ABSTRACT
FUNDAMENTAL ASPECT OF 3D SPATIAL OBJECTS VALIDATION VIA SET AND EULER THEORIES
(Key words: 3D spatial objects, DBMS, set theory, and Euler theory)
This research attempts to explore two mathematical theories, namely, set and Euler theories for validation of 3D spatial objects which were generated or constructed from triangular irregular network. The relationship between the theories and spatial database development of the objects also investigated. Validating of 3D objects was restricted to 3D solid only, other primitives of validation such as solid and surface, solid and line, etc are not part of the study. The validation process of the 3D objects was carried out by developing a computer program based on C++ and couple with open source DBMS such as PostgreSQL. The results show that the theories could be utilised for validating 3D spatial objects.
Researchers:
Assoc Professor Dr Alias Abdul Rahman Chen Tet Khuan
Email: {alias, kenchen}@fksg.utm.my Tel: 07-5530806
TABLE OF CONTENTS
CHAPTER TITLE PAGE
ABSTRACT i
TABLE OF CONTENTS ii
LIST OF TABLES vi
LIST OF FIGURES vii
CHAPTER I INTRODUCTION
1.1 General Introduction 1
1.2 Problem Statement and Motivation 2
1.3 Research Objectives 3
1.4 Research Methodology 4
1.5 Research Scope 4
1.6 Issues to be Considered 5
1.7 Organization of Thesis 5
1.8 Expected Findings and Contributions 7
1.9 Conclusion 7
2.2.2 Conventional DBMS data types 13
2.3 Spatial DBMS 16
2.3.1 DBMS Advantages Over File
System 17
2.3.2 Native Geometry and Non-Native Geometry Types
19
2.3.3 Spatial Queries 21
2.3.4 Spatial Indexing 22
2.4 Spatial Data Models 27
2.4.1 Spaghetti Data Model 28 2.4.2 Topological Data Model 30
2.5 The Existing Geo-DBMS 32
2.5.1 Oracle Spatial 35
2.5.2 PostGIS 38
2.5.3 MySQL 41
2.5.4 Some Reasons Why the PostgreSQl is Chosen
43
2.6 Summary and Conclusion 46
CHAPTER III OGC STANDARDS FOR GEOSPATIAL MODELLING
3.1 Introduction 47
3.2 OGC Abstract Specification for Feature
Geometry 48
3.2.1 Unified Modeling Language
(UML) Concepts 50
3.2.4.1 GM_Solid 58
3.2.4.2 TM_Solid 62
3.3 OGC Implementation Specification for
DBMS 63
3.4 Summary and Conclusion 66
CHAPTER IV FUNDAMENTAL SET AND EULER THEORIES
4.1 Introduction 68
4.2 Set Theory 69
4.2.1 Naive Set Theory 69
4.2.2 Axiomatic Set Theory 70 4.3 3D Topological Data Modeling for DBMS 72 4.3.1 3D Formal Data Structure (3D
FDS) 72
4.3.2 TEtrahedron Network (TEN) 74 4.3.3 Simplified Spatial Model (SSM) 76
4.3.4 Modified Topological Structure
Model 77
4.4 Implementation of Set Theories for
Spatial Data Modeling 78
4.4.1 Geometric Properties 79
4.5 Euler Theory 82
4.5.1 The Generalization of Euler's
Formula 84
CHAPTER V IMPLEMENTATION AND EXPERIMENT
5.1 Introduction 91
5.2 User-defined function for DBMS 92 5.2.1 Calling Conventions Version 0
for C-Language Functions 92
5.2.2 Calling Conventions Version 1
for C-Language Functions 94
5.2.3 Compiling and Linking
Dynamically-Loaded Functions 96
5.3 Querying 3D Topological Data Structure 98 5.4 Validation of The 3D Spatial Object 99
5.5 Summary and Conclusion 100
CHAPTER VI CONCLUSIONS AND RECOMMENDATIONS
6.1 Conclusions 101
6.2 Recommendations 102
LIST OF TABLES
NO TITLE PAGE
2.1 List of the default data types in DBMS 16
4.1 Logical operators, T = TRUE; F = FALSE 71
4.2 Platonic solids (without hole) that apply the
LIST OF FIGURES
NO TITLE PAGE
2.1 Directory of R-Tree indexing 24
2.2 A planar representation of an R-tree 25
2.3 A 3D representation of an R-tree 25
2.4 Spaghetti data model 29
2.5 The relations R1, R2, R3 and R4 32
3.1 Sample of UML diagram 51
3.2 (a). Composition, and (b). Aggregation 53
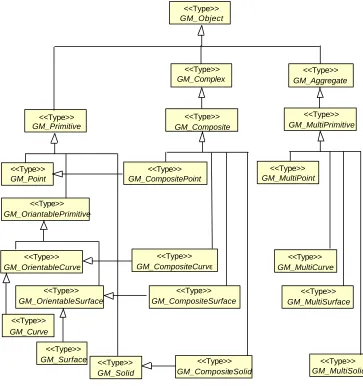
3.3 Geometry basic classes given in OGC 55
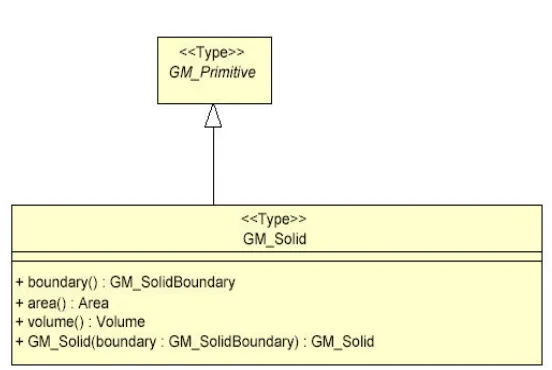
3.4 GM_Solid data type defined by OGC 59
3.5 Geometry package in OGC abstract specification
61
3.6 (a). TP_Solid defined, and (b). TP_Object
defined by OGC 62
3.7 PolyhedralSurface with consistent
orientation 64
3.8 Implementation specification for
PolyhedralSurface 64
4.1 3D FDS 74
4.2 TEN 75
4.3 Simplified Spatial Model 76
4.4 Modified topological data structure 78
4.5 Topological data structure 79
4.7 Sample of Platonic solids 83
4.8 Torus-like polyhedron 85
4.9 A cube 86
4.10 A cube with one inner loop on the top face 86
4.11 A cube with hole 87
4.12 TEN model 88
5.1 The methodology of creating new function
in DBMS environment 97
CHAPTER I
INTRODUCTION
1.1 General Introduction
3D conceptual spatial model, topological relationships, data collection, and spatial analysis might comprise a wide spectrum of questions.
With these efforts, the possibility of implementing set and Euler theories in 3D GIS is obvious and could be done by extending the existing 2D spatial data type to 3D. Therefore, some important questions are raised:
1). What are the fundamental set and Euler theories that can be implemented for 3D spatial modeling?
2). How to implement the set and Euler theories within DBMS?
