International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
267
Performance of Prioritized i-SLIP Algorithm with Multiple
Input Queued Switch
S. N. Kore
1, Dr. P. J. Kulkarni
21Associate Professor, Electronics Engineering @ Walchand College of Engineering, Sangli 2Professor, Computer Science Engineering @ Walchand College of Engineering, Sangli
Abstract—Input Queued Switch has throughput limitation of 58%.Hence concept of Virtual Output Queue is evolved. Selection of ‘N’ cells out of N2 is difficult task.
Prof.Nick Mckeown from Stanford University had suggested i-slip algorithm to provide throughput of 100%. Multiple Input Queued Switch is generalized case of Input Queued Switch, where M indicates number of queues/port. When M=N, its VOQ. When M=4, still 90% throughput can be obtained.
Our attempt is to analyze the performance of MIQ with i-slip under Bernoulli’s and on-off type of traffic. Flow control in internet world is popular for output queued switch. We would like to extent flow control towards the input side queue and named as prioritized i-slip algorithm for MIQ. The detail performance of multiple input queued switches is evaluated and presented in this paper. Numbers of queue per port, numbers of iterations in i-slip affect the performance to the greater extent. Priority based i-slip is useful for providing QoS in internet world.
Keywords—input queued switch, VOQ switch, SLIP, i-SLIP, MI-SLIP, Bernoulli arrival, bursty arrival
I. INTRODUCTION
A. Background
In high speed packet switching, efforts are being made to develop compact and low cost switches. There are different architecture are proposed for packet switches namely output queued switch, shared memory switches which outperform in throughput and providing quality of service(QOS). The last two decade has been spent by researcher to develop Output Queued switch with QOS [1].
As the internet spread over in every corner of world and enormous demand of web enabled, the internet services are emerging. Present architecture of output
queued switches are falling short to meet the requirement. Even present technique VLSI does not satisfy the memory bandwidth of these output switches [2].
Input Queued switches requires less memory bandwidth but can only provide 58.6% throughput single Queue at each input port [1],[2],[3]. In last two decade constant effort are made to suggest architecture which provide 100% throughput.
Virtual Output Queue i.e. Queues at input port provides 100% throughput [3]. Complexity arises in packet selection policies and providing guarantee of service (QOS). Moving towards the integrated broadband communication with demanding real time interactive service that too increased number of users is a real challenge in front of researcher. Hence it is current area of research in high speed networking.
Queuing schemes and scheduling algorithms are the two main factors affecting switch scalability. An internet router or packet switches uses cross bar switches to interconnect line cards. A crossbar switch is used because it is simple to implement and is non-blocking; it allows multiple cells to be transferred across the fabric simultaneously. But some of the potential drawbacks of using a crossbar switch are
i. The implementation complexity of an N-port crossbar switch increases with N²,making crossbar impractical for systems with a very large number of ports.
ii. Difficult to provide guaranteed quality of service as the cells arriving to the switch must contend foraccess to the fabric with cells at both the input and the output. Another option to overcome this is “Speedup” in which the core ofthe switch runs faster than the connected lines.
iii. A third drawback of crossbar switches is that usually uses input queues.The input queue switches suffer from inherently lowperformance due to head-of-line (HOL) blocking
B. Virtual Output Queued switch
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:2.595.57.271.111.286.2]268
Fig 1.1: Virtual Output QueueThis scheme is called "Virtual output Queuing"(VOQ) and was first introduce by Tamir et al. HOL blocking is eliminated. When VOQs are used it is possible to increase the throughput of an input queued switch from 58.6% to 100% for both uniform and non-uniform traffic [4],[5].
C. Parameters in scheduling algorithm
High Throughput: An algorithm that keeps the backlog low in the VOQs; ideally, the algorithm will sustain an offered load up to 100% on each input and output.
Starvation Free: The algorithm should not allow a nonempty VOQ to remain unserved indefinitely.
Fast: To achieve the highest bandwidth switch, it is important that the scheduling algorithm does not become the performance bottleneck; the algorithm should therefore find a match as quickly as possible.
Simple to Implement: If the algorithm is to be fast in practice, it must be implemented in special-purpose hardware, preferably within a single chip.
