Volume 3, Issue 6, 2016
58 Available online at www.ijiere.com
International Journal of Innovative and Emerging
Research in Engineering
e-ISSN: 2394 - 3343 p-ISSN: 2394 - 5494
Text Extraction from Hoardings
D. Jayaram
T.Anusha
Dept. of MCA, CBIT, Hyd, India
M.Tech( CSE), CBIT, Hyd, India
Dr. CRK Reddy
Dr.V. Kamakshi prasad
Dept. of CSE, CBIT, Hyd, India Dept. of CSE, JNTUH, Hyd, India
ABSTRACT:
Text extraction from hoardings is a challenging task due to variations in font size, style, orientation, alignment, and complex backgrounds. Text extraction from hoardings plays a major role in finding vital and valuable information. The current OCR (optical character recognition) techniques are extracting text from plain backgrounds but those techniques are unable to extract text from complex backgrounds. The proposed hybrid technique extracts the text from complex backgrounds, which is useful in many applications are helpful to foreigners in understanding the local languages, useful to persons who are visually challenged, helpful to persons who can’t read. The process of the proposed method consists of text detection, text segmentation and extraction of the individual characters from the segmented text. The proposed method achieved the text extraction accuracy of 83% on 142 input images.
Keywords: Text Extraction, Complex Background, Optical Character Recognition, Text detection, Edge detection, connected components
I. INTRODUCTION
Text extraction from hoardings is a challenging task because of its complex backgrounds and large variations of text patterns. With the increasing use of portable cameras and mobile phones, the text extraction from images becomes quite handy to various users. The image captured by these devices contains valuable information, which is useful in many applications. So it is very important to detect and identify the text regions as accurately as possible before performing character recognition. Some of the applications are number plate recognition, provide assistance to visually impaired persons and illiterate persons and it is also helpful to foreigners to understand the non-native languages.
Quality of natural images depends on resolution, image quality, camera lenses, object position, light affects during a day and complex background. In the last decade, many methods have been proposed to address the text detection and localization problems, and some of them have got impressive results. However, fast and accurate text detection and localization in natural scene images is still a challenging task. Although the existing methods have reported promising localization performance, there are still several challenges to look into [1].
There are many Optical Character Recognition (OCR) techniques are available for different languages. They can only handle text with plain backgrounds. They can’t extract text from a complex or textured background [2]. The process of text extraction from images can be divided into the following sub problems [3] i) text detection and localization and ii) text segmentation.
Text detection and localization [15] is the process of determining text locations in the image and generating bounding boxes around them. The existing methods of text detection and localization can be roughly categorized into five groups [3].
II. PREVIOUS RESEARCH WORK
The existing methods of text detection and localization can be roughly being divided into 5 types: edge-based, texture-based, connected components (cc)-based, stroke-based and the other methods [11].
A. Text detection and localization methods.
Volume 3, Issue 6, 2016
59 good edge profiles are hard to obtain under the influence of shadow or high light. Sun et al., [19] proposed a method to extract board text under natural scene. Liu and Samarabandu [4] proposed a multi-scale edge based text extraction algorithm, which can automatically detect and extract text in complex images. Ren et al. demonstrated a framework that computes edges. Bai et al. [5, 6, 7] investigated text detection in complex back-ground images.
Texture based methods: Texture based methods are utilized on the observation that texts in images have distinct textural properties that distinguish them from the background. Mostly used texture analysis approaches are Gaussian filtering, Wavelet decomposition, Fourier transform, discrete cosine transform (DCT) and Local binary pattern (LBP) [19]. Zhou et al. [9] proposed a multilingual text detection method. Pan et al. [10] proposed a new method for fast scene text localization in natural scene images, others also proposed methods for text detection.
Connected component based methods: Connected component based methods use a bottom-up approach by grouping small components into successively larger components until all regions are identified in the image. Zhang et al. , Wang et al. , Wang and Kangas [11] proposed methods based on connected components.
Stroke based methods: As a basic element of text strings, strokes provide robust features for text detection in natural scene images. Text can be modeled as a combination of stroke components with a variety of orientations and features of text can be extracted from combinations and distributions of the stroke components. One feature that separates text from other elements of a scene is its nearly constant stroke feature like stroke width ,this can be used to identify text regions. Epstein et al. [17], Srivastav and kumar [18] and others proposed methods based on strokes in the image.
The other approaches: Due to the large number of possible variations in text, approaches listed above are failed under certain conditions. To solve such problems, some researchers developed the new approaches by using the combination of text based methods, connected component methods and stroke based methods.
B. Character Segmentation
After finding the text region in the image, each character is segmented using bounding-box method.
