Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 6317–6322,
6317
Label Embedding using Hierarchical Structure of Labels
for Twitter Classification
Taro Miyazaki Kiminobu Makino Yuka Takei Hiroki Okamoto Jun Goto
NHK Science and Technology Research Laboratories
{miyazaki.t-jw, makino.k-gg, takei.y-ek, okamoto.h-iw, goto.j-fw}@nhk.or.jp
Abstract
Twitter is used for various applications such as disaster monitoring and news material gather-ing. In these applications, each Tweet is clas-sified into pre-defined classes. These classes have a semantic relationship with each other and can be classified into a hierarchical struc-ture, which is regarded as important informa-tion. Label texts of pre-defined classes them-selves also include important clues for clas-sification. Therefore, we propose a method that can consider the hierarchical structure of labels and label texts themselves. We con-ducted evaluation over the Text REtrieval Con-ference (TREC) 2018 Incident Streams (IS) track dataset, and we found that our method outperformed the methods of the conference participants.
1 Introduction
Twitter is used for various applications such as disaster monitoring (Ashktorab et al., 2014; Mizuno et al.,2016) and news material gathering (Vosecky et al., 2013; Hayashi et al., 2015). In these applications, each Tweet is classified into pre-defined classes. These classes have a seman-tic relationship with each other and can be classi-fied into a hierarchical structure. Consider a news material gathering system that has classes such as “Tornado,” “Flood,” and “Riot.” These can be classified into two upper classes, “Natural disas-ter” (“Tornado” and “Flood” as lower classes) and “Incident” (“Riot” as a lower class). These rela-tionships can be an important clue for classifica-tion. Needless to say, label texts of pre-defined classes themselves include important clues. Peo-ple can understand what the criterion of the clas-sification is by reading labels. Therefore, we pro-pose a method that can consider the hierarchical structure of labels and the labels themselves.
Our method is based on the Label Embedding
(LE) method (Zhang et al., 2018). The typical LE method embeds input text and label text, and then the embedded vectors are fed into “Matcher,” which outputs the score between the input text and label. We use a two-step attention mechanism for LE to consider the hierarchical structure of la-bels. We confirm the effectiveness of our method through evaluation over the Text REtrieval Con-ference (TREC) 2018 Incident Streams (IS) track dataset.
Our contributions are as follows: (1) we pro-pose label embedding using the hierarchical struc-ture of labels, and (2) our method outperformed others on the TREC 2018 IS track dataset for several metrics, including the Any-type Micro F1 score, which is the target metric of the track.
2 TREC 2018 IS track
The TREC 2018 IS track is a shared-task that aims to mature social media-based emergency re-sponse technology (McCreadie et al.,2019). The task of the track is classifying Tweets by informa-tion type, which consists of 24 classes. The list of information types and the description for each in-formation type are given as ontology as shown in Table1. The dataset contains approximately 1,300 Tweets for training and more than 20,000 for test-ing. The numbers of samples for each class are also given in the table1. As shown in the table, a training dataset does not include much data and is unbalanced for classes.
The track uses two evaluation methods — Multi-type and Any-type — as follows2.
Multi-type: Calculating categorization perfor-mance per information type in a 1-vs-All manner.
1
Note that, each sample has just one information type for training data, but more than one for testing data.
2See
http://trecis.org/2018/Evaluation.htmlfor
Table 1: Ontology information type.
