3879
DATAMINING BASED MULTIMODE APPROACH FOR
ESTIMATING THE RISK UNDER HEART FAILURE CASES
#1SYED UMAR#2 G. SRIDEVI #3YERRAGUDIPADU SUBBARAYUDU
#4N. YOGENDER NATH
#1Professor, Department Of Computer Science Engineering, MLR Institute of Technology, Hyderabad
#2Professor, Department Of Computer Science Engineering, Malla Reddy Institute of Technology,
Hyderabad
#3Assistant Professor, Department Of Computer Science Engineering, IARE, Hyderabad
#4Assistant Professor,, Department Of Computer Science Engineering, MLR Institute of Technology,
Hyderabad
ABSTRACT
Predictive modelling solutions difficult to assess the risks in the health information technology. People to work longer is the integration of clinical researchers from different areas in different parts of the doctor. Some pages are thick in general, varied and meaningful change over time. Parallel construction tools large data tools can be built and called the doctor can help clinical decisions. In this article, we combine a multi-model forecasts to a new approach to the predictive power of many multi-models to better predict. We show the effectiveness and efficiency of the creative work of the heart study. The results showed that the idea of a predictive model multi-architecture method is better than the best. With modelling errors of prediction models, we can select a group structure that offers value. Further details are made at different levels in the extraction system, resulting in a greater accuracy of the predictions.
Keywords: Multi node model, Clustering, Hadoop.
1. INTRODUCTION
If clinical and pharmaceutical data-intensive environment. Many details, such as the patient history, scan history clinical laboratory tests and hospital administrative data are used for routine [1] Instead, the digitization of early clinical data in the form of a computer disk as physical files. This information may be different from the system in different geographic regions. 80% of the clinical relevance of unstructured data [2]. These data are as EMR (electronic medical records) stored in multiple files, and laboratory and clinical scanned imaging system are preserved in the file, there is a medical certificate, medical information, and notes, CRM (clinical data management) systems and cash. Patient care can be significantly improved by increasing the progress of the useful data to analyse the system and analyse these data in clinical synthesis. The digitization of medical records to reduce healthcare costs and reduce errors blocks. But the amount of data presents new challenges. The information gathered doctors often overloaded from a variety of tools and information that not a
Great show. Site medical care and service. The challenge is to simply search the patient and synthesize information, and help doctors make clinical decisions. The challenge is to work with heterogeneous integration of clinical data, the figures do not mean that the standards and the data for data. Visualization of data and the concept of health because of the large amounts of complex data in this category and every day. These data are difficult to handle the software and hardware. Under the information and insights by analysing large pieces of data can occur at lower cost. The doctor and the doctor is able to make better decisions thanks to remove the explosion of intimidation for his knowledge of the data, [2] and thus make great applications research topics in analytical data and current employment trends. he intensive use of distributed processing model data applications. Apache Hadoop Map Reduce framework and processing of such data applications. Azure HD Insight software provides a framework that allows you to manage, monitor and report. Providing deployment Hadoop cluster
infrastructure. Hadoop provides software
applications using the following Hadoop
3880 analyse at the same time, the data stored in the distribution system. Today it is one of the leading causes of death in 65 heart failure [3]. Let our attention to include 1500 patients with more than 14 and a correct model of about 82%. Here, 25 types of the same process, the same amount of data, 86% accurate. This demonstrates the effectiveness of our values. The strength of the book is divided into the following sections: In this section, we will explain that the recommendation of the new legislation, a thorough discussion of the necessary multi-award winning model standard parts, the effectiveness of the approach with several models investigating the cause work now that the students discussed joint portion,
2. LITERATURE SURVEY
Much research has been done in the field of health. There is a large amount of data. This data may grow rapidly, in terms of size, complexity, and the production speed. [4] This article provides an overview of the different algorithms 1994-2013 as essential for a large amount of data. Definition of state method based on the image point [5]. It can be combined to collect patient data from various clinical sources in three steps 1); 2) indicates the type of health problem, provided that the results and the history and sources of clinical information; and 3) create a design exhibition based on the information available evidence. But their work, said that the model can fully meet the needs of medical information to perform certain tasks. All the data are not relevant.
Data Mining and not the decision to change the stored data or the correctness of the decision of the algorithm. The performance of the algorithm is not normal. There are many ways can the system combines various forecasts combined average. As, the production cannot be much better than the best algorithm. Many reviews refer to Sheela Dasarathy work in 1979 as an early example of the joint decision [6], as to improve the algorithms based on the training and expand some regression categories. [7] In a bypass operation with different algorithms. Ten years later, Hansen and Salamon show the same determination system used neural networks configured, performance classification can be improved. [8] However, he worked Schapiro screen through a process to determine the amount of error can be performed by a set of decision algorithms with binary classification problem arbitrarily low, faults much better than random guessing it called improving to be. [9] Master improvement is Ada Boost the basis
of the following algorithm. In all studies, right heart failure and analysing Big Data one of the most impressive projects. There are experts and many false discoveries have the need to develop a fast and efficient detection system. We appreciate the importance of effectively collected by different algorithms. The directive similar program used in this study.
