ContentslistsavailableatScienceDirect
Pattern
Recognition
Letters
journalhomepage:www.elsevier.com/locate/patrec
Text-independent
writer
identification
using
convolutional
neural
network
Hung
Tuan
Nguyen
a,
Cuong Tuan
Nguyen
a,
Takeya
Ino
a,
Bipin
Indurkhya
b,
Masaki
Nakagawa
a ,∗aDepartmentofComputerandInformationSciences,TokyoUniversityofAgricultureandTechnology,2-24-16Naka-cho,Koganei-shi,Tokyo184-8588Japan bInstituteofPhilosophy,JagiellonianUniversity,Cracow,Poland
a
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Availableonline25July2018
a
b
s
t
r
a
c
t
Thetext-independentapproachtowriteridentificationdoesnot requirethe writertowritesome pre-determinedtext.Previous researchontext-independentwriteridentificationhasbeenbasedon identi-fyingwriter-specificfeaturesdesignedbyexperts.However,inthe lastdecade, deeplearningmethods havebeensuccessfullyappliedtolearnfeaturesfromdataautomatically.Weproposehereanend-to-end deep-learningmethodfortext-independentwriteridentificationthat doesnot requireprior identifica-tionoffeatures.AConvolutionalNeuralNetwork(CNN)istrainedinitiallytoextractlocalfeatures,which representcharacteristicsofindividualhandwritinginthewholecharacterimagesandtheirsub-regions. RandomlysampledtuplesofimagesfromthetrainingsetareusedtotraintheCNNandaggregatethe ex-tractedlocalfeaturesofimagesfromthetuplestoformglobalfeatures.Foreverytrainingepoch,the pro-cessofrandomlysamplingtuplesisrepeated,whichisequivalenttoalargenumberoftrainingpatterns beingpreparedfor training theCNN for text-independentwriteridentification. Weconducted experi-mentsontheJEITA-HPdatabaseofofflinehandwrittenJapanesecharacterpatterns.With200characters, ourmethodachievedanaccuracyof99.97%toclassify100writers.Evenwhenusing50 charactersfor 100writersor100charactersfor400writers,ourmethodachievedaccuracylevelsof92.80%or93.82%, respectively.WeconductedfurtherexperimentsontheFiremakerandIAMdatabasesofoffline handwrit-tenEnglishtext.Usingonlyonepageperwritertotrain,ourmethodachievedover91.81%accuracyto classify900writers.Overall,weachievedabetterperformancethanthepreviouslypublishedbestresult basedonhandcraftedfeatures and clusteringalgorithms, whichdemonstratesthe effectivenessofour methodforhandwrittenEnglishtextalso.
© 2018ElsevierB.V.Allrightsreserved.
1. Introduction
Writer identificationhasbeen studiedformanyyearsbecause ithaspractical applicationsforforgerydetectionandforensic sci-ence. Since the mid-1960s, computational approaches have been developedforwriteridentification.Areviewofthestate-of-the-art methodsfor writer verificationandidentificationfrom the1960s tothe1980s canbe found inPlamondonandLorette[23] .In the early days, thisresearch was focused on using offline signatures to identifythe writer [5,11] because the signatureswere consid-eredasindividual signsfromthe past.Yoshimuraetal.proposed a text-dependentwriter identification method usinghandwritten text [33,34] .Due tothe difficulty ofcollecting multiple signature
∗ Correspondingauthor.
E-mailaddresses: [email protected] (T.Ino),[email protected] (B.Indurkhya),[email protected] (M.Nakagawa).
patternsandtheavailabilityoflargedatabasesofhandwrittentext from the early 2000s, there have been many studies on writer identification employing handwritten text. Srihari et al. [29] ar-gued that theindividualityof handwrittentext isappropriate for thewriteridentificationtaskandmachinelearningalgorithmscan betrainedforthistaskwithalargenumberofwriters.
There aretwo main approachesforwriter identification: text-dependent and text-independent. The text-dependent approach demands thesametext tobe writtenwhilethe text-independent approachdoesnotrequireanyparticulartext. Thewriter identifi-cationresearch sofar hasfocusedon decidingwhetherthegiven handwrittencharactersarewrittenbythepersonwhose handwrit-tensamplepatternsinthesamecategoriesareavailable.The prob-lem with this approach is that we cannot always find the sam-ple patterns in the same categories as the target patterns. The text-independent approach does not require collecting the same category patterns, which is useful in situations like forensic sci-ence. However, the text-independent approach is more compli-https://doi.org/10.1016/j.patrec.2018.07.022
cated than the text-dependentapproach because it must extract writer-specificfeaturesregardlessofsignatures,specifiedletters,or symbolstobecompared.Intheresearchpresentedhere,wefocus onsolvingthetext-independentwriteridentificationtask.
Recently, Sreeraj and Idicula [28] reviewed both the text-dependent and text-independent writer identification methods from the late 1990s to 2010. These methods employed textual features [24] , edge-based features [8] andallograph features [6] . In addition, they reviewed many approaches for writer identifi-cation basedon extractedfeatures:forinstance, cosinesimilarity
[1] ,k-nearest neighbor [17] andclusteringmethods [6,7] . Among these methods, the approach by Bulacu and Schomaker [6] pro-videsthetheoretical foundationforwriteridentificationbasedon handwrittentext,whereeachhandwritingpatternisdescribedby a two-levelpsychomotor process.In thisapproach,the handwrit-tenpatternsareproducedfromasophisticatedsequenceof think-ing andhandmovements, whichare characteristicofeach writer depending on his/her cognitive system, nervous system, muscle system, gender, age,schooling, andso on. Therefore, each writer hashis/herallographswheneverhe/shewritesaletterwhich sug-geststhatitispossibletoidentifyapersonbasedonhis/her writ-ing behavior. Bulacu and Schomaker [6] conducted experiments on thehandwritingdatabases with900 writersusingtheir hand-craftedfeaturesandclusteringmethods.Thebestaccuracyresults achieved were 80% when usinga singlehandcrafted feature and 87%whenusingcombinedfeatures.
There are two kindsof handwrittentext patterns: online pat-terns(timeseriesofpentrajectoriestowritetext)andoffline pat-terns (handwritten text images). Consequently, there are online andoffline methods ofwriter identification.Moreover, two kinds offeaturesareusuallyemployedforwriteridentification:local fea-turesandglobalfeatures.Forofflinewriteridentification,local fea-tures are extracted fromsub-regions of an image basedon local descriptorssuchasscale-invariantfeaturestransform(SIFT)[9,31] , localbinarypattern(LBP),local phasequantization(LPQ)[2] ,and contourfeatures [27] .Global featuresare extractedfroman input image atthedocumentlevelandparagraphlevelusingink width
[4] ,structuralfeatures [21] ,andtexturefeatures [1,13] .Moreover, there are several studies on combining local and global features
[6,10,29] .
The approachpresentedinthispaperdealswithofflinewriter identification usingthe trained features from Convolutional Neu-ralNetworks(CNNs).Themaincontributionsofthispaperarethe sub-region levelandcharacterlevel localfeatureextractors,three aggregationmethodstoformglobalfeaturesandasampling mech-anismfortrainingaCNN.Ourmethodnotonlyusesisolated char-actersasinputstotheCNNbutisalsoabletoworkwellwith sub-images extractedfrom handwritten text pages. Moreover, the ef-fectivenessofourmethodisdemonstratedbyexperimentingwith boththeJapaneseandtheEnglishhandwritingdatabases.
Therestofthispaperisorganizedasfollows:Section 2 presents abriefsurveyofrecentresearchontext-independentwriter iden-tificationusingCNNs.Section 3 presentsthedetailsofourmethod, whichincorporateslocalfeatureextraction,featureaggregationto formglobalfeaturesandasamplingmechanism.Section 4 presents experimental results demonstrating the efficacy of our proposed method on Japanese and English handwriting databases. In this section(Section 4 ),ourmethodiscomparedwiththebestexisting approachthatuseshandcraftedfeaturesandclusteringmethodson English databases.Finally,Section 5 presentsour conclusionsand suggestionsforfutureresearch.
2. Relatedworks
This sectionbriefly reviews relatedworksspecific tothe text-independent approach.Asit requireswriter-specificfeatures,
sev-erallocal features foroffline writer identificationhave been pro-posedto be extracted atthe character level.Previous studies fo-cusedon writer-specificfeatures fromthe texture. Bensefia etal.
[1] proposed morphological grapheme-based features extracted fromthegraphicalfragmentsofhandwrittenpatterns.Bulacuetal.
[8] proposed edge-based features combined with the connected-componentcontours andcurvatures ofhandwritten samples.The contourandcurvaturefeatureswerealsousedbySiddiqiand Vin-cent[27] toextractwriter-specificlocalinformationonorientation andshape.
Dueto their superiorperformance on imageclassification and matchingtasks,LBPandSIFTdescriptorswereemployedtoextract writer-specificlocalfeatures.Bertolinietal.[2] employedthe LBP-based and LPQ-based local features, which yielded an improved performanceonboththewriter verificationandtheidentification tasks.Christleinetal.[9] andWuetal.[31] employedSIFT descrip-torstoextractscaleandorientationfeaturesattheSIFTkey-points, whichresultedinahigheraccuracycomparedwiththeedge-based andthecontourfeatures.
BulacuandSchomaker[6] proposed acombinationof texture-leveland allograph-levelfeatures. For texture-levelfeatures, they considered probability distribution functions (PDFs) computed fromcontours, connected components,gray-scale images and bi-naryimages.Fortheallographfeatures,theyemployedacommon codebookofshapestorepresentthewriter-specificprobability dis-tribution ofink-trace fragments(graphemes) dueto the assump-tionthatindividualstochasticallywritesgraphemes.
Besides,manyglobalfeatureshavebeenstudiedto obtain dis-criminativeinformationofindividualwritersatthedocumentand the text-line levels. Marti et al. [21] proposed several structural features based on the width, slant andheight of the three main writing zones for each text line. By gathering these extracted globalfeaturesfromeverytextlinetoidentifythewriterofapage, their system achieved 90.7% accuracy for identifying 20 writers from100 pages.Brink etal.[4] proposed quillfeatures based on pixelcontoursto representtheink-trace width,which achieveda highenoughaccuracy tobe usedby domainexperts.In addition, therewereseveralstudiesoncombininglocalandglobalfeatures
[6,10] .
Previous research on writer identification used various classi-fiers such as distance-based classifier, Support Vector Machines (SVM)[15] ,HiddenMarkovModel(HMM) [25] ,Fuzzybased clas-sifier[30] andsoon.Forexample,approachesemploying distance-basedclassifiers usedifferent metrics likeEuclidean distance[7] , Chi-squareandHammingdistance[6] ,Bhattacharyyadistance[27] , etc.
Neural Network-based techniques have also been applied to writeridentification inrecentyears; forexampleFiel and Sablat-nig[14] ,Christleinetal.[10] .Thesetechniquesusedthe meritof CNNs toaddress the problemof feature extractionautomatically, becausehand-craftedfeaturesare difficulttodefine asmentioned above.Duringthelastdecade,deeplearningtechniqueshavebeen successfullyapplied to manyrecognition tasks [12,16,18] because theyare effectiveinlearningrelevantfeatures automatically. This suggeststhatthesetechniquescanalsobeappliedtoextract effec-tive writer-specific features from handwritten patterns automati-cally.
Forthe writer identification task,Fiel and Sablatnig [14] em-ployedCNNsaslocalfeatureextractors.Intheirapproach,thelast fullyconnectedlayeriseliminated becausethelayerjustabove it extractedadequatefeaturestoidentifythewriter.Then,themean vectorfor theinput image iscomputedusing all itslocal feature vectors, which is used for identifying the writer based on Chi-Squaredistance.Thismethodrequiresapreprocessingstepfor im-agebinarizationandnormalization,soitsperformancedependson thedatabaseandthepreprocessingmethod.
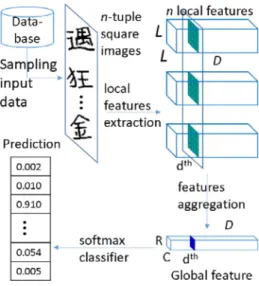
Fig.1. Overviewofourmethod.
Christlein et al.[10] presentedanother strategy: after extract-inglocalfeaturesfromCNNs,theyareusedtoformglobalfeatures basedonGaussian MixtureModels(GMM)super-vectorencoding. Thiscombinationmethod performedbetter than that of Fiel and Sablatnig[14] .Moreover,CNNsachievedabetterperformancethan thetraditionallocaldescriptorssuchasSIFT.
Yang et al. [32] proposed an end-to-end online text-independent writer identification system, which generates many artificial patterns from a single original online character pattern bydroppingoneormorestrokes.Theartificialpatternsformedby thesame original patternare fed into CNNs to get a probability distribution of each character. Then, the average distributions of allthecharacterpatternsinthedocumentarecomputedandused for identifying the writer. Even though this system achieved a highaccuracy, it requires many character patterns in documents tomaketheaveragesreliable.Moreover,itsDropSegment method isdifficulttoapplyforofflinehandwrittentextpatterns.
As mentioned above, the systemsof Christlein et al.[10] and FielandSablatnig[14] havetwoseparatetrainingsteps:feature ex-tractionandencoding,whereCNNsare pre-trainedandemployed forlocalfeaturesextraction.Thatis,thepre-trainedCNNsarefixed duringthesecond stepwhiletrainingtheencoder, whichreduces theperformance of thewhole systembecause the CNNs are not updated.Therefore,weproposetousean end-to-endnetworkfor writer identification,where the CNN-based feature extractor and theneuralnetwork-based classifier areconnectedandtrained to-gether.However,themostnotabledifferenceofourapproach com-paredtoothersisoursamplingandfeatureaggregationmethods.
3. Proposedmethod
3.1.Basicapproach
We proposeherean end-to-endmethod basedondeep learn-ing, which extracts features using CNNs and combines the ex-tractedfeatures fromhandwrittentextimagesofmultiple charac-terstoretainwriter-specificfeatureswhilereducingcharacterclass specificfeaturesasshowninFig. 1 .
First, handwritten square images of an individual writer are randomly sampled to form n-tuple images. We employ square shape imagessince Kanji (Chinese characters)have square shape andthe squareshape isratherstandardforextractingfeatures in asub-regionforKanjiandWesternalphabets.
Secondly,everyimagefromn-tupleimagesisfedtoaCNNlocal feature extractor. Due to the difficulty of handcrafting good
fea-tures to classify writers, the proposed method uses CNN for au-tomaticallylearningwriter-specificfeaturesfromhandwriting pat-terns. By using a new way of organizing training samples as n -tuple images, a CNN is able to extract text-independent writer-specificfeatures.
Thirdly,theextractedlocalfeaturesare aggregatedby aglobal featureaggregatorindifferentways,forexamplebasedonthe av-erageorthe maximum.Byformingglobalfeatures frommultiple characterimages,weexpect thatthewriter specificfeatures such asstructure,balance,slant,ligature,serif,andsooncould be ob-tainedindependentlyfromthetext.
Fourthly, the aggregated features are fed to a softmax classi-fier(fullyconnectedlayerconsistingofNfc unitswhichequalsthe numberofwriters)tomakeaprediction.
Asallthecomponents(localfeatureextractor,globalfeature ag-gregatorandclassifier)oftheproposednetworkaredifferentiable, the wholenetwork can be trainedby the stochastic gradient de-scentalgorithm,whichhelpstodiscovernotonlythelocalfeatures butalsotheglobalfeaturesthatarehardtodefinebyhandcrafted features.
Ourapproachincorporatesbothlocalandglobalfeatures,which aretextindependent,i.e.,charactercategoryinvariant.Weconsider twolevelsoflocalfeatures:thesub-regionlevelandthecharacter level. Thesub-region level,extractedfrom sub-regionsof a char-acter image, captures writer-specific features in writing strokes, whichare directlyrelatedto thepsychomotor process toidentify the writer. Thecharacter level, extractedfroma character image, captures features related to writing styles such ascharacter bal-ancing,characterlayoutsorstrokecombinations.
3.2. Localfeatureatthesub-regionlevel
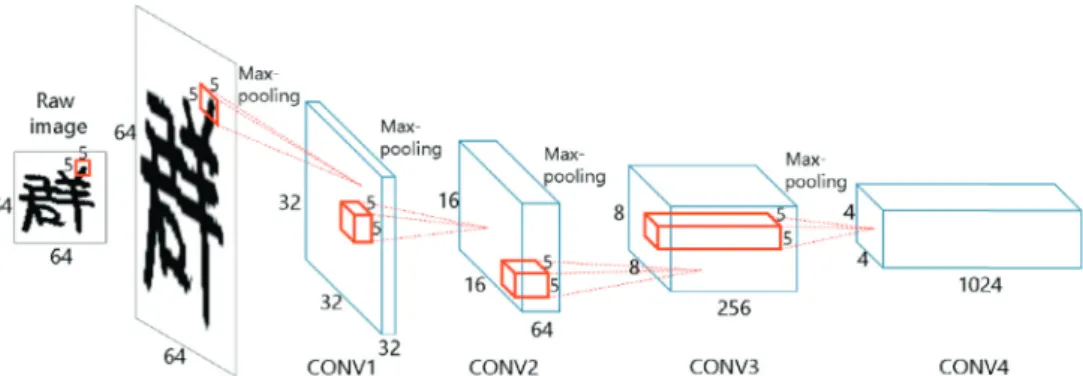
WeusethemodelillustratedinFig. 2 (a)forextractingfeatures fromsub-regionsinacharacterimage.Eachconvolutionlayeruses akernelsizeof5×5,stridestepof2andpaddingsizeof2.Each max-poolinglayeruses akernelsize of2×2andstridestepof2. Weuse4stagesofprocessing:ineachstage,aconvolutionallayer is followed by a max-pooling layer to produce the 4×4 feature maps froma 64×64 input image. Each columnin these feature maps can be considered asthe features from a sub-region of an inputcharacterimage asshowninFig. 2 (b).Specifically,each col-umn ofthe 4×4 feature maps represents the features extracted froma16×16sub-regionoftheentirecharacterimage.These lo-cal features (at thesub-region level) ofeach character image are extractedasa4×4×1024-dimensionalmatrix.
3.3. Localfeaturesatthecharacterlevel
Forextractingfeatures atthe character level,we use3 blocks of a convolutional layerfollowed by a max-pooling layerto pro-duce8×8feature mapsfroma64×64input imageasillustrated in Fig. 3 . These feature maps are then fed to a fully connected layer to extractfeatures ofthe entireimage of theinput charac-ter. Consequently, these local features (at the character level) of each character are extracted and represented by a 1×1× 1024-dimensionalmatrix.Insummary,thesub-regionlevellocalfeature extractorreceivesasquareinputimageandreturnsalocalfeature of size 4×4×1024 asshown in Fig. 2 . The character level local featureextractoralsoreceivesasquare inputimageandreturnsa localfeatureofsize1×1×1024asshowninFig. 3 .Thus,boththe sub-regionlevelandthecharacterlevellocalfeaturescanbe gen-eralisedasL×L×Dshapes.
(a)The model architecture consists of 4 blocks of a convolution layer followed by a max-pooling layer with the numbers of filters being 32, 64, 256, and 1024, respectively. The red block in each convolution layer indicates the convolution kernel.
(b)The red block of CONV1 is the extracted features from the 16x16 sub-region of an input image. Each red block of other convolution layers indicates the features from the red block of its previous convolution layer. Each green block in the convolution layer shows the bounding box from which the sub-region
image features could be extracted.
Fig.2. CNNmodelforextractingsub-regionslevellocalfeatures.
