LEARNING TO RANK FROM IMPLICIT
FEEDBACK
A Dissertation
Presented to the Faculty of the Graduate School of Cornell University
in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy
by
Filip Andrzej Radli ´nski August 2008
c
2008 Filip Andrzej Radli ´nski ALL RIGHTS RESERVED
LEARNING TO RANK FROM IMPLICIT FEEDBACK Filip Andrzej Radli ´nski, Ph.D.
Cornell University 2008
Whenever access to information is mediated by a computer, we can easily record how users respond to the information with which they are presented. These normal interactions between users and information systems areimplicit feedback. The key question we address is – how can we use implicit feedback to automati-cally improve interactive information systems, such as desktop search and Web search?
Contrasting with data collected from external experts, which is assumed as input in most previous research on optimizing interactive information systems, implicit feedback gives more accurate and up-to-date data about the needs of actual users. While another alternative is to ask users for feedback directly, implicit feedback collects data from all users, and does not require them to change how they interact with information systems. What makes learning from implicit feedback challenging, is that the behavior of people using interactive information systems is strongly biased in several ways. These biases can obscure the useful information present, and make standard machine learning approaches less effective.
This thesis shows that implicit feedback provides a tremendous amount of practical information for learning to rank, making four key contributions. First, we demonstrate that query reformulations can be interpreted to provide relevance information about documents that are presented to users. Second, we describe an experiment design that provably avoids presentation bias, which
is otherwise present when recording implicit feedback. Third, we present a Bayesian method for collecting more useful implicit feedback for learning to rank, by actively selecting rankings to show in anticipation of user responses. Fourth, we show how to learn rankings that resolve query ambiguity using multi-armed bandits. Taken together, these contributions reinforce the value of implicit feedback, and present new ways it can be exploited.
BIOGRAPHICAL SKETCH
Filip Radli ´nski was born in Warsaw, Poland. He grew up in Canberra, Australia, where he immigrated at a young age. He completed his Bachelor of Science with Honours degree at the Australian National University in Canberra, Australia in 2002. During his Bachelor’s degree, he spent a year as an international exchange student at the Pennsylvania State University in State College, Pennsylvania, United States. He received a Master of Science degree from Cornell University in Ithaca, New York, United States in 2006.
His awards include a university medal received from the Australian National University in 2002, a Fulbright Fellowship in 2002, a best student paper award at the ACM Conference on Knowledge Discovery and Data Mining in 2005 and a Microsoft Research Fellowship in 2006.
ACKNOWLEDGMENTS
I would like to thank my advisor, Thorsten Joachims, for his invaluable guid-ance, for always making time to talk, and encouraging me to tackle challenging problems. Many of the ideas explored in this thesis are the result of discussions with him. I also owe special thanks to Robert Kleinberg for his advice, always insightful observations, and his careful reading of this thesis.
I also thank all my other collaborators and co-authors, especially Susan Dumais, Vincent Crespi and Eric Loken. I have learned a lot working with them. I am also grateful to Simeon Warner, Paul Ginsparg and Paul Houle for providing me access to data, and support in running the search systems upon which much of the evaluation in this thesis rests.
I express my gratitude to the other faculty members of the department of Computer Science at Cornell University, in particular to Rich Caruana, Johannes Gehrke, Joe Halpern, Dan Huttenlocher and Dexter Kozen, for their support and advice. I also thank the administrative staff and particularly Becky Stewart, Stephanie Meik and Melissa Totman for their help whenever it was needed.
I extend special thanks to my friends and fellow graduate students nearest my research area, Eric Breck, Tom Finley, Art Munson, Alex Niculescu-Mizil and Yisong Yue. They were constant sounding boards for ideas, enormously helpful when learning new concepts, and always ready to distract me from too much work when necessary.
I am very grateful to Megan Owen for her wonderful friendship, encour-agement and many kind words. I also thank Sam Arbesman, Jill Chavez, Siggi Cherem, Lauren Childs, Steve Chong, Yashoda Dadkar, Russell de Vries, David Hellier, Katy Munson, Nate Nystrom, Matt Schultz, Daria Sorokina, Kevin Walsh as well as many of the other graduate students at Cornell University, for being
great friends throughout. I thank the Computer Science and Friends ice hockey team for getting me away from my work.
I thank my family for instilling in me a passion for research, for their continual support and for their unending patience. Above all, my warm thanks to my mother, Emilka, Basia and Campbell.
Finally, I would like to acknowledge that financial support for the work presented in this thesis came from a Fulbright Fellowship, a Microsoft Research Graduate Student Fellowship, NSF CAREER Award IIS-0237381, the KD-D grant, a research gift from Google, Inc, and the Department of Computer Science at Cornell University.
TABLE OF CONTENTS
Biographical Sketch . . . iii
Dedication . . . iv
Acknowledgments . . . v
Table of Contents . . . vii
List of Tables . . . x
List of Figures . . . xi
List of Definitions . . . xiii
List of Algorithms . . . xiv
1 Introduction 1 1.1 Overview . . . 1
1.2 Obtaining Relevance Information . . . 4
1.3 Relevance Judgments from Users . . . 8
1.3.1 Explicit Feedback . . . 8
1.3.2 Implicit Absolute Feedback . . . 9
1.3.3 Implicit Preference Feedback . . . 11
1.3.4 Preferences from Query Chains . . . 12
1.4 Clicks, Bias, Diversity and Noise . . . 14
1.5 Presentation Bias and Learning Convergence . . . 16
1.6 Combatting Evaluation Bias . . . 17
1.7 Addressing User Diversity . . . 19
1.8 Bibliographic Notes . . . 21
2 Understanding and Interpreting Users’ Decisions 23 2.1 Offline Decision Making . . . 23
2.1.1 What influences user decisions? . . . 24
2.1.2 Are decisions absolute or relative? . . . 25
2.2 Online Decision Making . . . 25
2.2.1 What can we observe of online user behavior? . . . 26
2.2.2 Which search results do users consider? . . . 27
2.2.3 Which results do users consider before clicking? . . . 29
2.2.4 How can we infer judgments from clicks? . . . 30
2.2.5 Implicit Feedback as Relative Relevance Judgments . . . . 33
2.2.6 Are these judgments valid? . . . 35
2.3 Summary . . . 37
3 Learning to Rank 38 3.1 Performance Metrics . . . 38
3.1.1 Precision and Recall . . . 38
3.1.2 Ranking Based Metrics . . . 40
3.1.3 Performance with Relative Judgments . . . 42
3.2 Algorithms for Learning to Rank . . . 46
3.2.1 Ranking as a Classification Problem . . . 46
3.2.2 Ranking as Ordinal Regression . . . 48
3.2.3 Ranking as Regression . . . 49
3.2.4 Learning to Rank with Pairwise Data . . . 49
3.2.5 Learning from Entire Rankings . . . 51
3.3 Two Particular Learning to Rank Algorithms . . . 52
3.3.1 Ranking SVMs . . . 53
3.3.2 Tournament Participant Ranking . . . 55
3.4 Summary . . . 57
