Customer Cloud Architecture for Big Data
and Analytics, Version 1.1
Executive Overview
Using analytics reveals patterns, trends and associations in data that help an organization understand the behavior of the people and systems that drive its operation. Big data technology increases the amount and variety of data that can be processed by analytics, providing a foundation for visualizations and insights that can significantly improve business operations.
This paper considers how harnessing cloud architectures can further change the economics and development lifecycle of these capabilities. It describes vendor neutral best practices for hosting big data and analytics solutions (or just “analytics solutions”) using cloud computing. The architectural elements described in this document will help you understand the components for leveraging various cloud deployment models.
The primary drivers for deploying analytics solutions on cloud include:
1. Low upfront cost of infrastructure and a reduction in the skills needed to get started.
2. Elastic data and processing resources that grow and shrink with demand, reducing the need to maintain capacity for the maximum workload.
3. Mitigation against limited internal capability for meeting information governance, compliance and security requirements.
4. Applying more processing resources to existing data sources.
5. Building solutions faster because it enables try and buy, rapid prototyping and shorter procurement processes.
Cloud deployments offer a choice of private, public and hybrid architectures. Private cloud employs in-house data and processing components running behind corporate firewalls. Public cloud offers services over the internet with data and computing resources available on publicly assessable servers. Hybrid environments have a mixture of components running as both in-house and public services.
It is important to have this choice of cloud deployment because location is one of the first architectural decisions for an analytics cloud project. In particular, where should the data be located and where should the analytics processing be located relative to the location of the data? Legal and regulatory requirements may also impact where data can be located since many countries have data sovereignty laws that prevent data about individuals, finances and intellectual property from moving across country borders.
The choice of cloud architectures allows compute components to be moved near data to optimize processing when data volume and bandwidth limitations produce remote data bottlenecks.
move, so the analytics processing system may need to access this data from its current storage location. The amount of data that the analytics processing system needs would then determine whether the analytics needs to be hosted with this data, or whether it can use APIs to retrieve the data it needs remotely.
Much of the data that an organization might process with analytics could be generated by existing systems and the log files and related documents that accompany it. This may then be augmented with data from third parties and new applications that are born on the cloud. Your cloud architecture needs to make trade-offs for where the data is to be accumulated and processed.
Analytics has a development lifecycle that also impacts where data is optimally located and managed. The first phase is the discovery and exploration of data. In this phase a catalog is used to discover (locate) the data to analyse. They then access the data and explore its values using analytics tools. The second phase is the development of the analytics model and finally, phase three is the deployment of the analytics model into production.
Each phase may run in the same cloud environment or be distributed in different locations. Typically phase one and two (the discovery, exploration and analytical model development) is collated with a vast collection of different types of data that has been harvested from its original sources. For phase three, the completed analytical models may be deployed with this data, or placed close to where this data is being generated, or where the resulting insight will be acted upon. Wherever the analytics model is deployed, it is accompanied by new data collection processes that gather the results of the analytics so they can be improved with another iteration of the analytics development lifecycle.
The architecture of the analytics cloud solution may evolve as this solution matures. Preliminary and proof-of-concept (POC) applications often start in public cloud environments where new resources can be acquired and evaluated quickly with a minimal procurement process. Development and deployment costs can then be estimated based on initial usage metrics. Development speed is generally enhanced via continuous release methodologies and by leveraging Platform as a Service (PaaS) and Software as a Service (SaaS). The cost model of paying for what you use, as you need it, is an attractive benefit of public cloud deployment for evaluating new approaches.
Organizations needing on-premises data storage and processing cite data privacy, security and legal constraints as chief motivations. Large data sets that cannot be moved and local operational
requirements are other factors that favor in-house provisioning. Private cloud deployment is a solution that generally offers the most efficient access to this secure data while maintaining access to internally shared software and analytics.
Hybrid cloud deployment is emerging as a preferred choice of customers who want to balance their requirements and costs. Critical data and processing remains in the enterprise data center, while other resources are deployed in public cloud environments. Processing resources can be further optimized with a hybrid topology that enables cloud analytics engines to work with on-premises data. This leverages enhanced cloud software deployment and update cycles while keeping data inside the firewall.
Another benefit is the ability to develop applications on dedicated resource pools in a hybrid cloud deployment that eliminates the need to compromise on configuration details like processors, GPUs,
subsequently deployed to an Infrastructure as a Service (IaaS) cloud service that offers compute capabilities matching the dedicated hardware environment which would be otherwise hosted on
premises. This feature is fast becoming a differentiator for cloud applications that need to hit the ground running with the right configuration to meet real-world demand.
