Volume: 03 Issue: 07 | July-2016 www.irjet.net p-ISSN: 2395-0072
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1002
Efficient Data Mining With The Help Of Fuzzy Set Operations
Anchutai H. More
1, Prof.R.S.Shishupal
21
Dept. of Computer Engineering Sinhgad Institute of technology, Lonavala
2
Dept. of Computer Engineering Sinhgad Institute of technology, Lonavala
---***--- Abstract:
Association rule mining is a key issue in data mining. However, the classical models ignore the distinction between the transactions, and therefore the weighted association rule mining doesn't work on databases with solely binary attributes, during this paper, we introduce a brand new live w-support, that doesn't need preassigned weights. However, there square measure several real-life things in which ones square measure unsure concerning the content of transactions. Two novel quality measures are proposed to drive the IWI mining process. Besides, two algorithm that perform IWI and Minimal IWI mining efficiently, determine
Keywords—Data mining, Data mining, association rule, fuzzy frequent pattern growth, and frequent item set
mining, Clustering, classification.
1.
Introduction
ASSOCIATION rule mining ambitions to explore huge transaction databases for association policies, which may display the implicit relationships the various information attributes. It has become a thriving research subject matter in facts mining and has numerous sensible packages, which include move advertising, classification, textual content mining, net log analysis, and advice structures.[9]
ITEMSET mining is an exploratory data mining method broadly utilized for finding profitable relationships among information.
Data mining is an approach for the extraction of new learning from data.[1] For studies that belong to the performance category, the central query considered is how to compute the frequent patterns as efficaciously as feasible, studies in this class attention on rapid Apriori-based totally algorithms as well as overall performance enhancement strategies to those Apriori-based totally algorithms (e.g., hashing and segmentation. word that the various algorithms in those classes of research are Apriori-based. They rely upon a generate-and-test paradigm. In different words, they compute common styles through generating applicants and checking their guide (i.e., their occurrences) in opposition to the transaction database.[10]
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1003
event of an item set in a given transaction is weighted by theheaviness of the most interesting item set. Note that, when managing streamlining issues, minimum and maximum are the most usually utilized cost capacities. Consequently, they are deem suitable for driving the determination of a beneficial subset of infrequent weighted data correlation. Specifically, the accompanying issues have been tended:
A. IWI and Minimal IWI mining driven by a maximum
IWI-support-min threshold, and
B. IWI and Minimal IWI mining driven by a maximum
IWI-support-max threshold.
Task (A) involves finding IWIs and minimal IWIs (MIWIs) which incorporate the item(s) with the minimum local interest
inside of every transaction.
Task(B) involves finding IWIs and MIWIs which incorporate item(s) having maximal nearby enthusiasm inside every transaction by misusing the IWI-support max measure.
For algorithm this term, lengthy expression are there, to over come this draw back author proposed the fuzzy set mining. To find infrequent mining. To mining the item set association rule is used, in that FP-Growth is applied, to mining the frequent patterns and sort infrequent one.Fuzzy Frequent Pattern development (FFP-Growth) to get from fuzzy association rules. At to start with, we apply fuzzy partiton method and choose a participation capacity of quantitative quality for every transaction item. Next, we execute FFP-Growth to manage the procedure of information mining. Furthermore, so as to comprehend the effect of Apriori algorithm and FFP-Growth algorithm on the execution time and the quantity of created affiliation manages, the analysis
will be performed by utilizing diverse sizes of databases and edges. In conclusion, the test results show FFP-Growth algorithm is more effective than other existing systems.
In this paper further we will see: Section II talks about related work studied till now on topic. Section III current implementation details, introductory definitions.
2.RELATED WORK
In this section discuss existing work done by the researchers for text mining process.
