NLPCA
willbe
the
two
partialderivatives
of(10)
with respectto
the
two parameters,
vand u.
These
are:(11)
(12)
dv
The
values oft
for
whichthese
derivatives
willbe
evaluated were chosenas
0
CO.
53
9.5,
withthe
values of v =1
and u =0.2.
These
ordinates andparameter values were chosen so
that
the
maximum value oft
wouldrepresent
just
less
than
2
RL
orRC
time
constants,
or,
alternatively,
anink
film
producing 85*/
relative opticaldensity.
These
data
appearin
Table
10.
1.287678
1.944126
4.707390
XX
1.186987
1.446948
1.163019
XY
2.251627
3.720265
2.027608
4.125533
YY
3.968110
9.683242
2.980871
7.992721
21.17249
TABLE
11.
COVARIANCE
MATRIX
FOR
NON-LINEAR
REGRESSION PROBLEM.
The
covariancematrix,
asbefore,
multipliedby
the
number ofdegrees
offreedom,
is
in
Table
11.
Table
12
containsthe
matricesfor
transforming
each partitioninto
its
linear
principalcomponents,
andthe
canonicalregression matrices
A
andB
arein Table
13.
"ORIGINAL"
PARTITION
Eigenvalue:
5.586594
Eigenvalue:
0.408474
Vector
#1:
(
0.412058
0.911157
)
Vector
#2:
(
0.911157
-0.412053)
Eigenvalue:
24.85652
Eigenvalue:
1.599312
Eigenvalue:
0.005129
AUGMENTED"PARTITION
Vector
#1:
Vector
*2:
Vector
#3: