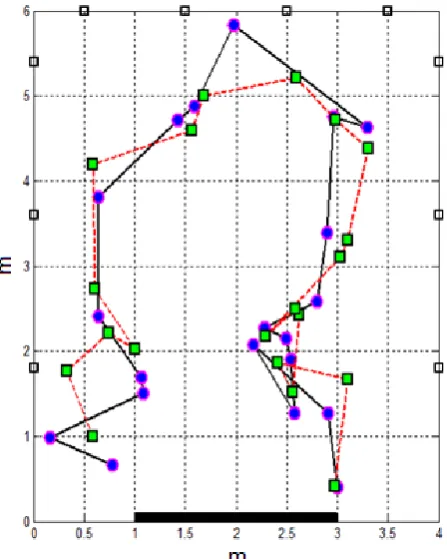
Particle Filter based Target Tracking in Wireless Sensor Networks using Support Vector Machine
Full text
Figure

Related documents
The comparison between diesel and alcohol-diesel blend has been made in terms of fuel properties characterization, engine performance such as brake power (BP)
We invite unpublished novel, original, empirical and high quality research work pertaining to recent developments & practices in the area of Computer, Business, Finance,
The RapidiOnline Services run with a unique technology called the RapidiConnector that ensures compressed and secure data transfer between RapidiOnline and the different
The patients who had lower probability of survival according to Trauma and Injury Severity Score (TRISS) had higher blood IL-6 levels on emergency department arrival (low vs..
For example, food insecurity and food access can affect people differently in urban versus rural neighborhoods, for a variety of reasons that may include the availability
Hazard assessment of debris flows for Leung King Estate of Hong Kong by incorporating GIS with numerical
The Inuence of some commonly used boundary conditions, the eect of changes in shell geometrical parameters and variations of volume fraction functions on the vibration
Administrative evidence-based practices in local health departments, Directors and Program Managers, United