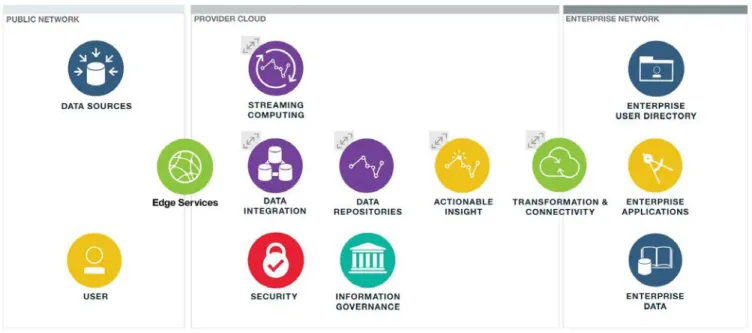
Figure 1 shows the elements that may be needed for any big data analytics solution across three domains: public networks, provider clouds, and enterprise networks.
The public network and enterprise network domains contain data sources that feed the entire
architecture. Data sources include traditional systems of record from the enterprise as well as emerging sources from Internet of Things (IoT).
The provider cloud uses data integration components and potentially streaming computing to capture this combined data into data repositories where analytics can be performed to deliver actionable insights. These insights are used by users and enterprise applications as well as stored in data storage systems. All of this is done in a secure and governed environment.
Results are delivered to users and applications using transformation and connectivity components which provide secure messaging and translations into systems of engagement, enterprise data, and enterprise applications.
Cloud Customer Architecture for Big Data and Analytics
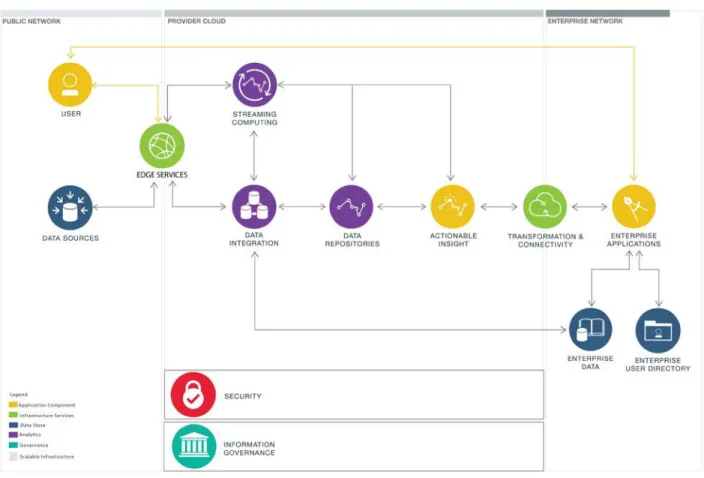
Figure 2 illustrates a simplified enterprise cloud architecture for big data and analytics.Figure 2: Cloud Components for Big Data and Analytics
Big data architecture in a cloud computing environment has many similarities to a traditional data center. Data is collected and staged by data integration so it can be prepared for intended consumers. The data is collected from structured and non-structured data sources, including real-time data from stream computing, and maintained in enterprise data stores. Common metadata and semantic definitions are added to enterprise data repositories. Data repositories provide staging areas for the different types of data. The data repositories provide the development environment for new analytics models or enhancements of existing models. Once the models are executed, their outcome is provided for use as actionable insight via information views into the data which are also exposed for ad-hoc analysis by end users or other applications on the client premises. Data is transformed and augmented as it moves through the processing chain.
Information governance and security subsystems encompass each processing phase to ensure
regulation and policies for all data are defined and enabled across the system. Compliance is tracked to ensure controls are delivering expected results. Security covers all elements including generated data and analytics.
Users are broadly classified in two ways: enterprise and third party. Enterprise users access resources on premises or via a secure Virtual Private Network (VPN). Data is available directly and through
applications that provide reports and analytics. Transformation and connectivity gateways assist by preparing information for use by enterprise applications as well as use on different devices, including mobile, web browsers and desktop systems. Third party users gain access to the provider cloud or the enterprise network via edge services that secure access to users with proper credentials. Access to other resources may be further restricted as dictated by corporate policy.
The remainder of this section describes the various components in detail.
Public Network
The public network contains elements that exist in the internet: data sources, users and the edge services needed to access the provider cloud or enterprise network.
Data sources contain all of the external sources of data for the data analytics solutions that flow from the internet.
Users set up or use the results of the analytical system, and are typically part of the enterprise. Users can be administrative type users, setting up the analytical processing system; analytical services users, using the results of the analytical system; or enterprise users, invoking enterprise applications in the analytical system. In the case of enterprise users, the access path may not go through the public internet and may go directly to the analytical insights or enterprise applications.
When the data or user requests comes from the external internet, the flow may come through edge services including DNS servers, Content Delivery Networks (CDNs), firewalls, and load balancers before entering the cloud provider’s data integration or data streaming entry points.
