Physics Procedia 24 (2012) 1715 – 1721
1875-3892 © 2011 Published by Elsevier B.V. Selection and/or peer-review under responsibility of ICAPIE Organization Committee. doi:10.1016/j.phpro.2012.02.253
Physics
Procedia
Physics Procedia 00 (2011) 000–000
www.elsevier.com/locate/procedia
2012 International Conference on Applied Physics and Industrial Engineering
A Shell Multi-dimensional Hierarchical Cubing Approach for
High-Dimensional Cube
Shuzhi ZOU,
Li ZHAO,Kongfa HU
Department of Computer Science and Engineering, Yangzhou University, Yangzhou 225009,China
Abstract
The pre-computation of data cubes is critical for improving the response time of OLAP systems and accelerating data mining tasks in large data warehouses. However, as the sizes of data warehouses grow, the time it takes to perform this pre-computation becomes a significant performance bottleneck. In a high dimensional data warehouse, it might not be practical to build all these cuboids and their indices. In this paper, we propose a shell multi-dimensional hierarchical cubing algorithm, based on an extension of the previous minimal cubing approach. This method partitions the high dimensional data cube into low multi-dimensional hierarchical cube. Experimental results show that the proposed method is significantly more efficient than other existing cubing methods.
© 2011 Published by Elsevier Ltd. Selection and/or peer-review under responsibility of [name organizer]
Keywords:data cube, multi-dimensional hierarchical cube, bitmap encoding
1. Introduction
OLAP refers to the technologies that allow users to efficiently retrieve data from the data warehouse for decision support purposes [1]. A lot of research has been done in order to improve the OLAP query performance and to provide fast response times for queries on large data warehouses. A key issue to speed up the OLAP query processing is efficient indexing and materialization of data cubes [2,3,4]. Recently, many data cubing algorithms, such as BUC [5], H-cubing [6], and quotient cubing [7] have been proposed.
A key challenge for efficient data cubing is that, in large data warehouse applications, data usually has a high dimensionality and each dimension has multiple hierarchy levels. Since data cube grows exponentially with the number of dimensions and number of hierarchy levels, it is generally too costly in both computation time and storage space to materialize a full high-dimensional data cube. Although some new algorithms, such as star cubes [8], condensed cube [9], or dwarf cube[10] , can delay the explosion, © 2011 Published by Elsevier B.V. Selection and/or peer-review under responsibility of ICAPIE Organization Committee. Open access under CC BY-NC-ND license.
they do not solve the fundamental problem. The minimal cubing approach by Li and Han [11] can alleviate this problem, but it does not consider the dimension hierarchies. We propose a novel cubing algorithm to support fast OLAP for high-dimensional hierarchical data. The algorithm decomposes the high dimensional data cube into low multi-dimensional hierarchical cube. In our algorithm, for each multi-dimensional hierarchical cube, we encode its dimension hierarchies using an intelligent prefix bitmap indexing that supports fast response to OLAP queries.
2. Concepts and Problem Definition
In data warehouses, a data cube C is formally defined as the following (n+m)-tuple: C=(D1,...,Dn, M1, ...,Mm) where Di, for 1<= i <=n, is a dimension and Mj, for 1<= j <=m, is a measure. Each dimension Di containing the hierarchical attributes { hi
i i
i
L
L
L
1,
2,
"
,
} ( 1 iL is the most abstract level and hi i L is the most detailed one), where i
j
L
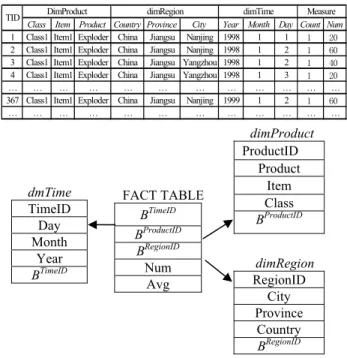
is the level i dimension hierarchy of the dimension Dj.We illustrate the method by using a data warehouse in Table 1 as a running example. Its star schema is shown in Figure 1.Table 1. A sample warehouse with two measure values
Class Item Product Country Province City Year Month Day Count Num 1 Class1 Item1 Exploder China Jiangsu Nanjing 1998 1 1 1 20 2 Class1 Item1 Exploder China Jiangsu Nanjing 1998 1 2 1 60 3 Class1 Item1 Exploder China Jiangsu Yangzhou 1998 1 2 1 40 4 Class1 Item1 Exploder China Jiangsu Yangzhou 1998 1 3 1 20
… … … …
367 Class1 Item1 Exploder China Jiangsu Nanjing 1999 1 2 1 60
… … … …
Measure TID DimProduct dimRegion dimTime
Figure 1. Star schema of the data cube
In this paper, we propose an orthogonal way to partition the cube space. We partition all the dimensions of a cube into subsets called the shell multi-dimensional hierarchical cubing segments. For example, for a warehouse of 30 dimensions has three hierarchy levels as D1(L11,L12,L31),D2(L12,L22,L32), D3( L13,L23,L33),...,D30( L130,L230,L330 ), we will compute 640 cuboids:{(L11,L12,L13),(L12,L22,L32),..., (All,All,All)}. Comparing this to the 36200 cuboids needed by the shell cube technique, the savings in cubing time and space are significant.
