Rochester Institute of Technology
RIT Scholar Works
Theses Thesis/Dissertation Collections
3-2016
An Artificial Neural Networks based Temperature
Prediction Framework for Network-on-Chip based
Multicore Platform
Sandeep Aswath Narayana
Follow this and additional works at:http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please [email protected].
Recommended Citation
An Artificial Neural Networks based Temperature Prediction
Framework for Network-on-Chip based Multicore Platform
By
Sandeep Aswath Narayana
A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Electrical Engineering
Supervised by Dr. Amlan Ganguly
Department of Computer Engineering Kate Gleason College of Engineering
Rochester Institute of Technology Rochester, NY
March 2016
Approved By:
_____________________________________________________________________________________
Dr. Amlan Ganguly
Thesis Advisor – R.I.T. Dept. of Computer Engineering
_____________________________________________________________________________________
Dr. Ray Ptucha
Secondary Advisor – R.I.T. Dept. of Computer Engineering
_____________________________________________________________________________________
Dr. Mehran Mozaffari Kermani
Secondary Advisor – R.I.T. Dept. of Electrical and Microelectronic Engineering
_____________________________________________________________________________________
Dr. Sohail A. Dianat
ii
iii
Acknowledgements
iv
Abstract
v
Table of Contents
Acknowledgements ... iii
Abstract ... iv
Table of Contents ... v
List of Figures ... vi
List of Tables ... vii
Chapter 1. Introduction ... 1
1.1 Network-on-Chip (NoC) ...2
1.2 Dynamic Thermal Management (DTM) ...7
1.3 Artificial Neural Network ...8
1.4 Thesis Contribution ...10
Chapter 2. Related Work ... 12
Chapter 3. Artificial Neural Network to Predict Temperature profile in a Multi-core chip ... 15
3.1 Creating the training dataset ...16
3.2 Design of the ANN ...16
3.3 ANN hardware ...18
3.4 Evaluation of the proposed thermal ANN predictor ...20
Chapter 4. Integration of ANN based Thermal predictor with Dynamic Thermal Management ... 26
4.1 Combined Dynamic Thermal Management Scheme Coupling Task Reallocation and Rerouting ...27
4.2 Thermal Characteristics with combined DTM and ANN ...33
Chapter 5. Conclusion ... 40
vi
List of Figures
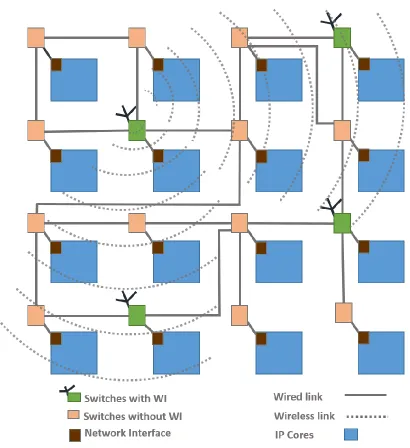
Fig. 1: Architecture for broadcast capable small-world WiNoC ...4
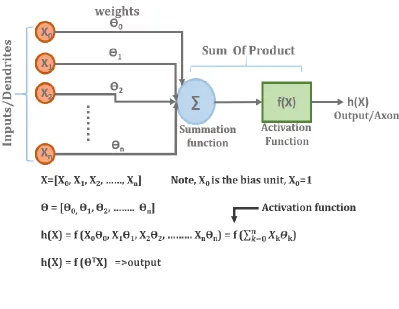
Fig. 2: Mathematical Model of a single neuron. ...9
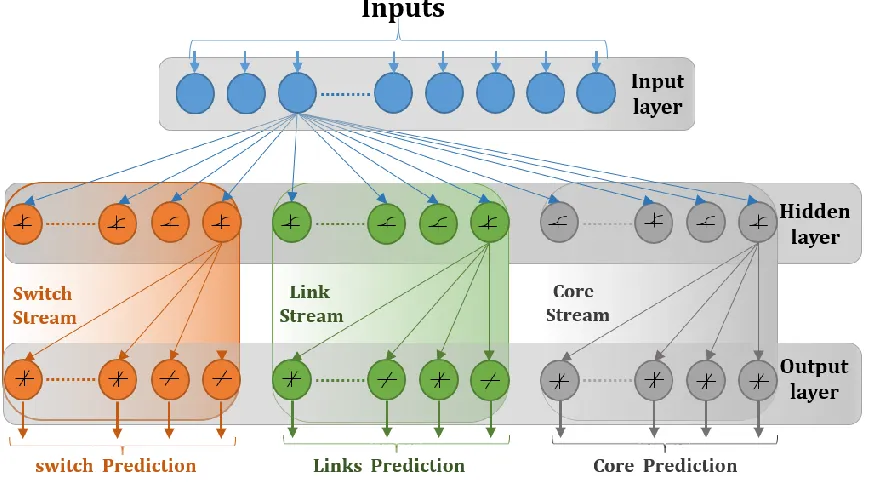
Fig. 3: Trained ANN structure. ...17
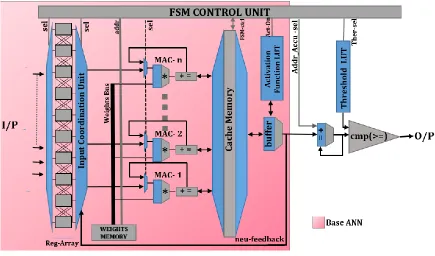
Fig. 4: ANN hardware...19
Fig. 5: Area overheads of different architectures ...24
Fig. 6: combined dynamic thermal management scheme ...28
Fig. 7: Thermal control message format ...30
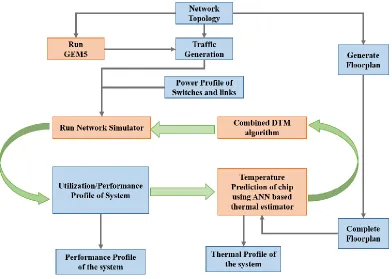
Fig. 8: Thermal profile evaluation simulation flow ...32
Fig. 9: Maximum chip temperature with and without combined DTM for (a) CANNEAL, (b) BODYTRACK, (c) VIPS, (d) DEDUP, (e) FLUIDANIMATE, (f) SWAPTION, (g) FREQMINE, (h) FFT, (i) RADIX, and (j) LU traffic...35
Fig. 10: Maximum chip temperature with and without combined DTM scheme for CANNEAL traffic running for long duration ...37
vii
List of Tables
Table I: Memory requirement for the ANN based thermal estimator ... 21
Table II: Root Mean Square Error of the ANN based predictor and event driven LUT based
thermal estimator with respect to HotSpot ... 22
1
Chapter 1.