Therefore, from the foregoing discussion, it can be seen that many issues need to be investigated. In this project, only part of the problems attempt to be investigated, that is to investigate the possibility of set and Euler theories for 3D GIS within DBMS environment. First, a new 3D data type, i.e. polyhedron, will be defined, which implements the set theory for object primitives and features. Later on, the 3D topological data structure will be designed within geo-DBMS (in this context, PostGIS (2006) is used). The 3D spatial object will be validated using the Euler theory. Recall the ultimate goal of this research is to develop 3D spatial spatial modelling using set and Euler theories, 3D visualization is out of the scope of this research.
be considered the most primitive kind of spatial information, since a change in topology implies a change in other geometric aspects, while the opposite is not true. The strength of topology comes from its mechanism, which able to reduce redundant data, provide object relationship for topological analysis (spatial query). Besides, other useful application is to accelerate/skip the computational geometry process. This could be accomplished as feature instances and geometric object instances are associated explicitly. This method manages to produce fast topological query because the geometrical calculations such containment (point- in-polygon), which is computationally intensive process is not involved. The combinatorial structures, which known as topological complexes are implemented to convert computational geometry algorithms into combinatorial algorithms. The methodology of combining topological primitives, i.e. nodes, edges, or faces, to construct a topological complex, e.g. solid, will be involved into combinatorial algorithms. In GIS, topology is commonly used in DBMS in order to enhance the functionalities of topological analysis, e.g. object’s construction and validation, relationship, etc.
The 3D spatial data modeling that implement set and Euler theories for topological structure are not available in DBMS. Two researches had been done in creating new 3D data types in DBMS: 3D polyhedron (Arens, 2003) and 3D freeform object (Pu, 2005). Both user-defined data types were designed and mapped into DBMS using external program. However, the 3D spatial data modeling does not implement the set and Euler theories. The implementations of both theories are important for topological data structure and data type validation.
1.3 Research Objectives
1. Since the 3D spatial data modeling implementing the set theory is rather limited within DBMS, the research is to investigate the possibility of developing 3D topological data structure within the DBMS environment;
2. Since validation function that implements Euler theory is important to validate the correct input data, the research also investigates the Euler theory to validate the defined 3D spatial data type from the topological structure.
1.4 Research Methodology
The methodologies of the research are to:
1. Implement the C language to create new user-defined data type for 3D object, 3D polyhedron for topological data structure. The data structure will implement the set theory that will ensure the produced 3D spatial data type could be used for an input validation function.
2. Validate the produced 3D spatial object from the 3D topological data structure using the Euler theory. The rule for the validation function should clearly define the valid 3D spatial object within DBMS environment.
3. The design is mapped using the C language (3D validation function) into DBMS. The Linux operating system and PostgreSQL will be implemented.
4. Visualize the 3D spatial object using ESRI ArcGIS module.
1. Since the research is focused on geometrical and topological models, the data structure (in defining a new 3D data type) of both models will be discussed extensively.
2. Since the absent of 3D data type in DBMS, the research aims to create a new user-defined data type for 3D spatial object, 3D polyhedron. With this effort, C language is used to define the new data type, whereas PostgreSQL will be used to provide the DBMS environment.
3. Since the absent of validation function that implement Euler theory for 3D spatial data type in DBMS, the research will attempt to create a validation function to validate the data input for 3D spatial object.
4. Questions related to data collection, dataset preparation, and 3D visualization are not treated explicitly in the research.
1.6 Issues to be Considered
1. How to implement the set theory for 3D topological data structure for 3D spatial data modelling?
2. How to implement the Euler theory for validating the designed 3D spatial data type, i.e. polyhedron?
1.7 Organization of Thesis
background theories of set and Euler theories. This part focuses on the supported theories for 3D spatial data modeling. This part is included in the chapters 4. The third part is the implementation and testing phase. It demonstrates how the design of 3D data type came into practice and explains the validation function for 3D spatial data object. This part includes chapter 5. Finally chapter 6, the concluding part, summarizes the most important achievements of the report.
Chapter 1 discusses the introduction for research. The chapter also discussed in brief the current DBMS status with respect to the defined scope is given, leading to the identification of the remaining problems and the objectives of the research.
Chapter 2 discusses the existing DBMS in general. A detailed review of current DBMS status is carried out, in term of spatial aspect, and data model. The research also selects one existing module as a DBMS platform.
Chapter 3 relates some reviews of OGC standard for 3D spatial data modeling. The standards include abstract specification and implementation issues for DBMS.
Chapter 4 discusses the background theory relating to the set and Euler theories. The theories will be used to extend the existing 2D spatial data modeling to 3D. The validation function that implements the Euler theory also being included in this chapter.
Chapter 6 concludes with the major findings of the research and recommendations of issues for future research.
1.8 Expected Findings and Contributions
The contributions to knowledge as a result of this research are:
• Investigation of 3D spatial data modelling implementing set for topological data structure, and Euler theory for validation function within geo-DBMS environment.
• Documentation of a methodology for the 3D spatial data modeling for 3D GIS.
The findings and contributions of this thesis are applicable and useful to:
• Commercial DBMS for 3D GIS
1.9 Conclusion
CHAPTER II
DBMS
2.1 Introduction
The second stage of the research started with a review existing DBMSs, in terms
of their characteristics and functionalities in managing data. A database management
system (DBMS), or database manager, is a program that lets one or more computer users
create and access data in a database. The DBMS manages user requests (and requests
from other programs) so that users and other programs are free from having to
understand where the data is physically located on storage. In handling user requests, the
DBMS ensures the integrity of the data (that is, making sure it continues to be accessible
and is consistently organized as intended) and security (making sure only those with
access privileges can access the data). The most typical DBMS is a relational database
management system (RDBMS). A newer kind of DBMS is the object-oriented database
management system (ODBMS). Common DBMS implements a standard user and
2.2 DBMS in General Terminology
The database management system, or DBMS, is a computer software program
that is designed as the means of managing all databases that are currently installed on a
system hard drive or network. Different types of database management systems exist,
with some of them designed for the oversight and proper control of databases that are
configured for specific purposes. A DBMS can be thought of as a file manager that
manages data in databases rather than files in file systems. In IBM's mainframe
operating systems, the non-relational data managers were (and are, because these legacy
application systems are still used) known as access methods. IBM's Information
Management System (IMS) was one of the first DBMSs. A DBMS may be used by or
combined with transaction managers, such as IBM's Customer Information Control
System (CICS).
There are four essential elements that are found with just about every existing
DBMS. The first is the implementation of a modeling language that serves to define the
language of each database that is hosted via the DBMS. There are several approaches
currently in use, with hierarchical, network, relational, and object examples. Essentially,
the modeling language ensures the ability of the databases to communicate with the
DBMS and thus operate on the system.
Second, data structures also are administered by the DBMS. Examples of data
that are organized by this function are individual profiles or records, files, fields and
their definitions, and objects such as visual media. Data structures are what allow DBMS
to interact with the data without causing and damage to the integrity of the data itself.
Some related works could be found in Hadzilacos and Tryfona (1996), Lipeck and
A third component of DBMS software is the data query language. This element
is involved in maintaining the security of the database, by monitoring the use of login
data, the assignment of access rights and privileges, and the definition of the criteria that
must be employed to add data to the system. The data query language works with the
data structures to make sure it is harder to input irrelevant data into any of the databases
in use on the system.
Last, a mechanism that allows for transactions is an essential basic for any
DBMS. This helps to allow multiple and concurrent access to the database by multiple
users, prevents the manipulation of one record by two users at the same time, and
preventing the creation of duplicate records. Related work could be found in Abel et al.
