Data Integration
Volume 2–Data Federation and EII
an evaluation and comparison
Data Integration
Volume 2–Data Federation and EII
an evaluation and comparison
Author: Philip Howard
Published July 2004 by Bloor Research Challenge House, Sherwood Drive, Bletchley,
Milton Keynes, MK3 6DP, United Kingdom Tel: +44 (0)1908 625100, Fax: +44 (0)1908 625124
Email: [email protected] Web site: www.bloor-research.com
Copyright Bloor Research 2004.
All rights reserved. No part of this publication may be reproduced by any means whatsoever, without the prior written consent of Bloor Research
Production: Brian Smithson ISBN 1– 874160 0150 – 69 – 4
“For years we lived anyhow with one another in the naked desert, under the
indifferent heaven. By day the hot sun fermented us; and we were dizzied by
the beating wind. At night we were stained by dew, and shamed into pe�iness
by the innumerable silences of stars.”
Contents
© Bloor Research 2004 Page i
Contents
Introduction
Introduction . . . 3
This report . . . 4
Report contents . . . 5
Bloor Research reports . . . 6
Acknowledgements . . . 7
Market Issues
Introduction . . . 11The requirement for Data Federation . . . 11
The evolution of the Data Federation market . . . 12
The Vendors . . . 16 Conclusion . . . 24
Technical Issues
Introduction . . . 27 Developer Services . . . 27 Integration Services . . . 29 Federation Services . . . 32 Conclusion . . . 36Product reviews
Introduction . . . 39Attunity Data Integration Connect, Stream and Federate . . . 40
Fast facts . . . 40 Key findings . . . 40 Bottom Line . . . 41 Vendor Information . . . 42 Background information . . . 42 Product availability . . . 42 Financial Results . . . 43 Product Description . . . 44 Introduction . . . 44 Architecture . . . 44 Data Connectivity . . . 45 Query Processing . . . 45
Contents
Page ii © Bloor Research 2004
Federation . . . 46 Attunity Studio . . . 47 Attunity Stream . . . 48 Summary . . . 48 Avaki 5.0 . . . 49 Fast facts . . . 49 Key findings . . . 49
The bottom line . . . 50
Vendor information . . . 51 Background information . . . 51 Product availability . . . 51 Financial results . . . 51 Product description . . . 53 Introduction . . . 53 Architecture . . . 54 Back-end integration . . . 54 Application development . . . 55 Integration framework . . . 56 Summary . . . 57
BEA Liquid Data for WebLogic . . . 58
Fast facts . . . 58
Key findings . . . 58
The bottom line . . . 59
Vendor information . . . 60 Background information . . . 60 Product availability . . . 60 Financial results . . . 61 Product description . . . 62 Introduction . . . 62 Data connectors . . . 62
Data View Builder . . . 62
Query Repository . . . 64
Distributed query engine . . . 64
Deployment options . . . 64
Administration Console . . . 65
Contents
© Bloor Research 2004 Page iii
cdeSolutions RESolution . . . 66
Fast facts . . . 66
Key findings . . . 66
The bottom line . . . 67
Vendor information . . . 68 Background information . . . 68 Product availability . . . 68 Financial results . . . 68 Product description . . . 70 Introduction . . . 70 Architecture . . . 70 Queries . . . 71 Processes . . . 71 Taxonomy Repository . . . 72 Administration . . . 73 Summary . . . 73
DataMirror Data Integration . . . 74
Fast facts . . . 74
Key findings . . . 74
The bottom line . . . 75
Vendor information . . . 76 Background information . . . 76 Product availability . . . 76 Financial results . . . 77 Product description . . . 78 Introduction . . . 78 Transformation Server . . . 78 DB/XML Transform . . . 79 Constellar Hub . . . 80 DataMirror iFederate . . . 80 DataMirror LiveAudit . . . 81 Summary . . . 82 DB2 Information Integrator . . . 83 Fast facts . . . 83 Key findings . . . 83
Contents
Page iv © Bloor Research 2004
Background information . . . 86
Business background . . . 86
Technology background . . . 87
Product availability . . . 88
Federated Data Server . . . 90
VeniceBridge integration . . . 91
Defining views . . . 91
Mediated schema support . . . 92
Building Queries . . . 92
Query optimisation . . . 93
Search . . . 95
Replication Server . . . 96
Summary . . . 98
Ipedo XML Intelligence Platform . . . 99
Fast facts . . . 99
Key findings . . . 99
The bottom line . . . 100
Vendor Information . . . 101 Background Information . . . 101 Product availability . . . 101 Financial Background . . . 101 Product Information . . . 102 Introduction . . . 102 Architecture . . . 102
Ipedo Integration Manager . . . 103
Ipedo XML Database . . . 105
Ipedo Assembly Manager . . . 106
XBRL Accelerator . . . 107
Summary . . . 108
iWay Enterprise Integration (ETL Manager) . . . 109
Fast facts . . . 109
Key findings . . . 109
The bottom line . . . 110
Vendor Information . . . 111
Background information . . . 111
Product availability . . . 111
Contents
© Bloor Research 2004 Page v
Product Information . . . 113
Introduction . . . 113
Architecture . . . 113
iWay Adapters . . . 113
Data Federation . . . 114
iWay ETL Manager . . . 115
iWay XML Transformation Engine . . . 117
Summary . . . 118
MetaMatrix 4.0 . . . 119
Fast facts . . . 119
Key findings . . . 119
The bottom line . . . 120
Vendor information . . . 122 Background information . . . 122 Product availability . . . 122 Financial results . . . 123 Product description . . . 124 Introduction . . . 124
The MetaMatrix Repository solution . . . 124
MetaMatrix Federation solutions . . . 126
Reference Data Management . . . 129
Summary . . . 129
Sagent Data Flow . . . 131
Fast facts . . . 131
Key findings . . . 131
The bottom line . . . 132
Vendor Information . . . 133 Background information . . . 133 Product availability . . . 133 Financial results . . . 134 Product Information . . . 135 Introduction . . . 135 Architecture . . . 136 Development . . . 137 Deployment . . . 138 Business Intelligence . . . 138 Summary . . . 139
Contents
Page vi © Bloor Research 2004
Supplementary product reviews
Introduction . . . 143
Actuate Enterprise Reporting Solutions . . . 145
Fast facts . . . 145
Key findings . . . 145
The bottom line . . . 146
Vendor information . . . 147 Background information . . . 147 Product availability . . . 147 Financial results . . . 148 Product description . . . 149 Architecture . . . 149
Actuate e.Reports and Actuate Query . . . 149
Actuate e.Spreadsheet . . . 151
Actuate Analytics . . . 152
Product futures . . . 153
Summary . . . 153
Corigin Data Sharing Suite . . . 154
Fast facts . . . 154
Key findings . . . 154
The bottom line . . . 155
Vendor Information . . . 156
Background information . . . 156
Product availability & Support Commitment . . . 156
Financial results . . . 156
Product description . . . 157
Introduction . . . 157
Corigin Extractor . . . 158
Corigin Migrator . . . 159
Corigin Change Propagator . . . 159
Mainframe operations . . . 160
Summary . . . 160
Hummingbird BI 8.5 . . . 161
Fast facts . . . 161
Contents
© Bloor Research 2004 Page vii
The bottom line . . . 162
Vendor information . . . 163 Background information . . . 163 Product availability . . . 163 Financial results . . . 164 Product description . . . 166 Introduction . . . 166 BI Server . . . 166 BI Query . . . 167 BI Web . . . 168 BI Analyze . . . 168 Summary . . . 168 Venetica VeniceBridge . . . 170 Fast facts . . . 170 Key findings . . . 170
The bottom line . . . 171
Vendor information . . . 172 Background information . . . 172 Product availability . . . 172 Financial results . . . 173 Product description . . . 174 Introduction . . . 174 Architecture . . . 174 Developer services . . . 175 Federation services . . . 175 Integration services . . . 176
VeniceBridge Wrapper for IBM DB2 Information Integrator . . . 176
DB2 II connection to VeniceBridge . . . 177
Summary . . . 178
Product evaluations and comparisons
Introduction . . . 181The Major Ratings . . . 181
The Minor Ratings . . . 182
The Scores . . . 182
Contents
Page viii © Bloor Research 2004
Winners and Losers
Introduction . . . 191 About the author . . . 192
Index
In
tr
od
uc
tio
n
1
Introduction
© Bloor Research 2004 Page 3
Introduction
This report is published in two volumes. The second volume, this one, is con-cerned with data federation, and the first volume considered data movement. This poses a number of questions, which we need to resolve before going on to discuss the contents of this report in more detail:
1. What do we mean by data integration? By data integration we mean any environment that requires data from one or more sources to be combined in one or more places. There are therefore a number of different potential scenarios:
» Single source–single target: a typical example would be migrating from one database to another.
