2018 International Conference on Communication, Network and Artificial Intelligence (CNAI 2018) ISBN: 978-1-60595-065-5
High-dimensional Data Classification Based on Principal Component
Analysis Dimension Reduction and Improved BP Algorithm
Tai-shan YAN, Yi-ting WEN and Wen-bin LI
School of Information Science and Engineering, Hunan Institute of Science and Technology, Yueyang, Hunan, China
Keywords: High-dimensional data classification, Principal component analysis, Neural network, Improved BP algorithm.
Abstract. In order to realize high-dimensional data classification accurately and reduce computation cost and dimension disaster, principal component analysis (PCA) is applied to reduce dimension of high-dimensional data firstly, and then BP neural network is applied to classify. Aiming at the problem of low classification efficiency of traditional BP algorithm, an improved BP algorithm with two times adaptive adjust of training parameters(TA-BP algorithm) is proposed. By two dynamic adjustment of learning parameters, the algorithm has higher learning efficiency. In MATLAB simulation experiment, the improved BP algorithm is applied to classify high-dimensional data after reducing dimension. The experimental results show that the training speed and classification accuracy of high-dimensional data is improved greatly by this method.
Introduction
Classification is one of the important technique in data mining that maps the data items of database to a certain class in giving categories by using a classification function or model. It can be applied to extract models of describing the major data category and predict the future data trend. Today human society has entered the big data era ,in the study of big data, a lot of data , such as: media data, remote sensing data, biomedical data, financial data are high dimensional data, is often processed with the cost of computing cost and dimension disaster[1-3]. However the traditional BP neural network has some disadvantages such as too long training time, local optimum and slow training speed when classifying large-scale high dimensional data[4-6]. Consequently, the principal component analysis (PCA) method is adopted to select some important and big influential data attribute sets from the original training samples in this paper, so as to reduce the high-dimensional data. And then an improved neural network BP algorithm based on secondary adaptive adjustment learning parameters is proposed to classify dimension-reduced data.
PCA Dimension Reduction Method for High Dimensional Data
To classify the high dimensional data directly, the classification results are often poor because the training samples are limited and the data dimension is very high,. According to the characteristics of high dimensional feature space, it is beneficial and necessary to reduce dimension for high dimensional data set.
Principles of PCA
Principal Component Analysis (PCA) is a mathematical method for data dimension reduction[7-9]. The basic idea is to try to recombine a number of original targets that have a certain correlation,
p X X
Let F1 is the principal component indicator formed by the first linear combination of original variables,F1 a11X1a21X2...ap1Xp, according to the mathematical knowledge, the amount of information extracted by each principal component can be measured by its variance. The larger the variance Var(F1)is, the more information theF1contains. It is often expected that the first principal component F1 contains the maximum amount of information, so the F1 should select the maximum linear combinations of variance in all the combinations of X1,X2,...,Xp, thus F1 is called the first principal component. If the first principal component not enough expresses the information of p
indicators, the second principal component indicator F2 is considered. In order to effectively reflect the original information, the existing information of F1 is no longer added to Fi(i1,2,...,m),In other word, F2 is independent and irrelevant to F1 which can be expressed by mathematical language that the covariance Cov(F1,F2)0.That is to say F2 is the largest linear combination of the variance of
p
X X
X1, 2,..., that is not related to F1.Therefore we call F2 the second principal component, In a similar way, the constructed indicators F1,F2,...,Fm are respectively the first, second,…, mth
principal component of original indicators X1,X2,...,Xp. They can be described as follows:
1 11 1 12 2 1
2 21 1 22 2 2
1 1 2 2
... ... ...
... p p
p p
m m m mp p
F a X a X a X
F a X a X a X
F a X a X a X
Calculation Steps of PCA
The specific steps of PCA is described as follows: Step 1: Calculate the covariance matrix
Compute the covariance matrix of the sample data: Σ=(sij)pp, where
1
1
( )( )
1 n
ij ki i kj j
k
s x x x x
n
i
,
j
1
,
2
,...,
p
Step 2: Calculate the eigenvalues iand corresponding Orthogonalized unit eigenvectors aiof Σ.
