Contents lists available atScienceDirect
Artificial
Intelligence
www.elsevier.com/locate/artint
Semantic
sensitive
tensor
factorization
Makoto Nakatsuji
a,
∗
,
Hiroyuki Toda
b,
Hiroshi Sawada
b,
Jin Guang Zheng
c,
James A. Hendler
caSmartNavigationBusinessDivision,NTTResonantInc.,Japan bNTTServiceEvolutionLaboratories,NTTCorporation,Japan cTetherlessWorldConstellation,RensselaerPolytechnicInstitute,USA
a
r
t
i
c
l
e
i
n
f
o
a
b
s
t
r
a
c
t
Articlehistory:
Received18August2014
Receivedinrevisedform28August2015 Accepted1September2015
Availableonline14September2015 Keywords:
Tensorfactorization Linkedopendata Recommendationsystems
The ability to predict the activities of users is an important one for recommender systems and analyses of social media. User activities can be represented in terms of relationships involving three or more things (e.g. when a user tags items on a webpage or tweets about a location he or she visited). Such relationships can be represented as a tensor, and tensor factorization is becoming an increasingly important means for predicting users’ possible activities. However, the prediction accuracy of factorization is poor for ambiguous and/or sparsely observed objects. Our solution, Semantic Sensitive Tensor Factorization (SSTF), incorporates the semantics expressed by an object vocabulary or taxonomy into the tensor factorization. SSTF first links objects to classes in the vocabulary (taxonomy) and resolves the ambiguities of objects that may have several meanings. Next, it lifts sparsely observed objects to their classes to create augmented tensors. Then, it factorizes the original tensor and augmented tensors simultaneously. Since it shares semantic knowledge during the factorization, it can resolve the sparsity problem. Furthermore, as a result of the natural use of semantic information in tensor factorization, SSTF can combine heterogeneous and unbalanced datasets from different Linked Open Data sources. We implemented SSTF in the Bayesian probabilistic tensor factorization framework. Experiments on publicly available large-scale datasets using vocabularies from linked open data and a taxonomy from WordNet show that SSTF has up to 12% higher accuracy in comparison with state-of-the-art tensor factorization methods.
©2015 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY license (http://creativecommons.org/licenses/by/4.0/).
1. Introduction
Theabilitytoanalyzerelationships involvingthreeormoreobjectsiscriticalforaccuratelypredicting humanactivities. An exampleofatypicalrelationshipinvolvingthreeormoreobjectsinacontentprovidingserviceisone betweenauser, anitemonawebpage,andauser-assignedtagofthatitem.Anotherexampleistherelationshipbetweenauser,hisorher tweet on Twitter,andthelocations atwhichheorshe tweeted.Theability topredict such relationships canbe used to improverecommendationsystemsandsocialnetworkanalysis.Forexample,supposethatauserassignsathrillermoviethe tag “romance”andanotherusertags itwith“caraction”.Here,methodsthatonlyhandlebi-relationalobjectsignoretags andfindtheseusersto besimilar becausetheymentioned thesameitem.Incontrast,multi-relational methodsconclude
*
Correspondingauthor.E-mailaddress:[email protected](M. Nakatsuji). http://dx.doi.org/10.1016/j.artint.2015.09.001
0004-3702/©2015TheAuthors.PublishedbyElsevierB.V.ThisisanopenaccessarticleundertheCCBYlicense (http://creativecommons.org/licenses/by/4.0/).
Fig. 1.Flowchart of SSTF.
thatsuchusersareslightlydifferentbecausethey havedifferentopinionsabouttheitem.Thequalityofrecommendations wouldbehigheriftheyreflectedthesesmalldifferences[1].
Tensorsare usefulwaysofrepresenting relationships involvingthreeor moreobjects,andtensor factorizationisseen asameansofpredictingpossiblefuturerelationships [2].Bayesianprobabilistictensorfactorization(BPTF)[3]isespecially promisingbecauseofits efficientsamplingoflarge-scaledatasets andsimpleparameter settings.However,thisandother tensorfactorizationschemeshavehadpooraccuracybecausetheyfailto utilizethesemantics underlyingtheobjects and havetroublehandlingambiguousand/orsparselyobservedobjects.
Semanticambiguityis afundamental problemin text clustering. Severalstudieshave usedWikipediaor WordNet
tax-onomies [4] to resolve semantic ambiguities and improve the performance of text clustering [5] and to compute the semanticrelatednessofdocuments [6].Weshow inthispaperthattaxonomy-baseddisambiguationcanimprovethe pre-dictionaccuracyoftensorfactorization.
Thesparsityproblemaffects accuracyifthedatasetused forlearning latent featuresintensor factorizationsisnot
suf-ficient[7].Inan attempttoimprovepredictionaccuracy, generalizedcoupled tensorfactorization(GCTF)[8,9] usessocial relationshipsamongusersasauxiliaryinformationinadditiontouser–item–tagrelationshipsduringthetensorfactorization. Recently,GCTFwas usedforlinkprediction[10],anditwasfoundtobethemostaccurate ofthecurrenttensor factoriza-tionmethods thatuseauxiliary information[7,11,12].However, sofar,no tensormethodshaveusedsemanticsexpressed astaxonomiestoresolveambiguity/sparsityproblemseventhough taxonomiesarepresentinrealapplicationsasa result ofthespreadoftheLinkedOpenData(LOD)vision[13]andthegrowingknowledgegraphsusedinsearch.1
Inthispaper,weproposesemanticsensitivetensorfactorization(SSTF),whichusessemanticsexpressedbyvocabularies andtaxonomiestoovercometheabove problemsintheBPTFframework. Vocabulariesandtaxonomies,sometimes called “simpleontologies”[14],arecollectionsofhuman-definedclasseswithahierarchicalstructureandclassificationinstances (i.e., itemsorwords). We will disambiguate the objects(items or tags)by using “vocabularies” forgraph structuresand “taxonomies”fortreestructures.
Fig. 1
overviewsSSTF.Thefactorizationhastwocomponents,semanticgroundingandtensorfactorizationwithsemanticaugmentation,whichrespectivelyresolvethesemanticambiguityandsparsityproblems.
