Rule Based Method Versus Statistical Method
For Speech Understanding Of The Tunisian
Dialect
Marwa GrajaAbstract: In this paper, we propose to compare two methods for speech understanding of Tunisian dialect. The first method is statistical method which integrates CRF discriminative models. The second one is a rule based method. We have used a spoken Tunisian dialect corpus acquired and annotated to perform experiments. The evaluation is based on semantic representation generated by each method. The obtained results shows that CRF models gives important results compared to rule based method, especially when dealing with limited task for under resourced languages.
Index Terms: Speech, understanding, Tunisian dialect, statistical models, rule based, pattern, CRFs.
—————————— ◆ ——————————
1 INTRODUCTION
Spoken Language Understanding is an important component in spoken dialogue systems. It aims to clarify the meaning from the spontaneous speech [1]. It is like a decoder, which convert the transcribed spontaneous speech to a sematic representation understandable by the machine [2]. It can also be defined as the process that generates the meaning of an utterance through the concept detection of the application. It could be also considered as the process of association between words and concepts of the domain, thus making it possible to generate a semantic representation of the useful meaning of oral utterances [3]. In the literature, we distinguish two levels of speech understanding: literal understanding and contextual understanding. The first level of understanding consists in extracting the meaning of the oral utterance without taking into account what was previously stated during the dialogue. While the contextual understanding is to exploit the dialogue history [4]. This latter type of understanding is based on the interaction with the user by proposing a set of questions in order to further clarify the speaker's need. Speech understanding requires two steps. The first is based on concept understanding and consists in translating the current statement into a language of concepts. While the second step is to identify the semantic structure by transforming the set of concepts obtained, in the first step, into a semantic representation used by the dialogue manager [5][2]. This second step can be defined as a representation converter [6]. The purpose of the semantic representation is to explicitly translate the meaning of an utterance, so it could be "understandable" by the dialogue manager. In the literature, several semantic representation formalisms have been proposed to provide the meaning of an utterance. We can cite attribute/value pairs, conceptual graphs, logical formulas, semantic schemes, and FrameNet. Therefore, the choice of an explicit and efficient semantic representation is a critical task. It should be also noted that this representation does not obey to any standard and may vary according to the need of the intended application.For example, if it is a query of a database, the semantic representation in the form of an SQL query is preferred like the PEGASUS understanding system for air transport information [7]. The diversity of semantic representation makes difficult the evaluation and comparison of speech understanding systems [8]. In addition, the diversity of semantic representation formalisms makes it difficult to choose the representation that faithfully conveys the meaning of an oral utterance. However, the introduction of FrameNet as a unified frame network proves the interest of frame-based semantic representation [9][10]. It is a representation able to represent rich dialogical information [9]. However, the FrameNet offers generic frames that may not meet the needs of the application [9]. Thus, it was essential to use a step of translation and adaptation of the FrameNet if we plan to exploit it for a specific dialect in a limited task. These remarks direct us towards the choice of a frame-based representation. In this work, we consider speech transcribed in textual form as the input of our understanding system. The semantic representation generated by our speech understanding system is analogous to that chosen by Bahou [11] and it is based on semantic schemas. This choice is motivated by the prospect of exploiting the same dialogue manager developed within our ANLP-RG research group. Finally, we consider the dialect as real form of communication for Arabic speakers and it is widely used to fulfill public services. So, it is so crucial to consider dialects which are still quite processed in dialogue system. The Tunisian dialect (TD) is a representative example for Arabic dialect and it represents under-resourced language. In this work, the main contribution is to compare two methods for speech understanding of Tunisian dialect (TD). The evaluation of each method is based on the final output which is semantic representation. The first method is a rule based method. The second method is based on CRF models learned from a little size corpus. The corpus used in this work is the TUDICOI corpus. It is a task-oriented spontaneous speech dialogue corpus in TD about railway request information. This paper is organized as follows. Section II presents an overview about the Tunisian dialect. Section III describes a spoken Tunisian dialect corpus used for experiments. Section IV presents the first method for speech understanding method based on CRF models. Section V presents the rule based method. Experiments and results of each method are presented in section VI. The conclusion is drawn in the last section.