(1995).
Various applications of DBMSs have brought to the great evolutions to the
computer revolution. It can store a huge quantity of data at one place and queried with
simple methods. DBMS are furthermore ideally thought of facilitating several processes,
such as (Rigaux et al., 2002):
• Defining a database - that is specifying data types, structures and constraints.
• Develop a database - create database and store dataset.
• Manipulating a database.
• Querying a database to retrieve specific data.
• Updating a database.
To execute any command within DBMS environment, the most common
However, as RDBMS only stores simple data types, alternative solution had to be
invented to handle complex data types like spatial data. The solution is to implement the
object-oriented approach in the DBMS (OO-DBMS). This technology has however not
gained as much popularity as first expected, but guided the development of
object-relational DBMS (OR-DBMS) that somewhat combines the functionalities of the two
approaches (Shekhar and Chawla, 2003).
2.2.1 SQL (Structured Query Language)
SQL stands for Structured Query Language. SQL is an ANSI (American
National Standards Institute) standard computer language for accessing and
manipulating database systems. SQL statements are used to retrieve and update data in a
database. Unfortunately, there are many different versions of the SQL language, but to
be in compliance with the ANSI standard, they must support the same major keywords
in a similar manner (such as SELECT, UPDATE, DELETE, INSERT, WHERE, and
others).
While the SQL Standard is often perceived as established technology, rather than
the innovative, cutting edge technology it was when the standards process started in
early 1980's, it is still an expanding, evolving, relevant standard.
The original SQL standard was completed as a USA ANSI (American National
Standards Institute) standard in 1986, and adopted as an ISO (International Standards
Organization) standard in 1987. To allow relevant pieces to progress at different rates,
completed in the 1990's, as additions to SQL-1992. SQL/CLI (Call Language Interface)
was completed in 1995 and SQL/PSM (Persistent Stored Modules) was completed in
1996. Following the completion of SQL:1999, there has been significant work on SQL
with Java (a Sun trademark) and XML, as well as the use of SQL to manage data
external to an SQL database.
Another revision to all of the parts was completed as SQL:2003. Since
SQL:2003, the SQL standards committees have expanded XML support and corrected
some errors. The expanded SQL/XML standard will be completed in late 2005 or early
2006. In addition to the SQL standards, there is a separate set of specifications called
SQL/MM that is a multi-media expansion of the SQL Standard.
From SQL standard language, there are several separate components in SQL
structure. Two of the most important are ‘Data Definition Language’ (DDL) and ‘Data
Manipulation Language’ (DML) (Shekhar and Chawla, 2003; Rigaux et al., 2002).
The Data Definition Language (DDL) part of SQL permits database tables to
define the data, tables, constrains and association. User can also define indexes (keys),
specify links between tables, and impose constraints between database tables. The most
important DDL statements in SQL are:
• CREATE TABLE - creates a new database table
• ALTER TABLE - alters (changes) a database table
• DROP TABLE - deletes a database table
• CREATE INDEX - creates an index (search key)
In Contrary, DML is apply SQL syntax for executing queries or used to access and edit
data in a database and perform operation like INSERT, UPDATE, DELETE, and
SELECT. These query and update commands together form the DML part of SQL:
• SELECT - extracts data from a database table
• UPDATE - updates data in a database table
• DELETE - deletes data from a database table
• INSERT INTO - inserts new data into a database table
2.2.2 Conventional DBMS data types
All DBMSs provide multiple choices of data types for the information that can
be stored in their database table fields. However, the set of data types made available
(typically numeric and alpha-numeric) varies from DBMS to DBMS.
The Object ID data type usually utilizes as primary key type for most of the
DBMSs. The primary key of a relational table uniquely identifies each record in the
table. The major difference is that for unique keys the implicit NOT NULL constraint is
not automatically enforced, while for primary keys it is. It can either be a normal
attribute that is guaranteed to be unique or it can be generated by the DBMS (such as a
globally unique identifier, or GUID, in Microsoft SQL Server). Prima ry keys may
consist of a single attribute or multiple attributes in combination. The common data type
The Integer data type may store integer values as large as each DBMS may handle.
Fields of this type may be created optionally as signed or unsigned integers, depending
on different DBMS that support it. The type of integer can be divided into INTEGER
(-2,147,483,647 to 2,147,483,647) SHORT INTEGER (-32,768 to 32,767), LONG
INTEGER (-9,223,372,036,854,775,808 to 9,223,372,036,854,775,807)
The decimal data type may store decimal numbers accurately with a fixed
number of decimal places. This data type is suitable for representing accurate values like
currency amounts. Some DBMS drivers may emulate the decimal data type using
integers. Such drivers need to know in advance how many decimal places that should be
used to perform eventual scale conversion when storing and retrieving values from a
database. There are several kinds of decimal data type available in DBMS, e.g.
Float/Real, and Double. The Float/Real data type may store floating-point decimal
numbers. This data type is suitable for representing numbers within a large-scale range
that do not require high accuracy. The scale and the precision limits of the values that
may be stored in a database depends on the DBMS that it is used (usually referred to 32
bit floating point).The Double data type stores same as Float/Real data type if the data
type is suitable for representing numbers that require high accuracy. The scale and the
precision limits of the values that may be stored in a database depends on the DBMS
that it is used (usually referred to 64 bit floating point).
The text data type is available with several options for the length. For instances,
Character, and Varying Character. The fields of this type should be able to handle 8 bit
characters (variable-length character string, 0-255). Some DBMS able to provide 16 bits
character (variable-length character string, 0- 65,535) for specific storage purposes, e.g.
The Date data type may represent dates with year, month and day. DBMS independent
representation of dates is accomplished by using text strings formatted according to the
IS0 8601 standard. The format defined by the ISO 8601 standard for dates is
YYYY-MM-DD where YYYY is the number of the year (Gregorian calendar), MM is the
number of the month from 1 to 12 and DD is the number of the day from 1 to 31.
Months or days numbered below 10 should be padded on the left with 0. Some DBMS
have native support for date formats, but for others the DBMS driver may have to
represent them as integers or text values. In any case, it is always possible to make
comparisons between date values as well sort query results by fields of this type.
Another data type related to Date is the time data type that may represent the time of a
given moment of the day. DBMS independent representation of the time of the day is
also accomplished by using text strings formatted according to the IS0 8601 standard.
The format defined by the ISO 8601 standard for the time of the day is HH:MI:SS where
HH is the number of hour the day from 0 to 23 and MI and SS are respectively the
number of the minute and of the second from 0 to 59. Hours, minutes and seconds
numbered below 10 should be padded on the left with 0. Some DBMS have native
support for time of the day formats, but for others the DBMS driver may have to
represent them as integers or text values. In any case, it is always possible to make
comparisons between time values as well sort query results by fields of this type.
The large object data types are meant to store data of undefined length that may
be to large to store in text fields, like data that is usually stored in files. Certain DBMSs
support two types of large object fields: Character Large OBject (CLOB) and Binary
Large OBject (BLOB). CLOB fields are meant to store only data made of printable
ASCII characters. BLOB fields are meant to store all types of data in binary format.
