Sharif University of Technology
Scientia IranicaTransactions A: Civil Engineering www.scientiairanica.com
Improved support vector machine regression in
multi-step-ahead prediction for rock displacement
surrounding a tunnel
B. Yao
a;, J. Yao
b, M. Zhang
aand L. Yu
ca. School of Automotive Engineering, Dalian University of Technology, Dalian, 116024, P.R. China. b. School of Civil Engineering, Beijing Jiaotong University, Beijing, 100044, P.R. China.
c. Yanching Institute of Technology, Beijing, 065201, P.R. China.
Received 6 July 2013; received in revised form 6 September 2013; accepted 26 November 2013
KEYWORDS Multi-step-ahead prediction; Tunnel;
Surrounding rock displacement; SVM;
Forgetting factor.
Abstract.A dependable long-term prediction of rock displacement surrounding a tunnel is an eective way to predict rock displacement values in the future. A multi-step-ahead prediction model, which is based on a Support Vector Machine (SVM), is proposed for predicting rock displacement surrounding a tunnel. To improve the performance of SVM, parameter identication is used for SVM. In addition, to treat the time-varying features of rock displacement surrounding a tunnel, a forgetting factor is introduced to adjust the weights between new and old data. Finally, data from the Chijiangchong tunnel are selected to examine the performance of the prediction model. Comparative results presented between SVMFF (SVM with a forgetting factor) and an Articial Neural Network with a Forgetting Factor (ANNFF) show that SVMFF is generally better than ANNFF. This indicates that a forgetting factor can eectively improve the performance of SVM, especially for time-varying problems.
c
2014 Sharif University of Technology. All rights reserved.
1. Introduction 1.1. Background
Rock deformation surrounding a tunnel and tunnel lin-ing cracks may lead to instability of the tunnel. When analyzing the stability of the surrounding rock mass of a tunnel, deformation is often used as the security index to denote the stability of the surrounding rock mass of the tunnel. The rate of deformation around the tunnel depends on geological and geotechnical conditions, and many techniques have been presented to estimate the conditions of the tunnel during tunnel construction. The need for statistical process control is important for quality assurance [1]. An ecient way is
*. Corresponding author.
E-mail addresses: [email protected] and [email protected] (B. Yao)
to use displacement statistics and analyses of the rock surrounding the tunnel to estimate the future displace-ment of the surrounding rock. However, the conditions of a tunnel during construction are varied, which will have an eect on the displacement of the tunnel. If the future displacement values of the surrounding rock of the tunnel could be predicted for reference, it could help to quantitatively evaluate the stability of the surrounding rock mass. Moreover, project managers could identify tunnel conditions and eectively operate their construction facilities. Furthermore, when the weak rock layer begins to become unstable and these failures could be acquired in advance, some correspond-ing measures could be taken to avoid these dangers.
Thus, displacement of tunnel surroundings is a common way to reect the condition of the tunnel, and nding an eective method to predict the displacement of the surrounding rock of the tunnel is important
underground construction, with increased costs and delays. Some literature about the displacement predic-tion of the surrounding rock of a tunnel can be found in Li et al. [2] and Sellner [3].
