Recurring Queries Optimization Using
Mapreduce Model
E. Subramanian, C. S. Sanoj
Abstract : In information rich domain, generic cluster computing has an eminent growth. The generic cluster computing environment consists of Hadoop and MapReduce consequently as a part of it which has a lesser efficiency by means of analytics of data. So the Recurring queries are deployed on information rich domain, generic cluster computing for data analytics. This survey paper analyzes various optimization strategies used for recurring queries. The MapReduce recurring query model explores the impact of the efficiency of the recurring queries. MapReduce consistent window slice model analyzes reuse of recurring queries which trim down the repeated data from the information rich domain. MapReduce late scheduling model analyzes the improvement of data processing resource computation in the generic cluster computing. The exploited Hadoop schedulers are used to manage large clusters of nodes and organize the order of users and their execution of tasks. An analysis done on various scheduling methods based on implementation idea, its merits and demerits, context-aware scheduler outperforms among exploited schedulers.
Keywords : Big data, Hadoop schedulers, MapReduce, Recurring queries
—————————— ——————————
1
INTRODUCTION
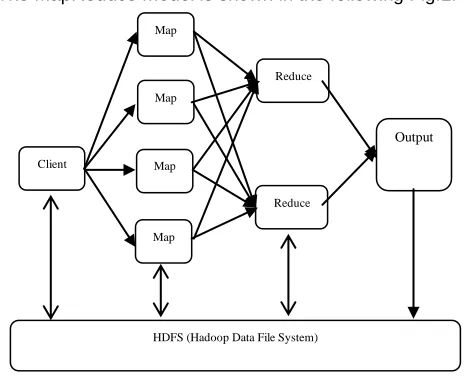
In Hadoop framework, MapReduce is the core component for data processing. It facilitates the splitting of the input data set into a several parts and executes a program at once on all data parts in parallel. It implies two separate distinct tasks. Primary is the ‗Map‘ operation, which takes a collection of data and converts it into another set of data, where individual parts are wrecked down into key / value pairs. The ‗Reduce‘ operation combines those data tuples based on the key and consequently modifies the value of the key. The abundance of data and the availability of Information rich data processing systems are available under this Hadoop framework, for example, the MapReduce and Hadoop platforms have enabled most applications to explore their data using Information rich analytical tasks that were not possible before. With the speedy growth of information technology, all kinds of data pertaining to human community increasing exponentially. Information rich data analytics such as Online advertisement, Log processing, Network intrusion detection, the conventional information processing and computing technology has been difficult to deal with in big data environment. In recent years, the ability to effectively process such huge amounts of data has become a key factor in dynamic business decisions. MapReduce model has recently emerged as a new paradigm for Information rich data analytics due to its high scalability, fault tolerance, and flexible programming model. Many famous companies such as Google, Amazon, Face book, picked up MapReduce model [1], and its open source implementation called YARN (Yet Another Resource Negotiator), to perform Information rich analytics applications on evolving big data.
The MapReduce model is shown in the following Fig.1.