Introduction
2
sizes and the associated computational overhead make it a non-scalable mechanism. On the other hand, Artificial Neural Networks (ANNs) have proven to be highly accurate to learn and adapt to a pattern which is used to modeling and prediction [5]. In [6], an ANN based predictor is proposed to monitor inter-core traffic congestion in a multicore chip. This thesis proposes to design an ANN based prediction engine to predict the thermal characteristics of the chip elements. The proposed ANN engine is used to trigger the DTM scheme that combines both core level and NoC level thermal management technique. Starting from Network-on-chip paradigm, this chapter discusses DTM techniques and ANN prediction engine.
1.1
Network-on-Chip (NoC)
3
control units or flits which are the smallest amount of information in a packet that can be transferred between adjacent switches in one clock cycle [34].
4
[image:12.612.114.524.181.629.2]photonic devices and integrating them with silicon-compatible circuits under area, power and delay constraints is a non-trivial challenge.
5
Multiband RF interconnects use wires as transmission lines to transfer data in the form of electromagnetic (EM) waves. The data is modulated onto a carrier using amplitude or phase shift keying [43]. Using this method of interconnection, bandwidth of conventional wires can be increased using multiple access techniques resulting in low latency data transfer at speed of light via EM waves. Multiband RF interconnects are limited by the design of high frequency oscillators and filters on the chip for the transceivers.
6
The antenna and the transceiver are the two principle components of the WiNoC architecture. The on-chip antenna for the WiNoC has to provide the best power gain for the smallest area overhead. Zig-zag antennas are non-directional and also demonstrate the characteristics of higher power gain for and smaller power gain [24]. These characteristics of the zig-zag antennas make it suitable for our application where the Wireless Interconnect (WI) attached to the Artificial Neural Network (ANN) needs to broadcast thermal control messages to all other WIs deployed in different parts of the chip. The antenna design from [9] provides a 3dB bandwidth of 16 GHz with a center frequency around 60GHz for a communication range of 20 mm which is adopted in this thesis. The quarter wave antenna uses an axial length of 0.38 mm in the silicon substrate for optimal power efficiency.
7
transmitter at a time. The token passing scheme eliminates the need for centralized control and arbitration among the transceivers, which might be located in distant parts of the die. Hence, the token passing scheme has been adopted in multiple WiNoC designs. A single-bit register in the wireless switches can denote the presence of the token at a WI to minimize the associated hardware. When this register is set, it enables that particular WI to transmit data flits over the wireless medium. When the WI is done with its transmission it passes the token to the next WI in a round robin fashion. The token flit consists of two fields, nextWI and prevWI. The prevWI denotes the ID of the WI that released the token and the nextWI denotes the ID of the WI that will possess the token next. Each WI possesses the token for a maximum period of time before releasing it to the next WI.
1.2
Dynamic Thermal Management (DTM)
8
temperature, they incur significant performance overhead. Task migration redistributes the existing processes based on the current thermal profile of the chip to reduce the peak temperature without throttling the computation. However, most of the existing task migration techniques are employed based on the temperature estimated from the thermal sensors. This makes the schemes reactive, in turn, requiring long reaction times. Moreover, the characteristics and reliability of the sensors affect the effectiveness of the scheme significantly [2]. Consequently proactive or predictive DTM mechanisms have received attention in recent times [3] [4]. In [4], a Look up Table (LUT) based thermal estimator is proposed. In such a predictor, the LUT characterizes the thermal response of the chip to the varying power dissipation profiles, which can be used to predict the future chip temperature. However, for highly scaled system sizes, the size of the LUT is very large and the associated memory requirements make it an unviable. ANNs have been known to be useful for prediction algorithms, and form a viable option for thermal estimation. In this thesis, we use an ANN based thermal estimator for reasons discussed in the following section.
