International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 9, September 2014)
17
Design and Development of an Efficient Calculation
Framework for Internal
Rate of Return (IRR) of a Fixed Income Portfolio with SIMD
Architecture.
Rao Casturi
Georgia State University
Abstract— IRR is a key indicator for a fixed income security. fixed income security (bond) pays a fixed amount at regular time intervals to the bondholder until the maturity of the security with the original principal. In general an investment portfolio consists of several bonds by the investor. IRR is a measure of the return on the investment and is also frequently used in deciding which investment is a better choice when multiple investment options are available. Using trial and error to calculate IRR of such kind of an investment portfolio in a sequential method can take several hours. The current analysis is performed to speed up the process of computing IRR. During this phase several frameworks were considered. Parallel computations on GPUs is a framework investigated against a regular sequential method and a Database driven framework to see if the proposed architecture can be deployed to calculate IRR more efficiently than the traditional methods.
Keywords—CUDA, Fixed Income, GPU, IRR, SIMD Architecture.
I. INTRODUCTION
Internal Rate of Return (IRR) or Yield [1] is an important measure of a fixed income security. This measure will help in determining what a yield of the security (bond) is or what is the return on the security. When a corporation wants to raise money for their expansion they issue bonds to the public and the public can buy them to support the corporation’s cause. In return the corporation pays a specified interest rate to the bond holder till the maturity of the bond. The payment is called coupon on the bond. These payments are also referred to as cashflow on the bond. If the bondholder holds the bond till maturity, the corporation will pay the initial amount the bond holder paid to buy the bond plus the final coupon payment. There are several variations in the bonds. The discussion or classification of various bonds in a fixed income universe is out of scope of this paper.
The price or Present Value (PV) of a given bond depends on the value of all the cashflows the bond will generate till the final payment.
If we can buy the bond at a lower price, then we will get a higher yield and viceversa. To calculate the PV of a cashflow, we need to find the IRR of the bond. Finding the IRR for a given security involves a trial and error method. This can quickly become computation intensive when there are multiple payment periods.
The IRR is also used in comparing various capital investment projects to come up with a decision on which capital project will make more return on the investment. In general the higher IRR project is better when comparing several capital projects. We can also define the IRR to be the Rate at which the sums of cash flows are zero. Here, the cash flow we spend initially to buy the bond is treated as negative value and the cash flows we receive are treated as positive values. This can easily extended to a portfolio (set of bonds) to find out the overall yield of different portfolios. This helps the financial managers make better investment judgments with their client’s money.
The current paper explores a better calculation framework for the IRR which can be used in several other financial applications like finding the portfolio return, the investment return on a set of portfolios and the Risk Adjusted Return on the investment.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 9, September 2014)
18 The motivation for this paper came from the time constraints we impose on calculating the IRR from a monitoring purpose on a set of bonds held in a portfolio. Portfolio is a set of bonds held as an investment vehicle for a client or for an institution to meet the future financial obligation. There are several other financial applications like Option Pricing [2][5] which uses the GPU calculation to speed up the pricing calculations. As increasing complex financial instruments enter market, pricing them is a constant challenge.[3].
II. BACKGROUND
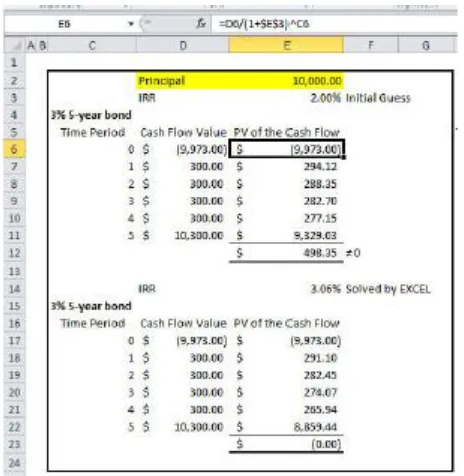
[image:2.612.53.285.304.542.2]Let us use the following example shown in Figure. 1 to understand the actual IRR calculation.
Figure 1. Example for a simple IRR calculation.(10,000) is an EXCEL representation of a negative number or negative cashflow
The IRR precision can be 2 to 3 decimals depending on the need. Assume that a bond buyer pays $9,973 for a 5 year 3 % bond with the principal amount of $10,000 to own and in return the buyer gets 5 yearly coupon payments shown in the column Cash Flow Value from Time Periods (1 to 5). The IRR = 3.06% is the value solved for by Microsoft EXCEL. If that r (rate of return) applied to each cashflow to find the PV and sum of all PVs make NPV = 0 then the EXCEL IRR is the correct IRR for the set of cashflows. This is demonstrated in the column PV of Cash Flow column in the figure [Fig.1].