4 Learning from Implicit Feedback Encoded in Query Chains 58 4.1 Introduction . . . 58
4.2 Related Work . . . 60
4.3 Analysis of User Behavior . . . 62
4.4 Implicit Feedback Strategies . . . 64
4.5 Detecting Query Chains . . . 68
4.6 Accuracy of the Feedback Strategies . . . 71
4.7 Learning Ranking Functions . . . 74
4.7.1 Ranking SVMs . . . 75
4.7.2 Retrieval Function Model . . . 76
4.8 Adding Prior Knowledge . . . 79
4.9 Evaluation . . . 81
4.9.1 Interleaved Evaluation . . . 83
4.9.2 Results and Discussion . . . 84
4.10 Summary . . . 89
5 Avoiding Bias in Implicit Feedback 90 5.1 Introduction . . . 90 5.2 Presentation Bias . . . 93 5.3 Bias-Free Feedback . . . 95 5.4 Theoretical Analysis . . . 98 5.5 Practical Considerations . . . 101 5.6 Learning Convergence . . . 103 5.7 Experimental Results . . . 105
5.7.1 Item Relevance Score . . . 106
5.7.2 Ignored Relevance Score . . . 108
5.7.3 FairPairs Preference Test . . . 109
5.8 Summary . . . 111
6 Active Methods for Optimizing Data Collection 113 6.1 Introduction . . . 113
6.2 Formalizing the Learning Problem . . . 115
6.2.2 Inference . . . 117
6.2.3 Loss Function . . . 120
6.2.4 Estimating the Model Parameters . . . 121
6.3 Exploration Strategies . . . 123
6.4 Evaluation Methodology . . . 127
6.5 Results . . . 129
6.5.1 Synthetic Data . . . 130
6.5.2 TREC Data . . . 133
6.5.3 Controlling for Presentation Loss . . . 140
6.6 Summary . . . 144
7 Optimizing Rankings with Dependent Document Relevances 145 7.1 Introduction . . . 145
7.2 Related Work . . . 147
7.3 Problem Formalization . . . 150
7.4 Learning Algorithms . . . 152
7.4.1 Ranked Explore and Commit . . . 152
7.4.2 Ranked Bandits Algorithm . . . 153
7.5 Theoretical Analysis . . . 156
7.5.1 The Offline Optimization Problem . . . 156
7.5.2 Analysis of Ranked Bandits Algorithm . . . 157
7.5.3 Analysis of Ranked Explore and Commit . . . 161
7.6 Evaluation . . . 163
7.6.1 Performance Without Click Noise . . . 164
7.6.2 Effect of Click Noise . . . 165
7.6.3 Practical Considerations . . . 165
7.7 Summary . . . 168
8 Conclusions and Open Questions 169 8.1 Thesis Conclusions . . . 169
8.2 Open Questions and Future Directions . . . 172
8.2.1 Personalization . . . 172
8.2.2 Malicious Noise . . . 177
8.2.3 Scalability and Generalizability . . . 185
LIST OF TABLES
2.1 Summary of the feedback strategies discussed by Joachims et al. (2005). . . 34 2.2 Accuracy of feedback strategies discussed by Joachims et al. (2005). 36 4.1 Features used to learn to classify query chains. . . 70 4.2 Accuracy of the strategies for generating pairwise preferences
from clicks. . . 72 4.3 Evaluation results on the Cornell University library search engine. 85 4.4 The most common words to appear in queries in the training data,
and the fraction of queries in which they occur. . . 87 4.5 Five most positive and most negative feature weights in the
rank-ing function learned usrank-ing query chains on the Cornell University Library search engine . . . 88 5.1 Results from a user study using the Google search engine
pre-sented by Joachims et al. (2005). . . 94 6.1 Mean Average Precision after 3000 iterations of optimizing
LIST OF FIGURES
1.1 Example of a TREC information need. . . 5 2.1 Percentage of time an abstract was viewed/clicked on depending
on the rank of the result. . . 29 2.2 Mean number of abstracts viewed above and below a clicked link
depending on its rank. . . 30 2.3 Fraction of results looked at, and clicked on, by users presented
with standard and modified Google results. . . 32 3.1 Example interleaving of two rankings. . . 45 3.2 The Glicko update equations (Glickman, 1999). . . 56 4.1 Percentage of time an abstract was viewed/clicked on depending
on the rank of the result. . . 63 4.2 Two example queries and result sets. . . 65 4.3 Strategies used to infer relevance judgments from implicit feedback. 66 4.4 Sample query chain and the feedback that would be generated
using all feedback strategies. . . 68 4.5 Example interleaving of two rankings. . . 83 5.1 Feedback strategies from Chapter 4. . . 91 5.2 Click probability measurements of the Item Relevance Score. . . 107 5.3 Click probability measurements of the Ignored Relevance Score. 108 5.4 Evaluation of the relative relevance of search results returned by
the arXiv search engine. . . 109 5.5 Probability of user clicking only on the bottom result of a pair as
a function of the pair. . . 110 5.6 Probability of user clicking only on the bottom result of a pair as
a function of the pair for all queries generating at least one user click. . . 110 6.1 Example of how we can maintain estimates of the relevance of
documents to a fixed query. . . 116 6.2 The Glicko update equations (Glickman, 1999). . . 122 6.3 Change in loss as a function of the number of pairwise
compar-isons for each exploration strategy on synthetic data. . . 131 6.4 Effect of the weight given to the prior on the final loss, evaluated
on synthetic data. . . 132 6.5 Change in loss as a function of the number of pairwise
compar-isons for each selection algorithm on TREC-10 data. . . 134 6.6 Change in MAP score as a function of the number of pairwise
6.7 Effect of different noise levels in pairwise preferences on final MAP score, evaluated on TREC-10 data. . . 137 6.8 Effect of incorrect assumptions about the noise level in relevance
judgments on final MAP score, evaluated on TREC-10 data using OSL. . . 139 6.9 MAP scores of the mode rankings and the presented rankings,
as a function of number of pairwise comparisons for OSL and RANDOM. . . 141 6.10 MAP scores of the presented ranking after 3,000 pairwise
com-parisons after presenting selected pairs at different ranks. . . 143 6.11 MAP scores of the mode and presented rankings after 3,000
pair-wise comparisons. . . 143 7.1 Example of users and relevant documents for some query. . . 151 7.2 Clickthrough rate of the learned ranking as a function of the
number of times the ranking was presented to users. . . 164 7.3 Effect of noise in clicking behavior on the quality of the learned
ranking. . . 166 7.4 Performance of RBA, REC and two RBA variants. . . 167 8.1 Evaluation of MF, MRV and MS diversity methods on a fixed
query set, as well as on queries taken from users’ Web browser cache. . . 177 8.2 User utility as a function of threshold whenµB = 1andσB = 2.
LIST OF DEFINITIONS 1.1 Implicit Feedback . . . 9 1.2 Clickthrough Data . . . 10 1.3 Query Chain . . . 13 1.4 Presentation Bias . . . 14 1.5 Evaluation Bias . . . 14 1.6 User Diversity . . . 15 1.7 Click Noise . . . 15 3.1 Precision . . . 39 3.2 Recall . . . 39
3.4 Mean Average Precision . . . 41
LIST OF ALGORITHMS
5.1 FairPairs Algorithm. . . 96
6.1 Evaluation simulation for active ranking. . . 129
6.2 Model of user behavior. . . 129
7.1 Ranked Explore and Commit Algorithm. . . 153
CHAPTER 1 INTRODUCTION
1.1
Overview
A tremendous number of interactive information ranking systems are available on the Internet, and on desktop computers everywhere. Web search engines rank Web documents in response to user queries, shopping sites rank products a user may wish to purchase, movie rental sites suggest movies, email clients rank email messages, desktop search applications assist in finding files, and many community websites rank everything from restaurants to photos to romantic matches. In general, the goal of interactive information ranking is to present a ranked list of results ordered such that the highest ranked results are those most related to a query or user profile provided.
