S
KATHOLIEKE UNIVERSITEIT LEUVEN
FACULTEIT INGENIEURSWETENSCHAPPEN
DEPARTEMENT COMPUTERWETENSCHAPPEN
AFDELING INFORMATICA
Celestijnenlaan 200 A — B-3001 Leuven
Standards based Interoperability for Searching in and Publishing to
Learning Object Repositories
Promotor :
Prof. Dr. ir. E. Duval Prof. Dr. H. Olivi´e
Proefschrift voorgedragen tot het behalen van het doctoraat in de ingenieurswetenschappen door
Stefaan TERNIER
S
DEPARTEMENT COMPUTERWETENSCHAPPEN
AFDELING INFORMATICA
Celestijnenlaan 200 A — B-3001 Leuven
Standards based Interoperability for Searching in and Publishing to
Learning Object Repositories
Jury :
Prof. Dr. ir. D. Vandermeulen, voorzitter Prof. Dr. ir. E. Duval, promotor
Prof. Dr. H. Olivi´e, promotor Prof. Dr. A. Bultheel
Prof. Dr. ir. P. Verbaeten
Prof. Dr. S. Ceri (Politecnico di Milano, Itali¨e) Prof. Dr. ir. G.-J. Houben (Vrije Universiteit Brussel)
Dr. H. Van de Sompel (Los Alamos National Laboratory, VS)
Proefschrift voorgedragen tot het behalen van het doctoraat in de ingenieurswetenschappen door
Stefaan TERNIER
U.D.C. 681.3∗H51, 681.3∗H3
c
°Katholieke Universiteit Leuven – Faculteit Ingenieurswetenschappen Arenbergkasteel, B-3001 Heverlee (Belgium)
Alle rechten voorbehouden. Niets uit deze uitgave mag worden vermenigvuldigd en/of openbaar gemaakt worden door middel van druk, fotocopie, microfilm, elek-tronisch of op welke andere wijze ook zonder voorafgaande schriftelijke toestemming van de uitgever.
All rights reserved. No part of the publication may be reproduced in any form by print, photoprint, microfilm or any other means without written permission from the publisher.
D/2008/7515/32 ISBN 978-90-5682-923-0
Preface
Over the last few years there is a growing interest in the use of learning objects as digital resources for learning. As authoring high quality e-learning content is often expensive, reuse of such content is of great value. Such reuse can be enabled by Learning Object Repositories. Many of such repositories have been deployed over the Internet and the World Wide Web over the past years. Together, these repositories host a vast amount of learning objects. This dissertation will address two questions to enable better "share and reuse" of learning objects:
1. How can we make it easier to nd relevant objects? Many learning object repositories provide their community with a specic search interface. This impedes discovery of relevant learning objects, since users must search each repository individually. This dissertation will investigate whether and how a uniform search can be provided to a collection of repositories.
2. How can we facilitate making objects available for reuse? The traditional procedure for publishing learning objects to a repository is tightly integrated with a specic repository, whereas the distribution of materials to learners typically relies on a Learning Management System (LMS) or a Virtual Learn-ing Environment (VLE). This complicates the workow of the creator who will often publish to learners only, so that the object does not become avail-able for reuse in a repository. In this dissertation, we will investigate how loosely coupled publication services can be integrated into learning or au-thoring environments, so that a learning object can be published from these environments to a repository in a single user interaction cycle.
Each learning object repository is based on a data and metadata model. Chap-ter 1 presents a simple model for learning objects and metadata. Also, a reference model for learning object repositories is dened that summarizes the components and their functionality. When addressing the problems of "share and reuse", the main focus was on realizing interoperability between the components in the dier-ent layers of this reference model.
Chapter 2 starts with presenting issues that hinder large scale reuse of learning objects. We discuss how a search and publishing protocol can address some of
the issues. The main objective of this dissertation is to enable interoperability for searching and publishing, so that "share and reuse" of materials can be facilitated. Section 2.2.3 discusses an approach for achieving interoperability so that the work that is presented can be applied to dierent technologies. We identify requirements for making the protocols applicable to a heterogeneous set of repositories. Both protocols must allow for loosely coupled integration, in order to enable transparent, exible integration in learning environments. Specic requirements for searching and publishing are analysed in separate sections.
The two protocols are presented in chapters 3 and 5. First, we aimed at reaching a critical mass of learning objects. The Simple Query Interface (SQI), presented in chapter 3, provides a solution for transporting queries between search clients and learning object repositories. Through the deployment of SQI, uniform search access to vast amount of learning objects has been enabled. SQI is now a CEN ISSS standard. Once a critical mass of objects was available, we focused on the problem of sharing materials. The Simple Publishing Interface (SPI), presented in chapter 5, deals with storing learning objects in a repository and enables more objects to be made available for reuse. SPI is currently being standardized in CEN ISSS. Both chapters present an abstract specication and a binding to a concrete technology.
Chapter 4 presents the ProLearn Query Language (PLQL), an abstract query language that can deal with hierarchical metadata schemas, such as the Learning Object Metadata standard. The specication of this query language complements the SQI protocol. As SQI can transport PLQL queries, together these protocols provide a complete solution for interoperability.
The search and publishing protocols can be used in two ways.
1. First, both protocols can be used to provide access to a single repository, using an existing metadata schema and query language. This is the focus of chapter 6 that analyses the ARIADNE KPS, a learning object repository that served as a testbed for experiments. Various ARIADNE use cases are analysed, for which solutions are discussed that use the protocols presented in chapters 3, 4 and 5. In this way, the ARIADNE implementations prove the practical usability of the protocols and validate that SQI, PLQL and SPI enable oering publish and search access to applications.
2. Secondly, enable uniform search access over a network of repositories. Chap-ter 7 demonstrates this in the context of the GLOBE network. Here, SQI and PLQL are used to provide search interoperability over all GLOBE learning object repositories. In this way, it is validated that with SQI and PLQL, a search application can interoperate with many learning object repositories. This chapter nishes with architectural patterns that generalize techniques for building a standards based search infrastructure.
iii The last chapter provides a general conclusion and points to further opportu-nities in this research.
Acknowledgement
A little more than six years ago, Prof. Dr. ir. Erik Duval took me on board of HMDB. I am very grateful for his guidance, all the international learning oppor-tunities he gave me and - not the least - the constructive feedback I received from him over the past years.
I want to thank my second promotor, Prof. Dr. Henk Olivié for reviewing this text and for the many thoughtful comments.
I am grateful to the members of my jury, Prof. Dr. ir. Dirk Vandermeulen, Prof. Dr. Adhemar Bultheel, Prof. Dr. ir. Pierre Verbaeten, Prof. Dr. Stefano Ceri, Prof. Dr. ir. Geert-Jan Houben and Dr. Herbert Van de Sompel for their evaluation eort and their feedback.
I am indebted to Dr. Martin Wolpers, Marion Wolpers, Joris Klerckx and Dr. Katrien Verbert for the many discussions, helpful comments and for reading parts of my dissertation.
During the past few years, I received a lot of support from all of my colleagues. Their presence, the many events we organized together, made working on this dissertation "serious fun". Thank you Dr. Kris Cardinaels, Dr. Koen Hendrikx, Filip Neven, Dr. Thomas Cleenewerck, Dr. Jehad Najjar, Dr. Bern Martens, Michael Meire, Nik Corthaut, Sten Govaerts, Bram Luyten, Ben Bosmans, Bram Vandeputte and Gonzalo Parra for the fruitful collaboration.
Soon after I arrived in HMDB, I became involved in ARIADNE, an interna-tional organisation that served as a testbed for this work. In this context, I'm most grateful to Emmanuel Fernandes, Dr. Maciej Macowicz, Dr. Julien Broisin, Xavier Ochoa and Gert-Jan Hufken for the pleasant cooperation.
I have spent many hours discussing search interoperability with the members of the CEN ISSS WSLT workshop and the ProLearn network. I am indebted to Dr. Daniel Olmedilla, Dr. Bernd Simon, Dr. David Massart, Fridolin Wild & Frans van Assche for their priceless help in getting a deeper understanding of the subject.