» Single source–multiple targets: an instance when you might require this would be if you were moving from a centralised implementation to a distributed one.
» Multiple sources–single target: the classic example would be loading a data warehouse. Another would be the consolidation of multiple ap-plications or databases.
» Multiple sources–multiple targets: for example, where you have a number of queries that need to access multiple back-end data sources. 2. How does it differ from application integration? Data integration differs
from EAI (enterprise application integration) in a number of respects. First, EAI (leaving aside its process oriented facilities) links applications to applications or data to applications, while data integration links applica-tions to data or data to data. Secondly, EAI is essentially record-at-a-time processing, while data integration involves sets of records. Of course, a set of records may be just a single record but the reverse is not true. Thirdly, EAI is essentially a push mechanism while data integration predominantly uses pull technology. That is, an application within an EAI environment sends data to another application. Using data integration, on the other hand, data is requested from a source environment. Again, this is not en-tirely true, as capturing changed data from a database is a push-based ap-proach that can be used within a data integration environment. However, from a logical perspective this can be treated as an ‘always on’ request. Replication is a similar exception that is included in some data integration environments.
3. What do we mean by data movement? There are, potentially, two ways to provide data integration. One of these is to physically move the data from all the relevant original sources. Alternatively, you can leave the data in situ and query it where it is. The former approach is data movement while the latter is data federation.
Data Integration, Volume 2
Page 4 © Bloor Research 2004
4. How does it differ from ETL (extract, transform and load)? ETL has tra-ditionally been associated with moving data into a data warehouse or, more generically, into a database. However, data movement is a much broader church than this, supporting such things as data synchronisation between ERP implementations, for example. While each of the elements of E, T and L apply to all of these environments they are frequently used in a dif-ferent order (perhaps TEL or ELT) but, even where they aren’t, it is useful to make a distinction between ETL in the traditional sense and the broader data movement products we see today.
This is for two reasons: first, data integration products in this area are in-creasingly offering extended data quality capabilities (see the recent Bloor
Research report: Data Quality Products: An Evaluation and Comparison) such
as data profiling and/or data cleansing that go beyond mere ETL and, sec-ondly, because the market is fragmenting along these lines with database vendors increasingly offering their own ETL capabilities (but which are lim-ited to ‘multiple sources–my database’) and independent suppliers offering products with a greater breadth of features.
5. What do we mean by data federation? This is the alternative approach to data integration, where you do not physically move the data but leave it in situ. Of course, in a sense, you move the data during the process of answering a query, but the point is that it is not stored directly, though it might be cached and the user might decide to store the retrieved information for later reuse or for off-line working, but that is not an intrinsic part of the process. 6. How does data federation differ from information integration? EII
(enter-prise information integration) is frequently used to describe this ability to access data from heterogeneous sources and then combine the results in order to present the results to some originating query. Essentially, the dif-ference between data federation and EII is that the latter includes the query environment while the former does not. In other words, a data federation platform is independent of the query environment that employs it, while an EII solution combines both technologies. Some of the latter will be propri-etary. Another potential difference is that some products support update as well as query, while others do not. However, we do not believe that this is the main difference between data federation and EII.
This report
This report focuses exclusively on data federation. However, some of the prod-ucts included in this report are not exclusively data federation prodprod-ucts. For ex-ample, Group 1’s product (formerly Sagent) provides both data movement and data federation capabilities, while Avaki provides both a data federation platform and facilities to integrate third party data movement and data quality products into the Avaki environment.
Where extended facilities are provided, product reviews are comprehensive, but the evaluation and comparison of products is limited to the features that are
rel-Introduction
© Bloor Research 2004 Page 5
evant to each report. Thus the Group 1 review, which appears in both Volume 1 and Volume 2 of this report, is only considered with respect to its data federation capabilities in this volume, and only with regard to its data movement features in Volume 1. We will, of course, highlight the fact that any complementary capabili-ties are available, because the advantages of having a single platform to support a broader range of requirements are obviously significant.
In addition, there are four products reviewed in this report that are not, or at least not primarily, data federation products at all. The Actuate and Hummingbird product reviews included here are business intelligence products that have some (more or less as the case may be) federated query capabilities built into them, while Corigin’s product represents a complementary technology that reduces the per-formance impact of federated queries on mainframe systems. As we will discuss in Chapter 3, there are potential performance problems associated with accessing production systems for federated query purposes and Corgin provides one way of overcoming these problems, at least in a mainframe environment. Finally, Ve-netica’s VeniceBridge is also complementary but in this case it is actually a feder-ated product. However, it provides content federation rather than data federation. Notably, Venetica is a partner of IBM’s for DB2 Information Integrator.
Report contents
The six chapters in this report deal with the following topics:
Chapter 1: Introduction is this chapter.
Chapter 2: Market Issues discusses the way that the market is developing in
gen-eral terms and then considers the various vendors whose products are reviewed in this report, with respect to their position in the market and how they are targeting it. A number of other vendors within the market are also briefly referenced within this Chapter.
Chapter 3: Technical Issues considers the various technology issues that arise
within the data federation arena. In general, we tend to focus on those aspects of the technology where there are significant differences between the various products, as opposed to areas where there is common functionality. However, the data federation market is sufficiently diverse that there are few such areas of com-mon ground. The issues discussed in this chapter form the basis of our product comparisons in Chapters 5 and 6.