Intent type Information type Description # (train) # (test) REQUEST
REQUEST-GOODSSERVICES The user is asking for a particular service or physical good 0 126 REQUEST-SEARCHANDRESCUE The user is requesting a rescue (for themselves or others) 0 286 REQUEST-INFORMATIONWANTED The user is requesting information 10 172
REPORT
REPORT-WEATHER The user is providing a weather report (current or forecast) 41 1,325 REPORT-FIRSTPARTYOBSERVATION The user is giving an eye-witness account 28 3,807 REPORT-THIRDPARTYOBSERVATION The user is reporting a information that they received from someone else 15 4,160 REPORT-EMERGINGTHREATS The user is reporting a potential problem that may cause future loss of life or damage 36 686 REPORT-SIGNIFICANTEVENTCHANGE The user is reporting a new occurrence that public safety officers need to respond to 34 415 REPORT-MULTIMEDIASHARE The user is sharing images or video 127 3,974 REPORT-SERVICEAVAILABLE The user is reporting that they or someone else is providing a service 15 1,076 REPORT-FACTOID The user is relating some facts, typically numerical 140 2,383 REPORT-OFFICIAL An official report by a government or public safety representative 52 403 REPORT-CLEANUP A report of the clean up after the event 2 62 REPORT-HASHTAGS Reporting which hashtags correspond to each event 4 3,363 CALLTOACTION
CALLTOACTION-VOLUNTEER The user is asking people to volunteer to help the response effort 2 116 CALLTOACTION-DONATIONS The user is asking people to donate goods/money 15 804 CALLTOACTION-MOVEPEOPLE The user is asking people to leave an area or go to another area 26 27
OTHER
OTHER-PASTNEWS The post is generic news, e.g. reporting that the event occurred 12 1,351 OTHER-CONTINUINGNEWS The post providing/linking to continuous coverage of the event 250 4,871 OTHER-ADVICE The author is providing some advice to the public 39 1,209 OTHER-SENTIMENT The post is expressing some sentiment about the event 39 6,952 OTHER-DISCUSSION Users are discussing the event 51 2,060 OTHER-IRRELEVANT The post is irrelevant, contains no information 163 2,605 OTHER-UNKNOWN Does not fit into any other category 26 77 OTHER-KNOWNALREADY The responder already knows this information 112 1101
embed Hierarchical attention
Label attention
Matcher
embed
embed
𝑤𝑥
𝑤𝐿
𝑤𝐿
𝑋
𝑈𝑗
𝐿𝑗
𝑠𝑗
Pre-trained model
Bi-directional LSTM
Two-layer FFNN
Lower label text Input Tweet text
Upper label text
ℎ𝑙𝑗
ℎ𝑢𝑗 ℎ𝑥
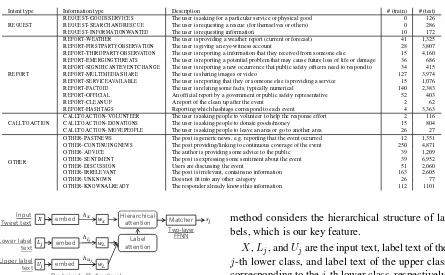
Figure 1: Overview of our proposed method.
Methods are evaluated using four metrics: Pre-cision, Recall, F1 (positive class), and Accuracy (overall).
Any-type: A system receives a full score for a Tweet if the system assigned any of the categories that the human assessor selected for that Tweet. Methods are evaluated using four metrics: Preci-sion, Recall, F1 (micro average: the target metric of the track), and Accuracy (micro average).
3 Our Method
As shown in Table 1, each information type has a rather rich description, so we think that us-ing the description can improve the performance. Also, the information types can be regarded as a hierarchical-structure label, which consists of four upper classes (equal to intent type, such as REQUEST and REPORT) and 24 lower classes (equal to information type, such as REQUEST -GOODSSERVICES and REPORT-WEATHER). To
use these useful features, we propose a label em-bedding using the hierarchical structure of labels.
The overview of our method is given in Fig-ure 1. Our method is similar to the one Zhang et al.(2018) used, but it differs in that our
method considers the hierarchical structure of la-bels, which is our key feature.
X,Lj, andUjare the input text, label text of the j-th lower class, and label text of the upper class corresponding to thej-th lower class, respectively. We use “description” and “intent type” in Table1 for the label text of the lower and upper classes, re-spectively. “Embed” in the figure is a pre-trained model such as BERT (Devlin et al., 2019) and ELMo (Peters et al.,2018) ofV×m, whereV and mdenote the vocabulary size and embedding size, respectively. wX and wL means Bi-directional Long Short-Term Memory (Bi-LSTM), and both have addimension of hidden layer.
