IJEDRCP1501045
International Journal of Engineering Development and Research (www.ijedr.org)202
Relevant Web Document Retrieval and
Summarization
1
P.Selvapriyavadhana,
2Dr.PSK. Patra,
3W. Mercy
1
Student, 2 Professor, 3Assistant Professor
Department of Computer Science and Engineering, Agni College of Technology, Chennai, Tamilnadu, India
________________________________________________________________________________________________________
Abstract - Consumer reviews for the product is submitted in the web. Since the reviews are disorganized it is difficult to accumulate the knowledge. This paper proposes document retrieval and summarization ranking algorithm to understand the important aspects by considering aspect frequency .In this paper, based on the inspection that consumer convey review openly in free text feedback comments. The overall reviews are pre-processed and the opinion words are differentiated as dependent and independent words. The classification is done and ranking is done by aspect ranking algorithm. The overall reviews are summarizes by K-means clustering algorithm. This will achieve the significant performance enhancement about the products.
Index Terms - Stopword, Stemming, POS, Unigram, Bigram, Polarity.
________________________________________________________________________________________________________
1.INTRODUCTION
The task of producing summary from many documents is called multi-document summarization. To develop a probabilistic aspect ranking algorithm to infer the importance of aspects by considering aspect frequency and the ranking of consumer review given to each product and their overall feedback. The important product reviews are identified based on two observations: 1) The important aspects are usually commented on by a large number of consumers.
2) Consumer opinions on the important aspects greatly influence their overall opinion on the product.
In particular, given the consumer reviews of a product, it first identifies product feedback by dependency and determines consumer feedback via a sentiment classifier. Moreover, I apply product based document retrieval and summarization ranking to two real-world applications, i.e., document-level sentiment classification and extractive review summarization, and achieve significant performance improvements, which demonstrate the capacity of product based document retrieval and summarization ranking in facilitating real-world applications.
2. EXISTING SYSTEM
The existing system is to regard the aspects that are often commented in consumer reviews as important. Though consumers’ feedback on the aspects may not influence their overall opinions on the product, and their purchasing decisions. A basic method to use the influence of consumers’ opinions on specific aspects over their overall ratings on the product is to count the cases where their opinions on specific aspects and their overall ratings are constant, and then ranks the feedback according to the number of the consistent cases. This method simply assumes that an overall rating was derived from the specific opinions on different aspects individually, and cannot precisely characterize the correlation between the specific opinions and the overall rating. Two methods were used in this existing system. They are Boolean weighting and term frequency (TF) weighting. Boolean weighting represents each review into a feature vector of Boolean values, each of which indicates the presence or absence of the corresponding feature in the review. Term frequency (TF) weighting weights the Boolean feature by the frequency of each feature on the corpus.
Drawbacks in the existing system are:
Training of the labeled data from source domain and target domain and applying it in some other domain will result in inaccuracy.
Supervised learning algorithm is expensive to annotate data for each new domain.
Cross domain sentiment classification system must id entify which source domain features are related to target domain features. Domain dependent word will not be correctly justified.
3. PROPOSED SYSTEM DESIGN
Relevant web document retrieval and summarization is beneficial to many of the real-world applications. In this paper, i examine its usefulness in two levels; one is document-level sentiment classification and extractive review summarization. The former one aims to determine a review document as a positive or negative opinion, and the later one aims to summarize consumer reviews. I perform wide experiments to evaluate the efficiency of aspect ranking in these two applications and achieve significant performance improvements. Relevant web document retrieval and summarization the following improvements:
It elaborates more discussions and analysis on web document retrieval and summarization ranking problem. It performs extensive evaluations on more products in more diverse domains.
