Abstract— The discourse segmentation problem in Arabic language has not been fully addressed. A technique to segment Arabic discourse into complete sentences is presented. The technique is derived from Arabic Rhetorical system by exploiting the main crucial connector "و", as defined by Arabic linguists almost one thousand years ago. This approach categorizes the six known rhetorical types of "و" into two classes: segment and unsegment, known as, "Fasl" and "Wasl". S egmentation places are decided according to the type of connector "و". A set of twenty two syntactic and semantic features devised from "Fasl and Wasl" rhetorical methods, are chosen to categorize each type of "و". The system undergoes the learning and testing stages, using S VM machine learning technique to identify the types of the connector "و". An Arabic discourse corpus is particularly developed for this experiment. We achieved results with an accuracy of 97.95% of discourse segmentation.
Index Term— Arabic rhetoric methods "Fasl and Wasl", discourse segmentation, , machine learning, Rhetorical S tructure Theory (RS T), S upport Vector Machine (S VM).
I. INT RODUCT ION
A sentence is the part of a speech or a written discourse that has a complete and independent meaning. Sentence segmentation refers to indentifying sentences in an unstructured text. The process of sentence segmentation is a basic step for discourse analysis processing systems. It is because, any text stream needs to be separated into coherent sentences in order to enable effective automatic analysis, such as information retrieval, summarization, understanding and translation. It is very important to first define what is meant by a complete and independent sentence. Some researchers have defined sentence, as a finite clause that has a complete and independent meaning [13]. The Cambridge Encyclopedia of Language defines a sentence as the largest unit to which syntactic rules apply [8]. All computational linguistic systems
Manuscript received January 24, 2011. Arabic Discourse
Segmentation Based on Rhetorical Methods.
Iraky Khalifa is with the Computer Science Department, Helwan University, Helwan, Egypt . (e-mail: [email protected]).
Zakareya Al Feky is with the Arabic Language Department, University of Alexandrai, Alexandria, Egypt (e-mail: [email protected]). Abdelfatah Farawila is with the Computer Science Department, Helwan University, Egypt. (phone: +966-507810636; e-mail: a_farawila@ yahoo.com), (Corresponding author).
that encode and analyze discourse texts, such as Rhetorical Structure Theory (RST), need to answer the following question: How to segment a discourse? This question has been answered, to a certain extent; for some languages such as in English, French, Chinese, Polish, Spanish, etc.[22], but a little work in Arabic has been done. This is due to the distinct and unique characteristics of Arabic language. In present study, we introduce a new method of segmenting an Arabic discourse into its sentence units. However, Arabic sentence segmentation processing is deemed hard due to two main difficulties: the lack of an Arabic corpus dedicated for sentence segmentation, and the very special nature of Arabic language. An Arabic Corpus is developed, particularly for the training and testing the segmentation experiments in this study. The proposed segmentation method is syntactic/semantic based, and it comprises two ideas: the Arabic rhetorical methods ; "Fasl and Wasl"; of discourse segmentation as defined by Arab linguists, and the supervised machine learning with Support Vector Machine (SVM).
It is realized that the connector "ٔ /and/Waw" is the most ambiguous connector due to its mostly rhetorical use [4]. In the Arabic rhetoric system, the meaning of " ٔ" plays a great role of understanding consecutive sentences , and in turn determines the places of sentence endings [1]. Historically, this problem was addressed long time ago, by a prominent Arabic linguist, "Abdel Quaher Al-Jorjany (يَبجسجنا سْبقنادجػ(, died in 471 Higri". In his book "Dalael Al Eegaaz شبجػلإا مئلاد", he defines an approach, called "Fasl and Wasl", which means, "identifying segmentation places in a text" [17]. This approach, identifies sentence ending places by understanding the meaning of the connector "ٔ" rather than other sentence connectors such as: "خنا ... ىث , ـف", because their functions as a sentence separator are evidently known [1].In this paper, we use "ٔ" and "Waw" interchangeably to denote the connector "ٔ", and similarly, we use "Fasl" and "Segment", and "Wasl" and "Unsegment" respectively. According to "Fasl and Wasl" rules; there are six different meanings of "ٔ", three of these signal to a segmenting place; i.e., "Fasl"; whereas the other three types are used when the context implies connecting the text before and after it, i.e., "Wasl' or Unsegment. Table I describes these six types of "ٔ", and their segmentation effects. The proposed method consists of two phases: 1) training; which characterizes the feature of each "ٔ", and 2) testing. Support Vector Machine (SVM) is used during both, training and testing phases. The significance of the proposed approach is that it is built on the well established Arabic rhetoric segmentation rules , "Fasl and Wasl مصٕنأ مصفنا" [17].
