International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
641
Task Scheduling in Homogeneous Multiprocessor Systems
Using Evolutionary Techniques
Aparna Vishwanath
1, Ramesh Vulavala
2, Sapna U. Prabhu
31,3
Department of Electronics, Fr. Conceicao Rodrigues College of Engineering, Mumbai University 2
Deparment of Chemical Engineering, D.J Sanghvi College of Engineering, Mumbai University
Abstract - Minimizing the total processing time by scheduling the tasks of a given network on to the available processors is an important and challenging problem. It is known to be a NP-complete problem and so the classical techniques of optimization require considerable time and effort to reach the optimum. In this work we propose to show how genetic algorithms can be adapted to tackle this problem, considering first a single task network and then a number of task networks with a given time period. For the single network as well as for a group of networks treated independently in a multi-network system, we show that the average of total processing time decreases with respect to generations.
Keywords- DAG, multi- network, multiprocessor, total processing time
I. INTRODUCTION
In multiprocessor systems, factors like load balancing, allocation of tasks onto processors, scheduling with communication delays have to be dealt with to improve system performance. Thus, task scheduling in multiprocessor systems with inter task communication delays is considered to be one of the important factors that can affect system performance. Finding the optimal solution of scheduling the tasks into the processors is NP-complete. Many evolutionary algorithms (e.g. Genetic Algorithm, Differential evolution) are used to reach the near optimal solution in linear time.
In our work heuristics for genetic algorithm based task scheduling in multiprocessor systems is proposed.
In multiprocessor based systems the processing capability of processors may vary. However in the further discussion we are considering a homogeneous multiprocessor system and hence all processors in the system have similar processing capability. The parallel tasks must be allocated onto the processors such that the total completion time must be as less as possible. Thus, the task scheduling problem in multiprocessor systems can be defined as allocating tasks onto processor such that the total processing time (make span) is minimized.
Genetic Algorithm, an evolutionary algorithm is used to find a suboptimal solution of the problem in considerable computation time. To reach the solution faster many heuristic based approaches are used. By heuristic based approach the initial population is much closer to optimal solution. This results in much less computation time in GA. GA proves to be better than the conventional algorithms viz. Next-Fit, Bin packing etc. and also involves lesser computational complexity than the above mentioned methods.
II.PROBLEM STATEMENT
The general problem of multiprocessor scheduling can be stated as scheduling a set of partially ordered computational tasks onto a multiprocessor system so that a set of performance criteria will be optimized. The difficulty of the problem depends heavily on the topology of the task graph representing the precedence relations among the computational tasks, the topology of the multiprocessor system, the number of parallel processors and the performance criteria (objective function) chosen.
III. PROPOSED MODEL
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
642
IV. SOLUTION STRATEGY
The application of Genetic Algorithms to this problem in its original form is not suitable because the sequence of tasks is more important than the individual tasks. The proposed strategy is to tackle one network at a time first and then all the networks put together. In the single network scenario, we propose to make use of available heuristics along with our own, to generate the initial population for a genetic algorithm. The Genetic Algorithm itself will consist of the usual selection, crossover, mutation operation with appropriate modification. In the selection process itself we ensure that the best sequence is passed on to the next generation. Other sequences are selected based on their fitness value. In crossover operation order of sequences is crossed over rather than the individual ones. In the mutation operation, two tasks will be swapped only if they belong to two different branches of directed acyclic graph.
In the multi-network scenario, we propose to employ genetic algorithms on linked sequences of tasks of all the networks, treating them as single entities. This gives us the maximum advantage of minimizing the communication delay between tasks linked by precedences at the same time keeping the precedence order intact. We propose to show that this gives the minimum total processing time for the combined networks.
V. GENETIC ALGORITHM
GAs encode the decision variables of a search problem into finite-length strings of alphabets of certain cardinality. The strings which are candidate solutions to the search problem are referred to as chromosomes, the alphabets are referred to as genes. In contrast to traditional optimization techniques, GAs work with coding of parameters, rather than the parameters themselves.
To evolve good solutions and to implement natural selection, we need a measure for distinguishing good solutions from bad solutions. The measure could be an objective function that is a mathematical model or a computer simulation, or it can be a subjective function where humans choose better solutions over worse ones. In essence, the fitness measure must determine a candidate solution’s relative fitness, which will subsequently be used by the GA to guide the evolution of good solutions. Another important concept of GAs is the notion of population. Unlike traditional search methods, genetic algorithms rely on a population of candidate solutions.
The population size, which is usually a user-specified parameter, is one of the important factors affecting the scalability and performance of genetic algorithms.
