International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-2, December 2019
Map Reduce clustering in Incremental Big Data
processing
Mudassir Khan, Aadarsh Malviya, Mahtab Alam
Abstract: An advanced Incremental processing technique is planned for data examination in knowledge to have the
clustering results inform. Data is continuously arriving by
different data generating factors like social network, online shopping, sensors, e-commerce etc. [1]. On account of this Big Data the consequences of data mining applications getting stale and neglected after some time. Cloud knowledge applications regularly perform iterative calculations (e.g., PageRank) on continuously converting datasets. Though going before trainings grow Map-Reduce aimed at productive iterative calculations, it's miles also pricey to carry out a whole new big-ruler Map-Reduce iterative task near well-timed quarter new adjustments to fundamental records sets. Our usage of MapReduce keeps running [4] scheduled a big cluster of product technologies and is incredibly walkable: an ordinary Map-Reduce computation procedure several terabytes of records arranged heaps of technologies. Processor operator locates the machine clean to apply: masses of MapReduce applications, we look at that during many instances, The differences result separate a totally little part of the data set, and the recently iteratively merged nation is very near the recently met state. I2MapReduce clustering adventures this commentary to keep re-calculated by way of beginning after the before affected national [2], and by using acting incremental up-dates on the converging information. The approach facilitates in enhancing the process successively period and decreases the jogging period of stimulating the consequences of big data.
Keywords: Map reduce, Big data, Mining, Clustering, MRBGraph, Hadoop.
I. INTRODUCTION
In the usual data mining algorithm, the mining methods need computationally serious processing elements for data analysis and correlations. The computing stage remains, in this way, expected to have green [5] get entry to, at smallest, two kinds of assets, data and registering computers [3]. In Big-Data mining, realisms ruler is some partition past the limit that a singular private PC can adjust to, a standard Big Data [5] getting ready structure will rely upon cluster PCs with an absurd execution [8] figuring stage, by means of a data removal adventure, creature passed on with using management some similar indoctrination gadgets, close by Map Reduce, on a noteworthy variety of enrolling centers [3]. The job of the product issuer is to brand certain that a single [4] data mining [11] responsibility, inclusive of
Revised Manuscript Received on December 05, 2019.
Mudassir Khan,Research Scholar, Noida International University, Gr. Noida, India.
Aadarsh Malviya, Assistant Prof, Noida International University, Gr. Noida, India.
Mahtab Alam,Associate Prof, Noida International University, Gr. Noida, India.
finding the high-quality suit of a request for a record with billions of [9] statistics, is cut up into a lot of tiny duties each of which is jogging on one or more than one compute nodes. Like a [5] Large Data framework, which mixes both equipment and programming program additives, is rarely accessible deprived of key engineering stockholder’s aid [5]. In fact, for decades, agencies have been created enterprise choices founded on transaction data stored in interpersonal data sets.
A. Big data clustering
Big data technologies are significant in generous progressively precise analysis, which strength quick increasingly strong fundamental [5] initiative achieving progressively noticeable operational efficiencies, cost decreases [9], and reduce risks for the occupants. As a rule, it is alluring to intermittently revive the mining calculation so as to stay up with the resent. Major commercial [4] enterprise intelligence organizations, such as IBM, Oracle [11], and thus forth, contain every one highlighted their possess merchandise near assist clients collect and prepare these numerous information resources and manage through consumers’ existing facts to discover new bits of knowledge and exploit shrouded connections [3]. A huge number of systems have been produced for big data analysis. MapReduce is one of the simple, framework [9] used in production. Executions of Map-reduce empower [5] a considerable lot of the most widely recognized counts on enormous ruler data to be achieved on huge [8] accumulations in PCs, productively & in a method that is accepting of equipment disappointments [5] throughout the calculation [3]. Here the main focus is on improving Map Reduce technique. Incremental processing is an advanced Strategy to clean mining grades. Specified the extent of the enter gigantic information, it is actually heavy weighted to return the whole calculation starting to scrape. Incrementally handling the new information of a huge data sets collection, accepts state as certain info and consolidates it with new data [9]. Map-Reduce programming model is broadly utilized 4 enormous scale and one-time information escalated dispersed figuring, though it needs for built-in support for the iterative process [8].