Arabic Discourse Segmentation Based on
Rhetorical Methods
112701-8989 IJECS-IJENS © February 2011 IJENS This paper is organized into seven sections. Section II
describes the rules of sentence segmentation in Arabic rhetoric system. Section III surveys some related work. Section IV presents a brief account of the development of the proposed Arabic Corpus. Section V explains the proposed Arabic text segmentation technique. Section VI gives experimental results along with some discussions. Final section of this paper concludes it. Because the paper contains some Arabic words and terms, which may cause some difficulties for non Arabic speakers, an Appendix is added at the end of this paper to translate Arabic terms mentioned in this paper into English.
II. TYPES OF T HE CONNECT OR "ٔ" IN "FASL AND WASL"
ARABIC RHET ORICS
The law of "Fasl and Wasl"; as defined by "Abdel Quaher Aljorjany يَبجسجنا سْبقنادجػ", is shown below in Fig. 1. It is interpreted, thereafter by the Arabic linguists when they related the segmentation places of "Fasl and Wasl" to the meaning of the "ٔ". There are six types of connector, "ٔ" in terms of meaning [2]. They are clustered into two classes: "Fasl" or "Wasl". The class "Fasl" contains three types of, "ٔ": 1) Waw1:"ىعقنأ", 2) Waw2:"ةزٔ", and 3)Waw3:"فبُئزظلاأ". The second class, "Wasl", contains the rest three types of, "ٔ": 4)Waw4:"لبحنأ", 5)Waw5:"خيؼًنأ", and 6)Waw6: "فطؼنأ" [2]. These six types of connector, " ٔ", their names, meanings, and the class which each type belongs to, are shown in Table I.
The following six examples show each type of " ٔ", with its significant meaning, when used to connect two sentences.
A. Waw1"ىعقنأ":
حرربظلأا فنأ ىهؼنا رييلازنا ًٌٕهؼي اللهٔ خهيع
ٌٕيدقين ىَٓإ .خيلأن ًبًيظػ ًلاًػ
(1)
[Professors teach students sciences and virtue, I swear to God, they have done a great mission for their nation]
In text (1), the "ٔ" along with "الله" give the meaning of testimony.
B. Waw 2 "ةزٔ":
ٕعين ةبجشنا ةزٔ ّهك غًزجًنا دبيشأ ٍي ءصج ىٓربيشأ ٌإ مث ٌَٕبؼي ٍيرنا ىْدحٔ ا
؟غًزجًنا دبقجغ ٍيث ٍي "ةبجشنا" ٗهػ ىرصكز اذبًن :لٕقي مئبظ (2)
[Young people are not the only ones who suffer, but their crises are part of the crises of the whole society and someone may ask: Why have focused only on youth only and not on the divisions of the whole society?]
In text (2), the "ٔ" along with " ةز" give the meaning: few or someone.
C. Waw 3"فبُئزظلاأ":
غًزجًنا ٔ خيعفُنا دلاكشًنا طؼث ٍي ٌٕقْاسًنا يَبؼي ٖسخأ دبيجهظ ّث خيبػ
سيثك ح. (3) [Adolescents suffer from some psychological problems and there are, in general, other numerous problems in the society.]
In text (3), the "ٔ" does not indicate any specific meaning, rather than joining two unrelated sentences. In the above three examples, the, "ٔ", refers to segmentation places according to Arabic rhetoric methods. These three types are contained in the class "Fasl".
In the other hand, the following three examples, show the other three types of "ٔ" which are contained in the "Wasl" class. They have unsegmenting effect because the meanings before and after the, "ٔ", are related.
D. Waw 4 "لبحنأ":
مخد ضزدًنا ىعزجي ْٕٔ مصفنا .
