International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
Abstract: Proceedings with advances in semiconductor innovation, combined with an expanding worry for vitality effectiveness, have prompted an industry-wide move in center towards particular structures that influence parallelism so as to meet execution objectives. Network on-Chip (NoCs) are generally viewed as a promising methodology for tending to the correspondence issues related to chip multi-processors for future applications, even with further increments in incorporation thickness. In the present work, is research the usage perspectives and configuration exchange offs with regards to switches for NoC solicitations. Specifically, our emphasis is on creating effective control rationale for superior switch usage. Utilizing parameterized RTL usage, the main assess delegate Virtual Channel (VC) and switch allocator designs as far as coordinating quality, postponement, zone and power. The proposed work is additionally researched the affectability of these properties to key system parameters, just as the effect of distribution on by and large system execution. In light of the consequences of this examination, the propose microarchitectural changes that improve postponement, region and vitality effectiveness: Sparse VC designation diminishes the multifaceted nature of VC allocators by abusing confinements on advances between bundle classes. Two improved plans for theoretical switch assignment improve deferral and cost while keeping up the basic inactivity upgrades at low to medium burden; this is accomplished by bringing about a negligible misfortune in throughput close to the immersion point. It additionally explore a commonsense execution of joined VC and switch distribution and its effect on system cost and execution. The second piece of the proposed work centers on switch input cradle the executives. Investigate the plan exchange offs engaged with picking a cushion association, and we assess reasonable static and dynamic cradle the executives plans and their effect on system execution and cost. These works moreover demonstrate that cushion sharing can prompt extreme execution corruption within the sight of clog. An epic plan that improves the use of powerfully overseen switch input cushions by shifting the firmness of the stream control criticism circle dependent on downstream clog. By hindering inefficient cushion inhabitance, this mitigates undesired obstruction impacts between remaining tasks at hand with varying execution attributes. Finally the 4x4 NoC design is shown the better results in terms of Area, delay, speed, latency and throughput as compared to counterpart work.
Keywords : NoC, Topology, Switching, Routing, Round Robin and FPGA.
I. INTRODUCTION
Proceeding with advances in semiconductor process innovation are furnishing chip originators with regularly expanding transistor spending plans. Customarily, each new
Revised Manuscript Received on August 02, 2019.
Amaresh. C, Research Scholar, R.V. College of Engineering, Bangalore, India
Dr.Anand Jatti, Associate Professor, R.V. College of Engineering, Bangalore, India
procedure age has brought about quicker, littler and progressively effective transistors; accordingly, architects have generally centered around improving single-strung execution by methods for higher clock speeds and the utilization of more extensive and progressively advanced microarchitectures which can improve the execution of the guidance in term of rates to isolate extending proportions of parallelism direction stream from a back to back. Regardless, with the completion of Dennard scaling [22], in additional to clock repeat augmentations are constrained by down beyond what many would consider possible on power dispersal; meanwhile, timing overhead and the execution repercussions of pipeline flushes concentrate more additions in pipeline significance unlikely. At last, superscalar execution procedures have achieved a point of consistent losses as regular guidance streams just offer a constrained measure of parallelism that can be separated at sensible expense. In the meantime, there is significant interest for proceeded with enhancements in handling power. In mix with an expanding worry for vitality effectiveness driven by the ascent of cell phones, this has prompted an industrywide move in spotlight towards structures that depend on express parallelism to accomplish their execution and proficiency objectives [2, 13, 9].In such parallel plans, framework execution is characterized by the total execution over various preparing components, and procedure scaling is misused by expanding the number—as opposed to the multifaceted nature—of such components. Consequently, as scaling proceeds, it winds up important to separate a given issue into an inexorably bigger number of sub-issues so as to acknowledge proceeded with execution enhancements; for a fixed issue estimate, this by and large suggests an expansion in the measure of correspondence between handling components, every one of which is in charge of a relatively littler cut of the general issue. With future structures expected to incorporate several handling centers on a solitary chip, on-chip correspondence is hence expected to significantly affect chip-level execution and vitality proficiency [30, 29, 20]. Systems on-Chip (NoCs) are generally viewed as a promising methodology for tending to the correspondence requests of substantial scale Chip Multi-Processors (CMPs) [9,19,32]. Such parcel exchanged on-chip interconnects are typified by a lot of switches that are associated with one another and to the system endpoints by point-to-point connections, and they are described by three essential plan parameters:
Topology: The framework topology deals with the amount of switches and channels and the accessibility among them. In choosing framework remove crosswise over and partition transmission limit, it develops basic points of confinement for all around framework execution and essentialness efficiency [4,31].