B. Map reduce Background
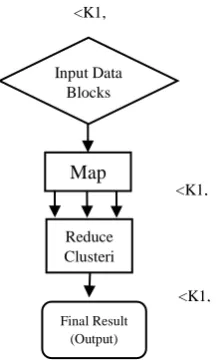
MapReduce is a [6] individual of a hopeful technique of computing that manage enormous scale calculations in a way that is tolerant of equipment shortcomings. A MapReduce fill in if all else fails area the dataset file list into self-overseeing pieces which are set up by the guide [11] undertakings in an altogether parallel way [8]. MapReduce includes two main functions, called [9] Map and Reduce. MapReduce computation is shown in Figure 1 [3]. In the Figure 1 The
harmonization of a task that perform Map or Reduce, also additionally deal through the option that such [6] a responsibility will fail to execute. These Map duties flip the bite keen on a series of key-fee pairs<K, V>. The manner key-cost pairs are created as the input records [8] be decided through the cipher written through the client used for [9] the Map characteristic [3]. Significant-price twosome from each Map strategic made by implies out of a grip controller and arranged by method for key [12]. The keys are separated amongst the majority of the decrease assignments, thus each key-cost pair through the identical key land up at the similar decrease undertaking. The decrease [6] obligations deal with each key in turn and consolidate every one of the qualities related to that key in a few ways [4]. The way of total of esteems is dictated by methods in the code made by implies out of the person for the decrease brand.
Figure 1. MapReduce clustering computation
II. LITERATURE SURVEY
A. A MapReduce - Large Cluster By using Data Processing.
For the last five years, many creators and others at Google have actualized lots of specific reasons [6] calculations that procedures massive amount of data for example, web solicitation logs, crawl data, etc. To compute various types of inferred data, for example, different representation of figure structure of web reports, generally visit question in a day, etc. [3]. Many calculations are forthright. Most of the time input data [6] is large. This data is distributed across many machines. In this system, design another reflection that permits to express the straightforward [12] calculation and attempting to perform, however, covers up the unstructured details of parallelism, data distribution and load balancing in library and fault tolerance [3]. This reflection is invigorated by the direct and decrease in various helpful lingo [4]. In this map function key/value pairs are used. Apply lessens activity for every one of the qualities that common same key, so as to consolidate the inferred information properly [9].
B. Incoop - MapReduce for Incremental Computation.
A computer system produces and collects increasing amounts [8] of data. Services for Internet company analysis to improve services [7]. Incoop system [12] is a generic framework which is based on Hadoop and use for incremental computation. Incoop can detect changes to the input data and enable the automatic updates of the output by
reusing mechanism of fine-grain incremental processing [4]. There are two case studies of higher-level services that are: i) additional doubt ii) Log Processing System without changing a single line of code of application input data it improves the significant performance of results.
C. Map Reduce in Big Data Mining
Big Data stands huge measure of information. Enormous data, software where material accumulation takes established ceaselessly, it is expensive to get, extricate & oversee and [10] procedure data utilizing existing programming devices. For instance, Forecasting of climate, Electricity Supply, Social media. By expanding the size [12] of information in data distribution center it is costly to perform a data investigation. Data 3D square generally unique and condense databases [3]. It is a method for organizing data in various n measurements for [6] examination on some proportion of intrigue. For data, preparing Big data handling structure, transfer on group PCs and parallel execution system given by the Map-Reduce. D. Iterative dispensation
Range of dispensing outline stake again occurred for huge facts Preparing. Help Loop improves the proficiency of the iterative calculation with the guide of way of assembly the project scheduler circle cognizant and through utilizing storing systems [13]. Twister utilizes a light-weight [6] unvaried MapReduce runtime gadget by means of reasonably fabricating a Reduce-to-Map circle. IMap Reduce helps unvaried procedure by recommending that of prompt passing the slice back yields to Map and with the aid of distinguishing variation nation statistics from the static facts [7].
E. One-step application in Incremental processing. Besides In coop, numerous latest research purpose in helping development system for simple method packages [8]. In-coop sanity adjustment of efforts& allow the automated inform of the crops by means of using a well-organized, nice-driven outcome recycles instrument [4]. The development landscape of facts proposes that performance huge-rule additional development in enhancing performance melodramatically. Than In-coop helps clean mission-degree development system. Thus, In-coop assure now not allow for reusing the huge current ignoble of Map-Reduce plans [4]. In-coop arrangements best, the straightforward calculation [8].