Semanticgrounding resolvessemanticambiguitiesbylinkingobjectstovocabulariesortaxonomies.Itfirstmeasuresthe
similaritybetweenobjectsandinstancesinthevocabularies(taxonomies).Itthenlinkseachobjecttovocabulary(taxonomy) classesviatheinstancethatismostsimilartotheobject.Consequently,itcanconstructatensorwhoseobjectsarelinked toclasses.Forexample,in
Fig. 1
,thetag “Breathless”canbelinked totheclass CT1,whichincludeswordinstancessuch as“Breathtaking”and“Breathless”orCT2,whichincludesthewordinstancessuchas“Dyspneic”and“Breathless”.CT1 and CT2 havedifferentmeanings,andatensorfactorizationtrainedonobservedrelationshipsthatincludesuchambiguoustags candegradepredictionaccuracy.SSTFextractsthepropertiesthatareassignedtoitementry v1 inLODsourcesandthose assignedtoinstancesinWordNet.Then,itlinksthetag“Breathless”toCT1 ifthepropertiesof“Breathless”inCT1 aremore similartothepropertiesofv1 thantothoseof“Breathless”inCT2.WedescribethisprocessindetailinSection4.2.Tensorfactorizationwithsemanticaugmentation solves the sparsity problem by incorporating semantic biasesbased on
vocabulary(taxonomy)classesintotensorfactorization.Thekeypointofthisideaisthatitletssparseobjectssharesemantic knowledge with regard to their classes during the factorization process. It lifts sparse objects to their classesto create augmented tensors.Todothis, itdetermines multiplesets ofsparse objectsaccordingtothe degreeof sparsityto create
multiple augmentedtensors. Itthen factorizesthe originaltensor andthe augmentedtensors simultaneouslyto compute feature vectorsforobjectsandforclasses.Byfactorizingmultipleaugmentedtensors,it createsfeature vectorsforclasses according to the degree of sparsity. As a result, through these feature vectors, relationships betweensparse objects can include detailedsemantic knowledge withregard totheir classes.This aims to solvethe sparsity problem. Forexample, in Fig. 1, items v1 and v2 are linked to classes CV1 and CV2, and items v3 and v4 are linked to class CV2. Suppose that items v1 and v2 are inaset thatincludes themostsparseitems. Item v3 isinaset thatincludes thesecond-most sparse items. In thiscase, v1 and v2 can sharethe semantic knowledge inCV1 and CV2 with each other.Moreover, v3 can sharethesemantic knowledgewith v1 and v2 inCV2.This semanticknowledgeameliorates thesparsity problemin tensorfactorization.Furthermore,SSTFcancombineheterogeneousandunbalanceddatasetsthoughitfactorizestheoriginal tensor andaugmented tensors,whichare createdfromdifferentdatasources,simultaneously. Thisisbecause,increating the augmented tensors, SSTF inserts relationships composed ofsemantic classes of sparsely observed objects (i.e. rating relationships composedofusers,itemclasses,andtags)intotheoriginal tensor.Thoseaugmentedrelationships areofthe sametypepresentintheoriginaltensor.ThissemanticaugmentationisdescribedindetailinSection 4.3.
Thus,ourapproachleveragessemanticstoincorporateexpertknowledgeintoasophisticatedmachinelearningscheme, tensor factorization.SSTF resolvesobjectambiguitiesby linkingobjectsto vocabularyandtaxonomyclasses.Italso incor-poratessemantic biasesintotensor factorizationby sensitivelytrackingthedegree ofsparsityofobjects whilefactorizing original tensorandaugmentedtensorssimultaneously;thesparsity problemissolvedbysharingthe semanticknowledge among sparseobjects. As aresult, SSTF achievesmuch higheraccuracy thanthe currentbest methods.We implemented SSTFintheBPTFframework.Thus,itinheritsthebenefitsofaBayesiantreatmentoftensorfactorization,i.e.,easyparameter settingsandfastcomputationbyparallelcomputationoffeaturevectors.
We evaluated ourmethodon threedatasets: (1)MovieLens ratings/tags2 withFreeBase3/WordNet,(2) Yelp ratings/re-views4 withDBPedia[15]/WordNet,and(3)Last.fmlisteningcounts/tags5 withFreeBaseandWordNet.Weputthedatasets andMatlabcodeofourproposalonline,soreaderscanusethemtoeasilyconfirmourresultsandproceedwiththeirown studies.6TheresultsshowthatSSTFhas6–12%higheraccuracyincomparisonwithstate-of-the-artmethodsincludingGCTF. It suitsmanyapplications(i.e.movierating/taggingsystems,restaurantrating/review systems,andmusiclistening/tagging systems)thatmanagevariousitemssincethegrowingknowledgegraphmeansthatapplicationsincreasinglyhavesemantic knowledgeunderlyingobjects.
The paper isorganized asfollows: Section 2 describesrelatedwork, andSection 3 introduces thebackground ofthis paper.Section4explainsourmethod,andSection5evaluatesit.Section6concludesthepaper.
2. Relatedwork
Tensor factorizationmethods are used in various applications such asrecommendation systems [2,16], semantic web analytics[17,18],andsocialnetworkanalysis[11,19,20].Forexample,
[2]
modelsobservationdataasa user–item–context tensortoprovidecontext-awarerecommendations.TripleRank[17]
analyzesLinkedOpenData(LOD)triplesbyusingtensor factorizationandranksauthoritativesourceswithsemanticallycoherentpredicates.[20,21]providepersonaltag recommen-dationsbyfactorizingtensorscomposedofusers,items,andsocialtags.This section firstdetails thetensor factorizationstudiesthat utilizethe side informationintheir factorizationprocess to solve the sparsity problem.It next describesefficienttensor factorizationschemes andthen introduces tensorstudies that use semanticdata includinglinked open data to analyzeorenhance factorized results.Other than thetensor-based methods,itfinallyexplainsmethodsthatuseatripartitegraphtocomputethelinkorratingpredictions.
2.1. Coupledtensorfactorization
Onemajorproblemwithtensorfactorizationisthatitspredictionaccuracytendstobepoorbecauseobservationsmade inrealdatasetsaretypicallysparse[7].Severalmatrixfactorizationstudieshavetriedtoincorporatesideinformationsuch associalconnectionsamonguserstoimprovefactorizationaccuracy
[22]
.However,theirfocusisonpredictingpaired-object relationships. As a result, they differin purposefromours, i.e.,predicting possible futurerelationships betweenthree or moreobjects.Coupledtensorfactorizationalgorithms
[7,8,11,12,16,23–26]
haverecentlygainedattention.Theyrepresentrelationships composed of threeor moreobjects (e.g.rating relationships involvingusers, items, andtags)as atensor andside infor-mation (e.g.linkrelationshipscomposedbyitemsandtheirproperties)asmatricesortensors.Theyassociateobjects(e.g. items)withtensorsandmatrices,eachofwhichtreatsdifferenttypesofinformation(e.g.tensorsrepresentrating relation-ships whereas matricesrepresent link relationship);this oftentriggers a balance problemwhen handling heterogeneous2 Availableathttp://www.grouplens.org/node/73. 3 http://www.freebase.com.
4 Availableathttp://www.yelp.com/dataset_challenge/. 5 Availableathttp://www.grouplens.org/node/462. 6 Availableathttps://sites.google.com/site/sbjtax/sstf.