The simplest approach of manually constructing a function that produces this ranking is difficult and time consuming, with diminishing returns in terms of improvement with increased effort. One of the main reasons for this is the sheer number of possible functions that could be used to rank results. Selecting the best parameterization, and then picking the best parameter settings, is simply too large a task to solve optimally by hand. This problem is exacerbated when we would like to use the same ranking system to serve many different people with different goals. For instance, the perfect function for ranking Web documents for academic users at Cornell University is not necessarily the same as the perfect one for teenagers in Japan. On a more fine grained level, it may well be the case that the best function for ranking Web documents for one Cornell researcher
is not best for another. In response, the machine learning community started addressing the question of how to optimize ranking functions automatically using machine learning techniques. For example, Cohen et al. (1999), Freund et al. (2003) and Burges et al. (2005), among many others, have addressed this question using a variety of approaches that will be discussed later in this thesis.
All techniques for learning to rank require two essential pieces of information:
training data, which provides examples for the learning algorithm as to what dis-tinguishes good results from poor results, and anerror metricthat the algorithm optimizes relative to this training data. Most previous research in learning to rank has assumed a supervised learning setting where training data is provided by some offline mechanism. Such data is often obtained by paying expert relevance judges to provide it, for instance presenting them with a sequence of recorded search queries and Web documents. The role of the judge is toguessthe users’ intentions based on the query issued, and provide an appropriate graded rele-vance score such asvery relevantorsomewhat relevantfor each document assessed. However, judgments collected from users would be preferable, as they would reflect the users’ true needs, and be much cheaper and faster to collect. With respect to error metrics, most algorithms optimize metrics that aggregate over the judgments made for (query, result) pairs, assessing how well the rankings produced by the learned ranking function agree with the judgments provided by the experts. Again, it would be preferable for error metrics to instead reflect the experiences of interactive information ranking system users.
This thesis extends research in learning to rank with four primary contribu-tions. First, we demonstrate that query reformulation in Web search provides extremely informative relevance information that reflects users’ needs. This
builds upon a technique proposed by Cohen et al. (1999) and Joachims (2002), but collects substantially more relevance judgments. Moreover, these judgments are often also more useful for learning algorithms. Second, we show that the way in which users interact with Web search systems means that standard learning algorithms trained with data collected from user interactions, using previous approaches, will never converge to a fixed ranking. We present a technique for modifying the rankings shown to users in a controlled manner, and show that it provably corrects for this problem. Third, most previous work in learn-ing to rank has not considered that there is a natural tradeoff when learnlearn-ing from user interactions. While in the short run presenting the best known results provides users with the best rankings, in the long run exploration of unknown results may improve average performance. We will demonstrate that by us-ing directed exploration, the rankus-ings learned can improve much more rapidly. Fourth, most previous algorithms for learning to rank optimize error metrics that measure performance with respect to relevance judgments provided by experts. We describe two principled algorithms that instead optimize abandonment, a performance metric that directly reflects desirable user behavior, and present formal performance guarantees.
It is important to note, that although we use ranking for Web search as the canonical interactive information ranking task in the remainder of this thesis, ranking is also a fundamental goal of many other real world applications. Some of these were enumerated in the first paragraph of the introduction. Other appli-cations studied in the research literature range from predicting consumer food preferences (Luaces et al., 2004) to assisting astronomers in devising schedules that optimally use limited telescope time (Branting & Broos, 1997). The machine learning community has also addressed ranking questions as diverse as ranking
people or teams based on the outcome of two-player (Herbrich & Graepel, 2006) or two-team games (Huang et al., 2004), ranking universities by various criteria (Dittrich et al., 1998) and ranking patients by their risk of developing pneumonia (Caruana et al., 1995). In all these settings, user interactions with ranking systems can implicitly provide training data and evaluation opportunities for improving the rankings produced.
Similarly, interpreting user behavior as implicit feedback is not limited to information retrieval settings. Any computer system or mobile computing plat-form can collect implicit feedback from users, be there a small or large number of them. While not addressed in this thesis, implicit feedback could be used in settings as varied as designing better software interfaces or measuring social phenomena.
1.2
Obtaining Relevance Information
The first step for any machine learning task is to obtain training data, to which we can then apply a particular algorithm. We will now consider how such data is usually obtained when we want to learn to rank Web documents.
In an academic setting, the largest public data collection suitable for learning to rank is derived from an annual evaluation run as part of the Text REtrieval Conference (TREC). The purpose of the evaluation is to compare the performance of competing search systems, given particular information needs. An example of the information needs provided in TREC evaluations is shown in Figure 1.1.
Topic Number 503
Title Vikings in Scotland?
Description What hard evidence proves that the Vikings visited or lived in Scotland?
Narrative A document that merely states that the Vikings visited or lived in Scotland is not relevant. A relevant docu-ment must docu-mention the source of the information, such as relics, sagas, runes or other records from those times. Figure 1.1: Example of a TREC information need.
For each information need, each competing system must automatically trans-form the request into a query, and return documents from a fixed document collection. The topnresults returned by any retrieval system taking part in the evaluation are then manually judged for relevance. Human judges rate each selected document as not relevant, relevant or highly relevant (Voorhees, 2004). All documents not ranked in the topnby any competing system are assumed not relevant. The dataset consisting of the information needs, documents and document judgments is then made publicly available.
However, TREC data is not representative of the data necessary for learning to rank in many interactive information ranking settings, including the ranking of Web documents. In particular, rather than a long description of an information need, the input to a Web search system is usually a short query. Yet, translating the TREC approach, the most common way that relevance judgments for training a Web search system are obtained is by providing human experts with (query, document) pairs. The experts then provide graded relevance judgments. The job of an expert is to understand each query he or she is presented with, and consider the possible relevance of the presented document to the information need that likely motivated a user to enter that query. The expert then needs to specify to what extent the document satisfies this inferred information need.
Clearly, this task is difficult and slow, requiring many experts to produce a meaningful amount of training data. For the judgments to be consistent across different experts and a wide variety of queries and documents, the experts must be trained and provided with extensive documentation as well as a detailed relevance scale.
This approach is often used by researchers at large search engine companies. For example Burges et al. (2005) from Microsoft, as well as Jones et al. (2006) from Yahoo!, assume expert labeled data is available. However, there are at least three difficulties present when learning for Web search that are absent in the controlled TREC setting. First, as obtaining judgments is time consuming, judgments can only be obtained for a minute fraction of typical queries and a handful of the billions of documents on the Internet. This brings up the the question of how the documents and queries to judge should be selected, so as to have the largest eventual effect on future users’ search satisfaction. Moreover, as Web users’ needs and the documents available change constantly, how should expert judgments be updated to stay representative of real search tasks?