1.3
Artificial Neural Network
9
First, to understand the overview of how an ANN works, consider a single neuron model as shown in the Fig.2. The dimension of the input sample is n-1 as X0 is the biased input. The weights ‘θ’ are initialized to small ± values centered on 0. When the n dimensional input (including the bias input) is sent through the ANN it is initially multiplied by its initial weights. When the weighted sum of the n dimensions exceed a threshold value then the neuron fires a floating point value which is then passed through the activation function 𝑓(𝜃T𝑋) for mapping the value to give an output. When Cost
[image:17.612.121.520.96.405.2]10
ANN to have a low cost. In the next cycle, next input is fed and simultaneously the weights are updated. The above process is recursively followed, until we have a low cost function. Multiple such neurons connected together is known as a Neural Network. The basic operation of processing the inputs to predict the output, make the ANN design easy to implement in VLSI. The detailed explanation of the ANN is given in the later section of the thesis.
1.4
Thesis Contribution
The following summarizes the contribution of this work:
1) Proposed Artificial Neural Network to Predict Temperature profile in a
Multi-core chip
a) Training dataset was collected from thermal Simulator and labeled for training of the ANN.
b) Designed an optimized ANN network with optimal latency, area, and memory requirements.
c) Evaluated the ANN on comparison look-up-table approaches
2) Integration of ANN based Thermal predictor with Dynamic Thermal
Management
11
3)
Evaluation of thermal characteristics and performance of the WiNoC withDynamic Thermal Management utilizing the proposed ANN based
12
Chapter 2.
Related Work
The problem of solving thermal hotspots prevention using Dynamic Thermal Management (DTM) of multicore system is an active researched field. Task migration redistributes existing processes to available cores based on the current thermal profile of the chip. Runtime task migration is a popular technique for reducing peak temperature. There are numerous workload migration schemes and also distributed migration schemes that are proposed in [15]. Systems with dynamic technique, respond to real-time changes and adapt to the current workload. Considering heterogeneous and morphable cores, an efficient task-mapping algorithm under power constraints is proposed in [17]. Autoregressive moving average and lookup table based thermal predictor are used in the DTM [3]. The temperature of multicore system for a user-defined threshold is controlled using convex optimization [19]. Thermal Herd, proposed in [20], provides a distributed runtime scheme for thermal management that allows NoC routers to collaboratively regulate the network temperature profile and work to avert thermal emergencies while minimizing performance impact. This work primarily targeted mesh-based wireline NoCs.
13
which can lead to online congestion and thus build on improving their ability to forecast the next hotspot occurrence in advance. In this thesis ANN based prediction engine is used in triggering a proactive DTM mechanism. The benefit of prediction based DTM approach is that it eliminated transient overshoots in temperatures as well as helps us avoid being conservative in setting maximum temperature bounds for the chips. In addition to being predictive, DTM for modern and future multicore chips must combine both core-level as well as interconnect level techniques.
14
multicore chip.In [28], effects of thermal management on wireless NoC architecture were studied. In [29], temperature aware rerouting for wireless network-on-chip is proposed.
15
Chapter 3.
Artificial Neural Network to Predict
Temperature profile in a Multi-core chip
16
3.1
Creating the training dataset
The desire to have an ANN to model the dependency between utilization of the core and NoC level components with the temperature various components of the chip (cores/switches/links), creates the necessity to generate a training dataset. The utilization of the cores are represented by the percentage utilization of the processors while the utilization of the switches are measured as the ratio of actual buffer occupancy to that of the maximum. The utilization of the links are measures at the attached switches as the ratio of the actual rate of flits transferred over the link to the maximum capacity of the link. All the utilizations are expressed as a percentage. To gather the training data, first random initializations of utilizations of core level and NoC level component is done on a cycle accurate in-house multi-core NoC simulator. The simulator is allowed to run for 3000 cycle with the initialized conditions. At the end of 3000 cycles simulator outputs the temperature change in each cycle. Similarly several random utilization conditions are initialized to the simulator, then the corresponding output temperatures are recorded as the training data. The total training data that was gathered is 3000 x 250 samples. This would help for the prediction of temperature in that particular help in the operating range of the system.
3.2
Design of the ANN
17
if the element has crossed the threshold or not. The trained ANN is a concatenation of three subdivided ANN streams. The subdivided ANN streams are Core streams, Link stream and Switch stream. The inputs to all the streams remain the same, i.e. the utilization of all the network elements and time to be predicted
[image:25.612.123.558.252.493.2]This structure of ANN results in better accuracy and decreases the number of connections between hidden layer and output layer i.e. the fully connected neurons exists only between the hidden neurons of cores and output neurons of the cores. The reduced number of connections between the hidden neurons and the output neurons decreases the latency of prediction. . The nntool box of Matlab is used to train
18
to neural network. The above Fig.3 shows the trained ANN structure. The number of hidden layer neurons used for the Cores stream is 250 whereas for the Switches and Links stream are 50 and 100 respectively. These hidden layer neurons were selected by a number of trials, resulting for the best accuracy and low latency. There were a number of experiments done using different kinds of activations function but the best accuracy was produced by using the sigmoid activation function for hidden layer and linear activation function for the output layer. To improve the latency of calculation, the number of neurons were decreased from 700 to 400. It was observed that there is negligible loss on accuracy for change in the number of neurons.
