Hierarchical Back-off Modeling of Hiero Grammar based on
Non-parametric Bayesian Model
Hidetaka Kamigaito1
[email protected] Taro Watanabe
2
[email protected] Hiroya Takamura
1
[email protected] Manabu Okumura1
[email protected] Eiichiro Sumita
3
1Tokyo Institute of Technology 2Google Japan Inc.
3National Institute of Information and Communication Technology
Abstract
In hierarchical phrase-based machine translation, a rule table is automatically learned by heuristically extracting syn-chronous rules from a parallel corpus. As a result, spuriously many rules are extracted which may be composed of various incorrect rules. The larger rule table incurs more run time for decoding and may result in lower translation quality. To resolve the problems, we propose a hierarchical back-off model for Hiero grammar, an instance of a synchronous context free grammar (SCFG), on the basis of the hierarchical Pitman-Yor process. The model can extract a compact rule and phrase table without resorting to any heuristics by hierarchically backing off to smaller phrases under SCFG. Inference is efficiently carried out using two-step synchronous parsing of Xiao et al., (2012) combined with slice sampling. In our experiments, the proposed model achieved higher or at least comparable translation quality against a previous Bayesian model on various language pairs; German/French/Spanish/Japanese-English. When compared against heuristic models, our model achieved comparable translation quality on a full size German-English language pair in Europarl v7 corpus with significantly smaller grammar size; less than 10% of that for heuristic model.
1 Introduction
Hierarchical phrase-based statistical machine translation (HPBSMT) (Chiang, 2007) is a popu-lar alternative to phrase-based SMT (PBSMT), in which synchronous context free grammar (SCFG)
is used as the basis of the machine translation model. With HPBSMT, a restricted form of an SCFG, i.e., Hiero grammar, is usually used and is especially suited for linguistically divergent lan-guage pairs, such as Japanese and English. How-ever, a rule table, i.e., a synchronous grammar, may be composed of spuriously many rules with potential errors especially when it was automati-cally acquired from a parallel corpus. As a result, the increase in the rule table incurs a large amount of time for decoding and may result in lower trans-lation quality.
Pruning a rule table either on the basis of signif-icance test (Johnson et al., 2007) or entropy (Ling et al., 2012; Zens et al., 2012) used in PBSMT can be easily applied for HPBSMT. However, these methods still rely on a heuristically determined threshold parameter. Bayesian SCFG methods (Blunsom et al., 2009) solve the spurious rule extraction problem by directly inducing a com-pact rule table from a parallel corpus on the basis of a non-parametric Bayesian model without any heuristics. Training for Bayesian SCFG models infers a derivation tree for each training instance, which demands the time complexity ofO(|f|3|e|3)
when we use dynamic programming SCFG parsing (Wu, 1997). Gibbs sampling without bi-parsing (Levenberg et al., 2012) can avoid this problem, though the induced derivation trees may strongly depend on initial derivation trees. Even though we may learn a statistically sound model on the basis of non-parametric Bayesian methods, current approaches for an SCFG still rely on ex-haustive heuristic rule extraction from the word-alignment decided by derivation trees since the learned models cannot handle rules and phrases of various granularities.
We propose a model on the basis of the previ-ous work on the non-parametric Inversion Trans-duction Grammar (ITG) model (Neubig et al., 2011) wherein phrases of various granularities are
learned in a hierarchical back-off process. We extend it by incorporating arbitrary Hiero rules when backing off to smaller spans. For efficient inference, we use a fast two-step bi-parsing ap-proach (Xiao et al., 2012) which basically runs in a time complexity ofO(|f|3). Slice sampling for an
SCFG (Blunsom and Cohn, 2010) is used for effi-ciently sampling a derivation tree from a reduced space of possible derivations.
Our model achieved higher or at least com-parable BLEU scores against the previous Bayesian SCFG model on language pairs; German/French/Spanish-English in the News-Commentary corpus, and Japanese-English in the NTCIR10 corpus. When compared against heuristically extracted model through the GIZA++ pipeline, our model achieved comparable score on a full size Germany-English language pair in Eu-roparl v7 corpus with significantly less grammar size.
2 Related Work
Various criteria have been proposed to prune a phrase table without decreasing translation qual-ity, e.g., Fisher’s exact test (Johnson et al., 2007) or relative entropy (Ling et al., 2012; Zens et al., 2012). Although those methods are easily ap-plied for pruning a rule table, they heavily rely on the heuristically determined threshold parame-ter to trade off the translation quality and decoding speed of an MT system.
