International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-6, April 2019
Abstract: By taking the data contained in numerous pictures of a similar size into one composite picture is called pixel-level picture combination is perceived as having high importance in an assortment of fields, for example, therapeutic imaging, advanced photography, remote detecting, video reconnaissance, and so on. Lately, profound learning (DL) has made extraordinary progress in various PC vision and picture handling issues. The utilization of DL systems in the field of pixel-level picture combination has additionally developed as a functioning subject over the most recent couple of years. This paper is about DL-based pixel-level picture combination writing. At first we outline the principle troubles that exist in customary picture combination look into and furthermore talk about the focal points that DL can offer to address every one of these issues. At that point, the ongoing accomplishments in DL-based picture combination are audited in detail. In excess of twelve as of late proposed picture combination strategies dependent on DL procedures including convolutional neural systems (CNNs), convolutional inadequate portrayal (CSR) . Finally, by condensing the current DL-based picture combination strategies into a few nonexclusive systems and displaying a potential DL-based structure for creating target assessment measurements, we set forward certain prospects for the future investigation on this point. The key issues and difficulties that exist in every structure are talked about and we further want to give increasingly productive systems.
Index Terms: pixel level fussion, deep learning, convolution techniques, image fussion.
I. INTRODUCTION
The point of the undertaking "profound learing for pixel level picture fussion utilizing cnn and csr methods "is to create a composite picture from different information source pictures which are of same size containing correlative data of a similar scene. The information sources known as source pictures are caught from various imaging gadgets or a solitary kind of sensor under various parameter settings. The composite picture known as combined picture ought to be progressively reasonable for human or machine discernment than any individual info. Because of this preferred standpoint, picture combination procedures display extraordinary criticalness in an assortment of utilizations that realy on at least two pictures of a similar scene. For example, in restorative imaging , doctors more often than not require
Revised Manuscript Received on March 07, 2019.
Dr D. Bhavana , Deartpartment of ECE, Koneru Lakshmaiah Education Foundation, Vaddeswaram, Guntur, Andhra Pradesh, India – 522502
K.Kishore Kumar, Department of ME, Koneru Lakshmaiah Education Foundation, Vaddeswaram, Guntur, Andhra Pradesh, India – 522502 Dr.V.Rajesh, Deartpartment of ECE, Koneru Lakshmaiah Education Foundation, Vaddeswaram, Guntur, Andhra Pradesh, India – 522502 Y.S.S.S.Saketha, Deartpartment of ECE, Koneru Lakshmaiah Education Foundation, Vaddeswaram, Guntur, Andhra Pradesh, India – 522502
T.Bhargav Deartpartment of ECE, Koneru Lakshmaiah Education
Foundation, Vaddeswaram, Guntur, Andhra Pradesh, India – 522502
.
medicinal pictures gotten by various modalities including CT , attractive reverberation (MR), single photon emanation registered tomography (SPECT), and so on. In this circumstance we incorporate the imperative data taken from various source pictures into a composite picture can frequently decrease the trouble in accomplishing exact determination[1]. Another run of the mill utilization of picture combination is computerized photography, for instance changes in powerful scope of a camera. Some other mainstream situations of picture combination incorporate video observation, remote detecting, and so on. The investigation of picture combination has gone on for 30+ years, amid which several related logical papers have been distributed as of late, profound learning (DL) has met numerous precise readings in different PC vision and picture preparing issues, for example, grouping division , super-goals and so on. In the field of picture combination, the investigation dependent on profound learning has likewise turned into a functioning point in recent years. An assortment of DL-based picture combination techniques have been proposed for advanced photography (e.g., multi-center picture combination, multi-introduction picture combination) , multi-methodology imaging (e.g., medicinal picture combination, infrared/obvious picture combination) , and remote detecting symbolism (e.g., multi-ghastly (MS) and panchromatic (PAN) picture combination, MS and hyper-otherworldly (HS) picture combination) appearing over traditional strategies and prompting cutting edge results. In this paper, we will survey the ongoing advances identified with DL-based picture combination and set forward some future prospects on this theme. Various delegate review works concerning picture combination have been proposed in the writing about multi-scale deterioration (MSD)- based picture combination approaches Another persuasive overview on multi-goals picture combination . Directed a careful investigation of the target measurements utilized in combination execution assessment. gave a far reaching survey on the scanty portrayal (SR)- based picture combination strategies as of late displayed an inside and out overview about picture combination coveringmethods, target measurements and applications There are likewise emerging some reviews that focus on the combination issues in a few explicit application fields, for example, medicinal imaging , remote detecting and reconnaissance . As DL-based picture combination has quite recently been concentrated all around as of late, the related strategies are excluded in existing overviews identified with picture combination. This paper exhibits a particular audit of the ongoing accomplishments in
Deep Learning for Pixel-Level Image Fusion
using CNN
DL-based picture combination, meaning to give a far reaching presentation about the present advancement in this field [2]. Besides, we set forward a few explicit prospects for the future investigation of DL-based picture combination, planning to give some new musings to analysts in the field of picture combination.