Fig.3. CNNmodelforextractingcharacterlevellocalfeatures.
Afterthreeconvolutionandpoolingblocks,theextractedfeaturesarefedtoafullyconnectedlayerFC4togetthecharacterlevellocalfeatures.
3.4. Globalfeaturesfrommultiplecharacters
Local features froma single character image may not contain enough informationforidentifyingthe writer. Therefore,we con-sider extractingglobalfeatures forwriter identificationby aggre-gatinglocalfeatures.Insteadofusingthewholedocumentor para-graph,we extract globalfeatures frommultiplecharacter images. Global features such as structuralfeatures, slant, and so on may varyfromone textimagetoanother,butwe expectthattheycan beextractedreliablyfrommultiplecharacterimages.
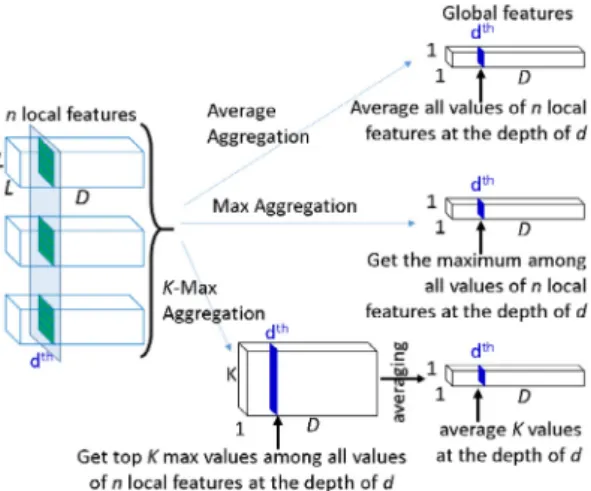
Fig. 4 shows three aggregation methods for obtaining global featuresfromn-tupleimages,whicharefedtoCNNstoextract lo-cal features. The localfeature vector ofeach image isof thesize L×L×D. Next,an aggregationmethod is applied to get a global featurevector.
We consider two basic methods for combining the local fea-tures(features extractedfrom thesub-region leveland the char-acterlevel)toformglobalfeatures(featuresfrommultiple charac-ters)asshowninFig. 4 .Oneis“AverageAggregation” (AA), which worksbycomputingtheaverageofallthevaluesalongthedepth ofnlocalfeaturevectors,asshowninEq. (1) .
global_feature[d] 1≤d≤D = 1 nL2
n t L i L j local_featuret[i, j, d] (1) where global_feature[d] is the dth element of the global feature vector. The local_featuret is the tth extractedlocal feature vector amongnextracted localfeature vectorsfromn-tupleimages.For AA,eachelement oftheglobalfeature vectoriscomputedby av-eragingall values ofn local featurevectors atdepth d.Thus, AAFig.4. Threeaggregationmethodstoformtheglobalfeatures.
producesmorerobustglobalfeaturescomparedwiththelocal fea-tures.
The other method is “Max Aggregation” (MA), which works by selecting the maximum value along the depth dimension, as showninEq. (2) .
global_feature[d] 1≤d≤D
= max
1≤t≤n;1≤i,j≤L
{
local_featuret[i, j, d]}
(2) MAselectsthemostrelevantlocalfeaturefromalltheelements ofnlocalfeaturevectorsatdepthdforwriteridentification.For the AA method, the common features shared among dif-ferent characters or their sub-regions are made more robust by averaging thelocal features. On the other hand, the MA method candiscover relevant features that maynot appear inall the lo-calfeaturesinsomedimension.Thedifferencebetweenthesetwo methodssuggeststhatcombiningthemmayresultinabetter ag-gregation.We alsoconsiderincorporatingthemethodof“Average ofK-Max Aggregation” (AKMA),whichcomputestheaverageofK largestvalues fromall the elements ofn local featurevectors at depthd,toyieldaglobalfeatureasshowninEq. (3) .
global_feature[d] 1≤d≤D = 1 K K k
K−max 1≤t≤n;1≤i,j≤L{
local_f eaturet[i, j, d]}
(3) wheretheK-maxfunctionyieldsKmaximumvaluesamongallthe nlocalfeaturevectorsatdepthd.Fig. 4 showsthree aggregation methods toform a global fea-ture.Theglobalfeaturesofthesethreeaggregationmethods have thesameshapeof1×1×1024,whichisaninstanceofthegeneral R×C×Dglobalshape.
3.5.Randomsamplingoftrainingpatterns
We assume that each writer providesat leastNs samples.For everytrainingepoch,weneedtopreparethetrainingdataby iter-atingthefollowingstepsptimes.
Step 1: Prepare m sets of n-tuples from Ns images (m is the greatest integer lessthanor equalto Ns/n),where each n -tuplecontainsnimagesasshowninFig. 5 .
Step2:RandomlyshuffleallNsimages.
Step3:GotoStep1.
Thus, the prepared data contains m sets of n-tuple images p times asshown in Fig. 5 . After all the n-tuples of the prepared dataareusedtotrainthenetwork,wemovetothenextepoch.
Fig.5. Randomlysampledtrainingimages.
Thetrainingepochsarerepeateduntilthereisnoimprovement inthevalidationaccuracy.Byreorderingimagesofn-tuplesineach iteration,andineachepoch,thenetworklayersaretrainedto ex-tractwriter-specificfeatureswithouttextdependency.
4. Experiments
4.1. Databases
4.1.1. JEITA-HPdatabase
We employed the JEITA-HP handwritten Kanji character pat-terndatabase(hereafter,JEITA-HP),whichispreparedby Hewlett-Packard Japan anddistributed by JapanElectronics and Informa-tion Technology Industries Association (JEITA) [19] . The JEITA-HP database consists of Dataset A and Dataset B, containing hand-writtencharacterpatternsfrom480and100writers, respectively. In JEITA-HP,foreach writer, thereare 3306 handwrittensamples (patterns)belonging to3,214 categoriesincluding2,965 Kanji, 82 Hiragana,10numerals,and157othercategories(Englishalphabet, Katakanaandsymbols).EverywriterwrotetwiceforeachHiragana andnumeral category andonce foreach ofthe other categories, which resulted in 3306=2 × (82+10)+2965+157 samples. In ourexperiments, we usedKanji character patternsonly fromthe writersintheDatasetA.First,werandomlysplit2,965Kanji char-actercategoriesinto3subsetsasfollows:2,000categoriesforthe trainingset,400 categoriesforthevalidationsetandthe remain-ingcategoriesforthetestingset.Thevalidationsetisusedtostop thetrainingprocessearliertoavoidoverfittingthenetwork.
