Microsoft® Big Data Solutions Published by
John Wiley & Sons, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com
Copyright © 2014 by John Wiley & Sons, Inc., Indianapolis, Indiana Published simultaneously in Canada
ISBN: 978-1-118-72908-3 ISBN: 978-1-118-74209-9 (ebk) ISBN: 978-1-118-72955-7 (ebk)
Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1
No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or autho-rization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at http://www.wiley.com/go/permissions.
Limit of Liability/Disclaimer of Warranty: The publisher and the author make no representations or warranties with respect to the accuracy or completeness of the contents of this work and specifi cally disclaim all warranties, including without limitation warranties of fi tness for a particular purpose. No warranty may be created or extended by sales or promotional materials. The advice and strategies contained herein may not be suitable for every situation. This work is sold with the understanding that the publisher is not engaged in rendering legal, accounting, or other professional services. If professional assistance is required, the services of a competent professional person should be sought. Neither the publisher nor the author shall be liable for damages arising herefrom. The fact that an organization or Web site is referred to in this work as a citation and/or a potential source of further information does not mean that the author or the publisher endorses the information the organization or website may provide or recommendations it may make. Further, readers should be aware that Internet websites listed in this work may have changed or disap-peared between when this work was written and when it is read.
For general information on our other products and services please contact our Customer Care Department within the United States at (877) 762-2974, outside the United States at (317) 572-3993 or fax (317) 572-4002.
Wiley publishes in a variety of print and electronic formats and by print-on-demand. Some material included with standard print versions of this book may not be included in e-books or in print-on-demand. If this book refers to media such as a CD or DVD that is not included in the version you purchased, you may download this material at http://booksupport.wiley.com. For more information about Wiley products, visit www.wiley.com. Library of Congress Control Number: 2013958290
Trademarks: Wiley and the Wiley logo are trademarks or registered trademarks of John Wiley & Sons, Inc. and/or its affi liates, in the United States and other countries, and may not be used without written permission. Microsoft is a registered trademark of Microsoft Corporation. All other trademarks are the property of their respective owners. John Wiley & Sons, Inc. is not associated with any product or vendor mentioned in this book.
Executive Editor Robert Elliot Project Editor Jennifer Lynn Technical Editors Rohit Bakhshi John Hoang Josh Luedeman Production Editor Christine Mugnolo Copy Editor Keith Cline Editorial Manager Mary Beth Wakefi eld Freelancer Editorial Manager Rosemarie Graham
Associate Director of Marketing David Mayhew
Marketing Manager Ashley Zurcher Business Manager Amy Knies
Vice President and Executive Group Publisher Richard Swadley
Associate Publisher Jim Minatel
Project Coordinator, Cover Todd Klemme
Proofreader
— Adam Jorgensen
For my beautiful and eternally patient wife, Jane, and our three children Lucy, Kate, and Oliver. I will love you all forever.
— James Rowland-Jones
To my lovely wife, Marlana, and my children, Kayla and Michael, thanks for the support and understanding during the late nights while I was writing.
— John Welch
To my family, thank you for your unconditional support throughout this process. I’d especially like to thank my wife Shannon for believing in me.
at PASS conferences, the Microsoft Business Intelligence conference, Software Development West (SD West), Software Management Conference (ASM/SM), and others. He has also contributed to multiple books on SQL Server, including
Smart Business Intelligence Solutions with Microsoft SQL Server 2008 (Microsoft Press, 2009) and the SQL Server MVP Deep Dives (Manning Publications) series.
John writes a blog on BI and SQL Server Information Services (SSIS) topics at http://agilebi.com/jwelch. He is active in open source projects that help ease the development process for Microsoft BI developers, including ssisUnit (http://ssisunit.codeplex.com), a unit testing framework for SSIS.
Dan Clark is a senior BI consultant for Pragmatic Works. He enjoys learning new BI technologies and training others how to best implement the technology. Dan is particularly interested in how to use data to drive better decision making. Dan has published several books and numerous articles on .NET programming and BI development. He is a regular speaker at various developer/BI conferences and user group meetings, and enjoys interacting with the Microsoft developer and database communities.
Chris Price is a senior consultant with Microsoft based out of Tampa, Florida. He has a Bachelor of Science degree in management information systems and a Master of Business Administration degree, both from the University of South Florida. He began his career as a developer, programming with everything from Visual Basic and Java to both VB.Net and C# as he worked his way into a software architect role before being bitten by the BI bug. Although he is still passionate about software development, his current focus is on ETL (extract, transform, and load), Data integration, data quality, MDM (master data manage-ment), SSAS (SQL Server Analysis Server), SharePoint, and all things big data. He regularly speaks at SQL Saturdays, PASS Summit, conferences, code camps, and other community events. He blogs frequently and has also authored mul-tiple books and whitepapers and has served as technical editor for a range of BI and big data topics. You can follow Chris on his blog at http://bluewatersql .wordpress.com/ or on Twitter at @BluewaterSQL.
Brian Mitchell is the lead architect of the Microsoft Big Data Center of Expertise. Brian focuses exclusively on data warehouse/business intelligence (DW/BI) solutions, with the majority of his time focusing on SQL Server Parallel Data Warehouse (PDW) and HDInsight. He has spent more than 15 years work-ing with Microsoft SQL Server and Microsoft Business Intelligence. Brian is a Microsoft Certifi ed Master–SQL Server 2008. You can fi nd his blog on topics such as Big Data, SQL Server Parallel Data Warehouse, and Microsoft Business Intelligence at http://brianwmitchell.com. Brian earned his Master of Business Administration degree from the University of Florida. When he is not tinkering with SQL Server or Hadoop, Brian enjoys spending time exploring his adopted home state of Florida with his wife, Shannon, and their kids.
Josh Luedeman has been working with SQL Server for more than eight years. He is currently a solutions architect with Data Structures, Inc., where he is working with customers to help them utilize business intelligence (BI) tools and big data. He has worked in IT for more than 10 years, holding positions in application support, database administration, and BI. In these industries, Josh has held integral roles in Fortune 500 companies, major institutions of higher education, small-medium businesses, and startups. Josh is a speaker at software development and data conferences including Code On The Beach and multiple SQL Saturdays. He is originally from Corning, New York, and currently resides in Orlando, Florida, with his wife and children. Josh can be found online at www .joshluedeman.com, [email protected], www.linkedin.com/in /joshluedeman, and @joshluedeman on Twitter.
Michael Reed has a long history of designing innovative solutions to diffi cult business problems. During the last 14 years, he focused on database development and architecture, and more recently business intelligence and analytics. He is currently employed by Pragmatic Works as a Senor BI Consultant. Previously he was director of Insight and Analytics at a healthcare claim processor. Prior to that he held operations, data, and information delivery centric roles in Microsoft’s Online Services Division; specifi cally the AdCenter Behavioral Targeting group, which is the primary research unit for mining social behaviors at Microsoft supporting the Bing decision search engine and BingAds advertising services.
