2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
Market models for federated clouds
Ioan Petri, Javier Diaz-Montes, Mengsong Zou, Tom Beach, Omer Rana and Manish Parashar
Abstract—Multi-cloud systems have enabled resource and service providers to co-exist in a market where the relationship between clients and services depends on the nature of an application and can be subject to a variety of different Quality of Service (QoS) constraints. Deciding whether a cloud provider should host (or finds it profitable to host) a service in the long-term would be influenced by parameters such as the service price, the QoS guarantees required by customers, the deployment cost (taking into account both cost of resource provisioning and operational expenditure, e.g. energy costs) and the constraints over which these guarantees should be met. In a federated cloud system users can combine specialist capabilities offered by a limited number of providers, at particular cost bands – such as availability of specialist co-processors and software libraries. In addition, federation also enables applications to be scaled on-demand and restricts lock in to the capabilities of a particular provider. We devise a market model to support federated clouds and investigate its efficiency in two real application scenarios:(i)energy
optimisation in built environmentsand (ii)cancer image processingboth requiring significant computational resources to execute
simulations. We describe and evaluate the establishment of such an application based federation and identify a cost-decision based mechanism to determine when tasks should beoutsourcedto external sites in the federation. The following contributions
are provided: (i) understanding the criteria for accessing sites within a federated cloud dynamically, taking into account factors such as performance, cost, user perceived value, and specific application requirements; (ii) developing and deploying a cost based federated cloud framework for supporting real applications over three federated sites at Cardiff (UK), Rutgers and Indiana (USA), (iii) a performance analysis of the application scenarios to determine how task submission could be supported across these three sites, subject to particular revenue targets.
Index Terms—Federated Clouds, Cloud Computing, Cost Models, Market Mechanism, CometCloud
F
1
I
NTRODUCTIONR
ESEARCHin cloud computing has led to a variety of mechanisms for the acquisition and use of re-sources, enabling ‘elastic’ and on-demand acquisition and use of such resources. The availability of cloud systems also provides application developers with the potential to change the way these applications interact with computational infrastructure (which, tra-ditionally, has been static and must be known a priori). Applications such as simulations are carried out using specialist software (such as EnergyPlus [3] or Octave [4]) which require significant computational resources and data management capability, and can generally be a time consuming process. The users of these applications are also often interested in car-rying out what-if scenarios by altering simulation parameters to determine various patterns within the solution space. Being able to utilize computational resources at external sites provides one option for reducing execution times of such applications, espe-cially if local resources (i) do not support suitable computational, data storage or hosting capability; (ii)I. Petri and O. F. Rana are with School of Computer Science & Informatics, Cardiff University, UK. E-mail: [email protected],[email protected]
Tom Beach is with School of Engineering, Cardiff University, UK. E-mail: [email protected]
J.Diaz-Montes, M. Zou and M. Parashar are with Cloud and Autonomic Computing Center, Rutgers University, NJ USA. E-mail:[email protected],[email protected]
are already being used for other applications and therefore likely to be unavailable over a particular simulation period; and/or (iii) are too expensive to acquire or use due to high operational costs. Cloud computing provides a useful alternative to enable users to conduct more complex simulations, which would be otherwise impossible due to limited avail-ability of local resources. Most significantly, the elastic nature of cloud computing enables resources to be acquired dynamically (perhaps after carrying out an initial set of simulations), preventing the need to guess the number of required resources beforehand. Using this approach, a user may be able to carry out a what-if investigation (on a smaller data set or with a restricted parameter range) on local resources, before making use of cloud based resources where the exact number of resources may grow with data volumes. This work focuses on understanding, from the application perspective, what factors need to be considered when integrating resources across multiple sites. In particular, our research question develops around the decision process involved when consider-ing the utilization of remote resources over local ones (especially from a cost perspective) and how remote resources that are part of a federated cloud could be dynamically integrated and used alongside local ones. Federation of cloud systems (and the use of “cloud bursting” techniques) enables connection of local in-frastructure to a global marketplace where partici-pants can transact (buy and sell) capacity on demand. This ability to scale out, on demand, provides one of
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
the unique benefits of cloud computing – although being able to undertake such scale out across multi-ple providers/vendors remains a challenge. Accessing global services instead of increasing costs associated with building new infrastructure (which may not be fully utilised and may only be needed to support peaks in workload over short time frames) can pro-vide significant benefits. More importantly, organi-sations with spare capacity in their data centre can monetize that capacity by selling it to other providers through a marketplace, creating an additional source of revenue [17], [18], [32].
In this paper, we present an application-centric federation between Cardiff (UK), Rutgers (US) and Indiana(US) Universities. Using this environment, we make two main contributions: (i) how resources across multiple institutions can be federated to create a mar-ketplace; (ii) how specialist capability located across multiple, distributed sites – where matching can take place between task requirements and such capability – can be effectively utilised in a particular application context. We use two specific applications as part of our framework: (i) EnergyPlus – which is used to calculate energy flow in a built environment and (ii) Octave used for cancer image processing, and show how a common framework integrating these applications can emerge governed by specific cost models. We also present a decision function that de-termines where tasks should be computed based on a cost analysis. Our federation model uses CometCloud [28], [16] – an autonomic computing engine based on the Comet [29] decentralized coordination substrate, that supports heterogeneous and dynamic federated cloud/grid/HPC infrastructures. CometCloud sup-ports the integration of public/private clouds and enables autonomic cloudbursts, i.e., dynamic scale-out to clouds to address extreme requirements such as heterogeneous and dynamic workloads and spikes in demands. CometCloud has been integrated with a variety of other systems, such as FutureGrid and OpenStack. Current work is focused on integrating CometCloud with IBM SoftLayer.
The rest of this paper is organised as follows: Sections 1 and 2 outline the development and use of federated clouds, providing a key motivation for our work (and analysing several related approaches in this area). In Section 3 we present several cost models which we consider relevant for our work. Section 4 presents the model explaining the methodological de-tails of CometCloud and the aggregated CometCloud federation. The evaluation of our implemented system is presented in section 7. We conclude and identify our contributions in sections 9 and 8 respectively.
2
R
ELATED WORKSeveral approaches have been reported in literature to support cloud federation. Villegas et al. [19] proposed
a composition of cloud providers as an integrated (or federated) cloud environment in a layered service model. Assuncao et al. [20] described an approach for extending a local cluster to a cloud resource using different scheduling strategies. Along the same lines, Ostermann et al. [21] extended a grid workflow ap-plication development and computing infrastructure to include cloud resources and carried out experi-ments on the Austrian Grid and an academic cloud installation of Eucalyptus using a scientific workflow application. Similarly, Vazquez et al. [22] proposed an architecture for an elastic grid infrastructure using the GridWay meta-scheduler and extended grid resources to support Nimbus. Bittencourt et al. [23] proposed an infrastructure to manage the execution of service workflows in a hybrid system composed of both grid and cloud computing resources. Analogously, Riteau et al. [24] proposed a computing model where resources from multiple cloud providers are used to create large-scale distributed virtual clusters. They used resources from two experimental testbeds, Fu-tureGrid in the United States and Grid’5000 in France to achieve this. Goiri et al. [25] explore federation from the perspective of a profit-driven policy for outsourcing (a required capability) by attempting to minimise the use of the external resource (and thereby the price of resources paid to the external provider). Toosi et al. [18] focuses on specifying reliable poli-cies to enable providers to decide which incoming request to select and prioritise, thereby demonstrating that policies can provide a significant impact on the providers’ performance [26], [27]. Other significant work in Cloud federation is the use of in-network analysis capability offered in the GENI project (which makes use of OpenFlow and MiddleBox) to offer a range of services within a network, rather then at network end points. GENICloud 1 enables “slices” across such network elements to be reserved by differ-ent applications/users, with commonly used scripts available for users to deploy on these slices. Such slices are supported over in-network general-purpose processors fronted by OpenFlow switches. A number of practical “test-bed” federations have been devel-oped using these concepts, such as JGN-X (Japan), SAVI (Canada), Ofelia (Europe). Such infrastructures provide a useful enabler for deploying real world applications, however, they do not take into account specific requirements of an application into account. Other related work in this context is the “OCCI” activity with the Open Grid Forum, where Cloud in-teroperability has been the main focus. Similarly, com-mercial providers, such as IBM, also support Cloud-based enterprise federation using their “GridIron” system – which makes use of Web services to support federation. There is also considerable interest in cloud federation and interoperability from IEEE – as part of
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
“P2302: Standard for Intercloud Interoperability and Federation (SIIF)” effort2.