datasets[27].Then, theysimultaneouslyfactorizethetensorsandmatricestomakepredictions.Among them,generalized coupledtensorfactorization(GCTF)[8]utilizesthewell-establishedtheoryofgeneralizedlinearmodelstofactorize multi-pleobservedtensorssimultaneously.Itcancomputearbitraryfactorizationsinamessagepassingframeworkderivedfora broadclassofexponentialfamilydistributions.GCTFhasbeenappliedtosocialnetworkanalysis
[9]
,musicalsource sepa-ration[28],andimageannotation[29]andithasbeenprovenusefulinjointanalysisofdatafrommultiplesources.Acaret al.haveformulatedacoupledmatrixandtensorfactorization(CMTF)problem,whereheterogeneousdatasetsaremodeled by fittingouter-product modelsto higher-ordertensors andmatricesina coupled manner.They proposed an all-at-once optimization approachcalled CMTF-OPT (CMTF-OPTimization), whichis a gradient-based optimizationapproach for joint analysisof matricesandhigher-order tensors [12]. Theyused their methodto analyze metabolomicsdatasets andfound thattheycancapturetheunderlyingsparsepatternsindata[30]
.Furthermore,onarealdatasetofbloodsamplescollected fromagroup ofrats, TheyusedCMTF-OPTtojointlyanalyzemetabolomicsdatasetsandidentifypotential biomarkersfor apple intake.Theyalso reportedthelimitationsof coupledtensorfactorizationanalysis, not onlyits advantages [31].For instance,coupledanalysisperformsworse thantheanalysisofasingledatasetwhentheunderlyingcommonfactors con-stitute onlya smallpartofthedataunderinspection orwhentheshared factorsonlycontribute alittle toeach dataset. Tosolvethesparsityproblemaffectingtensorcompletion,[23]proposednon-negativemultipletensorfactorization(NMTF), which factorizesthe target tensorandauxiliary tensorssimultaneously, where auxiliary datatensors compensate forthe sparseness ofthe target data tensor.More recently,[32] proposed amethod that uses commonstructuresindatasets to improve the predictionperformance. Instead ofcommon latent factors in factorization, it assumes that datasets share a commonadjacencygraph(CAG)structure,whichismoreabletodealwithheterogeneousandunbalanceddatasets.SSTFdiffersfromtheabovestudiesmainlyinthefollowingfoursenses:(1)itpresentsthewayofincorporatingsemantic information,whichisnowavailableintheformatoflinkedopendata,intotensorfactorization.Theevaluationsshowthat ourideas,semanticgroundingandtensorfactorizationwithsemanticaugmentation,areveryusefulinimprovingprediction results in tensorfactorization. (2) From the viewpointof coupled tensorfactorization, SSTF is morerobust to deal with heterogeneous andunbalanceddatasets, asdemonstratedin theevaluation section. Thisis becauseit augmentsa tensor byinsertingrelationships composedofsemanticclassesofsparselyobservedobjects(i.e.ratingrelationshipscomposedof users,item classes,andtags)intothe originaltensor. Theseaugmentedrelationships areofthe sametypepresentinthe originaltensor,soSSTFcannaturallycombineandsimultaneouslyfactorizetheoriginaltensorandaugmentedtensors.Thus, itsapproachissuitableforcombiningheterogeneousdatasetsinfactorizationsuchasratingsdatasetsandlinkrelationships datasets. (3) It focuses on multi-object relationships including sparse objects. Thus, it can effectively solve the sparsity problemwhileavoidingtheuseless semanticinformationfromobjectsthatareobservedalot. (4) ItexploitstheBayesian approach infactorizingmultiple tensors simultaneously. Thus,it can avoidover-fitting inthe optimizationwitheasy pa-rametersettings.TheBayesianapproacheshavereportedtobe moreaccurate thannon-Bayesianonesinratingprediction applications
[3]
.2.2. Efficienttensorfactorization
Recently,anefficienttensorfactorizationmethodbasedonaprobabilisticframeworkhasemerged[3,33].Byintroducing priorsontheparameters,BPTF[3]caneffectivelyaverageovervariousmodelsandlowerthecostoftuningtheparameters (seeSection3).Asforscalability,itoffersanefficientMarkovchainMonteCarlo(MCMC)procedureforthelearningprocess, soitcanbeappliedtolarge-scaledatasetslikeNetflix.7
Several studies have tried to compute predictions efficiently by using coupled tensor factorization. [34] presented a distributed,scalablemethodfordecomposing matrices, tensors,andcoupleddata setsthrough stochasticgradient decent on a variety of objective functions. [35] introduced a parallel anddistributed algorithmic framework forcoupled tensor factorizationtosimultaneouslyestimatelatentfactors,specificdivergencesforeachdataset,aswell astherelativeweights inanoveralladditivecostfunction.[36]proposedTurbo-SMT,whichbooststheperformanceofcoupledtensorfactorization algorithmswhilemaintainingtheiraccuracy.
2.3. Tensorfactorizationusingsemanticdata
Aswaysofhandlinglinked open data,[18,37]proposed methodsthat analyzeahuge volumeofLOD datasetsby ten-sorfactorizationina reasonableamount oftime.They,however,didnot useacoupledtensor factorizationapproach and thuscouldnotexplicitlyincorporatethesemanticrelationshipsbehindmulti-objectrelationships intothetensor factoriza-tion;inparticular,theycouldnotusetaxonomicalrelationshipsbehindmulti-objectrelationshipssuchas“subClassOf”and “subGenreOf”,whichareoftenseeninLODdatasets.
Taxonomies have been used to solve the sparsity problem affecting memory-based collaborative filtering [1,38–42]. Model-basedmethodssuchasmatrixandtensorfactorization,however,usuallyachievehigheraccuracythanmemory-based methods do [43]. Taxonomies are alsoused in genome science for clustering genomes with functional annotations [44].
Thus, their use is promisingfor analyzing such datasets aswell asuser activitydatasets. There are, however, no tensor factorizationstudiesthatusevocabularies/taxonomiestoimprovepredictionaccuracy.
We previously proposed Semanticdata Representationfor Tensor Factorization (SRTF) [16] that incorporates semantic biasesintotensorfactorizationtosolvethesparsityproblem. SRTFisthefirstmethodthat incorporatessemanticsbehind multi-object relationships into tensor factorization. Furthermore, SRTF can be considered the first coupled tensor factor-ization as that uses the Bayesian approach to simultaneously factorize several tensors for rating predictions. Khan and Kaski [45]presentedaBayesianextensionofthetensorfactorizationofmultiplecoupledtensorsafterourpublication[16]. This paper extendsSRTF by introducing the degreesof sparsity of objectsand adjusting how much thesemantic biases should be incorporatedinto tensorfactorizationby sensitivelytracking thosedegrees. Thispaper givesa muchmore de-tailed explanation of the Markov chain Monte Carlo (MCMC) procedure for SSTF than the one for SRTF in [16]. It also describesdetailedevaluationsthatusedadatasetonuserlisteningfrequenciesaswellasdatasetsonuserratingactivities. TheseevaluationsshowthatSSTFismuchmoreaccuratethanSRTFbecauseitsensitivelygivessemanticbiasestosparsely observedobjectsintensorfactorizationaccordingtothedegreeofsparsityoftheobjects.
2.4. Methodsthatuseatripartitegraph
Besidestensor-basedmethods,therearemethodsthatcreateatripartitegraphcomposedofusernodes,itemnodes,and tag nodes,forpredicting rating values[46,47].We could extendthesemethods sothat they can compute predictionsby combiningseveraltripartitegraphs(e.g.bycombiningauser–item–taggraphwithanitem–classgraphandtag–classgraph). Thetensorscan,however,morenaturallyhandleusers’activitiesthatareusuallyrepresentedasmulti-objectrelationships. We can plotthemulti-object relationshipscomposed ofusers, items, andtagsaswell asrating valuesinthe tensor.For example, asdepictedin Fig. 1, we canplot therelationship wherein useru2 assigns tag“Breathtaking” to item v2 with a certain rating value aswell asthe relationship thatuser u3 assigns tag“Breathtaking” to item v3 with anotherrating valueindependentlyinthetensor.Ontheotherhand,amodelbasedontripartitegraphshasthefollowingtwodrawbacks: (1) Itcannot handle eachrelationship independently. Wecan explain whythisis so byusing theexample inFig. 1. The modelbasedonthe tripartitegraphcan handletherelationship whereinusernode u2 isconnectedto itemnode v2 that connectstothetagnode“Breathtaking”.It,however,alsolinksusernodeu2 tonodeu3throughitemnode v2;thismodel mixesdifferenttypes ofrelationships(user–item–tag relationships anduser–item–userrelationships) inagraphandthus cannothandleusers’activitiesinthegraphsowell.(2)Itcannot handletheratingsexplicitly.Instead,itassignstheweights to edges (edgesbetween usernodes anditem nodes aswell as edges betweenitem nodes andtag nodes) to represent the ratingvaluesinthegraph.This,however,isunnaturalsince theratingvalue shouldbe assignedtoeach multi-object relationship (i.e.instanceofuseractivity).Thus,amethodbasedonatripartitegraphisnot suitableforcomputingrating predictionsofusers’activities.
