Proficient Cache-Promoted Direction System On Drive
K. Srilakshmi & N. Sujata Kumari
1
M.tech Student,
2Associate Professor,Departmentof CSE, Sridevi Women’s Engineering College,
Vatinagullapally(v), Rajendranagar(m), Ranga Reddy(d), Telangana state, India.
Abstract: Inferable from the wide accessibility of the
worldwide situating framework (GPS) and computerized
mapping of streets, street arrange route administrations
have turned into an essential application on numerous cell
phones. Way arranging, a key capacity of street organize
route administrations, finds a course between the predefined
begin area and goal. The productivity of this way arranging
capacity is basic for portable clients on streets because of
different dynamic situations, for example, a sudden alter in
driving course, startling activity conditions, lost or flimsy
GPS signs, et cetera. In these situations, the way arranging
administration should be conveyed in an opportune manner.
In this paper, we propose a framework, specifically, Path
Planning by Caching (PPC), to answer another way
arranging question continuously by proficiently storing and
reusing chronicled questioned ways Not at all like the
traditional cache based way arranging frameworks, where a
questioned way in reserve is utilized just when it
coordinates consummately with the new inquiry, PPC use
the in part coordinated inquiries to answer part(s) of the
new inquiry. Subsequently, the server just needs to process
the unmatched way portions, in this way altogether
decreasing the general framework workload. Thorough
experimentation on a genuine street organize database
demonstrates that our framework utflanks the best in class
way arranging procedures by diminishing 32% of the
calculation dormancy overall.
Keywords: Spatial database, path planning, cache.
I. INTRODUCTION
With the progress of the worldwide situating
framework (GPS) and the prominence of cell phones, we have seen a movement of the regular Internet-in view of
line route administrations (e.g., MapQuest) onto versatile
stages (e.g., Google Map). In portable route
administrations, on-street way arranging is an essential
capacity that finds a course between a questioned begin
area and a goal. While on streets, a way arranging inquiry
might be issued because of dynamic considers different
situations, for example, a sudden alter in driving course, surprising activity conditions, or loss of GPS signals. In
these situations, way arranging should be conveyed in an
opportune manner. The necessity of auspiciousness is
considerably all the more difficult when a
mind-bogglingnumber of way arranging inquiries is submitted
to the server, e.g., amid crest hours. As the reaction time
is basic to client fulfillment with individual route
administrations, it is an order for the server to proficiently deal with the overwhelming workload of way arranging
demands.
To address this issue, we propose a framework, to be
specific, Path Planning by Caching (PPC), that intends to
answer another way arranging inquiry productively by
storing and reusing verifiably questioned ways
(questioned ways in short). Not at all like regular store
based way arranging frameworks where a reserved
inquiry is returned just when it coordinates totally with another question, PPC influences incompletely
coordinated questioned ways in store to answer part(s) of
the new inquiry. Accordingly, the server just needs to
altogether lessening the general framework workload.
Figure 1 gives a review of the proposed PPC framework
structure, which comprises of three principle parts (in rectangular boxes, separately):
A. PPattern Detection,
B. Shortest Path Estimation
C. Cache Management
Given a way arranging question (see Step (1)), which
contains a source area and a goal area, PPC initially
decides and recovers various chronicledways in
store,called PPatterns, that may coordinate this new
inquiry with highlikelihood (see Steps (2)- (4)). 1 The possibility of PPatterns depends on a perception that
comparable beginning and goal hubs of two questions
may bring about comparable most limited ways (known
as the way intelligibility property [1]). In the segment
PPattern Detection, we propose a novel probabilistic
model to appraise the probability for a reserved
questioned way to be valuable for noting the new inquiry
by investigating their geospatial qualities. To encourage fast recognition of PPatterns, rather than comprehensively
examining all the questioned ways in reserve, we plan a
framework based record for the PPattern Detection
module. In light of these recognized PPatterns, the
Shortest Path Estimation module (see Steps (5)- (8))
builds competitor ways for the new inquiry and picks the
best (briefest) one. In this segment, if a PPattern
splendidly coordinates the inquiry, we promptly return it
to the client; generally, the server is made a request to register the unmatched way sections between the PPattern
and the question (see Steps (6)- (7)). Since the unmatched
portions are normally just a little piece of the first inquiry,
the server just procedures a "littler sub query", with a
decreased workload. When we restore the assessed way to
the client, the Cache Management module is activated to
figure out which questioned ways in store ought to be
expelled if the reserve is full. A vital piece of this module
is another reserve substitution arrangement which
considers the extraordinary qualities of street systems.