First, X, Lj, and Uj are embedded using the pre-trained model, and then the embedded vectors are fed into wX for X and wL for Lj and Uj, respectively. We gather the hidden states of Bi-LSTM for each input token and stack them, and then we get three matrices:
Text representing matrix:hx∈R|X|×2d, Lower label representing matrix:hlj ∈R
|Lj|×2d,
Upper label representing matrix:huj ∈R
|Uj|×2d,
where|X|,|Lj|and|Uj|represent the number of tokens inX,LjandUj, respectively. Note that we have a 2ddimension for the row of each matrix because of concatenating forward and backward states.
Next, we calculate “label attention” and “hi-erarchical attention.” The label attention weight
12dare calculated as follows:
wlabel= softmax (h·hTlj/
√ 2d),
alabel=wlabel·hlj,
where h ∈ 12d is the concatenation of hidden states of the final step of both directions of huj.
We use scaled-dot product attention for label at-tention (Vaswani et al.,2017).
By usingalabel, the hierarchical attention weight
whier ∈ 1|X| and hierarchical attention vector
ahier∈12dare obtained as follows:
whier=alabel·hTx,
ahier=whier·hx.
Note that we use normalization for label attention but not for hierarchical attention. We confirm that this condition is best by an experiment, which is detailed in the Discussion section.
Then, ahier is fed to “Matcher,” which
con-sists of a two-layer Feed-Forward Neural Network (FFNN):
vmid=Wmid ·ReLU (ahier) +bmid,
sj =Wmatcher ·ReLU (vmid) +bmatcher,
whereWmid ∈ Rd×2d andWmatcher ∈ R1×dare
weight matrices, andbmid ∈1dandbmatcher∈11
are bias.sj is a score between input TweetXand information typej.
We gathersjfor allj∈C, whereCdenotes the set of the information type. Finally, we obtain the estimation resultofor input TweetXas follows:
o= argmax (s1, s2, . . . , s|C|).
4 Experiments
4.1 Experimental Settings
Our experiments were based on TREC 2018 IS track in terms of the dataset and evaluation. The dataset consists of original json data of Tweets. We excluded @-mentions and URLs. We con-ducted 10-fold cross validation to find the best set-ting, and all models were used as ensemble models to predict the information type for testing data.
The models were implemented in Chainer (Tokui et al.,2015) and learned with the Adam op-timizer (Kingma and Ba, 2014), on the basis of categorical cross-entropy loss with class weights Wc = |cmax|
|c| , where |c| is the number of sam-ples of information typecappearing in the training data, and|cmax|is that of the most-frequent infor-mation type. We used BERT-base, Uncased3 as
3
https://github.com/google-research/bert
embed Attention Matcher
embed
𝑤𝑋
𝑤𝐿
𝑋
𝐿𝑗
𝑠𝑗
(a) Non-hier
(b) Transfer
embed Attention Matcher
embed
𝑤𝑋
𝑤𝐿
𝑋
𝑈𝑗′
𝑠𝑗′
transfer
embed Attention Matcher
embed
𝑤𝑋
𝑤𝐿
𝑋
𝐿𝑗
𝑠𝑗 Lower label
text Input Tweet text
Input Tweet text
[image:3.595.312.525.62.204.2]Input Tweet text Lower label text Upper label text
Figure 2: Baseline methods based on label embedding.
the pre-trained model, which has a 12-layer, 768-hidden states transformer model with 12-heads at-tention. The BERT model was used as a frozen model without fine-tuning.
The hyperparameters used were: a minibatch size of 32; hidden layer size of 200;L2
regulariza-tion coefficient of 10−5; dropout rate of 0.5; and 100 training iterations, with early stopping on the basis of the Macro F1 score of the development data.
4.2 Baseline Methods
We prepared three baseline methods. All base-line methods used the same hyperparameters as the proposed method.
Non-LE: This method is not based on LE. We use the BERT model as token embedding. The embedded vectors are fed into Bi-LSTM, and then the concatenation of hidden states of the final step of both directions is fed into the two-layer FFNN for classification into the information type.