___________________________________
1974
2
TUNISIAN
DIALECT
The Arabic language is known by three main collections: the Classical Arabic, the Modern Standard Arabic (MSA) and the dialectal Arabic. The latter is the real form of the language [12] since it is used in all informal communications. It is generally limited in use for request information and everyday communication. So it is so important to consider dialects in the spoken dialogue system. The Tunisian dialect (TD) is a subset of Arabic dialects related to the Arab Maghreb (western Arab world). TD is strongly influenced by other languages such as Turkish, Italian and French. It represents a mosaic of languages. It has several large regional varieties, but the variety of Tunis (used in the capital of Tunisia) is the most understood by all Tunisians [13]. Like all Arabic dialects, the TD is characterized by morphology, syntax, phonology, lexicon and orthography that have similarities and differences in comparison with the MSA and even with other Arabic dialects. In addition to that, the TD treatment is a complicated task for several reasons. In fact, there are not enough resources and processing tools such as transcribed texts, annotated corpora, dictionaries and morphological and syntactic analyzers.
3
SPOKEN
DIALOGUE
CORPUS
FOR
TUNISIAN
DIALECT
The construction of a dialogue corpus represents a big challenge especially when we deal with Arabic dialects which suffer from lack of resources [15][16]. In the context of our work, we have produced an initial corpus of real spoken dialogue corresponding to the task of railway inquiry. This corpus is called TUDICOI as TUnisian DIalect COrpus Interlocutor.
3.1 Corpus acquisition
The TUDICOI corpus was acquired with the collaboration of the National Company of Railway in Tunisia (SNCFT). The recordings are made in the SNCFT main station using a digital recorder to obtain mp3 format files. This digital recorder is fixed in the part of the staff preventing the client from knowing that the conversation will be recorded. This allowed us to avoid disruption and hesitation by customers, who then, they behave in a normal way in front of the staff to ask for information. We have not prepared any scenario for dialogues. Dialogues were in real form and with spontaneous speech using the real form of dialect.
3.2 Corpus description
The main task of the TUDICOI corpus is request information in the Tunisian dialect about the railway services. These requests are about train schedule consultation, train type, train destination, train path, fare and ticket booking. Based on these requests, several requests can be combined together during a dialogue between the staff and the client about railway services in the train station. An example of a real dialogue in the Tunisian dialect between a client and a staff is shown in Table I. Two speakers have participated in this dialogue who are the clients (C) and the staffs (S).
TABLE I
A SAMPLE OF A REAL DIALOGUE IN TUNISIAN DIALECT BETWEEN A CLIENT (C) AND A STAFF (S)
Turn Transliteration Transcription Translation
C:
sAmHny wqtA$ yxrj EttrAn ltwns سنوتل نارتلا جرخي شاتقو ينحماس
Excuse me when does the train leave to Tunis ?
S: mADy sAEh wrbEh OdrAj جاردأ هعبرو هعاس يضام Twenty past one
C: bqdA$ hwA Ettkyh هيكتلا اوه شادقب How much is the ticket ?
S:
vnA$ nlf wxmsmyh ltwns سنوتل هيمسمخو فلن شانث Twelve dinars and five hundred
to Tunis
The TUDICOI corpus consists of 1825 dialogues from 1831 users. These dialogues represent 12182 utterances. The most important characteristics of the corpus are shown in Table II.