Asthe numberofwritersandthenumberoftrainingsamples aredifferentforeachexperiment,werandomlyselectedwritersas wellassamplesfromthetrainingsetatthebeginningofeach ex-periment.IntheexperimentsdescribedinSections4.3.1 ,4.3.2 and
4.3.3 ,wechose100writersatrandom(Nwriters=100)whilein Sec-tion 4.3.4, we chose a variable numberof writersNwriters to ver-ifytheperformance ofournetwork.Foreachwriter,werandomly selecteda subset ofsamples(Ncharacter_img)fortraining, insteadof usingall the2000samplesin thetrainingset.Thus, theselected subsetisdifferentforeachexperiment.
4.1.2. FiremakerandIAMdatabases
InordertovalidateourmethodforEnglish,andtocompareour approach withthehandcrafted-feature-based approachof [6] , we employedtheFiremakerandIAMdatabasesofhandwrittentext.
For the Firemaker database provided by 250 writers, there are four subsets which are collected by different requirements
[26] . The first subset containsthe text-copyingpages using nor-mal handwriting which was used as the training and validation sets.Thesecondsubsetcontainsthetext-copyingpagesusingonly uppercase characters, which is unusual for handwritten text and
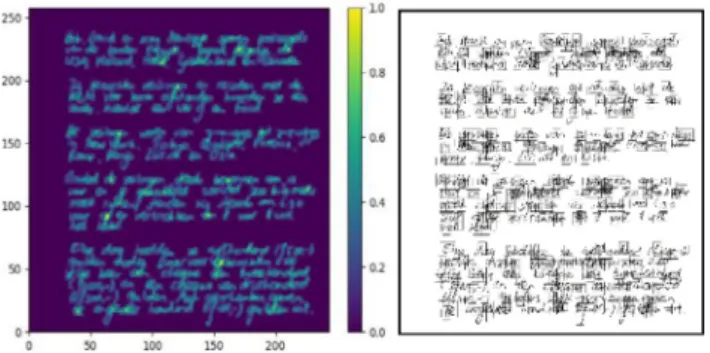
Fig.6. Sub-imagesextractionfromahandwrittentextpageintheFiremakerand IAMdatabases.
thereforewasnotusedinourexperiments.The thirdsubset con-tainsforgedtext,wherethewriterswereaskedtowriteina differ-entstyle,whichwasalsonotusedinourexperiments.Thefourth subset containsfree handwritten text to describe the content of a givencartoonwhich wasusedasthetestingset.Thus,foreach writer, we usedhis/hertext-copy pagefortraining/validating and freehandwrittentextpagefortesting.
IntheIAMdatabaseprovidedby650writers,thecharacter pat-ternsprovidedbyeachwriterrangedfrom1page(350writers)to 59pages (1writer)[22] .Duetothisimbalanceinthe numberof patterns from the writers, we tried to balance it as follows. For thewriterswhoprovidedonlyonepage,theirpagesweredivided roughly into two halves: the first half fortraining/validation and the second half fortesting. Forthe writerswho provided two or morepages,onlythefirsttwopages wereselected:thefirstpage was usedfor training/validationand thesecond pagefor testing. Hence,350writershadahalfpageandother300writershadone pagefortraining.
ForpreprocessingpagesfromtheFiremakerandIAMdatabases, we employedtheOtsubinarizationmethod.Thehandwrittentext in these two databases is written cursively, which is difficult to segment and separate into individual characters. However, our methodisdesignedtoextractwriter-specificfeaturesbasedonthe sub-regions of characters, which means that we do not require isolated characters as input. Therefore, we do not need to seg-ment the handwritten text in the Firemaker and IAMdatabases. Instead, as shown in Fig. 6 , we extracted Nsub_img sub-images of ksub_img × ksub_img pixels from the binarized page based on the handwritten text probabilities. Inorder to extract the probability of everypixel asshowninthe left image ofFig. 6 , we applieda 32×32 averagefilteronthebinarizedpageimage, andthen nor-malized theobtainedvaluesinto[0,1] range.Usingthe probabili-tiesintheleftimage,wesampled500(Nsub_img=500)sub-images of size 64×64 (ksub_img=64). Note that each of these 500 sub-imagescouldbean isolatedcharacter,asub-regionofacharacter, orsometimesevensub-regionsofseveralcharacters.Similartothe experimentsonJEITA-HP,werandomlyselectedwritersand train-ingsamplesfromthetrainingsetbasedonthenumberofwriters (Nwriters) and the numberof sub-images (Nsub_img), because these valuesweredifferentineachexperiment.
4.2. Parameters
IntheexperimentsofSection 4.3.2 ,weemployeddifferentsizes of n-tuples to find the optimum value of n. Then, we employed thebestsizeof20-tuplesforlaterexperiments.Besides,the num-ber ofcharacterimagesfortraining(Ncharacter_img) isoptimizedby theexperimentsdescribesinSection 4.3.3 .FortheFiremakerand IAMdatabases,thevalue ofNsub_imgwastakentobe500as men-tioned inSection 4.1.2 .The value ofm for m-sets is thegreatest integerlessthanorequaltoNcharacter_img/nfortheexperimentson
Table1
Accuracy(%)oflocalfeaturesanddifferentaggregationmethodson the JEITA-HPtestingset.
Aggregation Sub-regionlevelfeatures Characterlevelfeatures
None 48.47 40.16 AA 99.97 99.78 MA 92.00 91.78 AKMA(K=10) 99.53 98.56 AKMA(K=20) 99.89 99.45 AKMA(K=40) 99.82 99.78 AKMA(K=50) 99.86 99.80
theJEITA-HPdatabase.FortheexperimentsontheFiremakerand IAM databases, it was the greatest integer less than orequal to Nsub_img/n.In allofthe followingexperiments,the numberofthe trainingandevaluationiterationwassetto20foreachwriter(i.e., p=20)topreparetrainingpatternsforeachepoch.
WeimplementedournetworkbyTensorflowandexecuted the trainingprocess onaGraphicsProcessingUnit(GPU)forreducing thetrainingtime bythebatchsizeof10.Thus,amini-batch con-tainedn-tuples by 10writers. We also employed theAdam opti-mizer[20] totrainournetwork,withthelearningrateas10−4,
β
1 as0.9and
β
2 as0.999. The trainingprocess wasstopped earlier ifthere wasno improvement in thevalidation accuracy after 20 epochs.ForevaluatingourmethodontheFiremakerandIAMdatabases, we sampled a singlen-tuple from the handwritten test page by eachwriterandfedittothetrainednetworktoidentifythewriter. We made thisevaluation process fordifferent n-tuples from the pagefivetimesandsimplytooktheiraveragetoidentifythewriter (namedasfiven-tuples)aspresentedinSection 4.4.1 .