Previously, EM-algorithm based generative models were exploited for generating compact phrase and rule tables. Joint phrase alignment model (Marcu and Wong, 2002) can directly express many-to-many word aligments without heuristic phrase extraction. DeNero et al. (2006) proposed IBM Model 3 based many-to-many alignment model. Rule arithmetic method (Cme-jrek and Zhou, 2010) can generate SCFG rules by combining other rule pairs through an inside-outside algorithm. However, those previous at-tempts were restricted in that the rules and phrases were induced by heuristic combination.
Bayesian SCFG models can induce a com-pact model by incorporating sophisticated non-parametric Bayesian models for an SCFG, such as a dirichlet process (DeNero et al., 2008; Blunsom et al., 2009; Chung et al., 2014) or Pitman-Yor process (Levenberg et al., 2012; Peng and Gildea, 2014). A model is learned by sampling derivation
trees in a parallel corpus and by accumulating the rules in the sampled trees into the model. Due to the O(|f|3|e|3) time complexity for bi-parsing a
bilingual sentence, previous studies relied on bi-parsing at the initialization step, and conducted Gibbs sampling by local operators (Blunsom et al., 2009; Levenberg et al., 2012) or sampling on fixed word alignments (Chung et al., 2014; Peng and Gildea, 2014). As a result, the inference can easily result in local optimum, wherein induced deriva-tion trees may strongly depend on the initial trees. Xiao et al. (2012) proposed a two-step approach for bi-parsing a bilingual sentence inO(|f|3)in the
context of inducing SCFG rules discriminatively; however, their approach violates the detailed bal-ance due to its heuristic k-best pruning. Blun-som and Cohn (2010) proposed a slice sampling for an SCFG, in the same manner as that for Infi-nite Hiden Markov Model (iHMM) (Van Gael et al., 2008), which can efficiently prune a space of possible derivations on the basis of dynamic pro-gramming. Although slice sampling can prune spans without violating the detailed balance, its time complexity ofO(|f|3|e|3)is still impractical
for a large-scale experiment. We efficiently car-ried out large-scale experiments on the basis of the two-step bi-parsing of Xiao et al. combined with slice sampling of Blunsom and Cohn.
After learning a Bayesian model, it is not di-rectly used in a decoder since it is composed of only minimum rules without considering phrases of various granularities. As a consequence, it is a standard practice to obtain word alignment from derivation trees and to extract SCFG rules heuris-tically from the word-aligned data (Cohn and Haf-fari, 2013). The work by Neubig et al. (2011) was the first attempt to directly use the learned model on the basis of a Bayesian ITG in which phrases of many granularities were encoded in the model by employing a hierarchical back-off procedure. Our work is strongly motivated by their work, but greatly differs in that our model can incorporate many arbitrary Hiero rules, not limited to ITG-style binary branching rules.
3 Model
We use Hiero grammar (Chiang, 2007), an in-stance of an SCFG, which is defined as a context-free grammar for two languages. LetΣdenote a set of terminal symbols in the source language,∆
Figure 1: Derivation tree generated from Bayesian SCFG model
V a set of non-terminal symbols,Sa start symbol andRa set of rewrite rules. An SCFG is denoted as a tuple of ⟨Σ,∆, V, S, R⟩. Each rewrite rule in R is represented as X → ⟨α/β⟩ in which α is a string of non-terminals and source side termi-nals (V ∪Σ)∗ andβ is a string of non-terminals and target side terminals(V ∪∆)∗. An example derivation in an SCFG for the sentence pair “ ni-hongo wo eigo ni honyaku suru koto wa muzukasii
。/ Japanese is difficult to translate into English .” is represented as follows:
S →X1 eigo X2 muzukasii。/X1 difficult X2 English .
X1→X3wo/X3is
X2→X4honyaku suruX5wa/X4translateX5
X3→nihongo/ Japanese
X4→ni/ into X5→koto/ to .
A Hiero grammar has additional constraints over a general SCFG; the number of terminal sym-bols in each rule for both source and target sides is limited to 5. Each rule may contain at most two non-terminal symbols; adjacent non-terminal symbols in the source side are prohibited. For de-tails, refer to (Chiang, 2007).