TABLE II
MAIN CHARACTERISTICS OF THE TUDICOICORPUS
# Dialogues 1825
# Speakers 1831
# Client turns 6533
# Staff turns 5649
# Words in client turns 21682
The 1825 dialogues are composed of 6533 client turns and 5649 staff turns. On average, each dialogue consists of three turns for a client and three turns for staff. In addition, each client's turn is composed of 3.3 words, on average. It is so important to note that the average of words per client turn is very low. This is due to key words used by clients to ask for information about railway services.It is so important to notice that we are interested in client turns. That's why we have manually labeled only the transcribed speech data of clients based on semantic point of view in order to build a language model for client utterances. In fact, we have established a well-defined semantic annotation scheme for client utterances for the railway request information task to cover all aspects of client utterances in the studied task.
3.3 Transcription
The transcription step appears more critical in spoken dialogue corpora because the establishment of such a resource bank represents a major effort especially when dealing with the Arabic dialect. In fact, and because of the lack of automatic resources for speech transcription [17], we have used manual transcription based on phonetics to highlight the Tunisian accent in the dialogue. Until now, we have just transcribed 50% of speech data. In fact, we recorded approximately 104 hours in the railway station and we transcribed only 52 hours. Naturally, more than one utterance can appear in a dialogue turn. That's why we have considered a dialogue turn as a set of utterances. So, turns are not segmented into utterances during the transcription step.
3.4 Corpus treatment
results about the robustness of discriminative models against the deteriorated data. In the second version of the annotated corpus, some automatic processing was performed before annotation to improve the turn's structure. These treatments include the following tasks:
--Lexical normalization: since the transcription was done manually, any word in the TUDICOI corpus can be written in different orthographic ways. For example, we noticed that the word "نويسفرزر" "Reservation" is written in four different forms: "نويسفرزير" ,"نويسفرازار" ,"نويسفرزار" ,"نويسفرزر. That's why, we have performed automatic lexical normalization.
--Morphological analysis and lemmatization: in this analysis, we have performed verbs and nouns. Verbs treatment consists in determining the canonical form of the verb. For example, we replace the word "جراخ" "is going" and "جرخي" "goes" by the following canonical form "جرخ" "go". However, nouns treatment consists of two steps. The first step is returning to the singular form of the noun. The second step is replacing the definite form by the undefined form of the noun. As an example, the word "تاونيرتلا" "Les trains" is transformed into "نارت" "train". --Synonyms treatment: this treatment consists in replacing each word by its synonym. Given the lack of standard orthography and dictionaries for the Tunisian dialect, we have performed the lexical normalization and synonyms treatment by creating a lexicon dictionary for the railway request information domain. This dictionary helps us to correct the orthography and replace each word by its synonym. Due to the absence of an automatic analyzer for the Tunisian dialect, we have performed an automatic shallow morphological analysis for verbs and nouns by using the complete storage method [18]. Indeed, we have built a morphological base of possible changes for verbs and nouns which help us to perform nouns and verbs treatments. All these treatments are not done on the same version of the annotated corpus. In fact, we prepared different versions of an annotated corpus with different levels of treatment. These versions are investigated to perform multiple experiments to evaluate the CRFs models on different types of treated data.
3.5 Corpus Annotation
In order to model the client utterances and to extract the dependent semantic concepts of the task, we performed a manual annotation in terms of semantic concepts. A concept is a semantic label attributed to a word or set of words in an utterance to express a minimal unity of meaning. Based on this definition, we analyzed our corpus to extract the domain concepts and use them later for the semantic annotation. This analysis established a specific semantic annotation schema for client utterances that covers the concepts of the targeted domain. In fact, the annotation scheme used to annotate the TUDICOI corpus is inherited from the Interchange Format (IF) [20]. We have used a two-level annotation. The first level covers the general intention of the utterance by means of dialogue acts. While the second level gives more specific information about the task. Dialogue acts used in the first level are shown in Table III and semantic concept labels used to label all versions of the annotated corpus are shown in Table IV.
