Information Stewardship: Moving From Big Data to
Big Value
By John Burke
Principal Research Analyst, Nemertes Research
Executive Summary
Big data stresses tools, networks, and storage infrastructures. The amount of data, its growth rate, performance requirements, and needs for protection in disaster all create challenges for existing systems. To survive the transition to big data, organizations should practice good information stewardship by defining policy to guide every byte of information through acquisition and classification, its lifecycle in storage, its protection and insurance against disaster, and ultimate disposition at the end of its life. Guided by the principles of good stewardship, and using some combination of new analytics and storage architectures plus the mixing of public and private cloud resources, IT can provide an infrastructure up to the challenge of big data. IT needs to understand the goals of and inputs to all big data projects to make the best storage architecture choices for supporting them and know the full costs of internal compute and storage to make proper evaluation of possible cloud options.
The Issue
About 29% of organizations say they have a “big data” initiative already; another 6% plan to before the end of 2013, and 14% are evaluating whether they have a big data problem and how to deal with it.
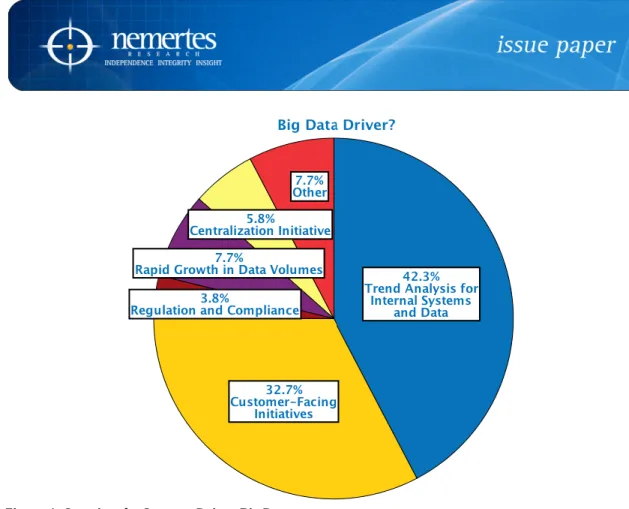
But what is big data? At its core, it is about deriving new business value from the combination of previously isolated streams of data. (Please see Figure 1.)
Figure 1: Crossing the Streams Drives Big Data
Big data is typified by:
• Massive volumes of data (in relative, not absolute, terms) • Rapid changes in data
• Multiple sources and formats of data
Big data projects often, for example, focus on combining data stored in traditional databases with unstructured data such as social media posts or video clips and semi-‐ structured data such as streams of environmental sensor readings.
Since big data is, well, big (even small companies with big data initiatives average 2 petabytes of data, and large companies grapple with orders of magnitude more), it can stress both network and storage infrastructures and can create challenges for data management and analytics tools. And, because
it brings together diverse types of information, it requires significant investment of staff time and potentially drives changes in organization. All these challenges add up to investments in staff and potentially in any or all parts of the data center infrastructure and even expansion into cloud compute and storage.
To survive the transition, organizations should practice good information stewardship.
1 Petabyte = 1024 Terabytes 1 Terabyte = 1024 Gigabytes For comparison, 1 terabyte equals approximately 8 seasons of a 1-hour HD TV show like CSI, while 1
petabyte equals a bit more than 13 years of HD programming.
Information Stewardship
Information Stewardship (IS) is driven by the principle that for every byte of information entering the organization there be policy in place defining how that information is to be stored, managed, and protected throughout its life. IS therefore comprises several disciplines:
• Data quality management
• Information lifecycle management • Information protection
• Disaster resilience
• Compliance management
Applying IS principles to big data is a path to sustainable success and the chance to wring big insights out of the data. Whether the goal of analysis is to improve
productivity or decrease costs, raise ad revenues or boost sales through customer loyalty programs, improve patient health or raise graduation rates, detect financial fraud or discern terrorist plots, underneath big data analytics lies the data. Long-‐term success with big data analytics rests on proper management of the data.
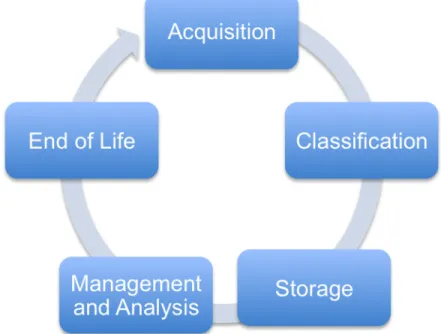
A Lifecycle for Big Data
IS tells us to pay attention to the whole lifecycle of the data starting with acquisition and attendant issues of data quality management and ending with the question of whether, how, and how long to retain data once the initial burst of use is complete.
Figure 2: The Big Data Lifecycle
Acquisition and Classification
New streams of data mean new concerns for making sure things mean what you think they mean (the IS discipline of data quality management), as well as for data security and privacy protection (IS’s information protection), and compliance (another IS discipline).
Many IT departments are used to thinking of critical data as primarily living inside databases. Data gets in through approved and controlled channels, generally with strict protections to guard consistency. When big data ramps up, data acquisition expands to encompass other less-‐controlled sources and includes new formats (such as pictures, sound, or video), and those assumptions are subverted. If two payroll records in a database refer to Jane Doe, it is usually straightforward to determine if they mean the same Jane Doe (do they point back to the same personnel record, for example). When a personnel record and a video clip of a customer complaining both refer to John Doe, do they mean the same one?