Chapters 4 and 5: Product Reviews. This chapter includes detailed reviews of
the following data federation and EII products: Attunity Federate (previously At-tunity Data Connect), Avaki 5.0, BEA Liquid Data for WebLogic, cdeSolutions RESolution, DataMirror Data Integration (including iFederate), IBM DB2 Infor-mation Integrator, Ipedo XML Intelligence Platform, iWay Enterprise Integra-tion, MetaMatrix 4.0, and Sagent Data Flow (from Group 1 Software, shortly to become part of Pitney Bowes). Where a vendor has a product set that includes additional capabilities that are marketed as a suite (for example, combined with ETL capabilities) then the whole suite is reviewed, not just its data federation
Data Integration, Volume 2
Page 6 © Bloor Research 2004
functionality. The non-data federation elements of the product are not, however, considered in Chapter 5.
In addition to the products detailed in the previous paragraph, two business intel-ligence suites that include federated query capabilities are included here, namely Actuate Enterprise Reporting Solutions and Hummingbird BI 8.5; as well as the complementary Corigin Data Sharing Suite and Venetica VeniceBridge. These products are not, however, included within the evaluation and comparisons that appear in Chapters 5 and 6 and nor are these products considered in Chapter 2, though there is a generic discussion of the use of federated query capability by business intelligence suppliers, with these two products used as exemplars. Each product review is what might be termed a ‘vanilla’ review. That is, each prod-uct is considered in its own terms, with respect to the market(s) that it addresses, rather than in comparison with other products. The reason for this is that while products frequently overlap in their target markets, there are also often areas which one addresses and another does not. Moreover, some vendors tend to adopt a strategy that heavily relies on industry partnerships, while other suppliers may have few or none of these, and may instead aim to offer a complete, integrated solution. While one approach may be preferred to the other in particular instances it would be invidious to suggest that one was better than another in general terms. For this reason there is no scoring and there are no marks associated with these products as a part of these reviews (these are included in Chapter 6). This would, again, be unfair as the use of partnerships or not would heavily prejudice the results. For the same reason, we no longer publish questionnaires as a part of our evaluation reports, for the simple reason that a questionnaire cannot be all-encompassing and anything short of that effectively blinkers any evaluation by as-suming that products fit within the particular box defined by the questionnaire.
Chapter 6: Data Federation product comparisons, evaluates the reviewed
prod-ucts (pure data federation prodprod-ucts only) against one another, with respect to the issues discussed in Chapter 3.
Chapter 7: Winners and Losers, provides details of those evaluated products that
we consider the best or worst in their sector.
Readers may discover that some of the concepts in the report are explained in more than one place. This is intentional; it is aimed at assisting those who wish to use the report as a reference work. However, we have attempted to keep repetition to a minimum, so that the report can be read from cover to cover, without causing irritation to the reader. Please note that all the research involved in producing this report was of an independent nature and was entirely funded by Bloor Research.
Bloor Research reports
Our reports form part of an information service that is aimed at providing cor-porate IT departments with high quality information, whether in electronic or printed format.
Introduction
© Bloor Research 2004 Page 7
To produce our reports we depend upon a number of information sources. These include the vendors themselves and our consultancy clients. We welcome feed-back from readers on the contents of our reports.
There is a limit to the number of products that can be covered by a report of this nature. However, we also provide a separate product evaluation service to our customers. This service also includes product re-evaluations when major new releases become available.
Acknowledgements
We would like to thank the vendors for their kind co-operation as well as those of our clients whose experience we were able to draw on. We also acknowledge the contribution of our publishing staff, who play a large part in defining the style and maintaining the quality of our information products.
M
ar
ke
t I
ss
ue
s
2
Market Issues
© Bloor Research 2004 Page 11
Introduction
The market for data federation is immature. This is easily demonstrated. First, there are more and more vendors entering the market, on an accelerating basis. Secondly, we are already beginning to see the signs of all sorts of sup-pliers claiming federated capability when they don’t really have them, or not much. Third, you haven’t heard of most of the vendors in the marketplace and, even where you have, this is often because they have acquired the tech-nology from someone that was previously more or less unknown. Fourth, the market is being penetrated by suppliers coming from a variety of differ-ent original technologies: reusing repositories or databases or whatever and then re-purposing them or, to be fair, in some instances there are companies developing purpose-built technology. Finally, there are all sorts of different approaches being offered to support federated queries. This strongly suggests that there is no consensus as to the best way forward. Indeed, while all the main products that are reviewed in this report are ostensibly competitors, they are also regarded, in some instances, as being complementary. For example, both cdeSolutions and Avaki are IBM partners, whose solutions may be im-plemented alongside DB2 Information Integrator.
The long and the short of it is that the market is confused. While there is a general acceptance that there is a significant and growing market for data federa-tion there is no agreement as to the best approach to take for providing such a solution. However, that debate is primarily concerned with the best technical approaches to be taken, which forms part of the subject matter for Chapter 3 of this report. Here we need to consider the requirement for data federation and EII (the distinction between these having been defined in the previous chapter), and how we believe that the data federation market will evolve, prior to discussing the individual market positions of the various vendors.
The requirement for Data Federation
The need for data federation is easily stated. There are occasions when you need access to production data that exists in multiple systems. For example, you might want to look at the complete state of a customer account, but that customer might do business with multiple divisions within the enterprise in multiple geog-raphies. Now, if you only need that information as of the end of last month then you can pull it out of a data warehouse or data mart. However, if you want an up-to-date picture of that relationship then you will need to address your production systems in real-time, which is where federated query capability comes in: you want to be able to access multiple production systems that exist in diverse application environments on heterogeneous databases and platforms, in real-time.
Another such environment, and one which is becoming increasingly common, is real-time dashboards and scorecards that are provided to support corporate per-formance management. If the metrics and key perper-formance indicators in these systems are to be genuinely real-time then, by definition, the source data will need to be derived form production systems in a live manner.
Data Integration, Volume 2
Page 12 © Bloor Research 2004
Note, however, that federated queries may not be limited to application environ-ments and relational databases. You might also want to retrieve data from legacy non-relational databases and flat file systems; you might want to incorporate in-formation collected via the Web; and you might want to include data derived from spreadsheets or other productivity tools. In theory, therefore, the federated environment should allow access to any sort of relevant data.
Further, once you have this access it makes sense to be able to write back to the source environment(s) where that is appropriate, and a number of the data fed-eration providers in this report allow that facility.
The evolution of the Data Federation market
While we cannot yet know the technologies and approaches that the market will determine are most suitable for data federation (and, in any case, that is a discus-sion for Chapter 3), we can make some predictions about the directions of the market itself. We believe that there will be two aspects to this: with respect to business intelligence suppliers on the one hand, and with regard to other data integration technologies on the other.