Two years ago, I was invited by Mike Halm for a stay at Penn State University. I want thank Mike Halm and Lorin Metzger for supporting a stay that not only helped me with my research, but that was also very pleasant.
I wish to thank all partners of the GLOBE network, with whom we had regular meetings across the GLOBE. I am grateful to Martin Koning Bastiaan, Jerry Leeson, Frédéric Bergeron, Prof. Dr. Tsuneo Yamada and Prof. Dr. Gilbert Paquette.
To my parents, sisters and relatives I am grateful for the love, support and encouragement. Finally, I wish to thank my close friends for all the pleasurable moments we shared: Dieter, Imely, Jasper, Joke, Maureen, Pieter, Soe, Stefanie and Tine.
Contents
Preface i
Acknowledgement v
Contents vii
List of Acronyms xiii
List of Figures xvi
List of Tables xviii
1 Learning Object Repositories 1
1.1 Introduction . . . 1
1.2 Learning Object . . . 1
1.3 Learning Object Repository . . . 2
1.3.1 Reference Model . . . 3
1.3.2 Digital Library . . . 6
1.3.3 Institutional Repositories . . . 8
1.3.4 Referatories . . . 10
1.4 State of the art . . . 10
1.4.1 Persistent locating . . . 11
1.4.2 The Semantic Web . . . 12
1.4.3 Metadata Application Proles . . . 13
1.4.4 Metadata harvesting . . . 14
1.4.5 Network topology . . . 15
1.4.6 Other research areas . . . 17
1.5 Conclusion . . . 17
2 Challenges in managing Learning Objects 19 2.1 Share and Reuse . . . 19
2.2 Requirements for Learning Objects Repositories . . . 22 vii
2.2.1 Heterogeneous preservation systems . . . 23
2.2.2 Loosely coupled integrations . . . 24
2.2.3 Interoperability . . . 25
2.3 Requirements for a search service . . . 27
2.3.1 Synchronous and asynchronous interaction . . . 27
2.3.2 Stateful and Stateless interaction . . . 28
2.4 Requirements for a publishing service . . . 29
2.4.1 By reference and by value publishing . . . 29
2.4.2 Application scenarios . . . 30
2.5 Conclusion . . . 31
3 Simple Query Interface 33 3.1 Session Management . . . 34
3.1.1 Create Session . . . 34
3.1.2 Create Anonymous Session . . . 35
3.1.3 Destroy Session . . . 35
3.2 Query Conguration Methods . . . 36
3.2.1 Set Query Language . . . 36
3.2.2 Set Maximum Number of Query Results . . . 37
3.2.3 Set Maximum Duration . . . 37
3.2.4 Set Results Format . . . 38
3.3 Synchronous Query Methods . . . 38
3.3.1 Set Results Set Size . . . 39
3.3.2 Synchronous Query . . . 40
3.3.3 Get Total Results Count . . . 41
3.4 Asynchronous Query Methods . . . 42
3.4.1 Set Source Location . . . 42
3.4.2 Asynchronous Query . . . 43
3.4.3 Query Results Listener . . . 44
3.5 Web service binding . . . 44
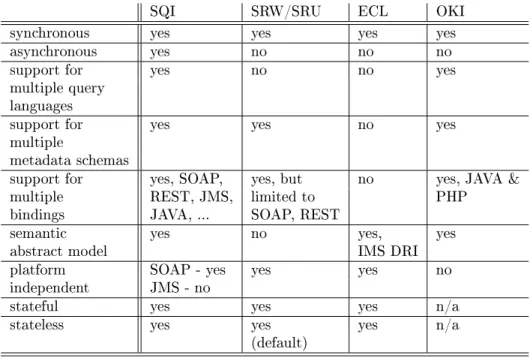
3.6 Related Work . . . 47
3.6.1 SRU/W . . . 48
3.6.2 The EduSource Communication Layer . . . 50
3.6.3 The Open Knowledge Initiative . . . 50
3.6.4 Comparison with SQI methods . . . 50
3.6.5 Security . . . 52
3.6.6 Query Languages . . . 53
3.6.7 Resumption Tokens versus Session Management . . . 55
CONTENTS ix
4 The ProLearn Query Language 61
4.1 Abstract versus Concrete Query Languages . . . 62
4.2 Hierarchic metadata . . . 64
4.3 Selection and projection . . . 65
4.4 PLQL Levels . . . 66 4.4.1 PLQL level 0 . . . 67 4.4.2 PLQL level 1 . . . 69 4.4.3 PLQL level 2 . . . 70 4.5 Results Format . . . 71 4.6 Implementing PLQL . . . 73
4.6.1 The Lucene query language . . . 74
4.6.2 XQuery . . . 76
4.7 Related work . . . 79
4.8 Conclusion . . . 80
5 Simple Publishing Interface 81 5.1 Submit & Delete Learning objects . . . 82
5.1.1 Set Data Format . . . 82
5.1.2 Set Source Location . . . 83
5.1.3 Submit Resource . . . 84
5.1.4 Notify Retrieval Status . . . 86
5.1.5 Delete Resource . . . 87
5.2 Submit & Delete Metadata . . . 88
5.2.1 Set Metadata Schema . . . 88
5.2.2 Submit Metadata . . . 89
5.2.3 Delete Metadata . . . 90
5.3 Connecting metadata and learning object . . . 91
5.3.1 Associate . . . 91
5.3.2 Dissociate . . . 92
5.4 Related work . . . 93
5.4.1 Fedora . . . 94
5.4.2 PENS . . . 97
5.4.3 SRU record update . . . 97
5.4.4 EduSource Communication Layer . . . 98
5.4.5 Open Knowledge Initiative . . . 100
5.5 Conclusion . . . 101
6 The ARIADNE Learning Object Repository: an experience re-port 103 6.1 The ARIADNE Knowledge Pool System . . . 104
6.2 Application of the Simple Query Interface in ARIADNE . . . 106
6.2.1 Export LOM metadata . . . 106
6.2.3 the ARIADNE query and indexation tool . . . 109
6.3 Application of the Simple Publishing Interface in ARIADNE . . . 110
6.3.1 The ARIADNE application prole . . . 110
6.3.2 Support for other metadata management paradigms . . . . 111
6.3.3 Reuse of components . . . 112
6.3.4 Publish from within an LMS . . . 113
6.4 Conclusion . . . 114
7 Case studies for search interoperability 115 7.1 Building SQI adapters . . . 116
7.1.1 One-to-one SQI implementations . . . 116
7.1.2 one-to-many SQI implementations . . . 120
7.1.3 Conclusion . . . 124
7.2 Federated Search Engine . . . 125
7.2.1 Architecture . . . 125
7.2.2 Federated Search API . . . 127
7.2.3 Asynchronous & synchronous communication . . . 128
7.2.4 Stateful or stateless queries . . . 128
7.3 Architectural patterns for searching distributed repositories . . . . 129
7.3.1 Federated Search pattern . . . 130
7.3.2 Search on Harvest pattern . . . 133
7.3.3 Search Adapter pattern . . . 135
7.3.4 Harvest Adapter pattern . . . 137
7.3.5 Conclusion . . . 139
8 Conclusion 141 8.1 How can we make it easier to nd relevant objects? . . . 141
8.2 How can we facilitate making objects available for reuse? . . . 143
8.3 Contributions . . . 144
8.4 Opportunities for future work . . . 145
9 Interoperabiliteit voor het publiceren en ontsluiten van leerobjecten in repositories met gebruik van standaarden 147 9.1 Uitdagingen om leerobjecten beter te beheren . . . 148
9.1.1 Vereisten voor zoeken . . . 150
9.1.2 Vereisten voor het publiceren . . . 151
9.2 Besluit . . . 151
9.3 De Simple Query Interface . . . 152
9.3.1 Beheer van sessies . . . 152
9.3.2 Query conguratie . . . 152
9.3.3 Synchroon zoekopdrachten sturen . . . 153
9.3.4 Asynchroon zoekopdrachten sturen . . . 154
CONTENTS xi
9.3.6 Besluit . . . 157
9.4 De Prolearn Query Language . . . 158
9.4.1 PLQL niveau 0 . . . 159
9.4.2 PLQL niveau 1 . . . 159
9.4.3 PLQL niveau 2 . . . 159
9.4.4 Formaat van de resultaten . . . 159
9.4.5 Het implementeren van PLQL . . . 160
9.4.6 Besluit . . . 162
9.5 De Simple Publishing Interface . . . 162
9.5.1 Publiceren van leerobjecten . . . 163
9.5.2 Publiceren van metadata . . . 164
9.5.3 Associëren van metadata en leerobject . . . 164
9.5.4 Besluit . . . 165
9.6 Ervaringen met het gebruik van SQI, PLQL en SPI . . . 166
9.6.1 De ARIADNE LOR . . . 166
9.6.2 Het GLOBE netwerk . . . 168
9.7 Besluit . . . 170