3.3
ANN hardware
19
[image:27.612.104.539.93.349.2]The number of neuron operations that are occurring in parallel are equal to the number of available MACs. As the number of MAC units that work in parallel are less than the number of inputs, we use register arrays to store the inputs. Inputs are being multiplied with the corresponding weight values that are fetched from the weight memory. The. FSM control unit synchronizes the received inputs, weights and directing these values to the right MAC unit. MAC outputs are stored in the cache. When all the connections to a particular neuron are complete then the output is passed through the activation function via buffer. The output of the LUT is feedback to the input coordination unit and REG array, only if the computation was done between first two layers (input layer and hidden layer). The process is repeated for the hidden layer and
20
the output layer. For the first iteration the predicted increase in temperature is added to the initial temperature of the chip and then accumulated. From the second iteration onwards predicted temperature is added to the accumulated result. The accumulator result is passed through a comparator, where it is compared with the threshold. The comparator outputs a single binary bit. This bit signifies that, the corresponding network element is in the 'ON' state and the zero bit signifies the ‘OFF’ state of the element. The comparator output is broadcasted wirelessly, which is used by network elements for efficient Distance Vector Routing (DVR) and Task Rerouting (TR). The ANN predicts the future temperature for a given utilization every 100,000 cycles. Hence, the bandwidth demand of these DTM related packets on the wireless interconnection is 0.054Gbps. This being a small fraction of the wireless bandwidth of 16Gbps does not significantly affect the performance. For efficient DVR and TR to be performed that results in a chip temperature less than the threshold, the 240 status bits are to be transmitted within 1,000,000 clock cycles.
3.4
Evaluation of the proposed thermal ANN predictor
21
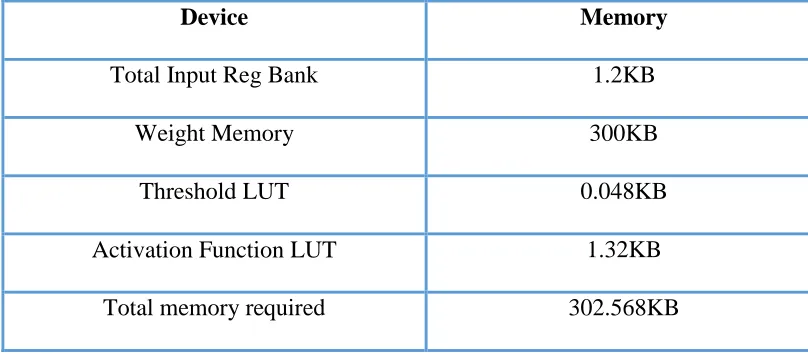
threshold value is stored on two separate LUTs. Table I shows the memory requirements for different elements of the ANN structure. In addition to the thermal estimator, the wireless transceivers required for the exchange for the thermal control flits and onchip data also require area overheads as explained next.
Table II shows the root mean square errors of the ANN and LUT-based thermal predictors with respect to the temperature traces generated using HotSpot. We have considered HotSpot as our baseline as it is a very accurate thermal modeling tool with error less than 1% [42]. A full system simulator GEM5 [35] was used to obtain the detailed processor and network-level information on SPLASH-2 [36] and PARSEC [[37] benchmarks. We consider a system of 64 alpha cores running Linux within the GEM5 platform for all experiments. The memory system is MOESI_CMP_directory, setup with private 64KB L1 instruction and data caches and a shared 64MB (1MB
Device Memory
Total Input Reg Bank 1.2KB Weight Memory 300KB
Threshold LUT 0.048KB Activation Function LUT 1.32KB
[image:29.612.123.527.234.411.2]Total memory required 302.568KB
22
distributed per core) L2 cache. The processor-level utilization statistics generated by the GEM5 simulations are incorporated into McPAT simulator [38] to determine the processor-level power statistics.
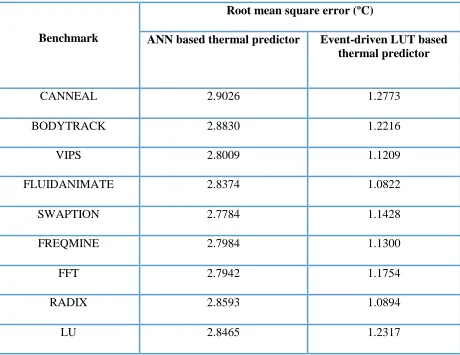
From table II, it can be seen that root mean square error for the proposed ANN based thermal predictor varies from 2.7ºC~2.9ºC whereas for the event driven LUT based predictor with fine-grained time interval (100μs), it is between 1.08ºC~1.23ºC.
Benchmark
Root mean square error (ºC)
ANN based thermal predictor Event-driven LUT based
thermal predictor
CANNEAL 2.9026 1.2773
BODYTRACK 2.8830 1.2216
VIPS 2.8009 1.1209
FLUIDANIMATE 2.8374 1.0822 SWAPTION 2.7784 1.1428 FREQMINE 2.7984 1.1300
FFT 2.7942 1.1754
RADIX 2.8593 1.0894
[image:30.612.84.544.196.551.2]LU 2.8465 1.2317
23
The ANN based prediction clearly has a greater mean square error when compared to the LUT method. This is because it is practically impossible to train the ANN for all possible input combinations. Running the ANN for input combinations that it has not yet been trained for will result in some error in its prediction. However, as the ANN has the capability to learn on its own as we keep using the ANN for thermal estimation, the mean square error will continue to reduce below the values specified in Table II.