Data Sources
There can be a number of different information sources in a typical big data system, some of which enterprises are just beginning to include in their data analytics solutions. High velocity, volume, variety and data inconsistency often kept many types of data from being used extensively. Big data tools have enabled organizations to use this data; however, these typically run on-premises and can require substantial upfront investment. Cloud computing helps mitigate that investment and the associated risk by providing big data tools via a pay per use model. Data sources include:
Machine &
Sensor Data generated by devices, sensors, networks and related automated systems including Internet of Things (IoT). Image & Video Data capturing any form of media (pictures, videos, etc.)
which can be annotated with tags, keywords and other metadata.
Social Data for information, messages and pictures/videos created in virtual communities and networks.
Internet Data stored on websites, mobile devices and other internet-connected systems.
Third Party Data used to augment and enhance existing data with new attributes like demographics, geospatial or CRM.
User
The User is a role that describes an enterprise user or third party user. Users perform multiple roles, including:
• Data analysts who perform a variety of tasks related to collecting, organizing, and interpreting information. In a cloud computing environment, such users will typically access information from streaming or data repositories, and make decisions on mechanics of data integration (such as the type of data integration services that should be used, the type of cleansing that needs to be performed, etc.).
• Data scientists who extract knowledge from data by leveraging their strong foundation in computer science, data modeling, statistics, analytics and math. Data scientists play the role of part analyst, part artist and will sift through all incoming data with the goal of discovering a previously hidden insight, which in turn can provide a competitive advantage or address a pressing business problem.
• Business users who are interested in information that will enable them to make decisions critical to tactical and strategic business operations.
• Solution architects who are responsible for identifying the components needed from the cloud provider in order to solve business problems.
The capabilities required to support the cloud user include:
• Self-service - enables users to sign up, customize the analytical processing, and access the output from the analytic systems and solutions without having to talk to a person on the phone or wait weeks for approval. The user may be an employee of the
enterprise, the cloud provider, or some other third party.
• Visualization - enables users to drive dashboards to explore and interact with data from the data repositories, actionable insight applications, or enterprise applications. The user must be authorized to access the visualization.
Edge Services
Edge Services- Edge services include services needed to allow data to flow safely from the internet into the data analytics processing system hosted on either the cloud provider or in the enterprise. Edge services also allow users to communicate safely with the analytical system and enterprise applications. These include:
• Domain Name System Server: Resolves the URL for a particular web resource to the TCP-IP address of the system or service which can deliver that resource.
• Content Delivery Networks (CDN): CDNs are not typically used for data source flows. For user flows, CDNs provide geographically distributed systems of servers deployed to minimize the response time for serving resources to geographically distributed users, ensuring that content is highly available and provided to users with minimum latency. Which servers are engaged will depend on
server proximity to the user and where the content is stored or cached.
• Firewall: Controls communication access to or from a system permitting only traffic meeting a set of policies to proceed and blocking any traffic which does not meet the policies. Firewalls can be implemented as separate dedicated hardware, or as a component in other networking hardware such as a load-balancer or router or as integral software to an operating system.
• Load Balancers: Provide distribution of network or application traffic across many resources (such as computers, processors, storage, or network links) to maximize throughput, minimize response time, increase capacity and increase reliability of applications. Load balancers can balance loads locally and globally. Load balancers should be highly available without a single point of failure. Load balancers are sometimes integrated as part of the provider cloud analytical system components like stream processing, data integration and repositories.
Provider Cloud
Provider cloud hosts components to prepare data for analytics, store data, run analytical systems and process the results of those systems.
Provider cloud elements include:
• Data Integration
• Streaming Computing
• Data Repositories
• Actionable Insight
• Transformation and Connectivity
A cloud computing environment often allows provisioning decisions to be delayed until data volume, velocity and related processing requirements are better understood. Experimentation and iteration using different cloud service configurations is rapidly becoming a preferred way to understand and refine requirements without upfront capital investment.
Data Integration - Data integration copies and correlates information from disparate sources to produce meaningful associations related to primary business dimensions. A complete data integration solution encompasses discovery,
cleansing, monitoring, transforming and delivery of data. Information provisioning methods include ETL, ELT, event-based processing, services, federation, change data capture with replication and continuous stream ingestion.
Data to be integrated can come from public network data sources, enterprise data sources, or streaming computing results. The results from data integration can feed streaming computing, be passed to data repositories for analytical processing, or passed to enterprise data for storage or feeding into enterprise applications.
A cloud computing environment allows data storage technology and physical location to change over time. Processing components can be moved closer to data as dictated by usage and bandwidth. Data can also be moved to more cost-effective storage containers as it ages or is no longer needed for ongoing analytics.
Capabilities required for data integration include:
Data Staging Converting data to the appropriate formats for downstream processing.
Data Quality Cleaning and organizing data to remove redundancies and inconsistencies so that it more readily aligns with systems of record and enterprise data.
Transformation
and Load Leveraging integration and quality capabilities to transform incoming data so it can be loaded into the data warehouses and databases used for reporting and analytics.
