2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
Personalized Ranking Algorithm Based
on User Interest Modeling
Cong LUO
1,a*and Zu-hua LI
2,b1Jiangnan Institute of Computing Technology, Wuxi, China.
2Jiangnan Institute of Computing Technology, Wuxi, China.
a[email protected], b[email protected]
*Corresponding author
Keywords: User interest model, Topic-based representation, User browsing behavior, BM25, Personalized ranking algorithm.
Abstract. It’s convenient for Internet users to access to web resources with a search engine. However, most traditional search engines can’t provide personalized search results for users. In order to overcome this limit, we adopt a combination method of the explicit and implicit user modeling to build and update a user interest model. To be specific, we first build the user interest model with a topic-based representation method by the information offered by users. Then we update the model by considering the time factor and the user browsing behavior. As nouns are obviously more distinctive than other words, we give a greater weight for them. Based on this, we have improved the BM25 algorithm. Finally, a personalized ranking algorithm combining topic ranking and BM25 ranking is proposed. The experiments show that the personalized ranking algorithm based on user interest modeling can provide personalized search service for users.
Introduction
With the sustained development of Internet, the amount of information increases explosively. A search engine is important for users to get useful information from massive resources.
Users’ interests can’t be identified by most traditional search engines. Users with different needs will get the same search result after they submit the same query. The difference between users can’t be reflected. In the meantime, users hope their query intentions can be identified by the search engine which can present personalized search results.
We build and update the user interest model by the information offered by users and the analysis of the user browsing behavior. In order to provide personalized search service for users, a personalized ranking algorithm based on the model is proposed.
Related work
In order to satisfy users’ needs much more, personality and intelligence become a hot research topic in the field of search engine. A personalized ranking algorithm based on a user interest model can present personalized search results for users.
emphasizes the use of immediate click-through information for implicit user modeling [2]. With the model, web pages that have not been clicked will be rebranded. Based
on BM25, Bouhiniproposes and by considering
the term frequency of query terms in the user profile [3]. Because TFIDF equally treats every page, Yang proposes the concept of page correlation weight and designs a weighted TFIDF algorithm to build a user interest model [4]. TY Liu presents the main approaches to learning to rank where hundreds or even thousands of features are learned via search log [5].
As shown in these related works, a user interest model is the foundation of personalized search. Personalized search service can only be provided by accurate understanding of user interests.
User Interest Model
We adopt a topic-based representation method to represent the user interest model. In other words, we use topics that the user interested in to represent the user interest model. Thus, we represent the user interest model as an n-dimensional interest vector , where each dimension is composed of a topic category and its weight which is the degree of the user’s interest in . For example, if a user is interested in sports and computers equally, then the user interest
model can be described as . For the rule of forgetting,
it’s necessary to consider the influence of the time factor to the user interest model. As
a result, we use a triplet by introducing the time factor to represent each dimension of the user interest model, where is the latest time that is updated. We introduce a forgetting factor to simulate the user interest attenuation [6]:
(1)
where is the current time, is the latest time that is updated and is half-life after which the weight will reduce by half. Then the corresponding weight can be expressed as:
(2)
The direct participation of users is demanded for the explicit user modeling which can be realized by asking users to offer their interests and evaluate search results. This approach has high reliability since it better reflects the user’s real interest. However, it will somehow lead load to users and users are generally unwilling to disclose relevant information. The implicit user modeling builds the user interest model automatically by analyzing the user's query history and browsing behavior. This approach is more convenient without the direct participation of users. However, it is hard to reflect the real interest of users. Considering this situation, we combine the explicit and implicit user modeling method to make up the weakness for each other.
