An Adaptive and Distributed Clustering Scheme for
Wireless Sensor Networks
Xinguo Wang, Xinming Zhang, Guoliang Chen, Shuang Tian Department of Computer Science and Technology
University of Science and Technology of China Hefei, 230027, P.R. China
[email protected] Abstract—In recent years, wireless sensor networks have gained
extensive attentions due to their bright future in military and civil fields. Innovative routing techniques that can prolong the network lifetime are highly demanded. Clustering is an effective technique in applications of periodical data gathering. Most clustering schemes make the common assumption that sensors are uniformly dispersed within an area. In this paper, we propose an adaptive and distributed clustering scheme (ADCS) for wireless sensor networks, which can work very well in both uniform and non-uniform scenes. Our approach elects nodes with comparatively more residual energy and more neighbors as the cluster heads. In the cluster formation phase, the plain nodes choose to join in cluster considering both distance and load balance. ADCS can generate an even distribution of the clusters, which helps to prolong the network lifetime. Simulation results show that ADCS outperforms LEACH significantly by prolonging the network lifetime over 40% in uniform scenes and 75% in non-uniform scenes respectively.
Keywords-adaptive and distributed; clustering scheme; energy efficient; routing protocol; wireless sensor network
I. INTRODUCTION
Recent rapid advances in MEMS technologies, wireless communications, and digital electronics make the deployment of large scale wireless sensor networks (WSN) feasible. Wireless sensor networks have attracted more and more attentions for their wide-range potential applications including environmental monitoring, target tracking and military [1]. Wireless sensor networks usually contain thousands or millions of sensors, which are randomly and widely deployed. Sensors are powered by battery, which is impossible to get recharged after deployment. Thus, energy efficiency is an important issue in sensor networks. Since routing consumes a lot of energy, an efficient routing scheme in sensor networks is highly required.
For periodical data gathering applications, mostly adopted routing technique is clustering scheme and data aggregation. LEACH [2], the first clustering protocol, proposes a two-phase mechanism that the plain nodes will turn off completely RF until their pre-allocated time slot. LEACH has a drawback that the clusters are not evenly distributed due to its randomized rotation of cluster heads. PEGASIS [3] improves the performance of LEACH and prolongs the network lifetime greatly with a chain topology. The delay is significant
although the energy is saved. HEED [4] selects cluster heads through O (1) time iteration according to some metric and adopts the multi-hop communication to further reduce the energy consumption. EECS [5] elects cluster heads with more residual energy through local radio communication while achieving good cluster heads distribution. Most clustering schemes make the common assumption that sensors are uniformly dispersed within an area. However, the topology may be non-uniform in factual applications. Obviously, the area where the node density is higher needs more cluster heads than other areas for load balance.
In this paper, we propose and evaluate an adaptive and distributed clustering scheme (ADCS) for periodical data gathering applications. In the cluster head election phase, a number of candidate nodes are elected and compete for cluster heads according to the node residual energy and node density nearby. The method is fully localized and produces an even distribution of cluster heads approximately. In the cluster formation phase, the plain nodes choose to join the cluster according to both distance and load balance. ADCS is absolutely distributed, energy efficient and adaptive to all kinds of topology. The simulation results show that it prolongs the network lifetime to as much as 145% of LEACH in uniform scenes and 175% in non-uniform scenes respectively.
The remainder of this paper is organized as follows. Section II outlines the issues of clustering scheme. Section III describes the details of ADCS and Section IV analyzes the performance of ADCS. Section V gives simulation results and compares it with LEACH. Section VI gives the conclusion and future work.
II. PROBLEM STATEMENTS
A. Network Model
To be simplification, we make some reasonable assumptions about network as follows:
1) All sensors and BS are stationary after deployment and the former always have data to send to the latter.
2) We just consider the energy consumed by wireless communication and data aggregation.
3) Sensors are highly connected to each other and the communication is constraint within a single-hop.
4) Sensors can compute the distance based on the received signal strength if the transmission power is given.
5) Sensors can adjust the transmission power according to the desired transmission range.
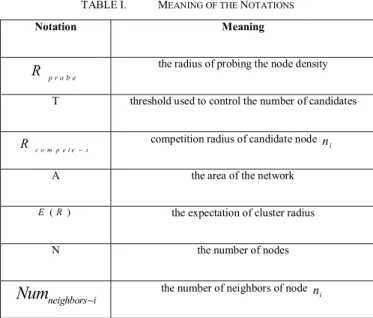
TABLE I. MEANING OF THE NOTATIONS
Notation Meaning
p r o b e
R the radius of probing the node density
T threshold used to control the number of candidates
c o m p e t e i
R − competition radius of candidate node ni
A the area of the network
( )
E R the expectation of cluster radius
N the number of nodes
neighbors i
Num
− the number of neighbors of nodei n
We consider the network lifetime as the interval from the network initialization till the first node dies out. Because once a node drains its energy, some area of the network won’t be covered or monitored any longer. Moreover, the simulation shows that the other nodes get down quickly, followingthe first dead node if node is balanced. We don’t make any assumption about the node density of the network. Our scheme can be adaptive to the scenes that the nodes are arbitrarily dispersed in a fixed area.
B. Energy Model
In this paper, we adopt the first radio model presented in [2], [6]. The energy consumption
E l d
T( , )
of transmittingl bit
−
data between two nodes separated by a distance ofd
meters is: 2 4,
(1)
( , )
( )
( , )
,
(2)
elec fs o T Tx elec Tx amp elec mp ol E
l
d d d
E l d E
l E
l d
l E
l
d d d
ε
ε
− −
×
+ ×
<
=
+
=
×
+ ×
≥
The first item presents the energy consumption of radio dissipation, while the second presents the energy consumption of amplifying radio. The distance between plain node and cluster head is commonly less than
d
o meters, so we adopt equation (1) to compute the transmission energy consumption for the plain node. For transmission to the base station, we adopt equation (2).To receive a
l bit
−
data, the radio expends:( )
(3)
R elec
E l
= ×
l E
Additionally, the operation of data aggregation consumes
da
E
energy. C. Scheme GoalsIt is crucial to elect
k
opt [7] cluster heads with good distribution at low cost. To prolong the lifetime of the network, we introduce a novel adaptive and distributed clustering scheme (ADCS). Specific goals in ADCS are as follows: 1) load balance: balance the load among the sensors, especially among the cluster heads; 2) low control load: the final goal is to gather data from the environment, so it is advisable to reduce the control load to extend the time of monitoring; 3) fully distributed scheme: Sensors interact with each other through localized communication; 4) adaptive scheme: our approach should be adaptive to all kinds of topologies. For example, Fig.1 shows that the elected cluster heads distribute evenly even in non-uniform scene.Figure 1. Even distribution of cluster heads
III. ADCSDETAILS
ADCS is a LEACH-like clustering scheme, where the network is partitioned into
k
opt [7] clusters with one cluster head in each cluster. We implement a probe-phase to probe the node density nearby before the first round begins. It helps the network form clusters with good distribution at low cost.A. Probe Node Density
In this phase, each node sends a “hello” message to all nodes within
R
probe and the TTL of messageis set to one. In this way each node can compute the number of its neighbors (nodes withinR
probe). An even distribution of cluster can be sought even in non-uniform scenes by taking the local node density into consideration. And there is less chance for the marginal nodes dispersed in sparse areas to be elected as the cluster head because of their low node densities nearby. We just probe node density for one time in the lifetime of the network based on: 1) we consider the network is dead when a node runs out of its energy as mentioned above; 2) the node density doesn’t vary until a node is dead; 3) the probe phaseconsumes a lot of energy. The sum of this kind of message is O (N). We will give the computation of
R
probe in section IV.B. Cluster Head Election
In this phase,
k
opt cluster heads are elected. Nodes become CANDIDATE nodes with a probability T and then broadcast the COMPETE_MSG to advertise their wills. Each CANDIDATE node receives messages and checks whether there is a CANDIDATE node with more residual energy within its range ofR
compete i− .R
compete i− is converse to the number of its neighbor nodes. Once the CANDIDATE node finds a more powerful CANDIDATE node in its competition range, it will give up the competition immediately. Otherwise, it will be elected as CLUSTER HEAD in the end. The specific process is given in Algorithm 1. It is not hard to prove that there is only one cluster head in the range of eachR
compete i− . And it is more probable for candidate nodes in the dense area to compete successfully than other areas, because their competition ranges are smaller. ; 1: ; 2: (0,1); 3: ( ) 4: ; 5: _ ( , ); 6: ( exp ) 7: _ ; 8: . i j n N state PLAIN Random if T then state CANDIDATE broadcastCOMPETE MSGid E while Timerhasnot ired domsg receiveCOMPETE MSG n msggetI
α
α
∀ ∈ ← ← < ← ← ← (); 10: ( ) // 11: (( . . )) ; 1 ij compete i compete iresidual j residual residual j residual i j
d if d R then if thereisanothercandidateinitsrangeR if E n E or E n E andn n state PLAIN − − < < ) ( == < 12: ← 3: ; 14: 15: 16: 17: 18: ( ) 19: ; 20: break endif endif endwhile endif if state CANDIDATE state HEAD endif == ← Algorithm 1 C. Cluster Formation
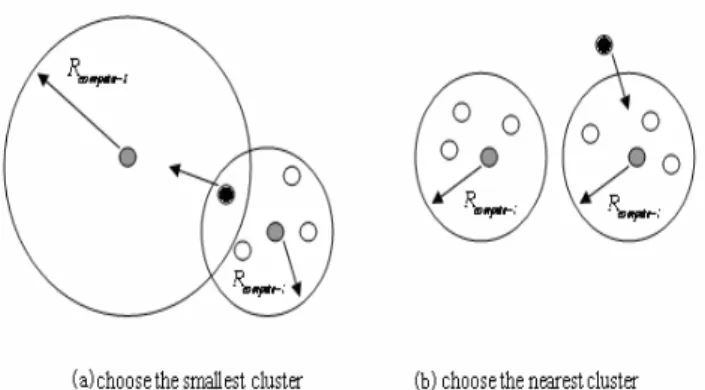
In this phase, cluster heads broadcast HEAD_MSG across the network while plain nodes receive HEAD_MSG and decide which cluster to join in. Most of the exited strategy for plain nodes is to choose the nearest cluster head. However, in
non-uniform network, this may result in load unbalance. Some cluster heads may consume too much energy because of their large sizes. In our scheme, a plain node chooses its cluster according to both distance and load balance. As shown in Fig.2, if a plain node isn’t in the
R
compete i− range of any cluster head, it chooses the nearest cluster to join in for reducing its transmission cost; otherwise, it chooses the smallest cluster to join in for balancing loads among clusters.Figure 2. Choose the cluster to join
IV. ADCSANALYSIS
In this section, we analyze the control load of ADCS firstly; and then give the computation of
R
probeandR
compete i− ; finally we prove that ADCS can form the cluster with good distribution.A. Control load analysis
Lemma 1.The control load across the network is O (N), where N is the number of nodes.
Proof: In probe-phase, all nodes send a “hello” message to their neighbors within the range of
R
probe. Clearly, the sum of this kind of message is N while it just runs for one time. In the election phase, only NT CANDIDATE nodes broadcast and receive COMPETE_MSG to compete for cluster head. In the formation phase, the sum of HEAD_MSG and JOIN_MSG is N. So the control load is O (N) for each round.B. Parameter Computation
According to [5], the network is partitioned into
k
opt clusters evenly. Ideally, thek
opt clusters should cover the entire network (even distribution). Namely,2
( )
( )
(4)
opt optA
k
E R
A
E R
k
π
π
=
⇒
=
Let probe( )
(5)
optA
R
E R
k
π
=
=
, so the expectation ofthe number of neighbors
E Num
(
neighbors)
is equal toopt
N
k
.So we regard that a node with more than
opt
N
k
neighborswithin the range of
R
probe is located at dense area, otherwise at sparse area.Additionally, we set
(
)
1
(6)
(
)
neighbors neighbors i compete i probe neighborsE Num
Num
R
R
E Num
− −−
=
+
As mentioned in section III, there is only one cluster head in the range of each
R
compete i− and it is easy to prove that theseopt
k
clusters cover the entire network with high probability.( 2 1
(
)
opt k compete i iE
π
R
−A
==
∑
) C. Distribution AlanysisLemma2. There are more cluster heads in dense area than sparse area.
Proof: We assume that there is CANDIDATE node
n
iin the dense area andn
jin the sparse area. Clearly node density of dense area is larger, soNum
neighbors i−>
Num
neighbors j− . According to equation (6),R
compete i−<
R
compete j− . That means it is more probable forn
ito become cluster head thann
i in the end. So there are more cluster heads in dense area than sparse area.V. SIMULATION
In this section, we evaluate the performance of ADCS protocol implemented with MATLAB. In the simulation, we adopt the same parameters and MAC protocols with LEACH. In order to prove that our scheme can be adaptive to both uniform and non-uniform topologies, we run simulation in two different scenes: a uniform distribution scene and a non-uniform distribution. The non-non-uniform topology is generated using a Gaussian function. (
σ =
1
, with maximum on the center of the area) In the simulation, we measure the lifetime in terms of round when the first node dies and regard the lifetime as the most important metric to check the performance of protocol. The values of the primary parameters used are listed in Table II.A. Experiment of T
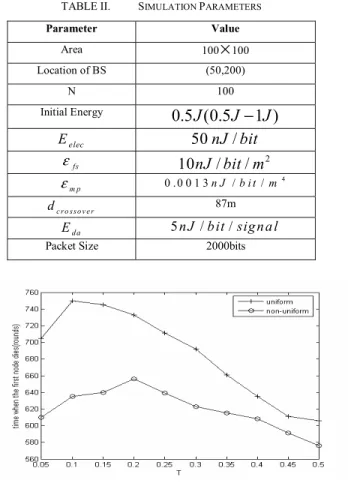
T is the threshold used to control the number of candidate nodes. Firstly, we examine the effect of T on the network lifetime in both scenes. We have done two independent
experiments in two different scenes. Set
k
opt=
5
, as T varies from 0.05 to 0.5, Fig.3 shows the relation between T and the network lifetime. In both scenes, T has the optimal value. For uniform network, the optimal value is 0.1 and for non-uniform network, the optimal value is 0.2. That indicates that non-uniform networks need more candidate nodes than non-uniform networks to guarantee the even distribution of cluster heads. When T is set to less than the optimal value, there aren’t enough candidate nodes to guarantee the even distribution of cluster heads. On the other hand, when T is set to larger than the optimal value, there are too many candidate nodes which consume a lot of energy in vain. In general, uniform network survives for a longer time than non-uniform network. When T is set to larger than the optimal value, the lifetime of uniform network drops more quickly than non-uniform network because its nodes distribute more evenly at the beginning.TABLE II. SIMULATION PARAMETERS
Parameter Value Area 100
×
100 Location of BS (50,200) N 100 Initial Energy0.5 (0.5
J
J
−
1 )
J
elec E50
nJ bit
/
fs ε10
nJ bit m
/
/
2 m p ε 0 .0 0 1 3n J /b i t/m4 c ro sso v e r d 87m da E 5nJ bit signal/ /Packet Size 2000bits
Figure 3. The effect of T on lifetime
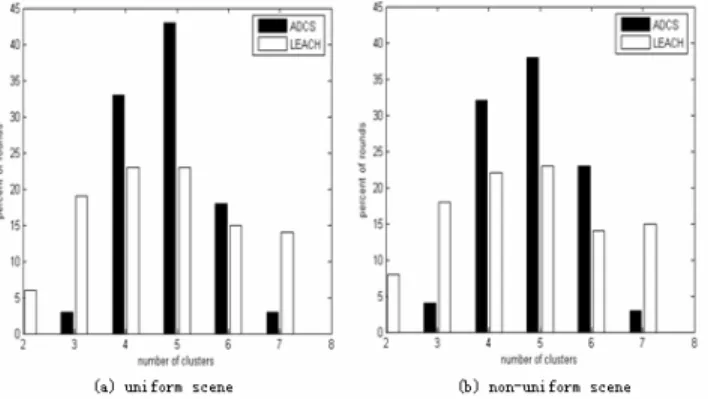
B. Number of Clusters
In [7], the author proposed and proved that there is the optimal value (
k
opt) for the number of clusters. In our scenes, we assume this rule is still in effect in non-uniform scenes and setk
opt=5. However, both ADCS and LEACH are distributed algorithms, since centralized algorithm wastes a lot of energy. We can’t ensure that such a huge and distributed system alwayselects the expected
k
opt cluster heads. We just wish it will achieve this with high probability. We count the numbers of cluster heads per round, and the results are given in Fig.4. As shown in Figures, ADCS mostly elects 4~6 cluster heads while LEACH elects 3~7 cluster heads. ADCS performs better than LEACH in both scenes because it electsk
opt cluster heads with higher probability, which is one of the reasons why ADCS survives a longer time.Figure 4. The number of clusters in ADCS and LEACH: (a) uniform scene, (b)non-uniform scene
C. Lifetime of the Network
As discussed in section II, the round when the first node dies out is regarded as the lifetime of the network. We have done two experiments where each node takes the same or different levels of energy. Fig.5 shows how two protocols perform if each node takes the same amount of energy. In the uniform scene, (T=0.1, Initial Energy=
0.5
J
,k
opt=5), ADCS prolongs the lifetime of the network over 40% against LEACH. In the non-uniform scene, (T=0.2, Initial Energy=0.5
J
,opt
k
=5), LEACH works very worse while ADCS is adaptive to non-uniform topology and prolongs the lifetime of the network over 75% against LEACH. The other nodes die quickly following the first dead node in ADCS. That indicates that all nodes in ADCS consume their energy with similar speed.Figure 5. Lifetime comparison of ADCS and LEACH when all nodes are assembled the same energy: (a) uniform scene, (b)non-uniform scene
In [2], LEACH is on the assumption that all nodes in the network are homogeneous. However, the nodes may differ in the amounts of energy in factual applications. The node with more energy should become cluster head for more times. Otherwise, the node with less energy will die quickly. ADCS can avoid this by confining the node with less energy to be cluster head. In order to prove that, we have done another two experiments. The only alteration is that the initial energy is set to a random number between 0.5
J
and 1J
. Fig.6 shows that ADCS works much better than LEACH. ADCS prolongs the lifetime of the network over 50% and 100% against LEACH in two scenes respectively.Figure 6. Lifetime comparison of ADCS and LEACH when all nodes are assembled different energy: (a) uniform scene, (b)non-uniform scene
VI. CONCLUSION AND FUTURE WORK
In this paper, we present a novel distributed, energy efficient and load balanced clustering scheme applied for periodical data gathering. ADCS can produce a uniform distribution of clusters even in non-uniform networks. The differences among cluster sizes are small and the load is balanced. All sensors consume their energy averagely according to their initial energy. Simulation results show that ADCS outperforms LEACH significantly with prolonging the network lifetime over by 40% in uniform scenes and 75% in non-uniform scenes.
We have made the assumption that all communications are based on single-hop. In large scale sensor networks, not all sensors can communicate to each other and single-hop may not be energy efficient in intra-cluster transmission. An effective solution is multi-hop communication. We will design a novel adaptive and energy efficient routing protocol based on multi-hop in the future work.
ACKNOWLEDGMENT
This paper is partially supported by the National Natural Science Foundation of China under Grant No. 60673171; the National Grand Fundamental Research 973 Program of China under Grant No.2006CB303006; the Open Foundation of Anhui Province Key Laboratory of Software in Computing and Communication 2005-2006; Anhui Province-MOST Co-Key Laboratory of High Performance Computing and Its Application.
REFERENCES
[1] I.F. Akyildiz,W. Su,Y. Sankarasubramaniam,and E. Cayirci, “A survey on sensor networks,” IEEE Communications Magazine,2002,
40 (8):l02-ll4.
[2] W. Heinzelman, A. Chandrakasan, and H. Balakrishnan, “Energy-Efficient Communication Protocol for Wireless Microsensor Networks,” Proc. of IEEE Hawaii International Conference on System Sciences, pp.3005-3014, Jan. 2000.
[3] S. Lindsey, and C.S. Raghavendra, “PEGASIS: Power-Efficient Gathering in Sensor Information Systems,” Proc. of IEEE Aerospace Conference Proceedings, Vol. 3, 9-16pp. 1125-1130, 2002.
[4] 0. Younis, and S. Fahmy, “HEED: A Hybrid, Energy-Efficient, Distributed Clustering Approach for AdHoc Sensor Networks,” IEEE Transactions on Mobile Computing, 3(4):660-669,2004
[5] Ye M ,Li CF,Chen GH,and W u J, “EECS:An energy efficient clustering scheme in wireless sensor networks,” Proc. of the IEEE Int’l Performance Computing and Communications Cone New York:IEEE Press,2005.535-540
[6] T. Rappaport, Wireless Communications: Principles & Practice. Englewood Cliffs, NJ: Prentice-Hall, 1996.
[7] W. Heinzelman, A. Chandrakasan, H. Balakrishnan, “An application-specific protocol architecture for wireless microsensor networks,” IEEE Transactions on Wireless Communications, 1(4):660-669, 2002.