In a prior life, he was co-owner of a multimillion dollar manufacturing busi-ness, grown from a startup, where he gained much of the business knowledge and insight he employs in his work today.
x Contents
Part II Setting Up for Big Data with Microsoft 37 Chapter 3 Confi guring Your First Big Data Environment 39
Getting Started 39
Getting the Install 40
Running the Installation 40
On-Premise Installation: Single-Node Installation 41 HDInsight Service: Installing in the Cloud 51 Windows Azure Storage Explorer Options 52
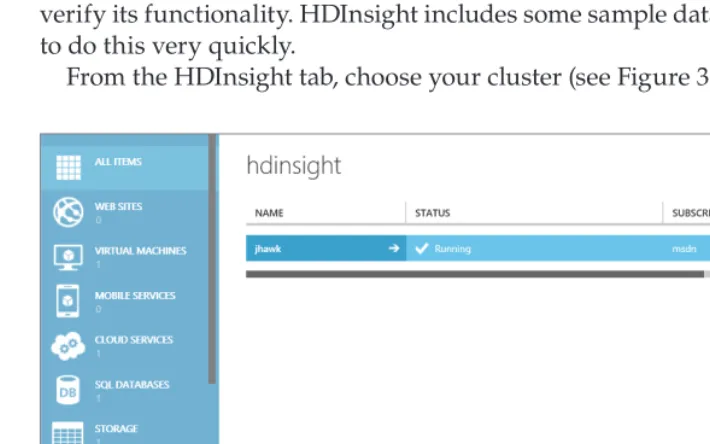
Validating Your New Cluster 55
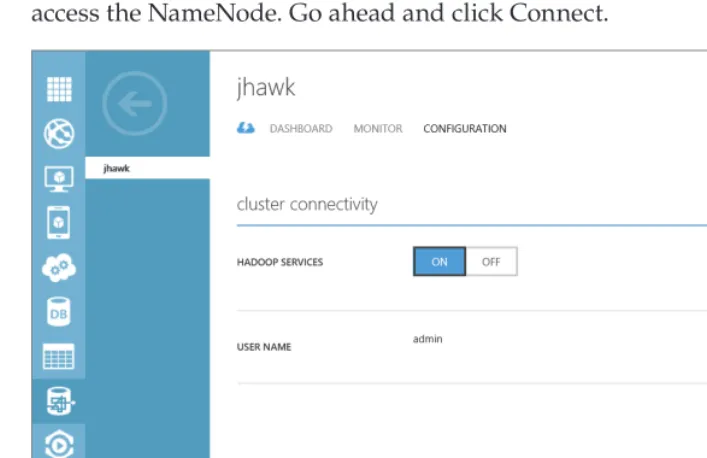
Logging into HDInsight Service 55
Verify HDP Functionality in the Logs 57
Common Post-Setup Tasks 58
Loading Your First Files 58
Verifying Hive and Pig 60
Summary 63
Part III Storing and Managing Big Data 65 Chapter 4 HDFS, Hive, HBase, and HCatalog 67
Exploring the Hadoop Distributed File System 68
Explaining the HDFS Architecture 69
Interacting with HDFS 72
Exploring Hive: The Hadoop Data Warehouse Platform 75
Designing, Building, and Loading Tables 76
Querying Data 77
Confi guring the Hive ODBC Driver 77
Exploring HCatalog: HDFS Table and Metadata Management 78
Exploring HBase: An HDFS Column-Oriented Database 80
Columnar Databases 81
Defi ning and Populating an HBase Table 82
Using Query Operations 83
Summary 84
Chapter 5 Storing and Managing Data in HDFS 85
Understanding the Fundamentals of HDFS 86
HDFS Architecture 87
NameNodes and DataNodes 89
Data Replication 90
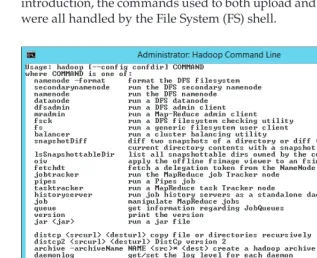
Using Common Commands to Interact with HDFS 92
Interfaces for Working with HDFS 92
File Manipulation Commands 94
Administrative Functions in HDFS 97
Moving and Organizing Data in HDFS 100
Moving Data in HDFS 100
Implementing Data Structures for
Easier Management 101
Rebalancing Data 102
Chapter 6 Adding Structure with Hive 105
Understanding Hive’s Purpose and Role 106
Providing Structure for Unstructured Data 107 Enabling Data Access and Transformation 114 Differentiating Hive from Traditional RDBMS Systems 115
Working with Hive 116
Creating and Querying Basic Tables 117
Creating Databases 117
Creating Tables 118
Adding and Deleting Data 121
Querying a Table 123
Using Advanced Data Structures with Hive 126
Setting Up Partitioned Tables 126
Loading Partitioned Tables 128
Using Views 129
Creating Indexes for Tables 130
Summary 131
Chapter 7 Expanding Your Capability with HBase and HCatalog 133
Using HBase 134
Creating HBase Tables 134
Loading Data into an HBase Table 136
Performing a Fast Lookup 138
Loading and Querying HBase 139
Managing Data with HCatalog 140
Working with HCatalog and Hive 140
Defi ning Data Structures 141
Creating Indexes 143
Creating Partitions 143
Integrating HCatalog with Pig and Hive 145
Using HBase or Hive as a Data Warehouse 149
Summary 150
Part IV Working with Your Big Data 151 Chapter 8 Eff ective Big Data ETL with SSIS, Pig, and Sqoop 153
Combining Big Data and SQL Server Tools for
Better Solutions 154
Why Move the Data? 154
Transferring Data Between Hadoop and SQL Server 155
Working with SSIS and Hive 156
Connecting to Hive 157
Confi guring Your Packages 161
Loading Data into Hadoop 165
Getting the Best Performance from SSIS 167
Transferring Data with Sqoop 167
Copying Data from SQL Server 168
xii Contents
Using Pig for Data Movement 171
Transforming Data with Pig 171
Using Pig and SSIS Together 174
Choosing the Right Tool 175
Use Cases for SSIS 175
Use Cases for Pig 175
Use Cases for Sqoop 176
Summary 176
Chapter 9 Data Research and Advanced Data Cleansing
with Pig and Hive 177
Getting to Know Pig 178
When to Use Pig 178
Taking Advantage of Built-in Functions 179
Executing User-defi ned Functions 180
Using UDFs 182
Building Your Own UDFs for Pig 189
Using Hive 192
Data Analysis with Hive 192
Types of Hive Functions 192
Extending Hive with Map-reduce Scripts 195
Creating a Custom Map-reduce Script 198
Creating Your Own UDFs for Hive 199
Summary 201
Part V Big Data and SQL Server Together 203 Chapter 10 Data Warehouses and Hadoop Integration 205
State of the Union 206
Challenges Faced by Traditional Data Warehouse
Architectures 207
Technical Constraints 207
Business Challenges 213
Hadoop’s Impact on the Data Warehouse Market 216
Keep Everything 216
Code First (Schema Later) 217
Model the Value 218
Throw Compute at the Problem 218
Introducing Parallel Data Warehouse (PDW) 220
What Is PDW? 221
Why Is PDW Important? 222
How PDW Works 224
Project Polybase 235
Polybase Architecture 235
Chapter 11 Visualizing Big Data with Microsoft BI 257
An Ecosystem of Tools 258
Excel 258 PowerPivot 258
Power View 259
Power Map 261
Reporting Services 261
Self-service Big Data with PowerPivot 263
Setting Up the ODBC Driver 263
Loading Data 265
Updating the Model 272
Adding Measures 273
Creating Pivot Tables 274
Rapid Big Data Exploration with Power View 277
Spatial Exploration with Power Map 281
Summary 283
Chapter 12 Big Data Analytics 285
Data Science, Data Mining, and Predictive Analytics 286
Data Mining 286
Predictive Analytics 287
Introduction to Mahout 288
Building a Recommendation Engine 289
Getting Started 291
Running a User-to-user Recommendation Job 292 Running an Item-to-item Recommendation Job 295 Summary 296
Chapter 13 Big Data and the Cloud 297
Defi ning the Cloud 298
Exploring Big Data Cloud Providers 299
Amazon 299 Microsoft 300
Setting Up a Big Data Sandbox in the Cloud 300
Getting Started with Amazon EMR 301
Getting Started with HDInsight 307
Storing Your Data in the Cloud 315
Storing Data 316
Uploading Your Data 317
Exploring Big Data Storage Tools 318
Integrating Cloud Data 319
Other Cloud Data Sources 321
Summary 321
Chapter 14 Big Data in the Real World 323
Common Industry Analytics 324
xiv Contents
Retail 325
Data Services 326
IT/Hosting Optimization 326
Marketing Social Sentiment 327
Operational Analytics 327
Failing Fast 328
A New Ecosystem of Technologies 328
User Audiences 330
Summary 333
Part VI Moving Your Big Data Forward 335 Chapter 15 Building and Executing Your Big Data Plan 337
Gaining Sponsor and Stakeholder Buy-In 338
Problem Defi nition 338
Scope Management 339
Stakeholder Expectations 341
Defi ning the Criteria for Success 342
Identifying Technical Challenges 342
Environmental Challenges 342
Challenges in Skillset 344
Identifying Operational Challenges 345
Planning for Setup/Confi guration 345
Planning for Ongoing Maintenance 347
Going Forward 348
The HandOff to Operations 348
