International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
731
Analysis of Audio Descriptor Contribution in Singer
Identification Process
Saurabh H. Deshmukh
1, Dr S. G. Bhirud
21IT dept, G.H.Raisoni COE&M, Wagholi, Pune, India 2
Computer Engineering Dept, VJTI, Mumbai, India
Abstract—An audio descriptor describes the information of an audio signal in a compact and precise representation. There are various standards available to extract the audio information in various ways to be used for particular applications such as, speaker recognition, musical instrument identification, singer identification, multimedia database indexing, genre detection and so on. There are various audio descriptor extraction and manipulation tools available to be used with MatLab. Audio descriptor plays vital role for the applications such as singer identification. The process becomes complex with respect to monophonic, homophonic and polyphonic type of music. In North Indian classical music, (homophonic version), an accompanying instrument called Tanpura is continuously played during the vocal performance of the singer. In such cases, merely standard procedures of speaker recognition or singer identification from polyphonic music are not sufficient. The contribution of different audio descriptors changes from one type of input to the other. In this paper, we have established a singer identification system using MIRtoolbox for Timbral feature extraction and K-Means clustering for classification. The purpose of this paper is two folded. A) to design and implement a singer identification system and B) to find the contribution of the audio descriptors from each level to the final accuracy of singer identification result. With the method proposed, an accuracy of 96.6667% is achieved using K-means clustering,
for the combination of Zero crossing Rate, Roll off, Brightness
and Irregularity audio descriptors, for 3 singers for a studio recorded audio input from North Indian Classical Music recordings with the accompanying background instrument ‘Tanpura’.
Keywords-- Audio Descriptor, MatLab, Tanpura, North Indian Classical Music, K-means.
I. INTRODUCTION
Music Information Retrieval (MIR) community has gained wide popularity after realizing the strengths of MatLab subroutines [1], [2] giving scope of manipulating sound signals in various efficient ways. In recent past, a lot of research is done on sound source separation, sound data acquisition, sound database processing, to name a few [3], [4], [5]. There are couple of real time audio processing tools enhancing the capabilities of online audio feature extraction and processing [6] & [7].
More or less researches have got encouraged and attracted towards audio processing after enhancements in the capabilities of MatLab tools. Music Information Retrieval research is divided into various sub-fields, including, Singer Identification, Musical Instrument Detection, Melody Matching, Generating and Managing Musical Database, Automatically Generating Metadata and so on.
Singing voice detection, just by listening to an audio sample, can be somewhat easy task for a musically trained human but providing this ability to a computer system is a challenging task. Humans have very strong sound detection and recognition system (hearing system) which, yet to be gained through computer. The ability to filter the sound, to extract the required musical information and to use a classifier that uniquely and perfectly detects a voice, is a god‟s gift to us.
The basic components responsible for successful
classification and detection are called as
„Audio Descriptors‟. MPEG-7 is a standard that provides a set of tools to describe the multimedia content [8]. The prominent features, included in this standard are, Descriptors (D), Descriptor Schemes (DS), Descriptor
Definition Language (DDL) and Binary Coded
representations.
In this paper, we have used the scalar audio descriptors defined by MPEG-7 standard. The descriptors are extracted through MIRtoolbox [9] with taxonomy of Timbre and are fed to simple K-Means Classifier for classification. The singer identification process is explained in depth further with respect to the input audio (North Indian Classical Music), the algorithm used to analyze and select the audio descriptors (Hybrid Selection method); the classification (K-Means clustering) and finally, the results with conclusions are discussed.
II. RELATED RESEARCH
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
732 Also, there is a little contributing work on comparing the audio descriptors efficiency in the singing voice detection process [14] and [15]. The former research uses a statistical classifier and considers only timbre descriptors that include Mel Frequency Cepstral Coefficients (MFCC), Log Frequency Power Coefficients (LFPC) and Harmonic Coefficients (HC) along with some general purpose audio descriptor such as, Spectral Centroids, Roll off, Flux, Skewness, Kurtosis and Flatness and pitch which though, generally used for instrument classification.
