Between XML Documents
Buhwan Jeong1, Daewon Lee1, Hyunbo Cho1, and Boonserm Kulvatunyou2
1
Department of Industrial and Management Engineering, Pohang University of Science and Technology (POSTECH),
San 31, Hyoja, Pohang, 790-784, South Korea {bjeong,woosuhan,hcho}@postech.ac.kr
2
Manufacturing Engineering Laboratory, National Institute of Standards and Technology (NIST),
100 Bureau Dr., Gaithersburg, MD, 20899
Abstract. Measuring structural similarity between XML documents has become
a key component in various applications, including XML data mining, schema matching, web service discovery, among others. The paper presents a novel struc-tural similarity measure between XML documents using kernel methods. Results on preliminary simulations show that this outperforms conventional ones.
Keywords: Information compatibility analysis, kernel methods, schema
match-ing, string kernel, structural similarity, XML mining.
1
Introduction
Nowadays, XML has been rooted as the standard means to express enterprise data and exchange the data among enterprise applications. Along with its explosive use, it has several bothersome obstacles including profusion, redundancy, and reproduction of sim-ilar information contents in differing way. Proper manipulation of XML content has become a main research issue both in academia and in industry. Two of the main issues of interest in this paper involve XML formalisms [1] [2] [3] and a variety of similarity measures [1] [3] [4] [5] [6]. Most of those measures focus primarily on the seman-tic/linguistic similarity between data items; in this paper, however, we focus on a novel measure of structural similarity.
This paper proposes a novel structural similarity measure for comparison of XML documents. We base this measure on well-known kernel methods for structured data. We first introduce an interface representation to capture the structure of an XML doc-ument, and then deploy the kernel methods to manipulate that representation. We use this approach to compute measures for two examples: OAGIS Core Components and ACMSIGMOD Records.
The rest of the paper is organized as follows: Section 2 illustrates a motivating ex-ample, in which software components are replaced based on the semantic similarity between information models. Section 3 describes our use of kernel methods to com-pute the structural similarity between XML documents. Section 4 includes preliminary simulation results, and Section 5 provides our concluding remarks.
H.G. Okuno and M. Ali (Eds.): IEA/AIE 2007, LNAI 4570, pp. 572–581, 2007. c
2
Motivating Example: Component Replacement and Selection
Consider the following common example. A company decides to replace a software component that is integrated with other components in the enterprise. This decision may arise because the original component provider goes out of business, ceases to support that particular version of the software, or introduces a newer version that is deemed to be more powerful. It may also arise when another version has better or less expensive alternative. In either case, the principal problem is to determine if the new component is compatible with the functionality of and is easily integrated with the other existing component(s).
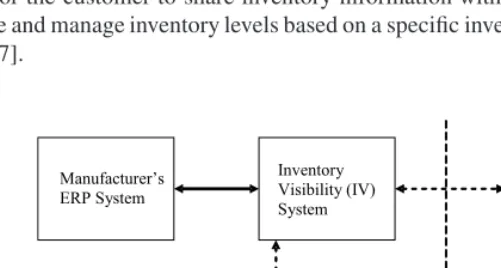
To find the answer to this problem, an IT manager must perform an information compatibility analysis. This analysis is complicated because, as noted above, this re-placement must meet both functional and connectivity requirements. Fig. 1 illustrates this situation with some particular software components. Suppose that the company has an Inventory Visibility (IV) system that is already integrated with its ERP system. An IV system consists of a processing module and web client interfaces. The system allows for the customer to share inventory information with suppliers. They both can visualize and manage inventory levels based on a specific inventory policy from the web clients [7].
Manufacturer’s ERP System
Inventory Visibility (IV) System
Supplier’s IV Visualization Web Interface
Customer’s IV Visualization Web Interface
Fig. 1. A software component connectivity scenario
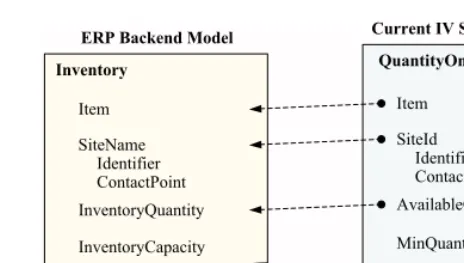
Item QuantityOnHand
SiteId
AvailableQuantity MinQuantity MaxQuantity Item
Inventory
SiteName
InventoryQuantity InventoryCapacity
Current IV Software Model ERP Backend Model
Identifier Identifier
ContactUrl ContactPoint
Fig. 2. An exemplary mapping of data between the ERP and the IV system
3
Kernel-Based Measurement of XML Structural Similarity
Our approach to computing structural similarity between XML documents using the kernel method has two steps. First, we transform the tree-structured XML documents into normalized plain documents. Then, we apply the word sequence kernel to the nor-malized documents to compute the structural similarity. We discuss these two steps in the following subsections after succinct introduction to string kernels.