4.3.ExperimentsontheJEITA-HPdatabase
Inthe followingsubsections, we presentour experimental re-sultsonthe JEITA-HPdatabase. First,each localfeature wasused to build the writer identificationmodel forevaluating its perfor-mance.Secondly,thethreeaggregationmethodsmentionedabove were employed on each localfeature to evaluate their individual performances.ThesetwostepsarepresentedinSection 4.3.1 .
Thirdly,the hyper-parameters, which consist of the tuplesize (n), the number of character images for training (Ncharacter_img) andthenumber ofwriters(Nwriters) were optimized asshownin Sections 4.3.2 ,4.3.3 and4.3.4 ,respectively.Accordingtotheresults fromthesesections,wechosethebesthyper-parameters forlater experimentsontheFiremakerandIAMdatabases(Section 4.4 ). 4.3.1. Experimentsonlocalfeaturesandaggregationmethods
Tocompare the localfeatures and globalfeatures with differ-entaggregationmethods, experimentswere conductedusing500 trainingcharactersofeachwriter toidentify 100writers. The re-sultsareshowninTable 1 .Thefirstrowshowstheresultsoflocal features asthere wasnoapplied aggregation.The followingrows show the results with aggregations, that is, global features. The global features are much better than the local features and the sub-region level features are better than the character level fea-tures.Theaverageaggregationmethodachievedthebestaccuracy of99.97%.Therefore,inthefollowingexperiments,weonlyapplied theaverageaggregationmethodtoformglobalfeaturesfromlocal features.
Thevalue ofK inAKMAmethodwassettobe 10,20,40and 50forthesub-region levelfeatures aswell asthecharacter level features.The AKMA methodachieveda higheraccuracy than the MA method forboth the sub-region and character level features asit preservesmoreinformationfromlocalfeaturesthan theMA method.Theaverageaggregationcankeepalltheinformationfrom
Fig.7. Accuracy(%)withdifferenttuplesizesnontheJEITA-HPtestingset.
Fig.8. Accuracy(%)withdifferentnumberoftrainingcharactersontheJEITA-HP testingset.
thelocalfeatures sothat itsaccuracy isalways thehighestinall theexperiments.
4.3.2. Experimentsonthetuplesize
The followingexperimentsdeterminedtheoptimum sizenfor n-tuples. The value of n was varied from 1 to 50 for both the sub-region levelfeatures (SF) andcharacter levelfeatures (CF) as shown in Fig. 7 . We employed 500 characters for each of the 100writersandappliedtheaverageaggregationmethodasitwas found to be the most efficient aggregation method. The SF pro-ducedabetterrecognitionratethantheCFandachievedabetter identificationrate even forsmaller n-tuples. Withan input from only10characterimages,ourmethodachievedawriter identifica-tionaccuracyof99.09%.Thehighestidentificationratewas99.97%, whichwasachievedbyapplyingSFwith20characterimages.
4.3.3. Experimentsonthenumberoftrainingpatterns
To determine the fewest characters required for training, we varied the number of training characters (Ncharacter_img) from 10 to 1000 for each writer to identify 100 writers. In these exper-iments, we used 20-tuples (n=20) and the average aggregation method on sub-region level features as these hyper-parameters were confirmed in the experiments described above. The results arepresentedinFig. 8 .Despiteusingonly50charactersfor train-ing,ourmethodachievedaperformanceof92.80%,whichsuggests thatit can extracttext-independent writer-specific features using asmallnumberoftrainingsamples.Theperformanceisimproved byincreasingthenumberoftrainingsamplesinlaterexperiments: whenweincreasedthenumberoftrainingsamplesto100,an ac-curacyof97.52%wasobtained.
Fig.9. Accuracy(%)withdifferentnumberofwritersontheJEITA-HPtestingset.
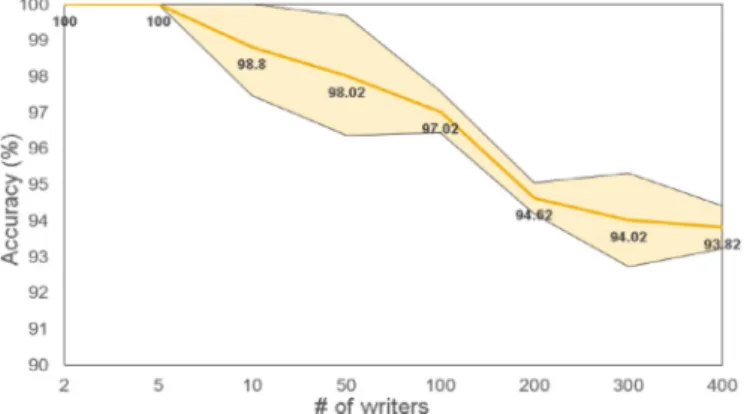
4.3.4. Experimentsonthenumberofwriters
Intheseexperiments,wevariedthenumberofwriters(Nwriters) from 2 to 400, used 20-tuples (n=20), 100 training characters andtheaverageaggregationmethodon sub-regionlevel features.
Fig. 9 showstheresultsoftheseexperiments,withtheorangeline showing the mean accuracy in each experiment. The variance is shown by the yellowshaded area between theupper and lower blacklines.Theperformancefallsgraduallyasthenumberof writ-ers increases.Our method achieved an accuracy of 93.82% using only100trainingcharactersforidentifying400writers.Moreover, we repeatedeach experiment20timestoobtainthevariance. As shown in Fig. 9 , the variances are approximately 1 point, which indicates thatthetrainingmethodcouldlearn writer-specific fea-turesindependentofthetext.
4.4. ExperimentsontheFiremakerandIAMdatabases
We now present our experiments on the Firemaker and IAM databaseswiththebesthyper-parameters fromtheabove experi-ments.WereusedtheoptimizedtuplesizefromJEITA-HPdatabase to train the network from the beginning for each experiment on the Firemaker and IAM databases. In addition, we compared the performance of our method with an existing state-of-the-art methodbasedonhandcraftedfeaturesandclustering[6] . 4.4.1. PerformanceonhandwrittenEnglishtext
Forevaluation,asinglen-tupleissampledfromeachwriterand fed into the trained network, as our method does not require a large page or many characters foridentifying writersduring the evaluationprocess.Weachievedthetop-1accuracyof92.38%and top-10accuracyof97.67%for250writersfromtheFiremaker test-ing set. For 650 writers from the IAM testing set, we achieved accuracy figures of90.12% (top-1) and97.82%(top-10).Using 20-tuples(n=20),ourmethod achievedaperformance of91.81%for 900writersfromthecombineddatabasesofFiremakerandIAM.