Zero Crossing Rate is correlated with spectral centroids and Energy features such as RMS energy and Low energy as variants of LFPC (the spectral descriptor variants). The experimental results for the input data set consisting of 44.1 kHz sampling rate and of duration of 0.1,1 and 3 seconds led to conclude an accuracy of 78.5% for MFCC. Each audio descriptor coefficients, as well as their deltas and double deltas, mean, median, standard deviation, the skewness and kurtosis are calculated and used. The research concludes that the audio descriptors modeling the spectral content of audio signal are most appropriate for the problem of singer identification such as MFCC, LFPC Spectral and Perceptual LPC). This approach generates a reduced set of audio descriptors.
The lateral research provides an application independent overview of feature extraction techniques. The work proposes a novel taxonomy for audio features. It classifies the audio features into; Temporal features, Physical Frequency features, Perceptual frequency features, Cepstral features, Modulation Frequency features, Eigen domain features and Phase space features. The grouping of audio features from frequency domain and autocorrelation domain into same domain is justified with a reason that, they represent similar information. Interestingly, the taxonomy does not even mention about timbre and timbral aspects of audio.
In CUIDADO project total 54 (scalars and vectors) audio descriptors are implemented [16]. In this, a large set of audio features are implemented related to Temporal Shape, Temporal, Energy, Spectral Shape, Harmonic, Perceptual and MPEG-7 low level audio descriptors. Taxonomy that is used to classify the audio descriptors includes four different points of view, for each audio descriptor. Although, even after considering such a large set of audio descriptors (total 54) the taxonomy fails to include timbral aspects of the sound.
There are three main properties of an audio descriptor [17] , the Temporal Extent, the signal representation used to compute and the concept described by the descriptor. The descriptors, in this research, are classified into global and time-varying categories.
The global descriptors are those, which hold same value throughout the signal while the time varying descriptors are calculated separately for each time frame defined early. The authors clearly give a comprehensive tabularization of audio descriptor, its unit and the input representation of the descriptor. A standard database of 6037 sound samples is used from McGill University Master Samples (MUMS) database. Unfortunately, all these data samples are from musical instruments and not of human voice. The analysis fails also to explain the contribution efficiency of each audio descriptor in the classification process.
There are many types of musical instruments.
Woodwind instruments, brass instruments, string
instruments, percussions, bow instruments and so on. If we carefully compare brass instruments, (such as a saxophone) or woodwind instruments (like flute), with human throat, both have similarity in one sense, in the production of sound. A lot of research done on timbre but it is little biased toward considering human singing voice as a kind of musical instrument. A sound without having some timbre properties is any way impossible. In this research, we have considered human voice as a kind of musical instrument providing all attributes such as amplitude, frequency and duration along with timbre. The timbre being a multidimensional and non tangible entity, it is realized through a set of audio descriptors described in MIRtoolbox, [9]. The following section explains the audio descriptors that are considered in this paper for singer identification process.
III. AUDIO DESCRIPTORS CONSIDERED
As stated earlier, audio descriptors can be classified using various view points. We have here considered the taxonomy given by [9] where, following audio descriptors are considered under Timbre category. The audio descriptors are as follows:
A.Attack time and attack slope
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
733 B.Zero Crossing Rate(ZCR)
Zero Crossing Rate (ZCR), is simply the rate with which the audio waveform changes its sign. The sound that is periodic in nature with low frequency usually has less number of such sign changes and thus small value for „zero crossing rate‟. On the other hand, if the sound contains noise component, then there are many such sign changes resulting in high value of zero crossing rate. ZCR is one of the measures used to identify the noise component present in the sound.
C.Roll off
Roll off (spectral) gives an estimation of the amount of high frequency in the input signal. It is found such a way that a certain fraction of the total energy is contained below that frequency. In other words, if the ratio is fixed to 0.85 or .95 then 85% or 95% signal energy is contained below the roll off point. For the audio input of North Indian classical music voice, roll off plays vital role in identifying the high frequency energy contained in the singing part of the input file.
D.Brightness
Similar to roll off, in other way, brightness gives a value (range: 0 to 1), indicating the amount of signal energy above a particular given cut off frequency. The cut off value chosen is 1500Hz for a simple reason that, the singer, singing North Indian classical music, sings in a frequency usually near to 1 kHz when we consider a „bright‟ voice.