Once the problem is encoded in a chromosomal manner and a fitness measure for discriminating good solutions from bad ones has been chosen, we can start to evolve solutions to the search problem using the following steps:
Initialization: The initial population of candidate solutions is usually generated randomly across the search space. However, domain-specific knowledge or other information can be easily incorporated.
Evaluation: Once the population is initialized or an offspring population is created, the fitness values of the candidate solutions are evaluated.
Selection: Selection allocates more copies of those solutions with higher fitness values and thus imposes the survival-of-the-fittest mechanism on the candidate solutions. The main idea of selection is to prefer better solutions to worse ones, and many selection procedures have been proposed to accomplish this idea, including roulette-wheel selection, stochastic universal selection, ranking selection and tournament selection, some of which are described in the next section.
Recombination: Recombination combines parts of two or more parental solutions to create new, possibly better solutions (i.e. offspring). There are many ways of accomplishing this (some of which are discussed in the next section), and competent performance depends on a properly designed recombination mechanism. The offspring under recombination will not be identical to any particular parent and will instead combine parental traits in a novel manner (Goldberg, 2002).
Mutation: While recombination operates on two or more parental chromosomes, mutation locally but randomly modifies a solution. Again, there are many variations of mutation, but it usually involves one or more changes being made to an individual’s trait or traits. In other words, mutation performs a random walk in the vicinity of a candidate solution.
Replacement: The offspring population created by selection, recombination, and mutation replaces the original parental population. Many replacement techniques such as elitist replacement, generation-wise replacement and steady-state replacement methods are used in GAs.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
643
VI. PROPOSED GENETIC ALGORITHM
Generation Of Initial Population :
Various heuristics have been used to build the initial population. Each heuristic is explained in detail below.
Two frequently used attributes for assigning priority are the t-level (top level) and b-level (bottom level) [Adam et al.1974; Ahmad et al. 1996; Gerasooulis and Yang 1992]. The t- level of a node ni is the length of a longest path
(there can be more than one longest path) from an entry node to ni (excluding ni). Here, the length of a path is the
sum of all the node and edge weights along the path. As such, the t-level ni highly correlates with ni’s earliest start-time. The b-level of a node niis the length of a longest path
from ni to an exit node. The b-level of a node is bounded
from above by the length of a critical path. A critical path (CP) of a DAG, which is an important structure in the DAG, is a longest path in the DAG.
Below is the procedure for computing t-levels:
Computing a t-level
Construct a list of nodes in topological order. Call it TopList.
for each node ni in TopList do max = 0
for each parent nx of ni do
if t-level(nx) + w(nx) + c(nx,ni) > max then max = t-level(nx) + w(nx) + c(nx,ni) endif
endfor
t-level(ni) = max endfor
A similar procedure for computing b-levels is shown below:
Computing a b- level
Construct a list of nodes in reversed topological order. Call it RevTopList.
for each node ni in RevTopList do max = 0
for each parent ny of ni do
if b-level(ny) + c(ni,ny) > max then max = b-level(ny) + c(ni,ny)
endif
endfor
b-level(ni) = max + w(ni) endfor
Some of the DAG scheduling algorithms employ an attribute called ALAP (As-Late-As-Possible) start-time [Kwok and Ahmad 1996; Wu and Gajski 1990]. The ALAP start-time of a node is a measure of how far the node’s start time can be delayed without increasing the schedule length. Some techniques do not consider the edge weights while computing the b-levels, this gives rise to a new technique names as sls (static levels).
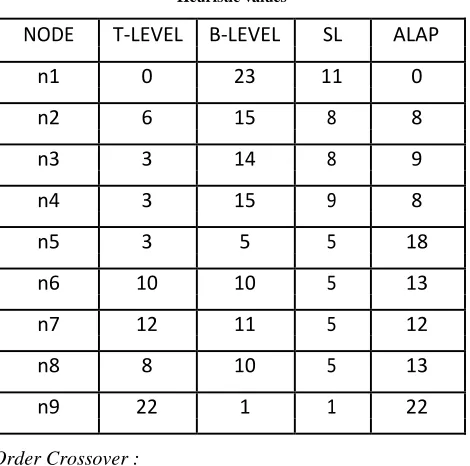
[image:3.612.328.563.344.577.2]The table below shows the t-level, b-level, sl-level and ALAP values for the task graph considered shown in figure 1.