1.2. Literature review
From the standpoint of engineering applications, it is necessary to learn the values to be predicted many time-steps into the future. During the past few decades, a great deal of research has been devoted to multi-step-ahead (MS) techniques to deal with these problems [4-6]. In this study, the MS technique is also used to predict the displacement of surrounding tunnel rock for planning and management activities during tunnel construction. However, ground condi-tions change greatly during tunnel construction, which makes it more dicult to predict the displacement of rock surrounding tunnels accurately. The Support Vec-tor Machine (SVM) is a relatively new kind of learning machine which has been applied successfully to some time series forecasting problems [7-11]. The numerical results indicate that SVM shows much resistance to the overtting problem and can provide a high gener-alization performance. These successful applications suggest that SVM is an acceptable tool to provide accurate displacement prediction of rock surrounded tunnels. Unlike the empirical risk minimization prin-ciple implemented in most traditional ANN models, SVM implements the structural risk minimization prin-ciple. The most important feature in the structural risk minimization principle is minimizing an upper bound to the generalization error instead of minimizing the training error. The parameter, C, can be adjusted to control the tradeo between errors of training data and margin maximization. For an SVM, the value of " in the "-insensitive loss function aects the complexity and the generalization capability of SVM. Fixing the parameter, ", can be useful for specifying the desired accuracy of the approximation in advance. Another parameter, , is the range at which the generalization performance is stable. Considering the parameters will greatly aect the performance of SVM, and some literature has attempted to determine the proper pa-rameter values for these problems. Hou and Li [12] proposed an evolution strategy with covariance matrix adaptation to determine the parameters in SVM. Hsu et al. [13] introduced a grid-search to determine the adaptive values for the parameters in SVM. Lin et al. [14] presented SVM for hydrological prediction, and a Shued Complex Evolution Algorithm (SCE-UA) was used to identify appropriate parameters in SVM. Lorena and Carvalho [15] optimized the parameter
1.3. Contributions
The purpose of this paper is to build on the pre-diction model by Yao et al. [16], and extend it to predict rock displacement surrounding a tunnel, which is related to long-term prediction. Thus, the con-tributions of this paper are to apply a multi-step-ahead prediction for rock displacement surrounding a tunnel based on SVM, which has been successfully applied in the literature [16-17]. Then, we use a forgetting factor to improve the prediction accuracy of SVM. In addition, to examine the performance of this algorithm, a comparison between SVMFF (SVM with a Forgetting Factor) and an Articial Neural Network with a Forgetting Factor (ANNFF) is used in this study.
This paper is organized as follows. In Section 2, we describe the MS prediction problem of rock dis-placement surrounding a tunnel, the SVM model for MS prediction, parameter identication for SVM and a brief introduction to SVM with a forgetting factor. In Section 3, some computational results are discussed and, lastly, the conclusions are provided in Section 4.
2. SVMFF for predicting rock displacement surrounding a tunnel
2.1. Formwork of the prediction
The properties of the prediction of rock displacement surrounding a tunnel with MS techniques not only depend on the observation values but also on the pre-vious prediction. Thus, the recursive relation between inputs and outputs in MS prediction can be expressed using general nonlinear input-output models, as the following:
8 > > > < > > > :
^xt+p= F (xt+p m; :::; xt; ^xt+1; :::; ^xt+p 2; ^xt+p 1)
p < m
^xt+p= F (^xt+p m; :::; ^xt+p 2; ^xt+p 1) p m
(1)
where p is the number of steps ahead of the p-step-ahead prediction model, F(.) (the horizon of MS prediction); m is dened as the number of inputs; ^xt+p, which has a \hat", represents an estimate of
the output at time-step t + p; and xt+p m, without a
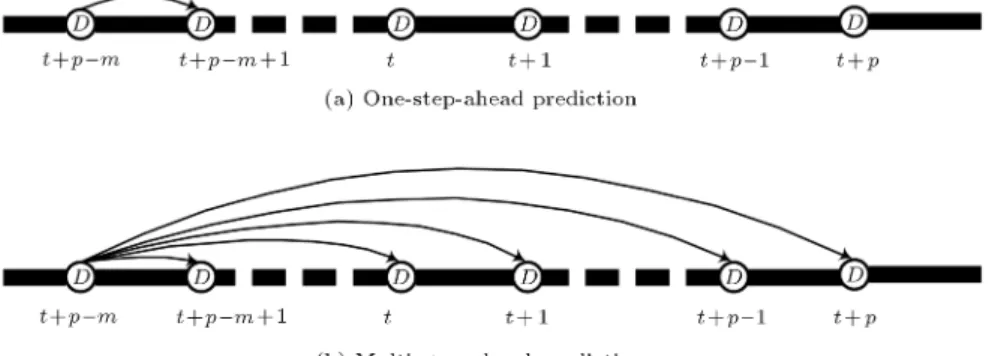
\hat", represents an observation. Obviously, if p < m, the model input consists of observation and prediction values, and if p m, it consists of all prediction values. Referring to multi-step prediction [18-19], the one-step prediction and multi-step prediction for tunnel surrounding prediction can be described in Figure 1.
Figure 1. Processes of one-step ahead prediction and multi-step ahead prediction for tunnel surrounding prediction.