Several cost models currently exist to encourage greater use of cloud resources (ranging from auctions to spot pricing), primarily to enable providers to optimise on potential revenue they could generate from their resource pool. Kondo et al. [7] explore the adoption of cloud computing platforms and services by the scientific community focusing on the perfor-mance and monetary cost-benefits for scientific ap-plications. This study compares the performance and monetary cost-benefits of clouds versus desktop grid applications, based on computational size and storage requirements. When comparing the two technologies it has been found that hosts register at a rate of 124 cloud nodes per day and the ratio of volunteer nodes needed to achieve the compute power of a small EC2 instance is about 2.83 active volunteer hosts to 1. Douglas et al. [6] describe how provenance information can be used to determine how much an application execution is likely to cost on public clouds (primarily focusing on Amazon EC2 instances). They extend their job submission system with cost and resource information based on previous executions to estimate the cost of executing scientific computing applications. A key assumption in this approach is that the backend computational infrastructure does not change over time and that execution times/costs previously recorded are likely to be representative when considered in the future. Generally, reserved resource instances are likely to be cheaper than on-demand instances. When making a reservation, a cloud consumers pays a providers before consump-tion, making it easier for the provider to plan its resource provisioning (and potentially energy usage). This however has the disadvantage of uncertainty of a consumer’s future demand. Cost optimisation algorithms have been proposed for adjusting the cost/benefit tradeoff between reservation of resources and allocation of on-demand resources [8].
Although these solutions enable participants to in-crease capacity and extend an existing market place, these efforts are unclear on when a local request should be sent to a remote site (in a federation) and the types of policies that may be used to govern such a federation model. From a cost perspective, these studies leave undetermined the efficiency spe-cific cloud cost models have with regards to a real world application, and are often more abstract in their description – focusing on general job/task character-istics rather than consider specific ones. In this work we describe various cost models that can be used to ensure greater performance and cost management both for users and providers by considering realistic application requirements.
2. http://standards.ieee.org/develop/project/2302.html
3
C
OST MODELSSeveral studies investigate the problem of costs in clouds infrastructures [10], [11], [13] trying to propose a cost minimisation algorithm for making service placement decision in clouds. Alongside these cost models, authors have proposed pricing schemes for maximising revenues [12]. In the filed of dynamic cost models for cloud computing, Xu et al. [9] propose a framework for improving profits and reducing cost. The proposed framework enables the provider to lease its computing resources in the form of virtual machines to users, and charge the users for the pe-riod these resources are used. The proposed scenario considers a cloud provider with fixed capacity using a spot price according to the market demand. A revenue maximisation solution is presented as a finite-horizon stochastic dynamic program, with stochastic demand arrivals/ departures. The result shows that the optimal pricing policy exhibits time and utilisation monotonicity, and the optimal revenue has a concave structure. The evaluation of economic efficiency of a cloud system with indicators for cost optimisa-tion have been addressed by developing a web tool where users can test various costing options. Various analysis are used in the internal cloud environment to compare capability with cost. The evaluation is undertaken with a suite of metrics and formulas con-sidering the characters of virtualization and elasticity. Utilisation cost leverages the metrics items defined in the cloud and takes workload, i.e. number of VMs cur-rently running, as input. Furthermore, dependencies among different cost metrics are identified and used in the calculation of utilisation cost. These models are embedded into a tool which can calculate cost without knowing the exact data of every cost item and provides a flexible way to analyse the effect of different metrics on the cost [14]. Understanding cloud computing cost models can help users to make informed decisions about which provider to use. As identified previously, cloud providers have various cost models based on an expected demand/workload profile or determined business objectives. Such cloud cost models are listed below:
Consumption-based cost model– where clients only pay for the resources they use. This is particularly relevant in IaaS offerings such as Amazon. The advantage is on both sides, as providers can balance their costs and clients only pay for resources they request such as disk space, CPU time and network traffic.
Subscription-cost pricing model – where clients pay a subscription charge for using a service for a period of time – typically on a monthly basis. This subscription cost typically provides unlimited usage (subject to some “fair use” constraints) during the subscription period. This model is dominant in SaaS offerings such as IBM SmartCloud for Social Business [33].
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
no charge or heavily-discounted service whereas the providers receive most of their revenue from adver-tisers. This model is quite common in cloud media services such as free TV provider net2TV.
Market-based cost model– where a client is charged on a per-unit-time basis. The market price varies over time based on supply and demand and the client can acquire the service at the current price for immediate use. Within this cost model services can also be pur-chased based on a bidding process at a reduced price. Amazon EC2 Spot Instances is an example of a market based model. A number or variants to this model have been implemented using multiple concurrent auction markets – and subject to significant research in cloud brokerage.
Group buying cost model – where clients can acquire reduced cost services only if there are enough clients interested in a deal. Profit can be achieved by both sides as long as there is a sufficient level of de-mand. An example of the group buying cost model is Groupon [15]. A deal is valid over a certain period of time, where purchase orders are accepted from users. Computation related to purchase orders is undertaken only after the deal is over, hence the estimated time of completion (ETC) is calculated assuming that the earliest start time is the end of the deal. Moreover, the deal is constrained by the number of clients interested in the service/product and potential impact on the reputation of the provider. The following cases can be identified as part of the group buying cost model: • Sufficient demand – where the deal is accepted due to a sufficient number of clients accepting the offer. Subsequently, there is a computation of a start time in order to grant an ETC to the users. • Insufficient demand – where there are not enough clients interested in the deal. This leads to the following cases: (i) the provider can continue of-fering the service identified in the deal, accepting subsequent costs due to limited demand from clients, but gaining on potential reputation bene-fits or (ii) the provider cancels the deal, minimis-ing costs but losminimis-ing reputation as purchase orders are cancelled and no computation is performed. As cloud computing evolves, we envision that other cost models will emerge. These future models are expected to be market-oriented and extend (pure) auction oriented systems that attract consumers to acquire services and provide enough price flexibility. Other possibilities range from comparison sites, ag-gregation services and more complex group buying models.
4
A
PPLICATIONS
CENARIOSIn this section we describe two application scenar-ios, demonstrating how CometCloud federation can greatly facilitate the scalability of these applications.
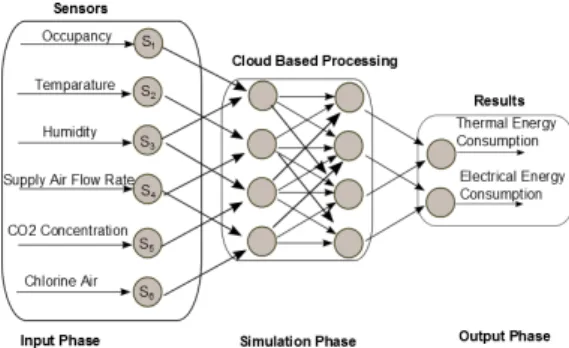
Fig. 1: EnergyPlus sensor application
Section 4.1 describes an application focusing on en-ergy simulations within built environments and sec-tion 4.2 describes a cancer imaging applicasec-tion. The first application is centered on the use of data from sensors embedded within a building, while the sec-ond focusses on the processing of image-based data requiring high end computing resources.