Efficient Design and Fpga Implementation of
Microarchitecture for Network-On-Chip Routers
Stream control: The stream control contrive directs how switches talk with each other; explicitly, it chooses when groups—or, in various sensible executions, fixed-gauge bits of packages called vacillates—can be sent beginning with one switch then onto the following. Along these lines, stream control oversees resource use and appropriately fundamentally influences execution. Furthermore, the support space necessities constrained by a given stream control scheme truly impact the use cost and power usage of each switch. The all NoC’s structures are uses the concepts of Virtual Channel stream for controlling purpose [17, 18]; regardless, progressing work has explored elective stream control plots with a true objective to diminish pad overhead [2-7, 11]. The parameters such as cost, efficiency, characteristics defined from specifications of NoC are depending on the usage of its essential fragments. In individual, switches, its framework routing channels are set to the inertness, also essentialness cost realized for each bounce that a pack takes on its way through the framework. Apart from framework, the microarchitecture of the switches supervises the strong use of the controlling count and stream control plot, chooses the direct inside seeing stop up, and limits the most outrageous working repeat; along these lines, it truly ffects as a rule framework throughput. Finally, the authentic use cost of the framework is evidently described by the cost of its portions. As the amount of focuses continues scaling up, the impact of the framework will end up being much progressively explained. For example, continuous work has found that the principal 16×16 Mesh speaks to 45% of the total imperativeness depleted in playing out a 106-segment radix sort on a save clear 256-center point CMP [12-16].
II. ROUTER MICROARCHITECTURE
Creating proficient channels is generally a circuit plan issue [14,20,25-27]; interestingly, a switch's execution, cost and effectiveness essentially rely upon its microarchitecture. The present thesis researches usage viewpoints and microarchitectural configuration exchange offs for proficient superior NoC switches. Contrasted with switches in customary whole deal and framework interconnection systems,
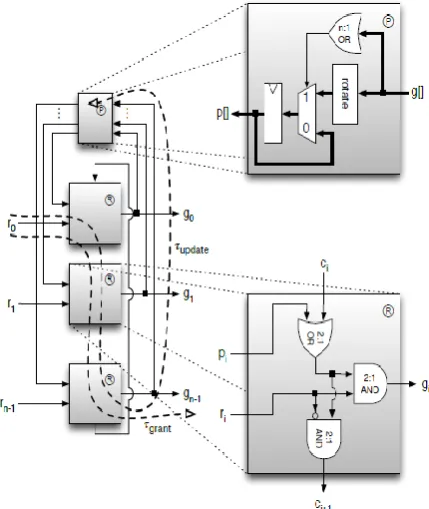
Fig.1. Overview of Single Router Microarchitecture
NoC switches are liable to especially unique plan requirements: As current semiconductor forms give an inexhaustible applied to on-chip for routing possessions, these are ordinarily no compelling reason to utilize the refined an encoding plans to channels. In the meantime, execution in chip multiple processor is normally significantly further delicate for arrangement of inactivity, ordering both the utilization of superficial switch pipelines and forceful process duration targets. At last, NoCs are commonly subject to inflexible zone for consumption of the power imperatives to maintain a strategic distance from impedance with the necessities of the system endpoints. Info lined switches have risen as the engineering of decision in momentum NoC inquire about; in such structures, parcels that can't be sent promptly are briefly detained in FIFO cradles at the switches' information ports until for data transfer and it can continue to the following routers. The framework switch is assigned at the data packet of fixed-measure flutters, at least one of which include a bundle, and is legitimately isolated into numerous VCs so as to keep away from stop and to decrease Head-of-Line (HoL) blocking [21, 23-24] appeared in Fig. 1. demonstrates an outline of a run of the mill NoC switch.