2.2. SVM for regression
SVM is a machine learning method proposed by Vap-nik [20,21]. Given a set of data points, fxk; ykg,
k = 1; 2; :::; s, xk 2 Rm, yk 2 Rn, k is the number
of training samples. SVM estimates the function by the following function:
f(x) =< w; x > +b; w; x 2 Rm; b 2 Rn; (2)
here, < w; x > is the feature of the inputs. The coecients, w and b, are estimated by the regularized risk functional.
To get the estimation of w and b, Eq. (2) can be transformed to a primal objective function:
Min J =12kwk2+ C
s
X
i=1
( i + i);
s.t. 8 > < > :
yi < w; xi> b " + i
< w; xi> +b yi " + i
i; i 0
(3)
where C is a regularization constant to determine the trade-o between training error and generalization performance; " is a tube to dene the range of the observation and prediction values. Both C and " are user-determined parameters. Two positive slack variables, , , are used to cope with infeasible
constraints of the optimization problem. The formula is an optimization problem and its minimum can be evaluated by Lagrange multipliers, i and i, in most
cases:
Max J = 12 Xs
i;j=1
(
i i)(j j) < xi; xj >
+
s
X
i=1
i(yi ") s
X
i=1
i(yi+ ");
s.t. 8 > < > :
Ps
i=1i=
Ps
i=1i
0 i C
0 i C
(4)
Let w =
s
X
i=1
(i i)xi: (5)
Thus; f(x) =
s
X
i=1
(i i) < xi; xj> +b: (6)
By introducing kernel function, K(xi; xj), Eq. (4) can
be rewritten as follows: f(x) =Xs
i=1
(i i)K(xi; xj) + b; (7)
where K(xi; xj) is the kernel function which is proven
to simplify the use of mapping. The value of K(xi; xj)
is equal to the inner product of two vectors, xi and
xj in the feature space '(xi) and '(xj), that is
K(xi; xj) = '(xi):'(xj). By the use of kernels,
all necessary computations can be performed directly in the input space, without having to compute the map, '(x). More details on SVM can be seen in [7,20].
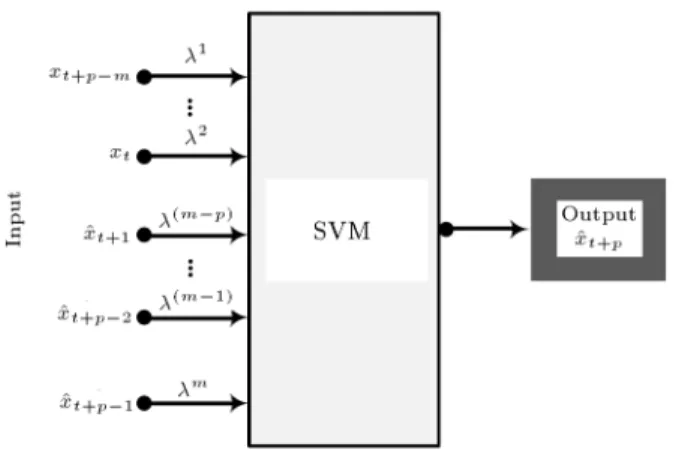
2.3. Application of SVMFF to prediction of rock displacement surrounding a tunnel Due to the rate of rock mass deformation varying with geological and geotechnical conditions, it is dicult to predict the displacement of rock surrounding a tunnel. The MS technique based on SVM is adopted to predict the future displacements with m observation data. In other words, the m + 1 value will be predicted based on the m observation data. The predicted output will be an input to the following predictions. Thus, future values will be recursively predicted in the same way. A formal denition of MS based on SVM can be summarized as follows:
1. A one-step-ahead predictor based on SVM is per-formed to provide a prediction output.
2. Future values can be predicted based on the re-cursive principles of p-step-ahead prediction by embedding a one-step-ahead estimator based on SVM.