3.1 Bayesian SCFG Models
Previous Bayesian SCFG Models, for instance a model proposed by Levenberg et al. (2012), are based on the Pitman-Yor process (Pitman and Yor, 1997) and learn SCFG rules by sampling a deriva-tion tree for each bilingual sentence. Figure 1 shows an example derivation tree for our running example sentence pair under the model. The
gen-erative process is represented as follows:
GX ∼ Prule(dr, θr, Gr0),
X → ⟨α/β⟩ ∼ GX, (1)
where GX is a derivation tree and
Prule(dr, θr, Gr0) is a Pitman-Yor process
(Pitman and Yor, 1997), which is a generalization of a Dirichlet process parametrized by a discount parameter dr, a strength parameterθr and a base
measureGr0. The output probability of a
Pitman-Yor process obeys the power-law distribution with the discount parameter, which is very common in standard NLP tasks.
The probability that a rule rk is drawn from a
modelPrule(dr, θr, Gr0) is determined by a
Chi-nese restaurant process which is decomposed into two probability distributions. Ifrk already exists
in a table, we drawrkwith probability
ck−dr· |φrk|
θr+nr , (2)
whereck is the number of customers ofrk, nr is
the number of all customers andφrk is a number
ofrk’s tables. On the other hand, ifrk is a new
rule, we drawrkwith probability
θr+dr· |φr|
θr+nr ·Gr0, (3)
where|φr|is the number of tables in the model.
3.2 Hierarchical Back-off Model
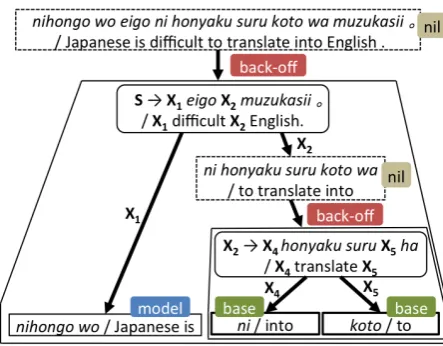
Figure 2: Derivation tree generated from the hier-archical back-off model
we reach phrase pairs which are generated without any back-offs. Let a discount parameter be dp, a
strength parameter beθp, and a base measure be
Gp0. More formally, the generative process is
rep-resented as follows:
GX ∼ Prule(dr, θr, Gphrase),
Gphrase ∼ Pphrase(dp, θp, GX),
X→ ⟨s/t⟩ ∼ Gphrase,
X→ ⟨α/β⟩ ∼ GX, (4)
wheresis source side terminals andtis target side terminals in phrase pair ⟨s/t⟩. Pphrase is
com-posed of three states, i.e., model, back-off, and
base, and follows a hierarchical Pitman-Yor pro-cess (Teh, 2006).
model: We draw a phrase pair ⟨s/t⟩ with the probability similar to Equation (2):
ck−dp· |φpk|
θp+np , (5)
whereckis the numbers of customers of a phrase
pairpkandnpis the number of all customers Note
that this state is reachable when the phrase pair
⟨s/t⟩ exists in the model in the same manner as Equation (2).
back-off: We will back off to smaller phrases using a rule generated byPruleas follows:
θp+dp· |φp|
θp+np ·
cback+γb·Gb
cback+cbase+γb ·Prule(dr, θr, Gphrase)
· ∏
X∈⟨α/β⟩
Pphrase(dp, θp, GX), (6)
wherecbackandcbaseare the number of customers
sampled from the back-off and base phrases, re-spectively, with a base measure Gb and
hyper-parameter γb. We use a uniform distribution for
Gb= 0.5since we consider only two states, back-off and base. Unlike the model state, Pphrase
may reach this state even when a phrase pair is not in the model. The phrase pair is backed-off to smaller phrase pairs using Pphrase through the
non-terminals in the generated ruleX∈ ⟨α/β⟩. base: As an alternative to theback-offstate, we may reach thebasestate which follows the proba-bility distribution on the basis of the base measure Gp0,
θp+dp· |φp|
θp+np ·
cbase+γb·Gb
cback+cbase+γb ·Gp0. (7)
In summary, Pphrase(dp, θp, GX) is defined as a
joint probability of Equations (5) through (7). 3.3 Base Measure
Similar to Levenberg et al. (2012), the base mea-sure for rule probability Gr0 is composed of
four generative processes. First, a number of symbols in a source side of a rule |α| is gen-erated from a Poisson distribution, i.e., |α| ∼
P oisson(0.1). Lett(x)denote a function that re-turns terminals from a string x. The number of target side terminal symbols|t(β)|is also gener-ated from a Poisson distribution and represented as |t(β)| ∼ P oisson(α + λ0)1. The type of
symbol αi in the source side, typei, either
ter-minal or non-terter-minal symbol, is determined by typei ∼ Bernoulli(ϕ|α|) where ϕ is a
hyper-parameter taking 0 < ϕ < 1. ϕ|α| is based on an intuition that shorter rules should be rela-tively more likely to contain terminal symbols than longer rules. Source and target terminal symbol pair ⟨t(α), t(β)⟩ are generated from the geomet-ric means of two directional IBM Model 1 word alignment probabilities and monolingual unigram probabilities for two languages, and represented as:
⟨t(α), t(β)⟩ ∼(Puni(t(α))P−−→M1(t(α), t(β))·
Puni(t(β))P←−−M1(t(α), t(β)))12. (8)
When thet(α) ort(β)is empty, we use the con-stant0.01instead of the Model1 probabilities.