III. PROPOSED CONTRIBUTION FOR DESIGN OF 4*4 NOC
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
[image:3.595.59.274.477.732.2]Whereas assignment wasteful aspects lead to marginally diminished throughput close immersion, the expense and postpone advantages of keeping away from a committed VC allocator render joined designation an alluring structure decision for some system designs. Fixed-need referees require that there be a reasonable, pre-set up need request among solicitations. Nonetheless, with regards to switches, we oftentimes experience circumstances where undifferentiated operators vie for access to a common asset. In such cases, we are commonly keen on keeping up a level of reasonableness among the specialists: at any rate, we need to guarantee that each solicitation is conceded in the long run (feeble decency); in a perfect world, however, awards ought to be disseminated impartially among operators (solid reasonableness). The round-robin mediator appeared in Fig.2 expands the fixed-need conspire from survey by including a need select info pi to each piece cell R and folding over the last piece cell's need yield cn to the first's need input c0. The need select sources of info are compelled by a register that contains data packets, pivoted by one piece position1. Subsequently, every time an allow is created, the following specialist in line after the one being conceded turns into the most elevated need demand in the following cycle; this plan gives solid reasonableness. Framework referees speak to another execution elective for giving solid reasonableness. This is accomplished by expressly following pairwise priority between all solicitation sources of info and refreshing it because of stipends such that executes a least-as of late served strategy. In particular, for each pair of information sources I and j, the priority pointer pi,j decides if a incomplete solicitation from information I is higher need than a undecided solicitation from info j. The priority pointers are put away in a network of registers that loans this kind of mediator its name4. Whenever an information k is without a doubt, it expect most reduced need by setting pi,k and resetting pk,j for all I and j.
Fig. 2. Linear implementation of a round-robin arbiter
IV. VIRTUAL CHANNEL ALLOCATION
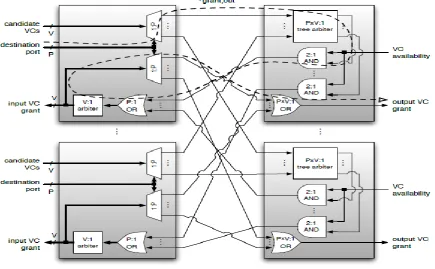
The control signals are asserted on the VC’s discussed in [17], the packets transfer along head are start to transferring from the one router to other along the data secure algorithms and it provides a complete security to all VC’s present in the design. The allocation of the VC creates a coordinating among all routers to the information VCs from one perspective, if those VC’s are used for data transfer to other switch, then packet is sends again to destination router. In the normal case, each switch has ports (P) and VC’s has port (V) and apart from these ports, NoC requires VC allocator to coordinate the combinations of PxV operations and to assets the PxV. In any case, practically speaking, the scope of yield VCs that any given parcel can demand is commonly subject to extra imperatives. Specifically, numerous generally utilized directing capacities in Networks-on-Chip (NoCs) return just a solitary yield for some random bundle, restricting the arrangement of applicant yield VCs to those at its chose goal port. We will accept that the steering capacity is limited along these lines all through the rest of this section; explicitly, we expect that the arrangement of passable yield VCs to packet given is transfer to by two signs produced by the directing rationale: One that that chooses its goal port and second one that conveys a bit route of hopeful VCs at the chose port. This rouses a few changes contrasted with an accepted P×V - by-P×V allocator execution. In light of effective designation, each conceded yield VCs is set apart as being used, and its route is refreshed to imitate which information and VC to it as of now doled out to. In the meantime, each triumphant information VCs refreshes its state to demonstrate that VC portion has been finished to stores the doled out yield VC in a register.