Through an exact investigation, we locate that normal street sections in different questioned ways more often
than not have street sorts of higher significance and limit
This moves us to characterize an ease of use an incentive
for every way by considering both of its street sort and
authentic recurrence of utilization. The primary
commitments made in this work are outlined as takes
after:
We propose an imaginative framework,
specifically, way arranging by caching (PPC), to
proficiently answer another way arranging inquiry by utilizing reserved ways to abstain from
experiencing a tedious most brief way calculation.
By and large, we set aside to 32% of time in
examination with a customary way arranging
framework (without utilizing reserve).
We present the thought of PPattern, i.e., a reserved
way which imparts sections to different ways. PPC
bolsters incomplete hits amongst PPatterns and
another inquiry. Our examinations demonstrate that halfway hits constitute up to 92.14% of all store
hits by and large.
A novel probabilistic model is proposed to
recognize the reserved ways that are of high
likelihood to be a PPattern for the new question in
view of the coherency property of the street
systems. Our tests show that these PPatterns spare
recovery of way hubs by 31.69% overall, speaking
to a ten times change over the 3.04% sparing accomplished by an entire hit.
We have built up another reserve substitution
component by considering the client inclination
among streets of different sorts. An ease of
usemeasure is doled out for each question by
prevalence. The test comes about demonstrate that
our new store substitution approach expands the
general reserve hit proportion by 25.02% over the cutting edge store substitution strategies.
II. RELATED WORK
An enhanced version adds easy route curves to lessen
vertices from being gone to and utilizes halfway trees to
diminish the pre-processing time. This work additionally
joins the advantages of the achieve based and ATL ways to
deal with decrease the quantity of vertex visits and the pursuit space. The examination demonstrates that the cross
breed approach gives a predominant outcome as far as
diminishing question preparing time. Jung and
Pramanikpropose the HiTi diagram model to structure a
huge street organize display. HiTi expects to decrease the
look space for the briefest way calculation. While HiTi
accomplishes superior on street weight overhauls and
lessens stockpiling overheads, it brings about higher calculation costs when processing the most brief ways than
the HEPV and the Hub Indexing strategies. To process
time-subordinate quick ways, Demiryurek et al. propose the
B-TDFP calculation by utilizing in reverse inquiries to
diminish the hunt space. It receives a territory level parcel
plot which uses a street progressive system to adjust every
zone. Be that as it may, a client may incline toward a course
with better driving knowledge to the briefest way.
Consequently, Gonzalez et al. propose a versatile quick way calculation which uses speed and driving examples to
enhance the nature of courses. The algorithm utilizes a road
hierarchical partition and pre-computation to enhance the
execution of the course calculation. The little street redesign
is a novel way to deal with enhancing the nature of the route
computation. In order to enhance the recovery efficiency of
the way arranging framework, Thomsen et al. propose
another reserve administration arrangement to store the
aftereffects of continuous questions for reuse later on. To
upgrade the hit proportion, an advantage esteem capacity is
utilized to score the ways from the question logs. Thusly, the hit proportion is expanded, henceforth diminishingthe
execution times. Be that as it may, the cost of developing a
store is high, since the framework must compute the
advantage values for all sub-ways in a full-way of inquiry
results. For on-line, delineate applications, preparing a
substantial number of concurrent way questions is an
essential issue. In this paper, we give another system to
reusing the already reserved inquiry comes about and a
successful calculation for enhancing the question assessment on the server.