9.7.1 Hoe kunnen we het gemakkelijker maken om leermateriaal te vinden? . . . 171
9.7.2 Hoe kunnen we het gemakkelijker maken om leermateriaal beschikbaar te maken voor hergebruik? . . . 171
9.7.3 Bijdragen . . . 172
9.7.4 Verdere onderzoeksonderwerpen . . . 173
List of Acronyms
AICC The Aviation Industry CBT (Computer-Based Training) Committee AMG Automatic Metadata Generation
API Application Program Interface
ARIADNE Alliance of Remote Instructional Authoring and Distribution Networks for Europe
CEN European Committee for Standardization CQL Contextual Query Language
DOI Digital Object Identier
DRI Digital Repositories Interoperability ECL EduSource Communication Layer ELF E-Learning Framework
IEEE Institution of Electronic and Electric Engineers IMS Instructional Management Systems
IR Institutional Repository
ISSS Information Society Standardization System GLOBE Global Learning Object Brokered Exchange JMS JAVA messaging system
KPS Knowledge Pool System LMS Learning Management System LOM Learning Object Metadata LOR Learning Object Repository
LTSC Learning Technology Standardization Committee MACE Metadata for Architectural Contents
MELT Metadata Ecology for Learning and Teaching
MERLOT Multimedia Educational Resource for Learning and Online Teaching MIME Multipurpose Internet Mail Extensions
MPEG Moving Picture Experts Group
OAI-PMH Open Archives Initiative Protocol for Metadata Harvesting OKI Open Knowledge Initiative
OSID Open Service Interface Denitions
P2P Peer-to-peer
PLQL ProLearn Query Language
xv RDF Resource Description Framework
SCORM Sharable Content Object Reference Model SOAP Simple Object Access Protocol
SPI Simple Publishing Interface SQI Simple Query Interface SRU Search/Retrieve via URL SRW Search/Retrieve Web Service URI Universal Resource Identier VSQL Very Simple Query Language WSDL Web Service Description Language
WS-I The Web Services-Interoperability Organization XML Extensible Markup Language
List of Figures
1.1 Model for learning objects and metadata . . . 2
1.2 Reference Model for Learning Object Repositories . . . 5
1.3 ARIADNE, MACE and GLOBE metadata application proles . . 14
1.4 Cordra Community . . . 17
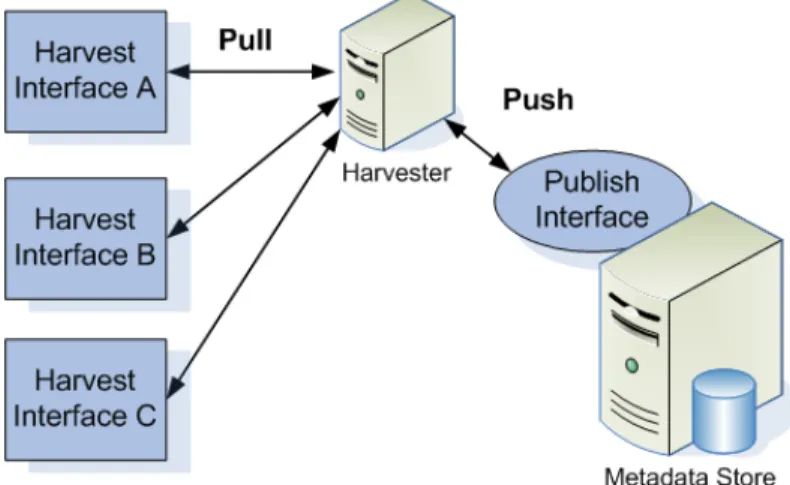
2.1 Pull with harvest, publish with push technology . . . 30
3.1 Synchronous query mode: a sequence diagram . . . 39
3.2 Asynchronous query mode: a sequence diagram . . . 42
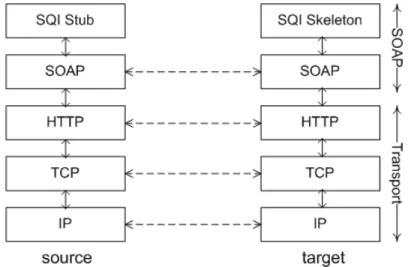
3.3 SQI communication on top of SOAP Protocol Stack . . . 45
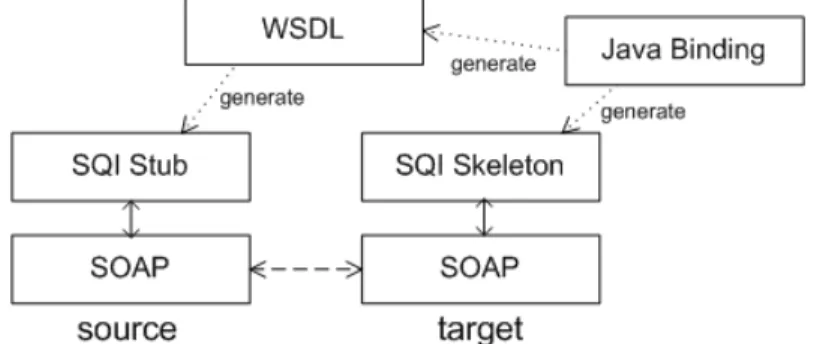
3.4 Generating a WSDL for SQI . . . 46
3.5 Creating a WSDL for SQI . . . 47
3.6 Oering a web service at the source . . . 47
3.7 SQI as both network and API based interface . . . 53
4.1 An SQI sequence diagram, transporting PLQL . . . 72
4.2 Lucene document model . . . 74
5.1 Submit by value: a sequence diagram . . . 85
5.2 Submit by reference: a sequence diagram . . . 85
5.3 Submit a metadata record: a sequence diagram . . . 89
5.4 Associate a resource and a metadata record: a sequence diagram . 91 5.5 Dissociate: a sequence diagram . . . 93
5.6 Update an associated metadata instance: a sequence diagram . . . 94
5.7 Fedora digital object model . . . 94
6.1 The ARIADNE replication architecture . . . 105
6.2 The ALOCOM architecture . . . 106
6.3 The MACE enrichment architecture . . . 112
7.1 MERLOT results format . . . 118
7.2 The LionShare adapter . . . 122 xvii
7.3 Proxies in the Edutella P2P network . . . 123 7.4 The LIMBS Brokerage System . . . 124 7.5 Federated search network . . . 126 7.6 Federated Search pattern . . . 130 7.7 Search on Harvest pattern . . . 133 7.8 Search Adapter pattern . . . 135 7.9 Harvest Adapter pattern . . . 137 9.1 Synchrone modus: een sequentie diagram . . . 154 9.2 Asynchrone query modus: een sequentie diagram . . . 155 9.3 Genereren van een WSDL voor SQI . . . 156 9.4 Creëren van een WSDL voor SQI . . . 156 9.5 Associëren van metadata en leerobject: een sequentie diagram . . . 165 9.6 Netwerk voor gefedereerd zoeken . . . 170
List of Tables
2.1 Interoperability framework . . . 26 3.1 Create Session . . . 35 3.2 Create Anonymous Session . . . 35 3.3 Destroy Session . . . 35 3.4 Set Query Language . . . 36 3.5 Set Maximum Number of Query Results . . . 37 3.6 Set Maximum Duration . . . 38 3.7 Set Results Format . . . 38 3.8 Set Results Set Size . . . 39 3.9 Synchronous Query . . . 40 3.10 Get Total Results Count . . . 41 3.11 Set Source Location . . . 43 3.12 Asynchronous Query . . . 43 3.13 Query Results Listener . . . 44 3.14 Characterization of Search Protocols according to protocol features 48 3.15 Comparison of SQI methods to other search initiatives . . . 51 4.1 LOM instance (a) . . . 65 4.2 LOM instance (b) . . . 66 4.3 An example VSQL instance . . . 67 4.4 Bachus Naur Form denition of PLQL level 0 . . . 68 4.5 Bachus Naur Form denition of PLQL level 1 . . . 70 4.6 Bachus Naur Form denition of PLQL level 2 . . . 71 4.7 Bachus Naur Form denition of PLQL results format URI . . . 72 4.8 PLQL results format summary . . . 73 4.9 Example of a lom lucene document . . . 75 4.10 Examples of PLQL LOM statements that are mapped to lucene
query language statements . . . 76 4.11 Results Format in XQuery . . . 77
4.12 Examples of PLQL LOM statements that are mapped to XQuery statements . . . 78 4.13 Comparison of QEL, CQL and PLQL . . . 79 5.1 Set Data Format . . . 83 5.2 Set Source Location . . . 83 5.3 Submit Resource By Value . . . 86 5.4 Submit Resource By Reference . . . 86 5.5 Notify Retrieval . . . 87 5.6 Delete Resource . . . 87 5.7 Set Metadata Schema . . . 88 5.8 Submit Metadata Record . . . 89 5.9 Delete Metadata Record . . . 90 5.10 Associate learning object and metadata . . . 92 5.11 Dissociate learning object and metadata . . . 93 5.12 Comparison of SPI to other specications for publishing . . . 95 7.1 MERLOT Search API . . . 117 7.2 EdNA Search API . . . 119 7.3 List Repositories . . . 127 7.4 Use Repositories . . . 127 9.1 PLQL resultaat formaat overzicht . . . 160 9.2 Voorbeeld van een LOM lucene document . . . 161
Chapter 1
Learning Object Repositories
1.1 Introduction
This chapter introduces the eld of learning objects, metadata and learning object repositories. It is structured as follows: section 1.2 introduces the concept of a learning object and metadata. Learning objects can be managed by digital libraries, institutional repositories, referatories and learning object repositories. In section 1.3, a reference model for learning object repositories is developed that adds perspective to the various paradigms for managing learning objects. Next, section 1.4 introduces research that applies to all these metadata and data management paradigms and that is not limited to technology enhanced learning. Finally, section 1.5 presents conclusions and scopes the research that this dissertation tackles.