IJEDRCP1501045
International Journal of Engineering Development and Research (www.ijedr.org)203
The proposed work automatically identifies the important aspects of products from numerous consumer reviews. Significant performance improvements are obtained on the applications of document-level sentiment classification and extractive review summarization by making use of aspect ranking. The aspects are ranked according to their importance scores.4. STEPS INVOLVED IN THE PROPOSED APPROACH
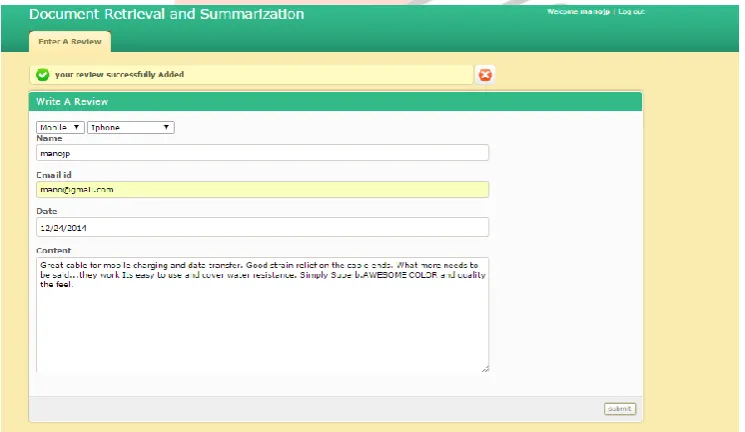
Step 1: User reviews are given through individual login. Step 2: User feedbacks are accumulated in the database. Step 3: Overall review is viewed through admin login.
Step 3.1: The reviews are pre-processed. Step3.1.1: Stop words are removed.
Step3.1.2: Stemming is done from the stop word removed dataset. Step3.1.3: Part-Of-Speech tagging is done for the stemmed words. Step 3.2: Opinion Word Feature Mining is done through two steps.
Step3.2.1: Dependent words are classified through wordnet. Step3.2.2: Independent words are classified through wordnet.
Step 3.3: Opinion Word Polarity Classification is done through SVM – Support Vector Machine. Step 3.4: Clustering of Polarity in Opinion Word by clustering positive and negative Polarity. Step 4: The summarized review about the products are given as a result.
5. PROPOSED METHODOLOGY
Design is multi-step process that focuses on data structure software architecture, procedural details, (algorithms etc.) and interface between modules. The design process also translates the requirements into the presentation of software that can be accessed for quality before coding begins
Figure 5.1. Document Retrieval and Summarization
5.1. PREPROCESSING OF REVIEW
The user reviews crawled from social media is already stored in the database. The reviews are stored as text file. From the database reviews is given as input in stop word removal for removing the stop word from the review.
In the stop word removal it will perform the following .The words like “this, that, is, a, it, is” are the stop words that should be removed from the review for easy analyses of reviews and meaningless words are removed. The list of stop word ordered based on alphabetical order and it is considered it as single array for quick accessing. So the given review will be searched for the stop words and it is removed. After removing the stop word stemming is done.
IJEDRCP1501045
International Journal of Engineering Development and Research (www.ijedr.org)204
the given product. A part of speech tagger is a software that reads text in some language and assign part of speech to each word such as noun, verb, adjective etc.., it use more fine-grained POS tags like “noun-phrase”.5.2. OPINION WORD FEATURE MINING
Opinion word feature mining will classify the word as dependent and independent. Using the opinion word that is tagged first will form unigram and bigram. Unigram is a single word and bigram is a combination of unigram. In this only the adjectives is considered since adjective only will express the attitude and feeling of the opinion holder.
In the Formation of unigram it will consider each word as a unigram and in bigram two words are combined to form a bigram. The formation of bigram is used to classify the polarity of word correctly. For example, “good” will give a positive polarity but when it is combined with some other word like not for example “not good” will give a negative polarity so it is necessary to form the unigram and bigram.
5.3. OPINION WORD POLARITY CLASSIFICATION
Opinion word polarity classification will classify the polarity of each opinion word. The word that is classified as dependent and independent will be checked for its polarity using a supervised learning method. Each word will be classified as positive and negative based on the meaning stored in dataset.
