815 | P a g e
SURVEY ON WEB CONTENTS, WEB MINING AND
PAGE RANKING
V.Jayashree
1, Dr.N.Sumathi
2 1Department of Computer Science , Sri Ramakrishna College of Arts and Science (Autonomous),
(India)
2
Department of Information Technology , Sri Ramakrishna College of Arts and Science
(Autonomous), (India)
ABSTRACT
Web mining associate on the knowledge retrieval and the extraction data are analyzed. This web data process
is extracted on the available sources (server, web page, cookies).search data is retrieved on the information
retrieval. The relevancy to the user need using search rank algorithm information retrieval process is going on
the web mining. The web mining serves on the log files on the ASCII text files to be log on the user’s the high
data usage are intended on the web documents in the Information retrieval. This paper will introduce late research utilizing keywords and information retrieval. Most of the search engines are ranking their search results in response to user’s queries to make their search navigation easier and it exploresthe Agent based
weighted page ranking algorithms for web content mining to retrieve more relevant information. AWPR
algorithm retrieves the most important content information or web pages in front of end users.
Keywords-Data extraction, Web Content Mining, Page Rank, Weighted Page Rank
I.INTRODUCTION
Web mining traverse on the pattern in the web navigation mining path traversal graph are recommended on the
web mining[4]. Web traversal mining navigates on the horizontal line. The user navigation pattern in the
hyperlinks. The method is navigated on the certain pattern web content mining are categorize under the web
query. While there are many benefits to be gained from web mining, A clear drawback is the potential for severe
violations of privacy. As online learning method are expanded to the standard level. In late 2006 the education
standard and quality assurance are medium level. Now the education standard is increased better. The web
mining is created through the web logs. The web usage mining association rules are exceeded some specified
threshold. [5] Classification techniques are building under the several e-commerce areas. The culture mining is
discovered using web mining concept. The culture plays an important role predicts to be search on web
mining.[6] Web mining system is constructing under the organized structure. To avoid problems we analyze the
web data to the optimal solution to fulfill these conditions. The data base is stored by the resource to construct
web data.
Personalized PageRank is a page rank calculation where random jumps are only allowed to a subset of start
nodes. The resources of current process of calculation of Personalized PageRank are highly prohibitive. FAST
Personalized PageRank is utilized to find the target nodeset. Using the mentioned target set, the algorithm gives
an estimation of the closeness of any pair of nodes in the graph. As the time taken by the estimation of
816 | P a g e
Page Rank algorithm is the most commonly used algorithm for ranking various pages depends upon linkstructure of the web pages. Agent based Weighted PageRank is used for Web structure mining as well as Web
content mining with the help of agents. Agent based algorithm is designed at clarifying the order of the pages in
the result list so that the user may get the relevant and important pages easily in the list. AWPR algorithm is
used for web structure mining as well as web content mining techniques. Web structure mining is used to
compute the importance of the page and web content mining is used to check the page is how much related.
Importance here means the popularity of the page which means how many pages are pointing to or referred by
this particular page. It can be evaluated based on the number of in-links and out links of the page[12].
II.DATA MANAGEMNET
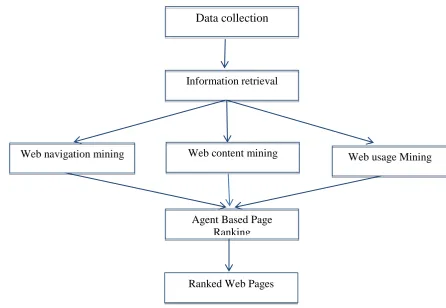
Fig. 1 Web Data Ranking Process
a. Data collection:
Data’s are collected from web page contents.Web data sets can be very large, it takes ten to hundreds of
terabytes to store on the database It cannot mine on a single server so it needs large number of server.
b. Information retrieval :
The information retrieval process related to the web mining. The extracts the relevant facts from the relevant
documents. The system is not manually feasible to the IR.The information retrieval automatically finds the
relevant documents and then filters out the non-relevant one.[2] The crawlers and robots are traverse on the
Ranked Web Pages
Data collection
Information retrieval
Web navigation mining
Web content mining
Web usage Mining
817 | P a g e
information retrieval process. The IR is dominant to the traditional database. The store the large data collectionsto the unstructured data. The IR is distinguished on the boosted search engine rankings.
c. Web navigation mining:
The path get traverse on the sequential pattern.The traverse sequence is operated on the hashing
technique.[7]The patterns are mostly sessions on the e-commerce technique.The path get traverse on the vertex
of the web browsing sessions.