We will start by considering the likely role of business intelligence providers. We have included two of these in this report: Hummingbird and Actuate. The former provides limited but nevertheless useful federated query capability while the latter does not currently offer federation capability at all, at least at the time of compil-ing this report. However, it is Actuate that is most interestcompil-ing. In 2003 it bought a company called Nimble which, had it remained independent, would have ap-peared in this report under its own name. That is, it was a significant data federa-tion specialist. Actuate acquired the company and is in the process of integrating the Nimble technology into its own product set. This will be available in the next major release of Actuate, which is scheduled for general availability in July 2004. What is interesting about what Actuate is doing with Nimble is that it is no longer marketing the product as a stand-alone capability but is using it purely to provide federated capabilities within its own environment. The company clearly sees this as a differentiator between its product set and those of companies such as Business Objects, SAS and Cognos.
The question therefore arises as to whether those companies will allow Actuate to have the federated query market to itself, relying instead on platform providers such as those evaluated in this report, or whether they will introduce their own federated query capabilities? We believe that the latter is more likely to be the case.
However, this poses a further issue. All of the vendors mentioned have their own ETL tools, so will they extend these capabilities to support data federation or will they embed relevant facilities within the business intelligence tools themselves? Either approach is plausible and it may be that different vendors will opt for different ap-proaches, possibly depending on the extent to which the suppliers see ETL as a stand-alone market as opposed to simply a supporting tool for their business intelligence solutions. At present, Cognos and Business Objects, in particular, only see ETL in this
Market Issues
© Bloor Research 2004 Page 13
light so they are likely to follow Actuate’s route. SAS is in a slightly different position because it could market its ETL product through its independent DataFlux subsidiary. What does seem clear is that in the business intelligence space, a significant proportion of the market will leave ETL as it is and implement federation within the BI environ-ment, rather than the other way round.
Development of the Data Integration market
It is now appropriate to consider how we believe that data federation will evolve in terms of the wider data integration market as a whole. In order to do that, we first need to go back to first principles.
The original products that populated what is now the data integration space were designed to provide ETL capabilities and they were specifically targeted at data warehousing and similar environments. Aside from technical arguments about the best way to achieve the movement of data into a warehouse or data mart, there was a consensus about the target market for this technology. In particular, it was a market that required the ongoing movement of data on a scheduled basis, in batch mode.
However, the world moves on and it has become increasingly apparent that there are a lot of other situations in which you would like to move data from one place to another. However, this is very often a one-off process. For example, you might want to populate the database for a new application with existing data. Once you have done that the job is done, at least as far as the end user is concerned. While there might be a market for selling an appropriate tool on an OEM basis to the vendor of the application, or as an ASP-based service, it is hardly surprising that the mid-market, which does not typically have big data warehouse implementa-tions, has not been able to afford such soluimplementa-tions, and has resorted to hand coding. However, there are now a number of vendors directly addressing this market with low total cost of ownership solutions.
Perhaps even more important as a driver of the move towards broader data inte-gration product suites is the action of the database vendors. Oracle, and especially Microsoft, have embedded ETL capabilities into their databases. It is clear that these vendors view ETL as a function of the database that will encourage users to adopt their platform. It is therefore likely that in the fullness of time the use of these facilities will become the obvious way to move data, for whatever purpose, into either an Oracle or SQL server database respectively. All other things being equal, this would obviously have a nasty knock-on effect for the major data inte-gration vendors if all they did was to continue to provide simple ETL capabilities. Thus they have broadened their offerings in order to continue to provide differ-entiators when compared to these database-based facilities.
However, there is only limited scope for extending the capabilities of ETL tools in terms of data movement per se. Certainly you can add real-time capabilities and you can add support for more sources and targets, but the intrinsic functionality of data movement remains essentially the same. For this reason, the leading ven-dors in the market, certainly at the high end, have pinned their faith in extending their products into increased support for data quality tools, either directly by pro-viding these products themselves, or through close integration with third parties.
Data Integration, Volume 2
Page 14 © Bloor Research 2004
This extension makes a lot of sense. One of the biggest causes of failures in data integration projects is inaccurate and invalid data, and you need data profil-ing and cleansprofil-ing tools to identify the problems and repair them. So, this is the direction that a number of the vendors have gone in. However, it is not the only possibility.
Data Movement and Federation
The question arises as to whether it is feasible to consider the merging of data movement and data federation. Let’s start by considering the synergies: both tech-nologies need access to diverse data sources both legacy and modern, relational and non-relational; increasingly (in the case of ETL), they both need access to real-time data; they both need to be able to perform transformations against the data they are retrieving; and they both need the facilities of data profiling and data cleansing to ensure that the data itself is in a fit state to process.
In other words, data federation and data movement products use the same con-nectors and the same ancillary tools, and they access the same data sources in the same ways. The only real differences between data federation and data movement are that the procedures involved in the former always take place in real-time (even if the data itself may not be that up-to-date) whereas that is only sometimes the case for data movement; and that data federation typically delivers its results to a target application, while data movement is usually addressed at physical targets or, possibly, message queues. Conversely, data federation retrieves information from data sources. While data movement does this too, products in this space tend to have strengths in understanding ERP and similar applications, which data federa-tion products do not (or may not) have.
There is one final difference: ETL tools move the data and data federation products don’t. That is, ostensibly, the big difference between them. However, it’s not true. There are lots of ETL vendors (SAS, GoldenGate and Hummingbird to name just three), that allow you to process data on the source before ‘extracting’ it. If that means processing the joins that you need for your query then how does it differ from data federation? Further, the proof of the pudding is in the eating: Group 1 specifically offers a product that provides both ETL and data federation.
In other words, data movement is potentially a superset of data federation.
Data Federation and EAI
As we have previously discussed, data federation solutions offer an open platform that support heterogeneous queries that are independent of the construction of those queries, while EII (enterprise information integration) includes a specific query envi-ronment and, typically, a proprietary platform. Both envienvi-ronments may or may not offer update as well as query capabilities across multiple data sources.
Consider the major distinguishing feature that separates EAI and data federa-tion. It is not that one is application to application and the other is application to data source. After all, a data federation solution can pass a result set to a message queue as easily it can to an application. Nor is it that one is a push technology (EAI) and the other (data federation) is a pull technology. This is because, actually, data federation products often include data replication capability. For example,
Market Issues
© Bloor Research 2004 Page 15
IBM’s DB2 Information Integrator includes both replication and federation ca-pabilities. Even without replication, change data capture is a commonly used push mechanism implemented within data federation (and data movement) products. No, the real difference between EAI and data federation is that the former is transaction oriented while the latter is not. More specifically, EAI is record-based and data federation is set-based. However, a record is simply a very small set. In other words it is a simple extension for a data federation vendor to extend its capabilities to support EAI. Conversely, to extend an EAI solution to provide set-based processing would require a major re-design of the product. Thus any movement can only be one way.
Of course, this isn’t the whole story. There are a variety of facilities that you would expect to see in an EAI environment that will not necessarily be in any current data federation product. But none of these features amount to rocket science and, in any case, data federation is a much newer discipline than EAI and we would expect it to take a little while to catch up, let alone overtake its bigger brother.