3. ANALYSIS OF PROPOSED METHOD
[image:2.612.321.513.452.582.2]Most heart failure [10, 11] and follow the best example, they come and knock on the model and the data must be on the system performance. System, one of these complexes mathematical models and are difficult to included optimized applications to convert; not public, where they can easily be converted to a product. The currency risk factors and other information, or loss of valuable information of redundant data. And multi-model approach, we should generally try to use such details. Open source data mining tools to create such models. We use the system for classifying and grouping to try more in the system. Classification Type built for misspellings like are combined to determine the type of distribution. There the two draft regulations are implemented, Phase 1: Development of the type that the flow of static electricity, Step 2: A model for errors on the basis of development, two studies in the group of the prediction model and weight calculation.
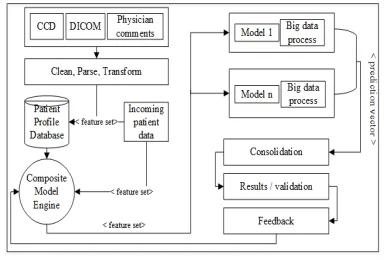
Figure 1: Architecture is that the multiple model approach recommended
3881 for drying is required, analysed changes not applied.
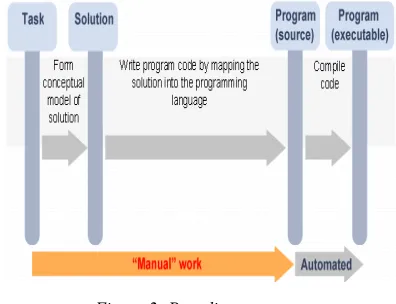
Figure 2: Paradigm program
The figure 2 shows that perform the following programming paradigm in different models. Each model is to put the class model, the report interface makes available; cites the work of the identity of the patient and class for each model control Mapper, emission vector i<id, class model, vector, predicting> Forecasting to demonstrate the model. The starter motor put into gear, leads collected friction, and transmits the last prophet. Each step is explained in detail below.
Collection: Dictionary patient ID as a key and a predicted value list, any acceleration unless it is included in the list, match the patient ID. A model of contention for a list of participants begins when all vector designs and processes.
Contention: to choose from at this stage of the
model is a configured model. The second phase consisted of analogous steps in the past ministering to the static weight of the final consequences. Conflict resolution through modelling error. Prediction can receive training in four groups divided type CCD, as shown in Table 2. If the records are now sick of the four groups as tiebreak conflict. A subset of the configured type is preferred as such probably correct participate say.
Consolidation: In this phase, the type of inverse standard method of calculation, which bear the brunt of the impact location, it is 5 in the final product prophet.
Emission: Patients with device ID unexpected value and removed infected transmit the corresponding dictionary entry.
As described above, the approximation with a plurality of models is carried out in two phases. The first phase of the affected part in the final set, that is to say for each model often weighs only 1 / n, where n is the number of the type used. The latter policy is a part of the static weight (pM) 1, and RGR; i, where special jig is formed. In this approach, the impact in predicting the effects is not effectively functioning properly. Intended two to a similar selection process to choose to eliminate a subset of the system and the model is even take erroneous predictions of the model as feedback for the best part models in part, it is impossible to predict accurately. Each model requires C01 C11 C00 says that all programs distributed error into four groups, C10, Table 1 provides an explanation of each group. In the context of the experiments predicted all tuple Klassen, clusters, the area of the housing any calculation error us the distance vector <D00, D01, D10, D11>, including predicting the participation of the current model of the final, as well as effect (by weight) prediction models determines the final prediction. Listing 1 shows the logic that determines the participation models.
Table 1: Cluster model with errorsMake list logic to
determine the predictive model of the eventual participation
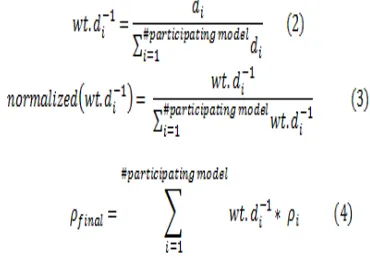
Once we have a subset of the subscriber and predict the classes, and the distance vector Vi for each class, we use the inverse distance function [17] given is given by the equation 2, to determine the model weight of participants, then the weigh normalized value between the values 0 and 1, as shown by equation 3, which uses a dynamic weight
If ρi≈ 0 then,
[image:3.612.314.534.460.641.2]3882 of the final prediction. A final prediction by
equation 4. If the resulting ρfinal by the differentiated
approach proposed model predictions. The improvement is the proposed model, the number of clusters in each category, a clear, i.e. the group C00, C01, C10, C11 represents raise the entire cluster or clusters, it will greatly the efficiency of the model, improve weight to determine Beteiligungs dynamic model. This work is part of the future.