3.1 String Kernel
Kernel methods, such as support vector machines, construct non-linear algorithms by mapping samples in original spaceX into those in a higher-dimensional Hilbert space
H. However, they have a computational explosion for large-scale problems [8]. For-tunately, the so-called kernel trick resolves it by getting the scalar product implicitly computed inHwhen an algorithm solely depends on the inner product between vec-tors. Recent kernel methods for structured data employ this kernel trick to incorporate types of data other than numerical and vector data. In particular, we introduce the string subsequence kernel dealing with string data. The following definition is critical to our application to computing structural similarity.
Definition 1 (String Subsequence Kernel [10]). LetΣbe a finite alphabet. A string is a finite sequence of characters fromΣ, including the empty sequence. For stringsand t, we denote by|s|the length of the strings=s1...s|s|, and bystthe string obtained
by concatenating them. The strings[i:j]is the substringsi...sjofs. We say thatuis a
subsequence ofs, if there exist indicesi= (i1, ..., i|u|), with1≤i1< ... < i|u|≤ |s|,
such thatuj = sij, forj = 1, ...,|u|, or u = s[i]for short. The length l(i)of the
subsequence insisi|u|−i1+ 1. We denote byΣnthe set of all finite strings of length
n, and byΣ∗the set of all strings, i.e.,Σ∗=∞n=0Σn. We now define feature spaces
Fn =RΣ n
. The feature mappingφfor a stringsis given by defining theucoordinate φu(s)for eachu ∈ Σn. We defineφu(s) =
i:u=s[i]λ l(i)
stringsandtgives a sum over all common subsequences weighted according to their frequency of occurrence and lengths
Kn(s, t) =
u∈Σn
φu(s)·φu(t)=
u∈Σn
i:u=s[i]
j:u=t[j]
λl(i)+l(j). (1)
Since a direct computation of these features would involveO(|Σ|n)time and space, a recursive computation inO(n|s||t|)is provided in [10]. The K(s, t), i.e., the inner product of the feature vectors, is defined as the similarity between the stringssandt
[11]. In addition, an extension to the basic string kernel is found in [12] [13], where the characters are replaced with words or syllables – word sequence kernel – as well as soft matching is allowed. This extension yields a significant improvement in computation efficiency for large documents.
Furthermore, one of the most critical factors to determine kernels’ performance is the choice of the decay factorλ. Compared with the original string kernel, which uses the sameλfor every character, [12] introduces a differentλ-weighting strategy that assigns a different weight (λc) to each character (c ∈ Σ). The weighted string kernelKwof two stringssandtis defined as
Knw(s, t) =
u∈Σn
φwu(s)·φwu(t)=
u∈Σn
i:u=s[i]
j:u=t[j] i|i|
k=i1
j|j|
l=j1
λskλtl. (2)
The evaluation ofKwcan be computed recursively using a technique similar to the one used in the original string kernel [12]. The use of different decay factors is one way of incorporating prior knowledge, such as synonymous relation between words, into the string kernel. We discuss the determination of weights for XML document structure later in the paper (in Section 3.3).
3.2 Transformation of XML Tree Structure into a Normalized Document
Fig. 3. Transformation of an XML document into a normalized document
instances derived from the same schema. A fundamental property of the resulting tree is that it disallows inclusive/duplicate structures. This means that each path is exclusive, i.e., a sequence of element/attribute names from the root node to a leaf node1does not
contain other paths. Another property is that the tree is expressive. That is any contents in an XML instance must be reachable by the resulting tree. This means that the abstract tree is a collection of the longest (or most general) paths between the root and the leaf nodes. For more on this process, see [14].
In the second step, the serialization transforms the abstract tree representation into a sequence of words. This serialization process is the key idea to manipulating the XML’s tree structure because it enables us to apply the word sequence kernel without any modification. We visit every node by a depth-first traversal of the tree producing a long sentence, which is a sequence of node labels from the root node to the rightmost leaf node.