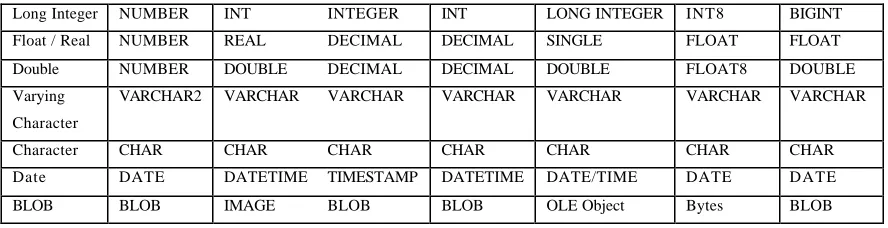
Table 2.1 provides overview of database data types, its description and naming.
Data Type
Long Integer NUMBER INT INTEGER INT LONG INTEGER INT8 BIGINT Float / Real NUMBER REAL DECIMAL DECIMAL SINGLE FLOAT FLOAT Double NUMBER DOUBLE DECIMAL DECIMAL DOUBLE FLOAT8 DOUBLE Varying
Character
VARCHAR2 VARCHAR VARCHAR VARCHAR VARCHAR VARCHAR VARCHAR
Character CHAR CHAR CHAR CHAR CHAR CHAR CHAR Date DATE DATETIME TIMESTAMP DATETIME DATE/TIME DATE DATE BLOB BLOB IMAGE BLOB BLOB OLE Object Bytes BLOB
Table 2.1: List of the default data types in DBMS
2.3 Spatial DBMS
A great way to manage with geographic objects and images of immense size with
high performance is to use of spatial DBMS technology. When a DBMS offers a native
geometry type together with supporting capabilities (such as spatial indexing), it is
referred to as a spatial DBMS (Paredaens, 1995; and Schneider, 1997).
GIS has become an important computerized application that major DBMS
vendors have extended their DBMS products with native geometry types as well as with
supporting capabilities. Oracle's dedicated spatial product, Oracle Spatial, provides
Oracle's SDO_GEOMETRY in order to manage spatial object within DBMS. Other
DBMS packages, such as IBM DB2 have spatial extenders, and open source DBMS
packages such as PostgreSQL now include “spatial” capabilities as well.
geometry of the spatial object. It specifies the shape and location of the points, lines and
areas of which the object consists. The second type of information is the attributes
information that may be attached to geometric objects. For example, an object (polygon)
that consists of a set of coordinates triplet providing the name from a country, may also
have attributes that give information about its area.
In nature, spatial data types are not provided by DBMS. Hence, a DBMS is
named as spatial DBMS if spatial data types are considered. A special column is used to
stored spatial data types within spatial DBMS, namely spatial column. However, special
program would be needed to visualize the geometry.
2.3.1 DBMS Advantages over File System
There are other ways to store and retrieve spatial information than offered by
DBMS (Ingvarsson, 2005). File format such as ESRI shape file (SHP) and Drawing
eXchange Format (DXF) used in CAD systems implement file system to store geometry
data. However, the concept of spatial DBMS offer several advantages batter than file
based solution (Shekhar & Chawla 2003). These advantages come from the capability of
DBMS system and architecture, which it manage to:
• Handle large amounts dataset with different data structures;
• Perform complex spatial query on the data with near instant results (e.g. routing);
No doubt, there are several advantages to storing attribute data externally outside
the DBMS. Even though geometry continues to be managed exclusively within the file
system, some limitations may be appeared.
The first limitation is that GIS packages usually do not have the sheer capacity
and cluster scalability of mainstream DBMS packages like Oracle or SQL Server. As a
result, the number of objects in geometry will normally be limited by the performance of
the file system running on a single machine.
A second limitation is often a restriction to single users or single processes
working with the geometry data stored by the file system. Mainstream DBMS packages
have evolved to meet intensely multi-user, multi-process needs but most file systems
have not been built with the multi-process, transaction-oriented architecture required for
intensively multi-user operations on geometry.
A third limitation is limited dynamic interoperability between different file
system packages and other applications. File system data can be intercha nged more or
less successfully in a static, limited way using well known formats such as shapefiles,
but cannot in general be interchanged dynamically as is taken for granted with DBMS
servers.
A dataset that can store geometry in a spatial DBMS can escape the above
limitations. Storing geometry in a DBMS can take advantage of the capacity and
scalability of the DBMS, resulting in drawings that can be terabytes in size. If a DBMS
the DBMS allows interchange with any application that understands those data types,
which will improve the interoperability in GIS.
2.3.2 Native Geometry and Non-Native Geometry Types
In spatial database, spatial data types are usually defined as Abstract Data Types
(ADT), i.e. encapsulated types together with spatial operations. At implementation level,
one can define spatial indices on spatial ADTs (Cardelli and Wegner, 1985; Liskov and
Zilles, 1974; Stonebraker, et al., 1983; Stonebraker, 1986). A spatial object is an
instance of a spatial type; it can have 0 (point), 1 (line), 2 (polygon), and 3 (solid)
dimensions. All data stored in a DBMS is ultimately in binary form. When storing
geometry within a DBMS, the question is what internal format the DBMS should use to
order the binary data used to store that geometry. There are two approaches.
One approach is used in DBMS as spatial DBMS. A spatial DBMS will have a
pre-defined way of organizing binary data to represent geometry, and this pre-defined
way of organizing binary data is built into the DBMS in the form of a data type, such as
SDO_GEOMETRY in Oracle Spatial or ST_GEOMETRY in IBM's DB2 Spatial
Extender. Because this data type is built into the DBMS it is called a native geometry
type. The data is still binary data, of course, but it has been organized in accordance with
a format expected for geometry data by the DBMS. When a DBMS has its own data
types, native geometry type it is also usually being supported within the DBMS
environment with additional infrastructure, such as the automatic creation of spatial
The other approach is used with DBMS that do not specify a pre-defined way of
organizing binary data to represent geometry but allow applications to utilize a generic
binary data type. Almost all existing DBMS provide a generic binary data type that can
be used to store binary data, which is unstructured by the DBMS. Often referred to as a
BLOB (Binary Large OBjects), such generic binary storage can be employed by
applications if they can fit. When such generic binary storage is used to store geometry
in a form not built into the DBMS it is called a non-native geometry type. Although the
use of non-native geometry types allows storing geometry within general-purpose
DBMS without requiring a special spatial form of a DBMS, it does require a GIS
application that supports the geometry formats to be used.
The main advantages of using a native geometry type within a spatial DBMS is,
first, to provide interoperability with any application that uses the native type, and
second, using a native type automatically takes advantage of the infrastructure within the
spatial DBMS that supports that native data type.
The main advantages of non-native binary storage are, first, to make us e of
spatial DBMS functionality utilizing non-native types within virtually every DBMS and
second, using a choice of non-native geometry types can provide greater flexibility
rather than committing to a single data type with specific format. A possible
disadvantage is that choosing from a variety of geometry types can make interoperability
with other applications more difficult. However, if a generic geometry type that is
well-defined and accepted by many applications, such as Well-Known Binary (WKB), is
2.3.3 Spatial Queries
Spatial query is a method of data searching within DBMS that satisfy a given
condition. There are two types of queries; both queries are not much different compared
to each other:
1. Query of attribute data - A spatial distribution or an area will be searched
with respect to a given attribute of interest.