The initial guess of 2% did not make the NPV to zero. So the 2% can’t be our IRR. Present Value (PV) is calculated by the following formula
In the above formula the r can be calculated by
numerical methods and can also be calculated by trial and error method. To run through a trial and error we notice that the computational complexity and time complexity will increase with the increase in time periods. Usually, the corporate bonds have 10, 15, 20 or 30 year maturity periods with multiple pay periods in a single year. For example the United States Treasury Bonds (US Tsy.) pay semi-annually. That means 2 times a year the coupon is paid. US Tsy bonds can have a 30 year maturity. Sometimes it may take several hundred iterations before we can converge upon the IRR value with a reasonable tolerance closer to zero. Multiple scenario path generation is one of the major areas where high performance computing [4][6] can be useful.
III. PROJECT PROPOSAL
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 9, September 2014)
[image:3.612.335.551.139.440.2]19 As we are aware of the CPU architecture, It may help to go over the GPU architecture as a high level which is a good fit for the SIMD (Single Instruction Multiple Data) architecture. Our current problem of finding the r has multiple data sets but single instruction of divide and power which makes the GPUs a primary device to investigate for a better calculation framework. GPUs are widely used due to their cost effectiveness. The GPUs are built as separate chips or cards which are added to the mother board and can be accessed via the hardware and software programs. The CPU and GPUs can communicate through the data and instruction bus. The following figure Figure 2. shows a high level architecture of the GPUs.
Figure 2. GPU Architecture. SM : Streaming Processors. [7]
The CUDA C, developed by NVIDIA can initiate multi threads on a given device which in this case the GPU unit. The internal architecture of the GPU can be seen as Block and Threads. Each Thread can perform one single instruction on the data sent as vector. The GPUs have their own Global Memory and each thread and block has their local memory as show in the Figure.3 the repeated computations like:
[image:3.612.64.278.298.500.2]can be sent as single row vectors to the GPU and get the results back to the CPU for further processing. In this architecture we call the CPU as the HOST and the GPU as the Device for easy reference.
Figure 3. GPU Architecture with Blocks, Threads, Local and Global Memory [7]
A. Design
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 9, September 2014)
20 We could not use the current program due to the modifications needed in order to work on a test data set are too time consuming and will be out of the scope for this project. The Benchmark program created is based on the following algorithm.
Second Approach: The second approach is done using the SQL Techniques. In this SQL Based Relational Algebra framework we wanted to see if we can use the already optimized SQL algorithms for the aggregation functions. The following code sample is shown to evaluate the IRR calculation on a Microsoft SQL Server.
Third Approach the GPU [8] Framework. In the GPU
framework model, the initial cashflow data and term data are moved to 2 arrays and the result of the fraction which is needed for the PV was implemented at GPU Level. The passing of the arrays to and from the HOST to the Device is coded through the CUDA C language. Sample code is shown below. While the dataset created did not have any scheduling issues [9], it is possible to have issues when the GPU threads do not end at the same time returning results to the Host can be problematic.
B. Hardware and Software requirements
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 9, September 2014)
21 Microsoft Visual Studio 2010 and Visual Studio 2013 with NVIDIA CUDA C framework is installed on the system in order to evaluate the GPU-CUDA framework.
IV. RESULTS
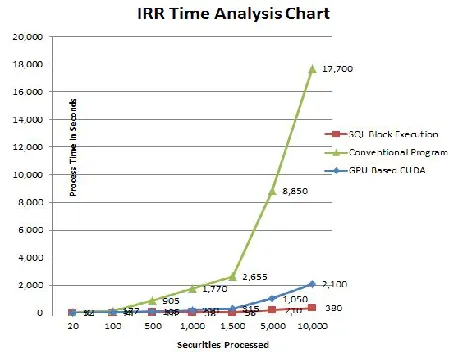
After going through the various framework executions, the time take for each framework was noted. The TABLE I will give us an indication how each framework performed. The first column in the table shows the number of securities the simulation ran. Columns 2,3 and 4 (Program, SQL Method, GPU-CUDA) show the respective time taken (in seconds) to complete the simulation. For example a 1000 security Simulation the on a Program Based framework takes 1,770 seconds whereas on SQL Method it takes 38 seconds and on GPU – CUDA it took 210 seconds.
Table I
Time Analysis Of 3 Different Framework Methods Used For This Paper
No. Securities Benchmark Program
SQL Method
GPU CUDA
20 57 1 1
100 177 4 21
500 905 18 105
1000 1,770 38 210
1500 2,655 58 315
5000 8,850 210 1,050
10000 17,700 380 2,100
[image:5.612.51.277.533.709.2]The timing data is plotted in Figure 4. The graph is given for an easy representation of the experimental output data. The X-Axis shows the number of securities for each scenario and Y-Axis shows the corresponding time taken for each scenario in the IRR calculation framework.