1.2 Learning Object
The Learning Technology Standards Committee denes a learning object as any entity, digital or non-digital, that may be used for learning, education, or training [LOM, 2002]. This denition is very broad and covers both digital and non digital resources. One could even argue that according to this denition everything can be cataloged as a learning object. Being able to classify every existing thing as a learning object is not necessarily a bug as we can learn with everything that exists: humans, places, ideas, events, etc.
However, for the purpose of this dissertation, when dealing with learning object repositories, only a subset of these learning objects is relevant: the set of all digital learning objects. Although "digital content" would cover the same set of materials, the term "learning object" is deliberately used for the remainder of this dissertation because all research that is presented has been applied in the eld of technology enhanced learning. Another reason why this term is often used,
is because of its relation to the object-oriented paradigm of computer science. This paradigm highly values the creation of software objects that can be reused [Wiley, 2001]. With reusable learning objects, instructional designers can build courses in the same way a software engineer can reuse JAVA swing objects to create a graphical user interface. This comparison however should not be taken too strictly, since other fundamental concepts in object-oriented programming, such as polymorphism, encapsulation and inheritance have not been translated to the LO context.
After their creation and while they are being used, learning objects are usually extended with properties. These properties are usually referred to as metadata. Metadata, "data about data", are descriptive information about an entity that can serve in many scenarios. For digital resources, these metadata enable better access to the resources, because metadata enable a search application to lter out resources that match with certain properties; e.g. give all learning objects that are published within a given date span. For learning objects, these metadata can provide additional information on the learning process. Learning related metadata can be exploited to deliver learning objects based on what skills the learner already masters and what competencies a learner needs to acquire. Apart from searching, metadata can serve for other purposes. In the context of accessibility, it can indicate whether an object is suited for people with a disability.
Figure 1.1: Model for learning objects and metadata
For learning objects and metadata, a somewhat traditional model is used (gure 1.1) that resembles the relation between books and index cards in a traditional library. The protocol for searching (chapter 3) will use a query language (chapter 4), to search for metadata instances that match certain criteria. Making distinction between both learning object and metadata is important because both can be published separately (chapter 5).
1.3 Learning Object Repository
Historically, research to learning object repositories started in two dierent re-search domains with the specication of two metadata standards. In 1995, ARIADNE (see chapter 6) started working on an educational metadata recommendation that later served as input for the LOM [LOM, 2002] metadata standard. Around the same time, in the research domain of digital libraries, a workshop was hosted in Dublin, Ohio, U.S. where the Dublin Core metadata standard [Weibel et al., 1998] originates from.
1.3 Learning Object Repository 3 A learning object repository (LOR) is a repository that manages learning ob-jects and/or their metadata. In practice, there is no dierence between learning object repositories and digital libraries. However, because the research presented in this dissertation was applied in the domain of technology enhanced learning, the term learning object repository will be used. In section 1.3.1, a reference model shows the entities that make up a learning object repository. Next, other paradigms for managing digital content and metadata will be presented: digital libraries (section 1.3.2), institutional repositories (section 1.3.3) and referatories.
1.3.1 Reference Model
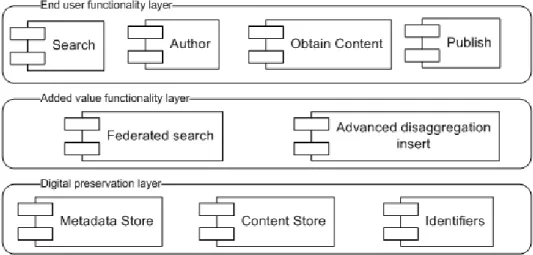
The intention of this section is to build a reference model for learning object repos-itories. The purpose of this model is twofold. It allows architects to use it as a template for composing architectures: chapter 7 will outline a number of archi-tectures that use this model. Furthermore, this reference model seeks to provide common semantics so that components and implementations can unambiguously be discussed and put into perspective. This model is depicted in gure 1.2 and presents three categories of components with their functionality.
1. The digital preservation layer captures the learning object repository and provides functionality that is of importance for managing learning objects. All functionally that is usually oered through this layer is discussed below and linked to the abstract model for learning objects and metadata presented in section 1.2.
• The content store covers all functionality that deals with managing learning objects. This store oers logic for physically storing and ac-cessing instances of the learning object entity in gure 1.1 .
• The identier component separates the logic that deals with the cre-ation of global or local identiers. Sometimes, multiple metadata in-stances refer to the same learning object. Therefore, both learning objects and metadata instances are identied by dierent identiers.
• The metadata store is a functional component that is responsible for storing and managing metadata. Once an identier is bound to a learn-ing object, the identier becomes part of the metadata instance that is associated to the learning object. A metadata instance can contain the identier of the learning object it refers to, and the identier that iden-ties the metadata instance. This component includes technology that can perform e.g. a search but would in a search scenario not deal with graphically presenting the search interface and eventually the results to an end user.
2. At the top level of this model, the end user functionality layer depicts func-tionality that teachers and users use with learning applications. This model
only focuses on a subset of the functionality that applies to learning objects and that is important for the research presented in this dissertation.
