Volume 2, Issue 11, November 2013
Page 342
Abstract
Computer systems and networks are increasingly used for many types of applications; as a result the security threats to computers and networks have also increased significantly. Traditionally, password user authentication is widely used to authenticate legitimate user, but this method has many loopholes such as password sharing, brute force attack, di ctionary attack and more. The aim of this paper is to improve the password authentication method using Probabilistic Neural Networks (PNNs) with three types of distance include Euclidean Distance, Manhattan Distance and Euclidean Squared Distance and four features of keystroke dynamics including Dwell Time (DT), Flight Time (FT), mixture of (DT) and (FT), and finally Up-Up Time (UUT). The results illustrate that Euclidean Squared Distance with (UUT) feature provide low error rate and high accuracy compared with the other two types of distances used.
Keywords: Biometrics, Keystroke Dynamics, Probabilistic Neural Network, User Authentication.
1.
I
NTRODUCTIONInternet applications use an authentication scheme to make sure that only genuine individual can login to the application [1]-[2]. User authentication is the process of validating claimed identity for the purpose of performing trusted communications between parties for computing application [3].Biometrics offers an automated methods for authentication and identification based on physiological or behavioral characteristics [4]-[5].
The keystroke dynamics authentication is based on the idea that each user has unique keystroke latency pattern which is different from others [6]. There are two types of keystroke dynamics: first one is the static keystroke dynamics in which the typed data is fixed and the typed time information is also fixed during login time. While the second one is continuous keystroke dynamics in which individuals are authenticated independently of what they are typing on the keyboard and the typing characteristics are analyzed during complete session [7].
This paper is organized as follows. Section two presents related work. Section 3 illustrates the features of keystroke dynamics. Section 4 presents the proposed approach; section 5 describes the proposed approach for user authentication, while the evaluation criteria explained in section 6. Finally the experiment results, results analysis and conclusions are given in sections 7, 8, and 9 respectively.
2.
R
ELATEDW
ORKThere are several previous works that may have a relation in one way or another to the present work.
-In[8], a comparison between ADALINE(Adaptive Linear Element) based on the single perceptron model and the BPNN(Back Propagation Neural Networks) model, using both the FT and digraph latency time, concluded that the BPNN surpass the ADALINE which was not capable of classifying patterns.
-In [9], a statistical method was used to classify users to legitimate users or impostors. The extracted FT feature was used and 63 users participated in their experiment.
-In [10], a statistical-based comprehensive study was carried out and presented the development of a keystroke dynamics-based user authentication system using the neural network with FT feature. The deduction was that neural network-dynamics-based methods have better results as compared with statistical methods in keystroke patterns classification.
-In [11], user’s typing biometrics was measured using a fuzzy logic. This experiment involved 29 users who provided their user ID (Identification) and password of length eight or more. Common DT were used and the typing difficulty between two successive keystrokes is calculated. One main disadvantage of using typing difficulty as keystroke feature was to set the categories of difficulty, as there are wide ranges of possibilities to define the typing difficulty.
3.
K
EYSTROKED
YNAMICSF
EATURESThe main purpose of the feature extraction phase is extracting vital features from the timestamp collected from raw keystroke data for template generation. The extracted features are certainly the critical means with regards to keystroke dynamics based biometrics and directly influence the performance of the classifier [11]. Extracting the right features from a dataset can reduce the computational complexity of the problem [14].Each sample in the dataset is represented by a sequence of timing information expressing the exact time at which keys have been pressed and released. There are many common types of features which can be extracted from a human keystroke as follows [11]-[12]:-
1-Dwell time: It is the time to measure how long a key is pressed (Down) until it is released (Up).
Probabilistic Neural Network for User
Authentication Based on Keystroke Dynamics
Sarab M. Hameed1, Mais M. Hobi2 and Sumaya Saad3
1,2,3
Volume 2, Issue 11, November 2013
Page 343
2-Flight time: It is the Interval between a key release (Up) and next key press (Down) time.3-Down-Down: It is the Interval between two successive key presses (Down). 4-Up-Up: It is the Interval between two successive key releases.