d. Web content mining :
WCM is the process of extracting useful information from the contents of Webpages. Content data corresponds
to the collection of facts a Web page was designed to communicate to the users. Web content mining is related
to data mining because many data mining techniques can be applied in web content mining.The NLP technique
are significant the web content mining.The heterogeneity and the lack of structure that permeates much of the
ever-expanding information sources on the World Wide Web, such as hypertext documents, makes automated
discovery, organization, and search and indexing tools of the Internet. It extracts the information through the
web documents.
e. Web usage Mining :
Web usage mining is the process of finding out what users are looking for on the internet.The web usage is
access on the web servers. Web Usage Mining is the application of data mining techniques to discover
interesting usage patterns from Web data in order to understand and better serve the needs of Web-based
applications.The information extraction is retrieve on the machine learning techniques are analyzed on the
heterogeneous form.
f. Agent Based Page Ranking:
AWPR is a page ranking algorithm which is used to give asorted order to the web pages with a help of agent and
returned by a search engine in response to a user query. The Agent assigns larger rank values to more important
pages instead of dividing the rank value of a page evenly among its content. AWPR is a numericalvalue based
on which the web pages are displaysin order.
g. Ranked Web Pages:
Ultimately at the end of the searching query, user will get the most related ranked web pages for the surfing
query.
III.CHALLENGES
we are plan to explore other types of online user search data regarding a user search logs for more
comprehensively and robustly conducting web mining based Explorations.We improve modified graph traversal
algorithm in the Better search results using rank algorithm.
IV.SUMMARY
We have been described about the key computer science contributions made by the field, a number of prominent
818 | P a g e
discussion. The web mining methods aim to discover useful information or knowledge from the web hyperlinkstructure, page content and usage log. The student learning process explored on the microstructure of
processing electronic syllabus was investigated. The server log file and different formats available for server log
file .we improve the log files in the several types.Web usage mining has raised huge usage data today. The
quality can be improved from each step of web usage mining process. In pattern discovery and analysis step,
hybrid methods were proposed to mine more knowledge.
V. CONCLUSION
In this survey we are providing the different kinds of approach for web content mining, web usage mining, web
navigation mining. The web mining are navigated on the pattern traverse web usage log are used to describe the
server log file. The quality gets improved by web usage navigation mining.Ranked web pages using AWPR.
Web mining examination is still a testing and time requesting undertaking that requires costly programming,
huge computational base and exertion.
REFERENCES
[1] Yoon, Hong-Jun, and Georgia Tourassi. "Investigating the association between sociodemographic factors
and lung cancer risk using cyber informatics." Biomedical and Health Informatics (BHI), 2016 IEEE-EMBS
International Conference on.IEEE, 2016.
[2] Hassanian-esfahani, Roya, and Mohammad-javadKargar. "A survey on web news retrieval and
mining." Web Research (ICWR), 2016 Second International Conference on. IEEE, 2016.
[3] Karna, Nyoman, IpingSupriana, and UlfaMaulidevi. "Social CRM using web mining." Information
Technology Systems and Innovation (ICITSI), 2014 International Conference on.IEEE, 2014.
[4] More, Sagar. "Modified path traversal for an efficient web navigation mining." Advanced Communication
Control and Computing Technologies (ICACCCT), 2014 International Conference on. IEEE, 2014.
[5]Srivastava, T., PrasannaDesikan, and Vipin Kumar. "Web mining–concepts, applications and research
directions." Foundations and advances in data mining (2005): 275-307.
[6]Rudas, Imre J., and Peter Toth. "Online learning, web mining and quality assurance." Interactive
Collaborative Learning (ICL), 2014 International Conference on.IEEE, 2014.
[7] Sharma, Pratibha, SurendraYadav, and BrahmduttBohra. "A review study of server log formats for efficient
web mining." Green Computing and Internet of Things (ICGCIoT), 2015 International Conference on.IEEE,
819 | P a g e
[8] Suadaa, LyaHulliyyatus. "A survey on web usage mining techniques and applications." InformationTechnology Systems and Innovation (ICITSI), 2014 International Conference on.IEEE, 2014.
[9]Kaur, Kamaljit. "Web cultural mining and enhancing user access on web using culture." Recent Trends in Electronics, Information & Communication Technology (RTEICT), IEEE International Conference on.IEEE, 2016.
[10]Chakrabarti, Soumen, Martin Van den Berg, and Byron Dom. "Focused crawling: a new approach to
topic-specific Web resource discovery." Computer networks 31.11 (1999): 1623-1640.
[11] Jayashree.V&Balasubramanian. A“Web Search Recommendation System Using Concept Based Mining
Techniques” International Journal of Advanced Research in Computer Science and Software Engineering,
Volume 4, Issue 7, July 2014.
[12] Hao Ma, Irwin KingSenior Member,and Michael Rung-TsongLyu, Fellow, “Mining Web Graphs for