TABLE III
DIALOGUE ACTS USED IN THE FIRST LEVEL AND AN EXAMPLE FOR EACH ONE
Dialogue act Example Translation Opening ريخلا حابص ، ةملاسع Hi, good morning
Closing ةملاسلاب Bye
Undefined كنرف ىتح يدنع داع ام يش I don't have any penny Waiting ةيوش ىنتس ا Wait a bit Request
Information نارتلا جرخي شاتقو
When the train leaves Acceptance يلاهيلخ يهاب Ok, leave it for me
Rejection لالا No No
TABLE IV
SEMANTIC CONCEPT LABELS USED IN THE SECOND LEVEL
Domain concepts Requests concepts Train
Train_Type Departure_ho ur
Arrival_hour Day Origin Destination Fare Class
Ticket_Numbe rs
Ticket Hour_Cpt Departure_Cpt Arrival_Cpt Price_Cpt Class_Cpt Trip_time Ticket_type
Path_Req Hour_Req Price_Req
Existence_Req Trip_timeReq Clarification_Req Booking_Req
Dialogue concepts Rejection Acceptanc e Politeness
Salutation_Begin Salutation_End Link concepts
Choice Coordination
Out of vocabulary Out
Given the complexity and time-consuming of the manual annotation task, we have only annotated 1476 dialogues. These dialogues represent 5047 client turns (Table V).
TABLE V
MAIN CHARACTERISTICS OF THE ANNOTATED CORPUS
# Annotated dialogues 1476
# Annotated client turns 5047
# Annotated words in client turns 16772
4
CRF
BASED
METHOD
FOR
SPEECH
UNDERSTANDING
1976 (λ1, λ2, ... λjn,μ1, μ2, ..., μkn) from the training data (x(i), y(i)),
i=1..N based on the following model:
) ,x,i) (y s μ ,x,i)+ ,y (y t λ exp( z(x)
1
p(y/x)=
∑
∑
j k
i k k i
i-1 j
j (1)
With:
∑ ∑
∑
y j k
i k k i
1 -i j
jt (y ,y,x,i)+ μ s (y,x,i)) λ
exp( = ) x (
z (2)
z(x) is the normalization factor that makes the sum of all probabilities equals to one. tj(yi-1,yi,x,i) represents a transition feature function of the entire observation sequence and the labels in positions i and i-1 in the label sequence. sk(yi,x,i) represents state feature function of the label in position i in the observation sequence. λj and μj are parameters which are estimated from training data.
Given this model defined in the Equation 1, the most probable labeling sequence y* for an input x, is:
) x / y ( p max arg =
y* y (3)
In the context of conceptual labeling and in order to take into account the dependence of the words (or group of words) of the same utterance, we can adopt several models that combine the n-grams of adjacent words. For each adopted CRF model, an estimate of underlying parameters is required based on a prior learning step. In order to achieve this, pretreatment and manual conceptual labeling sub-steps are required.
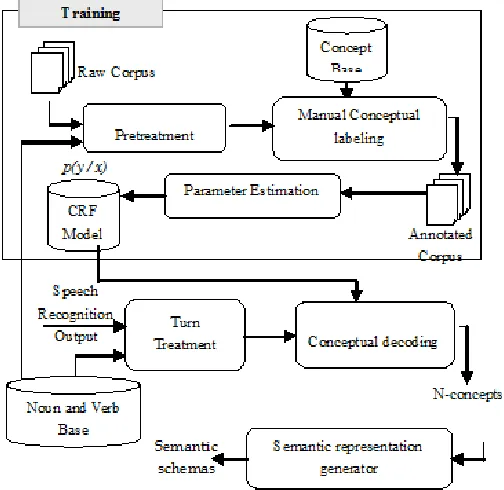
Fig. 1. CRF based method for speech understanding of TD
The CRF based method is presented in Fig 1. It includes the following steps:
− Pretreatment of the corpus: this sub-step is analogous to that carried out in the ontology-based method as it includes a morphological surface analysis of verbs and nouns, a spelling correction and synonymy analysis.