4.1 EnergyPlus for real-time energy optimisation
EnergyPlus has been demonstrated to provide an efficacious tool for running energy simulations [1], [2]. In EnergyPlus, inputs and outputs are specified by means of ASCII (text) files. The following types of input are used: (i) Input Data Dictionary (IDD) that describes the types (classes) of input objects and the data associated with each object; (ii) Input Data File (IDF) that contains all the data for a particular simulation; and (iii) Weather Data File (EPW) that contains all the data for exterior climate of a building. From a computational perspective, depending on the size of a building (which influences the the number and range of parameters being considered) Energy-Plus requires significant computational resources to execute. For relatively smaller building models (with a small number of surfaces, zones, and systems), which do not require large amount of computer memory, processor speed is generally more significant than I/O. For large models, main memory and internal cache have a greater influence on reducing run time. If an energy model run will produce lots of hourly or time step data, I/O access speed and latency also become important in reducing run time.
When undertaking simulation based optimisation with EnergyPlus in cloud based infrastructures a key aspect for both building (facility) managers and (cloud) infrastructure providers is to minimise time and costs. Hence, facility managers require simula-tion results within a given time frame; and a cloud provider/data centre manager is interested in reduc-ing costs associated with executreduc-ing the simulation and possible penalties due to an inability to comply with deadlines. As a number of EnergyPlus instances need to be concurrently executed, there are two parameters that are particularly important to identify: (i) complex-ity of the building model; (ii) the period to simulate. In
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
Fig. 2: Octave cancer image processing application
addition, the cloud system needs to support: (i) com-pletion time deadline: assuming that sensors generate readings every 15 minutes (for the particular building we consider in this case study), a new configuration of the building is constructed at this interval. As illustrated in Figure 1, the optimisation process needs to use the updated building configuration based on the latest readings as input and return optimised set points within this interval; (ii) results quality: an optimisation process, as identified in this study, is composed of a number of EnergyPlus simulations. Depending on the complexity of the building and the period to simulate, a time interval is associated with each optimisation process.
4.2 Octave for Cancer Image Processing
Medical imaging identifies a technique or process used to create images of the human body (or parts and associated function) for clinical purposes (medical procedures seeking to reveal, diagnose, or examine disease). Measurement and recording techniques are designed to produce images with corresponding data susceptible to be represented as a parameter graph or a map which contain information about the measure-ment location. All these types of data need further analysis and patterns need to be observed and diag-nosis applied.
In cancer image processing an image is split in parts which are computed separately on distributed machines (see Figure 2). The results are then merged and patterns are observed and analysed. The image analysis system works with a specific image patch obtained based on previous medical evaluations. This image patch is then segmented into several closed bins with equal intervals with high weights in center and decreasing weights outwards. The segmentation of the patch has to be equally divided into segments, from which a historical annual histogram (HAH) is calculated and concatenated together. This reconstruc-tion process of the various segments is undertaken by running multiple Octave simulation instances. This reconstruction has to consider a set of requirements: (1) has to be scale and rotation invariant; (2) has to capture spatial configuration of image features; and
(3) has to be suitable for hierarchical searching in the sub-image retrieval [5]. As a result, the system ap-pears to have reached the practical level of a diagnosis assistance system of the second-opiniontype in which the physician and the computer collaborate. Such a cloud system can contribute to the efficiency of cancer screening process as part of the diagnosis assistance by providing an automatic screening system in which the computer checks the image before it is diagnosed by the physician, so that the number of images to be checked by the physician is significantly reduced. This can be extremely efficacious, as in the near future, with the use of computers in mass screening, the number of images taken per patient will be drastically increased. In order to achieve the required level of assistance in cancer screening it is necessary to ensure the accuracy of tumor region recognition by testing and adopting new complex algorithms.
5
C
LOUDF
EDERATIONM
ARKETPLACEWe develop a CometCloud-based federation where resource exchange is undertaken in a marketplace. Us-ing CometCloud we develop a common “coordination space” that is logically viewable across multiple sites in the federation (but physically distributed across sites). This coordination space is used as the basis to provide a variety of different market mechanisms, supporting users to submit requests and providers to respond with offers. This section describes how the federated market framework has been developed.
5.1 CometCloud Federation Setup
CometCloud is an autonomic computing engine based on the Comet [29] decentralized coordina-tion substrate, and supports highly heterogeneous and dynamic cloud/grid/High Performance Comput-ing infrastructures, enablComput-ing the integration of pub-lic/private clouds and autonomic cloudbursts, i.e., dy-namic scale-out to clouds to address extreme require-ments such as heterogeneous and dynamic workloads and spikes in demands. Conceptually, CometCloud is composed of a programming layer, service layer and infrastructure layer. The infrastructure layer uses a dynamic self-organizing overlay to interconnect dis-tributed resources of various kind and offer them as a single pool of resources. The service layer pro-vides a range of services to support autonomics at the programming and application level. This layer supports a Linda-like [30] tuple space coordination model and provides a virtual shared-space abstraction as well as associative access primitives. Dynamically constructed transient spaces are also supported to allow applications to explicitly exploit context locality to improve system performance. Asynchronous (pub-lish/subscribe) messaging and event services are also
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
provided by this layer. The programming layer pro-vides the basis for application development and man-agement. It supports a range of paradigms including the master/worker/Bag-of-Tasks. Masters generate tasks and workers consume them. Masters and work-ers can communicate via the virtual shared space or using a direct connection. Scheduling and monitoring of tasks are supported by the application framework. The task consistency service handles lost/failed tasks. Each site in the federation has a number of available workers and a master that receives requests: (i) locally – identifying tasks received from users at the same site; (ii) remotely – requests from users at another site. A user submits a request (EnergyPlus or Octave with configuration parameters) to the master node at one federation site. The master determines the number of rounds of simulation to run, where each round of simulation identifies a unique combination of parameter ranges. Each simulation is deployed on one CometCloud worker. The master must decide how many tasks to run based on a cost based de-cision criteria. We assume that there is one worker per compute/data access node. All workers are the same, hence the master needs to decide the num-ber of workers allocated to local vs. external/remote requests. When one site has a high workload and it is unable to process requests from local users within their deadlines, it negotiate for the outsourcing of requests to other remote sites. This could range from two cloud systems sharing workload to a cloud outsourcing some of its workload to multiple other cloud systems. Conversely this ability allows systems with a lower workload to utilise spare capacity by accepting outsourced tasks from other cloud systems. Practically, this process of task exchange is undertaken by the master nodes of the two clouds negotiating how many tasks to be exchanged. Once this has been completed the master node on the receiving cloud informs its workers (using CometSpace) about the number of tasks it is taking from a remote site, and the connection details of the request handler from where the task is to be fetched. Subsequently, when a worker comes to execute a task from an external cloud system, it then connects to the request handler of the remote cloud to collect the task and any associated data.
5.2 Aggregated CometCloud Federation
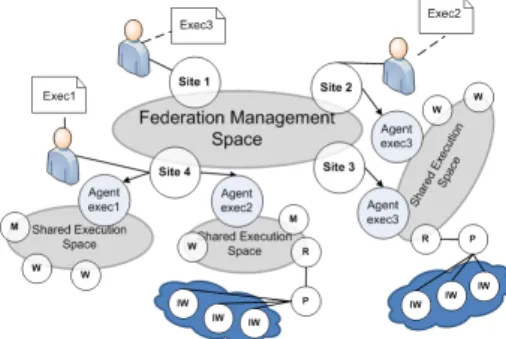
In the CometCloud federation model, each site com-municates with others to identify itself, negotiate the terms of interaction, discover available resources and advertise its own resources and capabilities. In this way, a federated management space is created at runtime and sites can join and leave at will. This feder-ation model does not have any centralized component and users can access the federation from any site (making it more fault tolerant) – see Figure 3. Another key benefit of this model is that since each site can
differentiate itself based on specialist capability, it is possible to schedule requests to take advantage of such capabilities.
Fig. 3: The overall Federation Management Space, here (M) denotes a master, (W) is a worker, (IW) an isolated worker, (P) a proxy, and (R) is a request handler.
