The Popularity Parameter in Unstructured P2P File Sharing Networks
JAIME LLORET, JUAN R. DIAZ, JOSE M. JIMÉNEZ, MANUEL ESTEVE
Department of Communications
Polytechnic University of Valencia
Camino de Vera s/n, 46022 Valencia
SPAIN
[email protected], [email protected], [email protected], [email protected]
Abstract: - Since P2P became extremely popular between Internet users, many researchers have tried to modelthose P2P networks. One of the parameters, used in these models, is the popularity of a file. Some articles demonstrate that, if a file is so popular, the probability to find this file inside the P2P file sharing network is bigger. This article deals with popularity parameter in P2P file sharing networks. In order to do so, the unstructured public domain Peer-to-Peer networks Gnutella, FastTrack, OpenNap, eDonkey, Soulseek and MP2P have been measured. The authors have established a relationship between some films, songs, programs and documents found in web search engines and the same files found in public domain P2P file sharing networks. If all these analyzed Peer-To-Peer file-sharing networks were interconnected, the probability to find a desired file will be incremented. On the other hand, t
hose analyzed P2P networks seems to be specialized
in different type of files as it is shown in the paper.
Key-Words: - Peer to peer, File Popularity, File Search, Peer-To-Peer Interconnection.
1 Introduction
Since Internet became accessible to the world, one of the first users concerns is to find the file or the information is looking for. A measurement study [1] of the deep Web reveals that it contains nearly 550 billion of pages and it is doubling each year. On the other hand, the surface Web contains an estimated 2.5 billion documents, growing at a rate of 7.5 million documents per day, and the deep Web is approximately 500 times greater than that visible to conventional search engines. Nowadays there are a lot of web search engines [2] and a lot of them have billions of textual documents indexed [3]. The Web search engines can be classified in three types: - Crawler-Based Search Engines, such as Google,
which create their listings automatically. They "crawl" or "spider" documents by following one hypertext link to another, then people search through what they have found.
- Human-Powered Directories, such as Open
Directory. It depends on humans for its listings. People have to submit a short description to the directory for their entire site. A search looks for matches only in the descriptions submitted. - Hybrid Search Engines, such as MSN search. It
is maintained by a combination of previous types and present both results.
The Web search engines employ some kind of centralized algorithm. In order to have the best
results, these algorithms use location/frequency method (search engines check to see if the search keywords appear near the top of a web page and how often keywords appear in relation to other words in a web page) and the off-the-page factor (like clickthrough measurement). They are the major factor in how search engines determine the popularity of a document. Habitually, search results are sorted in popularity order.
Currently there are a lot of P2P file-sharing networks in existence, and many of them have millions of on-line users and millions of data shared [4]. In this type of networks, what a user really wants is to find the file is looking for to download it. The probability to find a desired file, in the network where a user is searching, is associated to the popularity of the file. Some other parameters like the type of file it can be shared, the availability of the file and its replication are also considered. In order to have real search measurements about some films, songs, programs and documents, we have selected some of the most popular public domain P2P file-sharing networks. Those selected networks are Gnutella [5], FastTrack [6], Opennap [7], Edonkey [8], Soulseek [9] and MP2P [10]. Although there are other networks [11], we have selected this ones because they are so popular between Internet users.
On the other hand, we have selected two crawler-based search engines, Google and Altavista, and one search directory, Yahoo!, in order to find the same files in Web search engines.
Later on, it is established a relationship between the results obtained in web search engines and the results obtained in the peer-to-peer file-sharing networks aforementioned. It will give us the popularity of those files.
This paper is structured as follows. Section 2 discusses the search techniques used in Peer-To-Peer file-sharing networks. In section 3, it is described the popularity parameter. Section 4 shows the measurements taken in the Peer-To-Peer file-sharing networks and Web search engines selected. It is also shown the relationship between them. In section 5, it is discussed how can be increased the probability to find a desired file in Peer-To-Peer file-sharing networks. Finally, in Section 6, there are conclusions and future works.
2 Search Techniques in Peer to Peer
File Sharing Networks
In order to find a file in a P2P network, a search is needed. The implemented search algorithm in every network depends on the type of the network (centralized P2P, decentralized P2P and partially centralized). There are several types of searching algorithms and they can be classified as follows:
2.1 Loosely controlled P2P search
algorithms.