After Deployment 349
Summary 350
Chapter 16 Operational Big Data Management 351
Hybrid Big Data Environments: Cloud and
On-Premise Solutions Working Together 352 Ongoing Data Integration with Cloud and
On-Premise Solutions 353
Integration Thoughts for Big Data 354
Backups and High Availability in
Your Big Data Environment 356
High Availability 356
Disaster Recovery 358
Big Data Solution Governance 359
Creating Operational Analytics 360
System Center Operations Manager for HDP 361 Installing the Ambari SCOM Management Pack 362 Monitoring with the Ambari SCOM Management Pack 371 Summary 377
xvi Introduction
Our Team
We have assembled a strong international team of authors to make sure that we can provide a sound perspective and knowledge transfer on the right topics (we’ll discuss those shortly). Those topics include:
1. Accelerated overview of Big Data, Hadoop, NoSQL, and key industry knowledge
2. Key problems people are trying to solve and how to identify them
3. Delivering big data in a Microsoft world
4. Tool and platform choice
5. Installation, confi guration, and exploration
6. Storing and managing big data
7. Working with, adding structure, and cleansing your data
8. Big data and SQL Server together
9. Analytics in the big data world
10. How this works in the cloud
11. Case studies and real world applications
12. Moving your organization forward in this new world
This team includes members of Pragmatic Works, a global leader in information services, software, and training; Microsoft Research; Microsoft Consulting Services; Azure Customer Advisory Team; and some other industry fi rms making a big impact in this expanding space.
All Kidding Aside
Big data is coming on strong. You will have these solutions in your environ-ment within 24 months, and you should be prepared. This book is designed to help you make the transition with practical skills from a relational to a more “evolved” view of the data worlds. This includes solutions that will handle data that does not fi t nicely into a tabular structure, but is nonetheless just as or more important in some cases as the data that you have curated so carefully for so many years.
Who Is This Book For?
This book is for those data developers, power users, and executives looking to understand how these big data technologies will impact their world and how to properly approach solutions in this new ecosystem. Readers will need a basic understanding of data systems and a passion for learning new technologies and techniques. Some experience with developing database or application solutions will be helpful in some advanced topic areas.
What You Need to Use This Book
We have designed this book to make extensive use of cloud resources so, as the reader, you will need to have a newer model computer PC or Mac that can access the Internet reliably. In addition, you will want to be able to install additional pro-grams and tools as advised by the authors, so please ensure you have that access on the machine you’re using. Different chapters will have different tools or data sets, so please follow the authors’ instructions in those chapters to get the most out of your experience. Having access to a SQL Server database will be required in certain chapters, and if you wish to set up your environment on premise, then a virtualization technology such as Hyper-V, VMWare, or Virtual box is recommended.
Chapter Overview
Now we’ll go through the chapters in this text and discuss what you’ll be learning from each one.
■ Chapter 1: Industry Needs and Solutions
No book on big data would be complete without some coverage of the history, origins, and use cases in this ecosystem. We also need to discuss the industry players and platforms that are in scope for the book. Other books spend 5 to 6 chapters rehashing this information; we have done it effi ciently for you so you can get to work on more fun topics!
■ Chapter 2: Microsoft’s Approach to Big Data
xviii Introduction
■ Chapter 3: Installing HDInsight
In this chapter, you’ll get started confi guring your big data environment.
■ Chapter 4: HDFS, Hive, HBase and HCatalog
These are some key data and metadata technologies. We’ll make sure you understand when to use each one and how to get the most out of them.
■ Chapter 5: Storing and Managing data in HDFS
A distributed fi le system might be a new concept for most readers, so we are going to make sure we go through this core component of Hadoop and ensure you’re prepared for designing with this incredible feature.
■ Chapter 6: Adding Structure with Hive
We need to go deeper into Hive because you’ll use it a lot. Let’s dive in with this chapter to make sure you understand commands and the logic behind using Hive effi ciently.
■ Chapter 7: Expanding your Capability with HBase and HCatalog
Dealing with large tables and metadata requires some new tools and techniques. HBase and HCatalog will help you manage these types of challenges, and we’re going to take you through using them. Get ready to put the BIG in big data.
■ Chapter 8: Effective Big Data ETL with SSIS, Pig, and Sqoop
We have to load this data, and there is no better way to do it than with our ETL expert authors. Come along while they take you through using favorite and familiar tools, along with some new ones, to load data quickly and effectively.
■ Chapter 9: Data Research and Advanced Data Cleansing with Pig and Hive
Now we’ve installed, confi gured, explored, and loaded some data. Let’s get buys researching and cleansing this data with our new tools and platform.
■ Chapter 10: Data Warehouses and Hadoop Integration
How do SQL Server and business intelligence fi t in with big data? Very closely. Most of the time they will work in tandem. We will show you when to use each solution and how they work together in scale-up and scale-out solutions.
■ Chapter 11: Visualizing Big Data with Microsoft BI
4 Part I ■ What Is Big Data?
What’s So
Big
About Big Data?
The world has witnessed explosive, exponential growth in recent times. So, did we suddenly have a need for big data? Not exactly. Businesses have been tackling the capacity challenge for many years (much to the delight of storage hardware vendors). Therefore the big in big data isn’t purely a statement on size. Likewise, on the processing front, scale-out solutions such as high-performance computing and distributed database technology have been in place since the last millennium. There is nothing intrinsically new there either.