− Manual conceptual labeling: this sub-step consists in manually labeling the words or a group of words into concepts to generate the learning corpus.
− Parameter estimation: this step estimates the parameters λ_j and μ_k of the models in order to maximize the likelihood compared to a sample of annotated observations.
− Turn treatment: this sub-step is the same as that performed during learning in order to homogenize the learning and decoding data.
− Conceptual decoding: in this step, we exploit CRF models to infer the concept labels corresponding to the words of the utterance. It takes, as input, a processed utterance and provides, as output, a translation of the utterance into a conceptual language.
− Semantic representation generator: this step is responsible to generate a semantic scheme.
A semantic scheme is defined by its name, by one or more reference concepts of and a list of concepts. The scheme name is the type of the request, while the reference concepts facilitate the detection of the schema. The semantic schemes are instantiated by the words of the utterance. Fig 2 illustrates the general structure of a semantic scheme.
<Scheme_Name> <Reference_Concept/> <Concept1 /> <Concept2 /> .
.
</Scheme_Name >
Fig.2. General structure of semantic scheme
Following the study of our corpus, we determined a list of semantic schemes that respond to the utterances expressed by the client. It should be noted that an utterance can contain several requests identified through the reference concepts, which generates a set of semantic schemes. In the absence of a reference concept, the default scheme is selected. This last case occurs when an utterance depends on the dialogical context where the reference words are explained in the previous utterances of the dialogue. The step of generating the semantic representation results from a simple conversion from the conceptual representation to the corresponding scheme. If we consider the following example “ نم جرخي ساربسكإ نارت شاتقو سقافص / "When the Express train leaves Sfax?”. The result of the semantic annotation is as follows:
سقافص SfaAqis
نم min
جرخي yuxrij
ساربسكإ Ǎkspr aAs
نارت traAn
⧫
شاتقو wqtaAš Origin Semantic
Rel
Semantic Rel
Train_ Type
Train Dep_Hour_Req
<Scheme_Dep_Hour_Req> <Reference_concept> Dep_Hour_Req
</Reference_concept> <Origin>سقافص</Origin> <Destination />
<Train_Type>ساربسكإ<Train_Type/> <Day />
<Dept_Hour /> <Arrival_Hour />
</Scheme_Dep_Hour_Req>
Fig. 3. Instanciation of Dep_Hour_Req scheme
5
PATTERN
BASED
METHOD
FOR
SPEECH
UNDERSTANDING
Research work on MSA dialogue systems was conducted by Bahou [11]. This work proposes a method of literal understanding of the MSA within the SARF system (Arab Voice Information System for Railway Transport). SARF's method for speech understanding is part of the semantic approach and it is based on the formalism of case grammars for the generation of semantic schemas. The adaptation that we are looking for, does not correspond exactly to that proposed by Jabaian [8] which exploits the translation of resources to move from a reference system processing a source language (French) to another in a target language (Italian). The adaptation that we propose is to explicitly replace the resources of the SARF system with those of the TD and aims to compare the performance of the method we have proposed for understanding in TD with that translated from the MSA. The proposed adaptations are to replace lexical resources and treatments that are related to the MSA language without affecting the body of the proposed method based on patterns. During these adaptations, we exploited our TuDiCoI corpus to generate the lexicon, the patterns and the conceptual segments [23].
− Adaptation of lexical resources: The lexical database, extracted from the TuDiCoI corpus that we have integrated into the SARF system, contains the names base, compound word base and the verb base. We have also integrated a thesaurus built from these three bases. − Adaptation of conceptual segments: One of the
differences between TD and MSA lies in the structure of oral utterances. This distinction results mainly from the variation of the speakers and the spontaneity of the dialectal speech. To reflect this distinction, we have made changes to the conceptual segments created as part of the MSA. These changes created new conceptual segments by adding, deleting, or changing the order of concepts.