They are used in decentralized Peer-To-Peer networks. The data placement is not defined because the nodes of the network decide what files they want to share. There are two kind of loosely controlled P2P search algorithms:
2.1.1 Broadcast search technique
The query search is sent to all directly connected neighbours and they forward the query to all their neighbours. The query is propagated to sufficient number of nodes to match the entry or until a TTL value. If the neighbour has the content, it replies, otherwise if floods the query to its neighbours. This type of search is used by Gnutella network.
2.1.2 Selective search technique
The query search is sent to some nodes called supernodes that act as a central nodes. This supernodes will perform the search to other supernodes in order to find the requested file. The
clients with a higher bandwidth and process capacity will be considered automatically supernodes. Those clients with less bandwidth will be supernode clients. This type of system uses an flow control algorithm for sending queries and replies. It also has a diagram of priorities used to discard some messages. This type of search is used by FastTrack and Gnutella 2 [12].
2.1.3 Randomly search technique
The query is sent to k number of randomly selected neighbours. Each of these neighbours forward the query to any of their randomly selected neighbours. The query is propagated to sufficient number of nodes to match the entry or until a TTL value. This technique is described in [13].
2.1.4 Probably search technique
In this case, the queries are sent to specific clients which are considered to have the greater probability finding the request. Each node maintains a probability value corresponding to each neighbour which defines the chances that a query will be forwarded to that neighbour. An example of this type of search is APS [14].
2.2 Strongly controlled P2P search
algorithms.
In structured P2P networks, data placement and topology within the P2P file-sharing network is tightly controlled. These networks are based in Distributes Hash Tables (DHT), and the nodes do not decide what they store and share with other peers in the network. The data placement is defined by the algorithm. When a document is published, it is routed to the client whose ID is the most similar to the document’s ID. In order to find a file, the queries are sent to the client whose ID is the most similar to the document’s ID. The process is repeated until a close match is found. The main search problem in this type of networks is that they are not very efficient for keyword based search. This type of search is used by Freenet [15], CAN [16], Chord [17], Pastry [18] and Tapestry[19].
2.3 Server-centrally controlled P2P search
algorithms.
They are used in peer-to-peer networks where there is a server or a group of servers. This type of search is very simple and has short query time. There are two kind of server-centrally controlled P2P search algorithms:
2.3.1 Single-Server search technique
Initially, P2P clients connect to a central server where they publish their shared files (the files’ names, their sizes, etc). When a search query is sent to the server, it looks up in its index database. If there is a matching entry, the IP address of the node that shares the file is sent to the one that requested it, and then, the direct connection and download takes place. This technique is used by the Soulseek network.
2.3.2 Farm-of-Servers search technique
In this type of P2P networks, there is a group of available servers called “brokers”. P2P clients must be authenticated to one of those central servers. Each “broker” has the indexes of the local clients and in some cases the indexes of some files from neighbour “brokers”. When a client performs a query to a “broker”, this one searches in its local database and if it doesn’t find a match, it uses the local index in order to find a neighbour “broker” that can send the request. The server indexes are not static and it can change according to the files in the system. The networks OpenNap, eDonkey and MP2P use this technique.
3 The Popularity Parameter
There are different ways to measure the popularity parameter, it depends on where this parameter is needed. The following are some ways to measure the popularity parameter:
- In Web search engines, as such Google, it is given a lot of importance to the number of websites that link to a website, so the popularity parameter is measured by the number of incoming links to the site. With this popularity parameter it is built the PageRank.
- The popularity of a file can be related to the number of times the file has been retrieved from the surveyed archive during a certain period of time. It is used in web servers.
- The popularity of a file can be determined by the number of users that have requested its download. It is used to measure how many users use a certain software.
- The popularity parameter in movies can be
related with the audience it have had in cinemas, the number of DVD sold or the number of rented movies by videoclubs.
- The popularity parameter in songs can be
related with radio or web top lists.
-
In structured peer-to-peer networks, thepopularity of a file or a service is measured by the number of times the file is requested. It also affects to the probability that it is replicated by
other peers. The popularity of a file governs how long it stays in the network and how often it is replicated.
In peer-to-peer file-sharing networks, the popularity can be mathematically expressed as follows. Objects in a peer-to-peer file-sharing networks do not have the same popularity. Assuming that there are m files of interest in one P2P network and qi represents their normalized
relative popularity (number of queries issued for it), it is verified:
1 1
=
∑
i=m qi (1)All selected networks are unstructured public domain peer-to-peer networks. So, there is no control over network topology or data placement in any of them. Some of those networks are Zipf-like distributions, as such Gnutella and Napster [20][21].