Second, as the judged queries are usually drawn from those issued by actual users, how is an expert judge to know the intent of the users who entered the queries? This is particularly difficult because, in contrast to TREC, most Web queries are too short to unambiguously identify the users’ information needs. Typical Web queries are only two or three words long (Silverstein et al., 1998; Spink et al., 2001; Zhang & Moffat, 2006). Additionally, many queries have multiple valid meanings, with the “correct” one dependent on the user who issued the query. Canonical examples of ambiguous queries include jaguar
Jordan(which can refer to (i) a basketball player, (ii) sports clothing that bears his brand or (iii) a professor at the University of California, Berkeley) andflash
(which can refer to (i) a photography product, (ii) a popular file format or (iii) a superhero). There is no easy way for a judge to work out the relative importance of each meaning across the population of all users. Even seemingly unambiguous queries can mean different things to different people. For instance, the clearly machine learning querysupport vector machinemight be issued by researchers searching for downloadable software, for a tutorial about the algorithm or for theoretical performance bounds. These different needs are likely to be satisfied by different documents.
Third, different human judges may have different opinions concerning the relevance of a particular document to a particular query, even when the user intent is clear. For instance, one judge may not trust anything printed by a left-leaning newspaper, while another may consider blogs as much less authoritative. For these disagreements not to cause difficulties requires substantial training of judges, and long and detailed definitions of the judgment scale. In particular, it is difficult to trade off between obtaining judgments with sufficient granularity to be useful in practice, and obtaining reproducible judgments. Agreement between different judges providing relevance scores for the same (query, document) pair, usually termedinter-judge agreement, is often less than ideal. Although specific numbers depend on the granularity of judgments, some statistics from real search engine judges were recently provided by Carterette et al. (2008).
While there has been substantial effort in improving expert-labeled collec-tions (for example, Reid (2000) presented a partial overview), the four key con-tributions in this thesis will address an alternative method to circumvent these
difficulties: obtain relevance judgments directly from users, without involving expert human judges.
1.3
Relevance Judgments from Users
Since obtaining relevance judgments from human experts is fraught with diffi-culties, the alternative is to obtain relevance judgments directly from users. We now look at how to get relevance information from users.
1.3.1
Explicit Feedback
One obvious approach to obtaining training data from users is to solicit data by posing users explicit questions: Ask them whether or not specific documents are relevant. While an explicit feedback approach is commonly used when learning to recommend movies, for instance by Crammer and Singer (2001), Herbrich et al. (2000) and Rajaram et al. (2003), Web users are generally not willing to provide such explicit feedback. In particular, as judging documents is onerous, users cannot be expected to provide relevance judgments for each result presented or even each result clicked on in a Web ranking setting. In fact, search engines that attempted to add relevance judgment buttons to search results have not been successful. Moreover, given the option to provide such relevant judgments, malicious users would have much more incentive to provide judgments (promoting Web pages that should not be ranked highly) than regular Web users.
1.3.2
Implicit Absolute Feedback
Instead of explicitly asking users for relevance feedback, we could alternatively tracknormal user interactions with a interactive information ranking system. Consider that, when using an online interface, users usually perform actions as a result of the rankings they are presented with. These actions can be used to implicitly infer relevance judgments. In a movie task, this might be done by observing which movies users search for and then watch or perhaps buy. In the Web search setting, this can be done by extracting implicit relevance feedback from search engine log files, or by recording actions users perform in their Web browsers.
We define implicit feedback as follows:
Definition 1.1. Implicit feedbackis information that can be obtained by analyzing the normal interactions of a user with an online system. These interactions include any input the user provides, the information that is shown to the user in response, and all the user’s online actions in response to being presented with this information.
For example, in a Web search setting, implicit feedback may include the user query, any results clicked on, the timing of the clicks, further input provided by the user to the search system, the choice to no longer use the search system, or even bookmarking or printing a website. Most importantly, implicit feedback reflects the judgments of all the users of the search engine rather than a select group of paid judges. In addition, due to the scale at which search engines operate, this usually provides as much data as can be practically exploited, and does so at almost no cost.
Implicit feedback that simply records clicks on Web search results (also com-monly calledclickthrough data) is most easily observed by Web retrieval systems. Search engines typically collect clickthrough data by incorporating a redirect into all links on the results page presented to users1. While a number of researchers, including Kelly and Teevan (2003), Fox et al. (2005) and White et al. (2005), have considered data describing from other behavioral cues, such as bookmarking or scrolling behavior, we focus on clickthrough data. In particular, it effectively captures user intent while being most easily collected.
Definition 1.2. Clickthrough data is implicit feedback obtained by recording the queries users run on a search engine as well as the results they click on.
The interpretation of clickthrough data as relevance judgments that would most closely mirror relevance judgments collected from experts is in terms of absolute statements about the relevance of particular documents to particular queries. Indeed, early work in learning to rank took such an approach, for instance by Wong et al. (1988) and Bartell et al. (1994). Many researchers followed in this interpretation of absolute relevance judgments implicitly collected from clickthrough data, including Boyan et al. (1996); Cohen et al. (1999); Kemp and Ramamohanarao (2002); Cui et al. (2002); Tan et al. (2004); Dou et al. (2007). Such work usually assumes that documents clicked on in search results are highly likely to be relevant. For example, Kemp and Ramamohanarao (2002) assume results clicked on are relevant to the query and append the query to these documents to make them more likely to be ranked highly in the future. Similarly, Dou et al. (2007) propose reordering search results based on the frequency with which returned results are clicked on.
1Alternative methods also exist, for instance using JavaScript event actions or a browser
Yet, as we will see in Chapter 2, a user clicking on a result does not always indicate that the result is relevant. For example, Boyan et al. (1996) constructed three different ranking functions with very different performance, yet saw that the average rank at which users click did not differ meaningfully between the better and worse rankings. Given that the worse ranking functions ranked relevant results lower, we would have expected the rank of the first click to be lower for the poorer ranking functions. One approach to correct for biases in clicking behavior would be to model user clicking behavior and compensate for clicks on non-relevant documents using methods proposed by Dupret et al. (2007) or Carterette and Jones (2007). However, we will see that there is a simpler process by which reliable relevance judgments can be collected: interpreting clicks asrelative relevance judgments.
1.3.3
Implicit Preference Feedback
Cohen et al. (1999) suggested an alternative interpretation of clickthrough data, that instead of inferring absolute judgments from implicit feedback, we can interpret a click as a relative preference. Specifically, they suggested that clicked on documents are likely better than higher ranked documents that were not clicked on. Joachims (2002) formalized and evaluated this idea and found it to work well, learning an improved search engine ranking function specifically for a small number of German machine learning researchers using their clicking behavior.
In fact, Joachims et al. (2005; 2007) demonstrated in a laboratory study that clickthrough data is strongly biased by the position at which results are presented.
They showed that if a search result is moved higher in a presented result set, this immediately increases the expected number of clicks it will receive, even if the result is not relevant to the query. Moreover, if the top ten documents retrieved by a search engine are presented in reverse order, non-relevant documents are clicked more often. This is at odds with an absolute interpretation of implicit feedback, as presentation effects will strongly influence the relevance judgments obtained. On the other hand, their study confirmed that judgments can be validly interpreted as relative statements of the form that one document is more relevant than another based on clicking behavior. We will discuss these studies in depth in Chapter 2.