The first m larger eigenvalues 12...m 0 is the variance of the first m principal components, the unit eigenvector ai of i is the coefficient of the principal component Fi on the
original variable, then the ith principal component Fi is: Fi aiX
The variance (information) contribution rate of principal component is used to reflect the amount of information, i is :
1
/
mi i i
i
Step 3: Select principal component
Finally, select several main components, namely the m in F1,F2,...Fm determined by the accumulated contribution rate G(m) of variance (information):
1 1
( ) /
p m
i k
i k
G m
Step 4: Calculate principal component load
The principal component load can reflect the correlation degree between the main component Fi
and the original Xj.The load lij(i1,2,...,m;j1,2,...,p)of Xj(j1,2,...,p)on all principal component
) ,..., 2 , 1 (i m
Fi :
( ,
i j)
i ij(
1, 2, , ;
1, 2, , )
l Z X
a i
m j
p
Step 5: Calculate the principal component score.Calculate the score of the sample in m principal component:
1 1 2 2
...
i i i pi p
F
a X
a X
a X
i
1
,
2
,...,
m
BP Algorithm with Two Times Adaptive Adjust of Training Parameters(TA-BP Algorithm)
Aiming at BP neural network algorithm’s limitation such as falling into local minimum easily and low convergence speed, an improved BP algorithm with two times adaptive adjust of training parameters(TA-BP algorithm) is proposed. The work step of this improved BP algorithm can be described as follows:
Step1: Initialize the connection weights and thresholds by random numbers between 0 and 1; Step2: Select a training sample randomly for the network;
Step3: Calculate the output of hidden layer units and output layer units; Step4: Calculate output error ( )E t ;
Step5: Calculate the general error of output layer units and hidden layer units;
Step6: Adjust training rate and momentum factor
according to formula (1) and(2) , then adjust connection weights and thresholds.(t 1) ( )t ( ),t
; if ( )E t E t( 1) (1)
(t 1) ( )t ( ),t 0
; else (2)
Step7: Select the next training sample randomly for the network and return to step (3), till m training samples trained over;
Step8: Calculate the maximum errorSEmax( )N of this training course;
Step9: Judge error:
IfSEmax( )N e , training over; else, go to next step;
Step10: Adjust the optimal control value e :
Let SEmax( )N SEmax( )N SEmax(N1)
SEmax(N 1) SEmax(N 1) SEmax(N2) max [ max( ) max( 1)] / 2
SE SE N SE N
If SEmax
, then let eSEmax( ) / 2N ; else let eSEmax( )N . Where,
is the convergenceboundary value determined according to the accuracy requirement. e is the permitted convergence
error. SEmax is the average value of the maximum error in recent two times training.
Step11: Re-select a training sample randomly and return to step (3), tillSEmax( )N e ;
Simulation Experiment Experimental Idea
Two groups of 10 dimension data are generated by normal random number generator in MATLAB. One group is taken as training sample, and the other is taken as test sample. Each group has 600 samples and consists of four normal distributions. Firstly, principal component analysis (PCA) method is used to reduce dimension. Through principal component analysis, the total variance contribution rate of the first principal component, the second and the third principal component reached 92.3%. They can reflect the characteristics of the original data. So, the first three principal components are selected as the dimension reduction result. Then, the data before and after dimension reduction are input into traditional BP neural network and the improved BP neural network with two times adaptive adjust of training parameters(TA-BP algorithm)respectively. They can be trained and classify, and their training time, training error and classification accuracy are compared.
Experimental Result
[image:4.612.114.494.465.624.2]Training Time. Let traditional BP algorithm and TA-BP algorithm runs 10000 times with the same samples respectively. The time required is shown in Table 1.
Table 1. Training time of 10000 times(s). algorithm 10 dimension 3 dimension Traditional BP
TA-BP 26.27 22.12 19.39 16.55
From table 1, we know that the dimension reduction time of two algorithms have all fallen after dimension reduction. And under the same dimension, TA-BP algorithm needs less time than traditional BP algorithm.