Assume that all web pages can be divided into topics: . Firstly, users are asked to select topics that they are interested in and give them appropriate
weights , and then the initial user interest model
the consideration of the forgetting mechanism, we need to update the user interest model by analyzing the user browsing behavior after it is built. Generally speaking, users will browse web pages they are interested in according to the web page summarization. If they are not satisfied with the web page they click, they will choose the next web page they are more interested in. So we make the following assumptions. The degree of the user’s interest in the web page positively correlates the web page’s order of clicking during the query execution. On the other hand, the most relevant web pages tend to rank top in the personalized search result. Then the order of the web page in the search result will reflect users’ interest in web pages to a certain degree. YANG builds the user interest model with a two-layer tree structure [7]. Topic preference and term preference are both considered in the ranking algorithm. However, she identifies all web pages only as a certain topic. Considering comprehensive content of web pages some of which may be related to several topics, we update the user interest model from the perspective of the probability that the web page belongs to each topic. The probability can be calculated by a random forest classifier. If the user clicks web page whose probability that it belongs to is during the query execution and the corresponding weight of is , then we update each topic’s weight according to the following formula:
(3)
where is a constant, is the web page’s order of clicking during the query execution, is the order of the web page in the search result. Compared with , can better reflect a user’s interest. Therefore, we use the logarithm of and we add one to to prevent the value of the denominator being 0. In addition, should be updated with the current time. Taking account of the web page’s order of clicking during the query execution and the order of the web page in the search result is able to mine users’ interests effectively.
Personalized Ranking Algorithm
Okapi BM25 (BM25 for short) is a correlation ranking function, suiting for ranking web pages according to the relevance of a given query. BM25 and BM25F are two models superior to others in Text Retrieval Conference (TREC). They are known as the most advanced models in Information Retrieval (IR) field at present.
Assume that there is a query with terms , the general formula of BM25 is:
(4)
where is calculated as:
(5)
and are free parameters which are typically set to and respectively.
Term frequency, document length and average document length of web pages to be ranked are taken into account in BM25. However, BM25 equally treats every word and the difference of the ability to express document information among different parts of speech is overlooked in it. As a result, we set the value of nouns to be 1.5 and other words 1. BM25 is improved based on this and the relevance between query Q and web page D is now calculated as:
(6)
where is the value of .
[image:4.612.114.504.363.658.2]Generally, users are always interested in the information of a certain field. Without consideration of this, the accuracy of traditional personalized ranking algorithms is not high. Zhang considers the web page’s category and proposes the concept of domain ranking and local ranking [8]. Web pages in every domain will be ranked by local ranking on the base of domain ranking. However, Zhang thinks if a user is interested in one certain domain, then he is interested in all web pages of that domain. Obviously, it is not realistic. For example, a Python programmer, interested in ‘Computers’, takes no interest in Java programming. He may prefer to find the information of Java Island in Indonesia after submitting the query ‘Java’.
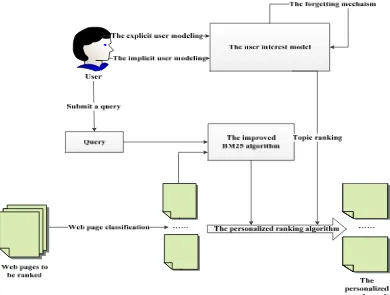
We still take domain ranking into account. However, it won’t play a decisive role in the ranking stage like above. Based on the user interest model, we propose the personalized ranking process as shown in figure 1.
Firstly, web pages are classified according to the predefined topics. Further, for a web page , if the probability that belongs to is and the corresponding weight of is , then the score of topic ranking of is:
(7)
where is a constant. In addition, combining the query , we can calculate according to the improved BM25 algorithm for . Finally, the total score of personalized ranking for is:
(8)
where is a constant. The value of should be set to because topic ranking can better reflect a user’s interests compared to BM25 ranking.
Experiments
The query log database of Sogou search engine contains user query requirement data and user click-through data for about one month. The data format is: User ID\t [Query]\t the order of the web page in the search result\t the web page’s order of clicking during the query execution\t URL. For example, a piece of data is saved as ‘37036540755502456\t [IE6.0]\t 10\t 1\t www.520mov.com/help/iesetup.htm’. It means the user with an ID of 37036540755502456 first clicked the web page whose URL is ‘www.520mov.com/help/iesetup.htm’ after he submitted the query ‘IE6.0’, and the web page ranked 10th in the search result. The User ID is assigned automatically according to the Cookie information when using the search engine. That is to say, different queries submitted during the same search process are corresponding to the same User ID. To prevent the occasionality of experiments, we choose users who have submitted at least 3 queries and clicked at least 10 URLs.
Using ODP (Open Directory Project) topics classification, we classify web pages into 15 types: Arts, Business, Computers, Games, Health, Home, Kids and Teens, News, Recreation, Reference, Regional, Science, Shopping, Society, Sports.