Streaming Computing - Stream processing systems can ingest and process large volumes of highly dynamic, time-sensitive continuous data streams from a variety of inputs such as sensor-based monitoring devices, messaging systems and financial market feeds. The “store-and-pull” model of traditional data processing environments is not suitable for this class of low-latency or real-time streaming applications where data needs to be processed on the fly as it arrives. Capabilities include:
Real Time Analytical
Processing Applying analytic processing and decision making to in-motion and transient data with minimal latency. Data Augmentation Filtering and diverting in-motion data to data warehouses for deeper background
analysis.
Cloud services allow streaming computing to be adapted as data volume and velocity changes. Adding virtual memory, processors and storage can accommodate peaks in demand. The option to add dedicated hardware can also help with specialized processing needs.
Data Repositories -The data stored in the cloud environment is organized into repositories. These repositories may be hosted on different infrastructure that is tuned to support the types of analytics workload accessing the data. The data that is stored in the repositories may come from legacy, new and streaming sources, enterprise applications, enterprise data, cleansed and reference data, as well as output from streaming analytics.
Catalog Results from discovery and IT data curation create a consolidated view of information that is reflected in a catalog. The introduction of big data increases the need for catalogs that describe what data is stored, its classification, ownership and related information governance definitions. From this catalog it is possible to control the usage of the data.
Data Virtualization Agile approach to data management that allows an application to retrieve and manipulate data without requiring technical details about the data
Landing, Exploration & Archive
Allows for large datasets to be stored, explored and augmented using a wide variety of tools since massive and unstructured datasets may mean that it is no longer feasible to design the data set before entering any data. Data may be used for archival purposes with improved availability and resiliency thanks to multiple copies distributed across commodity storage. Deep Analytics &
Modeling The application of statistical models to yield information from large data sets comprised of both unstructured and semi-structured elements. Deep analysis involves precisely targeted and complex queries with results measured in petabytes and exabytes. Requirements for real-time or near-real-time responses are becoming more common.
Interactive Analysis &
Reporting Tools to answer business and operations questions over internet scale datasets. Tools also leverage popular spreadsheet interfaces for self-service data access and visualization.
SaaS APIs implemented by data repositories allow output to be efficiently consumed by applications.
Actionable Insight - Data collected, processed and stored in the data repositories may be used by business applications to derive insights that ultimately drive actions. Examples include:
• Analysis of millions of streaming transaction records may flag some transactions as suspicious which may warrant further investigation.
• Analysis of large scale Call Detail Records for a telecom operator may detect abnormally low call quality in a region that warrants further analysis.
Such applications can be delivered by a cloud service provider using a SaaS or PaaS model that requires a subset of data residing in the data repositories.
Creating ‘actionable insight’ means relating new data with existing information in a convincing and understandable manner. Today, this work is ad hoc and executed by highly technical data scientists, but in the future, tools can enable Line-of-Business and other analysts to become more productive.
Statistics with a focus on regression analysis are the primary tools used to correlate and ultimately align messy data. Text analytics and various search tools are also part of this fundamental data preparation activity that results in more data aligned to the primary reporting dimensions of an organization.
Because there are complex associations combined with high data volumes, visualizations are often needed to share an idea or drive consensus. As more data is collected over time, predictive algorithms are often employed to project data into the future.
Finally, because data is generally held in its original form for longer periods of time, it is possible to create multiple correlation and prediction algorithms to drive organizations towards better analytics and, ultimately, the best supported version of the truth.
There are a number of related applications available today. The types of applications include:
Decision
Management Includes analytics-based decision management that enable organizations to make automated decisions backed by analytics, improve efficiency and enable collaboration. They also include operational decision management systems that rely on rules (which may in turn be augmented by analytics) to augment enterprise decision making to achieve specific business objectives (such as prevent a customer from churning, converting a visitor to a client, ordering more inventory, etc.).
Discovery &
Exploration Offers easy exploration across a variety of sources to provide business users with extensive new visibility into business performance without spending a huge amount of time specifying requirements for the system. Data discovery tools allow users to easily explore and understand this diverse data without having to build advanced queries or reports.
Predictive Analytics Extracts information from existing datasets to determine the current state, identify patterns and predict future trends.
Analysis & Reporting Reports of operational and warehouse data to business stakeholders and regulators where big data typically increases the scope and depth of available data.
Content Analytics Enables businesses to gain insight and understanding from their structured and unstructured content (also referred to as textual data). A large percentage of the information in a company is maintained as unstructured content, such as documents, blobs of text in database, wikis, etc.
Planning &
Forecasting Enables faster and more efficient development of plans, budgets and forecasts by creating, comparing and evaluating business scenarios.