2. Query of geometric data - With a given geometric condition for example
location, shape or intersection, all data that satisfy the condition will be
searched. In the case of a vector data form, to search an area, which includes
a given point, and to find all line segments that intersect a given line would
be a typical query of geometric data. In the case of raster form of data, it will
be easier to search any attribute and geometric data based on a given grid.
From the query of geometric data (also called spatial query), it is divided into
two types: static and dynamic query. A static query only observes the spatial objects and
returns a result without affecting the objects queried, e.g. measure area of a polygon.
Dynamic queries are different from static in the way that they affect the data itself, e.g.
merge, split, rotate, resize and copy (Shekhar and Chawla, 2003).
To perform spatial, some query languages are used. Query languages for
geographic databases and geographic information systems are either complex macro
languages, or extensions of SQL (Egenhofer, 1996). There are a large variety of Spatial
SQL dialects, and such SQL provides the means for accessing geographic databases and
retrieving data from a database. Most critical is the support for spatial relations. The
spatial relations are defined in order to become the logical condition for spatial query.
queries, which relates spatial relations. The term two-tier is used to indicate that two
distinct operations are performed in order to resolve queries. If both operations are
performed, the exact result set is returned. The two operations are referred to as primary
filter and secondary filter operations (Oracle Spatial 10g, 2007).
• The primary filter permits fast selection of candidate records to pass along to the secondary filter. The primary filter uses geometry approximations (or index tiles)
to reduce computational complexity and is considered a lower-cost filter.
• The secondary filter applies exact computational geometry to the result set of the primary filter. These exact computations yield the exact answer to a query. The
secondary filter operations are computationally more intensive, but they are
applied only to the relatively small result set returned from the primary filter.
2.3.4 Spatial Indexing
Another important aspect of data management within DBMS is spatial indexing.
Spatial indexes are used in DBMS for fast search especially when spatial functions are
applied. The problem with querying spatial data is that a common query, like querying a
point, would need to compare and check the point location with the geometry of every
object in the database, which is both time and memory consuming if the database is
large. Spatial indexing was developed to resolve this. Without indexing, any searches for
a feature would require a sequential scan of every record in the database. Indexing
speeds up searching by organizing the data into a search tree that could be quickly
traversed to find a particular record. There are few kinds of indexes within DBMS, i.e.
• B-Trees are used for data, which can be sorted along one axis; for example, numbers, letters, dates. B-tree is a fast data-indexing method that organizes the
index into a multi-level set of nodes. Each node contains a sorted array of key
values (the indexed data). Two important properties of a B-tree are that all nodes
are at least half-full and that the tree is always balanced (that is, an identical
number of nodes must be read in order to locate all keys at any given level in the
tree). A detail description of B-tree could be found in ITTIA (2005).
Another spatial indexing methods that store the approximation of geometry is in
the form of minimum-bounding box. This kind of spatial query is considered as a
two-step process, which involves the filter two-step and refinement two-step. The filter two-step compares
and eleminate the candidates that do not intersect with the query condition. This is less
time consumed as it is much simpler to compare and filter the geometry of the envelops
than the object geometry. The refinement step drops out the geometry that does not
intersect
with the spatial query though its envelope did. Finally the correct objects are returned as
a result of the spatial query.
The refinement step is rather uniform in all spatial indexing methods. It is
conventionally categorised into either space-driven or data-driven approaches (Rigaux et
al. 2002).In a space-driven approach, the 2-dimensional planar space is partitioned into
number of rectangles that are independent of the objects they serve. The objects are then
mapped to cells according to geometric criteria that differ somewhat considering what
method is used. Most popular space-driven methods are named “grid -file”,
“linear-quadtree” and “z-ordering tree”. A data-driven approach on the other hand, focuses on
the objects and in partitioning them into appropriate/logical groups considering number
and distribution in space. Most popular data-driven methods is the ‘R-tree’ and its
• R-Trees break up data into rectangles, and sub-rectangles, and sub -sub
rectangles, etc. R-Trees are used by some spatial databases to index GIS data, but
the PostGIS R-Tree implementation is not as robust as the GiST implementation.
Oracle Spatial will implement the 3D R-Trees in the coming version 11g.
The concept of sample R-tree structure is given in Figure 2.1, Figure 2.2, and
Figure 2.3 in two-dimension and three-dimension. The impact of z-coordinate in the 3D
spatial indexing will influence the execution time due to the indexing mechanism will
search each of the (x, y) elements that relates to its z-coordinate. For example, 7 (x, y, z)
points will search 7 times greater than 7 (x, y) elements. Note that the Oracle Spatial
R-Tree indexing provides the spatial index up to 4D, and the dimensionality should be
defined in the syntax.
Figure 2.2: A planar representation of an R-tree
Figure 2.3: A 3D representation of an R-tree
Another complex spatial query developed by PostgreSQL (2007) in order to be
• GiST (Generalized Search Trees) indexes break up data into “things to one side”, “things which overlap”, “things which are inside” and can be used on a wide
range of data-types, including GIS data. PostGIS (2006) uses an R-Tree index
implemented on top of GiST to index GIS data.
GiST indexes have two advantages over R-Tree indexes in PostGIS. Firstly,
GiST indexes allow null value in the index columns. Secondly, GiST indexes could
easily deal with GIS objects larger than the PostGIS 8K page size. The important part of
an object in an index will only be considered within DBMS, e.g. in the case of GIS
objects, just the bounding box. GIS objects larger than 8K will cause R-Tree indexes to
fail in the process of being built. It could take a long time to create a GiST index if there
is a significant huge amount of data in a table. However, The GiST index is widely used
for 2D data. The implementation of GiST is rather limited for 3D data. The research and
application on 3D GiST is expected in near future.
Other DBMS, e.g. Oracle Spatial, are able to provid e 3D indexing for 3D object
(MULTIPOLYGON). For Spatial, the metadata that maintains the lower and upper
bounds and tolerance of 3D object needs to be created. Later, a spatial index (R-tree in
3D) could be created on the tables to speed up spatial queries. The following example
denotes the sample in creating a 3D spatial index within Oracle Spatial.
-- Inserting metadata for 3D object: MUTIPOLYGON
INSERT INTO user_sdo_geom_metadata VALUES
('Solid3D', 'shape', mdsys.sdo_dim_array(
mdsys.sdo_dim_element('X', 0, 100, 0.1),
mdsys.sdo_dim_element('Y', 0, 100, 0.1),
mdsys.sdo_dim_element('Z', 0, 100, 0.1)
CREATE INDEX Solid3D_I on Solid3D(shape)
INDEXTYPE IS mdsys.spatial_index
PARAMETERS(’sdo_indx_dims=3’); -- Dimension = 3
ANALYZE TABLE SOlid3D COMPUTE STATISTICS;
2.4 Spatial Data Model
Tsichritzis and Lochovsky (1977) define a data model as a set of guidelines for
the representation of the logical organization of the data in a database consisting of
named logical units of data and the relationships between them. While the concept of the
data model is used in a variety of ways by numerous disciplines, a digital geographic
data model is generally defined as an information structure, which allows the user to
store specific phenomena as distinct representations, and enables the user to manipulate
the phenomena when held in the system as data (Raper and Maguire, 1992).