II. MOTIVATIONS OF DL FOR IMAGE FUSION 2.1. Problems with conventional image fusion This kind of fusion techniques and target assessment measurements. In this subsection, we talk about the primary troubles that exist in these two angles separately. For better comprehension of the dialogs, some delegate strategies will be quickly presented, while progressively thorough and increasingly nitty gritty audits could through different sources .
2.1.1. Image fusion methods
In perspective on its distinctive application fields, picture combination can be sorted into various sub-issues, for example, multi-center picture combination, multi-presentation picture combination, restorative picture combination, unmistakable/infrared (IR ) picture combination, remote detecting picture combination, and so forth. Among them, remote detecting picture combination, frequently known as dish honing much of the time, has particular contrasts with alternate sorts of combination issues. Container honing demonstrates the way toward combining a low-goals MS picture and a high-goals PAN picture to get a MS picture with high spatial goals. Consequently, skillet honing can be seen as a super-goals issue for the MS picture helped by a PAN picture, and numerous strategies starting from the field of picture super-goals have been connected to remote detecting picture combination. The circumstance of MS and HS picture combination is peaceful comparative, which can be viewed as a super-goals issue for the HS picture with the assistance of the MS picture. For different kinds of picture combination issues referenced over, the jobs of source pictures are commonly proportional in the combination procedure. Albeit some broad strategies in the field of picture combination are appropriate to remote detecting picture combination, the techniques dependent on super-goals have displayed clear points of interest and most strategies as of late proposed in this field have a place with this class. Consequently, for clearness, we make a different discourse by separating picture combination strategies into two classes, in particular, general picture combination and remote detecting picture combination.
1) General picture combination
As indicated by , general picture combination techniques can be arranged into four gatherings dependent on the picture change utilized: the multi-scale disintegration (MSD)- based strategies, the meager portrayal (SR)- based techniques, the spatial area based techniques and the crossover change based strategies. The MSD-based techniques share a prominent three-stage system, to be specific, MSD disintegration, combination and MSD reproduction. Average changes utilized in MSD-based picture combination strategies incorporate picture pyramids wavelet-based changes , multi-scale geometric changes spatial separating based deteriorations and so forth [3]. In the combination stage, the
action dimension of source pictures is estimated by the deteriorated coefficients dependent on some specific pixel-or window-based methodologies. At that point, some pre-structured combination principles, for example, pick max and weighted-normal are embraced to consolidate the coefficients of various source pictures. The essential presumption in the SR-based techniques is that the action dimension of source pictures can be estimated in a meager space initially presented a SR-based multi-center picture combination strategy by means of symmetrical coordinating interest (OMP) for inadequate coding and the maximum L1 combination system for coefficient blending . From that point forward, an assortment of novel meager portrayal models and related combination procedures have been proposed for picture combination . An extensive audit about this point is given in . Not at all like the MSD-based and SR-based techniques, the spatial space based strategies achieve the combination undertaking without expressly playing out a change. A sort of famous spatial space strategies depends on picture blocking or division. In these techniques, the source pictures are first partitioned into various squares or districts utilizing some specific methodologies, for example, fixed square size setting physically or dependent on streamlining approaches quad-tree decay and division Then, the squares or areas from various source pictures at the equivalent spatial area are melded by the structured movement level estimations and combination rules. In the previous couple of years, numerous novel picture combination techniques performed on pixel space have likewise been proposed . These techniques will in general receive moderately confused combination methodologies to seek after superb combination results. The half breed change based strategies demonstrate the methodologies which at the same time apply more than one changes in the combination methodology, expecting to join the benefits of various changes. Delegate strategies have a place with this class incorporate curvelet and wavelet based technique wavelet and contourlet based strategy multi-scale change and inadequate portrayal based strategy and so forth [4].
