3364
Efficient Deep Learning Hardware Accelerator
Using Past Adder
V Sridyuthi, Abhishek Choubey
Abstract: Convolution neural network (CNN) provides important image detection precision. A Deep Learning hardware accelerator is suggested to introduce image detection using CNN in machines. The suggested accelerator optimizes power effectiveness by avoiding unnecessary information movement. The accelerator can support arbitrary converting window size with distinctive filter decomposition method. Furthermore, the modified PASTA (Parallel Self Time Adder) design achieves logarithmic performance without any special speed- up circuitry or look-ahead scheme over random operand conditions, thereby improving the performance. The simulation result attains 13.610ns of delay and 8% of GCLK’s, 400 GOPS/W thereby, overhaul’s the speed.
Index Terms : CNN, hardware accelerator, DLHA, Speed-up, Parallel Self Time Adder.
—————————— ——————————
1.
INTRODUCTION
Machine Learning offers numerous creative applications in the IoT gadgets, for example, face acknowledgment, keen security and article identification [1]-[2]. Best in class AI calculation for the most part depends on the cloud servers. Profiting by the chart handling unit (GPU's) ground-breaking calculation capacity, the cloud can handle high-performance gadget audio data and use CNN to achieve exceptional accuracy in most AI apps [3]-[4]. This methodology has its own downsides in any event. Since the system availability is essential for cloud-based AI applications, those applications can't keep running in the regions where there is no system inclusion. What's more, information exchange through system initiates noteworthy inertness, which isn't satisfactory for ongoing AI applications, for example, security framework. At long last, most IoT apps have a high energy and price expenditure that could not withstand neighboring GPU agreements or transmit enormous image and noise data measurements to data farm processors. To deal with these difficulties, a restricted AI processing plan is proposed. The limited AI preparing plan goes for handling the gained information at the customer side and completes the entire AI calculation without correspondence system get to [5]. Routinely, this is done through neighborhood GPU or DSP Be that as it may, these outcomes in a restricted calculation capacity and moderately huge power utilization, does not make it suitable for operating starving neural system calculation , for example, CNN on power constrained internet gadgets. Hence, Iot’s devoted CNN equipment is scheduled to help AI with small power use. A part of thorough work in the neural system is focused on designing a particular neural system registration For instance, in, efficient machinery engineering is suggested to be based on the neural system sparsely by properly tapping the circuit. In any case, it is a progressively broad engineering to process the completely
associated profound neural system without considering parameter reuse. Despite what might be expected, the CNN has its one of a kind element that the channels' loads will be to a great extent reused all through each picture amid filtering [7]. Profiting by this component, many devoted CNN accelerator are accounted for. The greater parts of announced CNN hardware accelerator just spotlight on accelerator, the convection portion overlooks the use of t he pooling ability typical of the CNN arrangement. A CNN equipment accelerator utilizing a spatial engineering with 168 processing elements is illustrated [6]. Another committed convolution hardware accelerator with circle tiling enhancement is accounted for. Since pooling capacity isn't actualized in that hardware accelerator, the findings of the conversion need to be exchanged with CPU / GPU to operate pooling ability with afterward sustained reverse to quickening agent figuring the following layer. This information development expends much power as well as points of confinement by and large execution. The paper is further arranged in following sections. In section II we brief the Convolution Neural Networks by layers followed by section III , we discuss about the proposed work with the cadence results and comparison tables. In section IV and V we present the CNN results and its conclusion thereafter, concluding with the references part in section VI
2.
LAYER EXPLANATION
CNN systems are mostly produced of three common layer Includes the possibility that some in-line equations will be made display equations to create better flow in a paragraph. If display equations do not fit in the two-column format, they will also be reformatted. Authors are strongly encouraged to ensure that equations fit in the given column width.
A. Convolution Layer: ____________________________
V Sridyuthi currently perusing Masters of Technology in Sree Nidhi Institute of Technology, Department of electronics and Communication in Digital Systemsand Computer Engineering
Ph.no: 9494934880, email
AbhishekCoubey he ie working in Sreenidhi institute of science and technology, Hyderabad, India. His research interests include signal processing algorithms, VLSI architectures and digital signal processing in general
3365 Fig.1: Example of a CNN layer.
A convolution layer's important task is to apply convolution capability to delineate photos of the data layer to the next layer. Because each portion of the information can have separate information components, the conversion is 3D. Unlike conventional convolution, where all the data was required to generate data, neural system convolution is restricted by framing a provincial channel window in each individual data channel. The system of local flow lenses is considered to be one channel. The output information is acquired by managing the result of the internal signal weight
(1)
ko speaks to the present yield highlight's file number, Fi and Fo speaks of channels and yield highlights, l and m speaks to the yield highlight's information line and segment number, t is the walk size of the convolution window, X speaks to the channel weight, A speaks to the inclination weight of each channel,, ROW and COL, are the bit size, yield highlight line size and segment estimate separately.
B. Pooling Layer:
In addition, pooling layer is a basic part of the normal CNN along with the convolution layer. The task is to extricate data in each stream from several nearby image pixels. On a periodic basis, the pooling surface may be split onto two classifications: I) in the pooling Window, a maximum layer assigns an economic advantage for all the widest image data, while ii) the standard Pooling surface produces the required data measure throughout the window. Numerical representation is as (2) and (3).
