Informing Science: The International Journal of an Emerging Transdiscipline
Full text
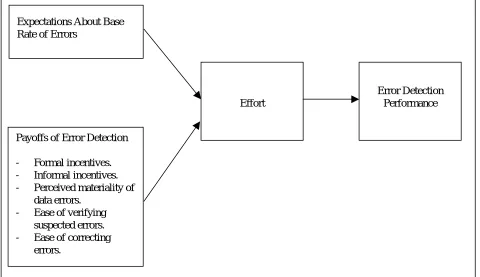
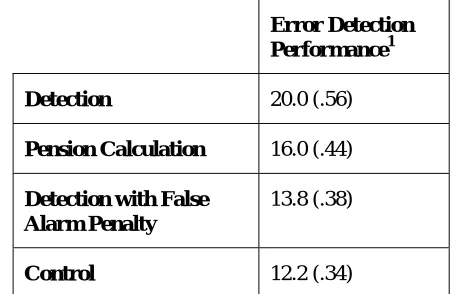
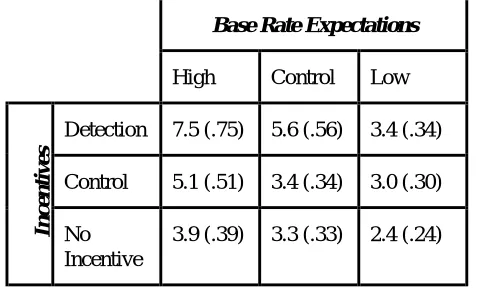
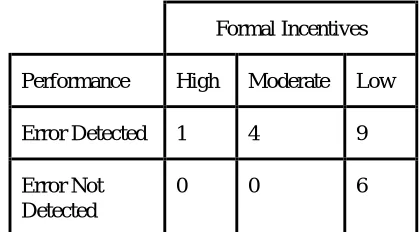
Figure
Related documents
Saker, Asymptotic behavior of solutions of a third-order nonlinear dynamic equation on time scales, J.. Saker, Hille and Nehari type criteria for third order dynamic
In our work, we have proposed a Graph based Node-Tagged propagation algorithm to predict spam in Mobile game apps. This Algorithm constructed bipartite graph G from
H control for uncertain 2-D discrete systems described by general model (GM) via state feedback controller has not been investigated up to date.. GM is one
graph and it show the minimum graph of node it provide shortest path Of node but it can be cost could be much larger than the cost of an MST, because the
Figure 1. The general model of distributed SOA applications in a cloud environment. The service consolidation problem is defined as an optimization problem which allocates
It deals with Web Services Security Architecture for Web Services Secure application design, for Authentication and authorization, using Model Driven Architecture
Imoru and Olatinwo [5] obtained some stability results for Picard and Mann itera- tion procedures by using a more general contractive condition than those of Harder and Hicks
THERAPY: WITH A REVIEW OF HEMATOLOGIC REACTIONS TO NEUTROPENIA IN AN INFANT SECONDARY TO