In detail, the major differencesbetween tensor andtripartite graph is that a triplet is captured by a grid in a 3-D matrices(tensor)usingtensorrepresentation;whileatripletisrepresentedasthreetwo-wayrelationsinatripartitegraph. Actually,tensorfactorizationprocessmakesuseofthreetwo-wayrelationsinatripartitegraph.Itusuallyunfoldsthetensor across acertaindimension,whichintuitivelymatchesthethreetwo-wayrelations.Inaddition,withthegraphembedding fortripartitegraphs,thelinkpredictioncanbeeasilyobtainedbytheinnerproductofobjects’latentvectors.
Furthermore, [27] compares the performance of the matrix-factorization-based methodwith those of other link pre-diction methods such as feature-based methods [48,49], graph regularization methods [50,51], andlatent class methods [52] when predicting linksinthe target graph(e.g.user–item graph)by using graphsfromother sources (i.e.side infor-mation fromother sources such asuser–user social graph). They concludedthat thefactorization methods predict links moreaccuratelybysolvingtheimbalanceprobleminmergingheterogeneousgraphs(thoughwepointedoutabovethatthe presentfactorizationmethodsstillsufferfromtheimbalanceproblem).Thispaperthusfocusesonapplyingourideastothe factorizationmethodtoimprovepredictionresultsformulti-objectrelationships.
3. Preliminaries
Vocabulariesandtaxonomies Vocabularies and taxonomies, sometimes called “simple ontologies” [14], are collections of
human-defined classesand usually have a hierarchical structure asa graph (vocabulary) or a tree(taxonomy). Theyare becomingavailableontheWebasaresultoftheiruseinsearchenginesandsocialnetworkingsites.Inparticular,theLOD approachaimstolinkcommondatastructuresacrosstheWeb.ItpublishesopendatasetsusingtheResourceDescription Framework(RDF)8andsetslinksbetweendataentriesfromdifferentdatasources.Asaresult,itenablesonetosearchand utilize thoseRDF linksacross datasources. Thispaperuses the vocabulariesofDBPedia andFreebaseandthe taxonomy ofWordNet toimprovethequalityoftensor factorization.DBPediaandFreebasehavedetailedinformationaboutcontent itemssuchasmusic,movies,food,andmanyothers.Asanexample,themusicgenre“Electronicdancemusic”inFreeBase isidentifiedbyauniqueresourceidentifier(URI)9andisavailableinRDFformat.ByreferringtothisURI,thecomputercan
8 http://www.w3.org/RDF.
Table 1
Definitionofmainsymbols. Symbols Definitions
R Tensor that includes ratings by users to items with tags. ˆ
R The predictive distribution for unobserved ratings by users to items with tags.
α Observation precision forR. um m-th user feature vector. vn n-th item feature vector. tk k-th tag feature vector.
vn n-th item feature vector updated by semantic bias. tk k-th tag feature vector updated by semantic bias. U Matrix representation ofum.
V Matrix representation ofvn. T Matrix representation oftk. V Matrix representation ofvn. T Matrix representation oftk.
X Number of different kinds of sparse item (or tag) sets.
V(i)
s Set of thei-th most sparse items.
T(i)
s Set of thei-th most sparse tags.
Rv(i) i-th augmented tensor that includes classes of items inV(i) s . Rt(i) i-th augmented tensor that includes classes of tags inT(i)
s . cv
j (i)
j-th semantically biased item feature vector fromRv(i).
ct j (i)
j-th semantically biased tag feature vector fromRt(i).
Cv(i) Matrix representation ofcv j (i) . Ct(i) Matrix representation ofct j (i) .
Sv(i) Number of classes that include sparse items inV(i) s . St(i) Number of classes that include sparse tags inT(i)
s . f(o) Function that returns the classes of objecto.
δ(i) Parameter used for adjusting the number of thei-th most sparsely observed objects.
(i) Parameter used for updating the feature vectors for thei-th most sparsely observed items or tags.
acquiretheinformationthat“electronic_dance_music”has“electronic_music”asitsparent_genreand“pizzicato_five”asone ofitsartists,andfurthermore,ithastheowl:sameAsrelationshipwiththeURIfor“Electronic_Dance_Music”inDBPedia.10 ObjectsliketheaboveartistsinDBPedia/Freebasecanhavemultipleclasses.Becauseoftheir graph-basedstructures, they aredefinedtobevocabularies.
WordNetisa lexicaldatabasefortheEnglishlanguageandisoftenusedtosupportautomaticanalysisoftextssuchas user-assignedtagsandreviews. InWordNet,each wordisclassifiedintooneormoresynsets, eachofwhichrepresentsa conceptandcontainsasetofwords.Thus,wecanconsidersynsetasaclassandwordsclassifiedinthatsynsetasinstances. Aninstancecanbeincludedinaclass.Thus,WordNet’streestructuredefinesittobeataxonomy.
Bayesianprobabilistictensorfactorization This paperdeals withthe relationships formed by userum, item vn, andtagtk.
A third-order tensor
R
(definition of main symbols is described in Table 1) is used to model the relationships among objects from sets of users, items, and tags. Here, the(
m,
n,
k)-th
element rm,n,k indicates the m-thuser’s rating of then-thitemwiththek-thtag.Thispaperassumesthatthere isatmostoneobservationforeach
(
m,
n,
k)-th
element.This assumptionisnaturalformanyapplications(i.e.itis rarethatauserassigns multipleratingstothesameitemusingthe same tag.Even ifthe userrates the same item usingthe same tag severaltimes,we can use the latest ratingfor such relationships).TensorfactorizationassignsaD-dimensionallatentfeaturevectortoeachuser,item,andtag,denotedasum, vn,andtk,respectively.Here,umisan M-length,vn isan N-length,andtk isa K-lengthcolumnvector. Accordingly,eachelementrm,n,kin
R
canbeapproximatedastheinner-productofthethreevectorsasfollows:rm,n,k
≈
um,
vn,
tk≡
D d=1um,d
·
vn,d·
tk,dwheretheindexdrepresentsthed-thelementofeachvector.
BPTF[3]provides aBayesiantreatmentforProbabilisticTensorFactorization (PTF)asthesamewaytheBayesian Prob-abilistic MatrixFactorization (BPMF) [53] provides a Bayesiantreatment forProbabilistic Matrix Factorization (PMF)[54]. Actually,in[3],theauthorsprovidetousethespecifictype ofthird-ordertensor(e.g.user–item–time tensor)thathasan additional factorfortime addedto the matrix(e.g. user–item matrix).We, however, considerthat BPTF inthis paperis an instance ofthe CANDECOMP/PARAFAC (CP) decomposition [55] anda simple extension of BPMF by addingone more objecttype (e.g.tag) to thepairs (e.g.user–itemmatrix) handledby BPMF.BPTF modelstensorfactorizationover a
erativeprobabilisticmodelforratingswithGaussian/Wishartpriors[56]overparameters.TheWishartdistributionismost commonlyusedastheconjugatepriorfortheprecisionmatrixinaGaussiandistribution.