The federation model is based on the Comet [29] coordination “spaces” (an abstraction, based on the availability of a distributed shared memory that all users and providers can access and observe, enabling information sharing by publishing requests/offers to/for information to this shared memory). In par-ticular, we have decided to use two kinds of spaces in the federation. First, we have a single federated management space used to create the actual feder-ation and orchestrate the different resources. This space is used to exchange any operational messages for discovering resources, announcing changes at a site, routing users’ request to the appropriate site(s), or initiating negotiations to create ad-hoc execution spaces. On the other hand, we can have multiple shared execution spaces that are created on-demand to satisfy computing needs of the users. Execution spaces can be created in the context of a single site to provision local resources or to support acloudburst
to public clouds or external high performance com-puting systems. Moreover, they can be used to create a private sub-federation across several sites. This case can be useful when several sites have some common interest and they decide to jointly target certain types of tasks as a specialized community.
As shown in Figure 3, each shared execution space is controlled by an agent that initially creates such space and subsequently coordinates access to re-sources for the execution of a particular set of tasks. Agents can act as a master node within the space to manage task execution, or delegate this role to a ded-icated master (M) when some specific functionality is required. Moreover, agents deploy workers to actually compute the tasks. These workers can be in a trusted network and be part of the shared execution space, or they can be part of external resources such as a public cloud and therefore in a non-trusted network. The first type of workers are called secure workers (W) and can pull tasks directly from the space. Meanwhile, the
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
second type of workers are called isolated workers (IW) and cannot interact directly with the shared space. Instead, they have to interact through a proxy (P) and a request handler (R) to be able to pull tasks from the space.
5.3 Decision Policies
A key policy is for each site to attempt to increase revenue by hosting/executing remote tasks without excessively compromising execution time (starvation) of local tasks running on the system. For developing our policies we use various tuning parameters such as:crepresenting the cost per second per node andt the average execution time per task.
General Policy: When a new job is submitted into Comet space, the following action is taken depending on the type of task. For each task, we calculate the time to complete locally – i.e. ttc = ttc(s) +ttc(e), where ttc(s) is the time until the job can start and ttc(e)is the time needed for job to execute.
Policy for Local Tasks:When evaluating a local task the policy is to always accept local tasks, thus local tasks have a non-rejection policy, according to which tasks submitted from local users will never be rejected but queued.
Policy for Remote Tasks: When evaluating a remote task the policy is to accept as many remote tasks as long as ttc < t by ensuring that the average execution time per task (t) is always higher then the time to complete locally (ttc), with an associated price of p=ttc(e)∗c. Remote tasks have a rejection policy attached, according to which remote tasks can be rejected when the site cannot meet the deadline and when accepting remote tasks can affect the pro-cessing of local tasks. When outsourcing tasks, a site requests price quotations from all other connected sites and sends as many tasks as possible to the cheapest of these. This policy will be repeated until all tasks have been outsourced. Depending on the number of sites involved, this process could generate significant price information traffic between sites. In our current prototype we consider two sites involved in the federation. To aid scalability, we also foresee the availability of specialist broker services which manage pricing information from multiple sites and can update this information periodically by polling for this information from site manager agents/nodes.
Market Policy: In this policy both local and remote tasks go to a common market for offers from every site interested in executing them. As in the previous cases, tasks are discriminated based on their origin to decide the offered price as well as the resources. Sites only place offers if ttc < t.
6
I
MPLEMENTATIONO
VERVIEWIn our CometCloud federated system, a site must have valid credentials (authorized SSH keys), and config-ured parameters such as IP address, ports, number of
workers. To integrate with an external site, Comet-Cloud provides gateways enabling requests to be forwarded to these infrastructures. As part of our fed-eration framework we use three sites: the Cardiff site consists of 12 machines, each with 12 CPU cores. Each physical machine uses a KVM (Kernel-based Virtual Machine (VM)) hypervisor. Each VM runs Ubuntu Linux utilising one 3.2GHz core with 1GB of RAM and 10 GB storage. In this deployment, workers, master and request handler are running on a separate VM:(i) workers are in charge of computing the actual tasks received from the request handler, (ii) the request handler is responsible for selecting and forwarding tasks to external workers at other federation sites and (iii) the master generates tasks based on user requests, submits tasks into CometSpace and collects results. The networking infrastructure is 1Gbps, with an av-erage latency of 0.706ms. At this site, one EnergyPlus simulation takes on average 6 mins to execute (5 min 57.935 sec). The Rutgers site is deployed on a cluster with 32 dedicated machines. Each node has 8 cores, 6 GB memory, 146 GB storage and a 1Gb network connection, with average latency of 0.227ms. Indiana site: makes use of OpenStack, as part of the FutureGrid project. We use medium instances, each with 2 cores and 4GB of memory, and average latency of the cloud virtual network being 0.706 ms. Each federation site has a site manager that controls one publisher and several subscriber processes, where the publisher puts tuples into the federated space and the subscriber retrieves the desired ones. Tuples can be used to exchange operational messages or to describe tasks that need to be computed. The site manager, including the publisher and subscriber processes are running on a single machine with network access to the rest of the sites. The master and workers are all running in independent machines.
7
E
VALUATIONIn this section we evaluate the status of the federated cloud when two different cost models are used. We seek to identify the advantages of each cost model and its appropriateness for application deployment. We consider that application deployment on cloud infrastructures have particularities especially when they illustrate realistic scenarios. With such a vari-ability in execution, cost models need to be adapted in order to ensure the requirements underpinning the application (i.e. quality of services, deadline, etc) and maximizing the benefits for clients and providers. Hence, the focus of the experiments is to evaluate a multi-cloud federated system governed by different cost market models in the context of real applications. As previously mentioned, experimental data is taken from two applications: (i)building energy optimisation
and (ii) cancer image processing, based on which we have determined the frequency of tasks, incoming
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
load and job complexity. We evaluate two different cost model configurations: (a) consumption-based cost model and (b) “Groupon” cost model based on which sites have the option of outsourcing to remote sites.
7.1 Energy Simulation Application Scenario
A user request represents a job defined as
[input, obj, deadline], where input identifies the input data represented as [IDF, W,[param]], IDF represents the building model to be simulated, W represents the weather file required for the simulation, [param] defines a set of parameter ranges associated with the IDF file that need to be optimised [param] = [ri → (xm, xn)]. A job obj encodes properties of the optimisation processobjective: [outV arN ame, min/max], defining the name of the output variable to be optimised outV arN ame and the target of the optimisation process min/max,min:minimising the outV arN ame or max:maximising the outV arN ame.Deadline is a parameters defining the time interval associated with the job submitted.
7.1.1 Consumption-based cost model
We consider a cost based function f(X) : C → R where C is a set of constraints(cost,deadline) and R is a set of decisions based on the existing constraints C. Each Master decides how to compute the received job based on a locally computed decision function. Based on a cost analysis the Master can decide: (i) where to compute the tasks: (a) locally or (b) remotely; (ii) how many iterations need to be run giving the deadline received from the user. All the costs have been calculated in pounds (£) derived from Amazon EC2 cost.
Cost(total) =Cost(T) +Cost(S) +Cost(E) (1) Cost with data transfer:Cost(T) – identifies the cost of transferring the data from one site to another. This cost is composed by the cost with transferring the input from one federation site to another and the cost with transferring the results between sites. S(IDF) represents the size of the IDF file(MB), S(W) repre-sents the size of the weather file(MB), N reprerepre-sents the number of tuples exchanges between sites, S(T) represents the size of a tuple(MB) and C(MBps) is the cost per megabyte of storage per second (see Table 1). Cost(T) = [(S(IDF) +S(W) + (N∗S(T)))∗C(M Bps)] (2) Cost with storage:Cost(S) – identifies a type of cost associated with storing the data composed by the in-put submitted by the user, inin-put transferred between sites, results transferred between sites(see Table 1).
Cost(S) = [(T∗(W∗(S(DF)+S(W)+S(IDF))))∗C(M Bps)] (3) Cost with execution: Cost(E) – is the cost deter-mined by the actual deployment of the EnergyPlus instances. This cost is related to the complexity of the objective submitted by the user (and influences the number of EnergyPlus instances that need to be run).