F. Iterative application in incremental processing. Naiad proposes an auspicious data flow world view that permits stateful calculation and self-firm developed cycles. To help steady iterative calculation, software engineers should completely revise their Map-Reduce bundles aimed at Naiad. Popular correlation, we broaden [7] generally utilized Map-Reduce adaptation for steady iterative scheming. Existing MapReduce projects might remain scarcely different toward keeping running on [8] i2MapReduce aimed at gradual handling.
G. IMapReduce: Framework for Iterative Computation in distributed Computing.
Relational records pervasive in maximum of the programs together with a social network analysis and statistics mining. These relational data [3] containing at the least thousands and thousands and masses of relations. This want to dispense computing frameworks for processing this information on big cluster [12].
An Example of one of these frameworks is MapReduce.
<K1, V1>
Input Data Blocks
Map
<K1, V2> Reduce
Clusteri ng
Final Result (Output)
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-2, December 2019
This paper presents I MapReduce, a system that supports iterative handling. Clients are getting the permit by indicating the iterative activities with guide and lessen capacities [8].
III. PROBLEM DESCRIPTION
Numerous online information collections develop gradually after some period as innovative sections stand gradually included and existing passages stand erased otherwise altered. Exploiting this instrumentality, [10] frameworks for steady mass information handling, for example, Social Network Datasets, Google‟s coffee pot, will accomplish effective updates. This proficiency, be that because it might, come at the value of behind similarity with the fundamental encoding model obtainable by non-gradual [3] frameworks, e.g., Map Reduce, grouping also every one additional critically, needs the developer to execute application-explicit dynamic/steady calculations, eventually increasing calculation and code complexnes [12].
The undertaking level coarse-grain steady preparing framework, Incoop, isn't openly accessible. In this manner, we can't come close i2MapReduce with In coop [7]. Instead, we compare i2MapReduce with an existing MapReduce model on Hadoop.
IV. EXISTING SYSTEM
Various past considers have pursued this guideline and planned new programming [8] models to help active process. Tragically, the modern calculation model is definitely entirely unexpected from MapReduce, expecting developers to [12] totally re-execute their calculations [3]. On the contrary hand, Incoop stretch absent Map Reduce towards the assisting dynamic procedure. Exist to as it might, it's 2 principle confinements [4]. To begin with, Incoop underpins exclusively task level dynamic procedure. That is, it spares and reuse state at the coarseness of [7] solitary Map and cut back endeavors. Every assignment ordinarily forms a curiously higher assortment of key-regard sets (kv-sets). If Incoop distinguishes some data change inside the donation of an assignment, it'll rerun the total errand. Though this methodology just use active [4] MapReduce choices for situation investment means, it ought to cause a larger than average amount of the recurring estimate if exclusively a tiny low portion of kv-sets have adjusted in an exceedingly task. moment, Incoop bolsters exclusively traditional dancing calculation, [12] while crucial mining calculations, similar to Page Rank, need tedious computation. Incoop would view every accentuation as an alternate MapReduce work.
A. Disadvantages of Existing system
a. The existing system [10] cannot give promising output, which enough for working in the Big Data.
b. The update of any data will result in re-run the complete setup.
c. It does support no more than task-level additional dispensation [12].
d. It does support only one-step computation.
V. PROPOSED SYSTEM
The proposed i2 MapReduce, and expansion towards MapReduce bunching so as to chains well-particle gradual
preparing to use for together individual-advance also constant figuring. Diverged from past plans, i2MapReduce joins the going with three novel features:
A. Cluster Configuration
The entirety of the ventures was executed on a bundle that included generally [12]1800 equipment. Every mechanism has two 2GHz Intel Xeon processors with Hyper-stringing enabled, 4 GB of recollection [10], 160 GB IDE circles, and a gigabit Ether interface. The equipment be engineered at a 2 - steps 3 - wrought traded framework through around 100-200 Gbps of all out information move limit open on the basis. The whole of the equipment was in the proportional encouraging workplace with accordingly the around excursion time among some pair of machinery not really a flash.
Out of the 4GB of memory, around 1-1.5GB was [8] held by various assignments running on the gathering. The undertakings were executed on a week's end [7] evening, when the CPUs, plates, and framework were generally inert.