Table 1 Heuristic values
NODE
T-LEVEL
B-LEVEL
SL
ALAP
n1
0
23
11
0
n2
6
15
8
8
n3
3
14
8
9
n4
3
15
9
8
n5
3
5
5
18
n6
10
10
5
13
n7
12
11
5
12
n8
8
10
5
13
n9
22
1
1
22
Order Crossover :
In the proposed method order crossover is used as the other variants of crossover viz. cycle crossover and PMX produce invalid results.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
[image:4.612.48.297.270.381.2]644
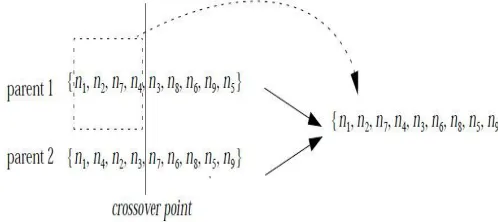
An example of the crossover operator is given in Figure 2. It should be noted that the chromosomes shown in the figure are all valid topological ordering of the DAG in Figure 1. The left segment{n1,n2,n7,n4} of parent 1 is passed directly to the child. The nodes in the right segment {n3,n8,n6,n9,n5} of parent 1 are then appended to the child according to their order in parent 2. This order crossover operator is easy to implement and permits fast processing. The most important merit is that it never violates the precedence constraints.Figure 2: An example of order crossover
The order crossover operator as defined above has the potential to properly combine the accurate task orderings of the two parent chromosomes so as to generate a scheduling list which can lead to a shorter schedule. This is because the “good” portions of a parent chromosome is a subsequence of the list which is an optimal scheduling ordering of the nodes in the subsequence. These good portions are essentially the building-blocks of an optimal list, and an order crossover operation can potentially pass such building-blocks to an offspring chromosome from which a shorter schedule may be obtained.
Mutation:
Mutation is a genetic operator for recovering the good characteristics lost during crossover and also for creating new chromosome. Mutation of a chromosome is achieved by simply flipping a randomly selected bit of the chromosome.
Like a crossover, mutation is applied with a certain
probability called the mutation rate which denoted by,
µm.
A valid topological order can be transformed into
another topological order by swapping some nodes.
For
example,
the
scheduling
list
{n
1,n
4,n
2,n
3,n
7,n
6,n
8,n
5,n
9} can be transformed into
an
optimal
list
{n
1,n
2,n
4,n
3,n
7,n
6,n
8,n
5,n
9}by
swapping n
2and n
4.Not every pairs of nodes can be
swapped without violating the precedence constraints.
Two nodes are
interchangeable
if they are not lying
on the same path in the DAG. Mutation operator is
thus defined as a swap of two interchangeable nodes
in a given chromosome.
Figure 3: A example of mutation operator
Control Parameters:
As suggested by Tanese [9], [10], if the parallel processors executing a parallel genetic algorithm use heterogeneous control parameters, the diversity of the global population can be more effectively sustained. To implement this strategy, we use adaptive control parameters as suggested by Srinivas et al. [11]. The adaptive crossover rate µc is defined as follows:
µc =
where,
fmax is the maximum fitness value in the local population, favg is the average fitness value,
f’ is the fitness value of the fitter parent for the crossover, kc is a positive real constant less than 1.
The adaptive mutation rate µm is defined as follows: µm =
where,
f is the fitness value of the chromosome to be mutated and km is a positive real constant less than 1.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
645
On the other hand, when the population tends to become more homogeneous, both rates increase because favg will be about the same as f’. Thus, under such a situation chromosomes are more likely to be perturbed. This helps to prevent a pre-mature convergence to a sub-optimal solution. Note that even though the initial setting of the crossover rate and mutation rate is the same for all the parallel processors, the adaptive strategy gradually leads to the desired heterogeneity of the parameters among the processors.The fitness function in our work is formulated as:
FF = 1/(1 + TPT)
Where, TPT – Total Processing Time
The population size Np and the number of generations Ng are also two critical control parameters that influence the performance of GA.
VII.MODEL DETAILS
The multiprocessor scheduling problem considered here is based on a deterministic model; that is the execution time and the relationship between the computational tasks are known. The precedence relationship among the task is represented by an directed acyclic graph (DAG). All processors are assumed to be identical and a processor completes the current task before executing a new one. An efficient method based on genetic algorithm for solving multiprocessor task scheduling problem has been presented here. Given a parallel program modelled by a node- and edge weighted directed acyclic graph (DAG), finding an optimal schedule with a minimum turn around time without violating precedence constraints among the tasks is well known to be an NP complete problem [1], [2], [3].