We denotethematrixrepresentationsofum,vn,andtk asU
≡ [
u1,
u2,
··
,
uM]
,V≡ [
v1,
v2,
··
,
vN]
,andT≡ [
t1,
t2,
··
,
tK]
.Toaccountforrandomnessinratings,BPTFusesaprobabilisticmodelforgeneratingratings:
R
|
U,
V,
T∼
M m=1 N n=1 K k=1N
(
um,
vn,
tk,
α
−1)
This equation represents theconditional distribution of
R
given U,V, andT in termsof Gaussian distributions,each havingmeansum,
vn,
tkandprecisionα
.ThegenerativeprocessofBPTFrequiresparameters
μ
0,β
0,W0,ν
0,W˜
0,,
˜
andν
˜
0inthehyper-priorsthatshouldreflect priorknowledgeaboutaspecificproblemandaretreatedasconstantsduringtraining.Theprocessisasfollows:1. Generate
U,
V,and
T
∼
W
(
|
W0,
ν
0),
whereU,
V,and
T aretheprecisionmatrices(aprecisionmatrixisthe
inverseofa covariancematrix)forGaussians.
W
(
|
W0,
ν
0)
istheWishartdistribution ofa D×
D randommatrixwith
ν
0 degreesoffreedomanda D×
D scale matrixW0:
W
(
|
W0,
ν
0)
=
||(ν0−D−1)/2
c exp(
−
Tr(W0−1)
2
),
where C isa constant.2. Generate
μ
U∼
N
(μ
0,
(β
0U
)
−1),
whereμ
U is used asthe mean vector for a Gaussian. In the sameway, generateμ
V∼
N
(μ
0,
(β
0V
)
−1)
andμ
T∼
N
(μ
0,
(β
0T
)
−1),
whereμ
Vandμ
TareusedasthemeanvectorsforGaussians.3. Generate
α
∼
W
(
˜
| ˜
W0,
ν
˜
0).
4. Foreachm
∈
(1
. . .
M),
generateum∼
N
(μ
U,
−U1
).
5. Foreachn
∈
(1
. . .
N),
generatevn∼
N
(μ
V,
−V1
).
6. Foreachk
∈
(1
. . .
K),
generatetk∼
N
(μ
T,
−T1
).
7. Foreachnon-missingentry
(
m,
n,
k),
generaterm,n,k∼
N
(
um,
vn,
tk,
α
−1).
Parameters
μ
0,β
0,W0,ν
0,W˜
0,,
˜
andν
˜
0 shouldbe setproperlyaccordingtotheobjectivedataset;varying theirvalues, however,haslittleimpactonthefinalprediction[3].BPTFviewsthehyper-parameters
α
,U
≡ {
μ
U,
U
}
,V
≡ {
μ
V,
V
}
,andT
≡ {
μ
T,
T
}
asrandomvariables,yielding apredictivedistributionforunobservedratings
R
ˆ
,which,givenanobservabletensorR
,is:p
(
R
ˆ
|
R
)
=
p
(
R
ˆ
|
U,
V,
T,
α
)
p(
U,
V,
T,
α
,
U,
V,
T|
R
)
d{
U,
V,
T,
α
,
U,
V,
T}
.
(1)BPTFcomputestheexpectationofp
(
R
ˆ
|
U,
V,
T,
α
)
overtheposteriordistribution p(
U,
V,
T,
α
,
U
,
V
,
T
|
R
);
itapprox-imates theexpectationbyaveraging samplesdrawnfromtheposteriordistribution.Since theposterioristoo complexto directlysamplefrom,itappliestheMarkovChainMonteCarlo(MCMC)indirectsamplingtechniqueoftoinferthepredictive distributionforunobservedratings
R
ˆ
(see[3]forthedetailsontheinferencealgorithmofBPTF).The time andspacecomplexity ofBPTFis O
(#
nz×
D2+
(
M+
N+
K)
×
D3)
andislower thanthat oftypical tensor methods(i.e.GCTFrequiresO(
M×
N×
K×
D)
[9]).#nzisthenumberofobservationentries,andM,N,orK ismuchgreater than D.BPTFcanalsocomputefeaturevectorsinparallelwhileavoidingfineparametertuningduring thefactorization.To initializethesampling,itcreatestwo-objectrelationshipscomposedofusersanditemsandtakesthemaximumaposteriori (MAP)resultsfromprobabilisticmatrixfactorization(PMF)[54];thisletsMCMCconvergequickly.4. Method
Here,webrieflydescribethetwomainideasbehindSSTFanddeveloptheseinmoredetailinsuccessivesections.
4.1. OverviewofSSTF
Semanticgrounding SSTFresolvesambiguitiesbylinkingobjects(i.e.itemsandtags)tosemanticclassesbeforeconducting
tensor factorization.Foritems(Section4.2.1),it resolvesambiguitiesby computingthesimilarities betweenthemetadata fortheitemsandthepropertiesgiventoinstancesinFreeBase/DBPedia.Then,itlinksitems(e.g.v1in
Fig. 1
)toclasses(e.g.CV1).Fortags(Section4.2.2),itfirstclassifiestagsintothoseexpressingthecontentofitemsorusers’subjectiveevaluations aboutitemssincetheyreflecttheirinterestsinitems.Next,itcomputesthesimilaritiesofthecontent(subjective)tagsand WordNet instances tolink tags (e.g.“Breathless”) to classes(e.g. CT1). SSTFis alsoapplied torelationships amongusers, items, anduser-assigned reviews(Section4.2.3). In thiscase, we replaceuser-assignedreviewswithaspect orsubjective phrases fromthereviews,treatthosephrasesastags,andinputthereplacedrelationshipstothesemanticgroundingpart of SSTF. Thisis becauseaspect andsubjective tags reflectusers’ opinionsofitems. SSTF linksthose tags to DBPediaand WordNetclassesfordisambiguation.Asaresult,itoutputsatensorwhoseobjectsarelinkedtosemanticclasses.
Tensorfactorizationwithsemanticaugmentation SSTFappliesbiasesfromsemanticclassestoitem(ortag)featurevectorsin tensorfactorizationto solvethesparsity problem. First,it createsaugmented tensorsby incorporatingrelationships com-posedofclassesofsparseobjects(e.g.multi-objectrelationships composedof“users”,“classesofsparseitems”,and“tags” orrelationships composed of “users”,“items”, and“classesof sparsetags”) intothe original tensor(Section 4.3.1). As an illustrationofhowthisisdone,supposethatitemsv1 andv2 in
Fig. 1
aresparseitems.SSTFcreatesanaugmentedtensor byincorporatingtherelationshipscomposedofu1 (oru2),CV1 (orCV2),and“Breathless”intotheoriginaltensor. Further-more,it determines multiplesets ofsparseobjects accordingto their degreeof sparsity andcreatesmultipleaugmented tensors;thisgivessemanticbiasestosparseobjectsaccordingtothedegreeofsparsity.Next,itfactorizestheoriginaltensor andaugmentedtensorssimultaneouslytocomputefeaturevectorsforobjectsandclasses(Section4.3.2).SSTFincorporates semanticbiasesintothetensorfactorizationbyupdatingthefeaturevectorsforobjectsusingthoseforclasses.Forexample, itcreates featurevectorsforclasses,CV1 andCV2, whichsharesemanticknowledge onsparse items, v1 and v2. Itthen usesthefeaturevectorsforclasses,CV1 and CV2,assemanticbiasesandincorporatesthemintofeaturevectorsforsparse items, v1andv2.Thisprocedureaimstosolvethesparsityproblem.4.2. Semanticgrounding
Wenowexplainsemanticgroundingbydisambiguation.