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-6, April 2019 systems, etc. In perspective on the decided development level
estimations, the blend rule is used to choose the responsibility of each source to the merged result. Pick max and weighted-ordinary are two standard blend administers in picture mix. As pick max is just an uncommon example of weighted-ordinary, mix rule fundamentally accept the activity of weight errand. Unequivocal approachs for weight figuring join direct extent as per movement level estimations, AI based methods and so forth [5].
Another discretionary segment which additionally has a place with the extent of combination methodology is known as consistency check in picture combination. It plans to refine the determined loads based on certain priors like spatial consistency. In picture combination, consistency confirmation is regularly founded on picture sifting methods, for example, middle separating, greater part separating, little district separating, edge-protecting separating, and so forth. In this manner, the investigation on picture combination techniques comprises of a few basic segments: picture change, movement level estimation, combination rule, and so forth. To advance the improvement of picture combination, specialists attempt consistent endeavors on all the above segments by presenting progressively successful picture changes, increasingly strong action level estimations and increasingly expound combination rules. Be that as it may, in spite of the huge advancement accomplished, a few bottlenecks in this field have turned out to be progressively clear as of late. In most ordinary picture combination techniques, the above segments are planned in a manual way. Specifically, it isn't elusive that movement level estimation and combination rule are dependably the center issues which are cautiously handled in most recently proposed strategies. To seek after better execution, these issues have the pattern to end up increasingly convoluted. All things considered, because of the constraints of numerous variables, for example, usage trouble and computational cost, it is very hard to physically raise a perfect structure which completely concerns the critical issues in a combination assignment. Notwithstanding the above trouble, the absence of powerful picture changes is another test in ebb and flow picture combination examine. As is outstanding, a powerful picture change is the essential of highquality combination strategies. To an expansive degree, the advancement on picture combination is generally accomplished alongside the improvement of picture portrayal hypotheses, which makes the further enhancements for combination procedure conceivable. The changes utilized in picture combination are mostly founded on picture portrayal speculations, for example, pyramid deterioration, wavelet change, multi-scale geometric change and meager portrayal, and so forth. Be that as it may, there still exist numerous deformities in these generally advanced methodologies when utilized for picture combination . In this way, it is of dire hugeness to examine some new picture portrayal approaches which are progressively compelling for picture combination.
2) Remote detecting picture combination
Container honing techniques in the beginning period basically incorporate the segment substitution (CS)- based strategies like power tint immersion (IHS)- based ones and the vital segment investigation (PCA)- based ones, and multi-goals examination (MRA)- based techniques like wavelet change based ones and contourlet-based ones.