E.MFCC
Mel Frequency Cepstral coefficients (MFCC) describe the spectral shape of an audio input. It is a multi processing system. First, the frequency bands are logarithmically positioned. This is called as Mel scale. A method that has energy compaction capability called, “Discrete cosine transform” (DCT) is used, that considers only the real numbers. By default first 13 components are taken. The experimental results however, have shown less significance in considering first 10, 20 and 30 coefficients. Thus, in this research we have considered first 20 coefficients of Mel scale.
F.Roughness
Roughness is an estimation of sensory dissension. It represents a rapid sequence of important events occurring in the audio sample. Roughness of a sound depends on the „shapes‟ of the events and the „frequency of occurrence‟ of those events. Roughness values are higher when short duration events occur for a fixed pulse frequency, while it is smaller when the pulse frequency is higher.
The presence of periodic musical support instrument called Tanpura, being played continuously in the background, in the input of classical music increases the importance of roughness value in order to identify a singer.
G.Irregularity
Irregularity is the sum of the square of the difference in amplitudes between neighboring partials. Yet, there is another approach to find the irregularity. It is calculated as sum of the amplitude minus the mean of previous, this and next amplitude. It is the degree of variation of the successive peaks of the spectrum. For classical music under consideration, a singer singing a „raga‟ [18] usually applies a lot of constant notes. And these prolonged notes in the spectrum usually, are same throughout the signal for a short duration. Thus, irregularity value shall be less for long notes and shall be higher for short duration notes being sung.
IV. EXPERIMENTS AND RESULTS
In order to analyze the contribution of each one of above audio descriptors in the singer identification process for North Indian Classical Music, three types of musical datasets are used.
1. DB1: containing noisy data with audio recordings of 9 classical singers with 8 samples per singer yielding 72 audio, .wav files with 11,025 sampling freq, 16 bit, mono and 5 sec duration each.
2. DB2: containing noiseless recordings of dry voices of classical singers with same above stated attributes, giving total 72 audio files.
3. DB3: systematic studio based, noise free, audio recordings of 72 files (same as above) with Tanpura and harmonium/ violin as accompanying instruments without any rhythm instrument.
A hybrid selection method for selecting the audio descriptors is implemented [19] except with a change that instead of forward and backward passes iteratively we chose only significant audio descriptors at each level and used only one pass. For the first level, all single audio descriptors under timbre group are used to extract the audio feature vector from all the three given data sets. These audio feature vectors are then submitted to simple K-Means clustering for training and codebook generation.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
734 Total results of correct classification of singing voice from known samples (the one given in training) and unknown samples is found out. Whichever four (out of six) audio descriptors, having highest accuracy, are selected for further combination with others in the second level.
Again in second level similar effect of combination of audio descriptors on overall classification efficiency is found out. This procedure is repeated till there remains no more combination for any audio descriptor. This way all the audio descriptors are evaluated with respect to their involvement in the efficiency of singer identification process. The same procedure is followed for 9(Class A), 5(Class B) and 3(Class C) singers at a time with all viz. DB1, DB2 and DB3 databases. At last level, from each database and from each class, best combination of audio descriptors is found out that gives maximum efficiency for singer identification from North Indian Classical Music.
To find out the role and importance of each audio descriptor in the complete singer identification process, one assumption is made. Like a path on a shortest path is always a shortest path, an audio descriptor that gives best efficiency at last level, must be best in all the previous levels. On an average the efficiency of the system decreases when more than four combinations of the audio descriptors are used. Hence, from the final result at level 4, the contributing audio descriptors giving best results are considered and their percentage involvement at each level is calculated by calculating an average of efficiency.
For the first level, each audio descriptor is selected individually. Hence, whatever the final efficiency of the result of classification achieved is through the sole presence of these audio descriptors only.
At level 2 and 3, the selected audio descriptors (giving better efficiency at level 1) give improved efficiency in combination with other audio descriptors. Hence, an average efficiency of singing voice detection for those combinations are calculated, wherever the selected audio descriptor was involved. It is to be noted that, there can be other combinations of the selected audio descriptor and some other less significant audio descriptors present at level 2 and 3.