5-Tri-graph: Is the elapsed time between the first key press (Down) and the third key press (Down). 6-Placement of the fingers: a camera is required in this type.
7-Pressure of keystroke: In this case a special type of pressure which has a sensitive keyboard needs to be used.
4.
P
ROBABILISTICN
EURALN
ETWORKSThe PNN consists of input layer, pattern layer, summation layer, and output layer. The number of nodes in input layer depends on length of timing information vector for specific user. The pattern layer is designed to contain one neuron (node) for each training sample available and the neurons are split into the two classes. Each neuron in the pattern layer computes a distance measure between the presented input vector and the training example represented by that pattern neuron. The summation layer contains one neuron for each class, while the output layer contains one neuron. PNN algorithm is started with read timing information vector (X) and feed it to each Gaussian function in each class, then for each group of hidden nodes, compute all Gaussian functional values at the hidden nodes as illustrated in equation(2)[17].
2
) (
2 exp
D p i x
(2)
Where
i
p
: represents the output of a pattern node.
x
: is the timing information vector to be assigned into classc
i.
: smoothing factor.D
: represents the distance between the timing information vectorx
and the sample vector (reference vector)y
is computed in this paper using three types of distance measures as illustrated in the following equations [15]-[16]:1-Euclidean Distance: is one of the most popular distance metric between two vectors x and y and is computed as in equation (3).
2
) ,
( x y x y
D
(3)
2-Euclidean Squared Distance: uses the same equation as the Euclidean distance metric, but does not take the square root.
3-Manhattan Distance: the Manhattan (or city block) distance between vector x and vector y is calculated as in equation (4).
y x
y x D ( , )
(4)
After these steps, for each group of hidden nodes, feed all its Gaussian functional values to the single output node for that group as illustrated in equation(5).
) ( 1
) (
1
x j
p n
x y
n
i
i
j
i
(5)Where
i
y
: represents the output of summation node i for
classi
j
n
: represents the number of samples in pattern layer of
classi
i
p
: represents the output of pattern node i
Finally, find maximum value of all summed functional values at the output nodes comparing the values of Y1(x) and Y2(x).
Volume 2, Issue 11, November 2013
Page 344
5.
P
ROPOSEDA
PPROACH FORU
SERA
UTHENTICATIONThe aim of this section is to apply PNN for keystroke dynamics. This section, also, clarifies the attributes that can be extracted from the users based on their typing styles that can be employed to maximize subtle differences between the typing styles of users.
5.1Keystroke Dataset Collection Phase
An essential part of any keystroke dynamics system is the acquisition of users keystroke data from the keyboard [13]. Therefore the keyboard property is set to enable the proposed system to distinguish between authentic users and impostors in an accurate way. The dataset acquired is a collection of timing of keystroke for specific passwords over a period of three months. The users are randomly selected from the staff of Baghdad University/college of science to participate building the required datasets. Two datasets are created. The first one is named Keystroke-1and the second one is Keystrok-2.
In Keystroke-1, 17 users are asked to type the password "computer" twenty five times. Five times (i.e. five samples) per week's session, i.e. five weeks are required to collect the dataset for each user. The user types the password in different sessions because there is a chance that when the user types continuously the same password again and again, the typing speed may be increased. Further, to take the probability of all user variations and circumstances.
However, the password “computer” is considered weak because of the relative ease with which a third party can guess them or find them via dictionary attacks. Hence, another dataset, Keystroke-2, is built up in a similar way to Keystroke-1, but 16 users were participated (thirteen of them are similar to those who participated keystroke-1). Here the users were asked to type password “comp.84-rl” which satisfies the strong password selection criteria, i.e., at 10 characters in length combining symbols and numbers.