4.2.1. Linkingitemstotheclasses
Contentprovidersoftenusespecificvocabulariestomanageitems.Eachitemintheproviderusuallyhasseveral proper-ties(e.g.itemsintheMovieLensdatasethavepropertiessuchasthemovie’snameandyearofrelease;itemsintheLast.fm datasethavepropertiessuch astheartist’snameandpublishedalbumname).Thevocabulariesattheprovidersareoften quitesimple;thus,theydegradethetensorfactorizationwithsemanticaugmentation(explainedinnextsection)afterthe disambiguationprocessbecausesuchsimplevocabulariesexpressonlyrough-grainedsemanticsforitems.Thus,oursolution istolinkitemstoinstancesintheFreebaseortheDBPediavocabulariesandresolvetheambiguousitems. Forexample,in ourevaluation, theMovieLensoriginal itemvocabulary hasonly19classes,whilethat ofFreebasehas360classes.These additionaltermsarecriticaltothesuccessofourmethod.
Wenowexplaintheprocedureofthedisambiguation:(i)SSTFcreatesapropertyvectorforitemvn,pvn,whoseelements arethevaluesofthecorrespondingproperties.Italsocreatesapropertyvectorforinstanceej inFreebaseorDBPedia,pej, which has the same propertiesas pvn; (ii) it computes the cosine similarity of the property vectors and identifies the instancethathasthehighestsimilaritytovn.Foritemdisambiguation,thissimplestrategyworksquitewell,andSSTFcan
usethe FreebaseorDBPediavocabulary(i.e. genrevocabulary)to classifytheitem; it linkstheitemobject tothevalues (e.g.Downtempo)oftheinstances’property(i.e.Genre).
Forexample,supposethatmusicitem vnhastheproperties“name”and“publishedalbumname”;pvn is{“AIR”,{“Moon Safari”,“TalkieWalkie”,. . . ,“TheVirginSuicides”}}.Thereareseveralmusicinstanceswhosenamesare“AIR”inFreebase; however, thereare only individual instances ej amongthe published albums named “Moon Safari”, “Talkie Walkie”, and
“TheVirginSuicides”.Thus,ourmethodcomputesthatej hasthehighestsimilaritytovn,takesthegenrepropertyvalues
“Electronica”,“Downtempo”,“Spacerock”,“Psychedelicpop”,and“Progressiverock”,andassignsthemasvn’sclasses.
4.2.2. Linkingtagstotheclasses
SSTFclassifies tagsintothose representingthecontent ofitemsorthoseindicating thesubjectivityofusers regarding theitems, because[1,46]indicates that suchtags areusefulinimprovingpredictionaccuracy. Whendeterminingcontent tags, noun phrases are extracted from tags because the content tags are usually nouns [46]. Here, SSTF removes stop-words(e.g.,conjunctions),transformstheremainingphrasesintoParts ofSpeech(PoS)tuples,andcomparestheresulting setwiththefollowing setofPOS-tuplepatterns definedforclassifyingcontenttags:[
<
noun>
],[<
adjective><
noun>
], and [<
determiner><
noun>
].In a similar way,we can comparethe resultingset withthe followingset ofPOS-tuple patterns defined for classifying subjective tags [46]: [<
adjective>
], [<
adjective><
noun>
], [<
adverb>
], [<
adverb><
adjective>
], and [*<
pronoun>
*<
adjective>
*]. For example,“Bloody dracula” matches the [<
adjective><
noun>
] pattern. SSTF also uses the Stanford-parser[57]toexaminenegativeformsofpatternsandidentifytagslike“Notgood”.Welinkthoseextractedtagstovocabularyclasses.Becausetagsareassignedagainstitems,theyoftenreflecttheitem’s characteristics.Thus, weanalyzethepropertiesassignedto theitemswhenlinkingtags tothe classes.Ourmethodtakes thefollowingtwoapproaches:
(1)itcomparestagtk andnamesofFreebaseentriesindicatedbypropertiesofitementryvn assignedbytk.Ifone of
theentrynamesincludestk,itlinkstk tothatentryandconsidersthisentryastk’sclass.Forexample,tag“Hanksisgreat”
assignedtomovieitem“Terminal”,and“Terminal”isrelatedtothe“TomHanks”entrythroughthe“hasActor”propertyin Freebase.Inthiscase,itlinksthistagtothe“TomHanks”entry.
(2)Asfortagsthatcannot belinked toLODentries,ourmethodclassifiesthoseintoWordNetclasses.Asexplainedin Section3,eachwordinWordNetisclassifiedintooneormoreconcepts.Thus,weshouldselectthemostsuitableconcept fortkfordisambiguation. Weuseasemanticsimilaritymeasurementmethod[58]basedonthevectorspacemodel(VSM)
method[59] fordisambiguation. Atagtkassignedtoitem vn oftenreflectstheitem’s characteristics.Accordingly,we use
Fig. 2.ExamplesofaddingsemanticbiasestoitemfeaturevectorswhenX=2.(i) Augmentingtensors(elementsintensorshighlightedwithlightercolor havesparseritems).(ii) FactorizingtensorsintoD-dimensionalfeaturevectors.(iii) Updatingfeaturevectorsbyusingsemanticallybiasedfeaturevectors.
WordNetinstancesassociatedwithwordwintagtk.EachWordNetinstancewjhasadescriptiondj.Here,wisanouniftk
isacontenttagandisanadjectiveoradverbiftkisasubjectivetag.(ii)Itnextremovessomestop-wordsfromthecrawled
description dj andconstructsa vector wj whoseelements are wordsindj andwhosevaluesarethe observedcountsof
thecorrespondingwords.(iii)Italsocrawlstheitemdescriptionofvn anddescriptionsofvn’sgenresinFreebase/DBPedia.
It constructs a vector in whose elements are words in those descriptions andwhose values are the observed counts of
the corresponding words.Thus, in representsthe characteristics of vn aswell asthose of vn’s genres. (iv)After that, it
computes the cosinesimilarity ofin andwj,andfinally, itlinkstk to the WordNetclass that hasthe instance withthe
highestsimilarityvalue.
SSTFalsousesnon-content(subjective)tags,thoughitdoesnotapplysemanticstotheirfeaturevectors.
4.2.3. Linkingreviewstotheclasses
Weuseaspectandsubjectivephrasesinthereviewsastagsbecausetheyreflecttheusers’opinionsoftheitems[39,60]. Methods of extractingaspect andsubjective phrases are described in [39,60].Ofparticular note, we use theaspect tags extractedinasemantics-basedminingstudy[39].Thisstudyanalyzedreviewsinspecificobjectivedomains(i.e.musicand foods) andextractedaspect tags fromreview textsthat matchthe instances(i.e. artistsandfoods) inthe vocabulary for thatdomain.Thus,inthecurrentstudy,theextractedtagswerealreadylinkedtothevocabulary.Asforsubjectivetags,we needtodisambiguatethem.Forexample,weshouldanalyzehowthetag“sweet”istobeunderstoodwithregardto“Apple sauce”inthesentence“Theapple saucetastedsweet.”SSTFworksasfollows:(i) itextractssentencesthatincludeaspect tag aa andsubjective tagss. Itconstructsa vectorsa,s whoseelements are wordsinsentencesandwhosevaluesare the
observed countsofthe correspondingwords.(ii)It crawlsthedescriptions ofWordNetinstancesassociatedwithword w inss.Becausessisasubjectivetag, wisanadjectiveoradverb.(iii)Itconstructsavectorwj forthecrawleddescriptiondj
oftheWordNetinstance wjandcomputesthesimilarityofsa,sandwjinthesamewayaswithtagdisambiguation.(iv)It
linkssstotheWordNetclassthathastheWordNetinstancewiththehighestsimilarity.