Transformation and Connectivity - The transformation and connectivity component enables secure connections to enterprise systems with the ability to filter, aggregate, modify or reformat data as needed. Data transformation is often required when data doesn’t fit enterprise applications. Key
Enterprise Network
Within enterprise networks, enterprises typically host a number of applications that deliver critical business solutions along with supporting infrastructure like data storage. Typically, applications will have sources of data that are extracted and integrated with services provided by the cloud provider. Analysis is performed in the cloud computing environment with output consumed by on-premises applications. Any data from enterprise applications can be sent to enterprise or departmental systems of record represented by the enterprise data components. Systems of record data have generally been matured over time and are highly trusted. It remains a primary element in reporting and predictive analytics solutions. Systems of record data sources include transactional data about or from business interactions that adhere to a sequence or related processes (financial or logistical). This data
can come from reference data, master data repositories, and application data used by or produced by business solutions functionally or operationally. Typically the data has been improved or augmented to add value and drive insight. Enterprise data may in turn be input into the analysis process through data integration or directly to the data repositories as appropriate.
Enterprise Data - Enterprise data includes metadata about the data as well as systems of record for enterprise applications. Enterprise data may flow directly to data integration or the data repositories providing a feedback loop in the analytical system. Enterprise data includes:
Reference Data Provide context about collected data. Master Data
Repositories These repositories can be updated with the output of analytics, to assist with subsequent data transformation, enrichment and correlation. They can host analytics and feed other analytics models when they execute.
Transactional Data about or from business interactions that adhere to a sequence or related processes (financial or logistical). This data can come from reference data, master data repositories, and distributed data storage.
Application Data used by or produced by business solutions functionally or operationally. Typically the data has been improved or augmented to add value and drive insight. This data can come from enterprise applications running in the enterprise.
Enterprise Security
Connectivity Monitors usage and secures results as information is transferred to and from the cloud provider services domain into the enterprise network to enterprise applications and enterprise data. Works with security capabilities and enterprise user directory. Transformations Transforms data between analytical systems and enterprise systems. Data is improved
and augmented as it moves through the processing chain. Enterprise Data
Connectivity Provides ability for analytics system components to connect securely to enterprise data. API Management Publishes, catalogues and updates APIs in a wide variety of deployment environments.
Developers and end users need to rapidly assemble solutions therefore discovery and reuse of existing data, analytics and services is a fundamental requirement.
Log Data Data aggregated from log files for enterprise applications, systems, infrastructure, security, governance, etc.
Enterprise Content
Data Data to support any enterprise applications.
Historical Data Data from past analytics and enterprise applications and systems.
Enterprise User Directory – Provides storage for and access to user information to support
authentication, authorization, or profile data. The security services and edge services use this to drive access to the enterprise network, enterprise services, or enterprise specific cloud provider services.
Enterprise Applications - Enterprise applications can consume cloud provider data and analytics to produce results that address business goals and objectives. Time to value and agility are primary drivers that draw organizations to a cloud solution. Distributed applications are assembled using APIs that promote reuse of existing services rather than writing custom code. Continuous delivery of
improvements, bug fixes and features are fundamental cloud advantages. Upgrades can be applied across a system in minutes instead of days or weeks. Applications include:
Customer Experience Customer-facing cloud systems can be a primary system of engagement that drives new business and helps service existing clients with lower initial cost.
New Business Models Alternative business models that focus on low cost, fast response and great interactions are all examples of opportunities driven by cloud solutions.
Financial Performance The office of finance should become more efficient as data is consolidated and reported faster and easier than in the past.
Risk Having more data available across a wider domain
means that risk analytics are more effective. Elastic resource management means more processing power is available in times of heightened threat.
IT Economics IT operations are streamlined as capital expenditures are reduced while performance and features are improved by cloud deployments.
Operations and Fraud Cloud solutions can provide faster access to more data allowing for more accurate analytics that flag suspicious activity and offer remediation in a timely manner.
Security
The lifecycle of big data from raw input sources to valuable insights and sharing of data among many users and application components requires rigorous security consideration at each step. Security services enable identity and access management, protection of data and applications as well as
providing actionable security intelligence across cloud and enterprise environments. It uses the catalog to understand the location and classification of the data it is protecting.
Identity and Access Management
Enables authentication and authorization (access management) as well as privileged identity management. Access management ensures each user is authenticated and has the right access to the environment to perform their task based on their role (i.e. data analysts, data scientists, business users, solution architects). Capabilities should include granular access control (giving users more precision for sharing data) and single sign on facility across big data sources and repositories, data integration, data transformation and analytics components. Privileged identity management capabilities protects, automates and audits the use of privileged identities to help protect from abuse of roles which have enhanced access rights, to thwart insider threats and improve security across the extended enterprise, including cloud environments. This capability generally uses an enterprise user directory.
Data and Application protection
Enables and supports data encryption, infrastructure and network protection, application security, data activity monitoring, and data provenance where:
• Data encryption supports the ability to secure the data interchange between components to achieve confidentiality and integrity with robust encryption of data at rest as well as data in transit.