1.3.4
Preferences from Query Chains
While implicit feedback interpreted as preferences gives rise to reliable relevance judgments that reflect user needs, previous work using this interpretation is still limited in the relevance feedback received. It is commonly known that search engine users predominantly click only on top ranked results. Granka et al. (2004) partially explained this effect through an eye tracking study, observing that most users do not even look at documents below the top few. Now, consider a user who enters a query for which the search engine performs particularly poorly, not retrieving any relevant documents in the top few positions. It is very unlikely that the user will scroll down to a truly relevant document and click on it. Rather, almost all users will either not click, or click on a highly ranked yet irrelevant document. Thus, any learning algorithm would have difficulty learning an improved ranking function, given that the training data is unlikely to provide any preferences identifying relevant documents.
However, many search users willreformulatepoorly performing queries. The first of the four key contributions of this thesis is to study how to generate relevance judgments from implicit feedback collected over sequences of multiple queries reflecting the same information need. Such sequences are termedquery chains.
Definition 1.3. Aquery chainis a sequence of queries issued by a user over a short period of time with a constant information need in mind.
We will show in Chapter 4 that collecting relevance judgments by considering query chains leads to significant improvements in search engine performance. Moreover, the reliability of the relevance judgments obtained from query chains is on par with the reliability of explicit judgments from expert judges.
Outside of a Web search setting, Furnas (1985) first proposed the use of learning from reformulations. In particular, he considered the task of learning new command names on a command line system by recording which commands users tried then reformulated. He interpreted two commands being seen in sequence to mean that the intended result of the first command is the same as the intended result of the second command. Similarly, Cucerzan and Brill (2004) looked at using reformulations to learn spelling corrections for Web queries. However previous work has not considered learning general functions using information inferred from reformulations, instead focussing on learning specific corrections that can be made.
1.4
Clicks, Bias, Diversity and Noise
As this thesis considers using records of user behavior to infer relevance judg-ments, we are limited by the noise and bias that is always present in real world data. The signal in clickthrough data is inherently masked in at least four ways, which must all be considered when relying on data from search engine log files. We now introduce these effects, and will periodically return to them throughout this thesis.
Definition 1.4. Presentation bias is manifested when users preferentially click on higher ranked results, irrespective of relevance.
Presentation bias is usually seen when particular search results move up or down an otherwise fixed ranking, and in consequence receive a vastly different number of clicks. As described in the previous section, one effect of presentation bias is that absolute relevance judgments tend to be difficult to collect from click-through data. While inferring relative relevance judgments from clickclick-through data avoids this difficulty, there is also bias in the preferences that can possibly be collected, as described in Section 1.5 below.
Definition 1.5. Evaluation biasis the bias exhibited by users to preferentially look at and evaluate highly ranked documents. The effect is that clickthrough data obtained from search engine logs predominantly describes the relevance of documents already ranked highly by a search engine.
There is an important albeit subtle distinction between evaluation bias and presentation bias. To see this, consider that it could well be that some users consider only highly ranked results but also only click on documents that are
relevant, thus exhibiting evaluation bias while not exhibiting presentation bias. Evaluation bias is partly combatted by the concept of query chains, as they allow relevance judgments to be collected about documents at low rank for the original query but ranked highly by reformulations. However, we will also present a further method for combatting evaluation bias in Chapter 6.
Definition 1.6. User diversityis the property that different users have different con-cepts of relevance given the same query.
The presence of user diversity was, for instance, shown by Teevan et al. (2005a; 2007). It adds noise to relevance judgments collected from users. In particular, due to user diversity contradicting preferences may be collected for only the reason that the same query (such asjaguar) indicates that one user is looking for information on one topic (such as big cats) while another user is looking for different information (such as computer operating systems).
Finally,Click noiseis present whenever logs of online user behavior are used.
Definition 1.7. Click noiseis noise in clickthrough data caused by users accidentally clicking on search results, or clicking without thinking.
The effect of click noise is to obscure the signal in clickthrough data with random noise. Methods for collecting relevance judgments from clickthrough data need to be robust to the presence of this noise.
1.5
Presentation Bias and Learning Convergence
As seen earlier, presentation bias can be combatted by interpreting user clicks as relative relevance judgments rather than absolute judgments. However, this causes a further difficulty: the only relative statements that can be obtained using the methods proposed by Cohen et al. (1999) and Joachims (2002) are of the form that a lower ranked document is preferred to a higher ranked document. The same applies to preference judgments collected from query chains, as described in Chapter 4. This means that the relevance judgments collected in any dataset always oppose the order in which results are presented to users. In particular, if an original ranking were reversed, all the preferences based on that ranking would be satisfied. The effect (further described in Chapter 5) is that any ranking function trained using such implicit feedback will never converge to a fixed ranking.
The second key contribution of this thesis, presented in Chapter 5, is to describe an algorithm for randomly modifying the results shown to users to compensate for presentation bias. In particular, the algorithm presented is proved, under reasonable assumptions, to allow a learned ranking function to eventually converge to the optimal ranking function.
Previous convergence results of algorithms for learning to rank apply only if training data is assumed to come from distributions that do not suffer from such bias effects. For instance, Cohen et al. (1999) and Freund et al. (2003) assumed preferences are drawn according to a model that does not allow for preferences one way (i.e. opposing the original presentation order order) to be much more likely than preferences the other way. Most other theoretical convergence results
for learning to rank address learning from absolute relevance judgments (for example, Herbrich et al. (2000); Crammer and Singer (2001); Chu and Keerthi (2005)).
1.6
Combatting Evaluation Bias
Although we have now seen that user behavior provides implicit relevance judgments, even after considering query chains, evaluation bias still limits which results are assessed by users. In particular, previous work in learning to rank using clickthrough data has only considered clickthrough data that is collected anyway. Specifically, it assumes that when collecting clickthrough data, users are simply presented with the documents as ranked by the current ranking function. As such, these documents are shown without regard for what data may be collected or how this data may impact the rankings presented in the future. However, Granka et al. (2004) showed that users very rarely even look at results beyond the top few. Hence the data obtained by restricting the rankings shown to those generated by a pre-existing ranking function is strongly biased toward results already ranked highly. This means that highly relevant documents that are not initially ranked highly, due to the ranking function being suboptimal, may very rarely be observed and evaluated. This can lead to the learned ranking converging to an optimal ranking only very slowly.
To avoid evaluation bias, the third key contribution of this thesis is to propose a method to select the rankings presented to users. We show that this method obtains more useful training data, while also presenting high quality rankings. As an illustration, a na¨ıve possibility for obtaining more useful training data and
guarantee eventual convergence to an optimal ranking would be to intentionally present unevaluated results in the top few positions of rankings, aiming to collect more feedback about them. However, such an ad-hoc approach is unlikely to be useful in the long run due to the sheer number of documents in a typical collection (for instance, the Web consists of at least tens of billions of documents), and will likely strongly hurt user satisfaction. In Chapter 6, we will introduce a principled approach to modify the rankings presented to users such that ranking quality improves quickly while limiting any temporary reduction in quality as new documents are explored. In particular, this approach consists of maintaining a probability distribution over document relevance. This contrasts it with other probabilistic approaches for ranking that estimate document relevance while not explicitly modeling uncertainty (for example, (Chu & Ghahramani, 2005c)).