II. PATH PLANNING ALGORITHMS AND PARALLELIZATION’S
Dijkstra that is an optimal algorithm, is the de facto baseline used in path planning applications. However,
several heuristic based variations exist that trade-off parameters such as parallelism and accuracy. ∆-stepping is
one exampleVertices Allocated to Threads Shown in
different color which classifies graph vertices and processes
them in different stages of the algorithm. The A*/D*
algorithms are another example that use aggressive heuristics to prune out computational work (graph vertices),
and only visit vertices that occur in the shortest path. In
order to maintain optimality and a suitable baseline, we focus on Dijkstra’s algorithm in this paper. A. Dijkstra’s Algorithm and Structure Dijkstra’s algorithm consists of
two main loops, an outer loop that traverses each graph
vertex once, and an inner loop that traverses the neighboring
vertices of the vertex selected by the outer loop. The most efficient generic implementation of Dijkstra’s algorithm
utilizes a heap structure, and has a complexity of O(E + V
logV). However, in parallel implementations, queues are
re-balancing the heap after each parallel iteration. Algorithm
1 shows the generic pseudo-code skeleton for Dijkstra’salgorithm. For each vertex, each neighboring
vertex is visited and compared with other neighboring
vertices in the context of distance from the source vertex
(the starting vertex).The neighboring vertex with the
minimum distance cost is selected as the next best vertex for
the next outer loop iteration.The distances from the source
vertex to the neighboring vertices are then updated in the
program data structures, after which the algorithm repeats
for the next selected vertex. A larger graph size means more
outer loop iterations, while a large graph density means more inner loop iterations. Consequently, these iterations translate into parallelism, with the graph’s size and density
dictating how much parallelism is exploitable. We discuss the parallelization’s in subsequent subsections and show
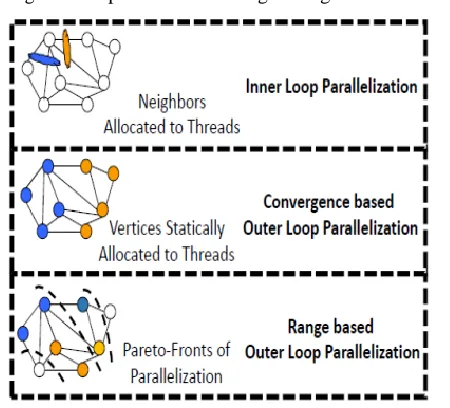
examples in Fig 1. Inner Loop Parallelization The inner loop
in Algorithm 1 parallelizes the neighboring vertex checking.
Fig 1.Dijkstra’s Algorithm Parallelization’s
Each thread is given a set of neighboring vertices of the
current vertex, and it computes a local minimum and updates that neighboring vertex’s distance. A master thread
is then called to take all the local minimums, and reduce to
find a global minimum, which becomes the next best vertex
to jump to in the next outer loop iteration. Barriers are
required between local minimum and global minimum
reduction steps as the global minimums can only be calculated when the master thread has access to all the local
minimums. Parallelism is therefore dependent on the graph
density, i.e. the number of neighboring vertices per vertex.
Sparse graphsconstitute low density, and therefore cannot
scale with this type of parallelization. Dense graphs having
high densities are expected to scale in this case. C. Outer
Loop Parallelization The outer loop parallelization strategy
partitions the graph vertices among threads, depicted in
Algorithm 1. Each thread runs inner loop iterations over its vertices, and updates the distance arrays in the process.
However, atomic clocks over shared memory are required to
update vertex distances, as vertices may be
sharingneighbors in different threads. 1. Convergence Outer
Loop Parallelization: The convergence based outer loop
statically partitions the graph vertices to threads. Threads
work on their allocated chunks independently, update
tentative distance arrays, and update the final distance array once each thread completes work on its allocated vertices.
The algorithm then repeats, until the final distance arrays
stabilize, where the stabilization sets the convergence
condition. Significant redundant work is involved as each
vertex is computed upon multiple times during the course of this algorithm’s execution. 2. Ranged based Outer Loop
Parallelization: The range based outer loop parallelization
opens pare to fronts on vertices in each iteration. Vertices in
these fronts are equally divided amongst threads to compute on, however, atomic clocks are still required due to vertex
sharing. As pare to fronts are intelligently opened using the
graph connectivity, a vertex can be safely relaxed just once
during the course of the algorithm. Redundant work is
therefore mitigated, while maintaining significant
parallelism. However, as initial and final pare to fronts
contain less vertices, limited parallelism is available during
parallelism is available during the middle phases of the algorithm. This algorithm’s available parallelism hereto
follows a normal distribution, with time on the x-axis.
III. EFFICIENT GRID-BASED SOLUTION
In order to retrieve these patterns efficiently, we propose
a grid-based solution to further improve the system
performance. The main idea is to divide the whole space
into equally sized grid cells, where the endpoints of all paths
are mapped to the grid cells. As such, the grid index
facilitates efficient cache. The distance measures can be approximated by counting the total number of covered grids.
3.1 Algorithm 1 PPatterns Detection
Input:qs;t : a query ; Dl: distance threshold; Dg: grid cell
size, C: a cache.
Output: All candidate PPatterns P T .
1:if D(s; t) < Dl then
2:Return P T = Ǿ.
3:end if
4:Divide the target space by size Dg.
5:Determine the start grid gs and destination grid gt.
6:Qs ← Logged queries whose paths pass gs.
7:Qt ← Logged queries whose paths pass gt.
8:Q = Intersect(Qs; Qt).
9:P T ← (Sub)paths from Gs to Gt for each query in Q.
10:Return P T .