In this paper [1], author has Frequent weighted itemsets speak to connections much of the time holding in data in which things might weight in an unexpected way. In any case, in a few settings, e.g., when the need is to minimize a specific cost capacity, finding uncommon data relationships is more intriguing than mining continuous ones. This paper handles the issue of finding infrequent and weighted itemsets, i.e., the rare weighted itemset (IWI) mining issue. Two novel quality measures are proposed to drive the IWI mining process. Moreover, two algorithm that perform IWI and Minimal IWI mining efficiently, determined by the proposed measures, are displayed. Trial results show efficiency and viability of the proposed approach.
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1004
actualize FFP-growth to manage the procedure ofinformation mining. What's more, all together to comprehend the effect of Apriori calculation and FFP-development algorithm on the execution time and the quantity of created association rules, the trial will be performed by utilizing distinctive sizes of databases and limits. In conclusion, the investigation results s how FFP- growth calculation is more effective than other existing methods.
In this paper [3], author, Itemset mining is an data mining strategy extensively utilized for learning essential connections among data. The point of Association Rule Mining is to discover the connection between information Items in view of recurrence of event Infrequent Itemset mining is a variety of continuous itemset mining where it finds the uninteresting examples i.e., it finds the information things which happens once in a while. Considering weight for each particular things in an exchange free way includes adequacy for finding continuous itemset mining. This paper concentrate on survey different Existing Algorithms identified with successive and rare itemset mining which makes a way for future looks into in the field of Association Rule Mining. Watchwords: Clustering, affiliation principle, weighted thing, rare itemset mining, weight, Correlation.
In this paper [4], author says When we examine positive and negative affiliation runs all the while, occasional itemsets turn out to be critical in light of the fact that there are numerous esteemed negative affiliation rules in them. Nonetheless, how to find rare itemsets is still an open issue. In this paper, we propose a various level least backings (MLMS) model to compel occasional itemsets and successive itemsets by giving deferent least backings to itemsets with deferent length. We contrast the MLMS model and the current models. We additionally plan a calculation
Apriori_MLMS to find all the while both successive and occasional itemsets in view of MLMS model. The test results and examinations demonstrate the legitimacy of the calculation.
In this paper [5], author has Probabilistic successive itemset mining in dubious trans-activity databases semantically and computationally diers from customary procedures connected to standard \certain" exchange databases. The thought of existential un-sureness of item(sets), showing the likelihood that an item(set) happens in an exchange, makes customary techniques inapplicable. In this paper, we present new probabilistic definitions of incessant itemsets in view of conceivable world semantics.In this probabilistic connection, an itemset X is called incessant if the likelihood that X happens in at slightest minSup exchanges is over a given limit . To the best of our insight, this is the rst approach advertisement dressing this issue under conceivable universes semantics. In thought of the probabilistic definitions, we exhibit a structure which can tackle the Probabilistic Frequent Itemset Mining (PFIM) issue eficiently. A broad exploratory assessment researches the effect of our master postured methods and demonstrates that our methodology is requests of size quicker than straight-forward methodologies
In this paper [6], author says,We think about the issue of mining successive itemsets from un- certain information under a probabilistic structure . We consider exchanges whose things are connected with existential probabilities and give a formal meaning of successive examples under such a dubious information model. We demonstrate that customary calculations for mining continuous itemsets are either inapplicable or computationally wasteful under such a model. A information trimming system is proposed to enhance mining productivity. Through broad examinations,
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1005
we demonstrate that the information trimming techniquecan accomplish critical investment funds in both CPU expense and I/O cost.