Given uncertainty information, it is possible to compute the probability of any particular ranking being optimal, and also compute what the loss from presenting a different, suboptimal, ranking would be. By integrating over all possible rankings, we will show how to compute the expected loss of any given ranking. The algorithm will then select rankings to show such that this expected loss is minimized, given the implicit feedback we expect to collect from users. In particular, minimizing such a user-centric loss contrasts with previous ap-proaches extending probabilistic models to actively select pairs of documents to evaluate. While Chu and Ghahramani (2005a) previously chose to ask for labels over pairs of documents where the entropy of the predicted outcome of a comparison would decrease most, the approach we present minimizes a user-centric loss measure. By minimizing the future expected loss as a function of the training data that is likely to be collected, we will show that the quality of
the ranking presented can improve much more rapidly than na¨ıvely presenting documents in terms of decreasing estimated relevance.
1.7
Addressing User Diversity
Until now, this introduction has presented training data collection for Web search in terms of the relevance of individual documents, either as absolute or relative (pairwise) judgments. This implicitly assumes that each document has some real valued relevance to a particular query. As such, with a complete set of relevance scores, should it be possible to collect them for all documents, it would be sufficient to rank the documents by these scores. More formally, given judgments assessing the relevance of documents to a query, the standard approach is to learn the parameters of a scoring function. Given a new query, this function can be called upon to compute the score for each documentindependently, and rank documents by decreasing score.
The theoretical model that justifies ranking documents in this way is the probabilistic ranking principle (Robertson, 1977). It suggests that documents should be ranked independently by their probability of relevance to the query. However, the optimality of this process relies on the assumption that there are no statistical dependencies between the probabilities of relevance among documents – an assumption that is clearly violated in practice. For example, if one document about jaguar cars is not relevant to a user who issues the queryjaguar, other car pages are also now less likely to be relevant. As users are often satisfied with finding a small number of, or even just one, relevant document, the usefulness and relevance of a document does depend on other documents ranked higher.
In fact most search engines today attempt to eliminate redundant results and producediverserankings that include documents that are potentially relevant to the query for different reasons.
Most previous work in obtaining diverse rankings suggests to diversify the top ranked documents given a non-diverse ranking. Perhaps the most common technique is Maximal Marginal Relevance (MMR), proposed by Carbonell and Goldstein (1998). Given a similarity (relevance) measure between a document and a query, as well as a similarity measure between two documents, MMR iteratively selects the most relevant documents that are also least similar to any other documents already selected. As such, MMR requires the relevance of a document to a query and the similarity of two documents to be known. It is usual to obtain these using standard algorithms for learning to rank, which will be discussed in Chapter 3. The goal of MMR is torerank an already learned ranking to improve diversity.
In contrast, the fourth key contribution of this thesis is to present an algorithm that learns rankings that directly maximize a proxy for the fraction of users who find at least one relevant search result. This algorithm produces a diverse ranking of results in a principled and provably optimal manner. Specifically, the Ranked Bandits Algorithm that we present in Chapter 7 obtains the best achievable polynomial time approximation to maximizing the fraction of users who click on at least one search result. In addition, the algorithm does not assume a relevance or document similarity measure is known or provided a priori, instead learning directly what ranking of documents is best to present.
It is also worth noting that implicit feedback is particularly useful when learn-ing to produce diverse ranklearn-ings in a principled manner. Learnlearn-ing to produce
optimally diverse rankings using expert judgments would require a document collection with document relevance obtained for all possible meanings of a query. While the TREC interactive track2provides some documents labeled in this way for a small number of queries, such document collections are even more difficult to create than standard expert labeled collections. Moreover, the judgments would need to establish the relative importance of the different meanings of each query to optimally satisfy the user population.
1.8
Bibliographic Notes
The research presented in this thesis was performed and subsequently pub-lished jointly with Professor Thorsten Joachims and partly jointly with Professor Robert Kleinberg at Cornell University. While Chapters 1, 2 and 3 present back-ground material, the key contributions of this thesis have been published as follows. Chapter 4, which presents and evaluates the concept of query chains was published in (Radlinski & Joachims, 2005b). Chapter 5, which presents an algorithm to combat presentation bias, was published in (Radlinski & Joachims, 2006). Chapter 6, which describes an approach to avoid evaluation bias, was published in (Radlinski & Joachims, 2007). Finally, Chapter 7, which addresses user diversity, was published in (Radlinski, Kleinberg and Joachims, 2008b).
During my degree, I have also contributed other research not presented as a chapter in this thesis. In particular, I have published research on personalized Web search (Radlinski & Dumais, 2006), identifying related documents using im-plicit feedback (Pohl, Radlinski and Joachims, 2007), machine learning algorithms
for optimizing ranking performance metrics (Yue, Finley, Radlinski and Joachims, 2007), ranking online advertisements (Radlinski, Broder, Ciccolo, Gabrilovich, Josifovski and Riedel, 2008a), studying the tolerance of learning from implicit feedback to random and malicious noise (Radlinski & Joachims, 2005a; Radlinski, 2007) and studying how high school students prepare for high stakes exams (Loken, Radlinski, Crespi, Cushing and Millet, 2004; Loken, Radlinski, Crespi and Millet, 2005). I also contributed to (Joachims, Granka, Pan, Hembrooke, Radlinski and Gay, 2007). Finally, a less technical overview describing a number of the key ideas in this thesis was published in (Joachims & Radlinski, 2007).
CHAPTER 2
UNDERSTANDING AND INTERPRETING USERS’ DECISIONS
This chapter presents an overview of previous research that considers users’ decision making processes, and how user actions can be interpreted. In particular, we will see how users’ decisions are affected by the way users are presented with choices to make. We start by considering the decisions people make in the offline world, from a marketing and economics perspective, as well as when applied to document relevance judgments. Following this, the majority of this chapter will consider user behavior in a Web search setting, asking a number of questions that will determine how implicit feedback can be interpreted.
2.1
Offline Decision Making
The process by which people make decisions offline has been studied extensively, particularly motivated by marketing applications. For instance, Eliashberg (1980) presented approaches for estimating consumer utility functions and Currim and Sarin (1984) studied job preferences using a related utility formulation. Numer-ous related behavioral models have been proposed, including bounded ratio-nality (Herbert, 1957), aspiration adaptation theory (Selten, 1998) and prospect theory (Tversky & Kahneman, 1981).
2.1.1
What influences user decisions?
Of more direct relevance to this thesis, a number of recent studies have explored factors that impact the reliability of preference choices made by people. Mantell and Kardes (1999) describe how the order in which choices are presented affects the preferences shown. In particular, they found that when comparisons are made between products based on specific attributes, order effects play a larger role than when comparisons are made in terms of overall (attitude-based) eval-uations. Moreover, when comparing pairs of products, Moore (1999) showed that if a superficially attractive option is presented first, consumers are willing to pay more for both options than when the superficially less attractive option is presented first. In addition, Coupey et al. (1998) and Zhang and Markman (2001) studied the effect of familiarity and motivation on preference decisions respectively. They found that the preferences people make are influenced by these factors, suggesting that consumer decision making is indeed a complex process.