α α i
i q
m
i i
∑
== 1 1 1
(2) Where α is a Zipf coefficient and i is the i-th most popular file. This Zipf distribution can be further used to determine the probability for a query to be associated with the i-th most requested file qi.
Other studies demonstrates that FastTrack and other P2P file-sharing systems are non-Zipf behavior [22][23].
Assuming that each file i is replicated on ri
nodes, the total number of interesting files stored in the network is R:
∑
== m
i i
r R
1
(3) We can assume that the most popular file is also the most replicated. Analyzed P2P file-sharing networks have rigid assumptions on how replications of objects happen in the system. Only nodes that request a file makes copies of the file.
On the other hand, in some networks, as such Gnutella (decentralized) and FastTrack (partially decentralized), search consists of randomly probing sites until the desired file is found. Thus, the probability to find a file Pr(k) on the k’th probe is given by [24]:
1
1
)
(
Pr
−
−
=
k i i i
n
r
n
r
k
(4)95%
1% 4% 0% eDonkey FastTrack Gnutella2 OpenNap soulseek MP2P
91%
8% 0%
1% 1%
eDonkey FastTrack Gnutella2 OpenNap soulseek MP2P
91% 8% 1% 1% 0% 0%
Figure 3: Software percentage Figure 4: Documents percentage 83%
15%
1%1% 0%
eDonkey FastTrack Gnutella2 OpenNap soulseek MP2P
37%
59%
0% 1% 2% 1%
eDonkey FastTrack Gnutella2 OpenNap soulseek MP2P
Figure 1: Movies percentage Figure 2: Songs percentage
83% 15% 1% 1% 0% 0%
37% 59% 1% 2% 0% 2%
Gnutella FastTrack OpenNap eDonkey MP2P SoulSeek
Average number of users 181 * 3.467.918 256.003 1.428.175 244.418 8981 Average number of shared files 55.540 * 631.678.681 158.902.178 103.469.627 59.756.764 n/t Average size of total shared data 0,294 GB* 4.947.261 GB 5.409.326 GB n/t 236.564 GB n/t
Max. Variation of users (%) 41,49 21,33 42,02 39,13 5,50 1,17
Max. Variation of shared files (%) 260,35 18,63 53,65 36,76 5,47 n/t Max. Variation of shared data (%) 349,49 15,72 34,58 n/t 5,79 n/t
4 Search results
We have measured the average number and the maximum variation of peers, shared files and total amount of data shared of the six selected networks in order to know how many peers and information are inside the selected networks. Those data are shown in Table 1. It has to be taken into account that Gnutella, FastTrack, Opennap, Edonkey, and Soulseek networks permit to search every type of file, but MP2P only permits audio files (mp3, ogg, wma, etc.).
In order to establish in which network is more probably to find movies, songs, software and documents, we have measured the number of peers that have files with keywords of 12 movies, 24 songs, 12 software programs and 8 documents. This measures have been taken in every one of the six networks.
To avoid wrong results in our searches we have employed next methodology:
- To limit the results to the type of file we were looking for, the type of file was added (avi, mpg, exe, pdf, doc, etc.) to they keywords of the search.
- The number of software versions were not
included in the keyword of the search.
- The name of movies that have second deliveries (shreck 2, Spiderman 2 and so on) were not included.
Although there are peers interconnected to more than one peer-to-peer network, they are insignificant compared with the total number of peers of every network. On the other hand, the files shared by those peers could not be the same for all connected networks.
If all analyzed networks were interconnected, the type of files shared by every network to the other are different. Although all of them supports every type of network (except MP2P), those networks seems to be specialized in different type of files, as it is shown in Figures 1 to 4. The table 2 shows which is the ranking for those six networks
In order to know the popularity of those movies, songs, software and documents, results have been compared with two search engines, Google and Altavista, and one search directory, Yahoo!.
95% 1% 4% 0% 0% 0%
P2P Network Movies Songs Software Documents
eDonkey 1st 2nd 1st 1st
FastTrack 2nd 1st 2nd 3rd
Gnutella2 4th 4th 3rd 2nd
OpenNap 3rd 3rd 4th 4th
Soulseek 5th 6th 5th 5th
MP2P X 5th X X
Table 2. Ranking in movies, songs, software and documents
To avoid wrong results in web searches and to limit the results to the type of file we are looking for, we have employed next methodology:
- For movie searches we have added the word
“movie” to the search.