II. THE SLIP ALGORITHM WITH SINGLE AND
MULTIPLEITERATIONS
A. SLIP Algorithm
SLIP is an acronym for “Serial line internet protocol”. The SLIP algorithm uses rotating priority (round−robin) arbitration to scheduleeach active input and output in turn. The main characteristics of slip is its simplicity and easy to implement in hardware.
Performance of basic round robin matching algorithm (RRM) is very poor. In the following section – we have described SLIP algorithmas a variation of RRM. The RRM algorithm, consists of three steps
Step 1: Request: Each input sends a request to every output for which it has aqueued cell.
Step 2: Grant: If an output receives any requests, it chooses the one that appears next in a fixed, roundrobin schedule starting from the highest priority element.The output notifies each input whether or not its request was granted. The pointer to the highest priority element of the round-robin schedule is incremented (modulo N) toone location beyond the granted input.
Step 3: Accept: If an input receives a grant, it accepts the one that appears next in a fixed, round−robin schedule starting from the highest priority element. The pointer to the highest priority element of the round-robin schedule is incremented (modulo N)to one location beyond the accepted output.
Fig. 2.1. VoQ Switch Model
(Above fig. is from Nick Mckeown,"The i-slip Scheduling Algorithm for input-Queued Switches”, IEEEACM trans. Vol7,No.2,April 1999.)
The slip algorithm improves upon RRM by reducing synchronization of output arbiters. Slip algorithm achieves this by not moving the pointer unless grant is accepted in step 3. SLIP is identical to RRM only difference in updating pointer. Here the Grant step is change to:
Step 2: Grant: An output receives any requests, it chooses the one that appear in a fixed round − robin schedule starting from the highest priority element. The output notifies each input whether or not its request was granted.
[image:2.595.324.528.296.478.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
269
B. SLIP algorithm with multiple iterationsHere we also introduce SLIP algorithm with multiple iteration i.e. called as "iterative SLIP (i-SLIP)". When the number of iterationis 'N', then it is known as N-SLIP algorithm. For multiple iterations, performance goes on increasing. Each iteration add the connection not made by earlier one.
Here we describe the i−SLIP algorithm, emphasizing the differences from non−iterative SLIP. We pay careful attention to updating pointer. In section IV,V,VI, we present the simulation result of i−SLIP. The i−SLIP algorithm with 1−SLIP called as SLIP and is stable and also it provide maximal match under uniform Bernoulli i.i.d. As we increase no. of iteration N, the performance goes on improving, the log2(N) iteration are sufficient to
achieve 100% throughput.
Once again, we shall see that de-synchronization of the output arbiters with respect to each other plays an important role in achieving low latency. However, we will also see that the basic i − SLIP algorithm tends to do a worse job of de-synchronizing the arbiters as the number of iteration increase.
The advancement of SLIP algorithm is the iterative SLIP algorithm, but there are number of differences in the behaviour of i − SLIP algorithm specially in updating pointer.All inputs and outputs are initially unmatched and only those inputs and outputs not matched at the end of one iteration are eligible for matching in the next. Connections made in one of the iteration are never removed by a later iteration, even if a larger sized match would result. The three steps in iteration are operated in parallel.
Step 1: Request: Each unmatched input sends a request to every output forwhich it has a queued cell.
Step 2: Grant: If an unmatched output receives any requests, it chooses theone that appears next in a fixed, round-robin schedule starting from the highest priority element. The output notifies each input whether or not its request was granted. The pointer to the highest priority element of the round-robin schedule is incremented (modulo N) to one location beyond the granted input if and only if the grant is accepted in Step 3 of the first iteration.
Step 3: Accept: If an unmatched input receives a grant, it accepts the one that appears next in a fixed, round-robin schedule starting from the highest priority element. The pointer to the highest priorityelement of the round-robin schedule is incremented (modulo N) to one location beyond the accepted output only if this input was matched in the first iteration. Refer Fig 3.
C. How Many iterations
When we implement i−SLIP, the first question arise that how many iterations? How many iteration required to converge i − SLIP algorithm? Answer is, N numbers of iterations are required. But it is not possible to take 'N' iterations within insufficient time, so in practice we need to consider the penaltyof 'i' iterations where i < N. Because de-synchronization of arbiter, i −SLIP usually converge fewer than N iterations. How much iteration should we use? it does not mean always to take N. One possible option is to run the algorithm up to completion but scheduling time varies from cell to cell. It is acceptable in some application but in case of ATM switch, it is desirable to maintain a fixed scheduling time and to try and fit as much iteration as possible. After simulation, we found that log2N iterations are required to
converge i−SLIP for an N × N switch. This is similar to the results obtained for PIM in [3], in which it prove that,
E[I] ≤ N + 4/3 (1)
Where, I is the number of iterations that PIM takes to converge [7],[5],[6].