The base measure for phrasesGp0 is composed
of three generative processes, in a similar man-ner as Levenberg et al. (2012), the number of terminal symbols in a phrase pair in the source side, |s|, is generated from a Poisson distribution
|s| ∼P oisson(0.1). The length for the target side
|t|is generated in the same manner as the source side of the phrase pair. The alignments between sandtare also generated in the same manner as those for the base measure in a rule.
4 Inference
In inference, we use a sentence-wise block sam-pling of Blunsom and Cohn (2010), which has a better convergence property when compared with a step-wise Gibbs sampling. We repeat the follow-ing steps given a sentence pair.
1. Decrement customers of the rules and phrase pairs used in the current derivation for the sentence pair.
2. Bi-parse the sentence pair in a bottom up manner.
3. Sample a new derivation tree in a top-down manner.
4. Increment customers of the rules and phrase pairs in the sampled derivation tree.
The most time-consuming step during the infer-ence procedure is bi-parsing of a sentinfer-ence pair which essentially takes O(|f|3|e|3) time using a
bottom up dynamic programming algorithm (Wu, 1997). When a span is very large, it can easily suf-fer combinatorial explosion. To avoid this prob-lem, we use a two-step slice sampling by perform-ing the two-step bi-parsperform-ing of Xiao et al. (2012) and by pruning possible derivation space (Blun-som and Cohn, 2010) in each step (Algorithm 1). From lines 1 to 7, a set of word alignment is enu-merated and put intocubea. In addition to the
ar-bitrary word alignment ofsourceitotargetj, null
word alignment is also merged into cubea (line
5). Note that word alignment considered in the algorithm is restricted to one-to-many. The set of word alignments incubeais pruned and added to
thechartaby SliceSampling. From lines 8 to 15,
all possible phrases and rules for each span con-strained by the pruned word alignment are enu-merated and temporally stored into cube. The phrases and rules incubeare pruned by SliceSam-pling and the remainders are added tochart. The
Algorithm 1Two-step slice sampling
1: fori←1,· · ·,|source|do 2: forj←1,· · ·,|target|do 3: cubea← {soucei, targetj} 4: end for
5: cubea← {soucei, null}
6: charta←SliceSampling(cubea) 7: clearcubea
8: end for
9: forh←1,· · ·,|source|do 10: forall thei, j s.t j−i=hdo
11: forinferablerule, phrasefrom the
sub-spans of[i, j]of all chartsdo 12: cube←rule, phrase 13: end for
14: chart←SliceSampling(cube) 15: clearcube
16: end for 17: end for
time complexity for the word alignment enumera-tion from lines 1 to 7 isO(|f||e|)and that for the phrase and rule enumeration from lines 8 to 15 is O(|f|3).