There is no way to prevent or resolve every ambiguity when disparate kinds of information are brought together. It is critical to understand the limits of disambiguation in these cases. IS says it is also crucial to have defined ways of assessing whether data in different streams are consistent with each other and whether inconsistencies will be a roadblock to use or simply a cautionary note.
Understanding what the data is also drives classification of data for purposes of managing it throughout its lifecycle. Classification serves to:
• Drive how data are secured in order to achieve and maintain compliance with
various laws, rules, and industry standards.
• Guide how data are stored in order to provide necessary performance. • Determine how disaster recovery procedures will provide for continuity of
access or restoration of the data in the event of major service disruption (the IS discipline of disaster resilience).
Storage, Management and Analysis, and Disposition
Once you have data, you want to use it, and so organizations doing big data projects have to work through issues of data management and analysis. This has implications for storage infrastructure. (It also sometimes pushes existing data management and analytics tools past their limits, which can drive adoption of alternatives to traditional SQL-‐driven relational databases, such as Hadoop.)
The IS discipline of information lifecycle management dictates that storage be tailored to the use cases it serves. To serve big data, the storage infrastructure must be able to deal with stresses big data brings along with it.
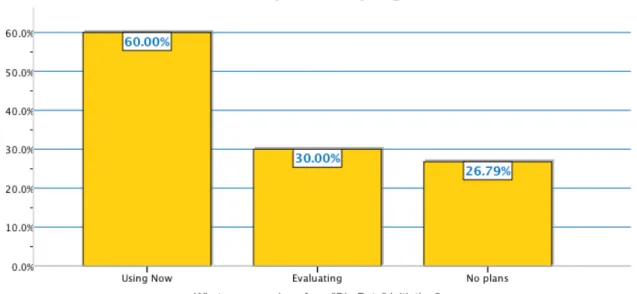
First and foremost, there is the volume of data to be managed, typically in the multiple-‐petabyte range, and the rate at which it grows—often at a much faster clip than was the case for other datasets. Beyond the volume of data there are challenges associated with servicing enough analytical transactions per second for jobs to get done in a reasonable amount of time and with the size of the individual data objects as well. In a big data environment, analysis tools or applications may want to address tens or hundreds of times as much data as existing data warehouse and business intelligence systems. Likewise, analysis may involve tossing around video or audio clips or other objects that are each much larger than typical database records. This can strain or overwhelm storage systems already in place.
Figure 3: Big Data Grows Faster...Much Faster
There are several solutions for these problems. One is to break the storage up across more storage nodes in a scale-‐out architecture. The mostly widely used data
management platform for big data, Hadoop, handles breaking a dataset across all the participating analytics nodes, each of which typically has some local or direct-‐
attached storage that it controls. Another solution is to add significant amounts of
solid-‐state disk to the environment to speed up response times to storage requests. A third is to use cloud resources to move some or all of the problems out of the data center entirely (use cloud servers and storage for the big data environment or perhaps simply to use cloud storage for older data).
IT can also use cloud resources to help with disaster resilience. Making big data resilient is a special challenge thanks to the volume of data in question as well as the speed with which it grows and the demands on storage performance created by analysis. These make continuous syncing of the full data set among data centers a
problem and push IT managers to approach the problem differently. One solution is fragmenting the data set across multiple data centers—each holding only part of the data — and replicating the fragments rather than full copies. Another is to, again, use cloud resources for disaster resilience.
And, of course, IS guides organizations to deal with the end of life question for data: Does it have an expiration date? If not, it has to be flagged for retention and provisions made for its long-‐term storage (this is another place cloud storage can come into the picture). If so, processes have to be in place to remove it from storage and audit that process for future reference.
Conclusions and Recommendations
Big data stresses tools, networks, and storage infrastructures. The volume of data in question, its rate of growth, the level of responsiveness required to perform useful analysis, and the needs of business continuity all create challenges for existing systems. To survive the transition to a big data environment, organizations should practice good information stewardship: Define policy to guide every byte of
information through a process of classification, its lifecycle in storage, protection and insurance against disaster, and ultimate disposition at end of life. Guided by IS
principles, some combination of new analytics and storage architectures and the mixing of public and private cloud resources can provide a big data infrastructure that both delivers solid performance in the face of new and dramatically more challenging workloads and remains resilient in the face of disaster.
Big data stewards:
± Understand the goals of any big data project, as well as the full spectrum of data sources involved and the data management and analysis tools under review, to make the best storage architecture choices for supporting them. ± Incorporate the full lifecycle of data in the planning for the big data.
initiative from acquisition and classification through archiving or disposal. ± Fully calculate the cost of internal storage, including staff and
environmental operating costs per terabyte of space available for use, to have a yardstick for measuring the attractiveness of cloud storage for various functions.
± Consider the costs of disaster resilience (replication tools, spare capacity, and bandwidth, plus the staff costs accompanying them).
± Evaluate cloud storage and cloud compute as adjuncts to, or replacements for, in-‐house resources in any phase of the lifecycle where they make economic sense.
About Nemertes Research: Nemertes Research is a research-‐advisory and strategic-‐ consulting firm that specializes in analyzing and quantifying the business value of emerging technologies. You can learn more about Nemertes Research at our Website,