Again, the proof of the pudding can be demonstrated: iWay offers limited EAI capabilities as well as EII and IBM has announced that its next release of DB2 Information Integrator will include EAI capabilities. DataMirror is also in this market already.
Data Movement and EAI
There are advantages in moving towards EAI directly from data movement and without data federation as an intermediate step. For example, Ascential is in-tegrating its Mercator acquisition into its data movement platform and, while Mercator used to be thought of as belonging to the EAI space, Ascential has it clearly pegged out as being within the data integration space—so dividing lines are moot. A more concrete example is Pervasive, which offers a single platform that supports both data movement and EAI but not (yet) data federation. One of the reasons why this might be a more realistic approach is that the ERP connection capabilities provided by ETL vendors are easily reusable within an EAI environment, whereas there is less requirement for these within data federa-tion, though they are supported by companies such as Avaki.
Conclusion
Exactly how it will come about remains moot, but we believe that data movement, data federation and EAI will merge to become different applications of a single entity which, for the sake of argument, we may as well call data integration. Also included within this catch-all platform will be the necessary data quality tools to support the whole integrated environment. As we discussed in Volume 1 of this report, the major pre-requisite for such a solution is an integrated metadata solu-tion, which some vendors have now introduced but towards which others are still struggling.
However, with a few exceptions (notably IBM, DataMirror and Avaki) the drive toward the merger of these technologies is coming from the data movement ven-Caveat on EAI
In these discussions we are using EAI in its historical sense: that of being able to move data between applications. Today, EAI has moved beyond that capa-bility and, in particular, it is increasingly seen as an environment within which you manage business processes. As a result, service oriented architectures and sup-port for Web services are now de rigueur in EAI products.
However, many users continue to require only the connectivity and message pass-ing facilities that were traditionally provid-ed by EAI products, and do not neprovid-ed busi-ness process management and workflow. As a result, a split has occurred within the EAI market, with a new class of product called an Enterprise Service Bus (ESB), specifically designed to cater for that part of the market that only requires traditional EAI facilities. It is this sector that we are describing when we refer to EAI in the dis-cussions in this report.
Data Integration, Volume 2
Page 16 © Bloor Research 2004
dors rather than the data federation suppliers. This poses a potential threat to the pure players in the data federation space. If companies like Informatica and As-cential, not to mention the business intelligence vendors, were to follow this path, then the data federation suppliers are going to find themselves under increasing competitive pressure. Of course it is common in emerging markets that the pure players spring up, thrive for a while, and then get acquired or go out of business. This is no less likely to occur in the space under discussion than it is in any other market: the fun is in trying to predict the companies that will thrive and survive.
The Vendors
Now that we have some idea of the direction in which the market is headed, it is time to turn our attention to the individual vendors and discuss what they are doing specifically. However, before we do that, it is worth briefly mentioning some of the vendors in the market whose products we have not reviewed. These include Composite Software, Journee, XAware, Decision Support, Global IDs, the Tukwila Data Integration System, Trustgenix, and the Denodo Data Integra-tion Platform, amongst others. Arguably, you could also include semantic systems such as those of Network Inference and Unicorn (which is a partner of IBM’s for DB2 Information Integrator), which also have facilities in this area.
Why have we not included these here? For several reasons: first, these vendors are typically limited to a single country (though that also applies to some of the prod-ucts we have included); secondly, many of them are relatively new entrants to the market (in some cases less than 6 months); and third, we have excluded semantic systems since they are based on even newer technology than data federation and, in any case, they are not primarily aimed at this market. However, the main reason is that we had to have a cut off point somewhere and the companies mentioned above just got unlucky.
Note that in the discussions of the various vendors below, we have omitted con-sideration of the market position of Actuate and Hummingbird, as these have already been covered. Corigin and Venetica both provide solutions to particular technical issues within the federation market and they are therefore discussed in Chapter 3.
Attunity
Attunity originally started as an Israeli company in the late 80s, but it now has its headquarters in the United States, though R&D remains in Israel. It started life as a vendor of connectivity solutions and, in particular, it provides facilities such as the ability to present legacy mainframe resources in relational format. It is also one of the few vendors to provide change data capture. That is, its connectors can monitor a relevant database log and it can propa-gate changes to the log as they are committed. Thus, unless you are using deferred commits, it provides real-time data capture capabilities. This market has historically been dominated by Striva but that company was bought by Informatica in 2003 and a number of Striva’s partners (Cognos, Business Objects, Hummingbird and others) have been looking for an alternative pro-vider. As iWay is also a competitor to these vendors (via its parent company,
Market Issues
© Bloor Research 2004 Page 17
Information Builders) and CrossAccess has been acquired by IBM, Attunity has gained significantly as a result.
As far as data federation is concerned, the Attunity product (whose name has recently been changed to Attunity Federate) utilises the company’s connectiv-ity products and otherwise is based on a virtual database (sometimes called a mediated database). It uses agent-based technology whereby agents know about the systems that they are running on, including the local optimiser, so that the environment is optimised even for distributed joins. The product also supports two-phase commit and can impose that even when it is not implemented on the source system.
Historically the company was primarily focused on direct sales but it is now in-creasingly working on channel partnerships. While Attunity has distributors in countries around the world it also has a number of significant partnerships in-cluding OEM licensing agreements with Oracle—to support open connectivity to that company’s database products and mainframe connectivity to its applica-tion server, HP—to provide open connectivity to the OpenVMS platform, and IDX—to provide standard reporting to HP NonStop data sources, as well as oth-ers including Attachmate and Corigin. Further, Attunity has recently announced a partnership with Cognos, and the company expects to be announcing additional partnerships with business intelligence companies in the near future.
Avaki
Avaki (which is a French Polynesian word meaning shared resources) originally derived from research done at the University of Virginia into distributed com-puting architectures. With the company only having been founded in 2000, this means that the product is based on grid computing and a service oriented archi-tecture. Thus, there is no mediated database in Avaki and, instead, the company provides a ‘data service layer’. In theory, the provision of data as a service could be done without recourse to Web Services but, in practice, this is how an Avaki environment is normally implemented.
In practice, what the use of a data service means is that Avaki stores not just the metadata that describes source data but also the mechanisms required to access that data. For example, in the case of relational data this might mean storing a relevant SQL statement or a pointer to a stored procedure. There are comparable API-based facilities for retrieving data from application environments such as ERP systems. This is provided to the Avaki environment by the owner of the data and there is therefore a strong element of security built into the product, though the downside to that arrangement is the involvement of data owners. Transformation facilities are built into the Avaki environment and you can use third party XML-based tools (the company has a partnership with Altova) for defining mappings from multiple sources. There are also some built-in SQL facili-ties and view generation capabilifacili-ties. Updates are supported but not two-phase commit at present.