The key difference to the slice sampling of Blunsom and Cohn (2010) lies in lines 6 and 3 of Algorithm 1. Letddenote a set of derivation trees dandube a set of slice variablesu. In slice sam-pling, we prune the rulesrspin each source span spbased on a slice variableusp corresponding to
thatsp. After pruning, we sample trees from the pruned space ofr. The above process is formally represented as:
u ∼ P(u|d),
d ∼ P(d|u), (9)
where P(d|u) is computed through sampling in a top-down manner after parsing in a bottom-up manner with Algorithm 1, and is equal to
∏
dP(d|u). The probability P(u|d) is equal to
∏
spP(usp|d). Letrsp∗ denote a currently adopted
rule in the span sp andP(usp|d)be defined using
a pruning scoreScore(r∗
sp)as follows:
Score(rspi) =Inside(rspi)·F uture(rspi),(10)
where Inside(rsp) and F uture(rsp) are inside
and outside probabilities forsp, respectively. Let srsp denote a set of source side words inrsp,trsp
a set of target side words inrsp,sspa set of words
words in a target sentence without trsp. By
us-ing IBM Model 1 probabilities in two directions, Inside(rsp)is calculated by
(P−−→M1(ssp,tsp)·P←−−M1(ssp,tsp))12. (11)
We use IBM Model1 outside probability for future score F uture(rsp). Similarly, the future score
F uture(rsp) is computed using the two
direc-tional models:
(P−−→M1(ssp,tsp)·P←−−M1(ssp.tsp))12. (12)
Whenspis used in the current derivationd, slice variable usp is sampled from a uniform
distribu-tion2:
P(usp|d) = I(usp < Score(r
∗
sp))
Score(r∗
sp) , (13)
otherwise,usp is sampled from a beta distribution
ifspis not in the current derivationd:
P(usp|d) =Beta(usp;a,1.0), (14)
wherea < 1is a parameter for the beta distribu-tion. If theScore(rspi)is less thanusp, we prune
therspi fromcube. Similar to Blunsom and Cohn
(2010), if the spanspis not in the current deriva-tion, the rules with low probability are pruned ac-cording to Equation (14). Letrd
spdenotes a rule in
dwith spansp,P(d|u)is calculated by:
∏
sp∈d
P(rd sp)
∑
rj∈rspP(rj)I(usp < Score(rj))
. (15)
In our experiments discussed in Section 6, slice sampling parameter a was set to 0.02 when in-corporating the future score of Equation (12). In contrast, we useda= 0.1when performing slice sampling without the future score. We empirically found that setting a lower value foraled to slower progress in learning due to a combinatorial explo-sion when inferencing a derivation for each sen-tence pair.
In the beginning of training, we do not have any derivation trees for given training data, al-though the derivation trees are required for esti-mating parameters for Bayesian models. We use the two-step parsing for generating initial deriva-tion trees from only base measures. The k-best
2I(·)is a function returns1if the condition is satisfied and
0otherwise
pruning is conducted against the score denoted by the equation 10 , which is very similar to Xiao et al. (2012).3
For faster bi-parsing, we run sampling in paral-lel in the same way as Zhao and Huang (2013), in which bi-parsing is performed in parallel among the bilingual sentences in a mini-batch. The up-dates to the model are synchronized by increment-ing and decrementincrement-ing customers for the bilincrement-ingual sentences in the mini-batch. Note that the bi-parsing for each mini-batch is conducted on the fixed model parameters after the synchronised pa-rameter updates.
In addition to the model parameters, hyperpa-rameters are re-sampled after each training itera-tion following the discount and strength hyperpa-rameter resampling in a hierarchical Pitman-Yor process (Teh, 2006). In particular, we resample
⟨dp, θp⟩, the pair of discount and strength
parame-ters for phrases from a distribution:
[θp]|dpφp| [θp]np1
∏
⟨s,t⟩ |φp|
∏
k=1
[1−dp](c1⟨s,t⟩−1) (16)
where[ ]denotes a generalized Pochhammer sym-bol, andc⟨s,t⟩the number of customers of phrase pair ⟨s,t⟩. We resample the pair ⟨dr, θr⟩ in the
same way as ⟨dp, θp⟩. The hyperparameter γb is
resampled from distribution:
(cback+γb·Gb)(cbase+γb·Gb)
(cback+cbase+γb)2 , (17)
where ϕ, used in the generative process for ei-ther terminal or non-terminal symbol typei ∼
Bernoulli(ϕα), is resampled from a distribution:
∏
⟨α/β⟩∈Base
Bernoulli(ϕ|α|)c⟨α/β⟩, (18)
wherec⟨α/β⟩ denotes the number of customers of rule⟨α/β⟩, andBasedenotes a set of rules gener-ated from the base measure. All the hyperparame-ters are inferred by slice sampling (Neal, 2003).