A. Design and Implementation of VC’s
A given yield VC can be set apart as inaccessible on the off chance that it gets demands from any information VCs, as one of these solicitations will result in a given in [1]. The consequences of yield side mediation are then disseminated again to sources of info VCs. Since a specified information VC just subjects solicitations to solitary yield port, it is sheltered to consolidate the approaching stipend data from all directions of router utilizing a P port as input OR gate; the result is a bit vector that shows the allowed yield VC—assuming any—at the chose goal port. The yield first use variety is depicted in Fig. 4. Here, every data VC sends requesting to all cheerful yield VCs at the picked objective port, where intercession is executed as in the data first case. Since decision among yield VCs isn't performed until after yield side affirmation, we can speak to VCs that are difficult to reach just by covering their yield specialists' permit signals. At the data side, we can join the honors from the assorted yield ports using a P-input OR as in the data first case. In any case, as a given data VC may get stipends from different yield VCs at its objective port, an additional intercession sort out is relied upon to pick a champ among them. Since yield VCs that were distributed must be separate as blocked off, the last data side permit signals must be multiplied back to the yield side; thusly, while yield first bit reduces the delay for creating the data side give signals, it assembles the deferral give, out for enrolling the give signals for individual yield VCs. A wave front-based VC allocator, as appeared in Fig. 4, involves an acknowledged P×V - input wave front allocator, with additional method of reasoning for making the P×V – wide requesting vector for every data VC as in the particular yield first case, and for diminishing the P×V - wide surrender vectors to V - wide vectors as in the data first case. Availability disguising can be performed at the commitments to the wave front allocator, while yield side endowments are made by joining the permit signals for all P×V input VCs for each individual yield VC. As in the yield first case, the last arranging bend addresses the allocator's all things considered essential way; its delay grant, out is overpowered by the real wave front allocator. In looking at coordinating quality between the three allocator executions, we find that distinctions principally show at burden levels that can't be supported persistently. Therefore, arrange level unfaltering state execution in to a great extent obtuse toward the decision of VC allocator; we have affirmed this utilizing broad reenactment keeps running on a commendable 64-hub Mesh organize. Accordingly, while choosing a VC allocator usage, the ideal decision is essentially controlled by deferral and cost contemplations. So as to improve the last qualities, we have besides created scanty VC allotment, a plan that diminishes the intricacy of the VC allocator by exploiting the way that numerous regular use cases arrange VCs as various disjoint parcel classes. By organizing the allocator to unequivocally uphold limitations on changes between bundle classes in equipment, meager VC portion lessens its base process duration by up to 26% contrasted with a na¨ıve execution, while improving territory and vitality effectiveness by up to 45 %. Generally speaking, our outcomes recommend that the distinct info first usage gives the ideal deferral, zone and vitality productivity among the three structures considered in the present work.
V. ALLOCATION OF SWITCH FOR PACKETS
TRANSMISSION
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
Or maybe, every data port sets up its crossbar affiliation using the triumphant VC's port select banner close to the completion of task. The last port select signs, united with the triumphant VC from every data port, other than trigger yield side recognize incorporate revives as in the data first case; the
[image:5.595.60.502.128.400.2]related arranging twist with deferral grant,out addresses the yield first allocator's fundamental way.
[image:5.595.75.511.444.713.2]Fig. 4: Separable input-first VC allocator
Fig.5. Switch allocation for Separable input-first
Fig.6. Separable output-first switch allocator
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
VI. RESULTS AND DISCUSSION
The control unit having reset and determination control signs to control by and large structure, the reset is to reset every inner register and choice is to choose the course of information exchange, there are four headings and one virtual channel, the bearing resemble north, south, west and east. In view of the determination flag the information will exchange from source to goal as appeared in Fig.7. At the point when all bearing lines are occupied for information transmission, at that point the proposed switch consequently changes over to virtual channel for successful correspondence. This virtual channel idea is an expensive and complex circuit, however it very well may be utilized for crisis information transmission. Each switch has its one virtual channel and dependent on solicitation direction on determination line, the virtual channel will get empower and associate with goal.
At last FSM controller has been intended for finding the most brief way from the source to goal and afterward exchanges the information. For 3x3 NoC switch, greatest probabilities are three headings, for example, evenly, vertically and corner to corner. This FSM control the all headings based most brief way and request of virtual channel, "req_in" is control flag utilized for determination of goal and it is outlined in the Fig.8. The 8-bit of information parcel is put away in the FIFO and its yield is associated with FSM to discover the who is the goal is appeared in Fig.4. There are four empower signs of six bearings with the name of "en_e", "en_w", "en_s", "en_n" , "en_r" and "en_l", where l and r speaks to left and appropriate for controlling of information move in the all headings.