In addition to supporting data federation, Avaki can also be used as a platform for integrating other solutions. For example, you can plug ETL tools into the Avaki environment. This will be useful when you want to use data movement in
Data Integration, Volume 2
Page 18 © Bloor Research 2004
conjunction with data federation but it doesn’t really provide a truly integrated capability since the products will still have separate repositories and so forth. Avaki primarily markets its product through a direct sales force within the United States. In other countries it is reliant on its reseller agreements with IBM, HP and Sun. The first of these is particularly interesting because of IBM’s own data federation offering. The two products are seen as being complementary in some cases, because Avaki offers a broader platform-level solution (for example, it ena-bles access to WAN-based files), whereas DB2 II is more specific.
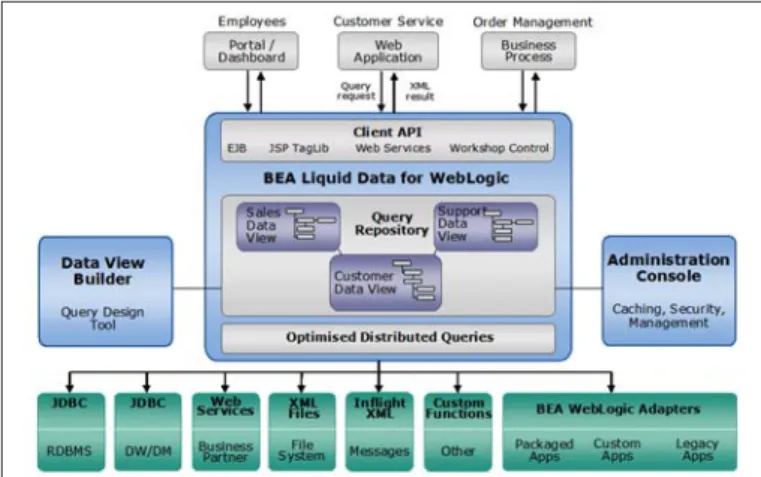
BEA
Liquid Data for WebLogic is one of a suite of integration products available from BEA, where the other two products in the set are WebLogic Portal and WebLogic Integration, where the latter provides process-level integration. The advantage of this approach is that there is a single development tool (WebLogic Workshop) for all three environments and, of course, they all run on the same application server.
Liquid Data in fact derives from two original products: the company’s own in-ternal developments and the Enosys distributed query engine. Enosys was a data federation vendor in its own right until BEA bought it, though the engine was previously OEMed by BEA.
The product uses a mediated schema approach (that is, you build one or more virtual schemas and then define particular views against that schema which sup-port the various queries that you require) but, unlike vendors such as Attunity, it is all XML-based. Thus, whereas Attunity allows you to build queries using SQL, BEA uses XQuery, though the use of WebLogic Workshop will nor-mally mean that this is invisible (though developers can get at the code if they really want to).
cdeSolutions
cdeSolutions is a relatively small, UK-based company, whose RES-olution product was first introduced in 2003. It is notable for a number of reasons. First, from a financial point of view it is unusu-ally small for a publicly quoted company. Moreover, it is not quoted in its own name but within a shell company called Enition, which was floated in January 2004. This does mean, however, that the company is well funded.
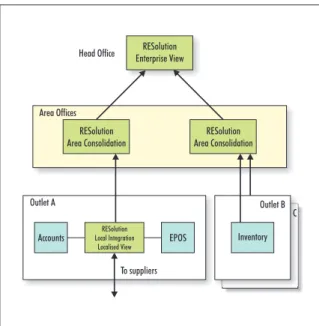
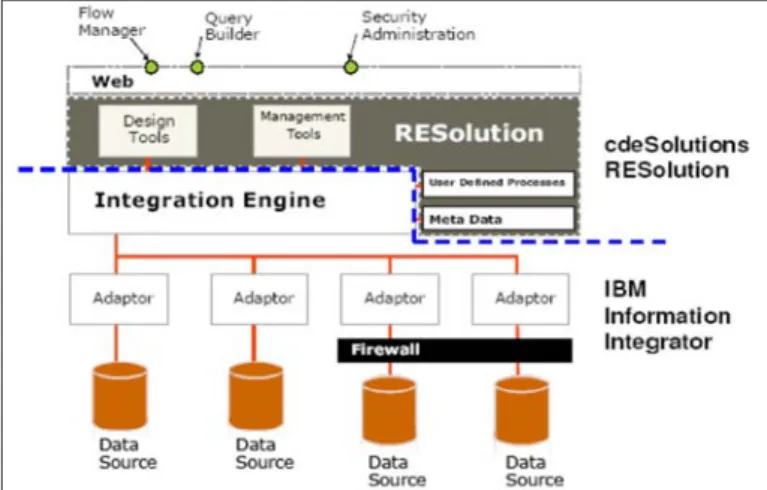
Secondly, RESolution is not just a data federation product but an EII product, in that it includes its own query environment. Further, it is only marketed as providing data federation within relatively limited environments. For larger, enterprise-level solutions it part-ners with IBM and its DB2 II product, leaving DB2 II to provide federation capabilities, while RESolution provides end-user based query and data/process flow (another differentiator) capabilities. One of the interesting features of this approach is that it allows you to build solutions using multiple instances of RESolution, as illustrated in Figure 1.
RESolution Enterprise View
RESolution
Area Consolidation Area ConsolidationRESolution Head Office
Area Offices
Outlet A Outlet B
C
To suppliers
Accounts Local IntegrationRESolution EPOS Inventory
Localised View
Market Issues
© Bloor Research 2004 Page 19
A further difference between RESolution and other products in this space is that cdeSolutions does not actually market the product as an EII solution but as an Enterprise Compliance Platform. That is, it focuses on allowing you to build federated queries and reporting capabilities that can then be expressed using XBRL (XML business reporting language), which is why the architecture illustrated potentially makes sense. Note that cdeSolutions is one of the first companies to support XBRL, which is the mandated stand-ard (by the FSA and others) for financial reporting. In fact, the company’s claim is that it will sort out your cross-system reporting issues, and then you get compliance for free.
The danger for cdeSolutions is that it is heavily reliant on its partnership with IBM. In contrast to conventional business intelligence vendors (Business Objects et al) that partner with IBM, it offers a product that has been specifically designed for federated environments and, as we have mentioned, it also supports process capabilities that allow you to build in external capabilities. Nevertheless, the com-pany needs to establish its credentials relatively quickly if it is to carve out a long term position within the market.
DataMirror
DataMirror is a Canadian company that is a little over a decade old. It has grown both organically and through acquisition. In the latter case, this has occurred most notably through the purchases of Constellar in 2000 and, most recently, PointBase, the vendor of the eponymous small footprint database. However, as DataMirror had provided seed funding for PointBase and already owned a signifi-cant part of the business, this was a logical next step.
Historically, DataMirror has concentrated on real-time environments and its main product is called Transformation Server. This provides real-time, peer-to-peer (that is, with no intermediate staging), bi-directional data integration with built-in transformation and filterbuilt-ing capabilities. Complementary to this is iFederate, which is the company’s data federation solution and Constellar Hub, which is an EAI product. The company also provides a variety of other real-time solutions, notable LiveAudit and LiveResiliency.