Non-hier: This method is almost the same as our proposed method but does not use hierarchi-cal attention. The vector fed into Matcher is hierarchi- cal-culated as attention between embedding vectors of the input text and label text of the lower class (Fig-ure2-(a)).
Table 2: Experimental results. italicsdenote the best results in TREC 2018, andbolddenotes the overall best results. For some metrics, the best results are for other TREC 2018 participants’ methods not shown in the table, so no results are initalicsorboldfor these metrics.
Method Multi-type, Macro Avg. Any-type, Micro Avg.
Precision Recall F1 Accuracy Precision Recall F1 (target metric) Accuracy
Non-LE 0.2461 0.1302 0.1523 0.9073 0.5032 0.7055 0.5874 0.4387
Non-hier 0.2522 0.1300 0.1497 0.9065 0.5206 0.6301 0.5701 0.4282
Transfer 0.2448 0.1324 0.1533 0.9071 0.5097 0.6810 0.5830 0.4361
Proposed 0.2464 0.1300 0.1521 0.9079 0.5164 0.7018 0.5950 0.4460
TREC2018 participants (Top-3 on Any-type Micro F1 score and Top-1 on Multi-type Macro F1 score)
cbunS2 0.2666 0.1122 0.1262 0.9059 0.4549 0.7780 0.5749 0.4213
KDEIS4 DM 0.1483 0.0708 0.0734 0.9035 0.3914 0.9856 0.5603 0.3908
umdhcilfasttext 0.1827 0.0962 0.1117 0.9044 0.4534 0.7260 0.5582 0.4022
DLR Augmented 0.2496 0.1657 0.1571 0.8996 0.3965 0.6165 0.4826 0.3419
4.3 Results
Table 2 presents the results for our methods and part of the TREC 2018 participants’ results. At TREC 2018, cbunS2, KDEIS4 DM, and umd-hcilfasttexthad the top three results for the Any-type Micro F1 score, which is the target metric of the track. DLR Augmentedhad the best Multi-type Macro F1 score.
Our proposed method outperformed others in terms of the Any-type Micro F1 score and both types of accuracy, while the best for the Multi-type F1 score isDLR Augmented.
4.4 Discussion
Comparison with other methods
Our proposed method performs the best for several metrics including the target metric (Any-type Mi-cro F1 score). Our hierarchical attention can give less weight for verbose phrases such as “The user is asking” in label text. These phrases include only a little information useful for classifying, so giv-ing them less weight is reasonable and effective. This is one of the advantages of our method, which distinguishes it from LE-based baseline methods. Our method outperforms not only LE-based meth-ods, but also the simple but strong baseline ( Non-LE) and the TREC 2018 participants’ methods. Therefore, we confirmed the effectiveness of our proposed method.
On the other hand, our method did not per-form the best for the Multi-type Macro F1 score.
DLR Augmented, which performed the best for this metric, uses augmented data. This is effec-tive in the learning process especially for classes that have small training data. Our method does not use augmented data, so it has lower accuracy for these classes thanDLR Augmented. Compar-ing our proposed method with the baseline meth-ods, differences in the Multi-type Macro F1 score
Table 3: Comparing normalization methods.
label attention hierarchical attention Macro F1 score
normalized normalized 0.2676
normalized none 0.3539
none normalized 0.0303
none none 0.0329
were small, and the proposed method achieved the best score for Multi-type accuracy. We think that the differences come from labels that have a small number of samples in test set because the F1 scores for these classes are sensitive to the output, which greatly affects the Macro F1 score.
Insight of our proposed method
To determine which combination of normalization is effective for our task, we conducted a small experiment using development data. Results are shown in Table3. We used the Macro F1 score as the metric4. We can see that using normalization for label attention but not for hierarchical attention is best. One reason is that the norm of the output vector of hierarchical attention directly affects the scoresj. Hierarchical attention without normal-ization can make distinctions for the output vector of each class in the norm, so it works well. On the other hand, using normalization is better in label attention. We observed that not using normaliza-tion for label attennormaliza-tion makes the model diverge, so normalization needs to be used for label atten-tion.