3.Implementation detailes
In this section discussed about the proposed system in detail. In this section discuss the system overview in detail, proposed algorithm, mathematical model of the proposed system,
4.System Overview
The following figure 1 shows the architectural view of the proposed system. The description of the system is as follows:
Figure 1: System Architecture
In the proposed system initially input is a Iris Dataset .Given a weighted value-based information set and a greatest
IWI-support (IWI-IWI-support min or IWI-IWI-support max) threshold
,the Minimal Infrequent Weighted Itemset Miner algorithm separates all the MIWIs that fulfill
.The pseudo code of theMIWI Miner algorithm is comparable to the one of IWI Miner, reported in Algorithm 1. Consequently, because of space imperatives, the pseudo code is most certainly not reported. Be that as it may, in the accompanying, the fundamental contrasts regarding IWI Miner are delineated. At line 10 of Algorithm 1, the MIWI Mining technique is summoned rather than IWI Mining. The MIWI Mining methodology is like IWI Mining. Nonetheless, since MIWI Miner concentrates on creating just negligible rare examples, the recursive extraction in the MIWI Mining technique is stopped as soon as an infrequent itemset occurs. Indeed, at whatever point an occasional itemset I is found, every one of its augmentations are not negligible. These Existing system hav many mathematical calculations and the system is slow down because of calculating complexity. To overcome this issue ,in proposed system, author introduced fuzzy Fp-growth. Because of the growth in data innovation has been quickly created, it makes data and administration in database be more imperative. As of late, expansive database and information distribution center are connected tremendously. By and large exchanges, gigantic information should be investigated, including helpful data and information. By every exchange record, we can hunt down the connection among one and another. This segment clarifies that how FFP-growth algorithm can be connected onto awesome exchange database and mine helpful data. Moreover, it permits chiefs or organizations execute awesome promoting procedures or business sector arranging.
5.Algorithm System Algorithm
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1006
Input: T, a weighted transactional Dataset.
, amaximum IWI-support threshold.Output: f, the set of IWIs satisfying
.Process:
Step 1: f = 0.
Step 2: countItemset IWI-support(T).
Step 3: Tree
a new empty FP-treeStep 4: for all weighted transaction tr in T do.
Step 5: TEq
Equivqlent tej in TEq doStep 6: for all transaction tej in TEq do
Step 7: insert tej in tree
Step 8: end for
Step 9 end for
Step 10: f
IWI mining(Tree,
,
null
)Step 11: return f
Algorithm 2: IWIMining(Tree,
,prefix)Input: Tree, a FP-tree
, a maximum IWI-support thresholdOutput: f , the set of IWIs extending prefix
Process:
Step 1: f = 0
Step 2: for all item I in the header table of tree do
Step 3: I = prefix
{i}Step 4: If IWI-support( I )
thenStep 5: F
F
{i}Step 6: end if
Step 7: condPatterns
generateConditionalPatterns.Step 8: Tree1 = create FP-tree(condPatterns)
Step 9: prunable Items
identifyPrunableItem (Tree1,
)Step 10: Tree
prunelIemset(Tree1, prunables items)Step 11: If Tree
0Step 12: F
F
IWIMining (Tree,
,I)Step 13:end if
Step 14: end for
Step 15: return F
6.Mathematical Model
The system S is represented as:
S= {D,I, F, T, P, O, M}(1)
Input
Input m = {D} (2)
Where D = Iris Dataset.(Real life data set).
Process
F = FP Growth algorithm
T= {t1, t2, t3... tn}
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1007
Where, T is the transaction containing I number of Itemsets.I = {i1,i2……in}
Where, I is the set of items I n each transactions.
M = IWI- support
Where, M is to calculate IWI-support min mining
Also IWI-support max mining.
IWI-support (I,T) =
(
,
).
) ( |
q t IS I T t
f
I
t
W
q q
Output
Output O = Frequent Itemset.
P= frequent patterns set.
7.Experimental Setup
The system is built using Java framework (version jdk 8) on Windows platform. The Netbeans (version 8.1) is used as a development tool. The system doesn’t require any specific hardware to run; any standard machine is capable of running the application.
8.Result and descussion
DataSet
Iris Dataset. This dataset contain numeric value for items. Contain 200 transaction of different length.
