International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075,Volume-8 Issue-11, September 2019
To Explore Dynamic Misuse-ability Score using
Machine Learning Model
A.V. S. Asha, M. Srihari Varma
Abstract: Digital behavior change interventions change the inner variations of humans based on discussions international experts relates to different domains publish their data to outsourced users. User’s access data from outsourced organization then organization follow basic state space representation to give data to users. This state space representation helps to users to guide and authorizing to improve measurement of security for users to release their data. So that in this paper we present novel concept i.e. Mis-usability weight measure for estimating risk factor in exploration from digital sources of data to insiders. This theory helps to generate score which represents sensitivity of data exposed to users by predict ability of malicious exploits user’s data. Main challenge behind Mis-usability weight measure calculation is acquiring knowledge from different domain experts. Experimental results give better and efficient risk assessment results for different users in digital interventions.
Keywords: Digital behavior interventions, outsourced users data, misusability, security measures, data leakage.
I. INTRODUCTION
A focal assignment in science is the improvement and refinement of hypotheses. A cross-disciplinary agreement meaning of hypothesis is “… a lot of ideas as well as explanations which determine how portent identify with one another. Our Assumptions makes sorting out portrayal of a framework that records for clarifications and predictions phenomena."1 For wellbeing conduct change, speculations give an instrument to embody past information about how varieties in quality factors (e.g., an intercession) produce an ideal impact . The hypothesis is valuable it gives clarifications and forecasts from past work into future regions of request and use. An audit of conduct change speculations with exacting meanings of hypothesis and conduct recognized 83 speculations. Of these, lone three were made a decision to be thorough inside their degree and there was commonly poor detail, both in developing definitions and in the connections between them. Further, most social hypotheses accentuated bunch level and to a great extent static speculation, which means the hypothesis bolsters clarifications and expectations about normal changes in results in gatherings. The hypothesis additionally can possibly create experiences for explicit people, especially what may happen later on for explicit people. In a perfect world, a great hypothesis will give both gathering level and individual-level speculations. In view of general hypothesis mediations for various client's practices. The main focus on this paper is on relieving spillage or abuse episodes of information that are kept in databases (i.e., unthinkable information) by an conspirator they got real benefits about that information.
Revised Manuscript Received on September 05, 2019.
A.V.S.Asha, Department of Computer Science and Engineering S.R.K.R, Engineering College, Bhimavaram, India.
M. Srihari Varma Department of computer Science and Engineering S.R.K.R, Engineering, College, Bhimavaram, India.
There have been various endeavors manage the vindictive conspirators (i.e Insiders) situation. These strategies are contrived commonly founded on client social profiles that characterize typical client conduct and issue a caution at whatever point a client's conduct essentially digresses from the ordinary profile. The most well-known methodology for speaking to client details are by examined and put together by an end user application and connects to database. And next methodology centers around breaking down the genuine information presented to the client, i.e., the outcome sets. In any case, these type of proposed techniques consider as affectability levels of the information to which an conspirator is uncovered. In that situation, the association has to face some incredible effect while evaluating the harm whenever the information was abused. Reliable information measures including Diversity, k-Anonymity, and (α,k)- Anonymity are primarily utilized to protect saving and are not important at the point. If client wants a free access to the information, we exhibit another idea, Misuseability Weight, which allocates an affectability score to datasets. Four discretionary utilizations of the misuse ability weight are proposed: (1) applying irregularity identification by knowing the ordinary conduct of an conspirator up to his affectability information about an person is normally presented to; (2) to develop the way toward dealing with spillage episodes recognized by other abuse recognition frameworks by empowering the security official to concentrate on occurrences including progressively delicate information; (3) actualizing a dynamic misuse ability-based access control, intended to manage client access to touchy information put away in social databases; and (4) diminishing the misuse ability of the information.