Fig. 1. MapReduce Model
Hadoop is a widely used platform for such Information rich applications because of its scalability, flexibility, and fault tolerance. The scalability and distributed processing are not enough to achieve high performance. Instead, the system needs to be highly optimized for various query types. In this survey, among several queries one type of queries, called ‗Recurring queries‘, which is a very common in most Hadoop based Information rich applications, yet not supported effectively by the modern systems gets optimized. In complex data analysis applications, such as log processing of Internet groups, news updates and abstract social networking service promotion, Recurring queries [13] often appear, the features of the system are periodically updating massive data, and must quickly real-time query processing. On the other hand, the same query analysis periodically performed on the changing data needs. In those cases, the query value depends on the granularity of data by user interest, so, recurring queries periodically executed again and again that it may continue to a few hours or a few days, or even months. The temporal characteristics of the data query in the real-time environment of the recurring queries are required for the existing computing
HDFS (Hadoop Data File System)
Output
Reduce Client
Map Map Map Map
Reduce
______________________
E. Subramanian, Department of Information Technology, AMET
University, Chennai, India. Email: [email protected]
C. S. Sanoj, Department of Computer Science and Engineering, Sri
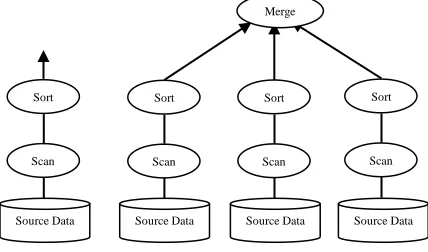
model. The characteristics of Recurring queries under the big data environment are massive data, high speed, variety of data types, low value density. Thus it must attempt the challenges between the Information rich query load and users of a scalable real-time increasingly dependent. As a result, recurring queries has become a focus very recently in the big data research [2]. Conventional databases often use query reuse to improve query efficiency. Data reuse technology makes full use of the relationship between the queries, it reduce the amount of system storage, shorten the user response time. However, due to its lack of scalability, user only rely on a single server, in the big data analysis and for the moment the computing resources are often exhausted, incompetent frequent query load pressure. To manage the urgent needs, the MapReduce distributed parallel computing framework to build scalable database gets introduced. The system supports the standard relational tables and SQL (Structured Query Language), at the same time for the end user the data is actually stored on multiple machines transparently. Many of these systems are based on the results of the pioneering research on the projects. In the late 1980s, the research direction of parallel database technology gradually turned to the general parallel machine and the key point is the physical organization, operation algorithm, optimization and scheduling of parallel database. As early as the mid of 80‘s in the 20th century, parallel DBMS (Database Management Systems) project began to explore through a high speed Internet connection with independent CPU based on a new parallel database schema. The computer processing power is increased by adding as many CPUs together. This procedure is called as virtualization. Multiple CPUs are added together to the client system which can improve the performance of the system. No specific rules to be followed for adding the number of CPUs. Multi-core processors have the capability to solve the complex processing. This method is used for heavy load process. The schema consists of main memory and disk share-nothing node cluster, as shown in Fig. 2.
Fig. 2. The parallel database Architecture
2 LITERATURE SURVEY
2.1 Parallel Database Research
Ce Zhang et al. [3] discussed the typical approach to large data processing is to use a parallel database system. Parallel database system is in the massively parallel processing system high performance database system and cluster parallel computing environment is established on the
foundation. This system is composed of many loosely coupled processing units, which refers to the processing unit rather than the processor. Each unit has its own private CPU (Central Processing Unit) resources, such as bus, memory and storage. This structure is the largest non-shared resources.
2.2 MapReduce Model
Nidhi Tiwari et al. [5] stated that, In 2004, after studying the data storage and parallel processing of the web, Google researchers proposed the MapReduce computing model. When dealing with large data, only need to run on an ordinary computer, need not to be like parallel database system needs elevated servers, whose cost is high. In 2008, Apache launched the Hadoop project based on the MapReduce framework. In October 2013 second generation Hadoop, namely YARN framework for release, big data analysis provides a new efficient solution of model and method, especially its strong flexibility provides a rich interface for the scheduling and reuse strategies implemented in Hadoop. The available job tracker will be responsible for a task in which several tasks gets split into small and assigns each task nodes in the Hadoop cluster and the implementation of real-time tracking of each computing node task. The task scheduling in Hadoop uses the FIFO (First In First Out) scheduling strategy. For data stream segmentation, MapReduce based on panel window method proposed. The method will equal to the size of all data segmentation. But this is used to divide the input data source for a frequent query, query optimization of data which features frequent decisions.