In the last step, the normalization process deals with the problems that each word is often a compound word comprised of several individual terms – for example,
Quan-tityOnHand and InventoryQuantity in Fig. 2. The normalization process recursively
consists of (1) tokenization, which separates a compound word into atomic dictionary words; (2) lemmatization, which analyzes these words morphologically in order to find all their possible basic forms; (3) elimination, which discards meaningless stop words such as article, preposition, and conjunction; and, (4) stemming, which finds a stem form of a given inflected word [14] [15].
Take the QuantityOnHand schema document in Fig. 2, for example, The serializa-tion process yields{QuantityOnHand, Item, SiteId, Identifier, ContactUrl,
Available-1
A leaf node can be either an element or an attribute, while intermediate nodes must be ele-ments.
(A)XML Schema document
<xsd:element name=“QuantityOnHand” type=“QuantityOnHandType” /> <xsd:complexType name=“QuantityOnHandType”>
<xsd:sequence>
<xsd:element ref=“Item” />
<xsd:element ref=“SiteId” minOccurs=“0”/> <xsd:element ref=“AvailableQuantity” /> …
</xsd:sequence> </xsd:complexType>
<xsd:element name=“SiteId” type=“SiteIdType” /> …
QuantityOnHand
AvailableQuantity
Item SiteId
(B) Abstraction
MinQuantity
Identifier ContactUrl
(C) Serialization
QuantityOnHand Item SiteId Identifier ContactUrl AvailableQuantity …
(D) Normalization
Quantity, MinQuantity, MaxQuantity}. The normalization process yields {Quantity, Hand, Item, Site, Identifier, Identifier, Contact, Universal, Resource, Locator, Avail-able, Quantity, Minimum, Quantity, Maximum, Quantity}. Note, the elimination pro-cedures removes the preposition On from QuantityOnHand; the lemmatization process changes Id into Identifier and Url into Universal, Resource, and Locator.
3.3 Applying Word Sequence Kernel to Measure Structural Similarity
We compute structural similarity measures only for normalized documents. For two XML documentsd1andd2and a kernel functionK, we define their structural similarity asSim(d1, d2) =K(s1, s2), wheres1ands2are their respective normalized strings. We use a modified word-sequence kernel that reads a pair of strings, generates two feature vectors, and then calculates their inner product·,·. The final inner product is the structural similarity.
As noted above, we use equation (2) with different weights assignments. That is, we assign different decay factorλto different nodes. To make this assignment, we intro-duce a depth-dependent decay factorλn=λ0/depth(n)r, wheredepth(n)is the depth of the noden(depth(root) = 1) andr≥1is a relevant factor. Since, as shown in the example below, the size of inputs, length of strings, is usually not a constant, the ker-nel value is sometimes normalized to [0, 1] byK(s, t) =ˆ K(s, t)/K(s, s)·K(t, t),
ˆ
K(s, t) = 1if and only if stringssandtare identical.
Take an illustrative example to compute the structural similarity between Inventory and QuantityOnHand (in Fig. 2 above). For simplicity, we use following symbols to each word in the normalized documents: A(vailable), C(ontact), H(and), I(dentifier), L(ocator), M(inimum), N(ame), P(oint), Q(uantity), R(esource), S(ite), T(Item), U(niversal), V(Inventory), X(Maximum), Y(Capacity). After normalized document transformation, we get the string ’VTSNICPVQVY’ for the Inventory document and the string ’QHTSIICURLAQMQXQ’ for the QuantityOnHand document. The common subsequences are{C, I(2), Q(4), S, T, CQ(3), IC(2), ..., TSICQ(6)}. Note that numbers in parentheses indicate the number of possible occurrences. Accordingly, as detailed in Fig. 4, their similarity is easily computed via equation (2) asKw 2.1399and
Kw 0.6149with respect tor = 1andr = 2, andλ
0 = 1, whereas computed via equation (1) with withλ= 0.5yieldsK= 2.3699.
4
Preliminary Experiments
To evaluate the proposed method, we performed experiments with XML schema docu-ments from OAGIS2. We designed two types of experiments. The first experiment is to
show the correlation between the proposed method and the human’s similarity scoring; the other is to verify that the proposed measures could discriminate relevant information from irrelevant information from the information retrieval perspective.