• Search represents the functionality in an application that enables a user to search for something. A search can be conducted on a metadata store but also on a federated search component. The functional unit does not cover the logics that conducts the search but supports a search inter-face and displays the results of a query. A search component sends a query to the digital preservation layer and will obtain metadata that describes the results. Searching often invokes the idea of a user formu-lating a query and submitting that query to a search engine. Note that the search component also generalizes other search paradigms (e.g. in-formation visualization [Klerkx et al., 2005]) where a component sends a query to another component.
• Publish expresses functionality that allows a user to publish a learn-ing object and/or metadata. Similarly to search, this component does not deal with the implementation of this functionality at the preserva-tion layer. [Neven et al., 2003] and [Memmel and Schirru, 2007] present examples of client applications that allow for publishing learning ob-jects. In both articles this functionality is clearly separated from the preservation layer.
• Author allows users to create learning objects, using for instance oce applications. Reusing existing content fragments that are managed in a preservation layer instance, authors can signicantly improve both the quality and the creation time of learning objects. [Verbert and Duval, 2007].
• Obtain content denotes functionality for retrieving content from a re-pository. This can for instance involve a web browser obtaining a doc-ument from a web server or an authoring tool obtaining content from a repository for reuse.
3. The added value functionality layer captures functionality that builds on the digital preservation layer and that provides functionality to the end user functionality layer. Through the use of proper standards this functionality can be exported to other infrastructures that implement an instance of the digital preservation layer. [Ochoa et al., 2006] discusses more features that this layer can oer and presents services that oer this functionality.
• Federated Search represents a component that provides unied search access to many digital preservation layers. This component will be covered in more detail in section 7.2.
• The advanced disaggregation component is able to disaggregate learn-ing objects that it receives from an end user functionality component,
1.3 Learning Object Repository 5 and to individually publish the disaggregated components into the con-tent store. An architecture and framework for disaggregating existing learning objects is presented in [Verbert et al., 2005].
Figure 1.2: Reference Model for Learning Object Repositories
In this reference model, components in the end user functionality layer have access to functionality that is available in the added value functionality layer or in the digital preservation layer, while components in the added value functionality layer can only access the digital preservation layer. For instance, a component such as the information visualization framework [Klerkx et al., 2005] resides in the end user functionality layer. This tool can either access a repository directly and communicate with an instance of the metadata store component in the digital preservation layer, or can have transparent access to many repositories through an instance of the federated search component in the added value functionality layer. This reference model presents high level components and assigns functionality to each of those components. The E-Learning Framework (ELF) [ELF, 2004] is a more complete framework. At the time of writing, this framework contains three layers:
1. Sample user agents. This layer corresponds to the end user functionality layer in gure 1.2.
2. The Learning domain services layer denes services that are specic for learn-ing, such as assessment, competency, gradlearn-ing, etc. This layer has no overlap with the reference model in gure 1.2.
3. The common services layer denes 37 services. Many of these services (e.g. calendaring, chat, rating, etc.) are not relevant for learning object reposito-ries. As this layer does not dene components but services, some of the ELF services can be implemented on the components dened in gure 1.2.
• For instance, archiving supports the preservation of materials and can be implemented on the content store component.
• Metadata management supports the creation, validation and retrieval of metadata. This service gives access to the metadata store component.
• The federated search service supports processing of searches that tar-get multiple repositories. This service maps to the federated search component in the added value functionality layer.
• Harvesting allows a harvester to make copies of metadata instances, available in a metadata store component.
The reference model in gure 1.2 presents components that are generally avail-able in or that require access to a learning object repository. A specication of services, such as the ELF services, complements this by dening how one can access these components. The ELF lists but does not specify services. Within this dissertation a concrete specication is developed for some of these services. The denition of our reference model aims at giving a better understanding of the components that are important in a LOR. Section 2.1 argues why it is important to have standardized interfaces between some of these components.
1.3.2 Digital Library
The term digital library is broad enough to cover a whole range of applications. It suggests a counterpart of a traditional library, so in a very narrow view, one could dene it as a collection of digital documents. Fox [Fox et al., 1995] remarks that although to some, a digital library evokes the vision of computerized traditional library, the real merit of a digital library lies in carrying out the functions of a digital library in a new way.
Project Gutenberg [Newby and Franks, 2003] is an example of a digital library that evokes this vision of a computerized traditional library. This eort to digi-tize and archive cultural works contains over 20.000 e-books and is supported by volunteers that help to proofread, procure and index books from which copyrights have expired.
Nowadays, a digital library goes beyond just the storage of digital documents. The Internet Archive [Kahle, 1997] is a non prot organization that maintains an example of such a digital library. In an attempt to prevent digital materials to disappear somewhere in the future, a huge digital library was constructed that includes snapshots of the World Wide Web, taken at various timestamps. A so
1.3 Learning Object Repository 7 called "wayback machine" exemplies how digital libraries can carry out functions in a new way. The Internet Archive exploits the dynamical nature of web content, and oers for each web page it indexes, a time line that allows researchers, histo-rians or students to consult archived versions of web pages. At the time writing, this wayback machine contains almost two petabytes of information and grows at a monthly rate of 20 terabytes, which eclipses the total amount of text contained in the Library of Congress.
One of the still open questions is how to set up a globally distributed digital library. Top-down approaches, such as web crawlers (Google, Internet Archive, Altavista, etc.), crawl the web and, while doing so, provide huge amounts of data that were found by following links in WWW pages. These approaches however fail at indexing the deep-web [Bergman, 2000] [He et al., 2007], content locked up inside repositories not available by following hyperlinks. Bottom-up approaches aim at tackling the deep-web problem from a "harvest and/or search" protocol side (see chapter 7).
Digital libraries are not fundamentally dierent from learning object reposito-ries. The following illustrates this by comparing the reference model for learning object repositories (see gure 1.2) to the 5S model, a unied formal theory for digital libraries [Gonçalves et al., 2004]. Streams, Structures, Spaces, Scenarios and Societies (5S) denes concepts such as digital objects, metadata, collections and services both informally and mathematically. A serialization (5SL) [André et al., 2002] of this formal model enables specifying and generating digital library applications. The remainder of this section relates learning objects, metadata and repositories, three important topics in this dissertation, to the 5S model.
• 5S denes streams as sequences of elements of an arbitrary type (e.g. bits, characters, images, etc). Within the scope of this dissertation, learning ob-jects are limited to digital obob-jects and can hence be encoded as a sequence of bits. Hence, learning objects are modelled as streams in 5S.
• In 5S, a structure species the way in which parts of a whole are arranged or organized. For instance, a markup language like HTML denes the inter-nal structure of HTML documents. Metadata have been informally dened as data about data. As 5S makes no clear distinction between data and metadata, a metadata instance is a stream of characters in the 5S model. However, metadata also imposes a structure on data and, therefore metadata instances are both streams and structures.
• Scenarios describe the possible ways to use a system to accomplish functions that the user desires. They specify the functionalities of a digital library or a component, by describing things as services, tasks, activities or operations. E.g. in gure 1.1 the components that constitute the bottom and middle layer will oer functionality to the upper layers through services.
• A Society is a set of entities (e.g. human surrogates, hardware, software components) and the relationships between them. In the context of this dissertation they are of less importance, as humans can be considered ex-ternal to a LOR. Yet, their actions might be reected in the metadata. For instance, when a new learning object is added to a digital library, the meta-data instance might contain a description of the author of the object, the indexer or even details on persons that (re)used it.
According to the 5S model, a content store and a metadata store both contain data that can be modelled with streams. Both allow for managing respectively content and metadata, and therefore dene structure. We can thus conclude that these preservation components that are important for learning object repositories, are part of a digital library according to the 5S model.
1.3.3 Institutional Repositories
Since 2002, Institutional Repositories (IR) have started to emerge. Cliord Lynch denes [Lynch, 2003] them as "a set of services that a university oers to the members of its community for the management and dissemination of digital ma-terials created by the institution and its community members". IRs are often contrasted with the prior situation where faculty members digitally manage and preserve their academic output themselves. At a technical level, an institutional repository comprises the following features:
• Through the use of an IR, an institution can organize long-term preservation. Individuals cannot do this in the long run as this preservation extends beyond their careers.