B. Fine-grain incremental processing using MRBG-Store:
Unlike In coop, i2 Map Reduce underpins kv-pair level fine-grain steady handling so as to limit the life of recompilation but very much like may fairly be expected [11]. The model the kv-pair stage information stream and statistics reliance in a very Map scale back calculation as a binary diagram, referred a to as MRB Graph.
C. Broadly helpful iterative count with humble development to MapReduce API
Our gift proposition provides broadly speaking helpful facilitate [8], as well as coordinated, nonetheless additionally one or many and many-to-various association. Improve the Map API to modify purchasers to effortlessly specific circle invariant organization data, and propose a [10] development API capability to precise [7] the communication starting cut back to Map. Whereas purchasers have to be compelled to fairly alter their calculation so as to exploit i2 Map Reduce.
D. Incremental processing for iterative computation Steadily iterative getting ready is basically a great deal of testing than a moderate one-advance technique considering the strategy that even scarcely any updates could impel to affect a colossal area of change states once totally various cycles. To deal with this problem, this research proposes to use again the consolidated condition of the past estimation and utilize a correction proliferation control (CPC) system. Additionally, upgrade the MRBG-Store [10] to more readily bolster the entrance designs in steady iterative handling [12].
E. Store - MRBG
The MRBG-Store bolsters the protection and recovery of well-particle MRBGraphstates for steady preparing. The client sees two fundamental prerequisites on the MRBG-amass [13]. To begin with, the MRBG-amass should gradually amass the developing MRBGraph. Believe a succession of occupations so as to steadily invigorate the aftereffects of a major information removal calculation. As info information develops, the middle of the road starts in the MRBGraph will likewise advance. It is inefficient to store the whole MRBGraph of
get and store just the refreshed piece of the MRBGraph. Next, the MRGB-Store have to bolster effective recovery of saved states by giving Reduce examples. For gradual Reduce calculation [9], i2MapReduce re-figures the Reduce case related by means of each misshapen MRBGraph border. For a distorted border [10], it inquiries the MRGB-amass towards recovering the protected condition of the in-limits of the related K2, and union the saved state through the recently figured border change as shown in figure 2.
Figure 2: MRBG Store
F. MRBG ARCHITECTURE
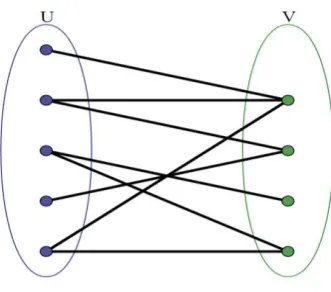
[image:4.595.316.541.385.602.2]Bipartite Graph: - a bipartite diagram (or history) is a chart [7] whose vertices can be partitioned into two disjoint sets U and V (that is, U and V are every free set) with the end goal that each edge associates a vertex in U to one in V as appeared in figure 3. Vertex set U and V are frequently signified as patient set. Comparably, a bipartite chart is a diagram that doesn't contain any odd-length cycles. The two sets U and V might be thought of as a shading of the diagram with two hues: in the event that one shading all hubs in U blue, and all hubs in V green, each edge have endpoints of contrasting hues, as is required in the chart shading issue. One regularly composes G= (U, V, E) to mean a bipartite chart whose segment has the parts U and V, with E indicating the edges of the diagram [13]. On the off chance that a bipartite chart isn't associated, it might have more than one bipartisan; for this situation, the (U, V, E) [10] documentation is useful in determining one specific bipartisan that might be of significance in an application. In the event that |U| and |V|, that is, in the event that the two subsets have equivalent cardinality, at that point G is known as a decent bipartite diagram. On the off chance that all vertices on a similar side of the bipartisan have a similar degree, at that point G is called unpredictable [13].