The data model represents a set of guidelines to convert the real world (called
entity) to the digitally and logically represented spatial objects consisting of the
attributes and geometry. The attributes are managed by thematic or semantic structure
while the geometry is represented by geometric-topological structure (Shunji 1999). The
ability to take the geographic location of objects into account during search, retrieval,
manipulation and analysis lies at the core of a GIS data model (Smith et al. 1987). How
well these tasks can be accomplished is determined by the spatial data model, apart from
other factors such as the data structures and database management systems selected for
the DBMS (Berry 1993). The theory of spatial data models currently attracts the most
active research and development with in the GIS community (Clarke 1986, Van Roessel
section discusses two types of data models, which they were reflected to this study, in
term of geometry and topology data types.
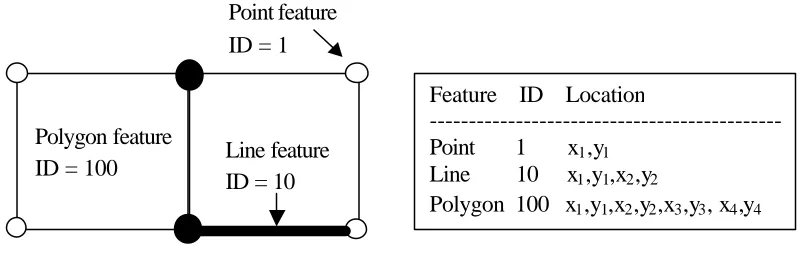
2.4.1 Spaghetti Model
Among many of the commonly used vector based data structure, the spaghetti
data model has the most simple data structure (Aronoff 1989). In the spaghetti data
model each entity on a map becomes one logical record in the digital file, and is defined
as a string of x, y coordinates. It indicates no explicit structure and it is used if the
geometry of spatial features in spatial DBMS is described completely independent and
irrespective of other features in the database (Ingvarsson, 2005). Although all entities are
spatially defined, no spatial relationships are encoded. This represents a significant
deficiency since, to perform any type of spatial analysis, the spatial relationship between
such entities must be derived through computation. Relationships like adjacency, within,
outside etc., between separate geometries are therefore calculated on demand. But the
spaghetti data model can efficiently reproduce maps digitally because information
unconnected to the plotting process is not stored (Peuquet 1984).
This model is also referred to raw data. The main characteristics of such data are
possible overlapping geometries and dangling lines. This is evident when representing
land parcels as spaghetti polygons, whereas each boundary has to be stored twice, and
the same corner mo nument stored at least three times, in different polygons (Ingvarsson,
2005). This creates problem of tracking boundary measurements. Also if geometric data
The properties of spaghetti data model are given as follows:
• Point is enclosed as single XY co-ordinate pair;
• Line is encoded as a string of XY co-ordinate pairs;
• Polygon is encoded as a closed loop of XY co-ordinates that define its boundary. The common boundary between adjacent polygons must be recorded twice, once
for each polygon;
• The Spaghetti model is a file of spatial data constructed in this manner is essentially a collection of co-ordinate strings with no inherent structure, and
hence the term spaghetti model is named; and
• Although all the spatial features are recorded, the spatial relationships between these features are not encoded.
Figure 2.4: Spaghetti data model Line feature
ID = 10 Polygon feature
ID = 100
Point feature ID = 1
Feature ID Location
---Point 1 x1,y1
Line 10 x1,y1,x2,y2
2.4.2 Topological Model
In this section, the discussion is focused on a model, which involves properties of
the database that are topological in nature. In this data model, concepts such as
adjacency, connectivity, and containment are important. Queries like “what is next to
polygon A?” or “List all the lines that constructs the polygon C” are typical in this
respect. Characteristic of topological properties is that they do not distinguish between
two databases that can be obtained from each other by a topological deformation. Such
data model is called topologically equivalent.
In applications in which only topological properties are under consideration, it
may be desirable to be able to work with a representation of the database, which is
topologically invariant, meaning that two topologically equivalent databases will be
represented identically. The idea of topological property in 2D spatial databases is
consisting of points in the plane R2, lines between these points, and areas formed by
these lines. This model is commonly referred to as the topological data model (Güting,
1994a; Güting, 1994b; Guting, 1989; Guting, and Schneider, 1993; Thompson and
Laurini, 1992). An example application is a subway or railway map in which only
relative positions of spatial objects such as stations and tracks are depicted without, for
instance, taking the actual length of the trajectory into account.
The Census Bureau of the United States introduced this data model in 1979
(Corbett, 1979) to model topological information on what they called zero-cells (points),
one-cells (lines) and two-cells (areas) (Thompson and Laurini, 1992). The information in
• R1: every one-cell has two zero-cells (indicating that every line has exactly two
endpoints);
• R2: every one-cell has two two-cells (indicating that every line is the border
between exactly two areas);
• R3: every two-cell is surrounded by a (ordered) cycle of one-cells and zero-cells
(indicating the border of an area);
• R4: every zero-cell is surrounded by a (ordered) cycle of one -cells and two-cells
(indicating the neighborhood of a point).
For relation R3 a clockwise order is agreed upon for outer borders of areas and a
counter-clockwise order is used for holes in areas. For relation R4 a clockwise order is
used. To settle the planarity of the model there is the additional condition that all
intersections of one -cells are zero-cells and all intersections of two-cells are one-cells
(see Figure 2.5).
R1 R2 R3 R4
A p q A a ß a p A 1 p A a 1
A q p A ß a a q B 2 p C d 2
B q r B a ? a r C 3 p D ß 3
B r q B ? a ß p D 1 q B a 1
C r p C a d ß s E 2 q A ß 2
C p r C d a ß t F 3 q F ? 3
Figure 2.5: The relations R1, R2, R3 and R4 (Paredaens, and Kuijpers, 1998)
2.5 The Existing Geo-DBMS
Existing DBMS provides a SQL schema and functions that facilitate the storage,
retrieval, update, and query of collections of spatial features. Most of the existing spatial
database support the object-oriented model for representing geomeries. The benefits of
this model is that it support for many geometry types, including arcs, circles, and
different kinds of compound objects. Therefore, geometries could be modeled in a single
row and single column. The model also able to create and maintain indexes, and later on,
perform spatial queries efficiently.
Conventional DBMS offer spatial data types and spatial functions fully in
two-dimension. Storing spatial data and performing spatial analysis can be completed with
SQL queries. The spatial data types and spatial operations reflect only simple
two-A
B C I
H
G
F E s
D
a
ß
?
d
pq
t r
features. With this spatial extend, DBMS have immediately been challenged by the third
dimension. The volumetric 3D data type (e.g. polyhedron, and tetrahedron) is expected
to be available in the coming Oracle 11g. However, certain DBMSs provide the support
of creating new data type using native programming. For instances, Oracle and
PostgreSQL support Java and C++ native programming. Consequently, function for
validation and 3D operators remains self-responsible by the users. The conclusions,
some DBMSs offer 2D data types (basically point, line, and polygon) but support 3D/4D
coordinates and offer a large number of functions more or less compliant with the Open
Geospatial Consortium (OGC) standards. Most of the functions are only 2D
dimensional. Several geo-DBMS, e.g. MySQL, and PostGIS, however, supports very
limited 3D operations, but only limited to certain regular 3D volumetric object, i.e. 3D
box. In the next section, some commercial spatial database will be discussed, in term of
their characteristics, capabilities and limitations in handling multi-dimensional datasets.