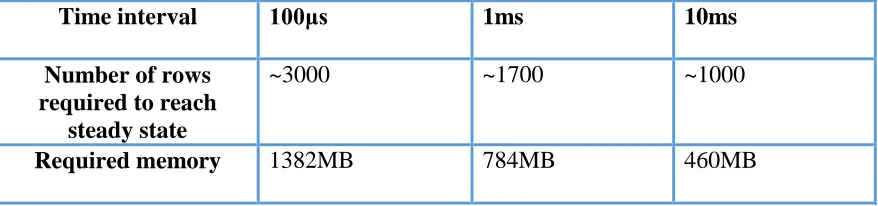
Although the LUT based thermal estimation method is more accurate it requires an impractical amount of memory storage due to large number of temperature samples it has to store. Table III shows the memory requirement for the event driven LUT based thermal estimator assuming 8 bit encoding to store the temperature values. Three different non-uniform time intervals is used to calculate the size of the LUT. This amounts to a memory requirement of 1382MB, 784MB and 460MB for time intervals of 100μs, 1ms, and 10ms respectively. Such a large memory requirement is neither practical nor scalable. On the other hand, the overheads of the ANN based predictor is
Time interval 100μs 1ms 10ms
Number of rows required to reach
steady state
~3000 ~1700 ~1000
[image:31.612.89.528.286.389.2]Required memory 1382MB 784MB 460MB
24
negligible in comparison to the LUT. Hence, we adopt the ANN-based temperature predictor for our thermal management scheme.
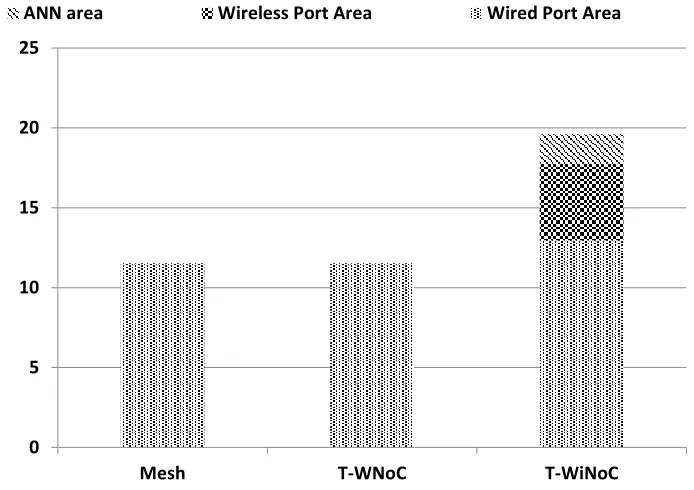
The area of a NoC switch depends on the number of ports, their virtual channels and buffer depths. On the other hand, the area of the wireless port is the total area of the transceiver circuit, antenna and the area required to buffer the wireless flits. The wireless transceiver circuits require an area of 0.3mm2 each [4] and the area of the
antennas is 0.33mm2 each. The total area for the different NoC architectures considered in this paper is shown in Fig. 18. The T-WNoC architecture contains same number of wired ports as planar mesh as they have exactly same number of links. In case of
T-Fig. 5: Area overheads of different architectures
0 5 10 15 20 25
Mesh T-WNoC T-WiNoC
A
re
a(sq
m
m
)
[image:32.612.162.509.180.425.2]25
26
Chapter 4.
Integration of ANN based Thermal
predictor with Dynamic Thermal Management
The efficiency of a Dynamic Thermal Management (DTM) scheme depends on proper thermal estimation and response delay of the control mechanism. From this viewpoint, DTM methods can be divided into two types: reactive DTM and proactive DTM. In case of reactive DTM methods, generally on-chip thermal sensor is used to sense the temperature. This allows the hardware to execute at full speed and initiate a corrective measure only when the temperature reaches a thermal limit and invokes the temperature control mechanism. However, effectiveness of such system relies on associated response delay. Due to the response delay, thermal thresholds need to be set conservatively to avoid temperature overshoot that in turn impacts system performance. Moreover, on-chip thermal sensors are sensitive to process variations and without recalibration, can report error temperatures.
27
and applied to predict the temperature at any given time based on the utilization of the chip components. The design of the ANN is explained in Chapter 3 of this thesis.
In the wireless NoC, data is transferred via wormhole routing using virtual channel (VC) based switches. Data packets are broken down and transferred in the form of flow control units or flits which are the smallest amount of information in a packet that can be transferred between adjacent switches in one clock cycle. In addition to normal VCs to transfer data flits the switches will have one reserved VC to send the utilization and routing control packets. All the switches will send link and switch packetized their activity information to their nearest WIs that in turn will send these packets to the scheduler. Based on this information, scheduler will predict the temperature using the thermal predictor to trigger the DTM scheme.
4.1
Combined Dynamic Thermal Management Scheme Coupling
Task Reallocation and Rerouting
28
[image:36.612.106.477.244.660.2]Redistributing the workload, temperature-aware task reallocation will reduce the temperature of the cores. Temperature-aware task reallocation may not reduce the network hotspots. A dynamic routing approach taking into account switch and links temperatures was proposed and investigated. The idea is to dynamically configure routing paths in response to temperature increases so that heat dissipation is distributed
29
better and points of failure are avoided in the NoC. One target temperature, Tth for
activating the combined dynamic thermal management scheme was considered. Task reallocation essentially changes the traffic among cores by redistributing tasks, triggering task-reallocation may affect rerouting decisions. For this reason, a sliding window method to trigger the combined scheme to avoid oscillation between task-reallocation and rerouting was employed. The ANN based thermal predictor described in Chapter 3, predicts component temperatures starting from next time instance to all time instances within the window. The scheduler using the combined DTM scheme activates a temperature-aware task reallocation strategy, if the predicted temperature of any core increases beyond Tth. Now, if predicted switch or link temperatures is above
Tth, then the scheduler slides the window to predict core temperature within next
window interval, and if any of the cores crosses Tth on the next window, scheduler
30
associated component has crossed the target temperature. The format of the thermal control message is shown in Fig.7.