In static scheduling, a parallel program can be modelled by a directed acyclic graph (DAG) G = (V, E), where V is a set of v nodes and E is a set of e directed edges. A node in the DAG represents a task which in turn is a set of instructions that must be executed sequentially without pre-emption in the same processor. The weight associated with a node, which represents the amount of time needed for a processor to execute the task, is called the computation cost of a node ni and is denoted by w(ni). The edges in the DAG, each of which is denoted by (ni,nj), correspond to the communication messages and precedence constraints among the nodes.
The weight associated with an edge, which represents the amount of time needed to communicate the data, is called the communication cost of the edge and is denoted by c(ni, nj).
The source node of an edge incident on a node is called a parent of that node. Likewise, the destination node emerged from a node is called a child of that node. A node with no parent is called an entry node and a node with no child is called an exit node. The precedence constraints of a DAG dictate that a node cannot start execution before it gathers all of the messages from its parent nodes. The communication cost among two nodes assigned to the same processor is assumed to be zero.
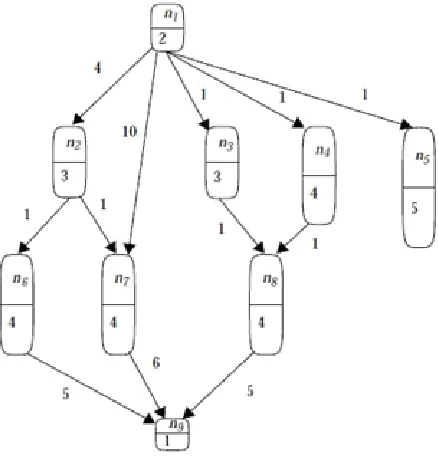
[image:5.612.334.553.369.601.2]The objective of scheduling is to minimize the schedule length by proper allocation of the nodes to the processors and arrangement of execution sequencing of the nodes without violating the precedence constraints. An example DAG, shown in Figure 1, will be used as an example in the subsequent sections.
Figure 1: Example DAG
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
646
VIII. RESULTS AND CONCLUSIONFollowing are the results obtained for single network scenario with variation in performance parameters.
Effect of Change in Population Size Np :
Np = 10, Kc = 0.7, Kmu = 0.3
Np = 7, Kc = 0.7, Kmu = 0.3
From the above results it is clear that with a larger population size the performance of GA improves and gives better output.
Effect of change in constant value Kc :
Np = 10, Kc = 0.2, Kmu = 0.3
From the above figures it is clear that lower values of Kc with larger population size Np gives better performance.
Following are the results obtained for multi-network scenario, where each network is treated independently. (no. of networks = 10)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
647
Np=10, Kc=0.7, Kmu=0.3
From the above figures it is clear that lower values of Kc with larger population size Np gives better performance.
REFERENCES
[1 ] E.G. Coffman, Computer and Job-Shop Scheduling Theory, Wiley, New York, 1976.
[2 ] M.R. Garey and D.S. Johnson, Computers and Intractability: A Guide to the Theory of NP-Completeness, W.H. Freeman and Company, 1979.
[3 ] J. Ullman, “NP-Complete Scheduling Problems,” J. Comp. Sys. Sci., 10, 1975, pp. 384-393.
[4 ] J.H. Holland, Adaptation in Natural and Artificial Systems, University of Michigan Press, Ann Arbor, Mich., 1975.
[5 ] W. Atmar, “Notes on Simulation of Evolution,” IEEE Trans. Neural Networks, vol. 5, no. 1, Jan. 1994, pp. 130-147.
[6 ] Probir Roy, Md. Mejbah U Alam and Nishita Das, (2012),“ Heuristic based task scheduling in multiprocessor systems with genetic algorithm by choosing the eligible processor”, International Journal of Distributed and Parallel Systems (IJDPS) Vol.3, No.4.
[7 ] L.D. Davis (Ed.), The Handbook of Genetic Algorithms, New York, Van N. Reinhold, 1991.
[8 ] D.E. Goldberg, Genetic Algorithms in Search, Optimization and Machine Learning, Addison-Wesley, Reading, Mass., 1989. [9 ] R. Tanese, “Parallel Genetic Algorithm for a Hypercube,” Proc. Int’l
Conf. on Genetic Algorithms, 1987, pp. 177-183.
[10 ]“Distributed Genetic Algorithms,” Proc. Int’l Conf. Genetic Alg., 1989, pp. 434-439.
[11 ]M. Srinivas and L.M. Patnaik, “Adaptive Probabilities of Crossover and Mutation in Genetic Algorithms,” IEEE Trans. Sys., Man and Cybernetics, vol. 24, no. 4, Apr. 1994, pp. 656-667.