II. REVIEW OF LITERATURE
Records Ranking
In this methodology, the space master is mentioned to allot an affectability score to individual records. In this way, the space master communicates the affectability level of various mixes of touchy qualities. Records Ranking [LR] handles obscure qualities well with a supposition that is made that the connections between the properties and the reliant variable are straight. Pair astute Comparison [AHP] utilizes scientific chain of importance process AHP tree structures and consequently delivers enhanced outcomes quicker. Records Ranking [CART] makes no supposition that the connections between the characteristics and the needy variable are direct and henceforth takes much time. Records Ranking [LR] and Pair astute Comparison [AHP] essentially beat the Records Ranking [CART] in master scoring and henceforth the picked method of learning model. Information gained from one master is adequate to figure the M-score for the whole space
III. MISUSEABILITY WEIGHT MEASURE
In this section, we present the procedure of the proposed approach i.e. misuse ability weight, in this we propose novel misuse ability weight measure score based algorithm. This algorithm considers and measures different misuse ability aspects of data in order to identify true events or false events of organization’s data falls with wrong user communication. Misuse ability score customized for different data sets and we cant apply for data which are not in table. i.e; different business plans and others. This score represents misuse ability weight measure of each user based on score, based on sensitive score from domain experts.
a) Basic Descriptions
[image:2.596.315.541.54.209.2]Under this segment, we state a formal definitions to the Misuseability- score. Having any loss of sweeping statement, we can expect the solitary database presists. All things considered, the measure can be effectively reached out to adapt to different databases. The formal statement of this M-Score talks about the structure squares of our measure (i.e ; qualities )DEFINITION 1. Table and Attribute. A table T(A1,…, An) is a lot of r records. Each record is a tuple of n esteems. The worth record is an incentive from a shut arrangement of qualities characterized by Ai, we can characterize Ai either as the name of the segment of record else space qualities. We demonstrate, non-meeting kinds of characteristics: semi modifier properties [15]; touchy traits; and different qualities, we don’t have any significance to our talk. For epitomize calculation of Misuseability-score, we can use this data structure of a cell organization throughout our work as spoke to in Fig. 1.
Figure 1. Representation of sensitive and quasi-identifier attribute relations.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075,Volume-8 Issue-11, September 2019
What's more, the information proprietor ought to characterize the precise setting qualities. For straightforwardness reasons, all through the paper and trials, we accepted that there is just a single setting. Be that as it may, we know about the ramifications of procuring a setting based, affectability score capacity and leave this for future work.
a) Calculating Misuse ability Measure Score Three primary elements that fuses on M-score
1. Information Quality - it means significance of the data.
2. Information Quantity – total amount of data which is uncovered.
Distinctive factor - Maintains the semi modifiers, and it can measure the attempts which requires particular elements of information table alludes to.
In this manner, RRS1 = min(0.5+1,1)=1 since, as indicated by Fig. 2, f(Account Type[Bronze])=1 and f(Average Weekly Bill[$550])=0.5. So also, RRS3 = min(0.5,1+0.3)=0.8, since f(Account Type[Gold])=0.7 and f(Average Weekly Bill[$200])=0.1).
a) Final Score
At long last, the Misuseability-score ( M-Score ) proportion of a table joins the affectability level of each individual records characterized by RS and the quantity factor (no of records in the distributed table, denoted by r). In the last advance of ascertaining the M-score, we utilize a settable parameter. So this parameter sets the significance of the amount factor inside the table last Misuseability-score( M-score ). For the higher we set to x, the lower the impact of the amount factor (total no of records in the distributed table ) on the last M-score.
Misuse ability Score r1/ x RS r1/ x max
Table 1 Sample representation of source and published table.
So as to exhibit the way toward computing the Misuse capacity score, we utilize the model displayed in sample representation of source and published table. This table includes our database tables while the right placed table is a distributed table that taken from source table. we compute Misuse capacity score.
Measuring Row Record Score
The count of record I ,(RRSi), this record score can be depends on the delicate properties considered in our pervious table settings. This M-Score of record decides the quality of information and their affectability work f,
DEFINITION 7. Consider a table with r records, In a table's M-score it is clear that : where r is the quantity of records, x is a parameter and RS is the last Record Score. For instance, for x = 5 ⇒ 1/x = 1/5, the M-score of Table 1b is, M-score (1b) = √6 × 0.2 = 1.09544. The determined M-score worth isn't limited. In this manner, it is troublesome to comprehend the importance of the determined worth and specifically the degree of risk that is reflected by the M-score esteem. Take into consideration that T is the distributed table that is inferred by making changes to the choice administrator on the source table S, on the bases of a lot of conditions, and afterward the choice administrator: T=πa1, a2… an (σ condition(S)).