III. PERFORMANCE EVALUATION OF VOQ WITH SLIP
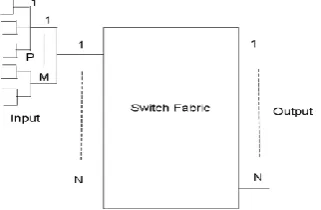
The switch model consists of input queues, arbitration logic and switch fabric.The incoming packets are placed in input queues depends on its destination address. The mainfunction of arbitration logic is the scheduling of packets. There are different algorithms,one of them is slip and i − SLIP. We developed our own simulator.
In our programme, we use different structure for cell and queue. In the cell structure,the parameters used like output port and input port no., its arrival time, priority, weight and cell pointer. In queue structure, the head and tail pointer, queue-length, total delay,total arrivals and loss per queue are included.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:4.595.320.541.104.313.2]270
IV. ON-OFF TRAFFIC ARRIVALFig 4.1: ON-OFF Traffic Model
State Transition Matrix T
P [State is ON] =
P [Sate is OFF] =
P
n = Probability that ON state has length n slot i.e.being ON sate it will remain for another (n-1) times in ON state and then goes to off state.
Geometric Distribution Average
Similarly,
Mean Burst Length=
Offered load = ρ =
V. SIMULATED PERFORMANCE OF I-SLIP
A. Performance with Bernoulli’s arrival for VOQ
Performance with Bernoulli Arrivals
Switch size (N) = 16
No. of queues per port (M) = 16 No. of iteration = 1,2,4
Fig 5.1: Performance of i−SLIP for 16x16 switch with 1,2 and 4 iterations compared with FIFO.
Saturation throughput achieved is 100%.Average delay get reduced as slip increases. It indicate that if offered load is 80%,then average delay is one slot for 4-slip,1.2 slot for 2-slip and for 1-slip it is 15 to 20 slots. It is observed that there is no significant change for delay and throughput performance for slip-2 and 4.It concludes that increasing the number of slips doesn’t improve the performance to larger extent.
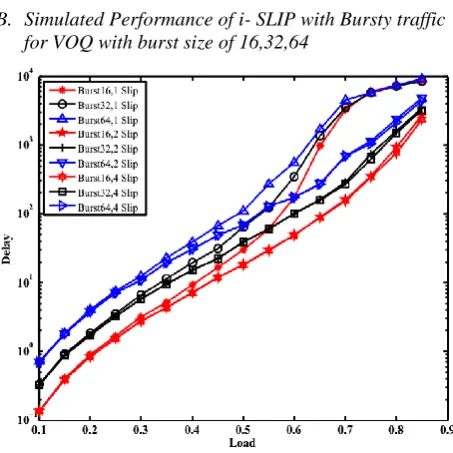
[image:4.595.54.271.126.344.2]B. Simulated Performance of i- SLIP with Bursty traffic for VOQ with burst size of 16,32,64
[image:4.595.318.545.421.648.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
271
Under the bursty traffic with burst size of 16,32 and 64 the performance of VOQ is evaluated. While obtaining the performance slip is varied from 1 to 4.If the burst size is larger than 100% throughput is not achieved. The worst performance is obtained for burst of 64 and 1-slip whereas improved performance for 16 burst size and 4-slip. [image:5.595.321.543.112.320.2]C. Performance of MIQ under i-slip
Fig 5.2: Performance of switch for 16x16 with 2queues and 1,2,4 i−SLIP
Fig5.3:Performance of switch for 16x16 with 4queues and 1,2,4 i – SLIP
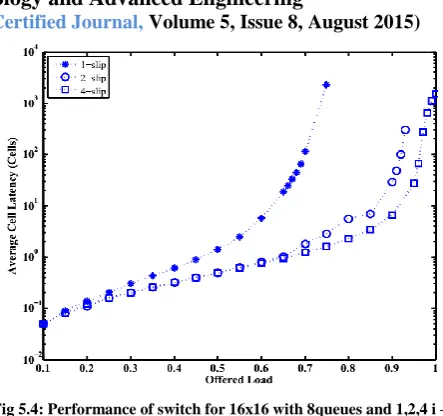
Fig 5.4: Performance of switch for 16x16 with 8queues and 1,2,4 i – SLIP
Performance is obtained with queues per port are 2,4 and 8 with 16x16 switch size .If M is small, then increasing the slip will not affect the performance i.e. slip with 2 and 4 has identical performance as in figure 4.1. As M increases, there is significant change in delay performance for increasing the slip[7],[8].