Figure 2. Structure of SVMFF model.
displacement surrounding a tunnel will be changed as time goes on. However, a standard SVM does not consider the time-varying features of the data, since it refers to the data of memory (window) with the same weights. A forgetting factor, i(0 < i 1; 1
i m), is applied to put exponentially less emphasis on past data. In this study, i is used to reect the
weights between new and old data, that is, the weight of former displacements (e.g. m; m 1; :::). When = 1, the SVM with the forgetting factor is the same as the SVM without the forgetting factor. When = 0, only the former rock displacement surrounding the tunnel is used to predict current displacement. Other former displacements have no inuence on the current displacement. Thus, the structure of SVMFF is illustrated in Figure 2.
3. Case study
The Chijiangchong tunnel of the Wuhan-Guangzhou railway, which is a high-speed rail line between Wuhan city and Guangzhou city in China, is chosen as the study site. The length of the tunnel is about 385 m and its location is from DK1659+720 to DK1660+105 of the Wuhan-Guangzhou railway. Three sections of the tunnel were selected to acquire the data on the rock displacement surrounding the tunnel. In general, the measurement frequency should be once per day at the beginning of the experiment and the frequency may be once every other day later [22]. This is because the deformation rate at the beginning of the experiments is obviously more than that later. Thus, in this paper, the measurement frequency is once every day in the rst thirteen days, and then, once every other day after the thirteenth day. The experiment continues until the rock displacement surrounding the tunnel is almost stable. Here, we take the dierence between two consecutive measurements, < 0:1 mm, as the termination condition. Thus, we acquired three sets of data; each set with thirty-two samples from the experiment, from September 8 to October 28, 2007.
Table 2. The parameters in SCE-UA.
m p q
20 4 11 1 21
3.1. Result comparison with grid-searchnSCE-UAnGA for parameter identication The parameter selection is important for the perfor-mance of the algorithm. In this section, the objective is to identify good parameters (C; "; ) in order to predict the unknown data accurately. Referring to previous literature on parameter selection for SVM, some methods, like grid search [13], SCE-UA [14] and genetic algorithm [15], were used to optimize the values of the parameters for SVM.
The Genetic Algorithm (GA) is inspired by evo-lutionary biology, like inheritance, selection, crossover, and mutation. A tness function is used as a measure for determining the relative superiority of one solution compared to a second solution. Then, GA attempts to retain relatively good genetic information from generation to generation.
The SCE-UA algorithm attempts to look for the optimum solution by combining the strengths of the simplex procedure, deterministic and probabilistic ap-proaches, competitive evolution and complex shuing. Thus, these three methods are also analyzed for parameter optimization for our problem, respectively. The parameters of GA and SCE-UA can be seen in Tables 1 and 2. To test the performance of the three methods, it is necessary to divide all the data into dierent sets. Here, the data are divided into three sets: training samples, testing samples and inspection samples. In this study, the data from the rst section and the third section are used for training and testing, and the data from the second section are used for inspection. To reduce the search space, according to previous literature [13], the constraints of the three pa-rameters are suggested as C 2 [2 5; 25], " 2 [2 13; 2 1]
and 2 [0; 2]. Then, to examine the prediction errors, an objective function should be considered:
RMSE = Pn
i=1(yi ^yi)
n p
1=2
; (8)
where n is the number of testing samples, p is the number of model parameters which refers to the liter-ature [23]. Then, the three methods continue running ten times under the same condition. The average solution, the number of the best solutions and average computation time of the three methods are shown in Table 3.