2.3 Query Reuse
Tomasz Nykiel et al. [14] have addressed as an important method to improve the performance of database query, query reuse technology is a hot research topic in database field. The cost was calculated by means of two kinds of strategies, one by the physical model, chemical balance model is another one, and then chose the low cost physical strategy. The self organization tuple reconstruction strategy based on Cracker Map gets introduced. The defect of this approach is that the maintenance cost of Cracker Map was too high when processing large data, which in turn affects the query efficiency. In addition, the MapReduce Share based has been proposed based on the MapReduce model in order to achieve shared scan, Map output stage sharing, Map share and share the Map process with a certain improvement. However the defect is shared time only for single table queries, and the model is required before tasks requires query consequently analysis for the entire query task was done. The task group meets the sharing condition, the high cost of system resources. The dynamic adjustment of the physical and chemical set is carried out on the static algorithm, but its adjustment strategy is too complicated, and the efficiency is not ideal. Restore system for the MapReduce task of the intermediate results generated by the storage reuse management. It reuses management work with MapReduce and Reduce Output Map materialized, and then through the subsequent task to determine whether reuse or not, thus avoiding redundant task scheduling. The current recurring queries have not yet been thoroughly studied, especially in the
Source Data Source Data Source Data Scan
Sort
Scan Sort
Scan Sort Merge
distributed environment of MapReduce how to conquer the increasing complexity of Information rich workloads.
3 FRAMEWORK
3.1 Recurring Query Model
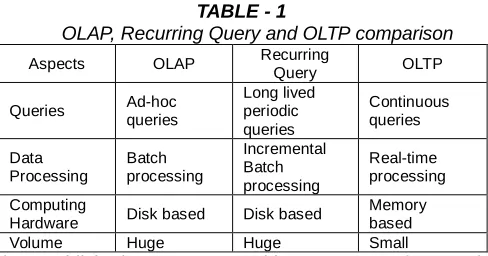
In MapReduce parallel computing environment, recurring queries is the data set of disk resident, according to the specified time period to execute batch query tasks. It means the data and datasets stored in HDFS. In each execution, a query bounds its computations to a time-based window over the datasets. Therefore, a recurring query is specified by two configuration parameters, Win and Slide. The window ‗Win‘ specifies the scope of data to process while the slide ‗Slide‘ specifies the frequency of execution. Once the query with Win and Slide gets registered in Hadoop, it periodically triggers the execution of the query according to the parameters Win and Slide. The growing inputs of the queries are consumed from a specific HDFS directory and the outputs are regularly produced to another HDFS directory. The differences among
OLAP (On Line Analytical Processing), Recurring query and OLTP (On Line Transaction Processing) environments was
observed from the following Table - 1.
TABLE - 1
OLAP, Recurring Query and OLTP comparison
Aspects OLAP Recurring
Query OLTP
Queries Ad-hoc queries
Long lived periodic queries
Continuous queries
Data Processing
Batch processing
Incremental Batch processing
Real-time processing
Computing
Hardware Disk based Disk based
Memory based
Volume Huge Huge Small
It is established to cover a wide spectrum of execution granularities. In specific, it is specified by a window size and execution frequency. The MapReduce parallel computing environment is designed to efficiently handle recurring queries through a best effort proactive execution mechanism, where it adaptively notice fluctuations in the data rate between different executions and proactively starts performing partial processing to deliver results. The data records within each file will have their own timestamps. The time ranges covered by the batch files do not overlap and they are in order. It optimizes the consecutive executions of Recurring queries through disk based caching and incremental processing. Even ad-hoc queries can benefit from the caching of the intermediate data to avoid processing and shuffling of overlapping data segments again and again across adjacent windows. The aim is to finish the execution of a Recurring query before the next execution. We define the recurring queries model as follows, presume that there is a user query task set Ω (Q) = *q , q , … . , q + each recurring queries is defined as a tuple q = (ω, σ) , Where ω represents the amount of data processing of the specified size, and σ is query execution frequency. Query processing time is the key factor that affects the efficiency of the recurring queries. We presume that the batch file contains the tuple set is not overlapping for analysis purpose. Thus, that there a set of input files exists for the data query that contains all the tuple
T (F) = *f , f , … , f + and
,T(i), T(f)-, ,T(f ), T(f )-, … , ,T(f ), T(f )- represents the corresponding time, where {∃[T(q), T(q)]| q, q ∈ Ω (Q), T(q) < 𝑇(q)+ for time to meet the conditions. Let f
denotes a time sequence, but there is no order constraint between the tuples in each file. Then there are two consecutive batch of execution tasks E and E, and corresponding execution time are T and T, provided that T, T ∈ T | T < T|. The input data mode of this system is the HDFS file form of a number of batches, there are time series respectively as T(f ), T(f ), … , T(f ) which corresponding to the File sequence T(f ), T (f), … , T (f ). In this the conditions areT < T (f), T (f ), … , T(f ) < T. The analysis of this model in big data applications represents Recurring queries in general, to meet the most real environment characteristic analysis system. For example, in the log query processing system, process per one hour from a cluster of machines to collect the latest log files, the batch file upload to the HDFS as a new process query task.