(4)
[The teacher came smiley into the classroom]
In (4), the "ٔ" indicates that its sentence "smiley into the classroom" acts as an adverb of state for the previous sentence "The teacher came".
E. Waw 5 "خيؼًنأ":
ٌبجيجحنا طهج سًقنا ءٕظٔ
. (5)
[The couple sat together with the light of the moon]
In text (5), the "ٔ" indicates that its following sentence acts as an object of accompaniment for the previous one.
F. Waw 6 "فطؼنا ٔ":
ىظزَأ خظازدنا دأدث ٔ ًٌٕهؼًنا
دًنا يف ةلاطنا ا
ضز . (6)
[The study started and students and teachers enrolled in schools]
In (6), the "ٔ" is a conjunction of related words or sentences.
TABLEI
T YPESOF T HECONNECT OR"ٔ"
No. Type of
"ٔ" M eaning of "ٔ"
Class: Fasl / Wasl
1 ىعقنا Swear by God or testimony Fasl
2 ة ز Few or little Fasl
3
فبُئزظلاا
It signals to adhere a sentence to its preceding one if the two sentences are not related in their meanings.
Fasl
4 لبحنا Adverb of state Wasl
5 خيؼًنا Object of accompaniment Wasl
6 فطؼنا Conjunction of two sentences Wasl
:ةسظأ خثلاث بٓن خهًجنا 1 - لبح بٓهجق ٗزنا غي بٓنبح خهًج خفصنا
غي ّجشن خزجنا فطؼنا بٓيف ٌٕكي لاف دكؤًنا غي ديكأزنبث ٔ فٕصًٕنا
بٓيف فطؼنا - ذفطػ ٕن - .ّعفَ ٗهػ ئشنا فطؼث
2 - مثي ُٗؼي ٗف ّؼي مخدي ٔ ىكح ٗف ّكزبشي َّأ لاإ ّهجق ٖرنا سيغ ٌٕكي ىظلاا لبح بٓهجق ٗزنا غي بٓنبح خهًج
ف ّينإ بفبعي ٔأ لإؼفي ٔأ لاػبف ٍيًظلاا لاك ٌٕكي ٌأ .فطؼنا بٓقح ٌٕكي
3 - ٌٕكي لاف ئش ٗف ُّي ٌٕكي لا ىظلاا غي ىظلاا ميجظ بٓهجق ٗزنا غي بٓهيجظ مث ٍينبحنا ٍي ئش ٗف ذعين خهًج
سكرنا كسر ٔ ّهجق ٖرنا سكذ ٌٕكي ٔ ّث دسفُي سيأث لاإ سكري ىن سكذ ٌإ ئش ْٕ مث ُٗؼي ٗف ّن بكزبشي لا ٔ ِبيإ ُيث ٔ ُّيث قهؼزنا ودؼن ّنبح ٗف ءإظ .خزجنا فطؼنا كسر ارْ قح ٔ ًبظأز ّ
Sentences fall in three types :
1- A sentence describes its predecessor being as an adjective of a noun. So, a conjunction is never used as it can be used as a semi conjunction if we consider two sentences one describing the other as conjunction.
2- A sentence following its preceding sentence is like a noun different from its preceding noun but both share a position and a meaning like a situation where the two names are subjects, objects or attaché.
3- A sentence different from both cases above as its position with the preceding one is the same as a noun to a noun completely different, not being the same or sharing a meaning but it is something, if mentioned, it is mentioned uniquely. In this case mentioning or non mentioning of the previous sentence is the same as there is no relation whatsoever. This implies no conjunction at all as dropping conjunction is either for connection to reach the meaning or disconnection to reach the meaning, and conjunction is for means between the two cases and it has a situation between two situations.
We notices that this text contains the " ٔ" twice but we are concerned with the one which connects sentences not words.