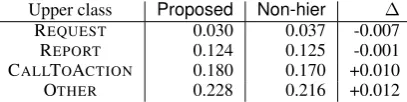
Table4shows the macro F1 scores summarized for each upper class of the proposed method and
Non-hier. ∆ in the table means the difference between two methods. Interestingly, our method works best for the upper class OTHER, which con-tains the fewest meanings in the upper class label
4Each sample has just one information type for
Table 4: Comparing macro F1 score for each upper class betweenproposedandNon-hier.
Upper class Proposed Non-hier ∆
REQUEST 0.030 0.037 -0.007
REPORT 0.124 0.125 -0.001
CALLTOACTION 0.180 0.170 +0.010
OTHER 0.228 0.216 +0.012
text. The lower class label text for the upper class OTHERincludes less verbose phrases such as “The
user requesting,” so label attention can give higher weight for important parts of the label text more precisely.
On the other hand, the F1 score of the proposed method for the upper class REPORTis worse than that ofNon-hier. This is caused by the lower class REPORT-SIGNIFICANTEVENTCHANGE(the∆is −0.05, which is the worst in all lower classes). The label text of the lower class includes a mis-spelling (“occurence” instead of “occurrence”5). This confuses our model when calculating label attention weight, so the F1 score is lower.
We found that the number of tokens in the lower class label text affects the effectiveness of the pro-posed method. The propro-posed method has a better F1 score thanNon-hierfor nine lower classes with a mean number of tokens in the lower class labels of 11.2. On the other hand, the proposed method has a lower F1 score than Non-hier for seven lower classes with a mean number of tokens of 8.0. This shows that the more tokens the lower class label text has, the more effective the proposed method becomes. Of course, this does not mean that our method works for only classes that have rich label text. For example, our method improves the F1 score for some classes that have short label text such as OTHER-DISCUSSION, which has only five tokens in the label text.
Overall, using hierarchical structure of labels is effective in many cases, but it is sensitive to the quality and quantity of label texts of the lower classes.
5 Related Work
Label embedding has attracted attention, es-pecially for few- and zero-shot learning tasks (Socher et al., 2013; Akata et al., 2013; Kodirov et al., 2017). Now, many methods ap-plied to natural language processing are proposed.
5Our label texts are made from provided ontology, so they
contain misspellings arising from the original ontology.
Zhang et al.(2018) used multi-task learning, and Xia et al. (2018) used capsule networks for LE and obtained good results. Our method differs in that it considers the hierarchical structure of labels.
There are many studies using a pre-defined hierarchical structure of labels (Wu et al., 2014; Li et al., 2015; Bilal et al., 2018), and some methods are used with LE (Bengio et al., 2010; Ren et al., 2016). These approaches are effec-tive but large-scale hierarchical data from a the-saurus need to be prepared. Our method does not need large-scale data, so it is advantageous when it comes to calculating cost and flexibil-ity.Shimura et al.(2018) used transfer learning to consider the hierarchical structure of labels, which is the basis of our baseline method (Transfer).
6 Conclusion and Future Work
In this paper, we proposed a method of label em-bedding using the hierarchical structure of labels and confirmed its effectiveness through evaluation over the Text REtrieval Conference (TREC) 2018 Incident Streams (IS) track dataset. Our method outperformed other methods and obtained the best results on the dataset for several metrics including the Any-type Micro F1 score, which was the target metric of TREC 2018 IS track.
We used rather long sentences for lower label text. Typical applications use shorter labels such as “Tornado” and “Riot.” Confirming whether our method works well for other datasets including ones that have only shorter label texts is left for our future work.
Acknowledgements
We would like to thank Prof. Timothy Baldwin and Dr. Ichiro Yamada for valuable discussions, and the TREC 2018 IS track organizers for pro-viding the dataset. We also thank the anonymous reviewers for their helpful comments.