Table 3. Results obtained by three methods. Average
solution
The number of the best
solutions
Average computation
time
Grid searech 1.712 10 55.27
SCE-UA 1.733 6 26.57
GA 1.726 8 31.15
By comparing the results from the three methods, it is obvious that all three methods can attain the best solution. However, the grid search attained the ten best solutions in the ten computing times. The GA acquired the best solutions 8 times, while SCE-UA attained the best solutions 6 times. This is because the grid search method simply determines the word search solver at each point on the grid of the parameter values. It may oer some protection against local minima, while the other two algorithms often tap into local minima. How-ever, it is not very ecient. When more parameters are included in the model, the number of determinations can be excessive. When compared with SCE-UA, GA seems more suitable to determine the parameters for SVM, for our problem. It is because GA is a search heuristic inspired by natural evolution, which is often used to generate useful solutions to optimization. In addition, compared with the average solutions of GA and UA, the stabilization performance of SCE-UA (in which the dierence between the best solution and the average solution is about 1.2%), is the worst of the three methods. However, the average time of the grid search is the highest. This could be due to the fact that the grid search computes the performance at all combinations of C, " and to get the performance surface. We can also see that the time consumed by GA is more than that of SCE-UA. This may be because it is a tness-based process, and using natural evolution, such as inheritance, mutation, selection, and crossover, will involve high computational time. Thus, for the practical prediction model of rock displacement surrounding the tunnel, GA is used to determinate the parameters for SVM, and the optimal values are attained as C = 6:4371, " = 0:0032 and = 1:4129. 3.2. The determination of forgetting factors
and the number of prediction steps
The forgetting factor is used to weigh the inuence from the new and the old data. The choice of the forgetting factor is typically a compromise between the ability to track changes in the parameters and the need ofsuppressing stochastic behaviors of the estimates. A large forgetting factor (eectively, a large memory of data) is used when the learning is in the steady state and there is no obvious model variation, while a small one (to fade away the very old data) is applied when the model error is large. A too large and too small
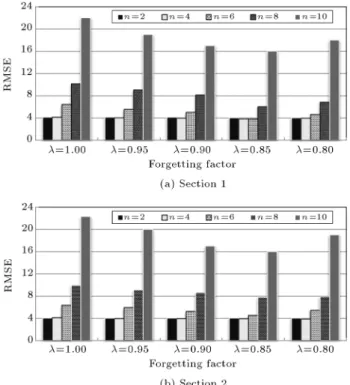
Figure 3. Comparison of various forgetting factors and prediction steps ahead.
forgetting factor will aect prediction accuracy and, even worse, the prediction ability of SVM. In addition, in the multi-step-ahead prediction model, the number of prediction steps is an important factor aecting prediction accuracy. It can be due to the fact that the MS prediction technique needs the recursive use of Single-Step (SS) predictors for reaching the end-point. Even small errors from preceding predictions are accumulated and propagated, thus, resulting in poor prediction accuracy in following predictions. To determinate the value of forgetting factors and the number of prediction steps, the prediction errors of SVMFF under various forgetting factor and prediction steps are shown in Figure 3.
From Figure 3, it can be observed that the changing trends of RMSEs on the two sections are almost the same, and prediction accuracy is the highest when prediction step is n = 6 and forgetting factor is = 0:85. When the forgetting factor is from 0.8 to 0.9, prediction accuracy is relatively less than others. Furthermore, as we predict ahead, the errors accumu-late and propagate. There are both increasing trends of RMSEs of the displacement predictions on two sections, as the increase of the step ahead. However, at the beginning, the prediction errors increase slightly with the increase of the step ahead, while they start to increase greatly after the number of prediction steps is 8. It can be attained that too long a step will increase prediction errors. Therefore, the forgetting factor and the number of prediction steps ahead are determined as 0.85 and 6 in this study, respectively.
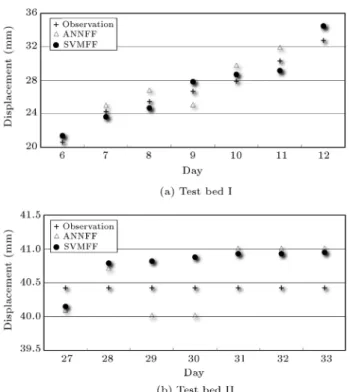
Figure 4. Comparison between the performances of SVMFF and ANNFF.
3.3. Results
To further analyze the characteristics of the MS predic-tion for the tunnel surrounding rock, we select the 6th to the 12th data from the second section, as test bed I (note: the rst ve data as the inputs), and the 27th to 33rd data from the second section, as test bed II. Here, the two test beds reect, respectively, two typical cases: One is the phase where tunnel surrounding displacement increases obviously, and the other is the phase when tunnel surrounding displacement changes smoothly.