Be that as it may, these techniques are probably going to either experience the ill effects of serious ghostly mutilation or neglect to safeguard spatial subtleties. As of late, the modelbased techniques have turned into a predominant course in this field. In this classification of strategies, skillet honing is seen as a super-goals issue, meaning to reestablish the high-goals MS picture from the lowresolution MS picture helped by the PAN picture . Thus, pansharpening can be displayed as reverse issues and illuminated by structuring some regularization terms. Various rebuilding based skillet honing techniques have been as of late proposed dependent on Markov irregular field , variational approaches , compressive detecting, and so forth. All the more as of late, after the precedent learning based regular picture super-goals strategies, for example, the notable SR-based one , some skillet honing techniques dependent on inadequate coding with coupled word references have been proposed [6] . From a specific perspective, taking care of the issue of picture super-goals is basically building a mapping from the low-goals picture to the high-goals picture Clearly, this thought is additionally substantial for remote detecting picture combination issue which simply has diverse information and yield. Since the issue is exceedingly not well represented, this mapping relationship is probably going to be non-straight and extremely intricate, with the end goal that it is for all intents and purposes difficult to be numerically communicated. In the reclamation based strategies, this mapping is certainly acknowledged by presenting a few suspicions or priors, for example, debased model, inclination limitation, scanty imperative, and so forth. Nonetheless, because of the constraint of model multifaceted nature, it is extremely hard to take all the pivotal components into thought. In the model learning based strategies, for example, the techniques dependent on inadequate coding with couple word references, the mapping referenced above is fundamentally acknowledged through gaining from the preparation models. The execution of these strategies depends vigorously on the viability of the structured learning model which is likewise founded on some related presumptions. In this manner, in spite of the fact that these learning-based techniques are bound to accomplish higher execution, the above trouble of the reclamation based strategies still exists. By and large, the primary trouble in ordinary remote detecting picture combination strategies is that the utilized models for the most part don't have adequate portrayal capacity to describe the mind boggling mapping connection between the info (source) and focusing on (intertwined) pictures.
2.1.2. Target assessment measurements
In the primary gathering, some straightforward picture quality estimates like standard deviation, spatial recurrence and entropy are generally utilized. The measurements that have a place with the second gathering are explicit for picture combination issues and can be assembled into four classes the data hypothesis based measurements the picture highlight based measurements the picture basic comparability based measurements and the human discernment based measurements .For remote detecting picture combination, the calculation is normally tried on the misleadingly corrupted information with the goal that the first MS picture can be utilized as the reference Popular assessment measurements utilized in remote detecting picture combination incorporate root mean squared mistake (RMSE), connection coefficient (CC), unearthly edge mapper (SAM) , ERGAS , and so forth. There additionally exist some nonreference measurements for dish honing, for example, the QNR record , which comprises of an unearthly bending list and a spatial distortionindex [6].
At the point when contrasted and the exploration on combination techniques, the investigation of target assessment has gotten significantly less consideration, as it is truly not a simple assignment to build up a generally perceived combination metric. Indeed, notwithstanding for the current existing measurements referenced above, it is eccentric to state that a specific one is in every case superior to others For various picture combination applications, the fitting measurements might be extraordinary [7].
Accordingly, the target assessment of picture combination execution still remains a testing issue.
2.2. Points of interest of DL for picture combination
Inferable from the solid capacity in highlight extraction and information representation,deep learning (DL) has prompted cutting edge results in numerous PC vision and picture handling errands. In this subsection, we essentially show that picture combination can likewise profit by DL systems. Specifically, for every one of the four challenges referenced over, the particular points of interest of DL for picture combination are talked about.
For the main trouble, the famous DL demonstrate convolutional neural systems (CNNs) can give some novel approaches to contemplating picture combination techniques. This is on the grounds that some picture combination issues can be considered as grouping issues . One great model is multifocus picture combination, which is normally founded on the presumption that a nearby locale is very much centered in just a single source picture. In this manner, the issue can be normally translated as a characterization issue by choosing the very much centered one among all the source pictures. For other picture combination issues, in spite of the fact that this determination based combination methodology might be not suitable, they can in any case be displayed as order issues by characterizing each yield class as a weight task . In view of the above thought, we might want to make a progressively astute examination between picture combination and visual acknowledgment. As is outstanding, regular visual acknowledgment strategies by and large contain three significant advances, in particular, include extraction, highlight determination and expectation. It is normal to coordinate them with the three principle ventures of picture combination referenced previously. That is, the picture
change, movement level estimation and combination rule in picture combination can roughly compare to include extraction, highlight determination and forecast in visual acknowledgment, separately.