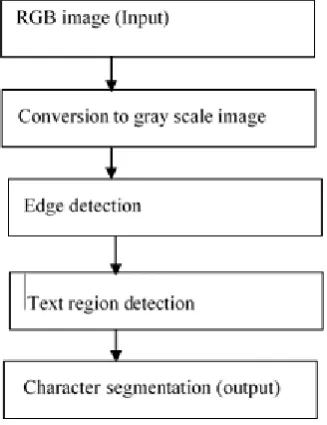
III. PROPOSED METHOD
The proposed hybrid method begins with the conversion of input image (RGB image) in Fig. 2 into a grayscale image. Then apply the edge detection method to find edges of the components, and then connected component method is used on edge detection image to find text regions. Apply the filtering techniques like eccentricity, area and solidity to eliminate the non-text region in the image. Then we will get only the text region of the image without noise and each character is segmented from the text region using bounding-box method. Then recognize the segmented characters using existing OCR methods. Fig. 1 shows the Phases of the hybrid method.
Volume 3, Issue 6, 2016
60 A. Methodology
The input image captured by the mobile phone or camera is processed. The original RGB image in the Fig. 2 consider as the input to the proposed method.
Fig 2: Original Image
Conversion of RGB image to grayscale: Generally the input image is an RGB image, which is converted into grayscale image to reduce the number of colors so that computation becomes easier. Gray scale image of the original image shows in the Fig. 3. The formula used to conversion of RGB image to gray scale image is
𝑝𝑖𝑥𝑒𝑙 𝑣𝑎𝑙𝑢𝑒 𝑜𝑓 𝑖𝑚𝑎𝑔𝑒 =((0.21 × 𝑅𝑒𝑑_𝑣𝑎𝑙𝑢𝑒) + (00.72 × 𝐺𝑟𝑒𝑒𝑛_𝑣𝑎𝑙𝑢𝑒) + (0.07 × 𝐵𝑙𝑢𝑒_𝑣𝑎𝑙𝑢𝑒))
3 (1)
Fig 3: Gray Scale Image
Edge detection: The gray scale image consider as an input to the edge detection. Edges of the objects in the image are detected using sobel edge detection operator. This operator gives accurate results compared to other methods like Canny, Prewitt, Roberts and Log edge detection methods to the images. Detection of edges of the objects in the image contains the following steps. Edges of the objects in the image are shown in the Fig. 4. Edge detection algorithm described below.
Volume 3, Issue 6, 2016
61 Fig 4: Edge detection image
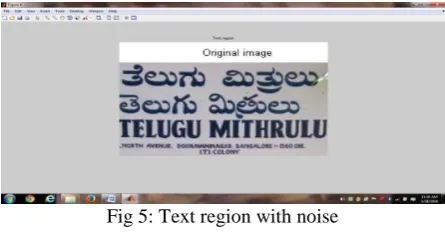
Text region detection: The edge detected image is taken as the input to this step. This image is converted into binary image before applying the connected components method [13, 14]. A Connected component method is used to segment the text regions [12]. After applying the connected components method on binary image, label matrix is generated. Label matrix consists of regions that are formed by taking edge detection image. Fig. 5 shows the text region of the image. This phase consist of two passes.
First Pass:
1) Iterate through each element of the matrix by column, then by row (raster scanning). 2) If the element is not the background
a) Get the neighboring elements of the current element.
b) If there are no neighbors, uniquely label the current element and continue.
c) Otherwise, find the neighbor with the smallest label and assign it to the current element and store the equivalence between neighboring labels.
Second Pass:
1) Iterate through each element of the matrix by column, then by row.
2) If the element is not the background then relabeled the element with the lowest equivalent labels.
Fig 5: Text region with noise
Noise filtering in the text region: Text regions with noise are given as the input to the filters to remove the non-text area from the text region. Area, eccentricity and solidity features are used for filtering purpose. Fig. 6 shows the text region without noise. Eccentricity is used to find fine straight lines as follows.
E = 𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒 𝑏𝑒𝑡𝑤𝑒𝑒𝑛 𝑡ℎ𝑒 𝑓𝑜𝑐𝑖
𝑚𝑎𝑗𝑜𝑟 𝑎𝑥𝑖𝑠 𝑙𝑒𝑛𝑔𝑡ℎ (2)
Area gives actual number of pixels in the region. Pixels less than 50 are removed to avoid small areas. Solidity gives pixels in the convex hull that are also in the region. It removes the extra region in the particular region.
𝑠𝑜𝑙𝑖𝑑𝑖𝑡𝑦 = 𝐴𝑟𝑒𝑎 𝑜𝑓 𝑟𝑒𝑔𝑖𝑜𝑛
Volume 3, Issue 6, 2016
62 Fig 6: Text region without noise
Character segmentation: Text region without noise is taken as the input and then apply the bounding-box method to
extract the individual characters from the text region which is shown in the Fig. 7. Bounding-box method described below.
Algorithm 2: Bounding-Box method
Fig 7: Character segmentation
Volume 3, Issue 6, 2016
63 We have applied the proposed hybrid method on different images apart from hoardings like display boards, car number plates, text embossed on rocks, papers and posters etc.,. The proposed hybrid method given more accuracy on number plates compared to other types of images. This method is more suitable for display boards and number plates. Some of the results were shown in the Fig. 8.