People also often talk about unstructured data, but, really, this just refers to the format of the data. Could this be a reason we “suddenly” need big data? We know that web data, especially web log data, is born in an unstructured format and can be generated in signifi cant quantities and volume. However, is this really enough to be considered big data?
In my mind, the answer is no. No one property on its own is suffi cient for a project or a solution to be considered a big data solution. It’s only when you have a cunning blend of these ingredients that you get to bake a big data cake. This is in line with the Gartner defi nition of big data, which they updated in Doug Laney’s publication, The Importance of Big Data: A Definition
(Gartner, 2012): “High volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision mak-ing, insight discovery and process optimization.”
What we do know is that every CIO on the planet seems to want to start a big data project right now. In a world of shrinking budgets, there is this sudden desire to jump in with both feet into this world of big data and start prospecting for golden nuggets. It’s the gold rush all over again, and clearly companies feel like they might miss out if they hesitate.
However, this is a picture that has been sharpening its focus for several years. In the buildup to this ubiquitous acceptance of big data, we’ve been blessed with plenty of industry terms and trends, web scale, new programming paradigms of “code fi rst,” and of course, to the total disgust of data modelers everywhere, NoSQL. Technologies such as Cassandra and MongoDB are certainly part of the broader ecosystem, but none have resonated as strongly with the market as Hadoop and big data. Why? In essence, unless you were Facebook, Google, Yahoo!, or Bing, issues like web scale really didn’t apply.
Big data, therefore, is a term that underpins a raft of technologies (includ-ing the various Hadoop projects, NoSQL offer(includ-ings, and even MPP Database Systems, for example) that have been created in the drive to better analyze and derive meaning from data at a dramatically lower cost and while delivering new insights and products for organizations all over the world. In times of recession, businesses look to derive greater value from the assets they have rather than invest in new assets. Big data, and in particular Hadoop, is the perfect vehicle for doing exactly that.
A Brief History of Hadoop
Necessity is the mother of invention, and Hadoop is no exception. Hadoop was created to meet the need of web companies to index and process the data tsu-nami courtesy of the newfangled Internetz. Hadoop’s origins owe everything to both Google and the Apache Nutch project. Without one infl uencing the other, Hadoop might have ended up a very different animal (joke intended). In this next section, we are going to see how their work contributed to making Hadoop what it is today.
As with many pioneering efforts, Google provided signifi cant inspiration for the development that became known as Hadoop. Google published two landmark papers. The fi rst paper, published in October 2003, was titled “The Google File System,” and the second paper, “MapReduce: Simplifi ed Data Processing on Large Clusters,” published just over a year later in December 2004, provided the inspiration to Doug Cutting and his team of part-time developers for their project, Nutch.
MapReduce was fi rst designed to enable Google developers to focus on the large-scale computations that they were trying to perform while abstracting away all the scaffolding code required to make the computation possible. Given the size of the data set they were working on and the duration of tasks, the developers knew that they had to have a model that was highly parallelized, was fault tolerant, and was able to balance the workload across a distributed set of machines. Of course, the Google implementation of MapReduce worked over Google File System (GFS); Hadoop Distributed File System (HDFS) was still waiting to be invented.
6 Part I ■ What Is Big Data?
There are similarities here to the SIGMOD papers published by various par-ties in the relational database world, but ultimately it isn’t the same. Let’s look at an example. Twitter has open-sourced Storm—their complex event process-ing engine—which has recently been accepted into the Apache incubator pro-gram. For relational database vendors, this level of open sharing is really quite unheard of. For more details about storm head over to Apache: http://incubator .apache.org/projects/storm.html.
Nutch
Nutch was an open source crawler-based search engine built by a handful of part-time developers, including Doug Cutting. As previously mentioned Cutting was inspired by the Google publications and changed Nutch to take advantage of the enhanced scalability of the architecture promoted by Google. However, it wasn’t too long after this that Cutting joined Yahoo! and Hadoop was born.
Nutch joined the Apache foundation in January 2005, and its fi rst release (0.7) was in August 2005. However, it was not until 0.8 was released in July 2006 that Nutch began the transition to Hadoop-based architecture.
Nutch is still very much alive and is an actively contributed-to project. However, Nutch has now been split into two codebases. Version 1 is the legacy and provides the origins of Hadoop. Version 2 represents something of a re-architecture of the original implementation while still holding true to the original goals of the project.
What Is Hadoop?
Apache Hadoop is a top-level open source project and is governed by the Apache Software Foundation (ASF). Hadoop is not any one entity or thing. It is best thought of as a platform or an ecosystem that describes a method of distrib-uted data processing at scale using commodity hardware confi gured to run as a cluster of computing power. This architecture enables Hadoop to address and analyze vast quantities of data at signifi cantly lower cost than traditional methods commonly found in data warehousing, for example, with relational database systems.
At its core, Hadoop has two primary functions:
■ Processing data (MapReduce)
■ Storing data (HDFS)
That said, a number of additional subprojects have been developed and added to the ecosystem that have been built on top of these two primary functions. When bundled together, these subprojects plus the core projects of MapReduce and HDFS become known as a distribution.
Derivative Works and Distributions
To fully understand a distribution, you must fi rst understand the role, naming, and branding of Apache Hadoop. The basic rule here is that only offi cial releases by the Apache Hadoop project may be called ApacheHadoop or Hadoop. So, what about companies that build products/solutions on top of Hadoop? This is where the term derivativeworks comes in.
What Are Derivative Works?
Any product that uses Apache Hadoop code, known as artifacts, as part of its construction is said to be a derivative work. A derivative work is not an Apache Hadoop release. It may be true that a derivative work can be described as “pow-ered by Apache Hadoop.” However, there is strict guidance on product naming to avoid confusion in the marketplace. Consequently, companies that provide distributions of Hadoop should also be considered to be derivative works.
N O T E I liken the relationship between Hadoop and derivative works to the world of Xbox games development. Many Xbox games use graphics engines provided by a third party. The Unreal Engine is just such an example.
What Is a Distribution?
Now that you know what a derivative work is, we can look at distributions. A
distribution is the packaging of Apache Hadoop projects and subprojects plus any other additional proprietary components into a single managed package. For example, Hortonworks provides a distribution of Hadoop called “Hortonworks Data Platform,” or HDP for short. This is the distribution used by Microsoft for its product, HDInsight.
You may be asking yourself what is so special about that? You could certainly do this yourself. However, this would be a signifi cant undertaking. First, you’d need to download the projects you want, resolve any dependencies, and then compile all the source code. However, when you decide to go down this route, all the testing and integration of the various components is on you to manage and maintain. Bear in mind that the creators of distributions also employ the committers of the actual source and therefore can also offer support.
8 Part I ■ What Is Big Data?
consider when picking a distribution. Frequency of updates is a key factor, given how quickly the Hadoop ecosystem evolves.
If you look at the Hortonworks distribution, known as Hortonworks Data Platform (HDP), you can see that there are a number of projects at different stages of development. The distribution brings these projects together and tests them for interoperability and stability. Once satisfi ed that the projects all hang together, the distributor (in this case, Hortonworks) creates the versioned release of the integrated software (the distribution as an installable package).
The 1.3 version made a number of choices as to which versions to support. Today, though, just a few months later, the top-line Hadoop project has a 1.2.0.5 release available, which is not part of HDP 1.3. This and other ecosystem changes will be consumed in the next release of the HDP distribution.