3.1.1 Fair Scheduling
pool while utilizing resources efficiently when these pools don‘t contain jobs.
3.2 MapReduce Consistent Window Slice Model
This model analyzes how recurring queries on the MapReduce, slice the input data source effectively to reduce disk Input and output operation, so as to reduce the cost of whole query task. This is for sharing window-based joins includes slicing window states of a join operator into smaller window slices, forming a chain of sliced window joins from the smaller window slices consequently reducing by pipelining a number of the sliced window joins. This model further pushes the selections down into chain of sliced window joins for computation sharing among queries with different window sizes. The chain build-up of the sliced window joins includes chain of the sliced window joins with respect to one of memory usage or processing usage. It comprises the steps like slicing window states of a shared join operator into smaller pieces based on window constraints of individual queries, forming multiple sliced window joins with each joining a distinct pair of sliced window states, and pushing down selections into any one of said formed multiple sliced window joins responsive to computation considerations. The slicing is done using a sliding window to join all into a chain of pipelined sliced joins for a chain build-up of said sliced joins in response to at least one of memory or processor considerations. We define the slice window model as follows: Let windows 𝑊 = ∃𝑊 | 𝑆(𝑊) = 𝑤 can be decomposed into a set of n slices *𝛹(𝑅) = *𝑠, 𝑠 , … , 𝑠 | 𝑆𝑡𝑎𝑟𝑡(𝑠) = 0, 𝐸𝑛𝑑(𝑠) = 𝑆𝑡𝑎𝑟𝑡(𝑠 )+ . The size of each partition is a collection of 𝑠 is expressed as *𝛩(𝑅) = *𝑟, 𝑟, … , 𝑟 | ∀1 ≤ 𝑖 ≤ 𝑛, 𝑟 = 𝐸𝑛𝑑(𝑠) − 𝑆𝑡𝑎𝑟𝑡(𝑠)+ .
3.2.1 Capacity Scheduling
The design of capacity scheduling is very similar to fair scheduling. But it uses queues instead of pool. Each queue is assigned to an organization and resources are divided among these queues. The scheduler puts jobs into multiple queues in accordance with the conditions, and allocates certain system capacity for each queue. If a queue has heavy load, it seeks unallocated resources, then makes redundant resources allocated evenly to each job. For maximizing resource utilization [10], it allows re-allocation of resources of free queue to queues using their full capacity. When jobs arrive in that queue, running tasks are completed and resources are given back to original queue. It also allows priority based scheduling of jobs in an organization queue. The capacity scheduler allows users or organization to simulate a separate MapReduce cluster with FIFO scheduling for each user or organization.
3.2.2 Self-Adaptive MapReduce Scheduling
A Self-Adaptive MapReduce scheduling is for heterogeneous environments. It improves MapReduce by saving execution time and system resources. It defines fast nodes and slow nodes to the nodes which can finish a task in a shorter time and longer time than most other nodes. On MapReduce, slow tasks delay the execution time of an entire job. In heterogeneous clusters, nodes require different times to accomplish the same tasks due to their differences, such as computation capacities, communication, architectures,
memory, and power. This can be improved further in terms of in two aspects. First, it will focus on how to account for data locality when launching backup tasks. Second, it considering a mechanism to incorporate that tune the parameters should be added.