A task reallocation heuristic that considers both temperature characteristics of the chip as well as the performance of the WiNoC is used. The Artificial neural network based thermal predictor is used to trigger the task reallocation. To evaluate resultant temperature, performance, and energy-efficiency of data communication over the T-WiNoC architecture, task reallocation heuristic with temperature aware rerouting is combined. A novel task reallocation algorithm based on future temperature trends (FTT) was proposed in [4]. It is a temperature-prioritized method where task reallocation is done such that threads with highest power consumption are allocated to either the fastest cooling or slowest heating cores. We adopt and modify this algorithm to factor in the performance of the NoC as well as temperature of the links and switches along with the temperature of the cores.
Taking into account switch and link temperatures, task reallocation is also combined with dynamic temperature aware routing approach. The temperature-aware rerouting scheme is based on adapting the Distance Vector Routing (DVR) algorithm [32] based on the Bellman-Ford equation for the NoC environment. DVR was designed to support routing under dynamic conditions in large scale networks. It is the de-facto standard for intra-domain routing over the internet where varying congestion
31
32
[image:40.612.83.475.373.652.2]DVR algorithm. In practical scenarios, the network paths using DVR eventually converge to the shortest path routing tree obtained through Dijkstra’s algorithm [32]. The old forwarding table is used till the entire network reaches convergence to avoid multiple paths between same source/destination pairs. Deadlock is avoided as at any point of time the flits are transferred over paths along the shortest path routing tree. Experimentally, it is found that a period of 600 cycles is sufficient for the entire network to converge in a 64 core system. Hence, all switches start using the new routing tables after 600 cycles after the rerouting is triggered. Switches know the exact time to start as the ANN broadcasts the time stamp of the last prediction when it sends the control flit that triggers the rerouting.
33
4.2
Thermal Characteristics with combined DTM and ANN
34
35
[image:43.612.58.537.93.562.2]The wireless transceiver adopted from [9] is designed and characterized using the Fig. 9: Maximum chip temperature with and without combined DTM for (a) CANNEAL, (b) BODYTRACK, (c) VIPS, (d) DEDUP, (e) FLUIDANIMATE, (f) SWAPTION, (g) FREQMINE, (h) FFT,
(i) RADIX, and (j) LU traffic.
0 2 4 6 8 10
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (a)
with combined DTM without combined DTM
0 5 10 15
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (b)
0 5 10 15
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (c)
0 5 10 15
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (d)
0 5 10 15 20
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (e)
0 2 4 6 8 10 12
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (f)
0 5 10 15 20 25
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (g)
0 2 4 6 8 10
64 66 68 70 72 Time (ms) M ax T em p ( °C ) (h)
0 5 10 15
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (i)
0 2 4 6 8 10 12
60 62 64 66 68 70 Time (ms) M ax T em p ( °C ) (j)
with combined DTM without combined DTM
with combined DTM without combined DTM
with combined DTM without combined DTM
with combined DTM without combined DTM
with combined DTM without combined DTM
with combined DTM without combined DTM with combined DTM without combined DTM
36
TSMC 65-nm CMOS process. This design is shown to dissipate 36.7mW for long range on-chip communication distances of the order of 20mm while sustaining a data rate of 16Gbps with a bit-error rate (BER) of less than 10-15.
The thermal profile is evaluated for the multicore chip with the T-WiNoC equipped with the combined DTM mechanism in presence of application based workloads. To evaluate the thermal characteristics of the combined DTM at high target temperature, the chip is first warmed up to 60°C. The initial task allocation is considered to be random. Although we can set any arbitrary temperature higher than ambient as target temperature, for the combined DTM, a target of 68ºC is set at the beginning of the simulation for this experiment. Fig. 9 (a), (b), (c), (d), (e), (f), (g), (h), (i), and (j) show the peak chip temperature for CANNEAL, BODYTRACK, VIPS, DEDUP, FLUIDANIMATE, SWAPTION, FREQMINE, FFT, RADIX, and LU traffic respectively.
37
components connecting those cores or the core itself can get very high compare to others creating a hotspot like behavior. As a result, redistributing traffic through cooler links/switches by bypassing hot links/switches or remapping tasks to cooler cores can obtain more uniformly distributed temperature profile on the chip.
[image:45.612.118.497.211.478.2]The effectiveness of the combined DTM is more evident from Fig. 10 where long-term transient temperature response of two systems: system with combined DTM and system with only temperature-aware rerouting are shown in presence of CANNEAL traffic. Compared to a system where combined DTM is used as thermal management policy, in a system with only temperature-aware rerouting as in [29], DTM triggers more frequently. This results in frequent oscillations in routing paths. Fig. 10: Maximum chip temperature with and without combined DTM scheme for
CANNEAL traffic running for long duration
0 2 4 6 8 10 12 14 16 18
60 62 64 66 68 70 Time (ms) M a x im u m T e m p e ra tu re ( °C )
Without combined DTM With Combined DTM
38
[image:46.612.114.524.114.429.2]This is because of the absence of core-level DTM policy. As time progresses, temperature of the cores also start to increase which in turn affect the temperature of links/switches connected with those cores. As a result, temperature of many links/switches increases relatively quickly making it difficult to find alternative paths to avoid these hot components, which in turn results in oscillation in routing paths.