While thinking about the particular importance of each progression, the above correspondence is straightforward. It is realized that CNNs have accomplished huge advances in visual acknowledgment issues when contrasted and customary techniques since CNNs are fit for taking in the best highlights from a lot of preparing information. In this way, CNNs additionally can possibly be utilized for picture combination. The picture changes, action level estimation and combination principles (or part of them) can be mutually executed in a verifiable way through learning a convolutional arrange. The fundamental focal points of this sort of methodologies are like those of the CNNbased characterization assignments, to be specific, maintaining a strategic distance from the multifaceted nature of ordinary carefully assembled structure and being bound to get better execution.
III METHODOLOGY
3.1 Common DL strategies utilized for picture fussion :
Convolution Neutral Networks :-
Convolutional neural systems are profound fake neural systems that are utilized basically to characterize pictures (for example name what they see), group them by likeness (photograph look), and perform object acknowledgment inside scenes. They are calculations that can distinguish faces, people, road signs, tumors, platypuses and numerous different parts of visual information.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-6, April 2019 organize ingests such pictures as three separate strata of
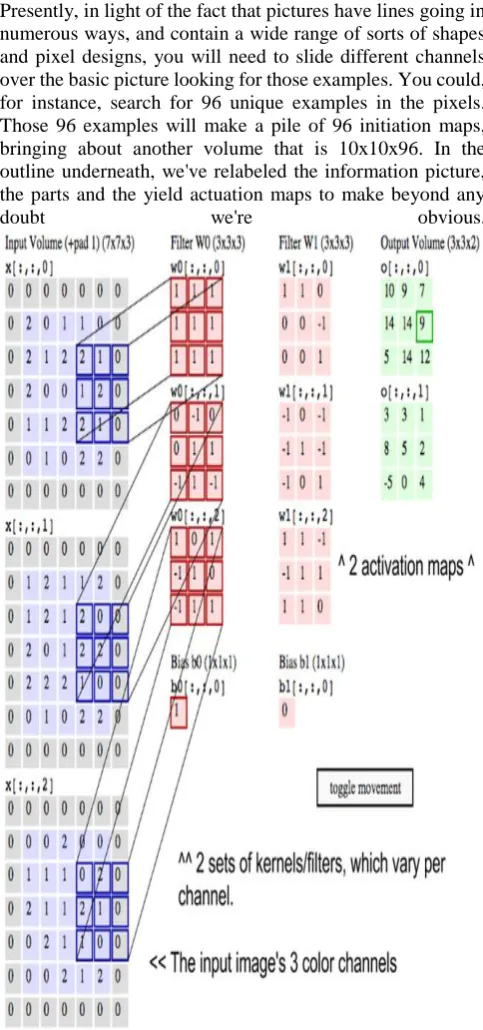
shading stacked one over the other. So a convolutional organize gets an ordinary shading picture as a rectangular box whose width and stature are estimated by the quantity of pixels along those measurements, and whose profundity is three layers profound, one for each letter in RGB. Those profundity layers are alluded to as channels. As pictures travel through a convolutional arrange, we will depict them as far as information and yield volumes, communicating them scientifically as frameworks of numerous measurements in this structure: 30x30x3. From layer to layer, their measurements change for reasons that will be clarified beneath. You should give close consideration to the exact proportions of each element of the picture volume, since they are the establishment of the direct variable based math tasks used to process pictures. Presently, for every pixel of a picture, the force of R, G and B will be communicated by a number, and that number will be a component in one of the three, stacked two-dimensional grids, which together structure the picture volume. Those numbers are the underlying, crude, tactile highlights being sustained into the convolutional organize, and the ConvNets design is to discover which of those numbers are huge signs that really help it arrange pictures all the more precisely. (Much the same as other feedforward systems we have talked about.) Instead of spotlight on one pixel at any given moment, a convolutional net takes in square fixes of pixels and goes them through a channel. That channel is likewise a square lattice littler than the picture itself, and equivalent in size to the fix. It is likewise called a portion, which will ring a chime for those acquainted with help vector machines, and the activity of the channel is to discover designs in the pixels. Credit for this great movement goes to Andrej Karpathy. Envision two grids. One is 30x30, and another is 3x3. That is, the channel covers one-hundredth of one picture channel's surface territory.