3.3 MapReduce Late Scheduling Strategy Model
In the same computation resource, data and query tasks are the decisive factors that affect the performance of MapReduce cluster computing. Network bandwidth in MapReduce cluster is much smaller than that of nodes cluster , and the network transmission delay is critical error. Scientific and efficient parallel scheduling will greatly increase the computing network Input and output of the cluster. If the data was achieved in scheduling at the nodes that are close in distance, thus, the computation will be the fastest and efficient while the required data of the task in a job have been all scheduled on the node before, without data transmission through the network. However, at several existing Internet cloud computing platforms the reality is often unsatisfactory. It is good enough that the job run in the same machine frame in most cases. Accordingly, this was the reason why the MapReduce proximal scheduling model and the MapReduce late scheduling strategy are proposed. The basic of MapReduce proximal nodes is defined as follows: Let
Ω (𝑄) = *𝑞 , 𝑞 , … . , 𝑞 + is a set of recurring queries and
𝑁 = *𝛾, 𝛾 , … . , 𝛾+ is MapReduce node set. The query input file which is needed by the recurring queries 𝑞 is denoted by 𝐼𝑛𝑝𝑢𝑡(𝑞), the HDFS file of the node 𝛾 is denoted by
𝐻𝐷𝐹𝑆(𝛾 ). If *∃ 𝛾 ∈ 𝑁, ∃𝑞 ∈ Ω (𝑄)|𝐼𝑛𝑝𝑢𝑡(𝑞) ⊂ 𝐻𝐷𝐹𝑆(𝛾) +, the task of recurring queries 𝑞 is the proximal node task. Suppose that the size of computing cluster of MapReduce data node is denoted by 𝑀, each node‘s CPU core number is denoted by 𝐻, then the total computing power can be simply expressed as 𝑆 = 𝑀 ∗ 𝐻. Let the set of recurring queries tasks Ω (𝑄) = *𝑞 , 𝑞 , … . , 𝑞 + , where 𝑞 the proximal node task among 𝑁𝑜𝑑𝑒 .
3.3.1 Context-Aware Scheduling
A Context-Aware scheduling uses the existing heterogeneity of most clusters and the workload mix, proposing optimizations for jobs using the same dataset. Although still in a simulation stage, this approach seeks performance gains by using the best of each node on the cluster. The design is based on two key factors. First, a large percentage of MapReduce jobs are run periodically and roughly have the same characteristics regarding CPU, network, and disk requirements. Second, the nodes in a Hadoop cluster become heterogeneous over time due to failures, when newer nodes replace old ones. The scheduler is designed to undertake this, as taking into account the job characteristics and the available resources within cluster nodes.
4 RESULT ANALYSIS
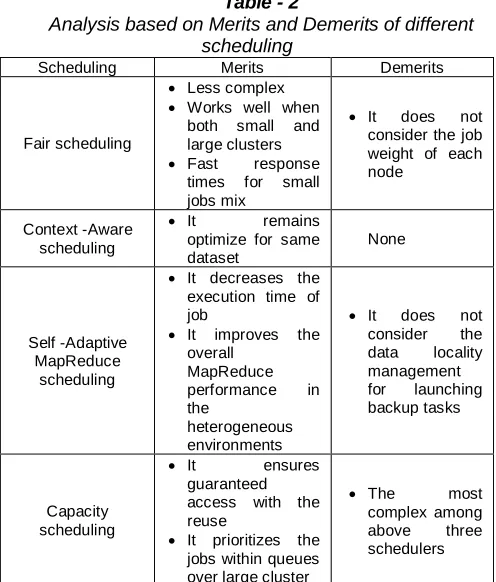
Table - 2
Analysis based on Merits and Demerits of different scheduling
Scheduling Merits Demerits
Fair scheduling
Less complex
Works well when both small and large clusters
Fast response times for small jobs mix
It does not consider the job weight of each node
Context -Aware scheduling
It remains optimize for same dataset
None
Self -Adaptive MapReduce
scheduling
It decreases the execution time of job
It improves the overall
MapReduce performance in the
heterogeneous environments
It does not consider the data locality management for launching backup tasks
Capacity scheduling
It ensures guaranteed access with the reuse
It prioritizes the jobs within queues over large cluster
The most complex among above three schedulers
Among all the three steps in the scheduling, context-aware scheduling remains the best in classifying the jobs among other scheduling, then it optimizes the datasets in classification of nodes among all other scheduling and finally, it leads and fulfils if the job demands come under different circumstances among all other scheduling.