Although iFederate uses a fairly standard mediated approach it differs from other data federation products in a number of ways. First, it runs directly on the mainframe (and only mainframes) and does not require an intermedi-ate server (though you may need this if iFederintermedi-ate is to be used in conjunc-tion with Transformaconjunc-tion Server); secondly, it enforces the materialisaconjunc-tion of views in batch mode, and you can then run queries against that view; thirdly, it does not use either SQL or XML for queries but the company’s own SQL-like language; and, finally, updates are not supported. There is a further comple-mentary product, DB/XML Transform, which you can use to support legacy databases such as Adabas, by converting their data into XML format, so that they can be addressed by iFederate. This product also supports such things as EDI messages, SWIFT and so forth.
DataMirror uses both a direct sales approach and it has a substantial reseller and distributor programme.
Data Integration, Volume 2
Page 20 © Bloor Research 2004
IBM
IBM’s provision of DB2 Information Integrator needs to be understood not only in its own terms, but also within the context of the database market as a whole. The major database vendors are split into two camps, with Oracle on one side and IBM, Sybase and Microsoft on the other. Oracle’s strategy is that, in general, the best approach to the multiple databases that exist within the enterprise is to consolidate into a large, centralised database. Oracle and IBM, on the other hand, contend that while this may be appropriate on occasions, the best general policy will be to leave those existing databases in place, and join them together to pro-vide a federated solution.
While most vendors have done little (to date) to provide sophisticated federa-tive capability, IBM is the exception. It originally introduced DB2 DataJoiner to provide this sort of capability, but this was dependent upon your having a DB2 implementation in the first place. DB2 Information Integration (DB2 II), on the other hand, is a stand-alone product and does not require you to be a DB2 user. In fact, the product has its own implementation of DB2 embedded within it, but this is not normally visible to the user.
So, DB2 II is not merely a data federation product for its own sake, but is also part of a broader database strategy. As a technology it is view-based and does not require a mediated schema and, as one might expect from a relational database vendor, it uses SQL, although there are some substantial XML capabilities as well. However, there are a number of respects in which it differs significantly from other approaches. One is that it provides replication, a second is that it provides federated search capabilities, and a third is that, from the outset, IBM has wanted to be able to address a wide range of non-conventional sources. While IBM is by no means alone in this last respect, it is the only vendor that we are aware of that has made a specific point of wanting to be able to address content management systems. In part, no doubt, this is because it is the only data federation vendor in the market that also has its own content management solution. With the recent announcement of a partnership between IBM and Venetica, DB2 II can now ap-ply federated capabilities to all the leading content management solutions. Both Avaki and cdeSolutions, companies whose products are discussed in this report, are also partners of IBM, as is iWay (for connectors).
Ipedo
Ipedo, which is an acronym for Information Processing Environment for Dis-tributed Environments, was founded in 2000. Like IBM it has also built its data federation solution around a database but, in this case, it is an XML database and not a relational one. Moreover, the company does not market its database as a database per se, and it is wholly focused on the data federation market.
As indicated, Ipedo is XML-based although there are SQL facilities built into the product as well. It uses a view-based approach without a mediated schema and probably has the most advanced features of any product in terms of develop-ing these views, many of which are pre-built, and there are also View Wizards. It includes two-phase commit capabilities though these are not XA compliant. Again, like a number of other vendors, it has a variety of extended features: it uses its database for caching queries to provide better performance (a facility that
Market Issues
© Bloor Research 2004 Page 21
a number of other products offer) but you can also use it as a complete ODS (operational data store) if you want to. As one might expect, there are extended XML capabilities including the ability to translate between XML schemas and DTDs (document type definitions) and lazy schema evolution.
Ipedo uses a direct sales model and despite the fact that it is relatively new, it already has some prestigious customers such as Reuters, BT, Hewlett-Packard and Fidelity National Finance. It has offices in the United States and China and a distributor in the UK.
iWay
iWay, which is a subsidiary of Information Builders, approaches data integration from yet another direction, in the sense that iWay’s main goal is to sell its adapters and connectors. However, it does have the secondary goal of supporting Infor-mation Builders’ query and reporting capabilities and it is for this reason that its main product is called ETL Manager rather than something that suggests the wider capability that it actually has. However, this is also the result of conserva-tism: the product used to be called Copy Manager!
There are two main differences between iWay’s ETL Manager and most of its competitor’s products. The first is that iWay offers more adapters and connectors that any other vendor. This may not be immediately obvious because rival
ven-dors often claim a different adapter for Oracle 8, Oracle 8i, Oracle 9i, and so on,
and some even claim different adapters for different platforms. As far as iWay is concerned there is just a single Oracle adapter with, perhaps, multiple versions. The company’s basic philosophy is to connect anything to anything. So it supports not just conventional data sources and applications, but also message queues, message formats such as SWIFT and EDI, environments such as Tibco and Biz-Talk, and many others. It is not surprising therefore, that iWay offers both ETL and EAI capabilities, albeit that the EAI capability is relatively simplistic in that it wouldn’t support complex workflows. Moreover, it also supports federated query capability, so it arguably offers the most capable product set of any company in this report.
The second big difference is that the product has been built on top of the FOCUS 4GL tool (which underlies WebFOCUS as well), which has a number of advan-tages. In a federated environment iWay stores a Master File Description for each data source and you can then use the 4GL to associate relevant items, based on those descriptions, in order to create appropriate heterogeneous queries. In practice this means that a federated query doesn’t look any different from a local query. In other words, iWay does not use a mediated schema. However, it does provide additional facilities that are not normally available from other suppliers, most notably a Resource Analyzer and Resource Governor, where the former will monitor the performance of queries, and the latter pre-emptively restricts queries that will impose too high a load on source systems. Updates, including two-phase commit, are supported.
Two further features that should be mentioned with regard to iWay is that it resells LakeView’s change data capture technology, so that it can support trickle
Data Integration, Volume 2
Page 22 © Bloor Research 2004
feeds into a data warehouse as well as near real-time capabilities, albeit that these are primarily (except for DB2) trigger-based. In addition, the company markets a product called the XML Transformation Engine, which can be used either in a stand-alone fashion or in conjunction with ETL Manager. This maps incoming data, either transactions or documents, into XML, and then maps the result to whatever source environment is required.
Finally, you can use WebFOCUS in conjunction with iWay’s adapter architecture to provide an EII solution to go beyond the data federation capabilities provided by iWay itself.
iWay has had a partnership with Group 1 (in the United States) to use its data cleansing software. However, with the latter’s acquisition of Sagent this arrange-ment is expect to lapse, leaving iWay with no partners in the data quality space.
MetaMatrix
MetaMatrix was founded in 1998 initially as an ASP (application service provid-er) for financial market data and trading systems. However, the dot bomb crash meant that that business plan did not survive. Nevertheless, the company had developed some advanced software as a part of its developments and it was able to switch track into becoming a software vendor, with its first product being re-leased in 2000.
The company’s eponymous product is based on the MetaMatrix repository and this is marketed as a product in its own right. However, data federation is the company’s main market, though it is also active in the rapidly developing refer-ence (or master) data management market.