The last section will provide reasons in order to decide which geo-DBMS was selected
to be implemented into this study. The criteria to select one DBMS as testbed was
considered in many aspects as follows:
1. Commercial aspect – As this research was aim to produce critical
development that manage to fill the gaps of spatial DBMS in the context of
3D, the chosen DBMS should be able to provide an useful module for
educational purposes. One of the important issues is that the open-source
issue was the primary target for this research. The distribution terms of
open-source tools / software must comply with free redistribution. The license
shall not restrict any party from selling or giving away the software as a
component of an aggregate software distribution containing programs from
several different sources. Besides, it shall not require a royalty or other fee
for such sale. Other than licensing aspect, the program must include source
code, and must allow distribution in source code as well as compiled form. If
some form of a product is not distributed with source code, there must be a
well-publicized means of obtaining the source code for no more than a
without charge. The source code must be the preferred form in which a user
would modify the program. The benefit of using the open-source module is
that it allows modifications and derived works, and allows them to be
distributed under the same terms as the license of the original software.
2. OGC compliant aspect – Standardization in GIS is very important for the
interoperability. The purpose of the OGC compliance module to be chosen is
to permit any user to take advantage of the standards that OGC has created.
This important aspect should be able to provide a research direction that
follows the OGC’s abstract and implementation specifications. The key to all
of this is “interoperability”, that is the ability for different kinds of software
to successfully interact with one another. An applicable example is to build a
GeoSpatial web, similar in scope to the World Wide Web, where anyone just
needs a Web Server, such as Apache or IIS, and then others can start
interacting with their information. The advantage over high interoperability is
that data exchange effort become less and ensure same data format could be
accessed easily to any user. One of the best things the OGC has done is
define a standard specification for data type and spatial operations. And
beyond that OGC have made every effort to be as easy as possible to set up a
standards compliant module, with no additional configuration needed to meet
the open standards for GIS development.
3. Native programming support – Several DBMSs were designed for
non-spatial data only. Until very recent development of geonon-spatial modelling,
DBMS has been linked with spatial data, where a specific column is meant
for managing the geographic object. Taking the advantages storing data
logically in the form of tablespaces and physically in the form of data files,
spatial data can be managed securely due to the available tool for checking
types and functions within DBMS environment. By extending the
geo-DBMS with custom data type and functions, this study could design the new
data type and spatial operations according to the proposed structure that
follows the standard specifications given by OGC. Some example of native
programming support are C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC,
etc.
4. Portability aspect - For the general usability purposes, portability gives an
important mean of software installation with as low requirement as it can,
and easy-to-use. It is also the ability to install to other platforms, i.e. different
operating systems, with less data size consumed.
2.5.1 Oracle Spatial
Oracle Spatial technology was first introduced in Oracle 7.2 under the name
Oracle MultiDimension (MD). Later, the product name was changed to Oracle Spatial
Data Option (or SDO) and to Spatial Data Cartridge in Oracle 8. Since objects were not
supported in these releases, the coordinates of a geometry were stored as multiple rows
in an associated table. Managing spatial (geometry) data in these prior versions was
inefficient and cumbersome.
Starting with Oracle 8i, the SDO_GEOMETRY data type was introduced to store
spatial data. Even in Oracle 10g, the same SDO_GEOMETRY model is used to store
spatial data in Oracle. In Oracle 9i (and Oracle 10g), the geometry data also included
SDO_GEOMETRY data type. In Oracle 10g, additional functionality (that exists in the
Advanced Spatial Engine) such as the Network Data Model is introduced in the Spatial
option of Oracle. Since the prior versions are named MultiDimension (MD) and Spatial
Data Option (SDO), users will see the prefixes MD and SDO for the files and schemas
that install Spatial technology. The name of the spatial install schema is MDSYS in all
versions of Oracle.
Oracle Spatial technology is automatically installed with the Standard or
Enterprise Edition of an Oracle database server, since Oracle Database 10g. Oracle
Spatial supports the relational model for representing geometries. The
object-relational model uses a table with a single column of SDO_GEOMETRY and a single
row per geometry instance. It supports the data storage of three-dimensional and
four-dimensional geometric types, where three or four coordinates are used to define each
vertex of the object being defined. The SDO_GEOMETRY data type captures the
location and shape information of data rows in a table. This data type is internally
represented as an Oracle object data type. It can model different shapes such as points,
lines, polygons, and appropriate combinations of each of these. In short, it can model
spatial data occurring in most spatial applications and is conformant with the OpenGIS
Consortium (OGC) Geometry model. The Oracle Spatial data model is a hierarchical
structure consisting of elements, geometries, and layers. Layers are composed of
geometries, which in turn are made up of elements.
An element is the basic building block of a geometry. The supported spatial
element types are points, line strings, and polygons. Each coordinate in an element is
stored as an X,Y pair, and it can be stored up to four-dimension. However, spatial
functions can work with only the first two dimensions, and all spatial operators are
• Point data consists of one coordinate.
• Line data consists of two coordinates representing a line segment of the element.
• Polygon data consists of coordinate pair values, one vertex pair for each line segment of the polygon. Coordinates are defined in order around the polygon
(counterclockwise for an exterior polygon ring, clockwise for an interior polygon
ring).
A geometry (or geometry object) is the representation of a spatial feature,
modeled as an ordered set of primitive elements. A geometry can consist of a single
element, which is an instance of one of the supported primitive types, or a homogeneous
or heterogeneous collection of elements. A multipolygon, such as one used to represent a
set of islands, is a homogeneous collection. A heterogeneous collection is one in which
the elements are of different types, for example, a point and a polygon. With the
approach of homogeneous collection of elements, the coming Oracle 11g is expected to
provide 3D primitive, i.e. Polyhedron. However, the 3D spatial function remains
uncertainty.
A layer is a collection of geometries having the same attribute set. For example,
one layer in a GIS might include topographical features, while another describes
population density, and a third describes the network of roads and bridges in the area
(lines and points). Each layer's geometries and associated spatial index are stored in the
database in standard tables.
In the installation, Oracle Spatial requires user to verify system requirements. For
Oracle 10g, the minimum RAM required is 1024MB, and the minimum required swap
space is 1GB. Swap space should be twice the amount of RAM for systems with 2GB of
RAM or less and between one and two time s the amount of RAM for systems with more
than 2GB. Besides, users also need 2.5GB of available disk space for the Oracle
needs at least 400MB of free space. Although the development of current computer
technology able to fulfill such requirements, for educational and research purposes, the
research development must be synchronized with the latest computer technology if more
research applications intended to be extended. Thus, the portability of using Oracle
Spatial is considered low, as more expenses would be used on setting up a moderate type
of database server.
As the Oracle Database is developed for high commercial applications, the
Oracle Spatial is not an open-source module. Some of the commercial offerings like
Oracle Spatial are not cost-sensible. This is because in order to use Oracle Spatial you
need to buy Oracle Enterprise. Plus if you are going to use it for Web Applications then
you will have to pay the per CPU license instead of the per user license. Therefore, the
educational aspect for Oracle Spatial is rather low compared to other open-source
module like PostgreSQL.