Quantitative Analysis
we investigate the multifaceted nature of the Misused ability score calculation. By this reason, we consider quantity of records in the distributed table and number of records of the basic information table (source table ) are n.
Guarantee 3. The calculation intricacy of the M-score figuring of a given table is O(r×n).
Confirmation. The nature of M-score calculation is mostly influenced by three factors: the record score of each record (RRSi); the distinctive factor for every tuple of data (Di); last one was last record score. To ascertain RRSi, the affectability score capacity should be determined for every delicate property's estimation. Given an affectability score work that maps every triplet of (setting × touchy characteristic × esteem) to a score, under the assumption of the quantity of settings.
For a record I, (RRSi) decides delicate qualities score in record, with a limit 1. While contrasting two information tables and diverse qualities, while touchy ascribes are high in count it may leads to impact on every record. So as to have the option to analyze the affectability of tables having distinctive number of qualities, For instance, in Table 1b there are two delicate properties: normal month to month bill and maintain an account.
IV. EXPERIMENTAL EVALUATION
Table 2 Sample data representation for calculating misuse ability for different data sets.
Cid Name Last Name Average Bill Account
1 Ernest Velasquez 991.0 Gold
2 Wayne Guerrero 973.0 Gold
3 Mayo Share 258.0 White
4 Clint Hernandez 965.0 Silver
[image:4.596.49.307.247.490.2]As shown in table 2, it shows relevant data into publication purpose to use data event generation. This data presents the relative event generation of the each client present in systematic procedures.
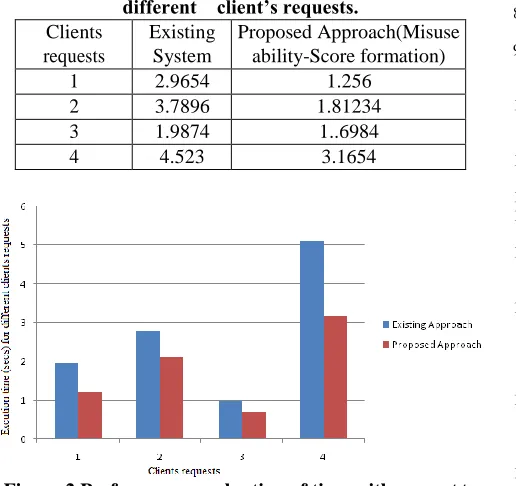
Table 3 Time efficiency of proposed approach with different client’s requests.
Clients requests
Existing System
Proposed Approach(Misuse ability-Score formation)
1 2.9654 1.256
2 3.7896 1.81234
3 1.9874 1..6984
4 4.523 3.1654
Figure 2 Performance evaluation of time with respect to client’s requests.
The above diagram shows the execution procedure for identifying quasi identifier in our presented data set by comparison of each record attribute values. [5] In this section we are measuring the each tuple space allocation. Initially it is α is greater gradually it is association with generalized values present in our data set.
V. CONCLUSION
We presented an idea of misuse ability weight furthermore, to discuss about its efficiency we estimating level of affectability of an information that an conspirator is presented to. We characterized four measurements that a misuse ability weight measure must consider. Supposedly and in view of the writing overview we stated, there is no recently proposed technique for evaluating this, abused information. Therefore, another Misuseability – score finds the M-score proposed. We broadened the Misuseability-score fundamental statement to consider earlier learning the client has able to displayed by four applications utilizing the whole encompassing definition. At last, we investigated on unique techniques on proficiently getting learning required for figuring the Misuse ability score,
objectives too..
REFERENCES
1. Michie, S., Campbell, R., Brown, J., West, RR., Gainsforth, H. ABC of Behaviour Change Theories: An essential resource for researchers, policy makers, and practitioners. London, UK: Silverback Publishing; 2014.
2. S. Mathew, M. Petropoulos, H. Q. Ngo, and S. Upadhyaya, "Data-Centric Approach to Insider Attack Detection in Database Systems," Recent Advances in Intrusion Detection, 2010.
3. L. Sweeney, "k-Anonymity: a model for protecting privacy," International Journal on
4. Uncertainty, Fuzziness and
5. Knowledge Based Systems, 10(5):571-588, 2002.
6. A. Machanavajjhala, et al., "l-diversity: Privacy beyond k-anonymity," ACM Trans. on Knowledge Discovery from Data, 1(1), 2007.