- For song searches, we have added not only the name of the song, but the name of the group. - For documents searches we have added the type
of the document (pdf, doc, etc.).
- For software searches we have searched only specific manufacturers software.
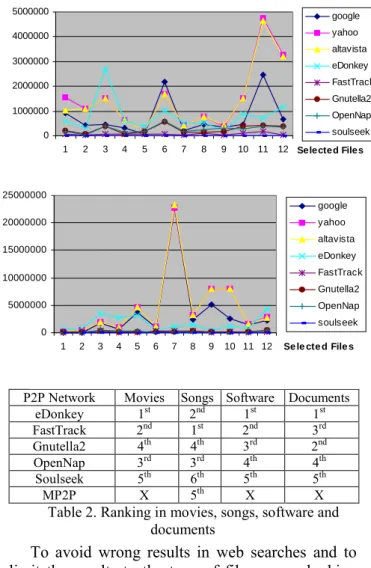
In order to analyze the P2P data collected and compare it with Web search engines we have scaled eDonkey and FastTrack data results with a x50 factor and OpenNap, soulseek and MP2P with x1000 factor. These factors have been used in movies, songs and software. Figures 5 to 8 shows the data collected. This measures have been taken only for comparative popularity purposes, it is pretended to know if a popular file in Web search engines will give a popular file in peer-to-peer file-sharing networks. As it can be seen in those figures, there is no result of movies, software and documents for MP2P due to its only-songs implementation.
5 Increasing the Probability to Find
the Desired File
The files are not always in the peer-to-peer network where the user is searching. Most of the networks implemented nowadays support any filetype, but there are some that only supports audio files. What is needed is a system which will allow to search in every P2P network and download from every peer of every network.
The union of Peer-To-Peer file-sharing networks, by the creation of a Peer-To-Peer file-sharing networks Interconnection System, will give greater probability to find the desired file. If there is n Peer-To-Peer file-sharing networks, the total probability will be:
( )
( )
nn n n n n n n
P
P
P
P
P
P
P
P
P
P
P
P
E
P
...
1
...
...
1
...
2 1 1 1 ... 1 1 1 1 1 − = > > > − = > > = > = =−
+
+
−
+
+
+
−
=
∪
∑
∑
∑
∑
η β α β η α γ β α β γ α β α β α α α α α (5)As it can be seen, the total probability to find the desired file will be greater than the probability of one them only, but less than the sum of all of them.
6 Conclusion
Six unstructured public domain Peer-to-Peer networks have been measured in order to know what is the P2P file sharing network with most search results in movies, songs, software and documents. As a result of our measurements, t
hose networks
seems to be specialized in different type of files
.Figure 5: Number of results of Movies Figure 6: Number of results of Songs
Figure 7: Number of results of Software Figure 8: Number of results of Documents
0 1000000 2000000 3000000 4000000 5000000
1 2 3 4 5 6 7 8 9 10 11 12 Selected Files
google yahoo altavista eDonkey FastTrack Gnutella2 OpenNap soulseek 0 500000 1000000 1500000 2000000 2500000 3000000
1 3 5 7 9 11 13 15 17 19 21 23Selected Files
google yahoo altavista eDonkey FastTrack Gnutella2 OpenNap soulseek 0 5000000 10000000 15000000 20000000 25000000
1 2 3 4 5 6 7 8 9 10 11 12 Se le cte d File s
google yahoo altavista eDonkey FastTrack Gnutella2 OpenNap soulseek 0 20000 40000 60000 80000 100000 120000 140000
1 2 3 4 5 6 7 Selected Files
google yahoo altavista eDonkey FastTrack Gnutella2 OpenNap soulseek
The search results have been compared with those obtained in Web search engines. We have checked that if a file is popular in Web search engines, it is also popular in P2P file-sharing networks. Future works will try to find the mathematical relationship between the file popularity in Web searches engines and the file popularity in P2P file-sharing networks.
acknowledgements
Authors want to acknowledge to Mr. Miguel A. Granados from Polytechnic School of Gandia for his data collection.
References:
[1] Michael K. Bergman, The Deep Web:
Surfacing Hidden Value, The Journal of
Electronic Publishing, Volume 7, Issue 1.