We are going to take the speck result of the channel with this fix of the picture channel. On the off chance that the two networks have high qualities in similar positions, the spot item's yield will be high. On the off chance that they don't, it will be low. Along these lines, a solitary esteem – the yield of the speck item – can disclose to us whether the pixel design in the fundamental picture coordinates the pixel design communicated by our channel.
We should envision that our channel communicates a flat line, with high qualities along its second column and low qualities in the first and third lines. Presently picture that we begin in the upper lefthand corner of the hidden picture, and we move the channel over the picture well ordered until it achieves the upper righthand corner. The measure of the progression is known as walk. You can move the channel to the correct one section at once, or you can make bigger advances.
At each progression, you take another dab item, and you place the aftereffects of that spot item in a third framework known as an enactment map. The width, or number of segments, of the actuation map is equivalent to the quantity of steps the channel takes to navigate the fundamental picture. Since bigger steps lead to less advances, a major walk will deliver a littler actuation map. This is imperative, in light of the fact that the measure of the frameworks that convolutional systems procedure and produce at each layer is specifically corresponding to how computationally costly
they are and how much time they take to prepare. A bigger walk implies less time and figure.
A channel superimposed on the initial three columns will slide crosswise over them and afterward start again with lines 4-6 of a similar picture. In the event that it has a walk of three, at that point it will create a framework of spot items that is 10x10. That equivalent channel speaking to an even line can be connected to every one of the three channels of the hidden picture, R, G and B. What's more, the three 10x10 initiation maps can be included, with the goal that the total actuation map for an even line on every one of the three channels of the fundamental picture is additionally 10x10.
Presently, in light of the fact that pictures have lines going in numerous ways, and contain a wide range of sorts of shapes and pixel designs, you will need to slide different channels over the basic picture looking for those examples. You could, for instance, search for 96 unique examples in the pixels. Those 96 examples will make a pile of 96 initiation maps, bringing about another volume that is 10x10x96. In the outline underneath, we've relabeled the information picture, the parts and the yield actuation maps to make beyond any
[image:5.595.305.547.212.728.2]doubt we're obvious.
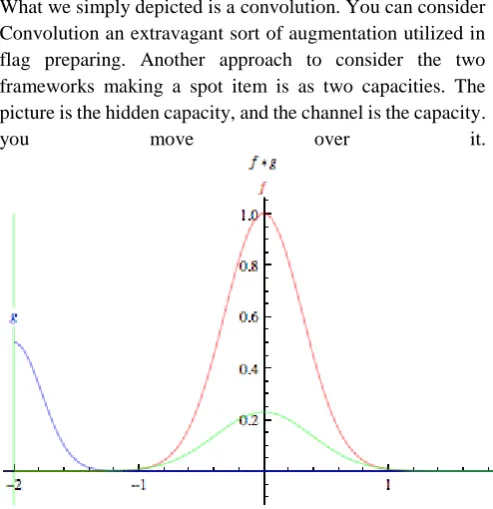
What we simply depicted is a convolution. You can consider Convolution an extravagant sort of augmentation utilized in flag preparing. Another approach to consider the two frameworks making a spot item is as two capacities. The picture is the hidden capacity, and the channel is the capacity.
[image:6.595.47.294.53.308.2]you move over it.