− Adaptation of treatments: Some additional treatments need to be considered in order to take into account the specificities of the TD in relation to MSA. The additional treatments, which we brought to the method, mainly concern the treatment of numbers and schedules because of the absence of certain markers in TD. It should be noted that the absence of these markers further complicates the task of detecting conceptual segments.
6
EXPERIMENTS
AND
RESULTS
The evaluation of speech understanding is a crucial task to compare the different proposed methods and measure their performance for the TD. In all the experiments conducted in
this work, we will use the same part of the TuDiCoI corpus for evaluation and adopt the same evaluation measures. The first evaluation consists in evaluating the first step of understanding. We check the aptitude of the developed methods to detect the correspondence between the concepts and the words of the same statement. We also present a second evaluation which aims to measure the overall performance of different methods in terms of acceptability of understanding. It is a question of measuring the accuracy of the semantic schemas generated by the four proposed methods.These evaluations are used in in the literature to evaluate automatic understanding. The first is partial (glass box) which evaluates the performance of the conceptual labeling step. While the second is interested in evaluating understanding module (black box) [24]. These approaches use assessment measures that have been developed to compare the understanding methods between them [25].
6.1 Partial evaluation:
Partial evaluation is used to evaluate the conceptual labeling step. For this we use the Concept Error Rate (CER). The CER makes it possible to compare the list of semantic reference concepts with the list of concepts emitted by the system according to the following equation:
concepts reference #
prediction concept
incorrect #
=
CER (5)
6.2 Global evaluation:
Global evaluation consists of seeking the overall performance of understanding in terms of the accuracy of the semantic scheme generated.
Bahou proposed other global assessment measures to calculate False understanding and Acceptable understanding. The False understanding consists of calculating the error rate in terms of utterances that have generated incorrect semantic representations [11].
With C.I indicates the number of utterances that generate incomplete semantic representations and C.E denotes the number of utterances that generate erroneous semantic representations.
Acceptable understanding is calculated by the following formula:
With C.C indicates the number of utterances that generate complete semantic representations and C.I denotes the number of utterances that generate incomplete semantic representations. It should be noted that these global assessment measures have been adopted to ensure the possibility of comparing the results obtained with the method based on patterns adapted from MSA to TD.
6.3 Training and test corpus
1978 TABLE VI
FEATURES OF TRAINING AND TEST CORPUS Training corpus Test corpus
Dialogues 1202 267
Turns 4131 906
words 13555 3217
Since we are interested in this work with literal understanding, we have classified all the turns of the test part into three types, according to the recommendation proposed by the ARPA community [26] namely the series A, D and X. Table VII presents the characteristics of these different series. This classification provides an overview of the types of statements contained in the test corpus.
TABLE VII
CHARACTERISTICS OF THE TEST SET OVER THREE SERIES A,D AND X
Client turn number
A D X Total
379 482 45 906
41.83% 53.21% 4.96% 100%
TABLE VIII
CHARACTERISTICS OF THE EVALUATION CORPUS
#Dialogues #User words
7 3217
Client turns
A D X Total
379 41.83%
482 53.21%
45
4.96% 906
The first set corresponds to context-independent client speech turns (Series A). This set contains oral utterances that do not relate to the dialogue history. While the second set corresponds to those dependent on the context (Series D). This set contains oral statements that relate to the dialogical context. The third set corresponds to out of context statements of the dialogue (X Series). This set includes the marginal utterances that have no relation to the domain. Table IX illustrates an example for each series’ type.
TABLE IX
EXAMPLE OF EACH SERIES TYPES
Series Transcription ⧫ / ◆Translittération / Traduction
A سلاك رييمرب سنوتل هيكت / tikiyh ltuwnis brumyiyr klaAs / Un
ticket pour Tunis première classe
D ؟ يه شادقب / b.qad~Aš hiya ? / Combien elle coûte ?