IV. CACHE-SUPPORTED SHORTEST PATH
ESTIMA-TION
Based on the PPatterns detected above, we estimate the
shortest path for a new query using Eq. (6). Note that the
detected PPatterns contribute to at least a part of the answer
path returned to the users and actually increases the cache
utilization. To facilitate our discussion, we refine the
concept of a traditional cache hit as follows:
Definition 1.Complete hit.Given a path planning query (asource-destination node pair), a complete hit occurs if there exists at least one queried-path in cache with source-destination node pair matching exactly with that of the input query.
Definition 2.Partial hit.Given a path planning query, apartialhit occurs if there exists at least one queried-path in cachedetected as a PPattern of the input query which however is not a complete hit.
To detect the estimated shortest path, we propose a
heuristic algorithm as shown in Algorithm 2. If there exists
no PPattern, the system contacts the server to compute the
shortest path and returns it immediately (Lines 1 to 3). If
there exists a complete cache hit, the corresponding path is
returned immediately (Lines 6 to 8). Otherwise, the system
calculates the estimated distance from each pattern candidate in P T for the query and selects the one with
minimal distance. To improve the performance, we adopt an
approximation distance (Lines 9 to 19) by calculating the
Euclidean distance between the source-source (Lines 9 to
11) and destination-destination nodes (Lines 12 to 13)
4.1 Algorithm 2 Shortest Path Estimation
Input:query source node s′ and destination node t′; all
candi-date PPatterns P T ; Cache C
Output:Estimated shortest path p^*.
1: ifisEmpty(P T )) then
2:p^* ← Calculate path from server and return.
3: end if
4: Initialize Estimated Shortest Distance ESD = ∞.
5: for each path p € P T do
6: if p is a complete hit then
7: Return p^* s’; t’ = p.
8: end if
9: s* = argmin s € Vp D(s’ ; s).
10: ds = D(s’ ; s*).
12: t* = argmin t € VpD(t ; t’).
13: dt = D (t*, t’).
14: Let dr = |SDP(s’; t’ )|.
15: d = ds + dr+ dt.
16: if d <ESD then
17: ESD = d.
18: Update best PPattern p* = ps* ; t*
19: end if
20: end for
21: ifs’ is not equal to vsp* then
22: SDP(s’ ;vsp* ) ←Compute shortest path SDP(s’ ; vsp* ).
23: end if
24: ift is not equal to vtp* then
25: SDP(vtp* ; s′) ←Compute shortest path SDP(vtp* ; t′).
26: end if
27: Return p^* = SDP(s’; vsp* )⊙ p*⊙SDP(vtp* ; t’).
V. CACHE MANAGEMENT
In a cache-supported system, it is important to efficiently
manage the cache contents to accelerate the path planning.
Therefore, in this section, we first discuss the
implementation of a grid-based index, followed by
describing a dynamic cache update and replacement policy.
5.1 Algorithms 3 Cache Construction and Update
Input: a queryq, a cacheC.
Output: a cacheC.
1: P T ← PPatterns Detection.
2: p ← Shortest Path Estimation from P T .
3: if C is not full then
4: Insert p into C; Return C.
5: else
6: {µ} ← Calculate usability for each cached path
7: p* ← Path with the minimum usability.
8: if p*.µ < p.µ then
9: C ← Replace p* with p.
10: end if
11: end if
12: Return C.
5.2 Index Structure for Cache Lookups
The grid index is primarily used to improve the I/O
access-ing time of the road network topology to support the
path selection operation in the path planning service. The
basic idea is to divide the spatial region uniformly into grid
cells.
The cache retains two tables for an efficient cache
lookup. The first table records each grid-cell through which
paths have passed. This table allows quick identification of poten-tialPPatterns for the new query. The second table
records all nodes of each path in their traveling order. This
table is ac-cessed when the final path for the new query is
determined.
5.3 Cache Construction and Update
Due to the limited cache size, it is necessary to determine which queried-paths should be evicted when the cache is
full. In this section, we propose a new cache replacement
policy by exploring unique characteristics of road networks.
In road networks, notice that certain routes are usually
preferred by users [2]. Empirically, these common road
segments are usually of higher road type, because major
roads are more frequently taken than the branch roads due to
their functions and capacities [30]. For example, the
interstate highway between San Jose and San Francisco is frequently taken when traveling between these two cities.
As a result, interstate highways are assigned higher road
type values.
V. CONCLUSION
In this paper, we propose a framework, in particular, Path
Planning by Caching (PPC), to answer another way
reserving and reusing the historical questioned ways.
Dissimilar to the customary store based way arranging
frameworks, where a questioned way in reserve is utilized just when it coordinates consummately with the new
inquiry, PPC influences the incompletely coordinated
reserved inquiries to answer part(s) of another question.