We have considered the average value of the singer identification result by using all the combinations of the selected audio descriptor since; we are calculating the efficacy and importance of audio descriptor in the entire singing voice detection process. At level 4, since only the best combination of any four audio descriptors is selected, the final result is itself the parameter of the percentage of involvement of this selected audio descriptor under consideration.
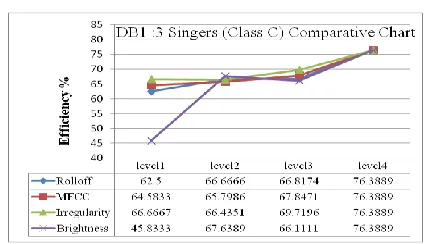
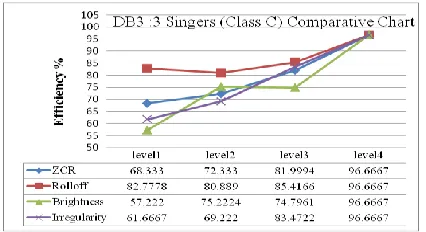
[image:4.612.331.562.143.516.2]Following charts represent the result from all classes for all databases used for singer identification process. Figure (i-iii) show the results and the % efficiency of audio descriptors at all levels giving best results at final level, for dataset DB1 for 9 singers (class A), 5 Singers (class B) and 3 singers (Class C) given for training and testing and Figure (iv-vi) for DB2 and Figure (vii-ix) for DB3.
[image:4.612.336.558.229.342.2]Figure i: Contribution efficiency of various audio descriptors of DB1 for 9 singers (Class A)
Figure ii: Contribution efficiency of various audio descriptors of DB1 for 5 singers (Class B)
[image:4.612.336.554.374.495.2] [image:4.612.337.551.529.651.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
[image:5.612.337.551.134.251.2]735
[image:5.612.64.277.136.251.2]Figure iv: Contribution efficiency of various audio descriptors of DB2 for 9 singers (Class A)
Figure v: Contribution efficiency of various audio descriptors of DB2 for 5 singers (Class B)
[image:5.612.337.553.285.402.2]Figure vi: Contribution efficiency of various audio descriptors of DB2 for 3 singers (Class C)
Figure vii: Contribution efficiency of various audio descriptors of DB3 for 9 singers (Class A)
Figure viii: Contribution efficiency of various audio descriptors of DB3 for 5 singers (Class B)
[image:5.612.62.277.288.408.2] [image:5.612.339.552.439.555.2] [image:5.612.64.276.440.559.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
736
V. CONCLUSION
Singer identification on the basis of timbral aspects of the singing voice gives maximum singer identification
efficiency of 96.6667% for the combination of Zero
crossing Rate, Roll off, Brightness and Irregularity audio descriptors, when 3 singers‟ 5 samples (per singer) given for training and 8 samples (including above 5) used for testing in DB3. As far as singer identification efficiency is concerned, best efficiencies from DB1, DB2 and DB3 and classes A,B and C are: (DB1,3 singers,76.3889), (DB2,3 singers,68.75) and (DB3,3 singers,96.6667).
The graphical representation of audio descriptors involved in this process clearly indicate that, the audio descriptors that give best results at level 4 also show steady linear growth in singer identification efficiency when these descriptors were used with other audio descriptors in combination at early stages.
For example in Figure (ix), consider irregularity. When irregularity is used as only audio descriptor at level 1 to identify the singers it gave 61.6667% accuracy. At level 2, an average of all efficiencies, (wherever irregularity involved) give 69.222% average efficiency of singer identification when irregularity was involved. At level 3, three audio descriptors considered where, one of them is irregularity and an average of efficiencies from all such combinations give 83.4722%. Further, at level 4, four audio descriptors are considered (that involves irregularity) giving maximum efficiency of 96.6667%.
Similar trend can be observed from all the above charts. At some cases there is surely a decrease in the average efficiency for the audio descriptor at level 2 and 3. The basic reason behind this drop of efficiency is that it is an „average‟ value containing inefficient contribution of bad audio descriptors. The result here shows how each audio descriptor contributes in the final efficiency at each level proving it to be the best candidate to be considered in the final combination of audio descriptors to be used to increase the efficiency of singer identification process.