TABLE 5.1:
PERFORMANCESWITCH SIZE=16 UNDER 1,2,4SLIP
No. of Queues/ port
1-SLIP 2-SLIP 4-SLIP Throughp
ut(%)
delay Throughp ut(%)
delay Through put(%)
delay
2 63 1221 78 718 78 45
4 66 2904 87 1651 91 351
8 71 2329 93 301 96 276
The similar performance is obtained for switch size of 32x32 with queues per port M=4,8,16 the figures 4.4,4.5,4.6 indicates. Table below summarizes the performance of MIQ with different slips
[image:5.595.54.272.239.462.2] [image:5.595.304.559.429.500.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
272
Fig5.6:Performance of switch for 32x32 with 8queues and 1,2,4 i – [image:6.595.336.524.137.332.2]SLIP
Fig 5.7: Performance of switch for 32x32 with 16queues and 1,2,4 i – SLIP
TABLE 5.2:
PERFORMANCE OF SWITCH SIZE=32 UNDER 1,2,4SLIP No. of
Queues/ port
1-SLIP 2-SLIP 4-SLIP
Th (%) D Th (%) D Th (%) D
2 63 4504 85 1666 89 571
4 64 1536 86 369 95 512
8 71 2789 93 1130 98 860
Where Th=throughput,D=delay
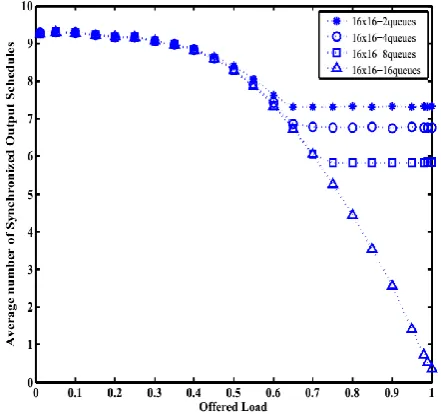
VI. SYNCHRONIZATION OF OUTPUT ARBITOR
Updation of grant pointer at output arbiter affects the performance in throughput and delay. Poor performance of RRM was just because of wrong rules used for updating pointers. This has brought output arbiter in lock-step and only one input is served during the cell time under heavy traffic time load. figure shows the poor performance of RRM where the throughput is limited to 50% only[5].
Fig 6.1: Synchronization Of Output arbiters for RRM and iSLIP for 16x16 switch
In case of i-slip the rule of grant pointer modification such that grant pointer is changed to next highest priority input if and only if grant is accepted by the input arbiter. Under the heavy load the number of synchronized arbiter tend to zero. Under low load, the numbers of output arbiters that clash with other arbiters are more. But as load increases, the clashes of output arbiters decrease.
[image:6.595.321.542.452.659.2] [image:6.595.41.299.520.600.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:7.595.55.275.108.317.2]273
Fig 6.3:Synchronization of output arbiters for 32x32 switch with4,8,16,32 queues per port
The following table indicates number of synchronized output arbiters with limitation of throughput for number of queues per port.
TABLE6.1:
SYNCHRONIZED OUTPUT ARBITERS WITH M
M= No of queues
/ port
Switch size=16x16 Switch size=32x32 No. of
synchronized output arbiters
Th. No. of synchronized
output arbiters
Th.