References
Zeynep Akata, Florent Perronnin, Zaid Harchaoui, and Cordelia Schmid. 2013. Label-embedding for attribute-based classification. InThe IEEE Confer-ence on Computer Vision and Pattern Recognition (CVPR), pages 819–826.
inform disaster response. InProceedings of the 11th International ISCRAM Conference.
Samy Bengio, Jason Weston, and David Grangier. 2010. Label embedding trees for large multi-class tasks. InAdvances in Neural Information Process-ing Systems 23, pages 163–171.
Alsallakh Bilal, Amin Jourabloo, Mao Ye, Xiaoming Liu, and Liu Ren. 2018. Do convolutional neural networks learn class hierarchy? IEEE transactions on visualization and computer graphics, 24(1):152– 162.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language under-standing. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech-nologies (NAACL-HLT), pages 4171–4186.
Kohei Hayashi, Takanori Maehara, Masashi Toyoda, and Ken-ichi Kawarabayashi. 2015. Real-time top-r topic detection on twittetop-r with topic hijack filtetop-r- filter-ing. InProceedings of the 21th ACM SIGKDD Inter-national Conference on Knowledge Discovery and Data Mining, pages 417–426.
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Elyor Kodirov, Tao Xiang, and Shaogang Gong. 2017. Semantic autoencoder for zero-shot learning. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3174–3183.
Xirong Li, Shuai Liao, Weiyu Lan, Xiaoyong Du, and Gang Yang. 2015. Zero-shot image tagging by hier-archical semantic embedding. InProceedings of the 38th International ACM SIGIR Conference on Re-search and Development in Information Retrieval, pages 879–882.
Richard McCreadie, Cody Buntain, and Ian Soboroff. 2019. TREC incident streams: Finding actionable information on social media. In Proceedings of 16th International Conference on Information Sys-tems for Crisis Response and Management.
Junta Mizuno, Masahiro Tanaka, Kiyonori Ohtake, Jong-Hoon Oh, Julien Kloetzer, Chikara Hashimoto, and Kentaro Torisawa. 2016. WISDOM X, DIS-AANA and D-SUMM: Large-scale NLP systems for analyzing textual big data. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstra-tions, pages 263–267.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word repre-sentations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 2227–2237.
Xiang Ren, Wenqi He, Meng Qu, Lifu Huang, Heng Ji, and Jiawei Han. 2016. Afet: Automatic fine-grained entity typing by hierarchical partial-label embed-ding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1369–1378.
Kazuya Shimura, Jiyi Li, and Fumiyo Fukumoto. 2018. HFT-CNN: Learning hierarchical category structure for multi-label short text categorization. In Proceed-ings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 811–816.
Richard Socher, Milind Ganjoo, Christopher D Man-ning, and Andrew Ng. 2013. Zero-shot learning through cross-modal transfer. In Advances in neu-ral information processing systems, pages 935–943.
Seiya Tokui, Kenta Oono, Shohei Hido, and Justin Clayton. 2015. Chainer: a next-generation open source framework for deep learning. InProceedings of workshop on machine learning systems (Learn-ingSys) in the twenty-ninth annual conference on neural information processing systems (NIPS), vol-ume 5, pages 1–6.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InAdvances in neural information pro-cessing systems, pages 5998–6008.
Jan Vosecky, Di Jiang, Kenneth Wai-Ting Leung, and Wilfred Ng. 2013. Dynamic multi-faceted topic dis-covery in twitter. InProceedings of the 22nd ACM international conference on Conference on informa-tion & knowledge management, pages 879–884.
Chenxia Wu, Ian Lenz, and Ashutosh Saxena. 2014. Hierarchical semantic labeling for task-relevant RGB-D perception. In Robotics: Science and sys-tems.
Congying Xia, Chenwei Zhang, Xiaohui Yan, Yi Chang, and Philip Yu. 2018. Zero-shot user intent detection via capsule neural networks. In Proceedings of the 2018 Conference on Empir-ical Methods in Natural Language Processing (EMNLP), pages 3090–3099.