In our context of interactive information ranking systems, these studies should be taken as indicative of the complexity of the behavior we will ob-serve from online users. It is unlikely that simple behavioral models will suffice to explain why people express the preferences they express. Rather the studies motivate careful analysis of online user behavior to identify complicating factors, to allow us to find ways to avoid them when collecting implicit feedback. For instance, these studies suggest that the order users are presented with online search results will affect their judgments of the relevance of the results.
2.1.2
Are decisions absolute or relative?
In the context of document relevance judgments, a particularly important ques-tion to ask in the offline world regards which sort of judgments people are able to make most reliably. In particular, when human experts are trained to make judgments about the relevance of documents to queries, what sort of judgments can we expect? Recently, Carterette et al. (2008) studied how relevance judg-ment quality is affected by the specific question asked of expert human judges. The standard approach to obtain relevance judgments from expert judges is for judges to provide a relevance score for each (query, document) pair on a two to six point scale. These relevance scores can then be used to construct a set of relative statements. Carterette et al.compared the relative judgments obtained in this way to those obtained by asking the experts for relative judgments directly. They found that relevance judges tend to agree more with each other when asked to directly provide relative judgments about pairs of documents. Moreover, it took the judges substantially less time to make a relative judgment than it took them to make an absolute judgment on a five point scale. This shows us that people (at least those trained to make relevance judgments) appear to have an easier time providing reliable and consistent relative judgments than absolute judgments.
2.2
Online Decision Making
We can now turn to the question of what decisions regular Web users make when searching for information online, and how we can identify the extent to which
2.2.1
What can we observe of online user behavior?
Given the online medium, the first question we must ask is how much of user behavior can we practically observe? In principle, it is possible to record all user interactions with a Web browser. In particular, Kelly and Teevan (2003) pro-vided a detailed survey of the many user actions that can be observed including browsing, bookmarking, printing, and so forth. Somewhat more recently, White et al. (2005), Fox et al. (2005) and Kellar and Watters (2006) also studied what can be observed of user behavior if users are asked to use specially instrumented Web browsers. Each study addressed a different prediction problem in terms of user satisfaction or user task. However, key to this thesis, to obtain such a complete picture of what users are doing online requires the users to use Web browsers with specific add-ons that record all these interactions. Understandably, a relatively small fraction of real users install such tools, both due to the inconve-nience of additional software installation and due to privacy concerns. Hence, the number of users for whom complete data could be collected is limited.
A simpler alternative is to record the entire stream of network traffic issued by users. For instance Kammenhuber et al. (2006) installed a monitor at the Internet gateway of a major German university, using the data collected to build a model of user behavior. However, this approach requires the cooperation of Internet service providers, with similar privacy concerns and logistical difficulties as when users are asked to install browser add-ons.
However, as we are concerned particularly with interactive information ranking systems, a sufficiently complete picture of user behavior can be obtained by recording the user interactions with just the system of interest. For instance, in
a Web search setting, user queries can be recorded by the search engine directly. If the search results link to addresses on a search engine server, that then redirect users to the actual result pages, we can also observe which search results users click on when they click.
Although we will study in detail what information is provided by logs of queries and clicks, as an example that clicks encode substantial information, consider a recent result obtained by Pohl et al. (2007). In their work, Pohl et al. found that documents in an academic search engine that are co-clicked on by search engine users tend to be co-cited in the future. This suggests that potentially useful information is present in clickthrough logs.
2.2.2
Which search results do users consider?
Before we can interpret user behavior in Web search, we must first establish which results users actually look at and hence can possibly be making judgments about. We do so by drawing on the results of groundbreaking eye tracking studies reported by Granka, Joachims and collaborators (2004; 2005; 2007). In particular, the authors study user behavior on the Google search engine3, considering both what users look at, and what users click on. While other researchers had previously used eye tracking studies to observe how users behave when using a Web browser (for instance, Brumby and Howes (2004)), they did not specifically focus on behavior on the results page of a Web search engine.
In each phase of a two-phase study, Granka et al. recruited undergraduate student volunteers to search for the answers to specific questions, while having
an eye tracker record where on the screen they looked during the process. The subjects were asked to start from the Google search page and find the answers to ten questions. Five of the questions asked were navigational (for example,
“find the homepage of Emeril, the chef who has a television cooking program”) while the other five were informational (for example,“what is the name of the researcher who discovered the first modern antibiotic?”) (Broder, 2002). The questions asked varied in difficulty and topic content. There were no restrictions on what queries the users may choose, how they may continue after entering the first query, or which links to follow. Users were told that the goal of the study was to observe how people search the Web, but were not told of the specific interest in their behavior on the results page of Google. All clicks, the results returned by Google, and the pages connected to the results were recorded by an HTTP proxy. A detailed presentation of the experimental setup is provided by Joachims et al. (2007).
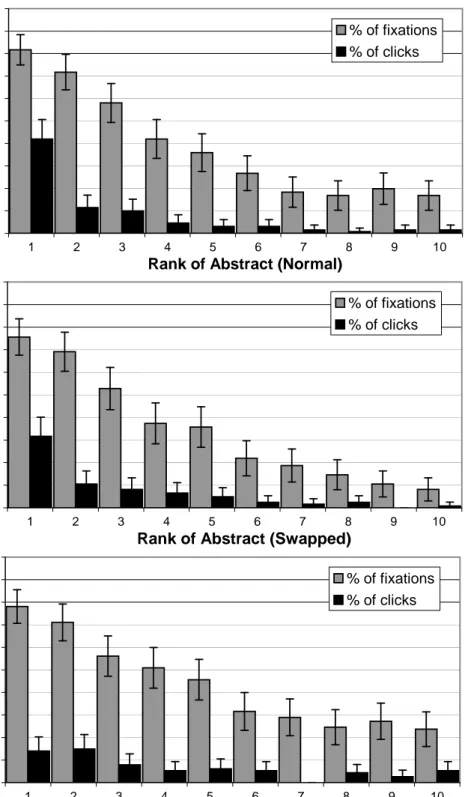
The light bars in Figure 2.1 (Figure 1 from Joachims et al. (2007)) show the percentage of result pages for which users looked at each of the top 10 search result abstracts (the short text that describes each search result) for a query. The dark bars show the fraction of the time that a user’s first click was at a particular rank. The striking result is that while most users looked at least at the top two result abstracts, the fraction of searches after which users even look at lower ranked results decays very rapidly with result rank.
These eye tracking results are consistent with other studies that have also seen that users tend to pay much more attention to top ranked documents in a Web search engine. For instance, Agichtein et al. (2006) presented a summary distribution of the relative click frequency on Web search results for a large commercial search engine as a function of rank for 120,000 searches for 3,500
0 10 20 30 40 50 60 70 80 1 2 3 4 5 6 7 8 9 10 Rank of Abstract P e rc e n ta g e % of fixations % of clicks
Figure 2.1: Percentage of time an abstract was viewed/clicked on depending on the rank of the result (from Joachims et al. (2007)).
distinct queries. They show that the relative number of clicks rapidly drops with the rank – compared with the top ranked result, Agichtein et al.observed approximately 60% as many clicks on the second result, 50% as many clicks on the third, and 30% as many clicks on the fourth.