(2)
(3)
Here K [l] [m] speaks to the channel's information at the position (l,m)
3.PROPOSED MODEL
A general design of DLHA (Deep Learning hardware accelerator} is appeared in Fig. 2.
3366 It is now shown that deep schemes with 16-bit fixed- point
number can be spoken to with stochastic adjustment and result in the exactness of the structure near zero corruption. In addition, the use of the 16-bit skimming snake charges much more rational entries than fixed point viper of a 16-bit size. The drifting tires in the middle of the preparing can be shortened to its fixed point. The hardware accelerator includes a single port SRAM of 96 Kbytes to place in the center of highway data and trade data of DRAM, a processor, memory controller, DMA module as well as DLHA arm. Processor is used by JTAG-UART to provide the user with programming interface and to communicate with DLHA. In specific, it transfers the data and weight matrix for both the inner BRAM module, that aims to activate the DLHA and yields the outcomes since execution. It is incorporated as an independent unit that can be adapted and versatile to require designs for different applications. The DLHA consists of three pipeline processing units Tiled Matrix Multiplication Unit (TMMU), Part Sum Accumulation Unit (PSAU), and Activation Function Increasing speed Unit (AFAU).DLHA looks through DMA's mapped storage data for execution, records with all three handling systems, and then composes the outcomes away into the database. The instructions can be two categories: instructions for layout and instructions for execution. The layout instructions are integrated in distinct levels, such as stream estimation and figures, empowering ReLU capability, or peak pooling capability, to organize the assets of the up and upcoming layer. The instructions for execution are to begin the calculation for convolution / pooling. Additionally, the development of the shifting place appreciation for a huge defined stream of conversion is integrated into the instructions of execution.
3.1 TMMU architecture:
A situation to depict matrix multiplication is presented. The outcome of such two equations is indeed the equation relative to the amount of distance across each couple of nodes which describes its row and column inside the matrix. It is important to keep in mind that when the declaration in previous section
terminates the sequence when its rank or column numbers are within the item block boundaries. It can only occur in the components either positioned the correct or the upper part of matrix. We use the BRAM to place two adjoining parts of weight statistics. The accelerator occurs in 32 by the consecutive quantity of the input storage weight database and cycles to skip in unique memory. Thus it can print in tandem ranges. We put up to print its information needed for subsequent repetitions then it can be used in current iteration to decrease the effect on the execution of the access time for information. The moment to record 32 entry numbers in our experiment is considerably less than the moment to calculate 32 scores. Thus, the registration of the process will start without being held apart from the main process.
Fig.3: Tiled Matrix Multiplication Unit
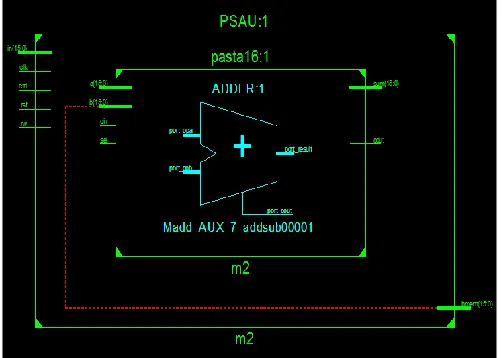
3367 3.2 PSAU architecture:
This device becomes responsible for all the retrieval function. These sections are supplied to the TMMU. At that stage, component aggregate takes that appreciation s and includes that characteristics using PSAU will form the motivation to produce cushion and in a pipeline manner deliver outcomes to AFAU. One part of sum per clock cycle can be recovered, so that the throughput matches the portion age of TMMUNumber footnotes separately in superscripts (Insert | Footnote)1.
3.2.1 Design Summary of CSA (Carry save Adder): It is usually made up by multi-operand elevated velocity that comprises a ladder of full adders. Here, there are 3 phases and each one of the SUM and CARRY producedPhases are flown to the next level. Therefore, do not spread CARRY as in traditional ripple hold adder. Thus, the generation of delays is less than other adders. This can be further decreased by addition using a carry save. The concept takes 3 digits say ,x+ y + z, and transform them into c+ s , in O (1) time. This is why adding could not be done in obtained point because of need to propagate the carry data. Besides, we keep going through carrier. A 8 and 16 bit carry save adder behaves differently in area wise delay wise, number of slices used wise
Drawbacks of CSA:
We understand the outcome of the addition at the same time at each point of a carry-save system .But, we still don't know if the result is bigger else just over specified amount (for example, it is not known whether positive or negative). This is a disadvantage to implement modular multiplication when using carry-save adders. The Montgomery, which depends on the right digit of the result, is one of the solution; although it carries a fixed overhead itself, so that a sequence time is saved not just one. Luckily, in public key cryptography, exponentiation is by far the frequent method, which is efficiently a series of multiplications. Careful analysis of error enables a decision to be made to subtract the module even if we do not understand for certain whether the outcome of the addition is sufficiently large to warrant the subtraction
3.2.2 Design Summary of PASTA (Parallel Self Time Adder):
Using combinational and sequential circuits for asynchronous or synchronous design, the general block diagram of the Parallel Self Timed Adder (PASTA) is presented with multi bit adders. Briefly, it will select the actual operands and move to feedback / carry routes. With each bit, the adder receives two operands first to carry out additions. For robustness against region, error and energy dissipation, the performance of adder topologies is discussed. As they have been widely used in many applications, they are selected for this job. Addition is an essential procedure for any digital high-speed scheme, digital signal processing or regulate system. In designing VLSI integrated circuits for elevated speed and elevated efficiency CMOS circuits, therefore, relevant selection of adder topologies is essential. Parallel self-time circuits have shown a range of benefits, including both quasi-delay-insensitive (QDI) circuits and less pure asynchronous circuitry types that use timing limitations for greater efficiency and reduced region and
energy. Some of main advantages may also include
Higher performance function units that provide completion in an average case rather than in the worst case. And a high-performance double- precision floating point adder.