• Infrastructure / Network protection supports the ability to monitor the traffic and communication between the different nodes (like distributed analytical processing nodes) as well as prevent man-in-the-middle, DoS attacks. This will also alert on the presence of any bad actors/nodes in the environment.
• Application security supports security as part of the development, delivery and execution of application components including tools to secure and scan applications as part of the application development lifecycle. This component helps eliminate security vulnerabilities from components that access critical data before they are deployed into production. • Data activity monitoring supports tracking all queries submitted and maintaining an audit
trail for all queries run by a job. The component will provide reports on sensitive data access to understand who is accessing which objects in the data sources.
• Data provenance provides traceability of origin, ownership and accuracy of the data and complements audit logs for compliance requirements.
Security
Intelligence Enables security information event management, protection of Personally Identifiable Information (PII or privacy), audit and compliance support that provides comprehensive visibility and actionable intelligence that can help detect and defend against threats through analysis of events and logs and correlation. High risk threats detected can be integrated with enterprise incident management processes. This component enables audit capability to show that the analytics delivered by the big data platform sufficiently protects PII and delivers anonymity as well as enabling automated regulatory compliance reporting.
Information Governance
Information governance provides the policies and capabilities that enable the analytics environment to move, manage and govern data. It has management interfaces to enable the business team to control and operate the processes that manage data. It provides protection classification and rules for managing and monitoring access, masking and encryption. It also provides workflow for coordinating changes to the data repositories, catalog, data and supporting infrastructure between different teams.
Cloud governance aims to reduce redundancies, improve flow and ultimately improve compliance by offering a wide range of services that minimally impact the underlying business processes. Similarly,
security systems aim to limit threats and provide a wider variety of information to only the people who are authorized to use it.
The Complete Picture
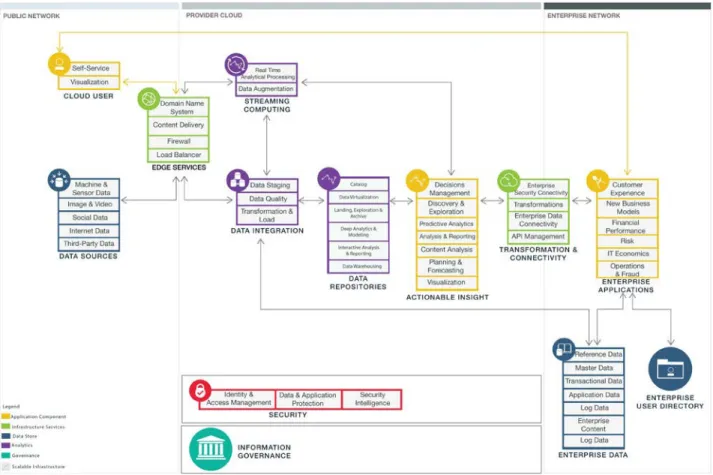
Figure 3provides a more detailed architectural view of components, subcomponents and relationships for a cloud-based analytics solution that provides historical analysis of an organization’s data.
Runtime Flow
Figure 4 illustrates the flow of a typical use case for Fraud and Identity Theft analytics applications.
Figure 4: Flow for Fraud and Identity Theft
In this example, a compliance and security analyst is looking to investigate fraud and identity theft threats related to banking operations. Yellow flows show the interactions of the compliance officers while blue flows show the flow of data across the analytical system.
Basic information flow includes:
1. Enterprise compliance officers customize and configure the analytical processing system on the cloud provider to look at banking transaction data from the enterprise as well as social media feeds from the public network to look for identity theft and correlate financial activity.
Edge services use security capabilities and enterprise user directories to validate third party and enterprise users and secure provider cloud access according to governance policy.
2. Data flows from public data sources like social media through edge services which route the data to the data integration components in the provider cloud.
applications, client name and address changes along with financial information from related institutions. Social media feeds are harvested for current location and activities. Collected and correlated data is enriched with directory information stored on premises to associate bank account information to past, current and new customers. Enterprise data stores are augmented with summary data as required by dependent applications.
4. Credit card transactions are forwarded directly to streaming computing components. In some cases, correlation of streaming data with other information is used to flag outliers and other potential threats. For example, client names need to be enriched with last known location (perhaps from social media) to provide alerts about the same customer being in more than one place at one time.
5. Incoming data from structured and streaming sources, along with related streaming analytics, are cached in the landing, exploration and archive component within data repositories. Other data is largely historical in nature. It requires complex, multi-pass machine learning algorithms to detect and flag unusual behavior. One example is entity analytics which seeks to distinguish clients with the same name and alternatively highlight people with different web identifiers, like email addresses and user names that actually represent the same individual.
6. Data that is flagged for further investigation is investigated by a case management team that run ad hoc analytics against new and historic data to find outliers and other abnormal behaviour. The result of this analysis is ultimately fed back into the process and enterprise applications to capture subsequent instances of fraud.