To see a nice graphic of the Hortonworks distribution history, I will refer you to http://hortonworks.com/products/hdp-2/. Hadoop is a rapidly changing and evolving ecosystem and doesn’t rest on its laurels so including version history is largely futile.
Hadoop Distributions
Note that there are several Hadoop distributions on the market for you to choose from. Some include proprietary components; others do not. The following sec-tions briefl y cover some of the main Hadoop distribusec-tions.
Hortonworks HDP
Hortonworks provides a distribution of Apache Hadoop known as Hortonworks Data Platform (HDP). HDP is a 100% open source distribution. Therefore, it does not contain any proprietary code or licensing. The developers employed by Hortonworks contribute directly to the Apache projects. Hortonworks is also building a good track record for regular releases of their distribution, educational content, and community engagement. In addition, Hortonworks has established a number of strategic partnerships, which will stand them in good stead. HDP is available in three forms. The fi rst is for Hadoop 1.x, and the second is for Hadoop 2.0, which is currently in development. Hortonworks also offers HDP for Windows, which is a third distribution. HDP for Windows is the only version that runs on the Windows platform.
MapR
10 Part I ■ What Is Big Data?
In this next section, we are going to delve a little deeper into these core Hadoop projects to build up our knowledge of the main building blocks. Once we’ve done that, we’ll be well placed to move forward with the next section, which will touch on some of the other projects in the Hadoop ecosystem.
HDFS
HDFS, one of the core components of Apache Hadoop, stands for Hadoop Distributed File System. There’s no exotic branding to be found here. HDFS is a Java-based, distributed, fault-tolerant fi le storage system designed for distribu-tion across a number of commodity servers. These servers have been confi gured to operate together as an HDFS cluster. By leveraging a scale-out model, HDFS ensures that it can support truly massive data volumes at a low and linear cost point.
Before diving into the details of HDFS, it is worth taking a moment to discuss the fi les themselves. Files created in HDFS are made up of a number of HDFS
datablocks or simply HDFS blocks. These blocks are not small. They are 64MB or more in size, which allows for larger I/O sizes and in turn greater throughput. Each block is replicated and then distributed across the machines of the HDFS cluster.
HDFS is built on three core subcomponents:
■ NameNode
■ DataNode
■ Secondary NameNode
Simply put, the NameNode is the “brain.” It is responsible for managing the fi le system, and therefore is responsible for allocating directories and fi les. The NameNode also manages the blocks, which are present on the DataNode. There is only one NameNode per HDFS cluster.
The DataNodes are the workers, sometimes known as slaves. The DataNodes perform the bidding of the NameNode. DataNodes exist on every machine in the cluster, and they are responsible for offering up the machine’s storage to HDFS. In summary, the job of the DataNode is to manage all the I/O (that is, read and write requests).
HDFS is also the point of integration for a new Microsoft technology called Polybase, which you will learn more about in Chapter 10, “Data Warehouses and Hadoop Integration.”
MapReduce
combination of Java ARchive (JAR) fi les and classes required to execute the MapReduce program. These fi les are themselves collated into a single JAR fi le known as a job fi le.
Each MapReduce job can be broken down into a few key components. The fi rst phase of the job is the map. The map breaks the input up into many tiny pieces so that it can then process each piece independently and in parallel. Once complete, the results from this initial process can be collected, aggregated, and processed. This is the reduce part of the job.
The MapReduce engine is used to distribute the workload across the HDFS cluster and is responsible for the execution of MapReduce jobs. The MapReduce engine accepts jobs via the JobTracker. There is one JobTracker per Hadoop cluster (the impact of which we discuss shortly). The JobTracker provides the scheduling and orchestration of the MapReduce engine; it does not actually process data itself.
To execute a job, the JobTracker communicates with the HDFS NameNode to determine the location of the data to be analyzed. Once the location is known, the JobTracker then speaks to another component of the MapReduce engine called the TaskTracker. There are actually many TaskTracker nodes in the Hadoop cluster. Each node of the cluster has its own TaskTracker. Clearly then, the MapReduce engine is another master/slave architecture.
TaskTrackers provide the execution engine for the MapReduce engine by spawning a separate process for every task request. Therefore, the JobTracker must identify the appropriate TaskTrackers to use by assessing which are avail-able to accept task requests and, ideally, which trackers are closest to the data. After the decision has been made, the JobTracker can submit the workload to the targeted TaskTrackers.
TaskTrackers are monitored by the JobTracker. This is a bottom-up monitoring process. Each TaskTracker must “report in” via a heartbeat signal. If it fails to do so for any reason, the JobTracker assumes it has failed and reassigns the tasks accordingly. Similarly, if an error occurs during the processing of an assigned task, the TaskTracker is responsible for calling that in to the JobTracker. The decision on what to do next then lies with the JobTracker.
The JobTracker keeps a record of the tasks as they complete. It maintains the status of the job, and a client application can poll it to get the latest state of the job.
N O T E The JobTracker is a single point of failure for the MapReduce engine. If it goes down, all running jobs are halted, and new jobs cannot be scheduled.
Important Apache Projects for Hadoop
12 Part I ■ What Is Big Data?
Some will succeed, while others will wither and die. That is the very nature of open source software. The good ideas get developed, evolve, and become great—at least, that’s the theory.
Some of the projects we are about to discuss are driving lots of innovation— especially for Hadoop 2.0. Hive is the most notable project in this regard. Almost all the work around the Hortonworks Stinger initiative is to empower SQL in Hadoop. Many of these changes will be driven through the Hive project. Therefore, it is important to know what Hive is and why it is getting so much attention.
Hive
Apache Hive is another key subproject of Hadoop. It provides data warehouse software that enables a SQL-like querying experience for the end user. The Hive query language is called Hive Query Language (HQL). (Clearly, the creators of Hive had no time for any kind of creative branding.) HQL is similar to ANSI SQL, making the crossover from one to the other relatively simple. HQL pro-vides an abstraction over MapReduce; HQL queries are translated by Hive into MapReduce jobs. Hive is therefore quite a popular starting point for end users because there is no need to learn how to program a MapReduce job to access and process data held in Hadoop.
It is important to understand that Hive does not turn Hadoop into a relational database management system (RDBMS). Hive is still a batch-processing system that generates MapReduce jobs. It does not offer transactional support, a full type system, security, high concurrency, or predictable response times. Queries tend to be measured in minutes rather in than milliseconds or seconds. This is because there is a high spin-up cost for each query and, at the end of the day, no cost-based optimizer underpins the query plan like traditional SQL developers are used to. Therefore, it is important not to overstate Hive’s capabilities.
Hive does offer certain features that an RDBMS might not, though. For example, Hive supports the following complex types: structs, maps (key/value pairs), and arrays. Likewise, Hive offers native operator support for regular expressions, which is an interesting addition. HQL also offers additional extensibility by allowing MapReduce developers to plug in their own custom mappers and reducers, allowing for more advanced analysis.
The most recent and exciting developments for Hive have been the new Stinger
initiatives. Stinger has the goal of delivering 100X performance improvement to Hive plus SQL compatibility. These two features will have a profound impact on Hadoop adoption; keep them on your radar. We’ll talk more about Stinger in Chapter 2, “Microsoft’s Approach to Big Data.”