We have mentioned that a number of vendors use a mediated schema approach to data federation (which we will discuss in detail in the next chapter). MetaMatrix is perhaps the archetypal vendor in this category, where you build traditional E-R (entity-relationship) diagrams using a conventional data modelling approach. In fact, it is notable that the whole environment is very standards based, with the repository being MOF (meta object facility) compliant, and modelling being done using UML (unified modelling language), both of which are OMG (Object Man-agement Group) standards. SQL is used for queries and the SQL related to your data models is automatically synchronised. Full XA compliant two-phase commit is supported.
MetaMatrix’s channel to market is both direct and indirect and the company has a number of partners that sell the product on MetaMatrix’s behalf, in addition to systems integrators and technology partners. The most notable of the latter is probably SAP, which includes MetaMatrix Server within the SAP NetWeaver ar-chitecture. The company has clients in a wide range of sectors including finance, telecommunications, pharmaceuticals, fast moving consumer goods, supply chain environment in general, government and defence.
The company has offices in the United States and the UK. The company also has partners in France, Korea, Japan and Australia, and expects to announce new partnerships in China shortly.
Market Issues
© Bloor Research 2004 Page 23
Pitney Bowes
Pitney Bowes, which is well-known, has just acquired Group 1 Software, which was itself a well established company, being some 20 years old. It specialised in marketing services, call centres and so forth. Most recently it had purchased Sa-gent, and it is with this company’s Data Flow product that we are concerned in this report. This product is unique in that it offers conventional data integration capabilities, a data federation platform, business intelligence capability and an EII solution.
There are actually four major components of the solution: two engines, which support data movement and data federation respectively, a business intelligence product that can work in conjunction with either or both of the engines, and a product that supports third party business intelligence solutions in conjunction with the engines.
However, there are two more important points. The first is that both engines are the same or, at least, they are different instantiations of the same technology; and the second is that you might well want to use Data Flow’s business intelligence capability along with one or more of the engines, even if you are going to use a third party tool to run against your data warehouse.
The reason for this is that Sagent’s approach has traditionally been very business-user centric. For example, its major emphasis has been on process development rather than mapping, because a developer can sit down and discuss how processes should work with the end user, but that will not generally be the case with regard to mappings. Similarly, the business intelligence capability built into Data Flow allows the user to see the results of each process step so that he can actually see the data to spot any exceptions. This facility also supports low-level, visual, data profiling but its principal use is in making the environment more user friendly. The business intelligence solution itself is probably more geared towards the mid-market than large enterprises.
As far as data federation is concerned, there is a limit to what you can do with Data Flow because, if you want to do any processing on the source then you have to have an instantiation of the engine on the relevant platform and, as the product does not run in mainframe environments this is a limiting factor—it does not preclude a solution but may be a constraint. The product also comes at data federation from an essentially ETL perspective: that is, you define each query in-dependently, rather than employing a mediated schema. While it can be complex to develop such schemas, once defined they do have the advantage of reducing maintenance for individual queries. Finally, Data Flow can do updates but it does not support two-phase commit.
Going back to Group 1, one of its major products is DataSight, which is data cleansing software. At the moment this is only sold in the United States though Group 1 does have international name and address capabilities to support US-based multi-nationals.
It is likely in the future that DataSight will be integrated with Data Flow and, we would guess, that the company will either buy or build data profiling capability.
Data Integration, Volume 2
Page 24 © Bloor Research 2004
At this point we would also expect the product set to be marketed world-wide. This is especially likely since one of the reasons for the Sagent acquisition was that company’s international operations and expertise. Once it has done all of this, particularly if it can do so within a relatively short time span, then the fact that it can offer a product that extends beyond those of most other companies in the data integration space (namely that it can offer both data movement and data federation) should leave Group 1 very well placed.
At the time of writing the acquisition of Group 1 by Pitney Bowes has only re-cently been announced, and it is not expected to be complete until Q3 2004. The company has announced that Group 1 will continue to operate under its existing management as an independent subsidiary but how this affects Group 1 in gen-eral, and Sagent Data Flow in particular, remains to be seen.
Conclusion
We have gone into rather more technical detail in the preceding sections on the vendors than is normal at this stage of a report. The reason for this is to illus-trate the diversity of the market. We have products that use mediated schemas and some that do not; we have products built on databases, repositories, grids and connectivity architectures; we have products that focus on XML, SQL and neither of them; and we have both well-established companies and relatively new start-ups.
As a result of this diversity it is difficult to predict how the market will develop. IBM and, to a lesser extent, BEA, will no doubt continue on their merry ways but which of the remaining vendors will prosper is very difficult to predict, although many of them have additional strings to their bows which may mean that they continue to thrive as companies, even if they are not particularly successful with respect to data federation. While we will investigate the various technical options in the next chapter it is usually the case that marketing is the driver of success in these situations as much as technical merit, and this is very difficult to evaluate.
Te
ch
nic
al I
ss
ue
s
3
Technical Issues
© Bloor Research 2004 Page 27
Introduction
From a technical perspective data federation may appear complex. Like all com-plex issues they are more easily understood if you break them down into their components and look at each of these separately. In the case of data federation this is relatively easy to do. As illustrated in Figure 2, data federation effectively consists of a three tier architecture: a front-end in which queries and federated access requirements are defined (developer services), a middle tier that does the hard work (federation), and a back-end that links to the data sources that store the data that you want to access (integration services).
In this chapter we will start by considering developer and integration services. We will leave federation services to the end because this is a more complex subject than the other two, and may require a further breakdown of characteristics.
Developer Services
In terms of data federation, developer services are the facilities provided to en-able developers to create federated queries and functions. In general, these are standards-based and the actual creation of federated applications falls outside of the data federation platform itself, which means that there is not a lot to discuss in this section.
There are a number of different ways to support federated capability at this level but, essentially, the key differentiator between products is whether they allow you to create queries using SQL, or XML, or both. Of course, in the case of XML, some vendors may simply support it via SQL extensions while others may have full support for XQuery. In respect of the latter, it is interesting to note that XQuery used to be supported by IBM (in DB2 II) through a partnership with Nimble Technologies. However, since Actuate acquired Nimble, this is no longer available. IBM has chosen not to replace this partnership (although it intends, in due course, to develop its own XQuery facilities) because it has found little demand for it. Nevertheless, several companies, such as BEA and Ipedo, provide full XQuery support. While on the topic of XML it may also be useful to be able to present result sets in XML format.
Some solutions lean towards more of an EII solution, whereby they go beyond simple support of standards that you could use with any third party tool and, in-stead, provide their own query capabilities. For example, iWay would typically be leveraged in conjunction with its parent company’s WebFOCUS product, while BEA provides a codeless development environment through WebLogic Work-shop. For products that are purely SQL based you can, of course, use any front-end tool that generates SQL. Somewhat surprisingly, DataMirror uses what it describes as an “SQL-like” language, which seems to us like falling between two stools.
In terms of the products reviewed within this report, the most notable of these EII solutions is that which is provided by cdeSolutions, primarily because it is Figure 2: The three-tier architecture of