4.3. Tensorfactorizationwithsemanticaugmentation
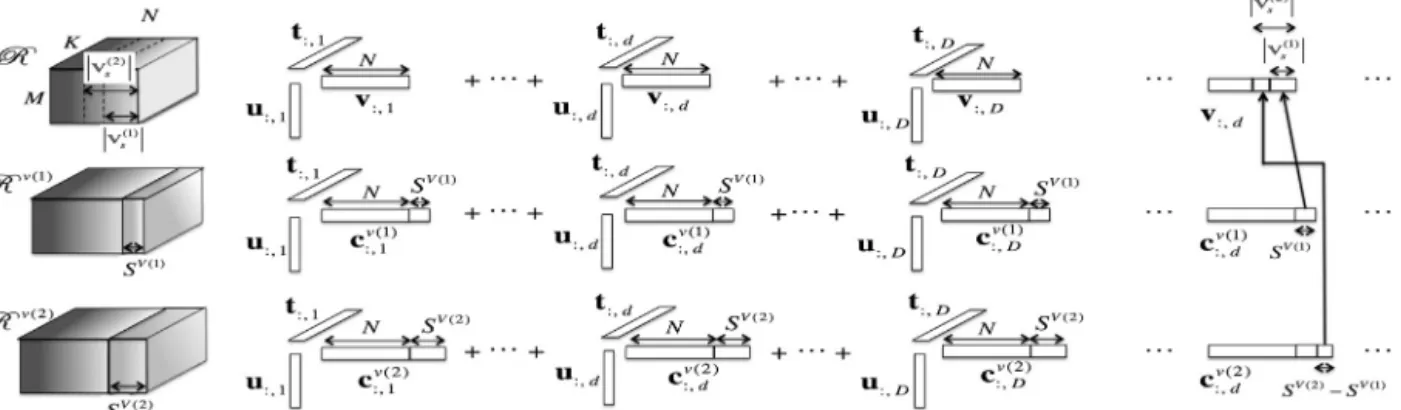
4.3.1. Semanticaugmentation
SSTF liftssparsely observedobjectstotheirclassesandutilizesthoseclassestoaugmentrelationships inatensor.This allows us toanalyze theshared knowledge that haslifted intothose classesduring thetensor factorizationandthereby solvethesparsityproblem(see
Fig. 2
-(i)).First,wedefineasetofsparseitems,denotedas
V
(si),forconstructingthei-thaugmentedtensorR
v(i).Thesetisdefinedasthegroupofi-thmostsparselyobserveditems,vss,amongallitems.Here,1
≤
i≤
X. X isthenumberofkindsofsets.Byinvestigating X setsinthesemanticaugmentationprocess,SSTF canapplya semanticbias toeachitemfeaturevector accordingtoits degreeofsparsity.Weseta 0/1flagtoindicatetheexistence ofrelationshipscomposed ofuserum,item
vn,andtagtk asom,n,k;
V
(si)iscomputedasfollows:(1)SSTF firstsortstheitemsfromtherarestto themostcommonandcreatesa listofitems:
{
vs(1),
vs(2),
. . . ,
vs(n−1),
vs(n)
}
.Forexample,vs(2)isnotlesssparselyobservedthanvs(1). (2)Ititeratesthefollowingstep(3)from j=
1 to j=
N.(3) If it satisfies thefollowing equation, SSTF addsthe j-thsparse item vs(j) to set
V
(si):(
|
V
(si)|
/
m,n,kom,n,k
)
< δ
(i)where
V
(si)initiallydoesnothaveanyitemsand|
V
(si)|
isthenumberofitemsinsetV
s(i).Ifnot,itstopstheiterationsandIntheaboveprocedure,
δ
(i) isaparameterusedtodeterminethenumberofsparseitemsinV
(si).Wealsoassumethatifi issmaller,
δ
i willalsobesmaller,e.g.,δ
(1)< δ
(2).Asmallerδ
i isusedtogeneratesparseritems.Typically,we setδ
(i) torange from0.05to 0.20 inaccordancewiththelong-tailcharacteristic [61] thatsparse itemsaccountfor5–20% ofall observations.Second,SSTFconstructsthei-thaugmentedtensor
R
v(i)byinsertingentriesforrelationshipscomposedofusers,classes ofsparseitemsinV
(si),andtagsintotheoriginaltensorR
asfollows:rv(i)m,j,k
=
rm,n,k
, (
1≤
j≤
N)
∩
(
j=
n)
rm,s,k
,
(
N<
j≤
(
N+
Sv(i)))
∩
(
s(vj−N)∈
f(
vs))
where f
(
vs)
is a function that returns the classes of item vs, Sv(i)= |
V(i)s f
(
vs)
|
is the number of classes that have the i-th mostsparse items, and sv(j−N) is a class of sparse item vs where(
j−
N)
represents the identifier ofthe class(1
≤
(
j−
N)
≤
Sv(i)). Thefirstlineintheaboveequationindicates thatSSTFusesthemulti-objectrelationships composed ofuserum,itemvn,andtagtk,observedintheoriginaltensor,increatingtheaugmentedtensorifj doesnotexceedN andj equals n.Thesecond lineindicatesthat SSTFalsousesthemulti-objectrelationships composedofuserum,class s(vj−N)
ofsparse item vs,andtag tk if j isgreater than N and s(vj−N) isa class ofsparse item vs.There are typicallyvery few observationsthathavethesameuserumandtagtkaswellassparseitemsvssthatbelongtothesameclasss(vj−N).Thus,
insuch cases,we randomlyset theratingvalue foran observationcomposed ofuserum,class sv(j−N), andtagtk among
thoseforobservationscomposedofum, vs,andtk.
In
Fig. 2
-(i),SSTFliftsitemsinthemostsparseitemsetV
s(1)totheirclasses(thesizeisSv(1))andcreatesanaugmentedtensor
R
v(1)fromtheoriginaltensorR
.Italsoliftsitemsinthesecond-mostsparseitemsetV
(2)s totheirclasses(thesizeisSv(2))andcreatesanaugmentedtensor
R
v(2) fromR
.Thesetofsparsetags
T
(si)isdefinedasthegroupofmostsparselyobservedtagsamongalltagsandiscomputedusingthe same procedure asthe set of sparse items
V
(si). So we omit the explanation of the procedure forcreatingT
( i) s . Wedenotethenumberofclassesthathavethei-thmostsparsetagsasSt(i)
= |
T(i)s f
(
ts)
|
andtheclassofsparsetagsass t(i) s .SSTFconstructsthei-thaugmentedtensor
R
t(i) inthesamewayasitcreatesR
v(i): rt(i)m,n,j=
rm,n,k
, (
1≤
j≤
K)
∩
(
j=
k)
rm,n,s
,
(
K<
j≤
(
K+
St(i)))
∩
(
st(j−K)∈
f(
ts))
4.3.2. Factorizationincorporatingsemanticbiases
SSTFincorporatessemanticbiasesintotensorfactorizationintheBPTFframework.