5 CONCLUSION
The targeted optimization of recurring queries efficiency by using MapReduce recurring queries model was dealt at first. Secondly, the MapReduce consistent window slice model proposed to ensure how recurring queries on the MapReduce, slice the input data source effectively to reduce disk Input and output operation, so as to reduce the cost of whole query task. Thirdly, MapReduce late scheduling strategy model designed to enhance the data transmission and optimizing the computation resource scheduling in MapReduce cluster. Finally, in terms of data scheduling, the schedulers ensures the guarantee for reuse over the cluster environments.
REFERENCES
[1] Hari Singh, Seema Bawa, ―A MapReduce based scalable Discovery and Indexing of Structured Big Data‖, Future Generation Computing Systems, 73, pp.32 - 43, 2018
[2] Shanthi H.J., ―A study on Urban planning using Big Data based on IOT‖, International Journal of Scientific Research and Review, 7(9), pp.122 - 130, 2018
[3] Ce Zhang, Arun Kumar, ―Materialization Optimizations for Feature Selection Workloads‖, ACM Transactions on Database Systems, 41(1), pp.2:1 - 2:32, 2016
[4] Archenaa J., Anita E.A.M., ―Interactive Big Data Management in Healthcare Using Spark‖, In: Vijayakumar
V., Neelanarayanan V. (eds) Proceedings of the 3rd International Symposium on Big Data and Cloud Computing Challenges (ISBCC – 16‘). Smart Innovation, Systems and Technologies, vol 49. Springer, Cham, 2016
[5] Nidhi Tiwari, Santonu Sarkar, Umesh Bellur, Maria Indrawan, ―Classification Framework of MapReduce Scheduling Algorithms‖, ACM Computing Surveys, 47(3), pp.49.1 - 49.38, 2015
[6] Daniel Reed, Jack Dongarra, ―Exascale Computing and Big Data‖, Communications of the ACM, 58(7), pp.56 - 68, 2015
[7] Jihoon Son, Hyoseok Ryu, Sungmin Yi, Yon Dohn Chung, ―SSFile: A novel column-store for efficient Data analysis in Hadoop based Distributed Systems‖, Information Sciences, 316, pp.68 - 86, 2015
[8] Michael Stonebraker, ―A valuable lesson, and whither Hadoop?‖ Communications of the ACM, 42(1), pp.18 - 19, 2015
[9] Kirubakaramoorthi R., Arivazhagan D., ―Analysis of Cloud Computing Technology‖, Indian Journal of Science and Technology, 8(21), pp.1 - 3, 2015
[10] Chulyun Kim, Kyuseok Shim, ―Supporting set-valued joins in NoSQL using MapReduce‖, Information Systems, 49, pp.52 - 64, 2015
[11] Kottalanka Srikanth, Arivazhagan D., ―Genetic scheduling to optimize Resource utilization for Hospitals‖, International Journal of Computer Engineering and Technology, 5(4), pp.126 - 137, 2014
[12] Alexander Thomson, Thaddeus Diamond, Shu-Chun Weng, Kun Ren, ―Fast Distributed Transactions and Strongly Consistent Replication for OLTP Database Systems‖, ACM Transactions on Database Systems, 39(2), pp.11.1 - 11.28, 2014
[13] Ganeshkumar K., Arivazhagan D., ―Implecation of Cyber Security, Cyber Forensics and Online Privacy in Organizations‖, International Journal of Applied Engineering Research, 9(15), pp.2981 - 2990, 2014 [14] Tomasz Nykiel, Michalis Potamias, Chaitanya Mishra,