III. RELAT ED WORK
The contemporary research on sentence segmentation is driven by approaches that depend on the purpose of text segmentation. Approaches include topic identification, reference table, statistics , syntax, and semantics. The most notable work to the present work, is reported in 2008 by Ameur A. Touir, et. Al. in [5]. They developed an empirical technique for Arabic sentence segmentation based on, the connecting words between sentences as these are usually used by Arabic writers in known literature. Their approach can be considered as semantic and cue phrase based approach. In [5], they introduced a new notion called active and passive connectors. Their technique depends on these active and passive connectors. Active connectors are words that indicate the beginning or the end of a sentence, or a complete sentence. Passive connectors do not indicate a new segment, an end of a segment, or a complete segment by themselves, rather they come with active connectors, which contribute in determining the position of the start or the end of the segments. The limitation of this technique comes from the fact that some active connectors might appear in other texts, as passive, and also because it is impractical to collect all possible active connectors. Furthermore, their technique is not based on the Arabic rhetoric methods [10], [15], and [16]. Some text segmentation methods are topic based, where each part of the text addresses a certain topic. In fact, this approach can segment a text into paragraphs rather than sentences. Work along these lines is carried out by Lamprier et al [11], using genetic algorithms, M. Magimai.-Doss et. al [14], using an entropy measure technique, etc.. Another approach is based on a reference table [3], as the potential segments that fit under the reference table attributes are identified, and then added to the table. Moreover, s tatistical approaches are extensively used in [6], [10], and [20]. In the work of Le Thanh et al. [12], the text is segmented into elementary discourse units , based on syntactic information and cue phrase. Cristea et al [7], utilized segmentation based on discourse structure for the purpose of text summarization. On the other hand, Palmer and Hearst [19], described a system using the syntactic context of a potential sentence boundary to classify the boundary. Other approaches used regular expressions , augmented with linguistic knowledge about abbreviations to detect boundaries [21].
IV. BUILDING AN ARABIC CORPUS FOR DISCOURSE
SENT ENCE SEGMENT AT ION
The need to develop an Arabic s entence segmentation method led us to recognize the importance of having a corpus to train the system and test its performance. There are some efforts in creating discourse corpora in different languages as the Penn Discourse Treebank (PDTB) for English, which is annotated for discourse connectives, the relations they convey, and their arguments. It has also been shown to be extensible to other languages such as Hindi, Turkish and
Chinese. Recently, a similar effort is done to Modern Standard Arabic by producing the Leeds Arabic Discourse Treebank (LADTB), but, unfortunately, it is not released for researchers yet [4]. For this reason, it was compulsory to develop an Arabic discourse corpus . This new corpus is restricted only for studying the connector "ٔ". To accomplish this job, some discourses are collected from Arabic newspapers and books . Some necessary preprocessing is performed. The corpus structure is a table like, that has two parts; a header part and an annotation part. The header part contains , the position and the type of each "ٔ" occasion, whereas the annotation part contains 22 columns of features . The preprocessing and extracting the features, for each type of, " ٔ", are explained with
more details in section V, subsection A
.
V. THE ARABIC SENT ENCE SEGMENT AT ION MET HOD
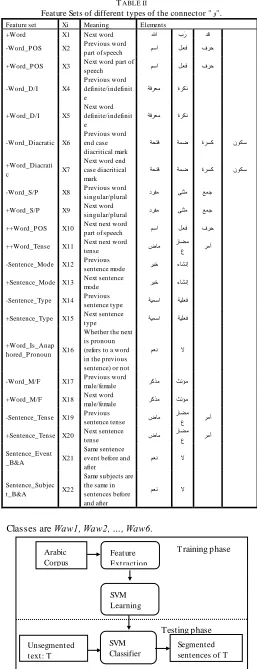
This proposed Arabic Sentence Segmentation Method is semantic based, depends on the role of the connector "ٔ", in Arabic language. According to the meaning of the "ٔ", the technique can decide on segmentation places in a text. There are six types of "ٔ"; classified into two classes, "Fasl" and "Wasl". Each class contains three types of "ٔ" as shown in Table I, according to Arabic rhetorical linguists [2]. Thus, the class "Fasl" is used as a sentence boundary detector on every occasion of it while the types of "ٔ", that constitutes class "Wasl", do not have a segmentation effect. During the learning stage, syntactic and semantic features for each occasion of " ٔ" are extracted manually. In testing phase, we use the supervised machine learning model. For that, we provided the Support Vector Machine (SVM) with the features of each "ٔ". Then, the learned SVM model is used in recognizing the type of "ٔ" which is, in turn, used as sentence boundary . Although the connector "ٔ", is not the only indicator of sentence boundaries, our method ignores other indicators, such as punctuation marks, cue phrases and other connectives as "ٔ" is the most common and most ambiguous connector. This system consists of three steps: 1)Preprocessing, 2)Feature extraction, and 3) Classification, as illustrated in Fig. 2.