2
s t
Sequence C I Q S
Product
T CQ TSICQ
1/3 1/3 1/2 1/2 1/2 1/36 …
1/3 1/2+1/3 1+3 1/2 1/2 1/2 1/36+1/144+1/576 …
0.1111 0.2778 1.2500 0.25 0.25 0.001 0.0000
(A) Input stringss= ‘VTSNICPVQVY’,t= ‘QHTSIICUAQMQXQ’ andr= 1
Kw(s,t) = 2.1399
s t
Sequence C I Q S
Product
T CQ TSICQ
1/9 1/9 1/4 1/4 1/4 1/1296 …
1/9 1/4+1/9 1+3 1/4 1/4 1/4 … …
0.0123 0.0401 0.4375 0.0625 0.0625 0.0000 0.0000
(B) Input stringss= ‘VTSNICPVQVY’,t= ‘QHTSIICUAQMQXQ’ andr= 2
Kw(s,t) = 0.6149
…
…
Fig. 4. Exemplary structural similarity computation using the proposed kernel method with
rele-vant factorr= 1andr= 2
For the first experiment, we randomly selected 200 pairs of CC’s (Core Compo-nents) and let four human experts (based on their own domain and linguistic knowl-edge) score every pair to assign their degree of relatedness in [0, 1]. We implemented four algorithms – TED (Tree Edit Distance)3; VSM by means of cosine of the angle [9]; kernels both with a fixed penalty (i.e.,λn = c) and with a variant penalty (i.e.,
λn =f(λ0, depth(n), r)). The experimental result is depicted in Fig. 5 in terms of cor-relation with the operators’ average score. ’Kern.1’ and ’Kern.2’ implemented a fixed weighting scheme withλ= 1and1/2, respectively. ’Kern.3’ and ’Kern.4’ implemented a variable weighting scheme (λ0= 1) with relevant factorsr= 1and2, respectively.
As shown in the figure, the kernel methods outperform the conventional measures, TED and VSM. Although VSM is a special type of the kernel method, the proposed ones give better performance because they preserve the parent-child relationship be-tween elements in XML documents. In other words, the bag-of-words model, VSM, gives the same importance between, for example, the root node and a leaf node. It is also noted that the proposed depth-depedentλ-weighting gives a more accurate measure than the fixed one does.
The second experiment was a mapping test that evaluates whether mappings estab-lished by an algorithm are correct compared with true mappings. We configured four experiment sets, each of which consists of two data sets having 10 CC’s and 20 CC’s. Between the two data sets, an algorithm and human operators selected no more than 10 plausible mappings4. Then, we compared the selections using three widely used
in-formation retrieval performance metrics: Precision, Recall, and F-Meausre. LetAbe a set of alignments mapped by an algorithm, andTbe a set of true mappings by human
3A state-of-the-art similarity measure for tree structures [4] [16]. 4
Fig. 5. Correlation between human judgment and various structural similarity measures – TED
(Tree Edit Distance), VSM with cosine of the anglecosθ, and Kernel-based measures (i.e.,λ= 1,λ= 0.5,λ0= 1 &r= 1, andλ0= 1 &r= 2, respectively)
experts. Then the metrics are defined as follows:P recision=|AT|/|A|,Recall=
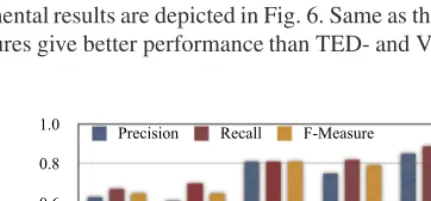
|AT|/|T|, andF−M easure= 2×P recision×Recall/(P recision+Recall). The experimental results are depicted in Fig. 6. Same as the first experiment, the kernel-based measures give better performance than TED- and VSM-kernel-based ones do.
0 0.2 0.4 0.6 0.8 1.0
TED VSM Kern.1 Kern.2 Kern.3 Kern.4 Precision Recall F-Measure
Fig. 6. Precision, Recall and F-measure
We conducted additional experiments with XML instance documents from ACM-SIGMOD Records5. We prepared two groups of XML instances. Each group had 50
documents randomly selected, but conforming to the same DTD (Document Type Defi-nition). The two DTD’s shared several common element definitions (e.g., author, title). Confirming to the same DTD apparently means its instances are structurally similar. We tried to discriminate the documents using the PAM (Partitioning Around Medoids) algorithm [17] with ten replications. The clustering results are depicted in Table 1, in which the low structural diversity among documents, particularly in the second group, makes them well-separated, except TED. Another implication from the result is the nor-malized document representation is a simple yet effective means to express XML’s tree structure. It should be noted that the experiment does not care about contents of those
5
Table 1. Clustering results for ACMSIGMOD Record: A comparison matrix
documents, but their structure only. For all that, the proposed kernel-based measures require a significant modification to reduce computation time for large datasets.