Figure 4. The Time Analysis of Various Solution Frameworks
V. SUMMARY AND CONCLUSION
After going through the results chart Figure 4 and TABLE I we conclude the SQL Framework works best for the given conditions and data sets. The first framework (Benchmark) the implementation of the IRR calculation is done with 2 FOR Loops. The time complexity is dependent on the FOR Loop. That is clearly shown in the time it took to complete each simulation.
For the SQL Method, the SQL Server Aggregation
Operations were optimized already and the data base
tables were indexed appropriately enhancing the
performance for the block operations. The Block SUM in the SQL Aggregation library was able to sum the individual cashflows of an individual security in a very optimal way. The results which are high in performance (less in execution time) on SQL Method was showed this for each simulation. The Block SUM works as a SIMD in a SQL Server Aggregation Function. That is the reason in this project the SQL Framework did better than other 2 frameworks.
The third framework GPU-CUDA did not do well enough to take over the SQL Framework in this project. There are a couple of things which hampered the performance on the GPU based framework. The first
problem is populating the cashflow and the r in the
denominator of the PV equation discussed in the Background section of this paper. The majority of the time took is to populate the 2 arrays which are key inputs to the GPU for the parallel thread processing. Even though the parallel processing in the GPUs took less time, the transfer from HOST to Device is another variable that added to the longer execution of the overall process. The other major issue noticed is the SUM on the PV which currently not implemented on GPU but on the HOST CPU. This being a FOR loop took majority of the time.
With these observations, I conclude that the SQL
Based Framework works better for this data set. This is also cost effective compared to the GPU-CUDA based framework. The existing SQL Servers can be exploited rather than building a new NVIDIA GPU based server to accomplish the IRR calculation. Once the bottlenecks in GPU framework can be addressed in future, the GPU based parallel SIMD can be more effective compared to SQL Based Framework.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 9, September 2014)
22 VI. FUTURE WORK
GPUs can be used in Fixed Income Applications but the data transfer[10] from Host(CPU) to the Device (GPU) can be a bottle neck when data is large. Also there are not very many efficient Summing Algorithms currently on GPUs in order to take advantage of the GPUs computational power. Further research into the GPU architecture to incorporate more local memory for the data store at the thread level will help in making less trips of the tread calculation to go to the GPU Global memory. This can improve the parallel processing.
REFERENCES
[1] Fabozzi, F., Fabozzi, T. The Handbook of Fixed Income Securities Fourth Edition, IRWIN Professional Publishing, 1995.
[2] Solomon, S., Tulasiram, R., and Tulasiram, P. Option Pricing on the GPU, 12th IEEE International Conference High Performance Computing and Communications (HPCC) ,1-3 September 2010 Melbourne, Australia, Page(s) 289-296
[3] Weston, S., Marin, J., Spooner, J., Pell, O., and Mencer O. Accelerating the Computation of Portfolios of Tranched Credit Derivatives, 2010 IEEE Workshop on High Performance Computational Finance, New Orleans, November 14th Pages 1- 8 [4] Spiers, B., and Wallez, D. High-Performance Computing on Wall
Street, IEEE Magazine - Computer, Volume 43, Issue: 12, August 2010, pages 53-59.
[5] Douglas. C., and Lee, H. Basket Option Pricing Using GP-GPU Hardware Acceleration,The 9th International Symposium on Distributed computers and Applications to Business, Engineering and Science, August 1-3 Honkong
[6] Murakowski, D., Brouwer, W., and Natoli , V. CUDA implementation of barrier option valuation with jump-diffusion process and Brownian bridge ,2010 IEEE Workshop on High Performance Computational Finance, New Orleans, November 14th Pages 1-4
[7] NVIDIA Corporation, NVIDIA CUDA C Programming Guide Version 4.2, NVIDIA,
[8] Li, H., and Stout, F. Reconfigurable SIMD Massive parallel computers, IEEE Journal and Magazines, Publication Year :1991 Digital Object Identifier 10.1109/5.92038 page(s) 429-443
[9] Moritsch, H. High Performance Computing in Finance - On the Parallel Implementation of Pricing and Optimization Models. PhD thesis, Institute of Software Technology and Interactive Systems,Vienna University of Technology, May 2006.
[10] Bernemann, A., Schreyer, R., and Spanderen , K. Pricing Structured Equity Products on GPUs,2010 IEEE Workshop on High Performance Computational Finance,
Acknowledgement
First and foremost I wish to thank my Ph.D. advisor,
Professor Rajshekhar Suderraman, acting chair
department of Computer Science, Georgia State University for guiding me in the right direction during this project. I also want to thank my advanced computer architecture
associate professor Michael Weeks for helping me in
![Figure 3. GPU Architecture with Blocks, Threads, Local and Global Memory [7]](https://thumb-us.123doks.com/thumbv2/123dok_us/8708534.881334/3.612.64.278.298.500/figure-gpu-architecture-blocks-threads-local-global-memory.webp)