5.2 Feature Extraction phase
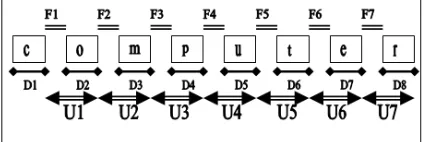
In this paper, DT, FT, and UUT features are extracted from the collected dataset. Figure (1) depicts the three major features that have been extracted when the users type the "computer" password. The same representation can be repeated with the second password”comp.84-rl”.
Figure 1 Features Representation of "computer" Password
The length of the timing information vector is different and depends on the length of the password, for example, a password “computer” which contains eight characters will result in eight DT, seven FT and seven UUT. Generally, a password with n character will yield n number of DT and n - 1 number for FT and UUT.
5.3 Preprocessing
To enable the proposed system to distinguish between authentic user and imposter with minimum error rate, a normalization process is performed as shown in equation (1)
(1)
where
F: is the feature value,
MinF: is the minimum value that the feature F can get, and MaxF: is the maximum value that the feature F can get.
5.4 Training Phase
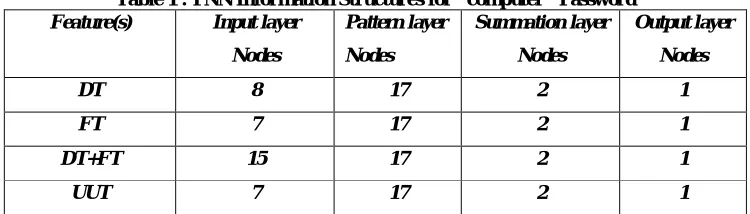
This section illustrates how PNN was used in proposed system..Table (1) shows the number of nodes in each layer when the features of "computer" password are extracted. The first row represents the information of PNN structure when DT feature is used. The number of input layer nodes represents the length of information timing vector according to specific feature. The number of pattern layer nodes represents the total number of training samples (users).
MinF MaxF
MinF F
F
Volume 2, Issue 11, November 2013
Page 345
Table 1 : PNN Information Structures for "computer" Password
Feature(s) Input layer
Nodes
Pattern layer
Nodes
Summation layer
Nodes
Output layer
Nodes
DT 8 17 2 1
FT 7 17 2 1
DT+FT 15 17 2 1
UUT 7 17 2 1
In this paper, there are two classes, the first class for authorized users and the second one for impostors. For example, in Keystroke-1 there are 17 users, the first 6 users are authorized and the remaining 11 users are impostors when the "computer" password is used. On the other hand, in Keystroke-2 there are 16 users the first 6 users are authorized and the remaining 10 users as impostors.
The main aim of training phase of PNN is to find a proper value of smoothing parameter
. In this paper, an algorithm is proposed to determine the proper range for
as clarified in algorithm (1). After the proper range for
is obtained, the training samples in pattern layer nodes are presented as input information vector in input layer. Then change
value within proper range and apply PNNalgorithm continuously until reaching to least error rates in classification. This value of
is considered the best value for good classification .Algorithm (1): Smoothing Parameter Range Determination
Input: Set of training timing information vectors
p
i,j.Output: Smoothing parameter
.Step1: [Find Mean Vector]
Compute the mean (centeroid) vector for each class
k
c
, 1<= k<=2.
1 i,j.
k
k p
N
Where
N
: is the total number of patterns with specific classj i
p
,: is the feature number
i
of pattern numberj
Step2: [Find Standard Deviation Vector]
Compute the standard deviation vector for each class, k.
.1 2
,
i ij
k
k p
N
std
where
i
: is theith
value of mean vectorStep3: [Find Range]
Find the minimum and maximum standard deviation value for each class to obtain the proper range of
value.5.5 Authentication Phase
Volume 2, Issue 11, November 2013
Page 346
output score of pattern layer node has the range of [0 1]. Then this output score is put forward into summation layer. Finally, the decision is made at output layer to classify the user either as authentic or imposter.6.