2.2.3
Which results do users consider before clicking?
Given that the interactions of users with the Web search engine that we record are clicks on search results, we next ask which results have been observed before users click.
Granka et al.found that users in their study considered search results in order from top to bottom. Figure 2.2 (Figure 3 from Joachims et al. (2007)) shows the number of abstracts viewed above and below any result that was clicked on. We see that the lower the rank of the clicked document, the more previous abstracts
the user is likely to have looked at first. While users do not tend to look at all earlier abstracts, this figure suggests that users do generally scan the results in order from top to bottom. We also see that users usually look at one abstract below any they click on. Further analysis by Joachims et al. (2007) showed that this is usually the abstract immediately below the one clicked on. We can conclude that users typically look at most of the results from the first to the one below the last one clicked on.
-2 -1 0 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 9 10 Clicked Link A b s tr a c ts V ie w e d A b o v e /B e lo w
Figure 2.2: Mean number of abstracts viewed above and below a clicked link depending on its rank (from Joachims et al. (2007)).
2.2.4
How can we infer judgments from clicks?
Now that we can infer which results users looked at before clicking, we can ask the question: What affects a user’s decision to click? To study these influences, Joachims et al. evaluated how users’ behavior is affected by the quality of the results shown. In the second phase of the eye tracking study, some users were presented with the original Google results, while some were presented with the
top two Google results swapped, and others were presented with the top ten results in reverse order. None of the users in the study suspected such a change was being made. Figure 2.3 (Figure 4 from Joachims et al. (2007)) shows how these changes affected which results users looked at, and which ones they clicked on. It shows that that reducing the relevance by modifying the order of results impacted how users behaved, both increasing the fraction of users who looked at lower ranked results, and increasing the number of clicks at low rank.
This may lead us hypothesize that users simply click on relevant results, as is assumed by much previous work (for example, by Boyan et al. (1996); Kemp and Ramamohanarao (2002); Fox et al. (2005)). We will now see that users’ decisions to click are more complex. Following the eye tracking study, Joachims et al. asked human evaluators to assess the relative relevance of all the results seen by each study participant. The evaluators were asked to rank all the short text abstracts presented to participants on the Google search results page in terms of relevance to the questions asked of the participants (evaluators were allowed to judge two abstracts as equally relevant). For the documents returned in the second part of the study, the evaluators were also asked to rank the documents linked to by the search results.
If users simply click on relevant documents, unaffected by the presentation order, we would expect that the frequency with which users click on the top two results only depends on the relevance of these results. However, Joachims et al. found a significant change in clicking behavior when the top results were presented in reverse order. They show that two effects are in play: first, atrust biasas users appear to trust that documents presented high by the search engine are most relevant, and second aquality-of-context biaswhere users are more likely
0 10 20 30 40 50 60 70 80 90 100 1 2 3 4 5 6 7 8 9 10
Rank of Abstract (Normal)
P e rc e n ta g e % of fixations % of clicks 0 10 20 30 40 50 60 70 80 90 100 1 2 3 4 5 6 7 8 9 10
Rank of Abstract (Swapped)
P e rc e n ta g e % of fixations % of clicks 0 10 20 30 40 50 60 70 80 90 100 1 2 3 4 5 6 7 8 9 10
Rank of Abstract (Reversed)
P e rc e n ta g e % of fixations % of clicks
Figure 2.3: Fraction of results looked at, and clicked on, by users presented with standard Google results (top), top two results reversed (middle) and all top ten results reversed (bottom) (from Joachims et al. (2007)).
to click on less relevant documents if they are embedded in a poorer quality ranking.
Due to these effects, interpreting clicks as judgments about the relevance of the clicked documents appears difficult. However, Cohen et al. (1999) and Joachims (2002) previously suggested an alternative interpretation of user clicks: asrelativerelevance judgments. Joachims et al. found evidence supporting such an interpretation of clickthrough data in the eye tracking study. We now discuss this approach.
2.2.5
Implicit Feedback as Relative Relevance Judgments
Intuitively, selection of Web search results may be much like the selections people make when purchasing products, where they must select among the available options. Perhaps users choose to click on a search result not because it is relevant, but because it ismore likelyto be relevant than any other option they are aware of. This idea is known as revealed preferences in economics (Samuelson, 1948; Varian, 1992). We now consider how clicking behavior encodes such preferences.
Cohen et al. (1999) and Joachims (2002) proposed an interpretation to click-through data in terms of relative relevance judgments. They hypothesized that when a user clicks on a document, the user is indicating that he or she considers the selected document more relevant than other documents he or she has already considered but not clicked on. Including this strategy, Joachims et al. (2005) dis-cuss five strategies for obtaining relative relevance feedback from users clicking behavior along similar lines. These strategies are summarized in Table 2.1
Table 2.1: Summary of the feedback strategies discussed by Joachims et al. (2005).
Strategy Description
CLICK>SKIPABOVE A clicked-on document is likely more relevant to the query than one presented higher but not clicked on.
LASTCLICK>SKIPABOVE The last clicked-on document is likely more relevant than any documents presented higher but not clicked on.
CLICK>EARLIERCLICK A clicked-on document is likely more relevant than any documents presented higher that were clicked on.
CLICK>SKIPPREVIOUS A clicked-on document is likely more relevant than the preceding document, if that document was not clicked on.
CLICK>NO-CLICKNEXT A clicked-on document is likely more relevant than the next document, if that document was not clicked on.
To illustrate these strategies and the relative relevance judgments they would generate, consider for example a user who submitted queryqand was presented with the ranked results(d1, d2, d3, d4), then clicked ond2 andd4. Note that in
this case, since the user clicked on the fourth result, the results from the eye tracking study suggest that the user probably also considered resultsd1 andd3
despite deciding not to click on them. CLICK>SKIP ABOVE would generate
three preferences:
d2 qd1; d4 qd1; d4 qd3
where di q dj should be taken to mean not thatdi is relevant toq, but rather thatdi is more likelyto be relevant than dj, with respect to the query q. LAST CLICK>SKIPABOVEwould generate just the preferences:
making the assumption that perhaps d2 is not actually more relevant to the
user, as he or she chose to come back to the search results after observing that document. CLICK>EARLIER CLICKwould generate the preference
d4 q d2,
again taking the view that perhaps the last clicked document is most likely to satisfy the user’s needs. CLICK>SKIPPREVIOUSwould generate the preferences
d2 q d1; d4 q d3,
being more conservative in generating long-distance preferences since the result most reliably evaluated before a click is the one directly preceding it. Finally, CLICK>NO-CLICKNEXTwould generate the preference
d2 q d3,
since users usually consider thenextresult before clicking.
2.2.6
Are these judgments valid?
While the feedback strategies described above are intuitively appealing, a quan-titative evaluation is necessary to establish their degree of validity. We now present a summary of an evaluation of the above strategies reported by Joachims et al. (2005).
Joachims et al. evaluated the accuracy of each of these feedback strategies by asking human judges to rate the relevance of every result returned to the volun-teers during the eye tracking study. The judges could know the ground truth