X تفشو تانرتنلأاع تلخد / dxalt ςalÂantirnaAt wušuft / Je suis
connecté à l'Internet et j'ai vu
6.4 CRF based method results
The best performances recorded by CRF models for concept labeling influenced the results of the evaluation of the semantic scheme generation stage. We note that the value of acceptable understanding is (94.48%). In addition, the false understanding obtained by the CRF-based understanding method is 21.53%. Results are illustrated in Table X.
TABLE X
GLOBAL EVALUATION RESULT OF CRF BASED METHOD
C.C C.I C.E false
Understanding
Acceptable Understanding
78.46% 16.01% 5.51% 21.53% 94.48%
6.5 Pattern based method results
The obtained results of speech understanding using pattern based method is very low compared to previous results. In fact, we obtained 73.32% as acceptable understanding and 47.19% as false understanding. All results are reported in Table XI.
TABLE XI
GLOBAL EVALUATION RESULT OF PATTERN BASED METHOD
C.C C.I C.E false Understanding
Acceptable Understanding
52.81% 20.51% 26.68% 47.19% 73.32%
TABLE XII
COMPARISON BETWEEN THE DIFFERENT PROPOSED METHODS
Partial evaluation Global evaluation
Recall Precisio
n F-mesure CER False Acce. Pattern
based 54.59% 68.94% 60.93% 24.59% 47.19% 73.32% CRF
Finally, type D statements produce a misidentification of the speaker's request information since they represent statements that depend on the dialogical context.
7
CONCLUSION
This paper compared two methods for speech understanding of the Tunisian dialect. We noticed that the results of the pattern-based method are unsatisfactory because of the complexity of modeling all possible patterns for dialect statements. We found that the CRF models are able to model possible utterance structures to detect domain concepts. They are also able to correlate concepts to find the best labelling. In summary, we can conclude that the CRF are robust for speech understanding in limited task. These models make it possible to overcome the lack of linguistic resources in the case where the target language is under-resourced language. Indeed, the learning of CRF models is performed on a corpus of relatively small size.
8
REFERENCES
[1] H. Aust. M.Oerder. F. Seide and V. Steinbiss. (1995. November). The Philips automatic train timetable information system. Speech Communication. volume 17 (Issue 3-4). pp 249–262.
[2] F. Bechet, A. Nasr, Robust Dependency Parsing for Spoken Language Understanding of Spontaneous Speech. In proceeding of the international speech communication association (Interspeech), pp.1039-1042, 2009.
[3] D. Lee, M. Jeong, K. Kim, S. Ryu, and G. Lee, Unsupervised Spoken Language Understanding for a Multi-Domain Dialog System. IEEE transactions on audio speech and language processing, vol. 21, 2013. [4] L. Lamel, S. Rosset, J. L. Gauvain, S. Bennacef, M. Garnier-Rizet, and B. Proust, The LIMSI-ARISE System. Speech Communication, vol. 31, pp.339– 354, 2000.
[5] Y. Y. Wang and A. Acero, Discriminative Models for Spoken Language Understanding. In proceeding of international conference on spoken language processing (ISCA), pp.1766-1769, 2006.
[6] S. Jamoussi, Méthodes Statistiques pour la Compréhension Automatique de la Parole. Thèse de Doctorat, université Henri Poincaré, 2004.
[7] V. Zue, S. Seneff, J. Polifroni, M. Phillips, C. Pao, D. Goddeau, J. Glass and E. Brill, Pegasus: A Spoken Language Interface for On-Line Air Travel Planning. Speech Communication, vol. 15, pp.331-340, 1994. [8] B. Jabaian, Systèmes de Compréhension et de
Traduction de la Parole : Vers une Approche Unifiée dans le Cadre de la Portabilité Multilingue des Systèmes de Dialogue. Thèse de doctorat, Université d’Avignon, 2012.