E
VALUATIONC
RITERIATo evaluate the predictive performance of the proposed biometric authentication system four measures are calculated. These measures are called False Reject Rate (FRR), False Accept Rate (FAR), Mean Error Rate (MER) and Accuracy. The formulas for calculating each of these measures are given as in equations (6), (7), (8) and (9) respectively [12]. FRR: is defined as the rate at which users are rejected when they could be authenticated.
attempts ligitimate of number Total
users ligitimate rejected
of Number FRR
(6)
FAR: is defined as the rate at which users are accepted when they should be rejected.
attempts impostor of number Total
attempts impostor accepted of Number FAR
(7) MER: is the mean rate of FAR and FRR.
2
FRR FAR
MER
(8)
Accuracy: is defined as the proportion of true results in the population.
attempts of number Total
attempts correct of Number Accuracy
(9)
7.
E
XPERIMENTALR
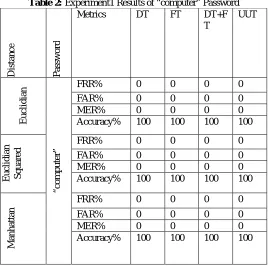
ESULTSTwo experiments are conducted independently. In each experiment the two passwords “computer” and “comp.4-rl” are used by PNN. In the first experiment was tested on the same sample in the training dataset i.e. 1 and Keystrok-2. Each sample contains mean values of keystroke timing vectors. The results of this experiment were obtained with error rates equal to 0% and Accuracy 100% of two passwords "computer" and "comp.84-rl" with three types of distances, as shown in tables (2-3).
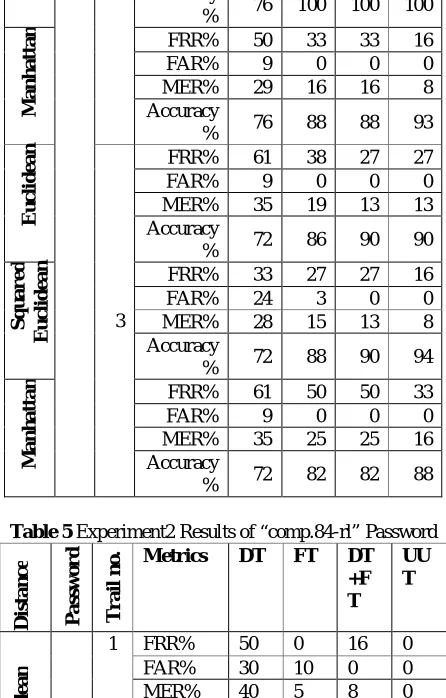
The second experiment deals with testing the proposed approach on line. This experiment includes computing the selected feature(s) for each key he/she typed. Then the preprocessing on the computed vector time is applied. Moreover, this experiment involves the testing when the proposed approach uses the first trial of password typing, and when it uses three trials of password typing. The results of this experiment are shown in table3( 4-5).
Table 2: Experiment1 Results of “computer” Password
D
is
ta
n
c
e
P
as
sw
o
rd
Metrics DT FT DT+F T
UUT
E
u
c
li
d
ia
n
“
c
o
m
p
u
te
r”
FRR% 0 0 0 0
FAR% 0 0 0 0
MER% 0 0 0 0
Accuracy% 100 100 100 100
E
u
c
li
d
ia
n
S
q
u
a
re
d
FRR% 0 0 0 0
FAR% 0 0 0 0
MER% 0 0 0 0
Accuracy% 100 100 100 100
M
a
n
h
a
tt
a
n
FRR% 0 0 0 0
FAR% 0 0 0 0
MER% 0 0 0 0
Accuracy% 100 100 100 100
Volume 2, Issue 11, November 2013
Page 347
D is ta n c e P a ss w o rdMetrics DT FT DT +FT UU T E u c li d ia n “ c o m p .8 4 -r l”
FRR% 0 0 0 0 FAR% 0 0 0 0 MER% 0 0 0 0 Accuracy
%
100 100 100 100
E u c li d ia n S q u ar ed
FRR% 0 0 0 0 FAR% 0 0 0 0 MER% 0 0 0 0 Accuracy
%
100 100 100 100
M a n h a tt a
n FRR% 0 0 0 0
FAR% 0 0 0 0 MER% 0 0 0 0 Accuracy
%
100 100 100 100
8.