Figure 3: Bipartite Graph G. MRBG Dataflow
MRB GraphAbstraction
The client utilizes a MRBGraph reflection to demonstrate the information stream in MapReduce. Every apex in the Map task speaks to a person Map work call occasion on a couple of (K1, V 1). Every apex in the decrease task speaks to a [7] individual Reduce work call example of a gathering of (K2, {V 2}). An edging starting a Map case to a decrease case implies that the Map example produces a (K2, V 2) so as to is rearranged towards turn out to be a piece of the contribution to the decrease occasion. The contribution of Reduce occasion an originates from Map occurrence 0, 2, and 4. MRB Graph limits be the well-particle states M that the client might want to safeguard for steady preparing. An border contain three snippets of data: (I) the foundation Map in additional information obtaining can fundamentally spare the assets used for information assortment; it doesn't re-catch the entire information collection yet just re-catch the modifications while the past period that information be caught [13]. Position, (ii) the goal decrease occasion (as recognized with K2), and (iii) the edge esteem (for example V 2). Because Map input key K1 may not be extraordinary, i2MapReduce creates an all inclusive special Map key MK for each Map example. In this manner, [7] i2MapReduce will safeguard (K2, MK, V2) for every MRBGraph border as shown in figure 4.
Figure 4: Data Flow of MRBGraph.
VI. IMPLEMENTATION
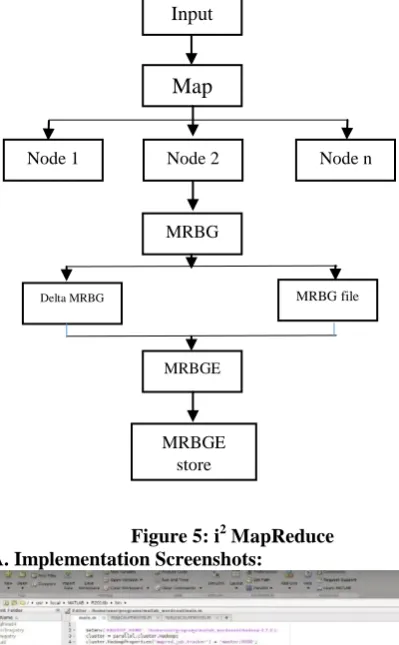
Approach of proposed works in the accompanying way: Stage 1: Assortment of advancing informer indexes, The developing informational indexes will be gathered for map and decrease.
Stage 2: Improvement of map procedure, The map [10] strategies will be created and the information determination is map utilizing these map systems as shown in figure 5 using the concept of MRBG.
Stage 3: Advancement of decrease procedure, The decrease strategies will be created and
the mapped information will be
MRB Graph File MRBGStore Merge
Read
Cache Append Buffer
Chunk 0 (k2a, {MK+, V+,a})
Chunk 1 (k2b, {MK+, V+,b})
Chunk 2 (k2c, {MK+, V+,c})
…………..
Read Window
K2a K2b K2c …..
K2b MK2 K2c MK7 V27,c
….
Data MRBGraph (from incrementalprocessing)
Main Memory
[image:4.595.85.251.646.792.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-2, December 2019
diminished utilizing these decrease methods.
Stage 4: Implementation of PageRank and K-means algorithm and GIM-V:
[image:5.595.52.252.110.433.2]Stage 5: Result Analysis and Comparison.
[image:5.595.320.533.201.335.2]Figure 5: i2 MapReduce A. Implementation Screenshots:
Figure 6: Algorithm Query in MRBG-Store main program clustering
K means is a normally utilized combination estimate that bundles centers into k packs. Customer demonstrate the ID of a point as paid, and its component [7] standards pval. The calculation begins with choosing k irregular focuses as group centuries set {CID, CVAL}. As appeared in 3rd method, in every emphasis, the Map case scheduled a aim paid doles out the aim to the closest centroid [13]. The decrease occurrence on a centric CID refreshes the centric by balancing the estimations of every single relegated point {pval}.
Figure 6.1: Map reduce
Piece of paper position is a notable dull diagram estimate of position surface. It registers a positioning achieve for every apex in a chart [11]. In the wake of introducing every single positioning score, the calculation plays out a Map Reduce work for each emphasis. I also j is apex ids, Ni is the arrangement of out-relate apex of I, RI are I' is positioning achieve so as to is refreshed interactively [13]. '|' Means connection. Every RI is being introduced to one 2. The decrease example resting on apex j refreshes Rj by adding the Ri,j got Applying the damping factor d from all its neighbors.