We conclude from this experiment and result,
a)Best combination of audio descriptors to be used, from timbre group, for singer identification problem are: Zero crossing Rate, Roll off, Brightness and Irregularity.
b)An audio descriptor that is best at the final stage also shows continuous linear growth in efficiency, from first level to nth level.
c)The percentage contribution of each audio descriptor, both alone or in combination with others, can be calculated at each level and be used to predict if that audio descriptor is useful in improving the efficiency of singer identification at early stage only.
d)For North Indian classical music, there is no effect of presence of accompanying instrument like Tanpura, provided however that the recordings are noise free.
e)MFCC works better with noisy database than
noiseless.
f) A maximum accuracy in singer identification for the input of North Indian Classical Music is 96.6667% using K-means clustering, for the combination of Zero crossing Rate, Roll off, Brightness and Irregularity audio descriptors, for 3 singers.
REFERENCES
[1] Malcolm Slaney, ""Auditory Toolbox"-V2.," Interval Research Corporation, Palo Alto, CA, Technical Report #1998-010, 1998. [2] Stuart Cunningham, ""Matlab Auditory Demonstrations" -V2.,"
Department of Computer Science , University of Sheffield, Sheffield,South Yorkshire,UK, Speech and Hearing Research -Documentation Recision 0.1, May-1998.
[3] ""Data Acquisition Toolbox"-V 3.4," MATLAB, Natick, MA, Manual Sept 2013.
[4] Kobi Nis, ""Audio Database Toolbox" ," MATLAB, MANUAL 21 Apr 2009 (Updated 25 Jun 2009).
[5] Dominik Wegmann, "DAFX Toolbox ," MATLAB, MANUAL 06 Nov 2006 (Updated 17 Jul 2007).
[6] Tucker McClure, ""Real-Time Audio Processor"," MATLAB, Manual 04 Sep 2012.
[7] Trevor Agus, ""Real-time audio input"," MATLAB, Manual 22 Jul 2011.
[8] Hyoung-Gook Kim, Nicolas Moreau, and Thomas Sikora, "MPEG-7 Audio and Beyond"- Audio Content Indexing and Retrieval. Chichester,West Susscx, England : John Wiley & Sons, Ltd, 2005. [9] Olivier Lartillot and Petri Toiviainen, ""A Matlab Toolbox for
Musical Feature Extraction from Audio"," in International Conference on Digital Audio Effects, Bordeaux, France, 2007. [10] Bishnu S Atal, ""Automatic Recognition of Speakers from their
voices"," PROCEEDINGS OF THE IEEE, vol. VOL. 64, no. NO. 4, pp. 460-475, APRIL 1976.
[11] Tae Hong Park, ""Towards Automatic Musical Instrument Timbre Recognition"," PRINCETON UNIVERSITY, PRINCETON, Thesis Report Nov 2004.
[12] Mark A. Bartsch, ""Automatic Sinfer Indentification in Polyphonic Music"," University of Michigan, Michigan, Thesis Report 2004. [13] Martin Rocamora, ""Singing Voice Detection in Polyphonic
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
737 [14] M., & Herrera P. Rocamora, ""Comparing Audio Descriptors for
Singing Voice Detection in Music Audio Files"," in 11th Simpósio Brasileiro de Computação Musical (SBCM07), Soo Paulo, Brazil, 2007.
[15] Matthias Zeppelzauer, Christian Breiteneder Dalibor Mitrović, "Features for Content-Based Audio Retrieval," Advances in Computers, vol. Volume 78 , no. ISBN: 978-0-12-381019-9, pp. Pages 71–150, 2010.
[16] Geoffroy Peeters, ""A Large Set of Audio Features for Sound Description (similarity and classification) in the CUIDADO Project"," IRCAM, Châtelet, Les Halles, version 1.0, 2004.
[17] Geoffroy Peeters, Bruno L. Giordano, Patrick Susini, Nicolas Misdariis, and Stephen McAdams, "The Timbre Toolbox: Extracting audio descriptors from musical signals," The Journal of the Acoustical Society of America DOI:10.1121/1.3642604, vol. 5, no. 130, pp. pp 2902-16., March 2011.
[18] Sadhana. (2011) hindustani.com. [Online]. http://raag-hindustani.com/Scales1.html