Fig 2 : Convolution process
One of the principle issues with pictures is that they are high-dimensional, which implies they cost a great deal of time and figuring capacity to process. Convolutional systems are intended to diminish the dimensionality of pictures in an assortment of ways. Channel walk is one approach to diminish dimensionality. Another path is through downsampling.
• Alternating Layers
[image:6.595.308.545.320.594.2]The picture underneath is another endeavor to demonstrate the grouping of changes associated with a common convolutional arrange..
Fig 3 : procedure for convolution layer arrangement
From left to right you see:
• The genuine information picture that is filtered for highlights. The light square shape is the channel that disregards it.
• Activation maps stacked on each other, one for each channel you utilize. The bigger square shape is one fix to be downsampled.
• The enactment maps dense through downsampling.
• A new arrangement of enactment maps made by disregarding channels the first downsampled stack.
• The second downsampling, which consolidates the second arrangement of initiation maps.
• A completely associated layer that characterizes yield with one name for each hub.
As more and more information is lost, the patterns processed by the convolutional net become more abstract and grow more distant from visual patterns we recognize as humans. So forgive yourself, and us, if convolutional networks do not offer easy intuitions as they grow deeper.
III. LITRATURE SURVEY
Presently multi day's numerous combination strategies are accessible in research, however every new technique dependent on the normal attributes on nuts and bolts strategy. This paper contains some essential picture combination techniques. They are IHS, PCA, BT, MRA and EMD. Here above techniques depicted in hypothetically.
A . Power Hue-Saturation (IHS) :- Image Fusion Method IHS is a typical method for melding high spatial goals, single band, container and low spatial goals, multispectral remote detecting picture. The R, G and B groups of the multispectral picture are changed into HIS parts, supplanting the force segment by the dish picture, and playing out the converse change to acquire a high spatial goals multispectral picture . HIS can upgrade spatial subtleties of the multispectral picture and improve the textural qualities of the combined, yet the combination picture exist genuine otherworldly twisting. The HIS change is utilized for geologic mapping on the grounds that the IHS change could permit assorted types of ghastly and spatial scene data to be joined into a solitary
informational index for investigation.
Fig 4 : The R, G and B multispectral image transformation
[image:6.595.47.288.513.584.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-6, April 2019 dependent on the non sub examined Contourlet change
(NSCT) and HIS accomplished expanded in holding the unearthly data and spatial subtleties and better coordination impact. With HIS change, the section based combination was grown explicitly or an unearthly attributes protecting picture blend combined with a spatial space sifting B. The Brovey Transform picture combination The BT depends on the chromaticity change. It is a straightforward technique for joining information from numerous sensors with the impediment that just three groups are included. It reason for existing is to standardize the three multispectral groups utilized for RGB show and to increase the outcome by some other wanted information to include the force or brilliance part to the picture. This method requires an accomplished investigator for the particular adjustment of parameters. This produces advancement of an easy to understand robotized apparatus. The Brovey Transform was created to stay away from the disservices of the multiplicative technique. It is a mix of number juggling tasks and standardizes the ghostly groups before they are duplicated with the panchromatic picture.
[image:7.595.303.511.235.686.2]C. Important Component Analysis PCA change is a system from measurements for streamlining an informational index. It was created by Pearson 1901 and Hotelling 1933, while the best present day reference is Jolliffe, 2002. The point of the strategy is to diminish the dimensionality of multivariate information while safeguarding however much of the important data as could be expected. It makes an interpretation of corresponded informational collection to uncorrelated dataset. PCA information are regularly more interpretable than the source information. By utilizing this technique, the excess of the picture information can be diminished. The PCA includes a scientific system that changes various related factors into various uncorrelated factors called central segments. It processes a smaller and ideal depiction of the informational collection. The primary central segment is taken to be along the course with the greatest fluctuation.