7. R. C. Wong, L. Jiuyong, A. W. Fu and W. Ke, "(α,k)-Anonymity: An Enhanced k-Anonymity Model for Privacy-Preserving Data Publishing," Knowledge Discovery and Data Mining, 2006. 8. E. Celikel, et al., "A risk management approach to RBAC," Risk and
Decision Analysis, 1(2):21–33, 2009.
9. B. Carminati, E. Ferrari, J. Cao, and K. Lee Tan, "A framework to enforce access control over data streams," ACM Trans. on Information Systems Security, 13(3), 2010.
10. Q. Yaseen, and B. Panda, "Knowledge Acquisition and Insider Threat Prediction in Relational Database Systems," Computational Science and Engineering, pages. 450-455, 2009.
11. G. B. Magklaras and S. M. Furnell, "Insider Threat Prediction Tool: Evaluating the probability of IT misuse,"
12. Computers & Security, 21(1):62-73, 2002
13. M. Bishop and C. Gates. "Defining the insider threat," Cyber Security and Information Intelligence Research, 1-3, 2008
14. C. M. Fung, K. Wang, R. Chen, and P. S. Yu, "Privacy preserving data publishing: A survey on recent developments," ACM Computing Surveys, 42(4), 2010.
15. Prestwich A, Sniehotta FF, Whittington C, Dombrowski SU, Rogers L, Michie S. Does theory influence the effectiveness of health behavior interventions? Meta-analysis. Health Psychol.
2014; 33(5):465.
http://dx.doi.org/10.1037/a0032853. [PubMed: 23730717]
16. Spruijt-Metz D, Hekler EB, Saranummi N, et al. Building new computational models to support health behavior change and maintenance: new opportunities in behavioral research. Translat Behav Med. 2015; 5(3):335–346.
17. http://dx.doi.org/10.1007/s13142-015-0324-1.
18. Yardley L, Patrick K, Choudhury T, Michie S. Current issues and future directions for research into digital behavior change interventions. Am J Prev Med. 2016.
19. Riley WT, Rivera DE, Atienza AA, Nilsen W, Allison SM, Mermelstein R. Health behavior models in the age of mobile interventions: are our theories up to the task? Translat Behav
Med. 2011; 1(1):53–71. http://dx.doi.org/10.1007/s13142-011-0021-7.
20. Nahum-Shani I, Hekler EB, Spruijt-Metz D. Building health behavior models to guide the development of just-in-time adaptive interventions: A pragmatic framework. Health Psychol. 2016; 34(Suppl):1209–1219. http://dx.doi.org/10.1037/hea0000306. 21. Christmas, S., Michie, S., West, R. Thinking about behaviour
change: an interdisciplinary dialogue. London, UK: Silverback Publishing; 2016.
22. Klasnja P, Hekler EB, Shiffman S, et al. Micro-randomized trials: An experimental design for developing just-in-time adaptive interventions. Health Psychol. 2016;
34(Suppl):1220–1228. http://dx.doi.org/10.1037/hea0000305. 23. Patrick K, Hekler EB, Estrin D, et al. Rapid rate of technological
development and its implications for research on digital health behavior interventions. Am J Prev Med. 2016
24. Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 25. 10(5):571-588, 2002.
26. Y. Yuan, et al. "Evolution of Privacy-Preserving Data Publishing," Anti Counterfeiting Security and Identification, 34-37, 2011. 27. K. LeFevre, D. DeWitt, and R. Ramakrishnan, “Workload- Aware
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075,Volume-8 Issue-11, September 2019
28. A. S. Hedayat, N. J. A. Sloane, and J. Stufken, Orthogonal Arrays - Theory and Applications. New York: Springer-Verlag, 1999. 29. L. Breiman, et al., Classification and Regression Trees. Monterey,
Calif.: Wadsworth and Brooks, 1984.
30. R Development Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org. 2010.
AUTHORS PROFILE
A.V.S.ASHA is pursing M.Tech. in department of Computer Science and Engineering, Bhimavaram, India. She did her B.Tech in GVIT Engineering College, India. This is the first paper that is going to publish by her.
M. Srihari Varma is an Assistant Professor in the Department of CSE in S.R.K.R Engineering College, India. He did his Post Graduation in M.TECH (IT) at S.R.K.R Engineering College.