A. Preprocessing
Step1: Diacretization:
In Arabic, the part of speech is determined by diacretization marks which are added at the end of each word. Often, writers neglect adding these marks , and let the reader guesses the proper diacretization during reading. Diacretization marks are compulsory for understanding Arabic. Hence, we added diacretization marks manually for both training and testing the texts during the preparation of the corpus .
112701-8989 IJECS-IJENS © February 2011 IJENS of word "دجٔ". During the second step, the confusion between
the connector "ٔ" and the letter "ٔ" is removed.
B. Feature Extraction:
During feature extraction stage, the syntactic and semantic features of each type of the connector "ٔ" are manually extracted. This analysis is built on Arabic rhetorical methods [2]. It is found that twenty two features are required to distinguish each type of the "ٔ". The feature sets named; X1, X2, …, X22; and the elements of each set are listed in Table II. In the following paragraphs, we discuss each feature for every possible occurrence of each type of the connector "ٔ".
B.1. Feature Extraction of the first type: Waw1 "ىعقنأ"
This type of "ٔ", comes before a word such as, "الله" , and it means "I swear by", as the next word; "الله"; is the object of oath or testimony. Normally, the object of oath is the word, "الله" or any equivalent word. There are two cases for Waw1. This type of "ٔ" is recognized by its successive word in the two cases as shown below:
Case 1:
- The successive word is the noun "الله", and
- The end case diacritical mark of the successive word is "genitive".
Therefore, we conclude the features as follows:
Features are: X1= "الله", and X7 = genitive mark Case 2:
- The successive word is a noun,
- The end case diacritical mark of the successive word is "genitive", and
- The successive word must not be a pronoun.
Then, features are: X3= noun, X7= genitive mark , and X16 = no
B.2. Feature Extraction of the second type: Waw2 " ةزٔ"
The structure of "ٔ", combined with the word " ة ز", means "few of or little". There are two cases for it, the first case occurs when the word, " ة ز" appears explicitly, and when the word " ة ز" is hidden and it is understood implicitly.
Case 1:
-The next word is the noun " ة ز", and
-The end case diacritical mark of the next word is accusative. Then, features are: X1 = " ة ز" and X7= accusative mark Case 2:
-The successive word is an unknown noun,
-The successive word diacritical mark end case is genitive, and
-The end case diacritical mark of the previous word is not genitive.
And features are:X3= noun, X5=indefinite, X6≠genitive mark
and X7= genitive mark
B.3 Feature Extraction of the third type: Waw3 " فبُئزظلاا ٔ"
This type has no meaning, rather than it joins two unrelated adhesive sentences. It can be recognized from the features of the two sentences before and after it. There are four structures of this type.
Case1:
- The two sentences before and after Waw3 have different kinds. In other words, if one of them is a statement sentence, the other is a subject sentence i.e. imperative, interrogative or a vocative sentence. The subject sentence in Arabic is called "Inshaeya خيئبشَإ خهًج". The feature is: X12 ≠ X13
Case2:
- Normally if the sentence types , before and after Waw3 are different, i.e., one sentence is nominal and the other is verbal. In this case, it is preferable to segment the two sentences. The feature is: X14 ≠ X15
Case3:
- Unless the two sentences are similar in their tenses, the segmentation of the two sentences is normally expected. The feature is: X19≠ X20
Case4:
- The two sentences before and after Waw3 have different verbs and different subjects. Therefore the features are: X21 = no and X22 = no
B.4. Feature Extraction of the fourth type Waw4 "لبحنأ"
This type of "ٔ", comes before an "adverb of state" sentence. It can be recognized from its successive word. It has two cases. In Arabic grammar the word that comes after Waw4 should have the following features:
Case1:
- The word after Waw4 is an anaphoric to a noun in the previous sentence. Hence, the feature is: X16 = yes
Case2:
-The word after Waw4 is , "دق", is followed by a verb in the past tense:
Then, features are: X1= "دق ", X10 = verb and X11 = past tense
B.5 Feature Extraction of the fifth type Waw5 "خيؼًنا ٔ":
This type is similar to "object of accompaniment" in English. It can be recognized by its successive word only. In Arabic grammar, the word that comes after "خيؼًنأ ", should be an accusative noun. The following are the features of "خيؼًنأ": X3 = noun and X7 = accusative mark
B.6. Feature Extraction of the sixth type Waw 6 "فطؼنا ٔ":
The function of,"فطؼنأ", or Waw6, is to join two related nouns, verbs, nominal sentences or two verbal sentences. It occurs in two cases as follows:
Case1:
-Conjunction of words, nouns or verbs.