7. After data has been collected, cleansed, transformed and stored it is communicated to
enterprise applications which help stakeholders make decisions. These enterprise applications can be delivered via SaaS requiring only data repositories to be changed to address a given reporting problem.
Decision management applications are used to determine whether a case should be opened for further investigation and action by the Fraud and Identity Theft team. The predictive analytics applications are used to classify incoming transactions against an established profile and flag potential outliers that represent identity theft threats. Analysis and reporting applications are used to provide dashboards that depict threat volume and severity. Risk analytics measure threats to the business arising from high profile threats including executive identity theft and brand fraud.
Relevant data from the data repositories (landing, exploration and archive in our case) and the cloud provider’s applications is then extracted via the transformation and connectivity layer to enhance client-specific threats, provide regulatory information about the steps taken to improve overall identity protection for customers and the business.
8. At the ‘end’ of the analytical process, enterprise users, such as compliance officers, use visualizations and interactive tools to provide alternative views of data and analytics. They promote better understanding of results by showing important areas of interest, highlighting outliers, offering innovative ways to refine and filter complex data, and by encouraging deeper exploration and discovery.
Sometimes applications and related data may be made available to third party users who would access the enterprise applications via edge services which, in turn, collaborate with security services and the enterprise user directory.
Cloud architecture makes this type of solution easier to implement and maintain. As demand increases, more resources must be acquired. The introduction of ‘feedback loops’ to introduce new analytics is made easier by cloud APIs that formalize the interactions between components. Continuous flow of data and updating of applications means that users can get the latest upgrades faster and easier.
Deployment Considerations
Cloud environments offer tremendous flexibility with less concern for how components are physically connected. The need for advanced planning is reduced but still important. This section offers
suggestions for better provisioning of data and computing resources.
Initial Criteria • Elasticity
• CPU and Computation
• Data Volume
• Data Bandwidth
• Information Governance and Security
No single cloud environment optimizes all these criteria. A little advanced planning goes a long way towards ensuring user satisfaction – and it helps keep costs in line with expectations.
Elasticity Elasticity is the ability for a cloud solution to provision and de-provision computing resources on demand as workloads change. Public clouds have a distinct advantage since they generally have larger pools of resources available. You also benefit by only paying for what you use. Private clouds and dedicated hardware can makeup some of the difference with higher bandwidth data paths.
CPU and
Computation The availability of inexpensive commodity processors means the private and hybrid cloud server farms are more viable than in the past. Modern development environments using Hadoop, Spark and Jupyter (iPython) take advantage of these massively parallel systems. Streams and high speed analytics are an emerging area where cloud applications leverage more powerful processor pools to enable real-time, in-motion data solutions. Dedicated hardware allows for faster development and testing prior to migration towards hybrid and public environments.
Data Volume All data loses relevance over time. Data retention requires a little experimentation unless specifically governed by regulatory or other policies. Public clouds offer the flexibility to store varying amounts of data with no advance provisioning. In-house cloud storage solutions can offer long term storage cost advantages when volume is predicted in advance.
Data Bandwidth Public and private clouds need to be optimized for big data. Large cloud data sets requiring fast access benefit from processing components with fast and efficient data access. In many cases, this means moving the processor to data, or vice versa. Cloud systems can effectively hide the physical location of data and analytics. Tuning activities can be carried
out continuously with minimal impact on deployed applications. Information
Governance and Security
As more data about people, financial transactions and operational decisions is collected, refined and stored, the challenges related to information governance and security increase.
Information governance policies must encompass a wider domain of data and ultimately deal with the results of related analytics that create sensitive data from inputs that are not themselves subject to safeguards. The simple fact that more people have access to data calls for better monitoring and compliance strategies. The cloud generally allows for faster deployment of new compliance and monitoring tools that encourage agile policy and compliance frameworks.
Cloud data hubs can be a good option by acting as focal points for data assembly and distribution. Tools that monitor activity and data access can actually make cloud systems more secure than standalone systems. Hybrid systems offer unique application
governance features: software can be centrally maintained in a distributed environment with data stored in-house to meet jurisdictional policies.
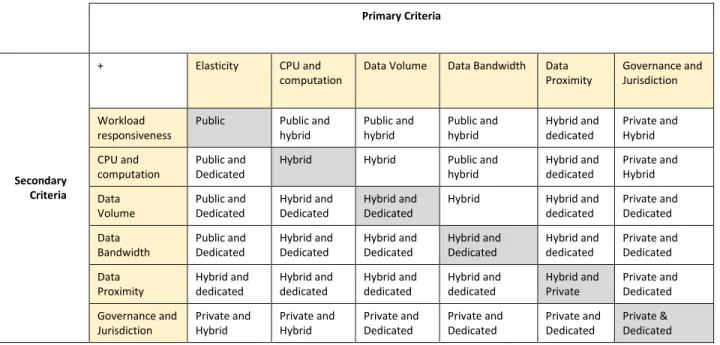
Optimized
Provisioning Optimized cloud provisioning can help you select the right product family for a given set of usage criteria. Figure 5 shows typical scenarios in a worksheet format that balances trade-offs between architectures. Primary criteria drive the initial architectural choice. One or more secondary criteria will tend to move the selection needle between public and private topologies.