C(E) = [C(CP U s)∗S] (4)
In the calculation of the total costC(T)we have used the following parameters:
TABLE 1: Total cost parameters
Parameter Description
S(IDF) the size of the IDF mode (MB) S(W) the size of the weather file (MB)
S(T) the size of the tuple (MB) S(DF) the size of the resulted data file (MB) C(MBt) Cost Per MegaByte of transfer (£) C(MBps) Cost Per Megabyte of storage per second (£) C(CPUs) Cost Per CPU Per Seconds(£)
N Number of tuples exchanged S Number of Seconds of CPU Time used T Total length seconds until final answer found W Number of workers used on remote system
7.1.2 Experiments
In our experiments we consider the following param-eters: (i) CPU time of remote site to determine time spent by each worker to compute tasks; (ii) storage time on the remote site as the amount of time needed to store data remotely; and (iii) the amount of data being transferred across sites.
TABLE 2: Input Parameters: Experiment 1
P1 P2 P3 P4 Deadline
{16,18,20,22,24} {0,1} {0,1} {0,1} 1 Hour
TABLE 3: Results: Experiment 1 Single Cloud Federated Cloud
Nodes 3 6
Cost £0 £7.46
Tasks 38 38
Deadline 1 hour 1 hour
Tuples exchanged - 15
CPU on remote site - 5626.45 Sec Storage on remote site - 1877.10 Sec Completed tasks 34/38 38/38 in 55min 40s
Experiment 1: Job completed: With the parameter ranges identified in Table 2, the federation site has two options: (i) run tasks on the local infrastructure (single cloud case) or (ii) outsource some tasks to a remote site (federation cloud case). In Table 3 we observe that in the case of single cloud there is no cost associated with processing as all tasks run locally. However because the tasks generated based on the job parameter ranges have a corresponding deadline of 1 hour, only 34 out of 38 can be completed. As these tasks represent EnergyPlus simulations, running a subset of simulations can impact the quality of results. In the second part of this experiment some tasks are outsourced. From Table 3 we observe that the total number of nodes used to compute the tasks within a federation context is 6 workers which has a direct impact on the total time consumed. In the federation context all tasks successfully complete in
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
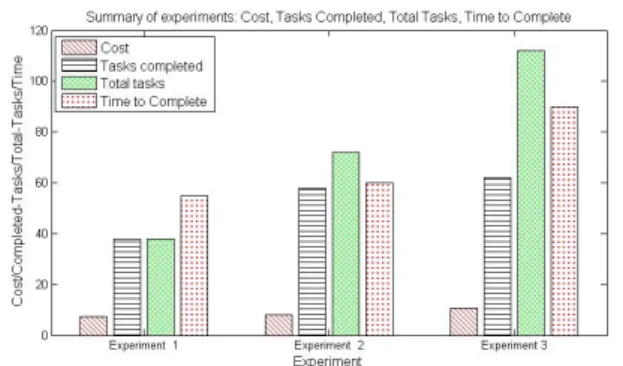
55 minutes, by outsourcing 15 tasks to the remote site. We can conclude that a cost effective decision is to process as many tasks as possible locally. This is only possible when the parameters ranges are small and consequently the number of tasks derived can be deployed exclusively on the local infrastructure. However, at the local site only 34 out of 38 tasks are completed. When the parameter ranges are large, resulting in a higher number of tasks, the federation option can reduce cost and increase the quality of results. When outsourcing to remote sites more tasks can be completed as illustrated in Table 3. The process of outsourcing has an associated cost of 7.46£.
TABLE 4: Input Parameter: Experiment 2
P1 P2 P3 P4 Deadline
{16,17,18,19,20,21,22,23,24} {0,1} {0,1} {0,1} 1 Hour
TABLE 5: Results: Experiment 2 Single Cloud Federated Cloud
Nodes 3 6
Cost 0 £7.90
Tasks 72 72
Deadline 1 hour 1 hour
Tuples exchanged - 15
CPU on remote site - 5637.27 Sec Storage on remote site - 1869.41 Sec Completed tasks 37/72 48/72
Experiment 2: Job uncompleted: In this experiment we increase the parameter ranges and consequently the number of tasks that need to be processed (but maintain the 1 hour deadline). We can observe from Table 5 that in the context of single cloud federation (3 workers) only 37 out of 72 tasks are completed within the deadline of 1 hour. On the other hand, when using a federation with 6 workers we observe that 58 tasks are completed in the same deadline. This takes place by exchanging 15 tuples between the two federation sites, with increased cost for execution and storage. Contrary to experiment 1 where most of the tasks are successfully completed within the single federation cloud, in this experiment we observe that only 48 out of 72 tasks are completed. We can conclude that in some cases, according to user requests, neither single or federated cloud is suitable. However there is a significant improvement in terms of number of tasks completed when using cloud federation – in the con-text of experiment 2, 11 more tasks are completed. It must be noted, that the percentage of tasks completed has a direct impact on the quality of results, which may involve reducing the total cost of energy use within a building. In comparison with experiment 1, there is an increase in cost of task execution, due to increased cost of using computational and storage resources remotely.
Fig. 4: Summary of experimental results for federated clouds
TABLE 6: Input Parameters: Experiment 3
P1 P2 P3 P4 Deadline
{14,15,16,17,18,19,20 {0,1} {0,1} {0,1} 1h 30 min ,21,22,23,24,25,26,27}
TABLE 7: Results: Experiment 3 Single Cloud Federated Cloud
Nodes 3 6
Cost 0 £10.70
Tasks 112 112
Deadline 1 h 30 min 1 h 30 min
Tuples exchanged - 22
CPU on remote site - 7983.74 sec Storage on remote site - 2687.15 sec Completed tasks 42/112 62/112
Experiment 3: Job uncompleted–parameters ranges ex-tended: In this experiment we increase the parameter ranges producing a greater number of tasks. In addi-tion, we extend the deadline associated to 1 hour and 30 minutes. The input parameters of this experiment are provided in Table 6. We show in this experiment that the application federation represents a complex problem that necessitates significant computing re-sources to run. In the single federation scenario we use 3 workers to compute a number of 112 tasks based on the parameter ranges submitted by the user. The overall number of tasks completed with single cloud is 42. Acknowledging that the quality of results is proportional to the number of tasks completed, we can conclude that in the context of this experiment single cloud federation provide unsatisfactory results. However, when using the federation to outsource a percentage of tasks we observe that the number of tasks completed increases to 62. This was achieved by using a total of 6 worker at the federated site. In terms of cost associated with outsourcing, it can be concluded that the higher the number of tasks to be processed, the higher the cost for storage and execution.
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See 7.2 Cancer Image Processing Application
Sce-nario
In this scenario, a task represents an Octave simula-tion and a job is formed by a number of simulasimula-tions. Each job returns a result within a particular time-frame and has a certain quality of results. In this scenario, we consider three federated sites using a market policy and study how the total cost varies over time when executing tasks. In this policy both local and remote tasks go to a common market for offers from every site interested in executing them. As in the previous cases, tasks are discriminated based on their origin to decide the offered price as well as the resources. One federated site does not perform the real computation of tasks, it is only responsible for receiving client requests and parsing the parameter ranges, giving bids based on a number of parameters combinations and sending the tasks to local master/worker. We assign one local master, one local worker and one external worker to each site. Local workers only consume local tasks, while external workers can consume both local and external tasks. The cost of computing a task is calculated based on the type of the task, the task location/origin and worker type and measured in conventionally in monetary units(m.u.).
TABLE 8: Aggregated CometCloud-Experiment Re-sult
Experiment Completed Tasks Total Cost(m.u.) Minimum Cost 472/1600 1458 Maximum Task Number 956/1600 3027
We have created 200 requests, each of them be-ing parsed to generate eight sub-tasks. In total we generate a number of 1600 tasks. The deadline for each task is 100 minutes and the normal completion time for each task is 30-35 minutes. We also assign a cost to complete for each task. Using a market policy, each site bids for consuming tasks and based on a decision function the winner to compute the tasks is chosen. We use two different decision functions in our experiments:
Experiment 1: Minimum Cost Scenario – In the first experiment, we modified our decision function for determine a winner from the bidding to consider the cost as the most important factor. In this case, the federated site that promises to give the lowest price for computing the tasks wins the bid.