Then, to evaluate the performance of the pro-posed model, a three-layer ANN model with forgetting factor (ANNFF) is also introduced in this paper. To get a good comparison, the same input and output vari-ables of ANNFF should be the same as the SVMFF. In the ANNFF, a scaled conjugate gradient algorithm [24] is employed for training. To prevent overtraining and improve the generalization ability, the hidden neurons are generally optimized by a trial and error procedure. In this study, the nal ANNFF architecture consists of ve hidden neurons that yield the best performance. Then, we compare the performance of the SVMFF with that of ANNFF using RMSE. Figure 4 depicts the prediction performance of the two models on the two test beds. It can be found that the two models obtain more accurate values at the former rather than at the latter data in each test bed. It can be attributed to the fact that the MS predictor is based on the recursive use of the SS predictor for reaching the end-point on the horizon. The prediction errors at the beginning
Figure 5. Comparison between the prediction errors of SVMFF and ANNFF.
of the horizon accumulate and propagate till the end prediction. It is true that prediction errors increase. However, in some real-world applications, especially for the prediction of rock displacement surrounding a tunnel, which has a relatively smaller time period, it requires enough time to take preventive measures to combat danger. Thus, it is acceptable to adapt to MS techniques to predict future displacements.
The relationship between observations and pre-dictions for the two test beds is also illustrated in Figure 5. It is obvious that the errors from SVMFF models, generally, are smaller than those of ANNFF. This can be explained by the fact that SVMFF uses the structural risk minimization principle to minimize the generalization error, while ANNFF uses the empirical risk minimization principle to minimize the training error. Furthermore, SVMFF always seeks to nd the global solution, while ANNFF may tend to fall into a local optimal solution. Therefore, it is feasible to use our model to solve the displacement prediction of rock surrounding a tunnel.
4. Conclusions
The deformation of rock mass surrounding a tunnel is an eective factor to reect the stability of a tunnel. Proving accurate displacement prediction in advance is a method to identify potential danger and some eective measures are used to reduce losses. In this paper, an MS prediction based on SVM is used to predict surrounding rock deformation. To improve the training eciency of SVM, grid-search, SCE-UA and GA are implemented for determining the parameters in SVM. To deal with the time-varying features of rock displacement surrounding a tunnel, a forgetting factor is used to weigh the eects from old and new data. In addition, considering the fact that long-time prediction by the MS technique will worsen the prediction errors, an experiment from the Chijiangchong tunnel is applied to determine the prediction horizon. The result shows that 7 is the suitable prediction horizon for our problem
in this study. Then, compared with ANNFF, the proposed SVMFF can provide a better performance in most situations than ANNFF. Thus, SVMFF has been proved an eective method for prediction of rock displacement surrounding a tunnel.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (51208079), the Major State Basic Research Development Program of China (\973" Program: 2013CB036203), Fundamental Re-search Funds for the Central Universities 2011JBM069 and the Fundamental Research Funds for the Central Universities (3013-852019).
References
1. McCoy, T., Yearout, R. and Patch, S. \Misrepresenting quality data through incorrect statistical applications - A statistical quality control (SQC) case study", In-ternational Journal of Industrial Engineering-Theory Applications and Practice, 11(1), pp. 66-73 (2004).
2. Li, X.H., Zhao, Y., Jin, X.G., Lu, Y.Y. and Wang, X.F. \Application of grey majorized model in tunnel surrounding rock displacement forecasting", Lecture Notes in Computer Science, 3611, pp. 584-591 (2005).
3. Sellner, P.J. \Prediction of displacements in tunnel-ing", Ph.D Thesis, Graz University of Technology, Graz (2000).
4. Xie, J.X., Cheng, C.T., Chau, K.W. and Pei, Y.Z. \A hybrid adaptive time-delay neural network model for multi-step-ahead prediction of sunspot activity", International Journal of Environment and Pollution, 28(3-4), pp. 364-381 (2006).
5. Liu, J., Wang, W. and Golnaraghi, F. \A multi-step predictor with a variable input pattern for system state forecasting", Mechanical Systems and Signal Processing, 23(5), pp. 1586-1599 (2009).
6. Yu. B., Yang, Z.Z. and Yu, B. \Hybrid model for pre-diction of bus arrival times", Neural Network World, 19(3), pp. 321-332 (2009).
7. Cao, L.J. and Tay, F.E.H. \Support vector machine with adaptive parameters in nancial time series forecasting", IEEE Transactions on Neural Networks, 14(6), pp. 1506-1518 (2003).