5
Conclusion
The paper presented a novel approach to compute the structural similarity between XML documents by incorporating a modified string kernel. To apply the proposed ker-nel methods to XML documents, we proposed normalized document representation for XML document structure and aλ-weighted word sequence kernel for structural sim-ilarity computation. The experimental results showed that the proposed kernel-based measure outperforms state-of-the-art approaches (i.e., TED and VSM). In particular, the kernel-based measure can help web services to be properly discovered, selected, and composed when those activities are performed based on the message type. More-over, we also expect that the result of this research will improve significantly the perfor-mance of XML-based applications such as XML document clustering and classification, schema matching, XML message mapping, ontology reconciliation.
Disclaimer
Certain commercial software products are identified in this paper. These products were used only for demonstration purposes. This use does not imply approval or endorsement by NIST, nor does it imply that these products are necessarily the best available for the purpose.
References
1. Flesca, S., Manco, G., Masciari, E., Pontieri, L., Pugliese, A.: Fast detection of XML struc-tural similarity. IEEE Transactions on Knowledge and Data Engineering 17(2) (February 2005)
2. Yang, J., Cheung, W., Chen, X.: Learning the kernel matrix for XML document clustering. In: Proceedings of the 2005 IEEE International Conference on e-Technology, e-Commerce and e-Service (EEE’05), Washington, DC, pp. 353–358. IEEE Computer Society Press, Los Alamitos (2005)
3. Lee, J., Lee, K., Kim, W.: Preparations for semantics-based XML mining. In: Proceedings of IEEE International Conference on Data Mining (ICDM 2001), pp. 345–352 (2001) 4. Nierman, A., Jagadish, H.: Evaluating structural similarity in XML documents. In:
Proceed-ings of the 5th International Workshop on the Web and Database (WebDB2002) (2002)
Methods TED VSM Kern.1 Kern.2
C1 C2 C1 C2 C1 C2 C1 C2
Real C1 34 16 50 0 50 0 50 0
5. Shvaiko, P., Euzenat, J.: A survey of scham-based matching. Journal of Data Semantics IV 3730, 14–171 (2005)
6. Jeong, B., Kulvatunyou, B., Ivezic, N., Cho, H., Jones, A.: Enhance reuse of standard e-business XML schema documents. In: Proceedings of International Workshop on Contexts and Ontology: Theory, Practice and Application (C&O’05) in the 20th National Conference on Artificial Intelligence (AAAI’05) (2005)
7. Ivezic, N., Kulvatunyou, B., Frechette, S., Jones, A., Cho, H., Jeong, B.: An interoperabil-ity testing study: Automotive inventory visibilinteroperabil-ity and interoperabilinteroperabil-ity. In: Proceedings of e-Challenges (2004)
8. Muller, K., Mika, S., Ratsch, G., Tsuda, K., Sch¨olkopf, B.: An introduction to kernel-based learning algorithms. IEEE Transactions on Neural Networks 12(2), 181–201 (2001) 9. Kobayashi, M., Aono, M.: Vector Space Models for Search and Cluster Mining, pp. 103–122.
Springer, New York (2003)
10. Lodhi, H., Saunders, C., Shawe-Taylor, J., Cristianini, N., Watkins, C.: Text classification using string kernels. Journal of Machine Learning Research 2, 419–444 (2002)
11. Vert, J., Tsuda, K., Sch¨olkopf, B.: A Primer on Kernel Methods, pp. 35–70. MIT Press, Cambridge (2004)
12. Saunders, C., Tschach, H., Shawe-Taylor, J.: Syllables and other string kernel extensions. In: Proceedings of the 19th International Conference on Machine Learning (ICML’02) (2002) 13. Cancedda, N., Gaussier, E., Goutte, C., Renders, J.: Word-sequence kernels. Journal of
Ma-chine Learning Research 3, 1059–1082 (2003)
14. Jeong, B.: Machine Learning-based Semantic Similarity Measures to Assist Discovery and Reuse of Data Exchange XML Schemas. PhD thesis, Department of Industrial and Manage-ment Engineering, Pohang University of Science and Technology (2006)
15. Willett, P.: The porter stemming algorithm: Then and now. Electronic Library and Informa-tion Systems 40(3), 219–223 (2006)
16. Zhang, Z., Li, R., Cao, S., Zhu, Y.: Similarity metric for XML documents. In: Proceedings of Workshop on Knowledge and Experience Management (FGWM2003) (2003)