Features are: X2 = X3, X6 = X7, and (X4 = X5 or X8 = X9 or X17 = X18)
Case2:
-Conjunction of sentences , nominal or verbal.
C. Support Vector Machine (SVM): Training and Classification
The experiments of our technique are implemented with Support Vector Machine, SVMm ulticlass version 2.20 developed by Thorsten Joachims [18]. We used 22 feature sets that represent the input of the SVM classifier and 6 classes that represent the output. Features are denoted: X1, X2, …, X22. Classes are Waw1, Waw2, …, Waw6.
VI. EXPERIMENT AND RESULT S
The Corpus of Arabic Discourse Sentence Segmentation, designed within this work, is incorporated in this experiment. We used 1200 instances for training, and 293 instances for testing. Class Waw5 "خيؼًنأ", did not appear neither in training, nor in testing because it is seldomly used in the Modern standard Arabic. Classes 1, 2 and 4 appeared in a few number of instances. It could be said that the experiment is actually done with only two classes , i.e., 3 and 6, which represent Waw3 "فبُئزظلاأ" and Waw6 "فطؼنأ" respectively. Table III summarizes the result of our experiment with precision recall measure.
As mentioned before, the three types of " ٔ", Waw1 "ىعقنأ", Waw2 "ةزٔ" and Waw3 "فبُئزظلاأ", act as a segmentation indicator whereas the other three types of " ٔ", Waw4 "لبحنا ٔ", Waw5 "خيؼًنأ" and Waw6 "فطؼنأ", do not act as segmentation indicator. Therefore, we can combine them in two classes only: Fasl and Wasl.
The results shown in TABLE III indicate clearly that, among the 293 instances of the connector " ٔ", there are 290 correct and 3 incorrect instances. One incorrect instance of Waw3 is predicted as Waw6, one incorrect instance of Waw6 is predicted as Waw3, and one incorrect instance of Waw2 is predicted as Waw4. Accordingly, the segmentation accuracy can be computed as:
True_Fasl = ∑ True instances of Wawi for i= 1 to 3 (1) True_Wasl = ∑ True instances of Wawj, for j= 4 to 6 (2) Segmentation Accuracy = True_Fasl + True_Wasl (3)
Total number of instances = (10+3+ 93) + (6+0+178) = 98.98 % 293
Although we only addressed the most tough part of the problem, the ambiguous connector "ٔ", our results is still better than that of the method that depends on identifying Active and Passive connectors [5] which is the only comparable work in Arabic text segmentation yet. Moreover, if we would have addressed other connectors su ch as punctuations and cue phrases as segmentation indicators as that have been done in [5] , we would have reached higher accuracy. Also we could get higher accuracy, if we enlarge the number of instance of the learning phase.
Comparing with the Active/Passive method, our method is able to segment the following sentence into two segments at the Training phase
Testing phase
Fig. 2 The Arabic sentence Segmentation System
Feature Extraction Arabic
Corpus
SVM Learning
SVM Classifier Unsegmented
text: T
Segmented sentences of T
TABLE III
Overall precision/recall measure of classifying the connector "ٔ"
Waw T yp e
No. of occurrences in testing
No. of occurrences in Prediction
Precision % Recall %
ىعقنا 10 10 100% 100%
ةز 4 3 100% 75%
بُئزظلاا ف
94 94 98.94% 98.94%
لبحنا 6 7 85.71% 100%
خيؼًنا 0 0 - -
فطؼنا 179 179 99.44% 99.44%
T otal = 293
T otal = 293 Avg.=96.82 %
Avg.=94.68 % TABLEII
Feature Sets of different types of the connector " ٔ".