• They leverage economies of scale as a professional can provide data integrity through backups, minimize security risks by installing daily security patches, etc.
• They allow for content to change status over time. If all goes well, a paper submitted for a conference will typically change over time from "submitted" to "accepted" and nally to "published". This life cycle metadata might have implications for whether or not the document is available for download. With the creation of open source institutional repositories such as EPrints [Martin, 2003] and DSpace [Tansley et al., 2003], there are few technical challenges left in setting up an IR. The issue of dealing with long-term preservation, a research topic that is also relevant for digital libraries, is still far from being solved.
Nowadays, institutional repositories seem to compete also with traditional scholarly publishing systems that are organized as follows:
1. An academic author creates knowledge and submits a paper to a journal for publishing.
1.3 Learning Object Repository 9 2. A journal enforces the quality of its contents and therefore tasks other aca-demic editors and peer-reviewers with the responsibility to validate the sub-mitted research.
3. Journals publish the research and hence provide a large audience with access to the author's research.
4. Other academics cite this research and hence provide the authors with proper credentials.
[Roosendaal and Geurts, 1997] distinguishes four essential components in sci-entic communication:
1. The registration component allows for claiming an idea, concept or research. 2. The certication component establishes the scientic validity of a nding
and veries its quality.
3. The awareness component ensures that research is accessible and, by dis-seminating the nding, it makes sure that others remain aware of the new ndings.
4. The archiving component enables a scientic nding to be preserved over time.
Crow [Crow, 2002] makes the observation that academic institutions ultimately bear most of the costs required for each of these components. For instance, the distribution component used to be expensive for non-digital publishing (typeset-ting, prin(typeset-ting, marke(typeset-ting, etc.). But with the evolution of digital publishing, these distribution costs have declined. However, because of the integrated publishing model, these decreases of costs in one component often are not reected in reduced journal prices. Crow therefore promotes the idea of a disaggregated publishing model, enabling dierent economies of scale to be developed for each individual component. This would lead to reduced prices, when increased cost eciencies are observed in one component.
Interoperability is an important topic that implicates both the awareness and archiving component of institutional repositories. Institutions can implement search and indexing functionality to make content searchable, but can also al-low for other services to harvest their metadata. Section 1.4.4 will elaborate on the OAI-PMH protocol that enables institutions to organize awareness through harvesting.
An institutional repository can be classied as a learning object repository since it clearly deals with objects that may be used for learning, education or training. Furthermore, the reference model presented in gure 1.2 is relevant when considering awareness and archiving. Making a conceptual separation between stores for content and stores for metadata is important for both IRs and LORs as metadata should be publishable without content.
1.3.4 Referatories
The term 'referatory' is used dierently by dierent authors. In [Rogers, 2003], a referatory is used to identify online systems providing links to learning objects. Others, such as [Hart and Albrecht, 2004] dene a referatory as a gateway for locating and using repositories. For the remainder of this dissertation, a referatory is dened as an instance of a LOR as it is modelled in gure 1.2 omitting the content store. Referatories can be set up for two reasons:
1. The Multimedia Educational Resource for Learning and Online Teaching (MERLOT) organization [McMartin, 2004] has set up a referatory to support its peer reviewing system, a system that allows the MERLOT community to write reviews for learning objects that are not housed by MERLOT. In this case, a referatory was thus set up to manage additional metadata on learning objects.
2. Initiatives such as EdNA [Ivanova, 2004] have implemented referatories that are harvesting metadata to centralized search indexes. In this way, they can provide their community with a centralized search engine, providing them with transparent search access to many repositories.
Google is a referatory that implements both ideas. Not only does it continuously crawl the web, seeking for new pages to index. It also manages additional metadata to optimize its page ranking algorithm. For each URL that Google indexes, it records for instance all known web sites that are referring to that URL through a hyperlink.
Although the former gives the impression that both incentives to implement referatories can live in harmony, this is often not the case. Unlike institutional repositories that have a clear incentive (awareness) to have their metadata har-vested, organizations such as MERLOT that invested many resources in authoring peer reviews, are not willing to let external parties harvest the peer review meta-data, constituting their value proposition.
1.4 State of the art
This section covers some of the research questions that are addressed in the learn-ing object repository community. The next chapter will identify protocols that facilitate the "share and reuse" of learning objects. In this section, research is pre-sented that complements the creation of those protocols. Section 1.4.1 analyses persistent locating. This issue is important for referatories, as for these reposito-ries, the metadata store component and the content store component are not part of the same system. Next, section 1.4.2 presents XML and RDF. Both XML and RDF enable the representation of metadata, but dier in semantic capabilities. Harvesting of metadata is discussed in section 1.4.4. This technique contributes to
1.4 State of the art 11 facilitating "share and reuse" as it enables aggregating (a critical mass of) meta-data instances that are copied from dierent repositories. Section 7.2 illustrates that a protocol for harvesting and a protocol for searching can be complemen-tary. Dierent learning object repositories often support dierent metadata elds. Even when two repositories implement the same metadata schema, the specic metadata elds that are mandatory, optional or not supported can be dierent. Section 1.4.3 discusses metadata application proles that enable the specication of the status of supported metadata elds. This is important when searching and publishing metadata instances. Section 1.4.5 discusses dierent topologies for con-tent and metadata stores. Research to these topologies is important for realizing scalable, distributed networks of learning object repositories. The protocols that are specied in this dissertation complement this research, as they are applicable to all of the topologies that are discussed. Finally, section 1.4.6 briey covers some other research topics that are relevant for learning object repositories.
1.4.1 Persistent locating
The content store component and the metadata store component (see section 1.3.1) do not always reside in the same system. Metadata instances that are managed by a referatory (see section 1.3.4) refer to content that is maintained elsewhere. For these systems, it is important to record a persistent location for each learning object. For instance, when a content store is migrated to a dierent location, the locators that are managed by the referatory should not require modication.
Currently, most of the internet resources are uniquely labeled with a Uniform Resource Locator (URL). A URL is a locator and consists of a DNS name and a local name. With this information, a browser can resolve the IP address of the web server that hosts the content, and can access the content. However, since the DNS model is a dynamic model and allows for DNS entries to change or disappear over time, the location of a resource is not persistently identied by such a URL. Furthermore, local names that are usually managed by a web server are subject to change over time as well. Nowadays, most initiatives deal with persistent locating in a two step approach. A persistent globally unique identier labels a resource and unlike the DNS model it is not allowed to change over time. When a resource is requested, a resolution service resolves the identier into a location, which is usually a URL. The DOI/CrossRef linking system, a collaboration between dierent publishers, is an implementation of this model. The system assigns a unique identier to every publisher (e.g. 10.1000) and allows a publisher to create unique DOIs by namespacing their local identiers with this prex. A resolution system like the Handle system [Sun et al., 2003], can lookup the location of a DOI and provide the user with a URL. Practically, a resolution service can be oered by a web server enabling resolution to be performed by a user's web browser. This requires the DOI to be prexed with a URL. For example, if one wants to resolve DOI 10.1000/182, the address http://dx.doi.org/10.1000/182 will
resolve into a URL that points to the location of the content (or a splash screen indicating how to obtain the content). Special handle clients that communicate directly with a handle server make the use of an intermediate web server obsolete but often require a plug-in to be installed in the browser.
The appropriate copy problem is introduced [Caplan and Arms, 1999] and [Van de Sompel and Hochstenbach, 1999a]: dynamic linking systems systems like the DOI/CrossRef system cannot link to an alternative copy of a document.The ability to resolve to an alternative copy is useful to circumvent a user being pre-sented with a splash screen after requesting a restricted resource that is for instance available in the digital library of the user's institution. If a user's digital library has an alternative copy of such a paper, the DOI will probably not link to the alternative copy as the handle system is unaware of this information.