2 8 60%
4 7 63% 15 60%
8 6 71% 14 63%
16 0 100
%
13 71%
32 0 0 100
%
VII. PRIORITIZED I-SLIP PERFORMANCE
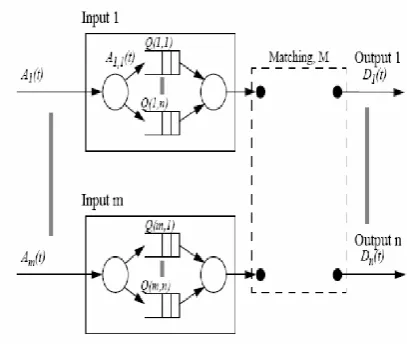
The Internet provides different types of services such as audio, video, FTP, mail, emergency data, etc. The quality of service is very important in present world of internet. The flow control technique used in output queued switch on the similar line the flow control is suggested for VOQ model of switch. The model is as shown in figure
In Prioritized algorithm, each input maintains a separate FIFO for each priority level and for each output i.e. each input maintains PxN FIFO for eac houtput. So in total it requires PxNxN = PN2 FIFO. The prioritized algorithm gives strict priority to the highest priority request in each cell time. This leads starvation for lower priority traffic.
In case of Prioritized algorithm, the same structure of cell and queue as used in i-SLIP algorithms. The same procedure is used to evaluate the performance of Prioritized algorithm. The only difference in this algorithm is that sorting of request, grant and accept are all depends on priority levels. At last, the cell which is having maximum priority is selected depends on round-robin priority wheel.
TABLE7.1:
No. of Iterations
Pri.0 Pri.1 Pri2 Pri3 D Th (%)
1-slip 417 199 157 122 896 99
2-slip 221 168 84 33 596 99
4-slip 61.32 61.51 31 26 180 100
[image:7.595.324.539.458.620.2]The above table shows the performance of virtual output queued switch of 16 x16 size with 4 different priority levels. Priority '0' being lowest priority cell where priority 3 being highest priority cell.
[image:7.595.88.249.643.748.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
[image:8.595.59.273.104.306.2]274
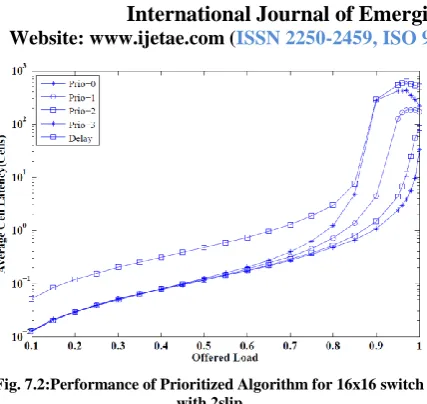
Fig. 7.2:Performance of Prioritized Algorithm for 16x16 switchwith 2slip
If the number of slips are increased then there is no necessity to implement priority.
VIII. CONCLUSION
In virtual output queuing gives 100% throughput with i-slip algorithm in large size of switches of size NxN, handling N2 queues is difficult. The NM (where M<8) queues and i-slip with four iterations are also sufficient to provide almost 100% throughput. The synchronization among the output arbiters in i-slip put the limitation on maximum throughput. The MIQ or virtual output queue doesn’t not provide any quality of service or flow control in internet traffic.
A prioritized MIQ or VOQ with i-slip can provide good quality of service for internet traffic or it can provide prioritization in different types of the flow, prioritization alone increases the complexity in VOQ but combination of i-slip with multiple iteration and priority to limited extend gives the optimal performance.
REFERENCES
[1] Karol M., Hluchyj M., Morgan S., "Input versus Output Queuing on a Space Division Switch", IEEE Transaction on Communications. Vol.35, n.12, Dec.1987, p.1347-1356
[2] M.G.Hluchyj and M.J.Karol,"Queuing in high performance packet switching " IEEE J.Selected Area of Communication, Vol6, pp.1587-1597, December 1988
[3] R.Y.Awdeh, H.Mouftah, "Survey of switch architectures", Elsevier Computer network and ISDN systems, vol.27 , pp.1567-1613, 1995
[4] Nick Mckeown,"The iSLIP Scheduling Algorithm for Input-Queued Switches", Department of Electrical Engineering , Stanford University, Stanford, CA 94305-9030
[5] Nick Mckeown,"The i-slip Scheduling Algorithm for input-Queued Switches”, IEEEACM trans. Vol7,No.2,April 1999. [6] A.H.Darvishan, H.Yeganesh, et.al“ Design and Implementation of
a fast VOQ Scheduler for switch Fabric”,IJCSNS,vol.8,No.9,Sept 2008.
[7] K.F.Chen,Edwin H.M., et al, “ Fast and noniterative scheduling in input- Queued Switches” ,IJCNSS,vol.3,pg no: 169-247,2009.
[8] S.N.Kore,Dr.P.J.Kulkarni,et. Al “A Performance