Feature set Xi Meaning Elements
+Word X1 Next word الله ة ز دق
-Word_P OS X2 P revious word
part of speech ىظا مؼف فسح +Word_P OS X3 Next word part of
speech ىظا مؼف فسح
-Word_D/I X4
P revious word definite/indefinit e
سؼي خف حسكَ
+Word_D/I X5
Next word definite/indefinit e
سؼي خف حسكَ
-Word_Diacratic X6
P revious word end case diacritical mark
خحزف خًظ حسعك ٌٕكظ
+Word_Diacrati
c X7
Next word end case diacritical mark
خحزف خًظ حسعك ٌٕكظ
-Word_S/P X8 P revious word
singular/plural دسفي ُٗثي غًج +Word_S/P X9 Next word
singular/plural دسفي ُٗثي غًج ++Word_P OS X10 Next next word
part of speech ىظا مؼف فسح ++Word_Tense X11 Next next word
tense ضبي
زبعي ع سيأ -Sentence_Mode X12 P revious
sentence mode سجخ ءبشَإ +Sentence_Mode X13 Next sentence
mode سجخ ءبشَإ
-Sentence_Type X14 P revious
sentence type خيًظا خيهؼف +Sentence_Type X15 Next sentence
type خيًظا خيهؼف
+Word_Is_Anap hored_P ronoun X16
Whether the next is pronoun (refers to a word in the previous sentence) or not
ىؼَ لا
-Word_M/F X17 P revious word
male/female سكري ثَؤي +Word_M/F X18 Next word
male/female سكري ثَؤي -Sentence_Tense X19 P revious
sentence tense ضبي زبعي
ع سيأ +Sentence_Tense X20 Next sentence
tense ضبي
زبعي ع سيأ Sentence_Event
_B&A X21
Same sentence event before and after
ىؼَ لا
Sentence_Subjec t_B&A X22
Same subjects are the same in sentences before and after
112701-8989 IJECS-IJENS © February 2011 IJENS position of "ٔ", while the Active/Passive method can detect a
sentence boundary at this position because the word "وٕق " is ر not a one of the connective list.
-ري حبجصنا يف خظزدًنا ٗنإ ءبُثلأا تْ و
.ءارغنا وبؼغ دادػئث ولأا وٕقر
[Children go to school in the morning and the mother prepares the lunch].
It is impractical to count all passive connectors in Arabic language. Therefore, our proposed method surpasses the active passive method by considering only the connector "ٔ" , along with the proposed 22 features mentioned in TABLE II.
REFERENCES
[1] Abdulaziz Ateque, "Elm Al-Maany". Dar Al-Nahda Al-Arabeia for
Publishing. Egypt, 2009, Published in Arabic.
[2] P. Abduquader Hussien, "Athar Al-Nohat fi Al-Bahth Al-Balaghy",
Dar Nahdat Misr for Printing and Publishing, Egypt, 1984,
Published in Arabic
[3] Agichtein, E. and V. Ganti, "Mining reference tables for automatic
text segmentation". Proceedings of the ACM International
Conference on Knowledge Discovery and Data Mining (SIGKDD'04), Seattle, Washington, USA, ACM Press, 2004, pp 20-29.
[4] Amal Al-Saif, Katja Markert, "T he Leeds Arabic Discourse
T reebank: Annotating Discourse Connectives for Arabic". LREC 2010 Proceedings,2010.
[5] Ameur A. T ouir, Hassan Mathkour and Waleed Al-Sanea,
"Semantic-Based Segmentation of Arabic T exts". Information
Technology Journal, Asian Network for Scientific Information,
2008, (7):pp.1009-1015.
[6] Beeferman, D., A. Berger and J. D. Lafferty, "Statistical models for
text segmentation", Mach. Learning, 1999, 34:pp.177-210.
[7] Cristea, D., O. Postolache and L. Pistol, "Summarization T hrough
Discourse Structure". Comput. Linguistics and Intelligent Text
Processing, Lecture Notes in Computer Science, Springer, Berlin, Heidelberg, Germany, 2005, Vol. 3406, pp.632-644.