[9] M.-J. Meurs, F. Duvert, F. Béchet, F. Lefevre, et R. de Mori, Annotation en Frames Sémantiques du corpus de dialogue MEDIA. Dans les actes de la conférence sur le traitement automatiques des langues naturelles (TALN), 2008.
[10]J. Trione, F. Bechet, B. Favre, and A. Nasr, Rapid FrameNet annotation of spoken conversation transcripts. Joint ACL-ISO Workshop on Interoperable Semantic Annotation, 2015.
[11]Y. Bahou, Compréhension Automatique de la Parole Arabe Spontanée : Intégration dans un Serveur Vocal Interactif. Thèse de doctorat, Université de Sfax, 2014.
[12]L. H. Belguith, Y. Bahou and A. Ben Hamadou, Une Méthode Guidée par la Sémantique pour la Compréhension Automatique des Énoncés Oraux Arabes. International journal of information sciences for decision making (ISDM), vol. 35, 2009.
[13]C. J. Fillmore, The Case for Case. Universals in Linguistic Theory, pp.1-90, 1968.
[14]Deoras, G. Tur, R. Sarikaya, and D. Hakkani-Tür, Joint Discriminative Decoding of Words and Semantic Tags for Spoken Language Understanding. IEEE transactions on audio, speech, and language processing, vol. 21, pp.1612-1621, 2013.
[15]S. Mejri. M. Said and I. Sfar, Pluringuisme et diglossie en Tunisie. In Synergies. volume 1. pp. 53-74, 2009. [16]Bouzemni, Linguistic Situation in Tunisia: French and
Arabic code switching. Interlinguistica, vol. 16, pp.217-223, 2005.
[17]Ouerhani, Interférence entre le Dialectal et le Littéral en Tunisie: Le Cas de la Morphologie Verbale. Synergies Tunisie, vol. 1, pp.75-84, 2009.
[18]J. M. Benedi, E. Lleida, A. Varona, M. J Castro, I. Galiano, R. Justo, I. Lopez de Letona and A. Miguel, Design and Acquisition of a Telephone Spontaneous Speech Dialogue Corpus in Spanish: Dihana. In proceeding of the international conference on language resources and evaluation (LREC), pp.1636– 1639, 2006.
[19]C. D. Martínez-Hinarejos, J. M. Benedí, and R. Granell, Statistical Framework for Spanish Spoken Dialogue Corpus. Speech communication, vol. 50, pp.992-1008, 2008.
[20]N. Alcacer. J. Benedi. F. Blat. R. Granell. C.D. Martinez. F. Torres. "Acquisition and labeling of a spontaneous speech dialogue corpus". In Proc. of 10th International Conference on Speech and Computer (SPECOM). Patras. Greece. 2005. pp. 583–586
[21]C. Raymond and G. Riccardi, Generative and Discriminative Algorithms for Spoken Language Understanding. In proceeding of Interspeech, pp.1605-1608, 2007.
[22]S. Hahn, M. Dinarelli, C. Raymond, F. Lefèvre, P. Lehnen, R. De Mori, A. Moschitti, H. Ney, and G. Riccardi, Comparing Stochastic Approaches to Spoken Language Understanding in Multiple Languages. IEEE transaction on audio, speech, and language processing, vol. 19, pp.1569‑1583, 2011. [23]W. Neifar, Y. Bahou, M. Graja and M. Jaoua,
Implementation of a Symbolic Method for the Tunisian Dialect Understanding. In proceeding of the international conference on arabic language processing (CITALA), 2014.
[24]R. Zajac, S. Helmreich and K. Megerdoomian, Black-Box/Glass-Box Evaluation in Shiraz. In proceeding of the workshop on machine translation evaluation at the international conference LREC, 2000.
1980 Media Evaluation Campaign for Literal
Understanding. In proceeding of the international conference on language resources and evaluation (LREC), pp.2054-2059, 2006.