4. SIMULATIONS AND RESULTS
Multi-performance model in the
Framingham record test [14] consists of 1500 patient records. A part of the Framingham study data, including laboratory / clinical data from 1,500 patients. Table 2 shows that predicting the image of the Framingham data, the main objective More Models is the class of the data field indicating whether to determine the patient will live or die. You can learn more about finding the varieties [14].
Table 2: Snapshot of the data Framingham
[image:4.612.318.516.97.220.2]Make all models, Weka, data extraction tools are used [15], 75% identical to the training data and 25% of the test data. Multi-model approach as a disk card reduces the work well Hadoop framework [16] run in the context of C # .Net. Multi-model approach and compare the best example. 25 kinds of pattern formation and performance of 82.42% regression of the database. The performance of the model is defined in Article 1, Table 3 shows purchased different types of instruments and Weka data and automatic operation.
Table 3: Various tools bought and tell Weka
[image:4.612.97.282.226.355.2]Regulatory and added two phase system described model system. Proposed in the first phase of each type of fixed configuration, 12:04 (25.01) and the like, and to carry out most of the model found 84.36%. Selected in the second reaction phase in which a portion of the model in the process described in the draft regulations, these operations were found a multimodal risk assessment 85.87%. Table 4 scholarships to compare the effectiveness of the model, see the results, the multi-model approach aims to fulfil the best example.
Table 4: Overall Results
5. CONCLUSION
In this article, we analyse the overall architecture of clinical decisions and predictive modelling system that powers the management of employee health information systems or business, this time the data warehouse. The results showed that the idea of several best architectural model the best method of prediction. With model error of the forecast model, we will choose the right model group. We reviewed the operation of the sampling system at various levels, leading to a more accurate forecast results.
REFERENCES:
[1] Hsu, William, Ricky K. Taira, Fernando
Viñuela, and Alex AT Bui. "A Case-based Retrieval System using Natural Language
Processing and Population-based
[image:4.612.321.515.388.467.2]3883 2011 First IEEE International Conference on, pp. 221-228. IEEE, 2011.
[2] Raghupathi, Wullianallur, and Viju
Raghupathi. "Big data analytics in healthcare: promise and potential." Health Information Science and Systems 2, no. 1 (2014)
[3] Zolfaghar, Kiyana, NarenMeadem,
AnkurTeredesai, SenjutiBasu Roy, Si-Chi Chin, and Brian Muckian. "Big data
solutions for predicting
risk-of-readmission for congestive heart failure patients." In Big Data, 2013 IEEE International Conference on, pp. 64-71. IEEE, 2013.
[4] Yadav, Chanchal, Shuliang Wang, and
Manoj Kumar. "Algorithm and approaches to handle large Data-A Survey." arXiv preprint arXiv:1307.5437 (2013).
[5] Hsu, William, Ricky K. Taira, Suzie
El-Saden, HooshangKangarloo, and Alex AT Bui. "Context- based electronic health record: toward patient specific healthcare."
IEEE Transactions on information
technology in biomedicine 16, no. 2 (2012): 228-234.
[6] Dasarathy, Belur V., and Belur V. Sheela.
"A composite classifier system design: concepts and methodology." Proceedings of the IEEE 67, no. 5 (1979): 708-713.
[7] Freund, Yoav, and Robert E. Schapire. "A
decision-theoretic generalization of online learning and an application to boosting. 1995." In European Conference on Computational Learning Theory.
[8] Hansen, Lars Kai, and Peter Salamon.
"Neural network ensembles." IEEE transactions on pattern analysis and machine intelligence 12 (1990): 993-1001.
[9] Schapire, Robert E. "The strength of weak
learnability." Machine learning 5, no. 2 (1990): 197-227.
[10] Jabbar, M. Akhil, Bulusu Lakshmana
Deekshatulu, and Priti Chandra. "Heart disease prediction system using associative classification and genetic algorithm." arXiv preprint arXiv: 1303.5919 (2013).
[11] Yadav, Pramod Kumar, K. L. Jaiswal,
Shamsher Bahadur Patel, and D. P.
Shukla. "Intelligent Heart Disease
Prediction Model Using Classification Algorithms." (2013): 102-107.
[12] Ferranti, Jeffrey M., R. Clayton Musser,
Kensaku Kawamoto, and W. Ed Hammond. "The clinical document
architecture and the continuity of care record." Journal of the American Medical Informatics Association 13, no. 3 (2006): 245-252.
[13] Mildenberger, Peter, Marco Eichelberg,
and Eric Martin. "Introduction to the DICOM standard." European radiology 12, no. 4 (2002): 920-927.
[14] Framingham Heart study, Extracted on
April 2016,
http://www.maths.utas.edu.au/DHStat/ Data/Flow.html
[15] Hall, Mark, Eibe Frank, Geoffrey Holmes,
Bernhard Pfahringer, Peter Reutemann, and Ian H. Witten. "The WEKA data mining software: an update." ACM SIGKDD explorations newsletter 11, no. 1 (2009): 10-18.
[16] Apache™ Hadoop®!,Accessed on April
2016, http://hadoop.apache.org/
[17] Bartier, Patrick M., and C. Peter Keller.