Input Image Output
Fig 8: Text extraction results
We have tested 142 images, which were captured by the mobile phone, among them 95 were on display boards. Among these texts extraction was success in 83 images. Twenty one number plates of the vehicle were tested. Out of which 19 were detected correctly. Thirteen embossed text on rocks were tested. Out of which 7 were recognized accurately. We have tested 6 posters, among these 4 were detected accurately. Above stated results are shown in the following table.
Table 1: Tested images
Type of the image No. of images Tested Correctly detected images Percentage of correctly detected images
Display Boards 95 83 87.3%
Number Plates 21 19 90%
Papers 7 5 71.4%
Rocks 13 7 53.8%
Volume 3, Issue 6, 2016
64 We have failed to recognize the images with accuracy in the case of blurred images, more complex background images and when the image foreground and background contains the same color.
V. CONCLUSIONS
In this paper a hybrid method is proposed to extract text from the images with complex backgrounds. We are able to extract text in different orientations, fonts and sizes. Display boards and number plates are recognized with high accuracy compared to other type of images. Text detection in natural scene images is still an unsolved problem due to the unpredictable text appearances, complex backgrounds and cluttered images. The future work is to improve the accuracy of the system and extract text from all types of images like cluttered images, logos, images with multilingual, etc.,
REFERENCES
[1] Prashant Madavanavar , Vinaykumar Patil ”Text Region Detection And Extraction From Road Direction Sign Boards” International Journal of Engineering Research & Technology (IJERT) Vol. 2 Issue 7, July – 2013.
[2] Feby Ashraf and Nurjahan V A “Connected Component Clustering Based Text Detection with Structure Based Partition and Grouping” IOSR Journal of Computer Engineering Volume 16, Issue 5, Ver. III (Sep – Oct. 2014), PP 50-56.
[3] Xu-Cheng Yin, Xuwang Yin, Kaizhu Huang, and Hong-Wei Hao “Robust Text Detection in Natural Scene Images” International Journal,2 jan 2013.
[4] X Liu, J.Samarabandu, Multi-scale edge-based text extraction from complex images, in: 2006 IEEE International Conference on Multimedia and Expo, IEEE, 2006, pp.1721-1724.
[5] C.Yao X.Bai “Detecting texts of arbitrary orientations in natural images,in: 2012 IEEE conference on computer vision and pattern recognition (CVPR),2012,pp. 1083-1090.
[6] P.Shivakumara, T.Q.Phan, C.L.Tan, A gradient difference based technique for video text detection, in:2009 10th International Conference on Document Analysis and Recognition,ICDAR’09,IEEE,2009,PP. 156-160.
[7] P.Shivakumara,W.Huang,C.L.Tan, An efficient edge based technique for text detection in video frames, in:2008 Eighth IAPR Internatinal workshop on Document Analysis systems,DAS’08,IEEE,2008 PP.307-314.
[8] X.Liu, J.Samarabandu, An edge-based text region extraction algorithm for indoor mobile robot navigation,in: 2005 IEEE, International Conference on Mechatronics and Automation, Vol. 2, IEEE,2005,pp. 701-706.
[9] G.Zhou, Y.Liu et., al “Detecting multilingual text in natural scene, in: 2011 1st Internatinal symposium on access spaces (ISAS), IEEE,2011,pp.116-120.
[10]Y.F.Pan, C.L.Liu, X.Hou, Fast scene text localization by learning-based filtering and verification, in:2010 17th IEEE Internatinal conference on image processing (ICIP),IEEE,2010,pp.2269-2272.
[11]Honggang Zhang, Kaili Zhao et., al “Text extraction from natural scene image: A Survey” Neurocomputing 122 (2013) 310-323 in Elsevir.
[12]Julinda Gllavata, Ralph Ewerth1 and Bernd Freisleben “A Robust Algorithm for Text Detection in Images” at University of Siegen.
[13]Sivaramakrishnan Rajaraman and Arun Chokkalingam “Connected Components Labeling and Extraction Based Interphase Removal from Chromosome Images” International Journal of Bio-Science and Bio-Technology Vol. 5, No. 1, February, 2013.
[14]B.Nishanthi1, S. Shahul Hammed “Detection of Text with Connected Component Clustering” Proceedings of International Conference On Global Innovations In Computing Technology Vol.2, Special Issue 1, March 2014. [15]Manjula Lamani, Arunkumar G, Srinivasa Rao Udara, Arun Kumar K. M, Spoorti J. Jainar “Detection and
Localization of Text from Natural Images with a Hybrid Method” The International Journal Of Science & Techno ledge, 242 Vol 2 Issue 4 April, 2014.
[16]Huizhong Chen, Sam S. Tsai, Georg Schroth, David M. Chen1, Radek Grzeszczuk and Bernd Girod “Robust Text Detection in Natural Images with Edge-Enhanced Maximally Stable Extremal Regions” at nokia research center Germany.
[17]Epshtein B, Ofek E and Wexler Y “Detecting text in natural images with stroke width transform “ CVPR’10 (oral). [18]A.Srivastav,J.Kumar,“Text detection in scene images using stroke width and nearest-neighbor constraints, in: IEEE
Region 10 Conference on TENCON 2008-2008, IEEE, 2008.pp.1-5.