Results
In this paper we find the frequent itemsets. In this project test start the algorithm by initialing parameters, let m =4,
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1008
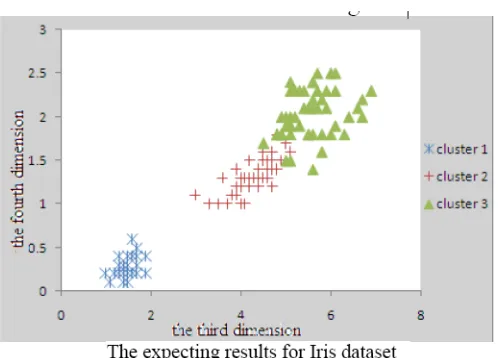
Figure 3: Expecting result for Iris datasetFigure 3: The Result with infrequent weight model on iris dataset
9.Conclusion and future scope
This paper faces the issue of finding Infrequent itemsets by utilizing weights for separating between important things and not inside of every exchange. Two FPGrowth-like
algorithm that achieve IWI and MIWI mining efficiently. The value of the found examples has been approved on information coming from a genuine setting with the assistance of an area maste. The fundamental accentuation of this paper is to propose a fuzzy data mining using so as to mine strategy to discover fuzzy association rules the fuzzy segment system and FP-growth. The components the proposed system exhibits are that it doesn't have to create applicant itemsets and enhances the productivity of dull database examining.
Presently, our system generates infrequent itemsets, in future it maintains the accuracy for mining frequent itemsets.
References
[1] “Infrequent Weighted Itemset Mining Using Frequent Pattern Growth”,Luca Cagliero and Paolo Garza, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 4, APRIL 2014
[2] “Applying Fuzzy FP-Growth to Mine Fuzzy Association Rules”, Chien-Hua Wang, Wei-Hsuan Lee, Chin-Tzong Pang,
[3] A. Gupta, A. Mittal, and A. Bhattacharya, “Minimally Infrequent Itemset Mining Using Pattern-Growth Paradigm and Residual Trees,” Proc. Int’l Conf. Management of Data (COMAD), pp. 57-68,2011.
[4] X. Dong, Z. Zheng, Z. Niu, and Q. Jia, “Mining Infrequent Itemsets Based on Multiple Level Minimum Supports,” Proc. Second Int’l Conf. Innovative Computing, Information and Control (ICICIC ’07), pp. 528-531, 2007.
[5] T. Bernecker, H.-P. Kriegel, M. Renz, F. Verhein, and A. Zuefle, “Probabilistic Frequent Itemset Mining in Uncertain Databases,” Proc. 15th ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining (KDD ’09), pp. 119-128, 2009
[6] C.-K. Chui, B. Kao, and E. Hung, “Mining Frequent Itemsets Uncertain Data,” Proc. 11th Pacific-Asia Conf. Advances in Knowledge Discovery and Data Mining (PAKDD ’07), pp. 47-58, 2007.
[7]D.J. Haglin and A.M. Manning, “On Minimal Infrequent Itemset Mining,” Proc. Int’l Conf. Data Mining (DMIN ’07), pp. 141-147,2007.
[8]X. Dong, Z. Zheng, Z. Niu, and Q. Jia, “Mining Infrequent Itemsets Based on Multiple Level Minimum Supports,” Proc. SecondInt’l Conf. Innovative Computing, Information and Control (ICICIC’07), pp. 528-531, 2007.
© 2016, IRJET | Impact Factor value: 4.45 | ISO 9001:2008 Certified Journal
| Page 1009
[9]K. Sun and F. Bai, “Mining Weighted Association RulesWithout Preassigned Weights,” IEEE Trans. Knowledge and Data Eng., vol. 20, no. 4, pp. 489-495, Apr. 2008.
[10]C.K.-S. Leung, C.L. Carmichael, and B. Hao, “Efficient Mining of Frequent Patterns from Uncertain Data,” Proc. Seventh IEEE Int’l Conf. Data Mining Workshops (ICDMW ’07), pp. 489-494, 2007.