As the samples of the Firemaker andIAM databases are cur-sivelyhandwrittentext,theextractedsub-imagesfromthem usu-ally contain connected characters or sub-regions of connected characters, which requires the network to represent features of connected charactersinaddition to thefeatures of isolated char-acters. Therefore, the performance on the Firemaker and IAM databases(92.38%for250writers)seemslowerthanonthe JEITA-HPdatabase(94.62%for200writersand94.02%for300writers). Theremaybeanotherreasonforareducedperformanceon hand-written English databases. The hyper-parameters were optimized forhandwrittenJapanesetextinJEITA-HP,whichmightnotbe op-timalforEnglish.
Inaddition,weemployedfive20-tuplesofsub-imagesforeach test pageto evaluateour methodwhich givesbetterresults than
Table2
Writeridentificationaccuracy(%)ontheFiremakerandIAMdatabases.
Database Firemaker IAM Firemaker+IAM
Numberofwriters 250 650 900
HF-single Top-1 81 81 80
Top-10 92 94 92
HF-comb Top-1 83 89 87
Top-10 95 97 96
Ourmethod Top-1 92.38
(1.08) 90.12 91.81 (0.88) (0.69) Top-10 97.67 (0.79) 97.82 98.07 (0.50) (0.51) Top-1byfive 20-tuples 93.56 (0.91) 93.14 94.75 (0.70) (0.81)
thetop-1accuracy byasingle20-tuple(94.75% forfive20-tuples compared with91.81% forsingle20-tuple).Thissuggeststhat we canextractandusemoren-tuplesofsub-imagestoachievea bet-teraccuracyofwriteridentificationinpractice.
4.4.2. Comparisonwithpreviouslypublishedresults
Table 2 shows a comparison between the method of Bulacu andSchomaker[6] andourmethod.BulacuandSchomaker[6] ob-tainedresultsfrom50identificationtestsonrandomselectionsof writers. They mentioned that “Forthe size of thedata sets used here, the writer identificationpercentages are 3–4percent confi-denceintervalata95percentconfidencelevel” .Hence,theresults ofHF-singleandHF-combbasedrecognizersshowninTable 2 are theaverageresultswithstandardvariationfrom3%to4% ata95 percentconfidencelevel.Ontheotherhand,ourmethodwas eval-uated20timesonthetestdatasothattheresultsofournetwork in Table 2 are the averageidentificationrates withvariances. For alltheexperimentsontheEnglishdatabases,thetop-1andtop-10 performance of our methodis higher than thebest single hand-craftedfeature(HF-single)andeventhebestcombinationof hand-craftedfeatures (HF-comb) in[6] .Thissuggeststhat ournetwork canrepresentwriter-specificfeaturesforalargenumberofwriters independentoftextandlanguage.
In order to verifystatistical significance of the difference be-tween the performance oftheir method andthat ofour method, weconsiderthefollowingEqs. (4) and(5) .
ˆ
σ
=SD 2 our_method 20 + SD2 prev_method 50 (4)whereSDprev_method isthenormalizedstandard varianceto[0,1]of theirmethodwhileSDour_method isthatofourmethod.
true_di ff erence=Accour_method−Accprev_method±Zα/2
ˆ
σ
(5)where Accprev_method is the normalized accuracy to [0,1] of their method while Accour_method is that of our method. Zα/2 is the Z score at the (1-
α
) confidence level. Here, we verify the true_difference at 95% confidence level (thus,α
=0.05) with Zα/2=1.96.For the Firemaker and IAM databases, we obtained
true_difference and confirmed that it is greater than 0. Hence, thenullhypothesisisrejectedwhichimpliesthattheperformance ofourmethodissignificantlydifferentwith
α
=0.05fromBulacu andSchomaker’smethod.AsshowninTable 2 ,thetop-1and top-10 results (in boldface) of our method are significantly different fromtheresultsofHF-comb ontheFiremakerdatabaseandona combinationoftheFiremakerandIAMdatabases.5. Conclusions
We presentedherea CNN-basedmethod fortext-independent writeridentification.Localfeatureswereextractedfromthewhole
character patterns as well as their sub-regions, which were ag-gregatedintoglobalfeatures bythreedifferentmethods. Random samplingwasappliedtocreatealargenumberoftrainingpatterns fromalimitednumberofsamplesforCNNduringthetraining pro-cess.Thismethodlearnedwriter-specificfeaturesautomatically in-dependentofthetextthroughend-to-endtrainingandachievedan identificationrateof99.97%ontheJEITA-HPdatabaseofJapanese handwrittencharacterpatternsforthetaskofidentifying100 writ-ers. Moreover, our method achieved an accuracy rate of 92.80%, whentrainedby only50charactersfor100writersand100 char-actersfor400writers. Thisapproachovercomesthedifficultiesof gatheringhandwrittencharacterpatternsinthesamecategoryfor writeridentification.
Intheexperimentson Englishdatabases(Firemaker andIAM), eventhoughthenumberofwriterswas900andtherewasan im-balance of handwriting patterns among the writers, our method achievedanaccuracyof91.81%, whichishigherthantheexisting state-of-the-artmethods basedon handcrafted features and clus-tering(80%whenusingasinglehandcraftedfeatureand87%when using combined features). The high performance on the English databaseswithalargenumberofwriterssuggeststhatthetrained network represents the writer-specific features and plays an im-portant role in solving the text-independent writer identification problem.
We plan to expand the scope of this method in the future. In our experiments, we used the best hyper-parameters tuned forhandwritten Japanese characters to handwritten English text. However, the accuracy can be improved by tuning the hyper-parameters for English. It would also be interesting to evaluate our writer identification method forother languages or multiple languages [3] . In addition, it would be challenging to apply the methodforidentifying unknown writersorregisteringnew writ-ers.
Conflictofinterest
None.
Acknowledgment
This work is partially supported by JSPS KAKENHI Grant NumberJP18K18068.
References
[1] A. Bensefia, A.Nosary,T.Paquet,L.Heutte,Writeridentificationbywriter’s invariants,in:Proceedingsofthe8thInternationalWorkshoponFrontiersin HandwritingRecognition,2002,pp.274–279.
[2] D. Bertolini, L.S. Oliveira, E. Justino, R. Sabourin, Texture-baseddescriptors for writer identification and verification, Expert Syst. Appl. 40 (6)(2013) 2069–2080.
[3] D.Bertolini,L.S.Oliveira,R.Sabourin,Multi-scriptwriteridentificationusing dissimilarity,in:ProceedingsoftheInternationalConferenceonPattern Recog-nition,2017,pp.3025–3030.