Experiment 2: Maximum Number of Tasks – In contrast to the first experiment, the decision function now chooses the federated site that promises to be able to finish the highest amount of tasks before the deadline. As illustrated in Table 8, the results of these two experiments show significant differences in total cost and number of completed tasks. For the minimum cost scenario, the final cost is about half of the cost
of the maximum number of tasks scenario. While in the maximum number of tasks scenario, the number of completed tasks is almost twice comparing with the minimum cost scenario. Since the number of com-pleted tasks can be correlated to the quality of results, we can conclude that different decision function could significantly affect the cost and the quality of results.
7.2.1 Groupon Cost Model
In this scenario we have three federated sites using a market policy. However, in this case one of the sites will have the groupon-like buying cost model (see Section 3) and offer services in bulk for a discounted price, while the others will keep using a regular pricing model. From the user’s perspective, the main difference is that in the groupon model there is the assumption that client requests are processed after the deal is over, while in the regular pricing model client requests are executed as soon as possible. In this scenario we consider that each site has ten available workers to execute tasks. We have chosen Rutgers site to be the groupon site – focusing on computing tasks during the period of time that the deal is active. This site will periodically generate new groupon deals specifying deal start time, deal end time, minimum number of required clients, and the discounted cost ratio. In this experiment, we generated three deals as described in Table 9.
TABLE 9: Groupon Deal Detail Information ID StartTime EndTime Min Buyer Num Discount
1 0 100 50 40%
2 140 190 30 60%
3 230 300 30 80%
In this scenario we have considered the following metrics:
• Price: Regular bidding price is calculated based on the operational costs and the provide’s desired profit. Groupon price is calculated by applying a discount over the regular price. This discounts as-sumes that the operational costs are lower when a large number of requests are processed together. In our experiments we consider the cost to be proportional to the time required to compute the workload.
RegularP rice=P rof it+Cost (5)
GrouponP rice=P rof it+Cost−Discount (6) • Reputation:The reputationRof a site is calculated using the scores obtained after processing client requests,R= 1
n n
X
i=1
(Score), where score is a value among -1, 0 and 1. A site obtains a score of 1 if the all the tasks involving a client request
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See 0 0.1 0.2 0.3 0.4 0.5 0.6 50 100 150 200 250 300 350 Price ($ ) Time (minutes) Rutgers Site(Groupon) Cardiff Site Indiana Site
(a) Task distribution and the price that clients paid for them
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 50 100 150 200 250 300 350 Total R evenue ( $ ) Time (minutes) Rutgers Site(Groupon) Cardiff Site Indiana Site (b) Total revenue
Fig. 5: Summary of experimental results of Maximize Price Influence
0 0.1 0.2 0.3 0.4 0.5 0.6 50 100 150 200 250 300 350 Price ($ ) Time (minutes) Rutgers Site(Groupon) Cardiff Site Indiana Site
(a) Task distribution and the price that clients paid for them
0 0.2 0.4 0.6 0.8 1 1.2 50 100 150 200 250 300 350 Total R evenue ( $ ) Time (minutes) Rutgers Site(Groupon) Cardiff Site Indiana Site (b) Total revenue
Fig. 6: Summary of experimental results of Maximize Reputation Influence
is completed within the deadline and 0 if the deadline is missed, -1 is obtained when a groupon site cancels a deal due to insufficient number of clients.
• Delay Time: For regular sites, this is the time be-tween client request submission and start execu-tion. For groupon site, the delay time is generally longer because it also includes the time spent waiting for the end of the deal.
• Estimated Time of Completion (ETC): The ETC of certain computation is the Delay Time plus the execution time required to complete the compu-tation. In order for a user to even consider a site, the ETC proposed for certain computation has to be lower or equal to the computation deadline. In this scenario we will have 180 client requests, each of them involving the execution of four sub-tasks. We simulate the execution of tasks using real traces from previous executions of the Cancer appli-cation. All client requests go to a common market place looking for offers from every site interested in executing them. Each interested site places offers and then the client decides which site executes its tasks. A decision function is applied to all valid offers (i.e. ET C < deadline) to decide which one is the best for the client. Since we consider that a site only sends an
offer when ET C < deadline, then all offers a client receives are valid. Our decision function includes parameters, such as, price, reputation, and delay time. The decision function to minimize is presented in equation 7.
S=w(P)∗P rice+w(R)∗(1−Reputation) +w(D)∗Delay (7) The relevance of each parameter can be specified using a weightingw(x). We use percentages to iden-tify the importance of each parameter to the overall solution. Hence, the weights are values between 0 and 1, andw(P) +w(R) +w(D) = 1. Equation 7 includes
Price, which is influenced by the time required to compute the workload (the longer the execution time, the higher the price). We also include the Reputation
as this identifies the reliability of a site or provider. The decision function uses1−reputation because in the best case scenario the reputation is 1. Finally, we have theDelaythat may be important when the client wants to start the execution as soon as possible and is probably not interested in models such as groupon. Every time the groupon site wins an auction (client buys the deal), it puts the client requests in a waiting list. Once the deal is over, the groupon site has to decide whether it will fulfill the deal and process all waiting requests or not. This decision is taken
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
based on the number of clients that bought the deal W aitRequets, the minimum number of required buy-ers M inRequiredRequests, and the reputation of the site. We identify the following cases:
• if there are enough clients (W aitRequets >= M inRequiredRequests) then the deal is granted and requests are processed as promised.
• if there are not enough clients (W aitRequets < M inRequiredRequests) then the site evaluates how cancelling the deal will affect its reputa-tion. In order to maintain a good reputation, if W aitRequets > 0.5∗M inRequiredRequests and Reputation < 0.5 then the site will grant the deal and process the requests as promised, which may involve higher operational costs and affect to the obtained profit; In any other case, the site cancels the deal, returns the money to the clients and assumes a loss in reputation. In other words, groupon site will choose between losing reputation or still computing all tasks with higher cost and lower profit.
7.2.2 Experiments
Experiment 1: Maximize Price Influence: In this experi-ment, we assigned the following weights to the deci-sion function described in equation 7: w(P) = 0.8,
w(R) = 0.1, w(D) = 0.1. Thus, clients preferably
chose a site with lowest price for computing tasks and do not care much about the reputation and delay in execution.
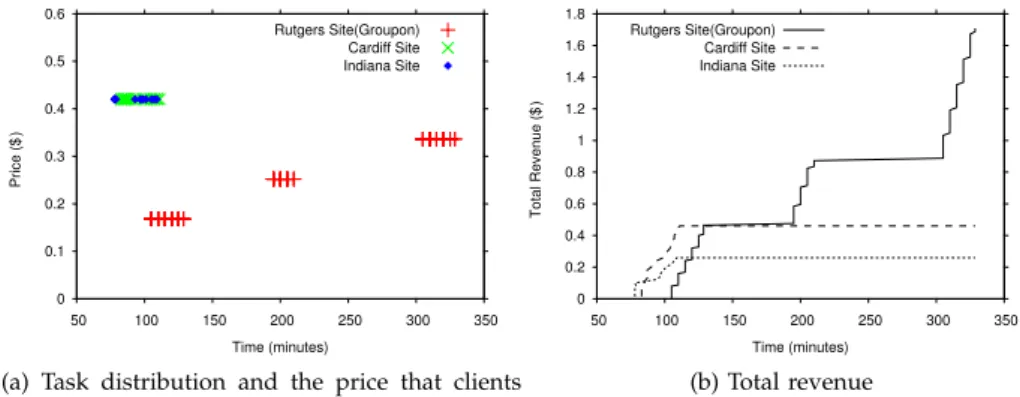
We can observe from the result shown in Table 10 that the groupon site is able to attract enough clients to meet the minimum requirements of the deal. This is also beneficial for clients as they get lower prices as shown in Figure 5a. Although the groupon site had the cheapest prices, we can observe in Figure 5a that some users chose regular sites. The estimated time of completion (ETC) proposed by the groupon site was unacceptable for those clients with a deadline lower than the ETC proposed by the groupon site. Alternatively, all requests generated during deal 2 and 3 are processed by the groupon site. Figure 5b shows how a groupon site could potentially process more client requests and gain more benefit, even when the profit per task is lower than on regular sites. In this case, the revenue of the groupon site largely exceeds the revenue of the other two regular sites.