Pig
Latin. Pig is another abstraction on top of the Hadoop core. It converts the Pig Latin script into MapReduce jobs, which can then be executed against Hadoop.
Pig Latin scripts defi ne the fl ow of data through transformations and, although simple to write, can result in complex and sophisticated manipulation of data. So, even though Pig Latin is SQL-like syntactically, it is more like a SQL Server Integration Services (SSIS) Data Flow task in spirit. Pig Latin scripts can have multiple inputs, transformations, and outputs. Pig has a large number of its own built-in functions, but you can always either create your own or just “raid the piggybank” (https://cwiki.apache.org/confluence/display/PIG/PiggyBank) for community-provided functions.
As previously mentioned, Pig provides its scalability by operating in a dis-tributed mode on a Hadoop cluster. However, Pig Latin programs can also be run in a local mode. This does not use a Hadoop cluster; instead, the process-ing takes place in a sprocess-ingle local Java Virtual Machine (JVM). This is certainly advantageous for iterative development and initial prototyping.
SQOOP
SQOOP is a top-level Apache project. However, I like to think of Apache SQOOP as a glue project. It provides the vehicle to transfer data from the relational, tabular world of structured data stores to Apache Hadoop (and vice versa).
SQOOP is extensible to allow developers to create new connectors using the SQOOP application programming interface (API). This is a core part of SQOOP’s architecture, enabling a plug-and-play framework for new connectors.
SQOOP is currently going through something of a re-imagining process. As a result, there are now two versions of SQOOP. SQOOP 1 is a client application architecture that interacts directly with the Hadoop confi gurations and data-bases. SQOOP 1 also experienced a number of challenges in its development. SQOOP 2 aims to address the original design issues and starts from a server-based architecture. These are discussed in more detail later in this book.
Historically, SQL Server had SQOOP connectors that were separate downloads available from Microsoft. These have now been rolled into SQOOP 1.4 and are also included into the HDInsight Service. SQL Server Parallel Data Warehouse (PDW) has an alternative technology, Polybase, which we discuss in more detail in Chapter 10, “Data Warehouses and Hadoop Integration.”
HCatalog
14 Part I ■ What Is Big Data?
HDFS fi les can, in theory, be in any format, and the data blocks can be placed anywhere on the cluster. HCatalog provides the mechanism for mapping both the fi le formats and data locations to the tabular view of the data. Again, HCatalog is open and extensible to allow for the fact that some fi le formats may be pro-prietary. Additional coding would be required, but the fact that a fi le format in HDFS was previously unknown would not be a blocker to using HCatalog.
Apache HCatalog is technically no longer a Hadoop project. It is still an important feature, but its codebase was merged with the Hive Project early in 2013. HCatalog is built on top of the Hive and leverages its command-line interface for issuing commands against the HCatalog.
One way to think about HCatalog is as the master database for Hive. In that sense, HCatalog provides the catalog views and interfaces for your Hadoop “database.”
HBase
HBase is an interesting project because it provides NoSQL database function-ality on top of HDFS. It is also a column store, providing fast access to large quantities of data, which is often sparsely populated. HBase also offers trans-actional support to Hadoop, enabling a level of Data Modifi cation Language (DML) (that is, inserts, updates, and deletes). However, HBase does not offer a SQL interface; remember, it is part of the NoSQL family. It also does not offer a number of other RDBMS features, such as typed columns, security, enhanced data programmability features, and querying languages.
HBase is designed to work with large tables, but you are unlikely to ever see a table like this in an RDBMS (not even in a SharePoint database). HBase tables can have billions of rows, which is not uncommon these days; but in conjunction with that, those rows can have an almost limitless number of columns. In that sense, there could be millions of columns. In contrast, SQL Server is limited to 1,024 columns.
Architecturally, HBase belongs to the master/slave collection of distributed Hadoop implementations. It is also heavily reliant on Zookeeper (an Apache project we discuss shortly).
Flume
The Flume architecture consists of the following components:
■ Client
■ Source
■ Channel
■ Sink
■ Destination
Events fl ow from the client to the source. The source is the fi rst Flume compo-nent. The source inspects the event and then farms it out to one or more channels
for processing. Each channel is consumed by a sink. In Hadoop parlance, the event is “drained” by the sink. The channel provides the separation between source and sink and is also responsible for managing recovery by persisting events to the fi le system if required.
Once an event is drained, it is the sink’s responsibility to then deliver the event to the destination. There are a number of different sinks available, including an HDFS sink. For the Integration Services users out there familiar with the term backpressure, you can think of the channel as the component that handles backpressure. If the source is receiving events faster than they can be drained, it is the channel’s responsibility to grow and manage that accumulation of events.
A single pass through a source, channel, and sink is known as a hop. The components for a hop exist in a single JVM called an agent. However, Flume does not restrict the developer to a single hop. Complex multihop fl ows are perfectly possible with Flume. This includes creating fan-out and fan-in fl ows; failover routes for failed hops; and conditional, contextual routing of events. Consequently, events can be passed from agent to agent before reaching their ultimate destination.
Mahout
Mahout is all about machine learning. The goal of the project is to build scalable machine-learning libraries. The core of Apache Mahout is implemented on top of Hadoop using MapReduce. However, the project does not limit itself to that paradigm. At present, Mahout is focused on four use cases:
■ Recommendation mining: Recommendation mining is the driving force behind several recommendation engines. How many of you have seen something like this appear in your inbox: “Because you bought this New England Patriots shirt, you might also like this NFL football.”
16 Part I ■ What Is Big Data?
■ Classifi cation:Classifi cation algorithms sit on top of classifi ed documents and subsequently learn how to classify new documents. You could imagine how recruitment agents would love clustering and classifi cation for their buzzword bingo analysis. If Apache Mahout is able to reduce the number of calls received for the wrong job, that’s a win for everyone in my book.
■ Frequent item set mining: Frequent item set mining is a way to under-stand which items are often bucketed together (for example, in shopping basket analysis).
Ambari
Ambari is the system center of the Hadoop ecosystem. It provides all the provi-sioning, operational insight, and management for Hadoop clusters. Remember that Hadoop clusters can contain many hundreds or thousands of machines. Keeping them confi gured correctly is a signifi cant undertaking, and so having some tooling in this space is absolutely essential.
Ambari provides a web interface for ease of management where you can check on all the Hadoop services and core components. The same web inter-face can also be used to monitor the cluster, confi guring notifi cation alerts for health and performance conditions. Job diagnostic information is also surfaced in the web UI, helping users better understand job interdependencies, historic performance, and system trends.
Finally, Ambari can integrate with other third-party monitoring applications via its RESTful API. So when I say it is the system center of Hadoop, it literally is!
Oozie
Oozie is a Java web scheduling application for Hadoop. Often, a single job on its own does not defi ne a business process. More often than not, there is a chain of events, processing, or processes that must be initiated and completed for the result to have meaning. It is Oozie’s lot in life to provide this functionality. Simply put, Oozie can be used to compose a single container/unit of work from a collection of jobs, scripts, and programs. For those familiar with enterprise schedulers, this will be familiar territory. Oozie takes these units of work and can schedule them accordingly.