In this the dependent and independent word that is classified will be given as input and it will find the polarity of the given opinion word. The word that is classified will be having meaning stored in the dataset. Based on the dataset it classifies the meaning of the word. Support Vector Machine are supervised learning models with associated learning algorithms that analyze data and recognize patterns, used for classification and regression analysis.
5.4. CLUSTERING OF POLARITY IN OPINION WORD
For accurate classification of polarity it uses SVM classifier with a training set. It is a processing of grouping the data or words belonging to a same polarity. It clusters the positive and negative polarity separately. It will group the data based on the k-nearest neighbors. In this it insert edges between a node and its k-nearest neighbors. Each node will be connected to k nodes. After clustering it generate a feature based summary and graph for representing it. Summary is an easy and understandable representation of the reviews. Graphically the summarization is represented with number of positive words, negative words, nouns, adjectives, verbs that is easy for understanding about the review summarization.
6. IMPLEMENTATION
The web document Retrieval and summarization is done by retrieving reviews about the products as xml files from the web.
IJEDRCP1501045
International Journal of Engineering Development and Research (www.ijedr.org)205
Figure 6.2. Pre-processed Dataset.
Figure 6.3. Summarized review result.
IJEDRCP1501045
International Journal of Engineering Development and Research (www.ijedr.org)206
7. CONCLUSION AND FUTURE ENHANCEMENTI have proposed a product based document retrieval and summarization ranking framework to identify the important feedback of products from various consumer reviews. The framework contains four components, i.e., Preprocessing of reviews, Opinion word extraction, Polarity classification, and Clustering of opinion word. First, I evaluated the Positive and negative reviews to improve aspect identification and Polarity classification on free-text reviews. I then developed a probabilistic ranking algorithm to infer the importance of various aspects of a product from numerous reviews. The product aspects are finally ranked according to their importance weights. The classified word will be given in support vector machine will classify the polarity of the word as positive and negative. The opinion word that is classified based on their polarity will be clustered using K-Means clustering and finally it generate the summary using the cluster of opinion words and a graphical representation of the report for quick understanding of user.
In future research we are create the authentication and Authorization of users as well as the customers as well as the reviewers. I can create new securities for securing data such as IP verification, and Session conformation. Sentiment classifier is used to classify the sentiment of the opinion word that is extracted from review as positive and negative. It is a processing of grouping the data or words belonging to a same polarity.
8. REFERENCES
[1] A. Y. Ng, M. I. Jordan, and Y. Weiss “spectral clustering: Analysis and an algorithm”in university of Hebrew, 2001. [2] Bing Liu and Minqing Hu “Mining and Summarizing Customer Reviews”, 2004
[3] Bo Pang and Lillian Lee “A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts”Department of Computer Science,Cornell University,2004.
[4] Danushka Bollegala “Cross-Domain Sentiment Classification using a Sentiment Sensitive Thesaurus” Member, IEEE, David Weir and John Carroll, 2011.
[5] Gang Li and Fei Liu “A Clustering-based Approach on Sentiment Analysis” Department of Computer Science and Computer Engineering La Trobe University, 2010.
[6] John Blitzer, Ryan McDonald and Fernando Pereira “Domain Adaptation with Structural Correspondence Learning” Department of Computer and Information Science, University of Pennsylvania, 2005.
[7] Shivakumar Vaithyanathan,Bo Pang and Lillian Lee “Thumbs up? Sentiment Classification using Machine Learning Techniques” IBM Almaden Research Center, 2004.
[8] Sinno Jialin Pan, Xiaochuan Ni, Jian-Tao Sun, Qiang Yang and Zheng Chen “Cross-Domain Sentiment Classification via Spectral Feature Alignment” Department of Computer Science and Engineering Hong Kong University of Science and Technology, Hong Kong, 2010.
[9] Thorsten Joachims “Text categorization with support vector machines: Learning with many relevant features” university of Dormant, 2005.
[10] Zheng-jun zha, jianxing yu, jinhui tang,Meng Wang, and tat-seng chua,” Product aspect ranking and Its applications”,IEEE transactions on knowledge and data engineering, vol. 26, no. 5, may 2014