The native programming supported by Oracle Spatial are PL/SQL, C/C++, Java,
and ect. These supports are the most appropriate way to create user-defined data types
and functions within geo-DBMS environment.
2.5.2 PostGIS
Refractions Research Inc. develops PostGIS (first released in 2001) as a spatial
advanced topological constructs (coverages, surfaces, networks), desktop user interface
tools for viewing and editing GIS data, and web-based access tools.
In terms of spatial databases, PostGIS is the most capable open source spatial
database extender for the PostgreSQL Database Management System. Built as an object
extension to PostgreSQL, PostGIS has been certified as “Simple Features for SQL”
compliant by the Open Geospatial Consortium.
Although OGC standard only support 2D geometries, PostGIS extended formats
are currently superset of OGC one (every valid WKB/WKT is a valid EWKB/EWKT).
PostGIS EWKB/EWKT add 3DM, 3DZ, 4D coordinates support and embedded SRID
information. Examples of the text representations (EWKT) of the extended spatial
objects of the features are as follows (PostGIS, 2007):
• POINT(0 0 0) -- XYZ
• SRID=32632;POINT(0 0) -- XY with SRID
• POINTM(0 0 0) -- XYM
• POINT(0 0 0 0) -- XYZM
• SRID=4326;MULTIPOINTM(0 0 0,1 2 1) -- XYM with SRID
• MULTILINESTRING((0 0 0,1 1 0,1 2 1),(2 3 1,3 2 1,5 4 1))
• POLYGON((0 0 0,4 0 0,4 4 0,0 4 0,0 0 0),(1 1 0,2 1 0,2 2 0,1 2 0,1 1 0))
• MULTIPOLYGON(((0 0 0,4 0 0,4 4 0,0 4 0,0 0 0),(1 1 0,2 1 0,2 2 0,1 2 0,1 1 0)),((-1 -1 0,-1 -2 0,-2 -2 0,-2 -1 0,-1 -1 0)))
• GEOMETRYCOLLECTIONM(POINTM(2 3 9),LINESTRINGM((2 3 4,3 4 5)))
PostGIS also implements the extended of simple features for SQL specifications
by defining a number of circularly interpolated curves. It includes 3DM, 3DZ and 4D
linear object, e.g. polygon). The well-known text extensions are not yet fully supported.
Besides, PostGIS cannot support the use of Compound Curves in a Curve Polygon.
Examples of some simple curved geometries are shown below (PostGIS, 2007):
• CIRCULARSTRING(0 0, 1 1, 1 0)
• COMPOUNDCURVE((0 0, 1 1, 1 0),(1 0, 0 1)
• CURVEPOLYGON(CIRCULARSTRING(0 0, 4 0, 4 4, 0 4, 0 0),(1 1, 3 3, 3 1, 1 1)) • MULTICURVE((0 0, 5 5),CIRCULARSTRING(4 0, 4 4, 8 4))
• MULTISURFACE(CURVEPOLYGON(CIRCULARSTRING(0 0, 4 0, 4 4, 0 4, 0 0),(1 1, 3 3, 3 1, 1 1)),((10 10, 14 12, 11 10, 10 10),(11 11, 11.5 11, 11 11.5, 11 11)))
Same as other spatial databases such as Oracle Spatial, it is used for
high-performance multi-user access to large seamless data sets. In a nutshell it adds spatial
functions such as distance, area, and specialty geometry data types to the database.
PostGIS is very similar in functionality to ESRI ArcSDE, Oracle Spatial, and DB II
spatial extender. The latest release version, it comes packaged with the PostgreSQL
DBMS installs as an optional add-on. This spatial DBMS works in windows
environment although most of the implementation applies to other supported platforms
such as Linux, Unix, BSD, Mac, and etc.
The PostGIS module is an extension to the PostgreSQL backend server. As such,
PostGIS 1.3.2 or above requires full PostgreSQL server headers access in order to
compile. PostGIS 1.3.2 can be built against PostgreSQL versions 7.2.0 or higher. The
installation does not require complex setting. The minimum memory of physical RAM is
256 MB, 2 GB of hard drive space, and minimum of 250-MHz processor are required. It
was easy to start and stop the server (same for client side), and user could do this
Within the PostgreSQL environment, it allows user-defined functions to be
specified in a number of languages, including its own procedural version of SQL called
PL/PGSQL, and C/C++, Java.
When compared with commercial spatial databases, PostGIS has most of the
core functions users will see in the commercial databases such as Oracle Spatial, has
comparable speed, fewer deployment headaches, but lacks some of the advanced
add-ons modules, such as Oracle Spatial network topology model, Raster Support and
Geodetic support. Often, the advanced spatial features are add-ons, on top of the
standard price of the database software. In certain application that requires wide-ranging
of database functions, Oracle Enterprise version with its myriad of features maybe able
to fulfill the requirements of a project better than PostgreSQL/PostGIS. However, as far
as spatial databases are concerned PostGIS does make economic sense more than Oracle
Spatial.
2.5.3 MySQL
MySQL (2007) is one of open source SQL database management system is
developed, distributed, and supported by MySQL AB. MySQL AB is a commercial
company, founded by the MySQL developers. It is a second -generation open source
company that unites open source values and methodology with business model. MySQL
is a relational database management system. MySQL implements spatial extensions
following the specification of the Open Geospatial Consortium (OGC). MySQL
implements a subset of the SQL with Geometry Types environment proposed by OGC.
This term refers to an SQL environment that has been extended with a set of geometry
type. The specification describe a set of SQL geometry types, as well as functions on
those types to create and analyze geometry values.
MySQL has data types that correspond to OGC classes. Some of these types hold
single geometry values:
• GEOMETRY
• POINT
• LINESTRING
• POLYGON
GEOMETRY can store geometry values of any type. The other single-value
types (POINT, LINESTRING, and POLYGON) restrict their values to a particular
geometry type. The other data types hold collections of values:
• MULTIPOINT
• MULTILINESTRING
• MULTIPOLYGON
• GEOMETRYCOLLECTION
GEOMETRYCOLLECTION can store a collection of objects of any type. The
other collection types (MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, and
GEOMETRYCOLLECTION) restrict collection members to those having a particular
Similar to PostGIS, MySQL enable spatial object being created using WKT , and WKB functions, which are defined in the OGC standard. Besides, MySQL also provides
MySQL-specific functions in create spatial object.
MySQL requires average time from software download to installation
completion. It remains true whether the platform is Microsoft Windows, Linux,
Macintosh, or UNIX. The self-management features like automatic space expansion,
auto-restart, and dynamic configuration changes are ready once installed. The portability
level is more or less similar to PostGIS. Recommended hardware requirements for
MySQL installation are Pentium V processor and 128 MB RAM. Note that MySQL can
be installed on a platform with as little as 32 MB. However, for better performance it is
recommended to have at least 128MB memory.
Although MySQL is part of LAMP (Linux, Apache, MySQL, PHP / Perl /
Python) environment, it only supports user-defined functions if written in C, and a
privileged account is then needed to link the compiled version with the MySQL
executable. The native programming language support aspect is rather low, compared to
Oracle and PostgreSQL.
2.5.4 Some Reasons Why the PostgreSQL Was Chosen
In this study, PostgreSQL was chosen as a DBMS testbed to perform 3D spatial
operations. The reasons to support the chosen DBMS are based on four factors as