R
ESULTSA
NALYSISThe PNN is used as keystroke dynamics authentication. The results of using PNN with different types of distances show the ability to distinguish authentic users from impostors. The results of experiment1 reflect a good training level in order to obtain high performance of proposed approach..The results of experiment2 give the indication to that the DT feature is the worst keystroke dynamic feature. On other hand experiment2 results indicate that UUT producethe best or equal results as compared with other features that are used in previous works DT, FT, and combination of DT and FT. Finally, the best results are obtained with UUT out performs others because UUT implicitly contains the two other features DT, and FT; that leads to build a new feature from the previous two features making the last feature having more capability to discriminate the authentic users from the impostors. Furthermore, this best result is obtained with fewer network net nodes when compared with combination of DT and FT features.The FAR%, FRR%, MER% and Accuracy of proposed approach evidence that it is possible to improve the password security mechanism considering not just the combination of DT and FT but also UUT feature.
9.
C
ONCLUSIONSFrom the results, one can conclude, in general, the following:
1-The DT, FT, and UUT features are candidate for distinguishing between authentic users and imposter one and may be exploited to reinforce password security.
2-The keystroke dynamics features namely DT, FT, combination of DT and FT and UUT are extracted. However UUT feature satisfies the best results among the others.
3-The accuracy of the presented work with PNN is close to meet acceptable error levels that would be required for a system with some degree of security.
4-When PNN with three types of distance metric (Euclidean distance, Euclidean squared distance, and Manhattan distance) is applied the results show that the Euclidean squared distance produced the best results.
Table 4 Experiment2 Results of “computer” Password
D is ta n c e P a ss w o r d T r a il n o .
Metrics DT FT DT +F T UU T E u c li d e a n “c o m p u te r" 1
FRR% 50 16 16 16 FAR% 9 0 0 0 MER% 29 8 8 8 Accuracy
% 76 94 94 94
S q u a r e d E u c li d e a
n FRR% 16 0 0 0
Volume 2, Issue 11, November 2013
Page 348
Accuracy% 76 100 100 100
M a n h a tt a
n FRR% 50 33 33 16
FAR% 9 0 0 0 MER% 29 16 16 8 Accuracy
% 76 88 88 93
E u c li d e a n 3
FRR% 61 38 27 27 FAR% 9 0 0 0 MER% 35 19 13 13 Accuracy
% 72 86 90 90
S q u a r e d E u c li d e a
n FRR% 33 27 27 16
FAR% 24 3 0 0 MER% 28 15 13 8 Accuracy
% 72 88 90 94
M a n h a tt a
n FRR% 61 50 50 33
FAR% 9 0 0 0 MER% 35 25 25 16 Accuracy
% 72 82 82 88
Table 5 Experiment2 Results of “comp.84-rl” Password
D is ta n c e P a ss w o r d T r a il n o
. Metrics DT FT DT
+F T UU T E u c li d e a n “ co m p .8 4 -r l"
1 FRR% 50 0 16 0 FAR% 30 10 0 0 MER% 40 5 8 0 Accuracy
%
62 93 93 100
S q u a r e d E u c li d e a n
FRR% 50 0 16 0 FAR% 30 10 0 0 MER% 40 5 8 0 Accuracy
%
62 93 93 100
M a n h a tt a n
FRR% 33 0 16 0 FAR% 20 20 10 0 MER% 26 10 13 0 Accuracy
%
75 87 87 100
E u cl id ea n
3 FRR% 55 5 5 11 FAR% 30 10 10 3 MER% 42 7 7 7 Accuracy
%
60 91 91 93
S q u a r e d E u c li d e a n
FRR% 66 11 5 11 FAR% 23 10 13 3 MER% 45 10 9 7 Accuracy
%
60 89 89 93
M a n h a tt a n
Volume 2, Issue 11, November 2013
Page 349
Accuracy%
62 87 89 91
R
EFERENCES[1] U. Dieckman N and R.W. Frischholz “BioID: A Multimodal Biometric Identification Systems” IEEE Computer, Vol.33, No. 2,pp.64-68, 2000 .