Accordingly, the server just needs to register the unmatched
sections, in this manner fundamentally lessening the general
framework workload. Thorough experimentation on a
genuine street arrange database demonstrates that our
framework outflanks the best in class way arranging
systems by lessening 32% of the computational inactivity all things considered.
REFERENCES
[1] L. Zammit, M. Attard, and K. Scerri―Bayesian
Hierarchical Mod-elling of Traffic Flow - With Application to Malta’s Road Net-work,‖ in International IEEE Conference on
Intelligent Transportation Systems, 2013, pp. 1376–1381.
[2] E. W. Dijkstra, ―A Note on Two Problems in Connexion with Graphs,‖ NumerischeMathematik, vol. 1, no. 1, pp. 269–271, 1959.
[3] U. Zwick, ―Exact and approximate distances in graphs – a survey,‖ in Algorithms – ESA 2001, 2001, vol. 2161, pp. 33–48.
[4] J. Li, Q. Wang, C. Wang. “Fuzzy keyword search over encrypted data in cloud computing”, Proc. IEEE INFOCOM, pp.
1-5, 2010.
[5] A. V. Goldberg and C. Silverstein,―Implementations of Dijkstra’s Algorithm Based on Multi-Level Buckets,‖ in
NetworkOptimization, 1997, vol. 450, pp. 292–327. 1041-4347 (c)
2015 IEEE.Personal use
ispermitted,butrepublication/redistributionrequires
IEEE permission. See
http://www.ieee.org/publications_standards/publ
ications/rights/index.html for more information.IEEE
TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING
VOLUME: 28, NO: 4, APRIL 1 2016 14.
[6] P. Hart, N. Nilsson, and B. Raphael, ―A Formal Basis for the [30] H. Kanoh, ―DynamicRoute Planning for Car Navigation
Sys-Heuristic Determination of Minimum Cost Paths,‖ IEEE
Transac- tems Using Virus Genetic Algorithms, International
Journal on Systems Science and Cybernetics, vol. 4, no. 2, pp.
100–107, Knowledge-based and Intelligent Engineering Systems,
vol. 11, no. 1, 1967.pp. 65–78, 2007.
[7] A. V. Goldberg and C. Harrelson, ―Computing the Shortest
Path: [31] M. Ali, J.Krumm, T. Rautman, and A. Teredesai, ―Acmsigspatial A Search Meets Graph Theory,‖ inACM
Symposium on Discrete Algorithms, 2005.
[8] R. Gutman, ―Reach-Based Routing: A New Approach to Shortest Path Algorithms Optimized for Road Networks,‖ in
Workshop onAlgorithm Engineering and Experiments, 2004.A. V.
Goldberg, H. Kaplan, and R. F.Werneck, ―Reach for A*:
Efficient Point-to-Point Shortest Path Algorithms,‖ in Workshop on
Algorithm Engineering and Experiments, 2006, pp. 129–143.
[9] S. Jung and S. Pramanik, ―An Efficient Path Computation
Model for Hierarchically Structured Topographical Road Maps,‖ IEEE TRANSACTIONS ON KNOWLEDGE AND DATA
ENGINEERING VOLUME: 28, NO: 4, APRIL 1 2016 , vol. 14, no.
5, pp. 1029–1046, 2002.
[10] R. Goldman, N. Shivakumar, S. Venkatasubramanian, and H. GarciaMolina,―Proximity Search in Aatabases,‖ in Interna-tional
Conference on Very Large Data Bases, 1998, pp. 26–37.
[11] N. Jing, Y.-W. Huang, and E. A. Rundensteiner, ―Hierarchical Optimization of Optimal Path Finding for
Transportation Appli-cations,‖ in ACM Conference on
Information and Knowledge Manage-ment, 1996.
TRANSACTIONS ON KNOWLEDGE AND DATA
ENGINEERING VOLUME: 28, NO: 4, APRIL 1 2016 , vol. 10,
pp. 409–432, 1998.
[13] U. Demiryurek, F. Banaei-Kashani, C. Shahabi, and A. Ran-ganathan, ―Online Computation of Fastest Path in Time-Dependent Spatial Networks,‖ in International Conference on
Ad-vances in Spatial and Temporal Databases, 2011.
[14] H. Gonzalez, J. Han, X. Li, M. Myslinska, and J. P. Sondag, ―Adaptive Fastest Path Computation on a Road Network: a Traffic Mining Approach,‖ in International Conference on Very
Large Data Bases, 2007.
[15] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein,