3259
Predictive Analysis On Student Competency In
Database Management System: A Data Mining
Approach
Devine Grace D. Funcion
Abstract - Proficiency in information technology is essential to those students who are seeking for employment. Being competent in database management is beneficial in these generation were numerous data are being process and stored in databases. The purpose of the study is to developed a decision tree model that will identify the competency level of the BSIT graduate of the Leyte Normal University. The study applies Knowledge Discovery in Database (KDD), a data mining techniques. The data was collected through the use of a survey questionnaire, created using the google form. A total of forty-five (45) 4th year IT students participated in the actual conduct of the survey. Therefore, using the J48 algorithm is an effective data mining technique that can predict a 97.619% accuracy rate in identifying student competency in the Database Management System course. However, it is recommended teachers assigned to teach the DBMS course should not only focus on the six attributes but instead, IT students should be competent in all the identified competency.
Index Term: Database Management, Competency, Information Technology, Data Mining, Prediction, Students, J48 algorithm
——————————
——————————
1. INTRODUCTION
Proficiency in information technology is significant in this digital world. As technology advances, an enormous data warehouse is needed to store data set for data analysis, data query, and data mining that is helpful during decision making. Hence, new job opportunities fueled by those job seekers who are tech-savvy. Graduates in higher institutions, colleges, and universities shape their students to be highly competitive equipped with knowledge and skills in Database Management System (DBMS). Hence, in the study of Mirchandani [1] and Aasheim [2], both identified the top growing IT skills, and these are wireless communications and applications, mobile commerce applications and protocols, IS security, Web applications, services, and protocols, and data management. Moreover, Lee [3] mentioned that the role of an IT programmer does not focus only on the programming realm. Instead, they are expected to play the role of IS developer. The database was found to be a vital software skill for programmers with (78.58%) result while the employability of graduates depends on the skills, knowledge, attitudes, and understanding that will enable graduates to make productive contributions to organizational objectives [4]. Radermacher's [5] study noticed that knowledge in databases is a frequently reported issue faced by the company that hires fresh graduates. Many of the newly hired have trouble in creating, designing, and interacting with databases, some have limited understanding of the internal mechanics behind databases, and others have a problem with connecting their code with databases. Some companies correctly pointed out a lack of experience with DBMS tools, with one indicating that recent graduates often did not even know how to use the tools to set up a new database. Babb [6] IT students must be competent in handling and understanding of data and information, must extend into the world of abstractions (such as the degree to which we synchronize systems analysis and design with Entity-Relationship Diagrams) and into the detailed environment of computing architecture (understanding how computers and operating systems work). Leyte Normal University offers a Bachelor of Science in Information Technology; one of the major courses provided is DBMS. The objective of the course is to equipped students with
3260 least is capable of being as much a student group 20.91%.
Kulkarni [10], the study uses four classifiers that can run incrementally; the Naive Bayes, KStar, IBK, and Nearest neighbor (KNN) have been compared to identify the student’s performance based on incremental learning. As observed in the result, the nearest neighbor algorithm gives better accuracy compared to other algorithms applied in the Student Evaluation dataset. Sundar [11] the study analysis the dataset of First Year students of MCA Hindusthan College of Arts & Science- Coimbatore in the period of 2012-2013. Initially, the student dataset contains 48 records and 10 Attributes. Moreover, the study uses Bayesian network classifiers for predicting the student's academic performance and generates a Model. This model helps earlier in identifying the dropouts and students who need special attention and allow the teacher to provide appropriate counseling/ Advising. In Addition to this, accurately predicting student performance is useful in many different contexts.
2.
METHODOLOGY
The study applies Knowledge Discovery in Database (KDD), a process that acquires new knowledge from a myriad of data using data mining techniques. The KDD process observes the following activities: data selection, data processing, data transformation, and Data Mining and Result [12].
Figure 1: Stages of the KDD process
Data Selection
The collected data through the use of a survey questionnaire, created using the google form. The questions were from the Information Technology Competency Model is patterned [13]. A total of forty-five (45) 4th year IT students were identified to answer the survey questionnaire; however, during the conduct of the survey, two (2) students were absent and were not included as respondents. There were eighteen (18) questions that the student will answer whether they are highly competent, competent, uncertain, somewhat skilled, not competent.
Preprocessing and Transforming
During the preprocessing stage, the eighteen questions were code that will be used in the mining process, as presented in table 1. The used code serves as the attribute name for each column that represents the answer of the students, as shown in table 2. Then the document is saved as a comma-separated value (CVS) format. Then using the WEKA application for the preprocessing of information, the CSV file was loaded. As presented in figure 2, wherein initial visualization of all individual attributes that show the competency level of the students.
Table 2: Dataset for the mining process
Figure 2: preprocessing- visualization of the attributes Table1: Database Management System Competency
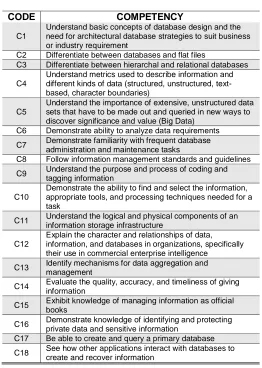
CODE COMPETENCY
C1
Understand basic concepts of database design and the need for architectural database strategies to suit business or industry requirement
C2 Differentiate between databases and flat files
C3 Differentiate between hierarchal and relational databases
C4
Understand metrics used to describe information and different kinds of data (structured, unstructured, text-based, character boundaries)
C5
Understand the importance of extensive, unstructured data sets that have to be made out and queried in new ways to discover significance and value (Big Data)
C6 Demonstrate ability to analyze data requirements C7 Demonstrate familiarity with frequent database
administration and maintenance tasks
C8 Follow information management standards and guidelines C9 Understand the purpose and process of coding and
tagging information
C10
Demonstrate the ability to find and select the information, appropriate tools, and processing techniques needed for a task
C11 Understand the logical and physical components of an information storage infrastructure
C12
Explain the character and relationships of data, information, and databases in organizations, specifically their use in commercial enterprise intelligence
C13 Identify mechanisms for data aggregation and management
C14 Evaluate the quality, accuracy, and timeliness of giving information
C15 Exhibit knowledge of managing information as official books
C16 Demonstrate knowledge of identifying and protecting private data and sensitive information
C17 Be able to create and query a primary database C18 See how other applications interact with databases to
3261 Data Mining
J48 Algorithm
J48 Algorithm was used to process the data and generate the decision tree model for student competency in DBMS, as shown in figure 3. J48 is an extension of ID3, and classification type of algorithm that performs a recursive process till every single leaf is pure, to allow classification of the data to be as perfect as possible. This algorithm creates the rules from which particular identity of that data. The objective is progressively generalization of a decision tree until it gains equilibrium of flexibility and accuracy [14], [15].
Figure 3: J48 Algorithm Result
3.
RESULT AND DISCUSSION
Table 3: Classification result
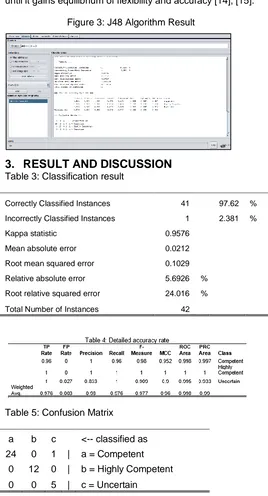
Correctly Classified Instances 41 97.62 % Incorrectly Classified Instances 1 2.381 %
Kappa statistic 0.9576
Mean absolute error 0.0212
Root mean squared error 0.1029 Relative absolute error 5.6926 % Root relative squared error 24.016 %
Total Number of Instances 42
Table 5: Confusion Matrix
a b c <-- classified as
24 0 1 | a = Competent
0 12 0 | b = Highly Competent
0 0 5 | c = Uncertain
As presented in table 3, the J48 algorithm was able to correctly classified instances with a percentage of (97.62%) which means the algorithm classifies the students whose competency level belongs to highly competent, competent, uncertain, somewhat relevant, and not competent. Hence, the result shown in Table 5, the confusion matrix supports
the result found in table 3; it reflects the classification of the IT students according to its level of competency. There are twenty-four (24) students who are classified correctly as Competent, twelve (12) students classified as Highly Competent, and five (5) students classified as Uncertain. However, there are no students who possess competency that belong to Somewhat Competent and Not Competent. It implies that the IT student is proficient in DBMS that they can deliver the required skills to undertake a task. Hence, Table 4 shows the detailed accuracy rate per competency level. They are having presented in ROC Competent (99,8%) accuracy rate, Highly Competent (100%) accuracy rate, and lastly, Uncertain (99.5%) accuracy rate. It means that the J48 was able to correctly classified the IT students with a Precision percentage level of (98%).
Figure 4: Student Competency in DBMS – Decision Tree Model
Moreover, figure 4illustrates the decision tree model of the 6 attributes that IT students show expertise. These are (C3)
or Differentiate between hierarchal and relational databases
3262 and had many more physical records than the HELP
database, but it is quicker and more efficient in storing data than the standard HELP utilities [19]. Example of the query language is SELECT, INSERT, UPDATE, and DELETE statement.
SELECT * from PATIENT
where PatientID = 43536
Fifth (C8) standards and follow information management guidelines. There should be a validation of collected information before the business used the result for decision making. Since data are an essential resource for any organization, the data presented to users must be of high caliber. The information must be recent, complete, and accurate for the purpose it is required, unambiguously understood, consistent, and available when it is need [20]. IT students should follow the guidelines in managing information to assure a high tone of data accuracy and consistency. Lastly, (C7) demonstrate familiarity with frequent database administration and maintenance tasks. Database maintenance tasks include data cleaning and backup. Data cleaning is a process of removing errors and inconsistencies from data to improve the quality of data. Data cleaning is not only needed for data warehousing but also query processing on heterogeneous data sources, e.g., in web-based information systems [21].
4.
CONCLUSION
Therefore, using the J48 algorithm is an effective data mining technique that can predict a 97.619% accuracy rate in identifying student competency in the Database Management System course. It implies that IT students demonstrated a competent to a highly skilled level of skill in all the six attributes presented in the decision tree model. Hence, IT students can effectively utilize their knowledge in creating a useful database design.
5.
RECOMMENDATION
The following identified recommendation for the study: 1 Teachers assigned to teach the DBMS course
should not only focus on the six attributes but instead, IT students should be competent in all the attributes.
2 Other universities, colleges, and higher education institutions may have utilized the result also to test their students the level of competency in the DBMS course.
3 Other research used different techniques in data mining to predict student competency.
6.
REFERENCES
[1] Mirchandani, K. L. (2010). Dynamics of the Importance of IS/IT Skills. Journal of Computer Information Systems, 50:4, 67-78.
[2] Aasheim, C. S. (2012). Knowledge and skill requirements for entry-level IT workers: A longitudinal study. Journal of Information Systems Education, 23(2), 193.
[3] Lee, C. K. (2008). Analysis of skills requirement for entry-level programmer/analysts in Fortune 500 corporations. Journal of Information Systems Education, 19(1), 17.
[4] Omar, N. H. (2012). Graduates' employability skills based on current job demand through electronic advertisement. Asian Social Science, 8(9), 103.
[5] Radermacher, A. W. (2014, May). Investigating the skill gap between graduating students and industry expectations. In Companion Proceedings of the 36th international conference on software engineering (pp. (pp. 291-300)). ACM.
[6] Babb, J. S. (2014). Confronting the issues of programming in information systems curricula: The goal is success. Information Systems Education Journal, 12(1), 42.
[7] Borkar, S. &. (2013). Predicting students academic performance using education data mining. International Journal of Computer Science and Mobile Computing, 2(7), 273-279.
[8] Ahmed, A. B. (2014). Data mining: A prediction for student's performance using classification method. World Journal of Computer Application and Technology, 2(2), 43-47.
[9] Alfiani, A. P. (2015). Mapping student's performance based on data mining approach (a case study). Agriculture and Agricultural Science Procedia, 3, 173-177.
[10]Kulkarni, P. &. (2014). Prediction of student’s performance based on incremental learning. International Journal of Computer Applications, 99(14), 10-16.
[11]Sundar, P. P. (2013). A comparative study for predicting students academic performance using Bayesian network classifiers. IOSR Journal of Engineering (IOSRJEN) e-ISSN, 2250-3021.
[12]Marbán, O., Segovia, J., & Menasalvas, E. &.-B. (2008). Towards Data. Information Systems Journal. [13]House, C. M. (2019, October 9). Database and
Application. Retrieved from https://www.careeronestop.org/CompetencyModel/bloc kModel.aspx?tier_id=4&block_id=964&IT=Y:
[14]Gholap, J. (2012). Performance tuning of J48 Algorithm for prediction of soil fertility. arXiv preprint arXiv, 1208.3943.
[15]Kaur, G. &. (2014). Improved J48 classification algorithm for the prediction of diabetes. International Journal of Computer Applications, 98(22).
[16]Symas OpenLDPA. (2019, September 29). https://3bmahv3xwn6030jbn72hlx3j-wpengine.netdna- ssl.com/wp-content/uploads/2018/08/Difference-
between-Hierarchical-Database-and-Relational-Database.pdf. Retrieved from https://3bmahv3xwn6030jbn72hlx3j-wpengine.netdna-ssl.com: https://3bmahv3xwn6030jbn72hlx3j-
wpengine.netdna-ssl.com/wp- content/uploads/2018/08/Difference-between-Hierarchical-Database-and-Relational-Database.pdf [17]NETWORK, T. (2019, SEPTEMBER 29).
https://searchbusinessanalytics.techtarget.com/definitio n/business-intelligence-BI. Retrieved from https://searchbusinessanalytics.techtarget.com:
https://searchbusinessanalytics.techtarget.com/definitio n/business-intelligence-BI
3263 [19]Huff, S. M. (1991). Evaluation of an SQL model of the
HELP patient database. I. In Proceedings of the Annual Symposium on Computer Application in Medical Care (p. 386). Salt Lake City, Utah: American Medical Informatics Association.
[20]Gordon, K. (2013, November). Principles of Data Management: Facilitating Information Sharing Second Edition. BCS.
[21]Rahm, E &. (2000). Data cleaning: Problems and current approaches. IEEE Data Eng., Bull. 23, no. 4 (2000): 3-13