TABLE 10: Experiment 1 - Client requests processed at each site
Deal ID Groupon site Cardiff Indiana
1 58 24 14
2 34 0 0
3 52 0 0
Experiment 2: Maximize Reputation Influence: We mod-ified the weights of our decision function to w(P) =
0.4, w(R) = 0.5, w(D) = 0.1. In this case, client
considers reputation and price as the most impor-tant. We also modified the minimum buyer number requirement for deal 2 from 30 to 40, which will force the site to cancel the deal. In this way we expect to see how the reputation affects client decisions.
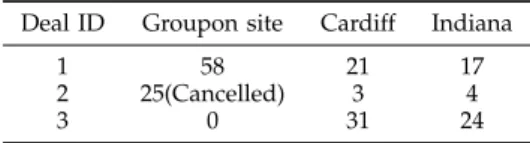
Figure 6 shows that the first deal is completed as in the previous experiment. However, the second deal is cancelled as the groupon site was not able to attract enough clients, see Table 11. This means that all accepted requests are cancelled, the client’s money returned, and the site’s reputation gets signif-icantly affected. As a result, in the third deal clients avoid executing their tasks on the groupon site, see Table 11. All tasks are computed by other normal sites because clients prefer sites with higher reputation. The revenue of these sites also shows the importance of maintaining a good reputation, see Figure 6b. TABLE 11: Experiment 2 - Client requests processed at each site
Deal ID Groupon site Cardiff Indiana
1 58 21 17
2 25(Cancelled) 3 4
3 0 31 24
From these experiments we can see that different winner selection policies used by clients would sig-nificantly affect the task prices they need to pay and the profit of normal and groupon sites. Moreover, a groupon site must carefully design its decision function for determining whether it should fulfill its promise of executing waiting tasks at deal price or not to gain higher profit.
8
D
ISCUSSIONSignificant progress has been made in the field of cloud computing over recent years. Various cloud provisioning models and a variety of different cloud services have been proposed. The providers, many of which are commercial, expose different cloud pack-ages according to varying user requirements. As these providers continue to operate within a cloud market, it is important to consider the types of offerings they have (which can range from a single resource to resource bundles). Although there is a significant range of configuration options available with many cloud providers – the economic models underpinning these offerings are limited. We demonstrate how a cloud provider may adopt different cost models and we propose: (i) a consumption based model and (ii) a group buying (groupon) cost model. Whereas in a consumption based model the users pay only for the number of resources they use (over a particular time frame), ensuring equity between the providers and consumers, in the context of a group buying cost
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
model the focus shifts to clients, who can get signifi-cant discounts by the use of a “deal” mechanism. We also present a cost oriented approach where cloud providers calculate the cost for a consumer based on specific application requirements. We evaluate our federated cloud system by developing relevant use case scenarios which use two real applications: an EnergyPlus-based scenario and an image processing workflow implemented using Octave, both having performance and real time deployment requirements. These scenarios are based on a federation framework that we have deployed between three sites.
Various approaches already exist in the context of cost models for clouds [10], [11], [13], [12], we differentiate from these in two ways: (i) we abstract the type of the cloud infrastructure being considered – our work applies both for private and public clouds, and (ii) we explore different pricing techniques in the context of a real federated cloud deployment. We provide a methodology for developing federated clouds that can be efficiently used for running and deploying real applications. The contribution of this study develops around the notion of cost models and economic mechanisms for cloud environments.
These models and mechanisms are validated in a real infrastructure using CometCloud – a federation framework that facilitates the orchestration of geo-graphically distributed resources and creates a multi-cloud environment where user requests are handled based on a decision function (influenced by resource availability, cost, performance and other user-defined constraints such as access privileges). Hence, our ap-proach can be generalised for other types of appli-cations, or can be adapted for a different federation framework without significant modification.
9
C
ONCLUSIONSIn this paper, we have investigated the problem of a cost based cloud federation by devising a federation framework based on CometCloud. We have shown how our model can be deployed within two applica-tion scenarios such asEnergyPlusused for energy opti-misation andOctaveused for cancer image processing and identified the advantages of an aggregated tuple-space (Comet tuple-space) to allocate resources based on a cost based decision function. In our CometCloud based model users can submit jobs and retrieve results in real time, benefiting from advantages of outsourc-ing tasks.
We have presented the design and implementation of the proposed approach and experimentally eval-uated a number of scenarios for individual clouds and federated clouds. The experimental results have shown a number of benefits that federation provides with regards to task completion and cost optimisation. From our experiments, we can conclude that it is essential to evaluate the trade-off between obtaining a
high quality solution (which may take longer to run on local resources) at a lower cost, vs. outsourcing tasks to a remote site in a cloud federation at a higher cost (but with lower execution time). In the second part of our evaluation we have demonstrated how the groupon cost model can be beneficial for both service providers and users. Our experiments have shown how the reputation of a site and the number of clients (within a group, using the same service) may be critical factors when using this model. Understanding how such a group-based model can be integrated within an application remains the next logical step of this work. Given a budget, an application user may therefore speculate on how many concurrent simula-tions (jobs) to execute to achieve a discount from a cloud provider – which may subsequently influence the scheduling decisions made by a job manager.
Acknowledgements The research presented in this work is sup-ported in part by US National Science Foundation (NSF) via grants numbers OCI 1339036, OCI 1310283, DMS 1228203, IIP 0758566 and by an IBM Faculty Award. This project used resources from FutureGrid supported in part by NSF OCI-0910812.
R
EFERENCES[1] Fumo, N.; Mago, P.; Luck, R. ”Methodology to Estimate Build-ing Energy Consumption UsBuild-ing EnergyPlus Benchmark Mod-els.” Energy and Buildings; (42:12); pp. 2331-2337, 2010. [2] Garg, V.; Chandrasen, K.; Tetali, S.; Mathur, J. ”Energyplus
Sim-ulation Speedup Using Data Parallelization Concept.” ASME Energy Sustainability Conference, New York: American Society of Mechanical Engineers. pp. 1041-1048, 2010.
[3] EnergyPlus, Available at: http://apps1.eere.energy.gov/build-ings/energyplus/
[4] Octave, Available at: http://www.gnu.org/software/octave/ [5] X. Qi, R. H. Gensure, D. J. Foran, and L. Yang. Contentbased
white blood cell retrieval on bright-field pathology images. Proceeding of SPIE Medical Imaging, 2013.
[6] G. Douglas, B. Drawert, C. Krintz and R. Wolski, “Cloud-Tracker: Using Execution Provenance to Optimize the Cost of Cloud Use”, Proc. GECON conference, Sept. 16-18, 2014. Cardiff, UK. Springer.
[7] Kondo, D.; Javadi, B.; Malecot, P.; Cappello, F.; Anderson, D.P., ”Cost-benefit analysis of Cloud Computing versus desktop grids,” IPDPS 2009. IEEE International Symposium on Parallel & Distributed Processing, 2009, pp.1-12, Rome, Italy, 23-29 May 2009
[8] Chaisiri, S.; Bu-Sung Lee; Niyato, D., ”Optimization of Resource Provisioning Cost in Cloud Computing,” Services Computing, IEEE Transactions on , vol.5, no.2, pp.164-177, April-June 2012 [9] Hong Xu; Baochun Li, ”Dynamic Cloud Pricing for Revenue Maximization,” IEEE Transactions on Cloud Computing , vol.1, no.2, pp.158-171, July-December 2013.