The SFX linking solution [Van de Sompel and Hochstenbach, 1999b] provided a rst generic solution that provides users with context-sensitive links and en-ables linking between link-sources and multiple link-targets. The OpenURL frame-work [Van de Sompel and Beit-Arie, 2001b] [Van de Sompel and Beit-Arie, 2001a], introduces the notion of a service component. Instead of prexing a persistent identier with a xed URL to resolve the content, the identier (together with other bibliographic metadata) is prexed with a service component that is aware of the user's context. Doing so, a service component can take into account the user's library collection (possibly with contextual information) and resolve it into an appropriate piece of content.
1.4.2 The Semantic Web
The World Wide Web allows web pages to interlink using hyperlinks, making it easy for humans to browse from document to document. As these links do not make their meaning explicit, they are dicult to interpret by software agents. The Semantic Web was therefore proposed by Tim Berners-Lee in [Berners-Lee et al., 2001], which introduced the idea of extending the WWW with RDF statements, which can easily be interpreted by machines. The article further explores the potential of representing knowledge with this framework. The RDF framework enables software agents to reason about distributed data.
In a later article [Shadbolt et al., 2006], Tim Berners-Lee and colleagues ac-knowledged that the ideas presented in the original article, remain largely unreal-ized and are still dicult to achieve in today's web. When it comes to modelling and representing metadata for the semantic web, RDF is often contrasted with XML. For instance, [Decker et al., 2000] favours the use of RDF over XML be-cause XML grammars do not include the possibility to capture the semantics of a document and hence results in a lack of a common interpretation of the data contained in the document. XML on the other hand is suited for representing metadata and very useful when it comes to one-to-one communications between parties with an advance agreement. Not needing this advance agreement is one of
1.4 State of the art 13 the strengths of RDF, as it does not rely on agreements. This however requires that mediation between RDF metadata instances should be done at runtime. This is dierent with how mediation is usually done with XML. Agreements between parties usually result in partners exporting their metadata according to a set of XML schemas. Such a preprocessing step has the advantage that the construc-tion of parsers is straightforward as one can rely on a xed schema, but has the disadvantage that the format is not as exible and extensible as RDF.
This dissertation does not take a position whether metadata should be modelled with RDF or not. The search protocol that is presented in chapter 3, has been designed in a way that it can deal with dierent metadata models and is validated later on, using metadata represented in XML. The protocol has also been validated in an RDF context. [Brunkhorst and Olmedilla, 2006] reports experiments with QEL, a query language for searching with RDF semantics.
1.4.3 Metadata Application Proles
IEEE denes metadata as information about an object, be it physical or digital. Dierent communities have dened metadata standards that t their needs. A simple standard such as Dublin Core allows for expressing key-value pairs and is widely used in the digital library community. Domain specic initiatives such as LOM (educational) or MPEG-7 (multimedia) cover more elements within a domain. Concrete implementations usually do not use all of these elds. Further-more, implementers often need to choose between many standards that are both complementary, but are also overlapping.
[Duval et al., 2002] presents a number of mechanisms through which a com-munity or organization can adopt a metadata standard. At the one hand, one can impose restrictions on existing metadata standards and for instance constrain the value space on some elements. [Heery and Patel, 2000] denes an application prole as a schema that consists of data elements drawn from one or more namespaces, combined with each other by implementers and optimized for a particular local application. Thus, an application prole can allow for the construction of mixed metadata sets. A metadata instance validates against an application prole if it does not violate any of the rules that are set in the prole. Apart from allowing an organization or community to customize its metadata model, application pro-les serve a role in establishing dierent degrees of interoperability [Duval, 2001]. For instance, the MACE project [Prause et al., 2007] and the ARIADNE com-munity [Duval et al., 2001] have both dened a rich LOM metadata application prole. Suppose that Lis the set of LOM instances:
L = {l|l is a LOM instance} (1.1) The set of valid MACE metadata instances is dened as:
The set of valid ARIADNE metadata instance is dened as:
A = {a|a∈ L ∧avalidates against the ARIADNE application prole}(1.3) Figure 1.3 illustrates that some metadata instances (e.g. "c") can implement both metadata application proles, while other instances (e.g. "a" and "b") either belong to MACE but not to ARIADNE, or vice versa. GLOBE, an organization that is presented in chapter 7, has dened a minimal metadata application prole:
G = {g|g∈ L ∧g validates against the GLOBE application prole} (1.4) In GLOBE only a small number of LOM metadata elds (title, identier, reposi-tory identier and location) have received the mandareposi-tory status. Since the meta-data elds that are mandatory in GLOBE are also mandatory in ARIADNE and MACE, all MACE and ARIADNE metadata instances are valid GLOBE instances.
Figure 1.3: ARIADNE, MACE and GLOBE metadata application proles This illustrates various degrees of interoperability. Applications that build on the GLOBE application prole, are interoperable with MACE and ARIADNE metadata. On the other hand, applications that build on metadata elements that have a mandatory status in ARIADNE might not be interoperable with all the metadata available via GLOBE.
Apart from dening the semantics of metadata, the syntax, i.e. the form in which the metadata are encoded, requires agreement. So far, these data binding approaches have been realized with RDF Schemas or XML Schemas. [Hunter and Lagoze, 2001] presents an approach for metadata interoperability using both RDF Schema and XML Schema. They conclude that there is a need for a re-examination of the two schema languages to make them more complementary.
1.4.4 Metadata harvesting
Metadata harvesting is a technique that allows for making local copies of metadata records. The best known protocol to do harvesting is the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), a protocol that enables selecting metadata records [Lagoze and Van de Sompel, 2001]. With this protocol, one can harvest an entire collection of metadata or one can do selective harvesting.
1.4 State of the art 15 Selective harvesting in OAI-PMH involves harvesting metadata that was modied within a given datespan and/or harvesting metadata that falls within a server-dened set. A server can for instance create multiple sets that enable grouping metadata. For instance, an OAI-PMH target can group metadata according to subjects, and by doing so, enables selectively harvesting metadata instances for a certain subject. Although this protocol originates from the institutional repository world, where it was introduced as a solution to make papers in e-print archives discoverable, it can nowadays serve to many dierent other scenarios. [Van de Som-pel et al., 2003] reports that the OAI-PMH protocol has been used with instances that do not validate the traditional model for learning objects and metadata, as depicted in gure 1.1. As an example, OAI-PMH has been used to harvest both metadata records in a thesaurus and usage logs. Usage logs and metadata items in a thesaurus usually do not refer to a digital learning object and hence are not an instance of the model in gure 1.1.
1.4.5 Network topology
The World Wide Web provides virtually unlimited space for content. The dis-tributed nature of the web makes discovering this content challenging. In order to make search over these resources eective, various paradigms that contribute to the overall goal of creating a global distributed library will be outlined from a network topology perspective.
Peer-to-peer (P2P) networks [Ternier et al., 2002] are networks in which every computer performs the same task. This approach can be contrasted with a clien-t/server based architecture, where the server provides dedicated services and clients access the services oered by the server to implement a meaningful interaction with the end user. In a peer-to-peer environment, every peer publishes its own informa-tion. When a peer goes oine, only the information stored in that peer becomes unavailable. When performing a query, a peer queries its own information and sends the query to other peers, which perform the same task. The partial results from the dierent peers are merged and the result of the query is returned to the sender. In a peer-to-peer network, all hosts interact as equals. There is no need for a central server which needs a lot of maintenance costs. As a consequence, a great advantage of a P2P approach is that the system becomes much more robust. When a peer gets disconnected from the network, only the information it manages itself becomes unavailable.
As P2P networks that do not broadcast queries to all peers scale better, Super-Peer networks make a P2P architecture more ecient by giving a small set of super-peers dierent capabilities. The Edutella super-peer topology [Nejdl et al., 2003] oers a back-bone of super-peers that are arranged according to the HyperCuP topology. In such a hypercube based topology, the maximum path length between two super-peers is never more then log2N, with N the number of super peers. Furthermore, this network avoids broadcasting queries to all peers by intelligently
routing queries based on clustering of peers. Peers with similar characteristics are assigned to the same super-peers. In this way, Edutella super-peers can populate their routing indices with detailed information on the connected peers.
• Schema information allows super-peers to route queries to peers that oer support for the schemas that are used in a query. This avoids for instance a Dublin Core query to be sent to a peer that only supports LOM metadata.