Factorizationapproach We willexplain theideasunderlying ourfactorizationmethod withthe helpof
Fig. 2
.Forease ofunderstanding,thisfigureshowstensorsfactorizedinto D-dimensionalrowvectors,whicharecontainedinmatricesU,V, andTanddenotedasu:,d,v:,d,andt:,d respectively,where1
≤
d≤
D.Theideasareasfollows:(1) SSTFsimultaneouslyfactorizestensors
R
,R
v(i)(1≤
i≤
X),andR
t(i)(1≤
i≤
X).Inparticular,itcreatesfeaturevectorscvj(i)andctj(i) byfactorizing
R
v(i) andR
t(i) andfeaturevectorsvn andtk by factorizing
R
.Thisenablesthesemanticbiasestobesharedduringthefactorization.Intheexampleshownin
Fig. 2
-(ii),R
,R
v(1),andR
v(2),aresimultaneously factorizedinto D-dimensionalfeaturevectors.(2) SSTFusesthesameprecision
α
,featurevectorsum,vn,andtk,andtheirhyper-parameterswhenfactorizingtheoriginaltensorandaugmentedtensors. Thus,the factorizationoftheoriginal tensorisinfluenced bythose oftheaugmented tensors through these shared parameters. It lets the factorizationof the original tensor be biasedby the semantic knowledge inthe augmented tensors.In Fig. 2-(ii), um andtk are shared amongthe factorizationsof
R
,R
v(1), andR
v(2).(3) SSTFupdatesthefeaturevectorforitem vn,vn,toanupdatedone,vn,byincorporatingthesetofsemanticallybiased
featurevectorsfor vn’s classes,
{
c(vN(i+)j)}
j,assemanticbiasesinto vn.This isdoneby iteratingthe followingequationfromi
=
1 toi=
X: vn=
⎧
⎪
⎨
⎪
⎩
(
1−
(i)
)
svj(i)∈f(vn)c v(i) (N+j) |f(vn)|(
vn∈
V
(i) s)
(i)v n (otherwise) (2)
Here,
(i)
(0
≤
(i)
≤
1)isaparameterthat determineshowstronglythesemanticbiasesare tobe appliedtov n.Thus,equation
(2)
returnsavectorvn that combinesfeaturevector vn andthesetofsemanticallybiasedfeaturevectorsfornon-sparseitem),itreturnsvn.tkisupdatedinasimilarwaybyincorporatingsemanticbiasesintothefeaturevectors
ofthesparsetags.
In Fig. 2-(iii), each rowvector c:v,(di) haslatent features for N items andthose for Sv(i) classes. The features for the classessharesemanticknowledgeonsparseitemsandsoareusefulforsolvingthesparsityproblem.SSTFincorporates thesefeatures intoitem-featurevectorsaccordingto thedegreeofsparsity; thefeaturesforthemostsparseitemsin
V
(1)s areupdatedbyusing Sv(1)features.Thefeaturesforthesecond-mostsparseitemsin
V
(2)s−
V
(1)s areupdated byusing Sv(2)
−
Sv(1)features.Inthisway,SSTFsolvesthesparsityproblembysharingparametersandupdatingfeaturevectorswithsemanticbiases whilefactorizingtensors.
Generativeprocess Thegenerativeprocessisasfollows:
1. Generate
U,
V,
T
Cv(i),and
Ct(i)
∼
W
(
|
W0,
ν
0),
whereU,
V,
T,
cv(i),and
ct(i) aretheprecisionmatrices forGaussians.
W
(
|
W0,
ν
0)
istheWishartdistributionofa D×
D randommatrixwith
ν
0 degreesoffreedomand a D×
DscalematrixW0.2. Generate
μ
U∼
N
(μ
0,
(β
0U
)
−1)
whereμ
U is the mean vector for a Gaussian. In the same way, generateμ
V∼
N
(μ
0,
(β
0V
)
−1),
μ
T∼
N
(μ
0,
(β
0T
)
−1),
μ
Cv(i)∼
N
(μ
0,
(β
0Cv(i)
)
−1),
andμ
Ct(i)∼
N
(μ
0,
(β
0Ct(i)
)
−1),
whereμ
V,μ
T,μ
Cv(i),andμ
Ct(i) arethemeanvectorsforGaussians.3. Generate
α
∼
W
(
˜
| ˜
W0,
ν
˜
0).
4. Foreachm
∈
(1
. . .
M),
generateumfromum∼
N
(μ
U,
−U1
).
5. Foreachn
∈
(1
. . .
N),
generatevn fromvn∼
N
(μ
V,
−V1
).
6. Foreachk
∈
(1
. . .
K),
generatetkfromtk∼
N
(μ
T,
−T1
).
7. Foreach i
∈
(1,
. . . ,
X)
and j∈
(1,
. . . ,
(
N+
Sv(i))),
generatecvj(i)fromcvj(i)∼
N
(μ
Cv(i),
−1
Cv(i)
).
8. Foreach i∈
(1,
. . . ,
X)
and j∈
(1,
. . . ,
(
K+
St(i))),
generatect(i)j fromc t(i)
j
∼
N
(μ
Ct(i),
−Ct1(i)
).
9. For eachn
∈
(1
. . .
N),
generatean updated feature vectorfor item vn, vn, by combiningvn withsemanticallybiasedfeaturevectorsforvn’sclasses,cv(N(i+)j)s,byusingEq.(2).
10. Foreachk
∈
(1
. . .
K),
generateanupdatedfeaturevectorfortagtk,tk,bycombiningtkwithasetofsemanticallybiasedfeaturevectorsfortk’sclasses,
{
c(t(Ki)+j)}
j,asfollows((0≤
(i)
≤
1)and(1
≤
i≤
X)):
tk
=
⎧
⎪
⎨
⎪
⎩
(
1−
(i)
)
stj(i)∈f(tk)c t(i) (K+j) |f(tk)|(
tk∈
T
(i) s)
(i)t k (otherwise) (3)
Thisequation indicatesthat iftk isa sparsetag,tk includessemanticbiasesfroma setofsemanticallybiasedfeature
vectorsfortk’sclasses,
{
c(t(Ki)+j)}
j,accordingtotk’sdegreeofsparsity.Otherwise,tkdoesnotincludesemanticbiases.11. Foreachnon-missingentry
(
m,
n,
k),
generaterm,n,kasfollows:rm,n,k
∼
N
(
D d=1 um,d·
vn,d·
tk,d),
α
− 1InferringwithMarkovChainMonteCarlo Here,weexplainhowtocomputethepredictivedistributionforunobservedratings.
Differently from the BPTF model (see Eq.(1)), SSTF should consider the augmented tensors and the degree of sparsity observed foritemsandtagsinordertocompute thepredictivedistribution.Thus, thepredictivedistributioniscomputed asfollows: p
(
R
ˆ
|
R
,
R
v,
R
t,
zv,
zt)
=
p(
R
ˆ
|
U,
V,
T,
Cv,
Ct,
zv,
zt,
α
)
p(
U,
V,
T,
Cv,
Ct,
U,
V,
Cv,
Ct,
zv,
zt,
α
|
R
,
R
v,
R
t,
zv,
zt)
d{
U,
V,
T,
Cv,
Ct,
U,
V,
T,
Cv,
Ct,
α
}
,
(4) whereR
v≡ {
R
v(i)}
X i=1,R
t≡ {
R
t(i)}
iX=1,zv≡ {
zv(i)}
Xi=1,zt≡ {
zt(i)}
iX=1, cv≡ {
cv(i)}
iX=1,ct≡ {
ct(i)}
iX=1,Cv
≡ {
Cv(i)
}
iX=1,andCt
≡ {
Ct(i)
}
Xi=1.Eq.(4)involvesamulti-dimensionalintegralthatcannotbecomputedanalytically.Thus,SSTFviewsEq.(4)asthe expec-tationofp