Fig 5 : dimensionality of multivariate data
The second key segment is compelled to lie in the subspace opposite of the first. Inside this subspace, this part focuses the course of greatest difference. The third central part is taken in the greatest difference heading in the subspace opposite to the first and two. The PCA is additionally called as Karhunen-Loeve change or the Hotelling change. The PCA does not have a fixed arrangement of premise vectors like FFT, DCT and wavelet and so forth. In the combination
procedure, PCA strategy produces uncorrelated pictures (PC1, PC2,… . PCn , where n is the quantity of information multispectral groups). The primary main segment (pc1) is supplanted with panchromatic band, which has higher spatial goals than the multispectral pictures. A while later, the opposite PCA change is connected to get the picture in the RGB shading model.
V. RESULTS CNN IMAGE FUSION
[image:7.595.305.510.248.370.2]Hear we took 2 sample images for the CNN mode of convolution and then observed the changes in the output image
Fig 6.1 : source image 1
Fig 6.2 : source image 2
Fig 6.3 result image
[image:7.595.51.239.570.644.2]Similar kinds of results are shown in Fig 6.4 Fig 6.5 Fig 6.6
[image:8.595.47.256.70.323.2]
Fig 6.4 source 1 Fig 6.5 Source 2
Fig 6.6 Result image
Fig 7 : output on comand window
The resultant process in the baground is shown in comand window
VI. CONCLUSION
The use of DL-based procedures to pixel-level picture combination has been advancing at a quick rate as of late. This paper reviews the ongoing advances accomplished in DL-based picture combination and puts forward some prospects for future examination in this field commitments of this work can be condensed as the accompanying three. 1. The challenges that exist in traditional picture combination examine are investigated and the benefits of DL procedures for picture combination are talked about .The pertinent troubles are condensed into four explicit focuses as far as combination strategies and target assessment measurements. For each point, the benefits of DL-based methodologies are talked about.
2. A careful diagram about the present accomplishments in DL-based picture combination is directed (Section 4). The overview covers in excess of twelve as of late proposed picture combination strategies that depend on DL methods including CNNs, CSR and SAEs. The essential thoughts, fundamental advances, explicit applications and real qualities of these strategies are presented.
3. A few prospects for the future investigation of DL-based picture combination are advanced Several conventional DL-based systems for creating general picture combination techniques, remote detecting picture combination strategies and target assessment measurements are abridged and displayed. The key issues and difficulties that exist in every structure are examined.
Taking everything into account, the ongoing advancement accomplished in DL-based picture combination shows a promising pattern in the field of picture combination with a colossal potential for future improvement. It is exceptionally expected that increasingly related examines would proceed in the coming a long time to advance the improvement of picture combination
ACKNOWLEDGMENT
The creators might want to thank the editors and unknown analysts for their adroit remarks and useful recommendations. This work is upheld by K L University and the Fundamental Research Funds for the Central Universities
REFERENCES
1. Goshtasby, A. A., & Nikolov, S. (2007). Image fusion: advances in the
state of the art. Information fusion, 2(8), 114-118.
2. Li, S., Kang, X., Fang, L., Hu, J., & Yin, H. (2017). Pixel-level image fusion: A survey of the state of the art. Information Fusion, 33, 100-112. 3. Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet
classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
4. Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3431-3440)..
5. Dong, C., Loy, C. C., He, K., & Tang, X. (2016). Image super-resolution using deep convolutional networks. IEEE transactions on pattern analysis and machine intelligence, 38(2), 295-307.
6. Dong, C., Loy, C. C., He, K., & Tang, X. (2014, September). Learning a
deep convolutional network for image super-resolution. In European
conference on computer vision (pp. 184-199). Springer, Cham.
7. Bengio, Y., Lamblin, P., Popovici, D., & Larochelle, H. (2007). Greedy
layer-wise training of deep networks. In Advances in neural information
processing systems (pp. 153-160).
8. Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., & Manzagol, P. A.
(2010). Stacked denoising autoencoders: Learning useful
representations in a deep network with a local denoising
criterion. Journal of machine learning research, 11(Dec), 3371-3408.