Primary Criteria
Secondary Criteria
+ Elasticity CPU and
computation Data Volume Data Bandwidth Data Proximity Governance and Jurisdiction Workload
responsiveness Public Public and hybrid Public and hybrid Public and hybrid Hybrid and dedicated Private and Hybrid CPU and
computation Public and Dedicated Hybrid Hybrid Public and hybrid Hybrid and dedicated Private and Hybrid Data
Volume Public and Dedicated Hybrid and Dedicated Hybrid and Dedicated Hybrid Hybrid and dedicated Private and Dedicated Data
Bandwidth Public and Dedicated Hybrid and Dedicated Hybrid and Dedicated Hybrid and Dedicated Hybrid and dedicated Private and Dedicated Data
Proximity Hybrid and dedicated Hybrid and dedicated Hybrid and dedicated Hybrid and dedicated Hybrid and Private Private and Dedicated Governance and
Jurisdiction Private and Hybrid Private and Hybrid Private and Dedicated Private and Dedicated Private and Dedicated Private & Dedicated Figure 5: Optimized Provisioning Worksheet
Public clouds are a popular choice for initial efforts. They are not the most common choice for
enterprise customers. Lower bandwidth, less powerful compute environments, along with governance and compliance concerns can limit the appeal of the traditional public cloud.
The Hybrid Cloud
An enterprise routinely needs a combination of public and on-premises components that when linked, create a hybrid cloud. There are several different definitions of what constitutes a hybrid cloud. Generally speaking, it will have two or more cloud implementations with different capabilities, user interfaces and control mechanisms.
Typical examples include premises implementations, different public clouds, public cloud and on-premises implementations, etc.
Businesses implementing hybrid clouds are looking for flexibility and agility in delivering new capabilities.
A few examples include: Integrating social/mobile
with core business systems Many organizations are using public cloud services to build social and mobile applications and improve the user experience. The data sources for these applications range from large social media datasets to low latency updates based on social messaging. Linking these mobile and social systems (systems of engagement) to core business systems (systems of record) can provide greater customer insight and value. Organizations are using application programming interfaces (APIs) to provide access to traditional systems and data in a form that is easier to use with social and mobile applications. Backup location for disaster
recovery Customers typically use a private cloud and switch to a public cloud in the event of a disaster to recover files. Applications and data are duplicated and synced in the public cloud. Large datasets are kept up-to-date with a mixture of continuous data transfer and smart analysis of content that minimizes bandwidth usage.
Hybrid Cloud Management
Although there are many features that make hybrid clouds appealing there are implementation challenges. One challenge is that by their very nature, hybrid cloud implementations involve different products and platforms. Each platform has its own way of doing things, including but not limited to tasks, such as:
• Configuring sets of resources, such as setting up networks or IP address pools
• Deploying new resources, such as creating a new virtual machine
• Monitoring the status of resources
• Starting and stopping virtual machines
It is difficult, even for trained administrators who work with the platforms on a daily basis, to handle the different interfaces and different capabilities. Productivity and quality both suffer as they shift from product to product and are forced to change their perspectives.
The challenge is even greater for casual users, ones who only occasionally need to perform routine tasks, such as restarting their application systems. Expecting them to master a variety of tools for different platforms is unreasonable.
The solution is to provide “unified single pane of glass management” across the various clouds that are linked in a hybrid manner. A common, integrated administration and systems management tool that works across platforms is needed, as well as easily deployed patterns of expertise that can be used on the various cloud sites.
Acknowledgements
Major contributors to this whitepaper are: Tracie Berardi (OMG), Mandy Chessell (IBM), Manav Gupta (IBM), Anshu Kak (IBM), Heather Kreger (IBM), and Craig Statchuk (IBM) and Karolyn Schalk (Garden of The Intellect LLC).
© 2015 Cloud Standards Customer Council.
All rights reserved. You may download, store, display on your computer, view, print, and link to the
Customer Cloud Architecture for Big Data and Analytics white paper at the Cloud Standards Customer Council Web site subject to the following: (a) the document may be used solely for your personal, informational, non-commercial use; (b) the document may not be modified or altered in any way; (c) the document may not be redistributed; and (d) the trademark, copyright or other notices may not be removed. You may quote portions of the document as permitted by the Fair Use provisions of the United States Copyright Act, provided that you attribute the portions to the Cloud Standards Customer Council Customer Cloud Architecture for Big Data and Analytics (2015)