Available Online at www.ijpret.com 305
INTERNATIONAL JOURNAL OF PURE AND
APPLIED RESEARCH IN ENGINEERING AND
TECHNOLOGY
A PATH FOR HORIZING YOUR INNOVATIVE WORK
SCANNED DOCUMENT WITH ITS COMPRESSION TECHNIQUES- A REVIEW
SEEMA M. LAD1, SHUBHADA S. THAKARE2
1. Electronics Engineering Department, M.Tech. in Electronics System and Communication, Government College of Engineering Amravati. 2. Electronics Engineering Department, Assistant Professor, Government College of Engineering Amravati.
Accepted Date: 05/03/2015; Published Date: 01/05/2015
\
Abstract:The image compression is reduction of irrelevance and recurring image data in order to accumulate or transmit data in an efficient form. Although there are technological advances in storage and transmission, today’s demand of the storage capacities and bandwidth of communication exceeds the availability. Scanned document is compressed to reduce requirement of storage space and communication. Scan image is compound document may contain different parts such as text, image, graphics etc. To compress these documents they are first segmented into different regions then these regions are compressed independently. This paper reviews different segmentation and compression techniques for scanned compound document. Scanned document compression is used in many applications e.g. archiving and digital libraries etc. .
Keywords: Deletion, reduction, truncation, rounding, final addition, truncated multiplier.
Corresponding Author:MS. SEEMA M. LAD
Access Online On:
www.ijpret.com
How to Cite This Article:
Available Online at www.ijpret.com 306
INTRODUCTION
A digital image is a 2-Dimensional array of pixels. Digital documents, according to creation process can be classified into vectorized and raster documents. These documents have
different compression goals because of different noise characteristics.[1] Unlike vectorized
documents, raster documents typically contain visually noticeable noise. Therefore it becomes more realistic for scanned documents that compression is visually lossless and not just lossless. Scanned document is the compound type of document, may contain different regions like image, text, graphics etc.
A.Principal of compression
Compression of scanned document is different than natural image. Contents of scanned document are diverse than regular images and depend on generation process. Scanned document is image of data.It is compressed by two ways 1) As continuous tone picture, and 2) binarized it before compression. Continuous tone compression is preferred because
binarization may cause strong degradation to object contours and textures.[1]
Scanned image contains distortions such as noise, paper degradation artifacts and ghost
images.[8] Standard compression techniques can be use to compresses document but
performance of such type of compression is poor. Compound documents can be compressed by segmenting document into different regions and compress them with different compression algorithms.
B. Need of compression
The educational institute, private industries and government sector has number of files; require lot of space for storage. Digital document can be store in small space, cheaper to use and also can send on internet. Many document imaging applications such as document storage and archiving, scan for printing, scan-to-email, internet, fax, wireless data transmission, teleconferencing and online libraries require the use of scanned representations of documents.
C. Performance parameter
Following are the performance parameters use to compare different image compression techniques:
1. Mean Square Error (MSE)
2. Peak signal to noise ratio (PSNR)
Available Online at www.ijpret.com 307 The MSE gives mean square error between the compressed and the original image. MSE is given as in (1)
M y N x y x I y x I MN MSE 1 1 2 , , 1 (1)Where, I(x, y) is original image I’(x, y) is decompressed image And M, N are dimensions of image.
MSE gives an average energy lost in the lossy compression of the original image.[2] Small value
of MSE denotes less distortion whereas large value denotes more distortion.
PSNR gives measurement of peak error between original and compressed image. The PSNR is expressed in decibels. It is given as
MSE MAX PSNR I 2 10 log 10 (2)
Where, MAXI is the maximum pixel value of the image.
Compression ratio is the basic metric used to evaluate the performance of the compression
algorithm [2]. The compression ratio is given as
Compression = (output file size) / (Input file size) Ratio (%) (3)
D. Orientation
Section II presents different segmentation techniques. Section III presents different compression techniques and paper is concluded in Section III.
I. SEGMENTATIONTECHNIQUES
First step to compress a compound image is to segment that image into different regions. Compound image compression normally based on the following segmentation
1. Object Based
2. Layer Based
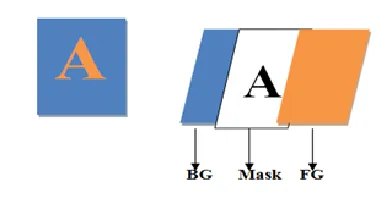
Available Online at www.ijpret.com 308 A page may consist of different objects such as a photograph, a graphic, a letter etc. In object based method a page is decomposed into object regions. These regions are represented using three layers mask, foreground, and background. Background layer contains picture, mask layer would contain text characters, line art, regions of graphics and text whereas foreground layer
contains the colors of the shapes in the mask layer.[1]The method is more complex than other.