Zookeeper
Distributed applications use Zookeeper to help manage and store confi guration information. Zookeeper is interesting because it steps away from the master/ slave model seen in other areas of Hadoop and is itself a highly distributed architecture and consequently highly available. What is interesting is that it achieves this while providing a “single view of the truth” for the confi guration information data that it holds. Zookeeper is responsible for managing and medi-ating potentially confl icting updates to this information to ensure synchronized consistency across the cluster. For those of you who are familiar with manag-ing complex merge replication topologies, you know that this is no trivial task!
The Future for Hadoop
You don’t have to look too far into the future to discern the future direction of Hadoop. Alpha code and community previews are already available for Hadoop 2.0, which is fantastic to see. Aside from this, the projects we’ve talked about in the previous section continue to add new features, and so we should also expect to see new V1 distributions from the likes of Hortonworks for the foreseeable future.
Of course, one of the most exciting things to happen to Hadoop is the sup-port for Hadoop on Windows and Azure. The opsup-portunity this presents for the market cannot be overstated. Hadoop is now an option for all data professionals on all major platforms, and that is very exciting indeed.
So, what can we expect in Hadoop 2.0? Two projects that are worth highlight-ing here (at least in summary): YARN and Tez.
Summary
20 Part I ■ What Is Big Data?
Those of us who had been following Microsoft’s efforts in this space were all waiting for Microsoft to release a proprietary product for distributed scale-out compute (for example, the Microsoft Research project known as Dryad). However, it was not to be. Microsoft elected to invest in this partnership and work with the open source community to enable Hadoop to run on Windows and work with Microsoft’s tooling. It was more than a bold move. It was unprecedented. Later that week, Dave DeWitt commented in his keynote Q&A that the “mar-ket had already spoken” and had chosen Hadoop. This was a great insight into Microsoft’s rationale; they were too late to launch their own product. However, this is just the beginning of the story. Competition is rife, and although Hadoop’s core is open source, a number of proprietary products have emerged that are built on top of Hadoop. Will Microsoft ever build any proprietary components? No one knows. Importantly, though, the precedent has been set. As product companies look to monetize their investment, it seems inevitable that there will ultimately be more proprietary products built on top of Hadoop.
Microsoft’s foray into the world of big data and open source solutions (OSS) has also overlapped with the even broader, even more strategic shift in focus to the cloud with Windows Azure. This has led to some very interesting consequences for the big data strategy that would have otherwise never materialized. Have you ever considered Linux to be part of the Microsoft data platform? Neither had I!
With these thoughts in your mind, I now urge you to read on and learn more about this fascinating ecosystem. Understand Microsoft’s relationship with the open source world and get insight on your deployment choices for your Apache Hadoop cluster.
N O T E If you want to know more about project Dryad, this site provides a great starting point: http://research.microsoft.com/en-us/projects/dryad/. You will notice some uncanny similarities.
Competition in the Ecosystem
Just because Hadoop is an open source series of projects doesn’t mean for one moment that it is uncompetitive. Quite the opposite. In many ways, it is a bit like playing cards but with everyone holding an open hand; everyone can see each other’s cards. That is, until they can’t. Many systems use open source technology as part of a mix of components that blend in proprietary extensions. These proprietary elements are what closes the hand and fuels the competition. We will see an example of this later in this chapter when we look at Cloudera’s Impala technology.
on a single project or initiative. To highlight how this is all playing out, let’s focus on one area: SQL on Hadoop. No area is more hotly contested or more important to the future of adoption of a distribution than the next generation of SQL on Hadoop.
SQL on Hadoop Today
To recap what you learned in Chapter 1, “Industry Needs and Solutions”: SQL on Hadoop came into being via the Hive project. Hive abstracts away the com-plexity of MapReduce by providing a SQL-like language known as Hive Query Language (HQL). Notice that it does not suddenly mean that Hadoop observes all the ACID (atomicity, consistency, isolation, durability) rules of a transaction. It is more that Hadoop offers through Hive a querying syntax that is familiar to end users. However, you want to note that Hive works only on data that resides in Hadoop.
The challenge for Hive has always been that dependency on MapReduce. Owing to the tight coupling between the execution engine of MapReduce and the scheduling, there was no choice but to build on top of MR. However, Hadoop 2.0 and project YARN changed all that. By separating scheduling into its own project and decoupling it from execution, new possibilities have surfaced for the evolution of Hive.
Hortonworks and Stinger
Hortonworks has focused all its energy on Stinger. Stinger is not a Hadoop proj-ect as such; instead, it is an initiative to dramatically improve the performance and completeness of Hive. The goal is to speed up Hive by 100x. No mean feat. What is interesting about Stinger is that all the coding effort goes directly into the Hadoop projects. That way everyone benefi ts from the changes made. This completely aligns with Hortonworks’s commitment and charter to Hadoop.
So what is Stinger? It consists of three phases. The fi rst two phases have already been delivered.
Stinger Phase 1
Phase 1 was primarily aimed at optimizing Hive within its current architecture. Hence it was delivered in Hive 0.11 in May 2013, forming part of Hortonworks Data Platform (HDP) 1.3 release. Phase 1 delivered three changes of notable signifi cance:
22 Part I ■ What Is Big Data?
much like SQL Server’s column store technology, only the bytes from the required columns are read from HDFS; reducing I/O and again adding a further performance boost.
N O T E ORCFile stands for Optimized Record Columnar File. This fi le format allows for the data to be partitioned horizontally (rows) and vertically (columns). In essence, it’s a column store for Hadoop.
■ SQL compatibility: Decimal as a data type was introduced. Truncate was also added. Windowing functions also made the list, so Hive picked up support for RANK, LAG & LEAD, FIRST & LAST, and ROW_NUMBER in addi-tion to the OVER clause. Some improvements were also made in the core syntax, so GROUP BY allowed aliases and ALTER VIEW was also included.
■ Query and join optimizations: As with most releases of database soft-ware, query optimizations are often featured, and Hive 0.11 was no exception. Hive had two major changes in this area. The fi rst was to remove redundant operators from the plan. It had been observed that these operators could be consuming up to 10% of the CPU in simple queries. The second improvement was to JOIN operators with the de-emphasis of the MAPJOIN hint. This was in part enabled by another change, which changed the default configuration of h i v e . a u t o .convert.join to true (that is, on).
Stinger Phase 2
Phase 2 was implemented as part of Hive 0.12, which was released in October 2013. Note that this release followed only 5 months after phase 1. The community behind Stinger are moving at a fast pace.
To continue with Stinger’s three-pronged focus on speed, scale, and SQL, phase 2 also needed to cut over to Hadoop 2.0. This enabled the engineers working on Hive to leverage YARN and lay the groundwork for Tez.
N O T E Refer back to Chapter 1 for defi nitions of Hadoop projects YARN and Tez.
Phase 2 included the following enhancements:
■ SQL compatibility: Two signifi cant data types were introduced: VARCHAR
and DATE. GROUP BY support was enhanced to enable support for struct and union types. Lateral views were also extended to support an “outer” join behavior, and truncate was extended to support truncation of columns. New user-defi ned functions (UDFs) were added to work over the Binary data type. Finally partition switching entered the product courtesy of
ALTER TABLE..EXCHANGE PARTITION.
N O T E SQL Server does not support lateral views. That’s because SQL Server doesn’t support a data type for arrays and functions to interact with this type. To learn about lateral views, head over to https://cwiki.apache.org/confluence/ display/Hive/LanguageManual+LateralView.