Fig. 11: Transient temperature response for CANNEAL with two different target temperature
0 1 2 3 4 5 6 7 8 9 10
60 61 62 63 64 65 66 67 68 69 70
Time (ms)
Ma
x
im
u
m
T
em
p
er
a
tu
re
(
°C
)
with combined DTM; Target Temp=68
39
40
Chapter 5.
Conclusion
Thermal concerns in a multicore chip are aggravated by aggressive scaling of system size and inter-core traffic interaction over the NoC fabric. A temperature-aware predictive dynamic thermal management technique combining both task reallocation and rerouting techniques designed for the WiNoC architecture successfully restricts the temperature of the NoC components near a target threshold value. The wireless interconnection with broadcast abilities along with the prediction capability of the ANN improve the reaction time of multicore system ensuring on-chip temperatures never exceed the target threshold. Such a system can be used to design thermally efficient multicore chips with wireless NoC fabrics with minimal overhead. This design is particularly suitable for applications where the utilization of the cores and NoC components are heterogeneous where some parts are utilized to a large extent creating local thermal hotspots leaving other components relatively cooler. Under these circumstances the workload can be redistributed to relatively cooler parts dynamically to ensure a more homogeneous thermal profile.
41
Compared to the LUT based thermal estimator, the ANN requires a total memory of 302.568KB, which is 0.022% of that of a LUT based thermal estimator. It is seen that bandwidth demand of the DTM related packets on the wireless interconnection is 0.054Gbps, which is a small fraction of the overall wireless bandwidth of 16Gbps. The total area and power of 10 MAC units is found to be 1.82572 mm2 and 501.11μW respectively. The total delay in the circuit for the overall ANN architecture is 1.1226μs. Increasing the number of parallel MAC units can decrease the computational time with the tradeoff for ANN hardware area.
42
REFERENCES
[1] Intel Research, “Single-chip Cloud Computer”
http://techresearch.intel.com/ProjectDetails.aspx?Id=1.
[2] Zhang, Y.; Srivastava, A., “Accurate temperature estimation using noisy thermal sensors,” in Proc. DAC, Jul. 2009, pp. 472–477.
[3] Coskun, A.K.; Rosing, T.S.; Gross, K.C., "Utilizing Predictors for Efficient Thermal Management in Multiprocessor SoCs," in Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on , vol.28, no.10, pp.1503-1516, Oct. 2009. [4] Jin C.; Maskell, D.L., "A Fast High-Level Event-Driven Thermal Estimator for Dynamic Thermal Aware Scheduling," in Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on , vol.31, no.6, pp.904-917, June 2012. [5] Haykin, S. and Network, N., 2004. “A comprehensive foundation. Neural
Networks, 2(2004)”.
[6] Kakoulli, E.; Soteriou, V.; Theocharides, T., "Intelligent Hotspot Prediction for Network-on-Chip-Based Multicore Systems," in Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on , vol.31, no.3, pp.418-431, March 2012. [7] Benini, L., and Micheli, G.D., “Networks on Chips: A New SoC Paradigm,” IEEE
Computer, Vol. 35, Issue 1, January 2002, pp. 70-78.
43
[9] Chang, K.; Deb, S., Ganguly, A.; Yu, X.; Sah,S.P.; Pande, P.; Belzer, B,;and Heo, D.; “Performance evaluation and design trade-offs for wireless network-on-chip architectures,” J. Emerg. Technol. Comput. Syst., vol. 8, no. 3, pp. 23:1–23:25, Aug. 2012.
[10] Zhao, D; and Wang, Y; “SD-MAC: Design and Synthesis of A Hardware-Efficient Collision-Free QoS-Aware MAC Protocol for Wireless Network-on-Chip,” IEEE Transactions on Computers, vol. 57, no. 9, September 2008, pp. 1230-1245.
[11] Ganguly, A.; Chang, K.; Deb, S.; Pande, P.; Belzer, B.; and Teuscher, C.; “Scalable Hybrid Wireless Network-on-Chip Architectures for Multicore Systems,” IEEE Transactions on Computers, vol. 60, no. 10, pp. 1485–1502, 2011.
[12] Mansoor N, Ganguly A. “Reconfigurable Wireless Network-on-Chip with a Dynamic Medium Access Mechanism”. InProceedings of the 9th International Symposium on Networks-on-Chip 2015 Sep 28 (p. 13). ACM.
[13] DiTomaso, D.; Kodi, A.; Kaya, S.; Matolak, D., "iWISE: Inter-router Wireless Scalable Express Channels for Network-on-Chips (NoCs) Architecture," in High Performance Interconnects (HOTI), 2011 IEEE 19th Annual Symposium on , vol., no., pp.11-18, 24-26 Aug. 2011
44
[15] Cuesta, D.; Ayala, J.L.; Hidalgo, J.I.; Atienza, D.; Acquaviva, A.;, and Macii, E.; “Adaptive Task Migration Policies for Thermal Control in MPSoCs,” Proc. of ISVLSI
2010, pp. 110-115.
[16] Ge, T.; Malani, P.; and Qiu, Q.; “Distributed task migration for thermal management in many-core systems,” Proc. of DAC 2010, pp. 579-584.
[17] Guangshuo, L.; Jinpyo, P.; Marculescu, D., "Procrustes1: Power Constrained Performance Improvement Using Extended Maximize-Then-Swap Algorithm,"
in Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on , vol.34, no.10, pp.1664-1676, Oct. 2015
[18] Gomaa, M.; Powell, M. D.; and Vijaykumar, T. N.; “Heat-and-run: Leveraging SMT and CMP to manage power density through the operating system,” in Proc. ASPLOS, 2004, pp. 260–270.