Fig.8. RTL diagram of FSM and FIFO
The
Fig.9
demonstrates
the
reenactment
aftereffects of a proposed single NoC switch, it
comprises of four bearings alongside left and right
headings and the solicitation order to choose
required course. The solicitation would be as 2n,
where n is a number piece. The accompanying
directions
are
utilized
for
solicitation
determination:
In the event that n=1, at that point 2n is 2 and it is
for left heading
In the event that n=2, at that point 2n is 4 and it is
for right heading
In the event that n=3, at that point 2n is 8 and it is
for west heading
In the event that n=4, at that point 2n is 10 and it is
for east heading
In the event that n=5, at that point 2n is 20 and it is
for south heading
In the event that n=6, at that point 2n is 40 and it is
for north heading
Fig.9. NoC Simulation results and timing results
VII. CONCLUSION
With the finish of Dennard scaling, consistent losses from customary ways to deal with expanding single-strung execution, and the ascent of vitality proficiency as an essential plan concern, proceeding with increments in handling force will depend on the improvement of productive extensive scale Chip Multi-Processors (CMPs). Systems on-Chip (NoCs) has developed as a promising methodology for fulfilling the correspondence necessities of such structures. The idleness and throughput qualities of the system directly affect the CMP's execution; in like manner, the expense of correspondence legitimately influences its vitality proficiency. While abnormal state plan parameter—topology, steering and stream control—set the system for the system's general execution and cost, an effective system must be made out of productive channel and switch usage. In the present paper, we have researched execution perspectives and microarchitectural configuration exchange offs for proficient elite NoC routers. we have first talked about commonsense usage viewpoints for rudimentary mediators and allocators, individually, and led a point by point assessment of standard-cell structures in a business 45nm procedure. To this end, we have examined a few methodologies for structure wavefront allocators that are free from combinational circles. Contrasting postponement, territory and vitality proficiency, found that framework judges, which have much of the time been refered to as the ideal structure decision with regards to interconnection systems, are at the same time less effective and slower than round-robin mediators at common sizes experienced in NoC switches. Moreover, we have demonstrated that our combination VC’s and allocator plans yield lower deferral and cost than a recently proposed circle free execution. In light of the rudimentary allocator plans, we have explored commonsense Virtual Channel (VC) allocator executions in previously. Since the viable burden on the VC allocator is low by and by, we have discovered that distinctions in coordinating quality between various usage variations don't convert into noteworthy contrasts in system
level execution; thusly, the ideal decision of VC allocator is fundamentally dictated by deferral and cost contemplations. Practically speaking, this favors distinguishable info first executions.
REFERENCES
1. P. Guerrier and A. Greiner, "A nonexclusive design for on-chip parcel
exchanged interconnections," in DATE, Mar. 2000, pp. 250– 256. 2. W. J. Falter and B. Towles, "Course bundles, not wires: on-chip
interconnection systems," in Proc.Des. Autom. Conf., 2001, pp. 684– 689.
3. L. Benini and G. D. Micheli, "Systems on chips: another soc
worldview," IEEE Comput., vol. 35, no. 1, pp. 70– 78, Jan. 2002.
4. Salminen ET AL., "Study Of Network-On-Chip Proposals", White
Paper, ©OCP-IP, and March 2008.
5. F. G. Moraes, N. Calazans, A. Mello, L. Mller, and L. Ost, "HERMES:
A foundation for low zone overhead bundle exchanging systems on chip," Integration. VLSI J., vol. 38, no. 1, pp. 69– 93, 2004
6. Marta Ortín-Obón ,DaríoSuárez-Gracia,"Analysis of system on-chip
topologies for cost-proficient chip multiprocessors",microprocessors and Microsystems,5 feb 2016,pp:1-13.
7. D. Wiklund and D. Liu, SoCBUS: exchanged system on chip for hard
constant inserted frameworks. IEEE Computer Society, 2003, p8-16. 8. K. Goossens, J. Dielissen, and A. Radulescu, "Æthereal arrange on
chip: Concepts, models, and usage," IEEE Des. Test Comput., vol. 22, no. 5, pp. 414– 421, May 2005
9. C. Bobda and A. Ahmadinia, "Dynamic interconnection of
reconfigurable modules on reconfigurable gadgets," IEEE Des. Test Comput., vol. 22, no. 5, pp. 443– 451, May 2005.
10. L. Benini and D. Bertozzi, "Xpipes: A system on-chip design for gigascale frameworks on-chip," IEEE Circuits Syst. Mag., vol. 4, no. 2, pp. 18– 31, Sep. 2005.
11. K. Lusala and J.- D. Legat, "A sdm-tdm put together circuit-exchanged
switch for with respect to chip systems," in Proc. Reconfigurable Commun.- driven Systems-on-Chip sixth Int. Workshop, Jun. 2011, pp. 1– 8.