■ End of HCatalog project: With Hive 0.12, HCatalog ceased to exist as its own project and was merged into Hive.
N O T E HCatalog is defi ned in Chapter 1.
Stinger Phase 3
Stinger phase 3 is underway, but will see Hadoop introduce Apache Tez, thus moving away from batch to a more interactive query/response engine. Vectorized queries (batch mode to SQL Server Query Processor afi cionados) and an in-memory cache are all in the pipeline. However, it is still the early days for this phase of the Stinger initiative.
Cloudera and Impala
Cloudera chose a different direction when defi ning their SQL in Hadoop strat-egy. Clearly, they saw the limitations of MapReduce and chose to implement their own engine: Impala.
Cloudera took a different approach to Hortonworks when they built Impala. In effect, they chose to sidestep the whole issue of Hadoop’s legacy with MapReduce and started over. Cloudera created three new daemons that drive Impala:
■ Impala Daemon
■ Impala Statestore
■ Impala Catalog Service
Impala Daemon
24 Part I ■ What Is Big Data?
query. As the coordinating node is decided for each query, a common single point of failure and bottleneck for a number of massively parallel-processing (MPP) systems is elegantly removed from the architecture. Note, however, that the Impala daemon you connect to when submitting your query will be the one that will take on the responsibility of acting as the coordinator. This could be load balanced by the calling application. However, it is not automatically load balanced.
Once one node has been defi ned as the coordinator, the other nodes act as workhorses performing delegated tasks on data subsets as defi ned by the coor-dinator. Each workhorse operates over data and provides interim results back to the coordinator, who will be responsible for the fi nal result set.
The Impala daemons are in constant contact with the Statestore daemon to see which nodes in the cluster are healthy and are accepting tasks.
Impala Statestore
The Statestore is another daemon known as statestored. Its job is to monitor all the Impala daemons, confi rming their availability to perform tasks and inform-ing them of the health of other Impala daemons in the cluster. It therefore helps to make sure that tasks are not assigned to a node that is currently unreachable. This is important because Impala sacrifi ces runtime resilience for speed. Unlike MapReduce, queries that experience a node failure are canceled; so, the sooner the cluster knows about an issue, the better.
Note that only one Statestore daemon is deployed on the cluster. However, this is not an availability issue per se. This process is not critical to the operation of Impala. The cluster does become susceptible to runtime stability for query operation, but does not go offl ine.
Impala Catalog Service
The Catalog Service is the third daemon and is named catalogd. Its job is to distribute metadata changes to all nodes in the cluster. Again, only one Catalog Service daemon is in operation on the cluster, and it is commonly deployed on the same node as the Statestore owing to the fact that it uses the Statestore as the vehicle for transmitting its messages to the Impala daemons.
26 Part I ■ What Is Big Data?
consider all the angles as we evaluate which is the most appropriate option for a given environment. This next section fi rst discusses a number of the consid-erations. The discussion then turns to possible topologies. Ultimately, you want a scorecard to help you make some objective decisions.
Deployment Factors
Which deployment option you choose will be dictated by several factors, many of which are intertwined like the fi bers of a shredded-wheat biscuit. It’s therefore worth keeping them all, as follows, in mind as we work through this section:
■ Elasticity
■ Flexibility
■ Scalability
■ Security
■ Proximity
■ Functionality
■ Usability
■ Manageability
Elasticity
Think of your elasticity requirement as a rubber band:
Do you need to be able to stretch your performance requirement to enable faster processing or to cope with spikes/surges in demand?
Elastic scale is the sweet spot for cloud services such as those offered by Windows Azure. I can alter the size and compute power of my cluster at will. With an on-premise service, I am always able to grow, albeit more slowly, but shrinking the topology isn’t possible. Once I’ve bought the kit, I am stuck with it for three years—even if I don’t want it any more.
Also, ask:
■ Would you like to be able to reduce your outlay/capacity when there is little or no work to do?
■ Do you know your workload and could you characterize it?
■ Is it predictable and constant, or is it volatile in nature?
■ How quickly can you scale your target environment?
■ Is this even important to you?
Flexibility
Closely tied to elasticity is the concept of fl exibility:
■ Are you sure of your processing requirements?
■ How dynamic are your requirements?
■ How complete is the vision driving your project?
■ Is it possible you may need to change your mind as you enter into a voy-age of discovery with big data?
Different models offer the opportunity for greater fl exibility in terms of dynamic change. Buying hardware also tends to be a fi xed commitment with a three-year write-down.
Scalability
You can look at the scalability factor quite simplistically and answer the follow-ing question: How many data nodes do you need?
However, this answer also drives a number of follow-up questions for you to consider:
■ Where will you put these nodes?
■ How will you manage and monitor them?
■ Who will manage and monitor them?
Because Hadoop is a scale-out architecture, the fi rst question of quantity is really a trigger point to think about the broader issues associated with the scale of the deployment. In actuality, the answer to the scale question provides additional context into the decision making of other factors, particularly fl ex-ibility and elasticity.
In terms of scale, there are also considerations that relate to limitations. For example, in HDInsight, Microsoft currently allows a maximum of 40 data nodes. However, this is merely an artifi cial cap placed on the service and can be lifted.
Architecturally no limit applies.
One might say the same about an on-premise deployment. Certainly, the largest clusters in the world are on premise. However, practicalities will often get in the way. In truth, the same challenges exist for Azure. There has to be capacity in the data center to take your request. However, I have to say, I quite like the idea of making this Microsoft’s problem.
Security
28 Part I ■ What Is Big Data?
hardware when evaluating all these options. Other options include a “secure by default” confi guration, which may well be worth replicating if you want to lock down your deployment.
Proximity
When addressing the question of proximity, you must know where the data is born. This is relevant for a number of reasons, but the prime reason is latency. We do not want the source and analytical systems to be far apart, because if they are, this distance will add latency to the analysis. That latency can often be directly correlated back to cost; a short local network can often be signifi cantly cheaper and result in less impact that than a geographically dispersed network.
The value of the insights from the data may depreciate significantly as the data ages. In these situations, therefore, we may want to keep in close proximity to the data to reduce the mean time to value when analyz-ing the data.
In addition, the farther apart the systems are, the more expensive and poten-tially brittle the networking becomes. This is especially apparent in ultra-low latency network topologies where expensive Infi niBand cables may be used to move data at signifi cant velocity. For example, FDR Infi niBand networks can move data at 56Gbps. However, that performance comes at a price, so the shorter the network cables are the better.
Consequently, and by way of simple example, if the data is born in the cloud, it will often make sense to provide analytics in the cloud. By doing so, your network will be local, and the performance between environments will be LAN Ethernet speed rather than Internet/VPN (virtual private network) speed. Your environment and total cost of ownership (TCO) will also benefi t because you will avoid data egress charges.
Functionality
Although perhaps not immediately obvious, you need to make sure that your target platform offers the functionality you want to use. Not all Hadoop distri-butions are created equally. A simple example is differing support for versions of Hive or the inclusion of HBase in a Hadoop distribution. That is not to say that you cannot add/upgrade Hadoop projects to your deployment. However, when you do this, you are stepping outside of the boundaries of the hardened distribution.