Layer-based method divides a page into layers. Most of these methods follow the 3-layer mixed raster content (MRC) model as shown in fig. 1. This model represents a color image as two color layers, foreground (FG) and background (BG), third layer is a binary layer (mask). Mask layer is
used to recreate original image from FG/BG layers.[4] There are some limitations of this method
such as imperfect segmentation, coding of mask layer. Coding of this layer should be accurate because it contains information about foreground and background.
Block-based method divides a page into rectangular blocks. Block based segmentation is based on 1) histogram of block and 2) AC-coefficient based. The histogram based segmentation uses
different thresholds for separation of the blocks.[5] The AC coefficient based segmentation
uses AC coefficient of DCT to decide block type. Background block is identified by adding AC energy to user defined threshold. Other blocks are then classified as text or image block based
on k-means clustering by using feature vectors.[5] The advantages of this approach are easy
segmentation, use of existing compression algorithms
III. RELATEDCOMPRESSIONTECHNIQUESAVAILABLE
In traditional facsimile page compression run-length coding is applied on the document image, but it does not provide high compression ratio. There are several standards developed for binary image compression such as JPEG, JBIG1, JBIG 2, TIFF, CCITT group 3 and 4, GIF, Photo CD, PNG etc. CCITT is used for facsimile transmission of document which uses Huffman coding
technique.[6] JBIG is used as lossy or lossless compression technique for bilevel images.
Available Online at www.ijpret.com 309 The Djvu coder is the most popular algorithm for lossy compression of scanned document. It is based on Mixed Raster Content (MRC) model. The mask layer is compressed by the JBIG2 coder and the background or foreground layers are compressed by a wavelet-based image coder (IW44). For entropy coding both techniques uses a new adaptive binary arithmetic coder i.e. Z-coder. A typical magazine page scan at 300 dpi can be compressed with Djvu coder to
approximately 5 to 10 times better than JPEG for a similar level of subjective quality.[7] Though
Djvu has achieved high compression ratio, the quality of decoded images is merely satisfactory for the web-browsing purpose. With this method document images can be transmitted at faster rate over low speed connections.
The ancient document should be pre-processed first to remove noise. For compression document image is first segmented into the text and background images. Binarized text image
is compressed by using the pattern matching and substitution (PMS) compression technique.[8]
In this technique, dictionary of patterns is dynamically created from the image. Each new component in the image is compared with the elements in the dictionary and coded with a reference element. The patterns and the dictionary are then entropy coded using standard Ziv-Lampel dictionary based technique. After text removal from image, the background image is obtained by filling the holes. The background image is then compressed by using the lossy compression technique.
In reference [9], document image is compressed using structural analysis and pattern matching. Image is segmented into symbols according to the relation of foreground to background and symbol connectivity and a symbol set is formed. This initial symbol set is then converted to final symbol set using multistage structure clustering and removing repeated and identical patterns. The position of symbols and parameters of representative patterns are compressed using the adaptive arithmetic coder whereas library image is compressed using Q-coder. This technique is independent of symbol and size and can be used for various symbolic images. This method is used in [10] for compression of Chinese document images.
Available Online at www.ijpret.com 310 A technique uses the H.264/advanced video coding (AVC) standard video coder for scanned document image compression. In proposed method video interframe prediction is used as pattern matching algorithm for document coding. The image is first partitioned into the number of blocks. In encoding process inter-frame and intra-frame prediction is used to reduce the redundancy of the document image. In prediction technique a block is predicted by using neighboring blocks and prediction error is generated i.e. residual block. This block is compressed using integer transformed and resulting transformed coefficients are quantized. Context Adaptive Binary Arithmatic Coding (CABAC) is used for entropy coding. These techniques give the improvement of 6.2 dB over JPEG2000. The prediction is of little utility in
text images.[11] When this method is applied to the text document then it can generate the
residue block with energy close to that of the original block.