12. Jara-Berrocal and A. Gordon-Ross, "SCORES: An adaptable and
parametric streams-based correspondence design for secluded reconfigurable frameworks," in Proc. Des., Autom. Test Eur. Conf., 2009, pp. 268– 273.
13. J. Lin and X. Lin, "Express circuit exchanging: Improving the
execution of bufferless systems
14. on-chip," in Proc. IEEE First Int. Conf. System Comput., Nov. 2010,
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-10, August 2019
15. WeiweiJiang ,KshitijBhardwaj ,"A Lightweight Early Arbitration
Method for Low-Latency Asynchronous 2D-Mesh NoC's", ACM 978-1-4503-3520-1/15/06,2015.
16. RiteshRampal, RajeevanChandel, Philemon Daniel,"A
Network-on-Chip Router for Deadlock-Free Multicast Mesh Routing," 978-1-4799-9985-9/15. ©2015 IEEE
17. FatemehNasiri , Hamid Sarbazi-azad, Ahmad Khademzadeh,"
Reconfigurable multicast steering for Networks on Chip", Microprocessors and Microsystems 42 (2016) 180– 189.
18. Akram Ben Ahmed, Abderazek Ben Abdallah," Adaptive
Fault-Tolerant Architecture and Routing Algorithm for Reliable Many-Core 3D-NoC frameworks", J. Parallel Distrib. Comput. (2016).
19. PooriaM.Yaghini, AshkanEghbal, Nader Bagherzadeh," On the
Design of Hybrid Routing Mechanism for Mesh-put together Network-with respect to Chip", INTEGRATION, the VLSI diary, S0167-9260(14)00092-3.
20. Marcus Eggenberger, Manuel Strobel, Martin Radetzki,"Globally
Asynchronous LocallySynchronous Simulation of NoCs on Many-Core Architectures", 2016 24th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing.
21. R. Akbar , F. Safaei ,"An epic power proficient versatile RED-based
stream control instrument for systems on-chip", 0045-7906/© 2015 Elsevier.
22. N. Teimouri, M. Modarressi, and H. Sarbazi-Azad, "Power and
execution effective fractional circuits in bundle exchanged systems on-chip," in Proc. IEEE 21st Euromicro Int. Conf. Parallel,Distrib. Netw. Procedure, Feb. 2013, pp. 509– 513.
23. Rohit Kumar and Ann Gordon-Ross, "Macintoshes: A Highly
Customizable Low-Latency Communication Architecture", IEEE Transactions on Parallel and Distributed Systems, VOL. 27,NO. 1, January 2016, PP-237-249.
24. J. Kim et al., "A low inactivity switch supporting adaptively for on-chip interconnects," in DAC, Jun. 2005, pp. 559– 564
25. RimpyBishnoi , Vijay Laxmi , Manoj Singh Gaur , Mark Zwolinski,"
Resilient directing execution in 2D work NoC", Microelectronics Reliability 56 (2016) 189– 201.
26. Edson I. Moreno,cesar.a.m.marcon,"arbitration and steering sway on NoC design",978-1-4577-0660-8/11 ©2011 IEEE.
27. H.- C. Chi and J.- H. Chen, "Structure and usage of a directing switch
for on-chip interconnection systems," in AP-ASIC, Aug. 2004, pp. 392– 395.
28. A. I. A. Jabbar, Noor .Th. AL Malah," Design and Implementation of a
Network on Chip UsingFPGA", Al-Rafidain Engineering Vol.21 No. 1 February 2013, pp: 91-100.
29. Lu Wang, Sheng Ma," A High Performance Reliable NoC Router," 978-1-4673-9569-4/16-©2016 IEEE.
30. ParthaPratimPande , Andre' Ivanov "Execution assessment and
configuration exchange offs for system on-chip interconnect structures," IEEE Trans. PCs, vol. 54, no. 8, pp. 1025– 1040, Aug. 2005.
31. J. Henkel, W. Wolf, and S. Chakradhar, "On-chip arranges: a versatile,
correspondence driven implanted framework structure worldview," in VLSI, Jan. 2004, pp. 845– 851.
32. LudovicDevaux, SebastienPillement, Daniel Chillet, Didier Demigny.