[8] David Crystal, "T he Cambridge Encyclopedia of Language".
Cambridge University Press, New York, 1987.
[9] Fredrik Jørgensen, ”Clause Boundary Detection in T ranscribed
Spoken Language", Joakim Nivre, Heiki-Jaan Kaalep, Kadri
Muischnek and Mare Koit (Eds.) NODALIDA 2007 Conference
Proceedings, 2007, pp.235-239.
[10]Golcher, F., "Statistical text segmentation with partial structure
analysis". Proceeding (KONVENS 2006), Konstanz, Denmark,
2006, pp.44-51.
[11]Lamprier, S., T . Amghar, B. Levrat and F. Saubion, "SegGen: A
genetic algorithm for linear text segmentation. Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, January 2007, pp.1647-1653.
[12]Le T hanh, H., G., Abeysinghe and C. Huyck, "Automated discourse
segmentation by syntactic information and cue phrases". Proceedings of AIA 2004, Innsbruck, Austria, 2004, pp.411-415.
[13]M T aboada, LH Zabala, "Deciding on Units of Analysis within
Centering T heory", Corpus Linguistics and Linguistic Theory,
2008, 4, pp.3-108.
[14]M. Magimai.-Doss1, D. Hakkani-T ¨ur1, O¨. C¸ etin1, E.
Shriberg1,2, J. Fung1, N. Mirghafori, "ENT ROPY BASED
CLASSIFIER COMBINAT ION FOR SENT ENCE
SEGMENT AT ION", IEEE, 2007.
[15]Marcu, D., "T he rhetorical parsing of unrest ricted texts: A surface-based approach". Comput. Linguistics, 2000, 26: pp. 395-448.
[16]Marcu, D., "T he T heory and Practice of Discourse Parsing and
Summarization". 1st Edn. The MIT Press, 2000, UK.
[17]Mostafa Hemeida, "Nedhum Ertebat wa Rabt fi T arkeeb
Al-Gomla Al-Arabeia". The Egyptian Int.Company for Pub.
(Longman), Egypt, 1997, Published in Arabic.
[18]Multiclass Support vector machine. Available: http://svmlight.
Joachims.org/svm_multiclass.html
[19]Palmer, D., and Hearst, M., "Adaptive Multilingual Sentence
Boundary Disambiguation", Computational Linguistics, 1997, 23
(2), pp.241-267.
[20]Utiyama, M. and H. Isahara, "A statistical model for
domain-independent text segmentation". Proceedings of the 39th Annual
Meeting of the Association for Comp. Linguistics and 10th
Conference of the European Chapter of the ACL2001, T oulouse,
France, 2001, pp. 91-498.
[21]Walker, D.J., Clements D.E., Darwin M. and Amtrup W.,
"Sentence Boundary Detection: A Comparison of Paradigms for
Improving MT Quality", In Proceedings of the 8th Machine
Translation Summit, Santiago de Compostela, Spain, 2001, pp.369-372.
[22]Yang, C.C. and K.W.LI, "A heuristic method based on a statistical approach for Chinese text segmentation", J. Am. Soc. Inform. Sci. Technol., 2005, 56:pp.1438-1447.
Appendix A: Arabic to English translation of Arabic terms used in this paper.
Arabic term
English translation
Arabic term
English translation
ىظا noun تئبغ سيًظ pronoun
فبُئزظلاا resume ـف next
لبحنا adverb of state خحزف accusative mark خنا
. etc. )Fasl(مصف segment
فطؼنا conjunction مؼف verb
ىعقنا swear دق perhaps
الله God حسعك genitive mark
خيؼًنا object of accompanimen t
لا no
سيأ imperative ضبي Past tense
ىث next ُٗثي double
غًج plural سكري male
خيًظا خهًج nominal sentence
عزبعي present tense
خيئبشَإ خهًج subject sentence
خفسؼي known
خيسجخ خهًج statement sentence
دسفي singular
خيهؼف خهًج verbal sentence
ثَؤي female
فسح preposition ىؼَ yes
ةز few حسكَ unknown
ٍيش tense )Waw(ٔ and
ٌٕكظ Jussive mark )Wasl(مصٔ unsegment خًظ nominative