[4] A.A. Brink, J. Smit, M.L. Bulacu, L.R.B. Schomaker, Writeridentification us-ingdirectionalink-tracewidthmeasurements,PatternRecognit.45(1)(2012) 162–171.
[5] D.Bruyne,R.Forre,Signatureverificationwithelasticimagematching,in: Pro-ceedingsofthe InternationalCarnahan Conferenceon SecurityTechnology: ElectronicCrimeCountermeasures,1986,pp.113–118.
[6] M.Bulacu,L.Schomaker,Text-independentwriteridentificationand verifica-tionusingtextural andallographicfeatures,IEEETrans.PatternAnal.Mach. Intell.29(4)(2007)701–717.
[7] M.Bulacu,L.Schomaker,Acomparisonofclusteringmethodsforwriter iden-tificationandverification,in:ProceedingsoftheInternationalConferenceon DocumentAnalysisandRecognition,2005,pp.1275–1279.
[8] M.Bulacu,L.Schomaker,L.Vuurpijl,Writeridentificationusingedge-based directionalfeatures,in:ProceedingsoftheInternationalConferenceon Docu-mentAnalysisandRecognition,2003,pp.937–941.
[9] V.Christlein,D.Bernecker,F.Hönig,E.Angelopoulou,Writeridentificationand verificationusingGMMsupervectors,in:ProceedingsoftheIEEEWinter Con-ferenceonApplicationsofComputerVision,2014,pp.998–1005.
[10] V.Christlein,D.Bernecker,A.Maier,E.Angelopoulou,Offlinewriter identifica-tionusingconvolutionalneuralnetworkactivationfeatures,in:Proceedingsof theGermanConferenceonPatternRecognition,2015,pp.540–552.
[11]P.C.Chuang,Machineverificationofhandwrittensignatureimage,in: Proceed-ingsoftheInternationalConferenceOnCrimeCountermeasuresScienceand Engineering,1977,pp.105–109.
[12] R.Collobert, J.Weston,Aunifiedarchitecture fornaturallanguage process-ing,in:Proceedingsofthe25thInternationalConferenceonMachineLearning, 2008,pp.160–167.
[13] C.Djeddi,L.-S.Meslati,I.Siddiqi,A.Ennaji, H.ElAbed,A.Gattal,Evaluation oftexturefeaturesforofflinearabicwriteridentification,in:Proceedingsof the11thIAPRInternationalWorkshoponDocumentAnalysisSystems,2014, pp.106–110.
[14] S.Fiel,R.Sablatnig, Writeridentificationand retrievalusingaconvolutional neuralnetwork,in:ProceedingsoftheInternationalConferenceonComputer AnalysisofImagesandPatterns,2015,pp.26–37.
[15] K.Franke,O.Biinnemeyer,T.Sy,Inktextureanalysisforwriteridentification, in:Proceedingsofthe International Workshopon FrontiersinHandwriting Recognition,2002,pp.268–273.
[16] K.He,X.Zhang,S.Ren,J.Sun,Deepresiduallearningforimagerecognition,in: ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recogni-tion,2016,pp.770–778.
[17] C.Hertel,H. Bunke, A setofnovelfeaturesforwriter identification, Audio-Video-BasedBiometricPersonAuthent.2688(2003)679–687.
[18] G.E.Hinton,S.Osindero,Y.-W.Teh,Afastlearningalgorithmfordeepbelief nets,NeuralComput.18(7)(2006)1527–1554.
[19] T.Kawatani,H.Shimizu,HandwrittenkanjirecognitionwiththeLDAmethod, in:Proceedingsofthe14thInternationalConferenceonPatternRecognition,2, 1998,pp.1301–1305.
[20]D.P.Kingma,J.L.Ba,Adam:amethodforstochasticoptimization,in: Proceed-ingsofthe3rdInternationalConference forLearningRepresentations,2015, pp.1–15.
[21]U.-V.Marti,R.Messerli,H.Bunke,Writeridentificationusingtextlinebased features,in:Proceedings ofthe 6thInternational Conference on Document AnalysisandRecognition,2001,pp.101–105.
[22]U.V.Marti,H.Bunke,TheIAM-database:anEnglishsentencedatabasefor of-flinehandwritingrecognition,Int.J.Doc.Anal.Recogn.5(1)(2003)39–46. [23]R.Plamondon,G.Lorette,Automaticsignatureverificationandwriter
identifi-cation-thestateoftheart,PatternRecognit.22(2)(1989)107–131. [24]H.E.S.Said,T.N.Tan,K.D.Baker,Personalidentificationbasedonhandwriting,
PatternRecognit.33(1)(2000)149–160.
[25]A.Schlapbach,H.Bunke,Awriteridentificationandverificationsystemusing HMMbasedrecognizers,PatternAnal.Appl.10(1)(2007)33–43.
[26]Schomaker,L.R.B.,Vuurpijl,L.,2000.ForensicWriterIdentification:A Bench-markDataSetandaComparisonofTwoSystems,TechnicalReport.Nijmegen University,Tilburg,TheNetherlands.
[27]I.Siddiqi,N.Vincent, Combiningcontourbasedorientationandcurvature fea-turesforwriterrecognition,in:ProceedingsoftheInternationalConferenceon ComputerAnalysisofImagesandPatterns,2009,pp.245–252.
[28]M.Sreeraj,S.M.Idicula,Asurveyonwriteridentificationschemes,Int.J.Comp. Appl.26(2)(2011)23–33.
[29]S.N.Srihari,S.H.Cha,H.Arora,S.Lee,Individualityofhandwriting:avalidation study,in:ProceedingsoftheInternationalConferenceonDocumentAnalysis andRecognition,2001,pp.106–109.
[30]G.X.Tan,C.Viard-Gaudin,A.C.Kot,Automaticwriteridentificationframework foronlinehandwrittendocumentsusingcharacterprototypes,Pattern Recog-nit.42(12)(2009)3313–3323.
[31] X.Wu,Y.Tang,W.Bu,Offlinetext-independentwriteridentificationbasedon scaleinvariantfeaturetransform,IEEETrans.Inf.ForensicsSecur.9(3)(2014) 526–536.
[32]W.Yang,L.Jin,M.Liu,DeepWriterID:anend-to-endonlinetext-independent writeridentificationsystem,IEEEIntell.Syst.31(2)(2016)45–53.
[33]I. Yoshimura,M. Yoshimura, Writeridentificationbasedon the arc pattern transformation,in:Proceedingsofthe9thInternationalConferenceonPattern Recognition,1988,pp.35–37.
[34]M.Yoshimura,F.Kimura,I.Yoshimura,Experimentalcomparisonoftwotypes ofmethodsofwriteridentification,IEICETrans.E65(6)(1982)345–352.