[19] Murali, S.; Mutapcic, A.; Atienza, D.; Gupta, R.; Boyd, S.; Benini, L.; De Micheli, G., "Temperature Control of High-Performance Multi-core Platforms Using Convex Optimization," in Design, Automation and Test in Europe, 2008. DATE '08 , vol., no., pp.110-115, 10-14 March 2008
[20] Shang, L.; Peh, L.-S.; Kumar, A.; Jha, N.K.; “Temperature-Aware on-Chip Networks,” IEEE Micro: Micro’s Top Picks from Computer Architecture Conferences, 2006.
45
[22] Zhao, D.; Wang;, Y.; Li, J.; Kikkawa, T., "Design of multi-channel wireless NoC to improve on-chip communication capacity!," in Networks on Chip (NoCS), 2011 Fifth IEEE/ACM International Symposium on , vol., no., pp.177-184, 1-4 May 2011. [23] Lee, S. B. et al., “A scalable micro wireless interconnect structure for CMPs,” in
Proc. ACM Annu. Int. Con. Mobile Comput. Network. (MobiCom), 2009, pp. 20–25. [24] Lin, J. et al., “Communication Using Antennas Fabricated in Silicon Integrated
Circuits,” IEEE Journal of Solid-State Circuits, vol. 42, no. 8, August 2007, pp. 1678-1687.
[25] Deb, S.; Ganguly, A.; Pande, P.; Belzer, B.; and Heo, D.; “Wireless NoC as Interconnection Backbone for Multicore Chips: Promises and Challenges,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 2, no. 2, pp. 228–239, 2012.
[26] Murray, J; Klingner, J.; Pande, P.; and Shirazi, B.; “Sustainable Multi-Core Architecture with on-chip Wireless Links”, Proceedings of ACM Great Lake Symposium on VLSI, GLSVLSI 2012.
[27] Murray, J; Pande, P.; and Shirazi, B.; “DVFS-Enabled Sustainable Wireless NoC Architecture,” Proc. of IEEE SOC Conf., 2012.
46
[29] Shamim, M.S.; Mhatre, A.; Mansoor, N.; Ganguly, A.; Tsouri, G., "Temperature-aware wireless network-on-chip architecture," in Green Computing Conference (IGCC), 2014 International , vol., no., pp.1-10, 3-5 Nov. 2014.
[30] Watts, D.J.; and Strogatz, S. H.; “Collective dynamics of ‘small-world’ network,”
Nature, vol. 393, 1998, pp. 440-442.
[31] Petermann, T.; and De Los Rios, P.; “Spatial small-world networks: a wiring cost perspective”,2005. arXiv:cond-mat/0501420v2.
[32] Kurose, J., and K. Ross. "Computer Networking: A Top Down Approach, 4e."
Hands on 1 (2012): 1.
[33] Pei, D.; Zhang, B.; Massey, D.; Zhang, L.; “An analysis of convergence delay in path vector routing protocols”. Computer Networks. 2006 Feb 22;50(3):398-421. [34] Duato, S.; Yalamanchili, S.; and NI, L.; “Interconnection Networks-An
Engineering Approach”, Morgan Kaufmann, 2002.
[35] Binkert, N. et al, “The GEM5 Simulator,” ACM SIGARCH Computer Architecture News, 39(2), 2011, pp. 1-7.
[36] Woo S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; and Gupta, A.; “The SPLASH-2 Programs: Characterization and Methodological Considerations,” Proc. of ISCA, 1995, pp. 24-36.
[37] Bienia, C.; “Benchmarking Modern Multiprocessors,” Ph.D. Dissertation, Princeton Univ., Princeton NJ, Jan. 2011.
47
Architectures,” Proc. of the International Symposium on Microarchitecture, 2009, pp. 469-480.
[39] Pande, P; Grecu, C.; Jones, M., Ivanov, A.; Saleh, R.; "Performance evaluation and design trade-offs for network-on-chip interconnect architectures," , IEEE Transactions on Computers, vol.54, no.8, pp.1025-1040, Aug. 2005
[40] Chip MultiProjects (http://cmp.imag.fr)
[41] Mansoor, N.; Iruthayaraj, P.J.S.; Ganguly, A., "Design methodology for a robust and energy-efficient millimeter-wave wireless network-on-chip," in Multi-Scale Computing Systems, IEEE Transactions on , vol.1, no.1, pp.33-45, March 1 2015 [42] Skadron, K.; Stan, M.R.; Huang, W. ; Velusamy, S.; Sankaranarayanan, K.; and Tarjan,
D.; “Temperature-Aware Microarchitecture,” Proc. of the International Symposium on Computer Architecture, 2003, pp. 2-13.
[43] M F. Chang, el. al., "CMP network-on-chip overlaid with multi-band RF-interconnect," High Performance Computer Architecture, IEEE 14th International Symposium on , vol., no., pp.191,202, 16-20 Feb. 2008
[44] L. Shang, L. Peh, A. Kumar, and N.K. Jha, "Temperature-Aware On-Chip Networks," IEEE Micro, 2006

![Ethyl (1R,4S,5R,9S,10R,13S) 5,9,13 trimethyl 14 methylene 14 oxotetracyclo[11 2 1 01,10 04,9]hexadecane 5 carboxylate](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)