8. Zhou, H., Li, W., Zhang, C. and Liu, J. \Ice breakup forecast in the reach of the Yellow River: the support vector machines approach", Hydrology and Earth Sys-tem Sciences Discussions, 6(2), pp. 3175-3198 (2009).
9. Yu, B., Yang, Z.Z. and Yao, B.Z. \Bus arrival time prediction using support vector machines", Journal of Intelligent Transportation Systems, 10(4), pp. 151-158 (2006).
10. Yu, B., Lam, W.H.K. and Lam, T.M. \Bus arrival time prediction at bus stop with multiple routes", Transportation Research Part C, 19(6), pp. 1157-1170 (2011).
11. Yu, B., Yang, Z.Z., Chen, K. and Yu, B. \Hybrid model for prediction of bus arrival times at next station", Journal of Advanced Transportation, 44(3), pp. 193-204 (2010).
12. Hou, S.M. and Li, Y.R. \Short-term fault prediction based on support vector machines with parameter optimization by evolution strategy", Expert Systems with Applications, 36(10), pp. 12383-12391 (2009).
13. Hsu, C.W., Chang, C.C. and Lin, C.J. \A Practical guide to support vector classication", Technical Re-port, Department of Computer Science and Informa-tion Engineering, NaInforma-tional Taiwan University (2003).
14. Lin, J.Y., Cheng, C.T. and Chau, K.W. \Using sup-port vector machines for long-term discharge predic-tion", Hydrological Sciences Journal, 51(4), pp. 599-612 (2006).
15. Lorena, A.C. and de Carvalho, A.C.P.L.F. \Evolu-tionary tuning of SVM parameter values in multiclass problems", Neurocomputing, 71(16-18), pp. 3326-3334 (2008).
16. Yao, J.B., Yao, B.Z., Li, L. and Jiang, Y.L. \Hybrid model for displacement prediction of tunnel surround-ing rock", Neural Network World, 22(3), pp. 263-275 (2012).
17. Yao, B.Z., Yang, C.Y. and Yao, J.B. \Tunnel surround-ing rock displacement prediction ussurround-ing support vector machine", International Journal of Computational In-telligence Systems, 3(6), pp. 843-852 (2010).
18. Lee, K.L. and Billings, S.A. \A new direct approach of computing multi-step ahead predictions for non-linear models", International Journal of Control, 76(8), pp. 810-822 (2003).
19. Zhang, G., Patuwo, B.E. and Hu, M.Y. \Forecasting with articial neural networks: The state of the art", International Journal of Forecasting, 14, pp. 35-62 (1998).
20. Vapnik, V.N. \An overview of statistical learning the-ory", IEEE Transactions on Neural Networks, 10(5), pp. 988-999 (1999).
21. Vapnik, V.N., The Nature of Statistical Learning The-ory, Springer, New York (2000).
22. Schubert, W., Steindorfer, A. and Button, E.A. \Displacement monitoring in tunnels - An overview", Felsbau, 20(2), pp. 7-15 (2002).
23. Dong, B., Cao, C. and Lee, S.E. \Applying support vector machines to predict building energy consump-tion in tropical region", Energy and Buildings, 37(5), pp. 545-553 (2005).
Biographies
Baozhen Yao received her PhD degree from Beijing Jiaotong University, Beijing, China, in 2011, and is currently postdoctoral research student in the School of Automotive Engineering at the Dalian University of Technology, China. Her current research interests include articial intelligence, and logistics systems. Jinbao Yao received his PhD degree, in 2010, from Beijing Jiaotong University, Beijing, China, where he is currently lecturer in the School of Civil En-gineering & Architecture. His research interests
in-Mingheng Zhang received his PhD degree from Jilin University, Changchun, China, in 2007. Currently he is lecturer in the School of Automotive Engineering at Dalian University of Technology, China. His research interests include articial intelligence, intelligent Vehi-cle navigation, image processing.
Lan Yu received her MS degree from Helsinki School of Economics, Finland, and is currently lecturer at the Yanching Institute of Technology, China. Her current research interests include articial intelligence, and data processing and analysis.