August, 2001.
[2] Danny Sullivan, Nielsen NetRatings Search Engine Ratings, July 14, 2004. Available at: http://searchenginewatch.com/reports/article.ph p/2156451
[3] Danny Sullivan, Search Engine Sizes,
September 2, 2003. Available at: http://searchenginewatch.com/reports/article.ph p/2156481
[4] J. Lloret Mauri, B. Molina Moreno, C. Palau Salvador y M. Esteve Domingo. Public Peer-To-Peer Filesharing Networks Evaluation. The 2nd Iasted International Conference On Communication And Computer Networks. MIT
Cambridge, MA, USA. November 2004.
[5] Eytan Adar and Bernardo Huberman. Free
riding on gnutella. First Monday, 5(10), October 2000.
[6] Nathaniel Leibowitz, Matei Ripeanu, and
Adam Wierzbicki. Deconstructing the Kazaa
Network, 3rd IEEE Workshop on Internet
Applications, San Jose, USA June 2003.
[7] OpenNap http://opennap.sourceforge.net/
[8] Oliver Heckmann and Axel Bock. The
eDonkey 2000 Protocol. Technical Report
KOM-TR-08-2002, Multim. Communications Lab, Darmstadt University of Technology,
December 2002.
[9] Soulseek http://www.slsk.org
[10]MP2P http://www.blubster.com/protocol1.html [11]Wikipedia
http://www.wikipedia.org/wiki/Peer-to-peer [12]Gnutella2 http://www.gnutella2.com
[13]Christos Gkantsidis, Milena Mihail, and Amin Saberi, Random Walks in Peer-to-Peer Networks, The 23rd Conference of the IEEE Communications Society (Infocom 2004), Hong
Kong, March 2004
[14]D. Tsoumakos and N. Roussopoulos: Adaptive Probabilistic Search for Peer-to-Peer Networks.
In Proceedings of the 3rd IEEE International Conference on P2P Computing, Linkoping,
Sweden, September 2003.
[15]I. Clarke et al. Freenet: A distributed
anonymous information storage and retrieval system, ICSI Workshop on Design Issues in Anonymity and Unobservability, Int'l Computer
Science Inst., 2000.
[16]S. Ratnasamy, P. Francis, M. Handley, R. Karp, S. Shenker, A Scalable Content-Adressable Network, ACM Sigcomm 2001, San
Diego, CA, USA, August 2001,
[17]I. Stoica, R. Morris, D.Karger, F.Kaashoek, H. Balakrishnan, Chord: A Scalable Peer-To-Peer Lookup Service for Internet Applications, ACM Sigcomm 2001, San Diego, USA, August 2001,
[18]A. Rowstron and P. Druschel, Pastry: Scalable, distributed object location and routing for large-scale peer-to-peer systems, IFIP/ACM International Conference on Distributed Systems Platforms (Middleware), heidelberg,
Germany, pages 329-350, November, 2001
[19]B. Zhou, D.A. Joseph, J. Kubiatowicz,
Tapestry: a fault tolerant wide area network infraestructure, UC Berkeley technical report UCB/CSD-01-1141
[20]Kunwadee Sripanidkulchai, the popularity of gnutella queries and its implications on scalability. In O’Reilly’s www.openp2p.com, February 2001
[21]Zihui Ge, Daniel R. Figueiredo, Sharad
Jaiswal, Jim Kurose, Don Towsley. Modeling Peer-Peer File Sharing Systems, Proceedings IEEE INFOCOM 2003, San Francisco,
March-April 2003.
[22]Krishna P. Gummadi, Richard J. Dunn, Stefan Saroiu, Steven D. Gribble, Henry M. Levy, John Zahorjan, Measurement, Modeling, and Analysis of a Peer-to-Peer File-Sharing Workload, Proceedings of the nineteenth ACM symposium on Operating systems principles,
2003, p. 314-329.
[23]J. Chu, K. Labonte, and B. N. Levine.
Availability and locality measurements of peer-to-peer file-sharing systems. In Proceedings of SPIE ITCom: Scalability and Traffic Control in IP Networks, volume 4868, July 2002.
[24]Qin Lv, Pei Cao, Edith Cohen, Kai Li, and Scott Shenker, Search and replication in unstructured peer-to- peer networks,
Proceedings of the 16th international conference on Supercomputing, ACM Press,