[2] F. Monrose and A. D., Rubin “Keystroke Dynamics as a Biometric for Authentication” Future Generation Computing Systems (FGCS), Vol.12, No 12, pp.351-359, 2000.
[3] L. O’Gorman Comparing Passwords, Tokens, and Biometrics for User Authentication, Proccedings of the IEEE,Vol.91,No.12, pp.2019-2040, 2003.
[4] Y. Chen and A. jain, “Beyond minutiae: A fingerprint individuality model with pattern, ridge and pore features,” in ICB09,2009.
[5] H. Mendez, C.Martin, J. Kittler,Y. Plasencia, and E. Garcia Reyes, “Face recognition with lwirimagery using local binary patterns,” in Proceedings of the International Conference on Advances in Biometrics, 2009.
[6] L. C. F Araujo,H. R. LuizSucupirajr., Miguel G. Lizarrage, Lee L. Ling, and Joao B. T. Yabu-Uti, “User Authentication Through Typing Biometrics Features”, IEEE Transactions on Signal Processing, Vol. 53,No.2, pp.851-855, 2005.
[7] D. Davis and W. Price, “Security for Computer Networks”, John Wiley & Sons, Inc., 1989.
[8] N. Abdullah, A.M. Ahmad, “User Authentication via Neural Networks”, in Proceedings of the 9th International Conference on Artificial Intelligence: Methodology, Systems, and Applications, pp. 310-320, 2000.
[9] D. C. D. Souza, “Typing Dynamics Biometric Authentication”, Bachelor engineering thesis, Faculty of Engineering and Physical Sciences, University of Queensland, Australia, 2002.
[10]L. C. Change., L. W. Kin, and L. C. Peng, "Keystroke Patterns Classification Using the ARTMAP-FD Neural Network", In proceeding of 3rd International Conference on Intelligent Information Hiding and Multimedia Signal Processing, IIHMSP, Vol. 2, pp. 61-64, 2007.
[11]P.S. Tee.,T.S. Ong. andA. B. J. Teoh, “A Multilayer Layer Fusion Approach on Keystroke Dynamics”, Springer, Vol. 14, pp. 23-36, 2011.
[12]H. Barghouthi, “Keystroke Dynamics How Typing Characteristics Differ from One Application to Another”, Msc in Information Security, Gjøvik University College, Norway, 2009.
[13]S.Steven Richard, "A New Approach to Securing Passwords Using a Probabilistic Neural Network Based on Biometric Keystroke Dynamics", Ph.D thesis, University of Newcastle upon Tyne, UK, The Department of Electrical and Electronic Engineering,2003.
[14]G. Romain,M. El-Abed and R.,Christophe, "Keystroke Dynamics Authentication", International Symposium on Collaborative Technologies and Systems, France, 2009.
[15]F.Monrose and A. D. Rubin, “Keystroke Dynamics as a Biometric for Authentication”, Future Gener Compute Syst Vol. 16, No.4, pp. 351– 359, 2000.
[16]R. Kenneth, "User Authentication via Keystroke Dynamics: an Artificial Immune System Based Approach", in Proceedings of 5th International Conference on Information Technology, 2011.