When it is known that the inputs that have not yet arrived are irrelevant, early completion of a circuit. Lower power consumption because unless it performs helpful computation, no transistor ever transitions.. It is also possible to remove clock drivers that can considerably decrease power consumption.
Better compos ability and modularity.
The production method requires far fewer hypotheses
Table I: Simulation Results of Adders
Table II: Theoretical Results of Adders
Sl. No CSA[8] PASTA
8-bit 16-bit 8-bit 16-bit
HA 11 17 8 16
FA 5 15 -
-MUX - - 8 16
Adder Bits Delay(ns) Average
power (µW)
Transistor Count
PASTA
8-bit
4.24 730.2 236
16-bit
9.01 950.9 468
CSA[8]
8-bit
6.12 815 311
16-it
3368 Table III: Synthesis results of Adders
Fig: 5:16-Bit Parallel Self Time Adder (PASTA)
Fig 7: Synthesize XST view of Deep CNN Accelerator
3.3 AFAU architecture:
Activation Function Acceleration Unit(AFAU)does not involve elevated precision to calculate DNNs; Piecewise direct introduction may attain desired execution over various approaches ,such as binomial growth of direct addition to the parts execute whichever actuation works along unimportant drop of exactness is in consequential enough little
IV CNN RESULTS
Fig 8: RTL Schematic View of Deep CNN Accelerator
AND
Fig 9: Delay Report of CNN
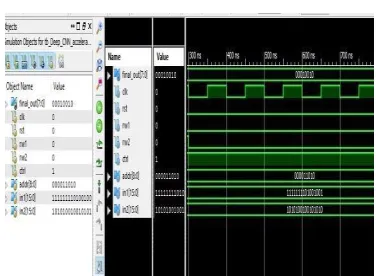
3369 Fig 10: Simulation Results of CNN
V.CONCLUSION
We proposed a CNN hardware accelerator streaming architecture. By decreasing unwanted information motion, the suggested accelerator optimizes energy effectiveness. It also uses filter decomposition method to support random image size convolution. Additionally, this accelerator also supports the pooling feature by incorporating distinct pooling module and adequate setup of the convolution engine..
REFERENCES
[1] [1] Sutkver .I , G. E. Hinton and Krizhv sky ―ImageNet classification with deep convolutional neural networks,‖ in. Adv. Neural Inf. Process. Syst., vol. 34. 2015, pp. 1097–1105.
[2] [2] Silver . ―Mastering the game of Go with deep neural networks and tree search,‖ Nature, vol. 429, no. 7581, pp. 473–89, January. 2016.
[3] [3] Classify Images With TensorFlow Using Google Cloud Machine Learning and Dataflow‖. S. Bilac. Searched on Nov. 2016.[Online].
[4] [4] Zisserman. A and K. Simonyan ―Very deep convolution networks for large-scale image recognition,‖15, September. 2014.
[5] [5] Hameed et al., ―Understanding sources of inefficiency in general-purpose chips,‖ Proc. 37th Annu. Int. Symp. Comput. Archit., 2010, p. 46.
[6] [6] M. horowittz, ―Computing’s energy problem ―IEEE Int. Solid- State Circuits ― Conf. (ISSCC) Dig. Tech. Papers, 2014’ February , pp. 10
[7] [7] S. Han et al., ―EIE: Efficient inference engine on compressed deep neural network,‖ in Proc. 43rd Int. Symp. Comput. Archit., 2016, pp. 56
[8] [8] J.-M. Muller and L. Beuchat, "Automatic generation of modular multipliers for fpga applications," IEEE Transactions on Computers, vol. 57, no. 12, December 2008, pp. 1600.
[9] [9] F. Dinechin, Detrey and X. Pujol, "Return of the hardware floating-point elementary function," in Proceedings of the 18th IEEE Computer Society Press, June 2007, pp. 161-
[10][10] H. Eberl, G. N. Shantz, V. Gupta, L. Rarick, and Sundaram,S. "A public-key cryptographic processor for RSA and ECC," in Proceedings of the International
Conference on Application-Specific Systems,
Architectures and Processors (ASAP2004),
September 2004.