We set the value of to 7 days, , , , and
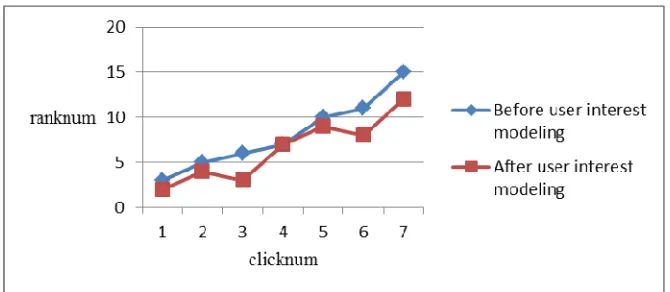
Figure 2. Contrast of the order of web pages that the user clicked before and after user interest modeling
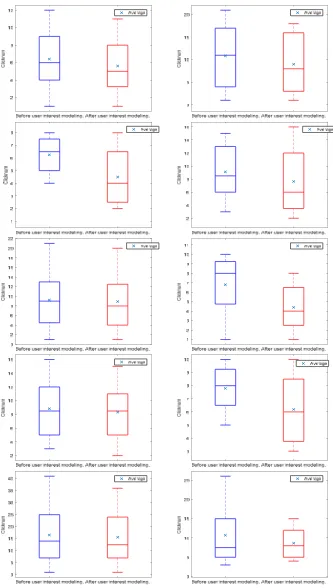
Applying the same method, we choose another 10 eligible users for the experiment like above. We use the Box-plot to contrast the order of web pages that the user clicked in the search result before and after user interest modeling. For easy viewing, we also add the average value as another evaluation index on the base of the initial Box-plot. The concrete result is shown as figure 3.
In addition, we adopt [6]to evaluate the personalized ranking algorithm we propose, defined as follows:
(9)
where is the order of the web page in the search result. If the web page is clicked by the user, then , otherwise . We set to 5 as a regulator. Based on this formula, if the web page that the user clicks has a high ranking, then will get a higher value since the value of of top ranked web pages will be 1.
We choose 100 eligible users to calculate the value of before and after user interest modeling respectively and the result is shown in table 1.
Table 1. Value of before and after user interest modelling.
Before user interest modeling After user interest modeling
Figure 3. Contrast of the order of web pages that the user clicked before and after user interest modeling of another 10 users
based on our user interest model can improve the order of web pages the user interested in for the majority of users despite a few isolated cases. In general, the algorithm can improve the retrieval quality and provide personalized search service for users.
Conclusions
To overcome the deficiency that most traditional search engines are unable to present personalized search results for users, we combine the explicit and implicit user modeling method to build and update the user interest model. Based on this model, a personalized ranking algorithm combining topic ranking and BM25 ranking is proposed to provide personalized search service for users.
However, there still exist some drawbacks in the meantime. First, we simply regard web pages clicked by users as what they are interested in as default. We only consider the order of the web page in the search result and the clicking order of the web page during the query execution to estimate the degree of interest. We plan to make a quantitative analysis of saving; downloading and collecting a web page in the future work. In addition, as we haven’t divided user interests into short-term and long-term user interests, we just simply set the half-life of all interests to a same value. This will be taken into account as well in the further research.
References:
[1] Qiu, F., Cho, J. Automatic identification of user interest for personalized search [C]. International Conference on World Wide Web. DBLP, 2006:727-736.
[2] Shen, X., Tan, B., Zhai, C. X. Implicit user modeling for personalized search [C]. 2005:824-831.
[3] Bouhini, C., Gery, M., Largeron, C. Personalized information retrieval models integrating the user's profile [C]. 10th International Conference on Research Challenges in Information Science. IEEE, 2016:1-9.
[4] Xian-feng YANG. Research on the Technology of Personal Information Retrieval in Search Engine [D]. Beijing: China University of Petroleum, 2007. In Chinese. [5] Liu, T. Y. Learning to Rank for Information Retrieval [M]. Now Publishers, 2009:423-434.
[6] CHENG. Y., QIU. G., BU. J., et al. Model bloggers’ interests based on forgetting mechanism[C]. 17th International Conference on World Wide Web. ACM, 2008: 1129-1130.