dmTime TimeID Day Month Year BTimeID FACT TABLE BTimeID BProductID BRegionID Num Avg dimRegion RegionID City Province Country BRegionID dimProduct ProductID Product Item Class BProductID
To index the data, we employ a bitmap join index called dimension hierarchical encoding on the high-cardinality dimensions dimProduct, dimRegion and dimTime. We create the dimension hierarchical encoding for the dimTime dimension by using separate bit sub-patterns to encode Years, Months within Years, Days within Months etc. We only need 12 bits to identify a particular TimeID so that the index only consists of 12 bits instead of 1,860 bits needed for simple bitmaps. Therefore, to locate all fact rows of a specific time, we need to evaluate only 12 bitmaps. The encoded bitmap indices on dimProduct and dimRegion need 16 and 16 bitmaps, respectively.
For each dimension Dj, each hierarchy level
L
ij is encoded as a bit string {<bk-1... bi...b0>|bi∈
{0,1},i=0,...,k-1}. The bitmap string BDjfor each hierarchical dimension Dj is defined as the concatenation of all the hierarchy levels, following the order of hierarchy levels, with the highest hierarchy levels appearing at the leftmost side of the bitmap index.For each hierarchy level Lij on the dimension Dj, the number of bits needed can be computed as Bit(
L
ij) =⎡
log2m⎤
, where m=max(|Lij |) is the maximum number of distinct members of the hierarchyi j
L
. The total number of bits in the bitmap index for a dimension Di is Bit(D
j) = ∑i=1..hi Bit(L
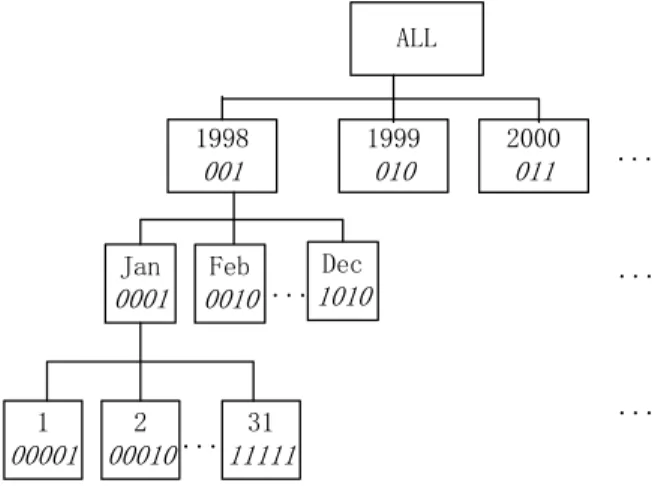
ij).Example 1. Figure 2 shows the DimTime dimension hierarchy tree, while Table 2 shows the DimTime dimension hierarchy encoding and its hierarchy encoding table in the sales warehouse.
In Figure 2, the dimension DimTime has three hierarchy levels {Year,Month,Day}. The BitYear of the hierarchy level Year is BitYear =⎡log2max(|Year|)⎤=
⎡
log25⎤
=3 bit. The BitMonth of the hierarchy level Month is BitMonth =⎡
log2max(|month|)⎤
=⎡
log212⎤
=4 bit. The BitDay of the hierarchy level Day is BitDay =⎡
log2max(|day|)⎤
=⎡log231⎤=5 bit. The BitTime of the dimension DimTime is BitTime = BitYear+ BitMonth + BitDay= 12 bit. It is smaller than the integer encoding.The dimension hierarchical encoding of the member “1998.Jan.2” on the dimension DimTime is 001000100010. It consists of BYear=1998BMonth=1BDay=2 and is computed by B1998.Jan.2=(BYear=1998<<BitMonth|BMonth=1)<<BitDay|BDay=2 =(001<<4|0001)<<5|00010 =001000100010. 1998 001 1999 010 ALL 2000 011 1 00001 2 00010 31 11111 Jan 0001 Feb 0010 ... ... ... ... ...1010Dec
Table 2. The dimTime Dimension Hierarchy Encoding
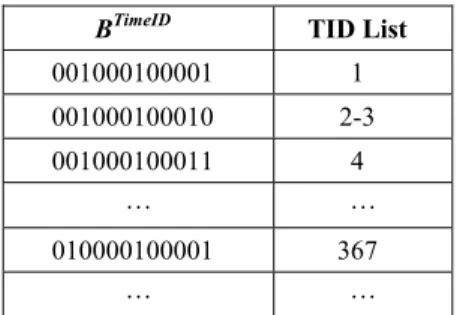
TimeID Time BTimeID 1 98.Jan.1 001000100001 2 98.Jan.2 001000100010 3 98.Jan.3 001000100011 … … … 367 99.Jan.2 010000100001 … … …
By using the prefix bitmap encoding for dimensional hierarchies, we can register a list of tuples IDs (tids) associated with the dimension members for each dimension. For example, the TID list associated with the dimTime dimension are shown in Table3 .