[10] Jrn Altmann, Mohammad Mahdi Kashef, Cost model based service placement in federated hybrid clouds, Future Genera-tion Computer Systems, Volume 41, December 2014, Pages 79-90, ISSN 0167-739X.
[11] Van den Bossche, R.; Vanmechelen, K.; Broeckhove, J., ”Cost-Optimal Scheduling in Hybrid IaaS Clouds for Deadline Con-strained Workloads,” Cloud Computing (CLOUD), 2010 IEEE 3rd International Conference on , vol., no., pp.228,235, 5-10 July 2010
[12] Juthasit Rohitratana, Jrn Altmann, Impact of pricing schemes on a market for Software-as-a-Service and perpetual software, Future Generation Computer Systems, Volume 28, Issue 8, October 2012, Pages 1328-1339, ISSN 0167-739X.
[13] Khanh-Toan Tran; Agoulmine, N.; Iraqi, Y., ”Cost-effective complex service mapping in cloud infrastructures,” Network Operations and Management Symposium (NOMS), 2012 IEEE , vol., no., pp.1,8, 16-20 April 2012
2168-7161 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
[14] Xinhui Li; Ying Li; Tiancheng Liu; Jie Qiu; Fengchun Wang, ”The Method and Tool of Cost Analysis for Cloud Computing,” IEEE International Conference on Cloud Computing, 2009. CLOUD ’09, pp.93-100, Miami, Florida, USA, 21-25 Sept. 2009 [15] Liu Hong Wei; Zhu Hui, ”Empirical research on the groupon
technology acceptance mode,”6th International Conference on New Trends in Information Science and Service Science and Data Mining (ISSDM), 2012 , vol., no., pp.356,360, 23-25 Oct. 2012
[16] H. Kim and M. Parashar, “CometCloud: An Autonomic Cloud Engine,” Cloud Computing: Principles and Paradigms, Wiley, 2011, pp 275-297.
[17] I. Goiri, J. Guitart, and J. Torres. Economic model of a cloud provider operating in a federated cloud. Information Systems Frontiers, pp. 1-17, 2011.
[18] Adel Nadjaran Toosi, Rodrigo N. Calheiros, Ruppa K. Thu-lasiram, and Rajkumar Buyya, Resource Provisioning Policies to Increase IaaS Provider’s Profit in a Federated Cloud Environ-ment. In Proceedings of the 2011 IEEE International Conference on High Performance Computing and Communications (HPCC ’11). IEEE Computer Society, Washington, DC, USA, pp. 279-287, 2011.
[19] D. Villegas, N. Bobroff, I. Rodero, J. Delgado, et al., Cloud federation in a layered service model. J. Comput. Syst. Sci., 78(5):1330-1344, 2012.
[20] M. D. de Assuncao, A. di Costanzo, and R. Buyya, Evaluating the cost-benefit of using cloud computing to extend the capacity of clusters, In Proc. 18th ACM Intl. Symp. on High performance distributed computing (HPDC), pp. 141-150, 2009.
[21] S. Ostermann, R. Prodan, and T. Fahringer, Extending grids with cloud resource management for scientific computing, In Proc. 10th IEEE/ACM Intl. Conf. on Grid Computing, pp. 42-49, 2009.
[22] C. Vazquez, E. Huedo, R. Montero, and I. Llorente, Dynamic provision ofcomputing resources from grid infrastructures and cloud providers, In Proc. Workshops at the Grid and Pervasive Computing Conference, pp. 113-120, 2009.
[23] L. F. Bittencourt, C. R. Senna, and E. R. M. Madeira. Enabling execution of service workflows in grid/cloud hybrid systems. In Network Operations and Management Symp. Workshop, pp. 343-349, 2010.
[24] P. Riteau, M. Tsugawa, A. Matsunaga, J. Fortes, and K. Kea-hey. Large-scale cloud computing research: Sky computing on futuregrid and grid, In ERCIM News, 2010.
[25] I. Goiri, J. Guitart, and J. Torres, Characterizing Cloud feder-ation for enhancing providers profit, in Proceedings of the 3rd International Conference on Cloud Computing. Miami: IEEE Computer Society, pp. 123-130, July 2010.
[26] E. Gomes, Q. Vo, and R. Kowalczyk, Pure exchange markets for resource sharing in federated Clouds, Concurrency and Computation: Practice and Experience, vol. 23, 2011.
[27] B. Song, M. M. Hassan, and E.-N. Huh, A novel Cloud market infrastructure for trading service, in Proceedings of the 9th International Conference on Computational Science and Its Applications (ICCSA). Suwon: IEEE Computer Society, pp. 44-50, June 2009.
[28] CometCloud Project. http://www.cometcloud.org/. Last ac-cessed: August 2013.
[29] L. Zhen and M. Parashar,A computational infrastructure for grid-based asynchronous parallel applications, HPDC, pp. 229-230, 2007.
[30] N. Carriero and D. Gelernter, Linda in context, Commun. ACM, vol. 32, no. 4, 1989.
[31] H. Kim, Y. el-Khamra, S. Jha, I. Rodero and M. Parashar, Autonomic Management of Application Workflow on Hybrid Computing Infrastructure, Scientific Programming Journal, Jan. 2011.
[32] Anand, K. S. and R. Aron (2003). Group buying on the web: A comparison of price-discovery mechanisms. Management Science 49, 1546–1562.
[33] IBM Smart Cloud. http://www.ibm.com/cloud-computing/us/en/
Ioan Petriis a Research Associate in School of Computer Science & Informatics at Cardiff University. He holds a PhD in ’Cybernetics and Statistics’ and has worked in industry, as a software developer at Cybercom Plenware. His research interests are cloud comput-ing, peer-to-peer economics and information communication technologies.
Javier Diaz-Montes is currently Assistant Research Professor at Rutgers University and a member of the Rutgers Discovery Informatics Institute (RDI2) and the US National Science Foundation (NSF) Cloud and Autonomic Computing Center. He re-ceived his PhD degree in Computer Sci-ence from the Universidad de Castilla-La Mancha (UCLM), Spain (Doctor Europeus, Feb. 2010). His research interests are in the area of parallel and distributed computing and include autonomic computing, cloud computing, grid computing, virtualization, and scheduling. He is a member of IEEE and ACM.
Mengsong Zouis currently a PhD student in Computer Science at Rutgers University, and a member of the Rutgers Discovery In-formatics Institute (RDI2) and the US Na-tional Science Foundation (NSF) Cloud and Autonomic Computing Center. He received both of his Bachelor and Master degrees in Computer Science from Huazhong Univer-sity of Science and Technology, China. His current research interest lies in parallel and distributed computing, cloud computing and scientific workflow management.
Tom Beach is a lecturer in Construction Informatics. He holds a PhD in Computer Science from Cardiff University. He special-izes in High Performance, Distributed, and Cloud Computing. His recent work focuses on applications in the Architecture Engineer-ing and Construction domain. This work has included the use of cloud computing for the storage, security, management, coordination and processing of building data and the de-velopment of rule checking methodologies to allow this data to be tested against current building regulations and performance requirements.
Omer F. Ranais a Professor of Performance Engineering in School of Computer Science & Informatics at Cardiff University & a mem-ber of Cardiff University’s “Data Innovation Institute”. He holds a Ph.D. in ”Neural Com-puting and Parallel Architectures” from Impe-rial College (University of London). His re-search interests include distributed systems and scalable data analysis.
Manish Parasharis Professor of Computer Science at Rutgers University. He is also the founding Director of the Rutgers Discovery Informatics Institute (RDI2), the NSF Cloud and Autonomic Computing Center (CAC) at Rutgers and the The Applied Software Sys-tems Laboratory (TASSL), and is Associate Director of the Rutgers Center for Informa-tion Assurance (RUCIA). Manish received the IBM Faculty Award in 2008 and 2010, the Tewkesbury Fellowship from University of Melbourne, Australia (2006), and the Enrico Fermi Scholarship, Argonne National Laboratory (1996). He is a Fellow of AAAS, Fellow of IEEE / IEEE Computer Society, and ACM Distinguished Scientist.