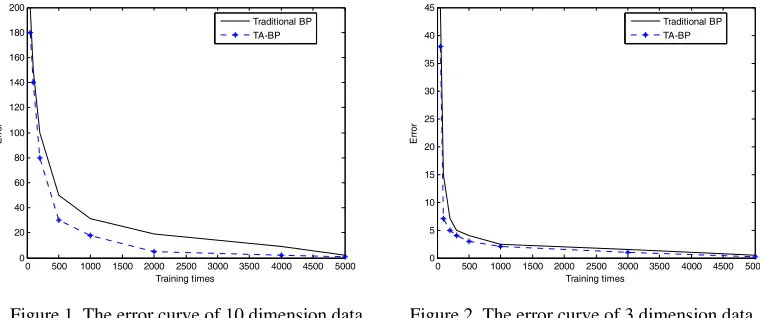
Error Curve. The error curves of 10 dimension data and 3 dimension data under two BP algorithms are shown in Figure 1 and Figure 2.
It can be seen from the error curves of 10 dimensional data and 3 dimensional data, TA-BP algorithm has faster convergence speed than traditional BP algorithm. It indicates that the improved BP algorithm has better performance.
Figure 1. The error curve of 10 dimension data. Figure 2. The error curve of 3 dimension data.
Classification Accuracy. Table 2 lists the classification accuracy of two algorithms applied in the 10 dimension and 3 dimension data training sets. As shown in Table 2, the results of two algorithms are all good, which indicates that the neural network is well trained. After dimension reduction, the classification accuracy of two algorithms is more high. Moreover, under the same dimension condition, the classification accuracy of improved BP algorithm is higher than that of traditional BP algorithm.
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 0
20 40 60 80 100 120 140 160 180 200
Training times
E
rro
r
Traditional BP TA-BP
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 0
5 10 15 20 25 30 35 40 45
Training times
E
rro
r
Table 2. Classification accuracy.
algorithm 10 dimension 3 dimension Traditional BP
TA-BP 91.36% 92.24% 94.25% 97.26%
Conclusion
In order to classify the high dimensional data, the classification method after dimension reduction is proposed. The first three principal components are extracted from high dimensional data by principal component analysis. They are input traditional BP neural network and TA-BP neural network in order to test the classification effect. The experimental results show that the training speed of neural network is faster and the classification accuracy is higher after PCA dimension reduction. Moreover, TA-BP algorithm has better recognition ability and classification accuracy than traditional BP algorithm, and the robustness of neural network is enhanced.
Acknowledgements
Support from the Natural Science Foundation of Hunan Province under Grant No.2017JJ2107, the Science and Technology Program of Hunan Province under Grant No. 2016TP1021 is gratefully acknowledged.
References
[1] Domingos P. A few useful things to know about machine learning. Communications of the Acm, 2012, 55(10): 78-87.
[2] Zhang Daoqiang, Chen Songchan. The method of dimension reduction for high dimensional data. Communication of Chinese Computer Society, 2009, 5(8): 15-22.
[3] Donoho D.L. High dimensional data analysis: the curses and blessings of dimensionality. American Mathematics Society Conference: Math Challenges of the 21st Century, Los Angeles, USA, 2000.
[4] Zhang Yue- qin, Liu Xiang, Sun Xian-yang. An Improved Algorithm of BP Neural Network and Its Application. Computer Technology and Development, 2012, 22(8): 163-166.
[5] Li Ming, Yi Shen-min, Yang Shu-zi. Research on Neural Network’s Adaptive Training.Systems Engineering and Electronics, 2007, 5(3): 29-36.
[6] Liu Haoran, Zhao Cuixiang. Research on a improved neural network algorithm optimized by genetic algorithm. Journal of Instruments and Instruments, 2016, 37(07): 1573-1580.
[7] Ruan Yue, Chen Hanwu, Liu Zhihao. Quantum principal component analysis algorithm. Chinese Journal of Computer, 2014, 37(3): 666-676.
[8] Shi Jiarong, Zhou Shuisheng, Zheng Xiuyun. Multilinear robust principal component analysis. Electronic Journal, 2014, 42(8): 666-676.