Reference [12] introduces a technique for scanned compound document encoding using multiscale recurrent patterns, which is based on the multidimensional multiscale parser (MMP). Image is first classified into smooth and non-smooth image block. Image decomposition is performed
Using block based segmentation. Binary segmentation mask is compressed using a differential adaptive arithmetic coder. The non-smooth block is encoded using the MMP-text algorithm and smooth block is encoded by using MMP-FP (flexible partitioning).
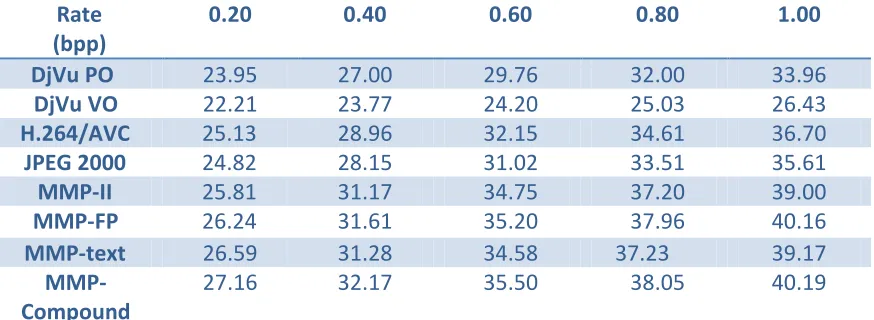
TABLE 1. Comparison of PSNR (dB) Djvu, H.264, JPEG 2000, and MMP
Rate (bpp)
0.20 0.40 0.60 0.80 1.00
DjVu PO 23.95 27.00 29.76 32.00 33.96
DjVu VO 22.21 23.77 24.20 25.03 26.43
H.264/AVC 25.13 28.96 32.15 34.61 36.70
JPEG 2000 24.82 28.15 31.02 33.51 35.61
MMP-II 25.81 31.17 34.75 37.20 39.00
MMP-FP 26.24 31.61 35.20 37.96 40.16
MMP-text 26.59 31.28 34.58 37.23 39.17
MMP-Compound
Available Online at www.ijpret.com 311
IV. CONCLUSION
In this review paper different segmentation and compression techniques are discussed. Numbers of different segmentation and compression techniques are introduced day by day. Based on this review paper we conclude that compression algorithm is depend on quality of reconstructed image, quantity of compression, speed of compression. Table 1 shows comparison of different compression techniques in terms of PSNR
ACKNOWLEDGMENT
I would like to express my deep sense of gratitude towards my guide Thakare S. S., who is a constant source of guidance, suggestions and inspiration. I also would like to thank all teachers and staff member of Electronics and Telecommunication Department for their help to complete this paper.
REFERENCES
1. R. L. de Queiroz, “Compressing compound documents,” in the Document and Image Compression Handbook, M. Barni, Ed. New York, USA: Marcel Dekker, 2005.
2. S. Jayaraman, S. Esakkirajan, T. Veerakumar, “Image Compression,” in Digital image processing, Ed. New Delhi McGraw-Hill, 2013, pp 493-494.
3. X. Li, S. Lei, “Block-based segmentation and adaptive coding for visually lossless compression of scanned documents,” in Proc. ICIP, vol. 3, 2001, pp 450-453.
4. D. Maheshwari, Dr. V. Radha, “Comparison of layer and block based classification in compound image compression,” IJCSIT, Vol. 2(2), pp. 888-890, 2011.
5. D. Maheshwari, Dr. V. Radha, “Improved block based segmentation and compression techniques for compound images,” IJCSET, Vol. 2 No. 3, pp. 49-53, 2011.
6. H. G. Musmann, D. Preuss, “Comparison of redundancy reducing codes for facsimile transmission of documents,” IEEE Trans. on Communications, Vol. Com-25, No. 11, November 1977.
7. L. Bottou et al., “High quality document image compression using DjVu,” Journal of Electronic Imaging, Vo1.7, pp.410-425, July 1998.
Available Online at www.ijpret.com 312 9. Y. Yang, H. Yan, D. Yu, “Content lossless document image compression based on structural analysis and pattern matching,” Pattern recognition 33, pp 1277-1293, 2000.
10. Maggie M. K. Tsui, Alan W. C. Liew, H. Yan, “Pattern based content lossless compression of Chinese document images,” International symposium on intelligent multimedia, video and speech processing, October 2004, 20-22.
11. A. Zaghetto, R. L. de Queiroz, June 2013, “Scanned document compression using block- based hybrid video codec,” IEEE Trans. image processing, vol. 22, No.6, pp.2420-2428, June 2013.