Table 3. dimTime dimension TID
BTimeID TID List 001000100001 1 001000100010 2-3 001000100011 4 … … 010000100001 367 … …
3. Parallel Shell Multi-dimensional Hierarchical Cubing Algorithm
The algorithm for shell prefix cube segment parallel computation can be summarized as follows.
Algorithm 1 (Parallel computation of shell multi-dimensional hierarchical cubing segments)
Input: A base cuboid BC of n dimensions:(D1; ... ;Dn).
Output: (1) A set of multi-dimensional hierarchical cubing segment partitions {P1;..., Pk} and their corresponding (local) multi-dimensional hierarchical cubing segments {MCS1; ... ; MCSk}, where Pi represents some set of dimension(s) and P1∪...∪ Pk are all the n dimensions, and (2) an ID measure array if the measure is not tuple-count such as {sum, avg}.
{ partition the set of dimensions :(D1; ... ;Dn) into a set of k multi-dimensional hierarchical cubing segments {P1;..., Pk};
scan base cuboid BC once and do the following with parallel processing {insert each <tid, measure> into ID-measure array;
for each attribute value ai of each dimension Di;
build an dimension hierarchy encoding index entry: <B: TID list>;} parallel processing all segment partition Pi as follows
build a local multi-dimensional hierarchical cubing segments MCSi by intersecting their corresponding tid-lists and computing their measures;}
Based on the bitmap indexing, we can efficiently retrieve the matching hierarchy levels of each dimension, evaluate the set of query ranges for each dimension, and improve the efficiency of OLAP queries. A key property of our encoding is that it is a prefix indexing scheme that allows one to quickly retrieve a path prefix for each dimension.
The path prefix of the member
d
ik of the hierarchy levelL
ij is defined as DMPrefixpath(DTree,d
ik )=∪
1j=i DMPrefixpath(DTree,Parent(d
kj ))={ Ancestor(d
ik )}, whereAncestor(
d
ik) is the all ancestors of the memberd
ik according to its dimension hierarchy tree. The encoding prefix of the memberd
ik is defined as Bprefix(B ki d ,
L
mi−1)= B k i d >>∑
j= m l (Bit l iL
), where m={1, ...,j}.Algorithm 2 (OLAP Query)
Input: A set of precomputed shell Cube Segments for partitions {P1,…, Pk}; an TID measure array;
and a OLAP query Q<a1,…,an,M>.(The ai is attribute for the dimension Ai and M is the measure of the
query.)
Output: The computed measure
{ ascertain all multi-dimensional hierarchical cubing Segment MCSi according as the each dimension attribute of the query Q<a1,…,an,M>;
for each MCSi
{ compare the MCSi with query Q<a1,…,an,M> using the Lattice and find the all dimension Di of
MCSi∩{a1,…,an} with parallel processing;
compute the TID List of the all BCi cells of MCSi∩{a1,…,an} in Di and its aggregate Cuboids;
intersect the TID List of th BCi and compute the query result set RQ{TID List};
compute the aggregate with each TID of the TID-measure array from the set RQ{TID List}; }}
4. Performance Study
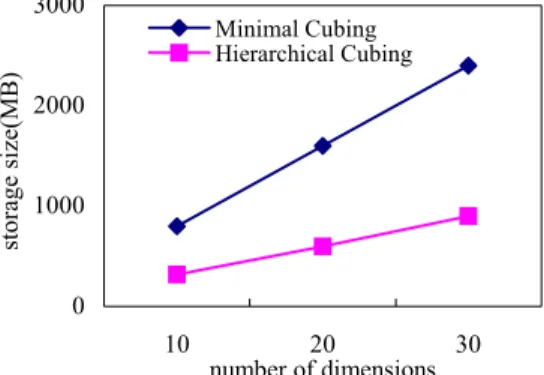
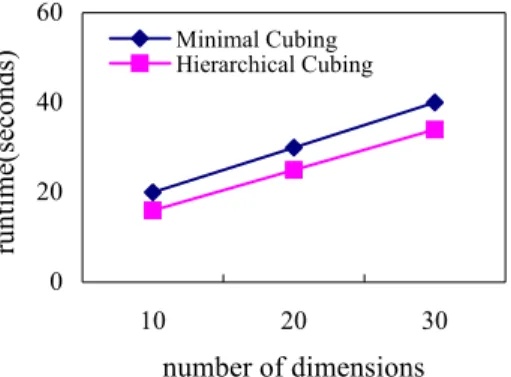
The performance results of parallel multi-dimensional hierarchical cubing and the minimal cubing of Li’s and Han’s[11] are reported from Figure 3 and Figure 4. Figure 3 shows the storage size of the two methods on the cube had T=106 tuplesand h =3 level hierarchy and with shell fragment size f=3. Figure 4 shows the time needed to compute the shell Cube segments with fragment size f=3.
0 1000 2000 3000 10 20 30 number of dimensions storage size(M B) Minimal Cubing Hierarchical Cubing
0 20 40 60 10 20 30 number of dimensions ru nt im e(s eco nd
s) Minimal CubingHierarchical Cubing
Figure 4. Time needed to compute the cube segments
The Figure 3 - Figure 4 show the performance of the parallel multi-dimensional hierarchical cubing method is more efficient than the other existed leading cubing algorithms such as minimal cubing[11].
5. Conclusion
The pre-computation of data cubes is critical to improving the response time of OLAP systems and accelerating data mining tasks in large data warehouses. We have proposed a novel approach for OLAP in high-dimensional datasets with a moderate number of tuples. It partitions a high dimensional cube into a set of disjoint low multi-dimensional hierarchical cubes. We have experimentally compared the proposed method with the other existing cubing algorithms such as minimal cubing. The analytical and experimental results show that the proposed parallel multi-dimensional hierarchical cubing algorithm is significantly more efficient in time and space than the other leading cubing methods on large data warehouses.
Acknowledgements
The research in the paper is supported by the National Natural Science Foundation of China under Grant No. 60773103; the Natural Science Foundation of Jiangsu Province under Grant No. BK2009697 and BK2008206; the “Six Talent Peaks Program” of Jiangsu Province of China; the ‘Qing Lan’ Project Foundation of Jiangsu Province of China.
References
[1]S. Chauduri, U. Dayal, “An overview of data warehousing and OLAP technology”. SIGMOD Record ,1997, 26(1), pp.65-74.
[2]K.Wu, E. J. Otoo, A. Shoshani, “A performance comparison of bitmap indexes” , Proceedings of the 10th Int. Conf. on
Information and Knowledge Management(CIKM’01), ACM Press ,New York, NY, 2001, pp.559-561.
[3]H. Mistry, P. Roy, S. Sudarshan, Materialized view selection and maintenance using multi-query optimization”, Proceedings
of the 2001 ACM SIGMOD Int. Conf. on Management of Data(SIGMOD’01), ACM Press ,New York, NY, 2001, pp.307-318.
[4]J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, F. Pellow, H. Pirahesh, “Datacube: A relational
[5]K. Beyer, R. Ramakrishnan, “Bottom-up computation of sparse and iceberg cubes”, ProceedingsProc. of the 1999
ACM SIGMOD Int. Conf. on Management of Data(SIGMOD’99). ACM Press ,New York, NY,1999, pp.359-370.
[6]J. Han , J. Pei, G. Dong, K.Wang, “Efficient computation of iceberg cubes with complex measures”, Proceedings of the
2001 ACM SIGMOD Int. Conf. on Management of Data(SIGMOD’01) . ACM Press ,New York, NY, 2001, pp.1-12.
[7]L. V. S. Lakshmanan , J. Pei, J. Han, “Quotient cubes: how to summarize the semantics of a data cube”, Proceedings of 28th
Int. Conf. on Very Large Data Bases (VLDB’02). Morgan Kaufmann, San Fransisco, 2002, pp.778-789.
[8]D. Xin, J.Han, X. Li, B. W. Wah, “Star-cubing:computing iceberg cubes by top-down and bottom-up integration”, Proceedings of 29th Int. Conf. on Very Large Data Bases (VLDB’03) . Morgan Kaufmann, San Fransisco, 2003 ,pp. 476-487.
[9]L. V. S. Lakshmanan , J. Pei, Y. Zhao, “QC-trees: An efficient summary structure for semantic OLAP”, Proceedings of the
2003 ACM SIGMOD Int. Conf. on Management of Data(SIGMOD’03).ACM Press ,New York, NY, 2003, pp. 64-75.
[10]Y. Sismanis, A. Deligiannakis, Y. Kotidis, N. Roussopoulos, “Hierarchical dwarfs for the rollup cube”, Proceedings of 30th
Int. Conf. on Very Large Data Bases (VLDB’04). Morgan Kaufmann, San Fransisco, 2004, pp.540-551.
[11]X. Li, J. Han, H. Gonzalez, “High-dimensional OLAP: A minimal cubing approach”, Proceedings of 30th Int. Conf. on Very