Figure 6.2: Reduce Count word
B. 4th Algorithm MapReduce in GIM-V
[image:5.595.315.545.606.838.2]GIM-V duplication (GIM-V) is a reflection of numerous dull chart removal tasks. These diagram removal calculations can be commonly spoken to by working on n × n grid M including apex v of size n. Assume together the framework alsp the vector is partitioned into sub-squares. Allow mi,j indicate the (I, j)- th square of M and vj signify the j-th square of v. The calculation techniques are like individuals of the network vector augmentation and can be preoccupied into three activities: (1) mvi,j = merge 2(mi,j ,vj); (2) v′i = join All i({mvi,j}); also (3) vi = assigns (vi, v′ i).User can contrast merge 2 with the duplication among mi,j and vj , and contrast consolidate All with the entirety of mvi,j for push I. Calculation 4 explains the MapReduce usage through 2 employments for every cycle. The primary occupation allocates vector square vj to numerous lattice squares mi,j (∀i) and achieve merge 2 (mi, j, VJ) to acquire mvi, j. The subsequent activity bunches the mvi, j and VI on a similar I, plays out the join All ({mvi,j}) activity, & new technique [7] VI utilizes allot (vi, v′ i ).
Figure 6.3: Output – 1 Hadoop Properties Node 2 Node n
Node 1
Input
Map
MRBG
Delta MRBG MRBG file
MRBGE
[image:5.595.67.274.636.766.2]Figure 6.4: Output – 2 Scheduler Metrics
Figure 6.5: Output 3 – Schedular Metrics C. Advantages of the Proposed System
I. To the extent anybody is worried, i2MapReduce is the first MapReduce base arrangement so as to proficiently bolsters steady iterative calculation.
II. AMRBG Store is expected to defend the well-particle state in the MRB Graph and reinforce gainful request to recoup well-particle states for steady handling [11].
III. Dissimilar to In coop, i2MapReduce bolsters kv-pair level fine-grain steady handling so as The present recommendation gives extensively valuable assistance, including direction to restrict the proportion of re-computation anyway much as could be normal [13]. IV. The present suggestion gives comprehensively valuable help, including facilitated, yet in addition, one-to-many, many-to-one, and many-to-numerous correspondence [11]. V. Client update the Map API to enable customers to viably articulate round invariant organization data, and customer proposes a [7] Project API ability to express the messages from slice back to the Map.
VI. Even as customers need to possibly change their estimations so as to exploit i2MapReduce, such alteration is modest stood out from the push to re-actualize counts on an absolutely remarkable programming perspective [13]. VII. Usher proposes to reprocess the joined condition of the past computation and use a change proliferation control segment.
D. Disadvantages of the Proposed System
Following slighter Numeral of Situation kv-pair. Certain techniques, the quantity of state keys is less than n. K implies, is an extraordinary case with just a solitary state kv-pair. In these techniques, the all out size of the state information is regularly very little [13]. In this manner, the regressive exchange overhead is low. Under such circumstance, i2MapReduce doesn't have any significant bearing the above parcel capacities. Rather, it segments the structure kv-sets utilizing MapReduce‟s [11] Default strategy, while imitating the state actualities to each segment.
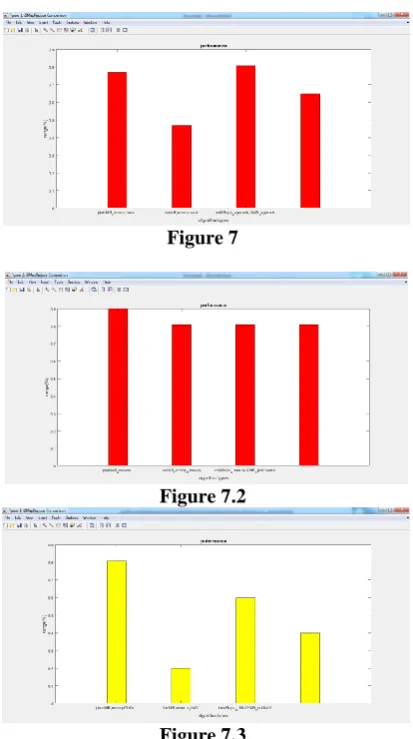
VII. EXPERIMENTAL RESULTS AND ANALYSIS
[image:6.595.325.532.148.518.2]After implementing the programming models on three different raw data sets, the result obtained for k-means algorithm, PageRank algorithm and GIM-V, is depicted in figure6 [13]. It shows the performance [11] analysis of i2mapreduce k-means algorithm, PageRank algorithm and GIM-V i.e., shows the decrease in time consumed with respect to i2mapreduce model compared to that of MapReduce model.