• As some peers support only certain metadata application proles and might not oer full support for a schema, routing tables can be populated with the set of properties that a peer supports.
• Storing (some) values of controlled vocabularies can also be advantageous to limit trac to certain peers. Adding this information to the routing indices of a super-peer, enables the super-peer to route queries to peers that support a given vocabulary value. For instance, a super-peer can record that a connected peer only supports English documents. Queries that contain the dc:language metadata eld will then not be routed to this peer if the query species that the dc:language value should be equal to a language other than "en".
Further research will focus on how query mediation can enable translating queries across dierent metadata schemas [Nejdl et al., 2003]. Such services will enable the creation of local schemas, and the denition of rules that map these local schemas several global schemas.
CORDRA (Content Object Repository Discovery and Registration/Resolution Architecture) provides a reference model for learning object repositories that de-nes amongst other things how a federation of learning object repositories should be designed and networked. At the bottom level, content repositories publish their metadata into a CORDRA metadata registry. Figure 1.4 depicts this model using the components discussed in section 1.3.1. CORDRA [Jerez et al., 2006] dictates the use of an intermediate registry of registries in which metadata from dierent communities are grouped. [Jerez et al., 2006] however points out that it is not yet clear what metadata will populate this registry. The same is valid for the master registry of registries, the top level registry. This registry could contain references to other intermediate registries, enabling the federated search at the CORDRA top level or could on the other hand harvest all content object metadata in centralized fashion.
The distributed nature of institutions and their favour to self-administer con-tent promotes distributed repositories. As a result, many of these distributed systems like CORDRA, Edutella and the ARIADNE KPS, deployed their net-work in a bottom-up approach. The Federation of DSpace using CORDRA (FeD-COR) [Manepalli et al., 2006] is an example of such a CORDRA instance, where the content repositories at the bottom layer are DSpace institutional reposito-ries. This distribution of repositories led to a change in the way repositories deal
1.5 Conclusion 17
Figure 1.4: Cordra Community
with metadata and metadata application proles [Holden, 2003]. As distributed repositories cannot function together without metadata standards, compliance to metadata standards is often obligatory. EdNA, the Education Network Australia, harvests metadata from a number of Australian collections of learning objects and requires harvested metadata to be either Dublin Core or EdNA metadata standards version 1 compliant. This syntactic compliance enables EdNA to easily integrate new repositories into their search infrastructure.
1.4.6 Other research areas
Beside the research areas presented in this section, there are numerous other areas that are relevant for learning object repository infrastructures:
• Formats for representing data, storage media and software are changing rapidly in this digital era. Research in Long-term preservation [Lorie, 2001] is concerned with archival of both data and programs that read the data so that they will still be readable somewhere in the future.
• When one wants to open up repositories and lower the boundaries for pub-lishing learning objects, ensuring quality is not a trivial task. Research dealing with quality approaches is relevant at the level of e-Learning prod-ucts and services, quality of the learning objects and quality of the metadata describing the learning objects. [Ehlers and Pawlowski, 2006]
1.5 Conclusion
This chapter presented a background for what will follow in the remainder of this dissertation and summarized other research topics that are of importance for learning object repositories.
A model for learning objects and metadata and for learning object repositories was developed. The model for learning objects and metadata is intentionally very general, as the goal of this dissertation is to enable the creation of a critical mass of learning objects. Next, a reference model is presented that analyses dierent components that are important for learning object repositories. This model es-tablishes a terminology that is used in this dissertation to identify components for
which interoperability is important. This intention diers from 5S, a formal model for digital libraries. The goal of the 5S model is to enable declarative specication and to enable the generation of digital library applications.
Despite all research eorts, digital libraries and more specically learning ob-ject repositories are often still isolated islands oering valuable content. The lack of transparent access prevents large scale reuse across repositories to become reality. Section 2.1 will discuss this problem in more detail and will propose two proto-cols that enable "share and reuse" of learning objects. Although the problems that trigger this research (see chapter 2), originate from the eld of technology enhanced learning, the protocols that will be developed in chapter 3, 4 and 5 are not specic for this research domain. Hence, they can be applied to all domains (e.g. digital libraries (section 1.3.2) and institutional repositories (section 1.3.3)) where managing digital content and metadata is of importance.
Chapter 2
Challenges in managing
Learning Objects
This chapter presents some of the challenges in managing learning objects. Sec-tion 2.1 addresses the impediments to "share and reuse" of learning objects. Aim-ing at makAim-ing both authorAim-ing and ndAim-ing learnAim-ing objects more cost eective, bringing search and publishing functionality to a front-end application enhances "share and reuse" of learning objects. This section contributes to the identication of the relevant protocols for integrating this functionality in front-end applications. These protocols enable communication between the components that were dened in section 1.3.1 and complement the research presented in section 1.4. The next sections analyse the requirements of these protocols. Section 2.2 deals with general requirements for these protocols such as heterogeneity (section 2.2.1), loosely cou-pled components (section 2.2.2) and interoperability (section 2.2.3). Next, more specic requirements for a search protocol are discussed in section 2.3. Finally, the requirements for a publishing protocol are presented in section 2.4.
It is important to stress that the issues treated in this chapter are not just the result of an arbitrary mental exercise. These requirements were collected through the author's active participation in various networks (GLOBE & PRO-LEARN [Wolpers and Grohmann, 2005] ), projects (MELT & MACE [Prause et al., 2007]), specication and standardization bodies (CEN/ISSS WS/LT [SQI, 2005] & IMS [IMS, 2003]) and while developing learning object repository software for the ARIADNE community [Duval et al., 2001].
2.1 Share and Reuse
This section outlines a strategy to improve the "share and reuse" of learning ob-jects. This problem is relevant for both companies and universities as "share and
reuse" reduces the cost of creating learning objects. The ARIADNE community has developed tools to facilitate share and reuse of learning objects. This work was at the basis of the IEEE Learning Technologies Standardization Committee Learning Object Standard (LOM) [LOM, 2002] [Duval et al., 2002] [Duval and Hodgins, 2003] standard. [Neven and Duval, 2002] observed that, since the start of the ARIADNE project, the amount of both commercial and non-commercial Learning Object Repositories has grown which leaves us with already quite a num-ber of learning objects that dier in content, technology, ideology, etc. However, one property was shared by almost all of them: the lack of a critical mass of learn-ing objects. Nowadays, this situation has improved. The GLOBE community for instance builds on SQI (see chapter 3 and 7) to provide its members with access to learning objects spread over many learning object repositories.
It has been suggested [Russell, 2006] that Metcalfe's law [Metcalfe, 1995], the more people who use a network of items, the more valuable the network and additions become, applies to learning objects too. Furthermore, the long tail phenomenon states that there is a great value in selling small volumes of (less popular) items [Anderson, 2006]. This illustrates the high value in sharing learning objects. Nevertheless, in the ARIADNE community, the observation was also made [Ternier et al., 2003a] that users are often not motivated to share learning objects that they have authored.
1. As initially, the community lacked a critical mass of learning objects, users were not able to reuse. Because they were not able to reuse, they did not benet from the ARIADNE toolset. Hence, they were not motivated to - be the rst to - share their learning objects, as there was no immediate benet for doing so.
2. A query and indexation tool provided the ARIADNE community with the facility to upload learning objects and submit them to a network of learning object repositories. Content authors often found it cumbersome to upload their learning objects and are not willing to spend the extra amount of eort to add metadata to their LO [Duval and Hodgins, 2003]. Moreover, there was again no immediate benet from doing this additional work. Most teachers for instance favoured uploading their materials directly into the environments where they were to be used by students. As sharing learning objects was not trivial and not part of the daily workow of a user, a critical mass of learning objects could not be gathered. Without a critical mass of learning objects, reuse cannot take place.
This dissertation explores two separate research tracks that complement each other in solving this "chicken & egg" problem. Because publishing content was not easy, ARIADNE lacked a critical mass. As ARIADNE was lacking a critical mass of learning objects, users were not motivated to share and contribute their materials.