Figure 7
Figure 7.2
Figure 7.3
Figure 7.1, 7.2 and 7.3: PageRank, K-means and GIM-V Algorithm Performance analysis using i2MapReduce.
VIII. CONCLUSION AND FUTURE ENHANCEMENT
We have defined I2MapReduce-Acceptable Ounce Incremental Dispensation based completely on MapReduce outline. Helps k/v couple degree exceptional-ounce incremental dispensation to decrease the quantity of recompilation & MRBG-Stock to help capable quires for retrieving best-grain states for gradual handling and to keep the first-class-ounce conditions in MRBG This outline syndicates a best-modicum improve the machine, [7] a trendy-motive iterative perfect, and a usual of actual systems aimed at better-ounce incremental iterative calculation. Physical-device researches display that I2MapReduce container, drastically lessen the track period to refresh big data removal result as related to re-calculate on together simple MapReduce. We are reading value-conscious execution optimization that intelligently [13] makes use of the MRB Graph country and
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-2, December 2019
analysis.In destiny, we're seeking to identify the information changes on every occasion, there's a dynamic updating using FP algorithm. Though retrieval of statistics becomes easier with map reduce, the interdependence of map and decrease responsibilities requires extra fault tolerance. So, we [7] are focusing on proper fault tolerance solutions by using analyzing, and experimenting with numerous computing frameworks like PageRank, k-means, GIM-V etc.. We propose that array based languages, like R are ideal to express these algorithms for processing bigdata
REFERENCES
1. Khan, M. and D. B. Kalra (2018). "AN INSPECTION ON BIG DATA COMPUTING."
2. International Journal of Engineering & Science Research(Special Issue/Article No-52): 326-329.
3. Yanfeng Zhang, Shimin Chen, Qiang Wang, and Ge Yu, Member, IEEE, “i2MapReduce: Incremental MapReduce for Mining Evolving Big Data” IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 27, NO. 7, JULY 2015.
4. Shivaram Venkataraman,Indrajit Roy Alvin and Au Young Robert S. Schreiber,” Using R for Iterative and Incremental Processing,” in HotCloud'12 Proceedings of the 4th USENIX conference on Hot Topics in Cloud Ccomputing Pages 11-11 - 2015.
5. D. G. Murray, F. McSherry, R. Isaacs, M. Isard, P. Barham, and M. Abadi, Naiad: A timely dataflow system, in Proc. 24th ACM Symp. Oper. Syst. Principles, 2013, pp. 439455.
6. C. Yan, X. Yang, Z. Yu, M. Li, and X. Li, “IncMR: Incremental data processing based on mapreduce,” in Proc. IEEE 5th Int. Conf. Cloud Computing., 2012, pp. 534–541.
7. S. R. Mihaylov, Z. G. Ives, and S. Guha, Rex: Recursive, deltabased, data-centric computation, in Proc. VLDB Endowment, 2012, vol. 5, no. 11, pp. 12801291
8. Y. Zhang, Q. Gao, L. Gao, and C. Wang, “imapreduce: A distributed computing framework for iterative computation,” J. Grid Computing., vol. 10, no. 1, pp. 47–68, 2012.
9. P. Bhatotia, A. Wieder, R. Rodrigues, U. A. Acar, and R. Pasquin, “Incoop: Mapreduce for incremental computations,” in Proc. 2nd ACM Symp. Cloud Computing., 2011, pp. 7:1–7:14.
10.J. Ekanayake, H. Li, B. Zhang, T. Gunarathne, S.-H. Bae, J. Qiu, and G. Fox, “Twister: A runtime for iterative mapreduce,” in Proc. 19th ACM Symp. High Performance Distributed Computing., 2010, pp. 810–818.
11.D. Peng and F. Dabek, “Large-scale incremental processing using distributed transactions and notifications,” in Proc. 9thUSENIX Conf. Oper.
12.J. Ekanayake, H. Li, B. Zhang, T. Gunarathne, S.-H. Bae, J. Qiu, and G. Fox, “Twister: A runtime for iterative mapreduce,” in Proc. 19th ACM Symp. High Performance Distributed Computing., 2010, pp. 810–818.
13.J. Dean and S. Ghemawat, “Mapreduce: Simplified data processing on large clusters,” in Proc. 6th Conf.Symp. Opear. Syst. Des. Implementation, 2004, p. 10.