5 Extraction of Translation Model
In the previous work on Bayesian approaches (Blunsom and Cohn, 2010; Levenberg et al., 2012), it is a standard practice to heuristically ex-tract rules and phrase pairs from the word align-ment derived from the derivation trees sampled
from the Bayesian models. Instead of the heuris-tic method, we directly extract rules and phrase pairs from the learned models which are repre-sented as Chinese restaurant tables. To limit gram-mar size, we include only phrase pairs that are se-lected at least once in the sample. During this ex-traction process, we limit the source or target ter-minal symbol size of phrase pairs to 5.
For each extracted rule or phase pair, we com-pute a set of feature scores used for a HPBSMT decoder; a weighted combination of multiple fea-tures is necessary in SMT since the model learned from training data may not fit well to translate an unseen test data (Och, 2003). We use the follow-ing six features; the joint model probabilityPmodel
is calculated by Equation (2) for rules and by Equation (5) for phrase pairs. The joint posterior probability Pposterior(f, e) is estimated from the
posterior probabilities for every rule and phrase pair in derivation trees through relative count es-timation, motivated by Neubig et al. (2011) 4.
The joint posterior probability is considered as an approximation for those back-off scores. The conditional model probabilities in two directions, Pmodel(f|e) and Pmodel(e|f), are estimated by
marginalizing the joint probabilityPmodel(f, e):
Pmodel(f|e) = ∑Pmodel(f, e)
f′Pmodel(f′, e). (19)
The inverse direction Pmodel(e|f) is estimated,
similarly. The lexical probabilities in two direc-tions,Plex(f|e)andPlex(e|f), are scored by IBM
Model probabilities between the source and target terminal symbols in rules and phrase pairs. In ad-dition to the above features, we use Word penalty for each rule and phrase pair used in the cdec de-coder (Dyer et al., 2010).
As indicated in previous studies (Koehn et al., 2003; DeNero et al., 2006), the translation quality of generative models is lower than that of mod-els with heuristically extracted rules and phrase pairs. DeNero et al. (2006) reported that con-sidering multiple phrase boundaries is important for improving translation quality. The generative models, in particular Bayesian models, are strict in determining phrase boundaries since their models are usually estimated from sampled derivations. As a result, translation quality is poorer when
4Note that the correct way to decode from our model is to score every phrase pair created during decoding with back-off states, which is computationally intractable
compared with a model estimated using a heuristic method. The Hiero grammar severely suffers from the phrase granularity problem and can overfit to the training data due to the flexibility of the rules.
To alleviate this problem, Neubig et al. (2011) combined the derivation trees across training it-erations by averaging the features for each rule and phrase pair. During the sampling process, each training iteration draws a different deriva-tion tree for each sentence pair, and the combi-nation of those different derivation trees can pro-vide multiple possible phrase boundaries to the model. Inspired by the averaging over the mod-els from different iterations, we combine them as a part of a sampling process; we treat the derivation trees acquired from different iterations as addi-tional training data, and increment the correspond-ing customers into our model. Hyperparameters are resampled after the merging process. The new features are directly computed from the merged model.
6 Experiments
6.1 Comparison with Previous Bayesian Model
First, we compared the previous Bayesian model (Gen) with our hierarchical back-off model (Back). We used the first 100K sentence pairs of the WMT10 News-Commentary cor-pus for German/Spanish/French-to-English pairs (Callison-Burch et al., 2010) and NTCIR10 cor-pus for Japanese-English (Goto et al., 2013) for the translation model. All sentences are lower-cased and filtered to preserve at most 40 words on both source and target sides. We sampled 20 it-erations for Gen and Back and combined the last 10 iterations for extracting the translation model.5
The batch size was set to 64. The language mod-els were estimated from the all-English side of the WMT News-Commentary and europarl-v7. In NTCIR10, we simply used the all-English side of the training data. All the 5-gram language mod-els were estimated using SRILM (Stolcke and oth-ers, 2002) with interpolated Kneser-Ney smooth-ing. The details of the corpus are presented in Ta-ble 2. For detailed analysis, we also evaluate Hiero grammars extracted from GIZA++ (Och and Ney, 2003) grow-diag-final bidirectional alignments us-ing Moses (Koehn et al., 2007) with Hiero options.
News-Commentary NTCIR10
de-en es-en fr-en ja-en
Model Sample BLEU SIZE BLEU SIZE BLEU SIZE BLEU SIZE
∗GIZA++ - 16.66 7.07M 23.16 6.07M 20.79 6.25M 26.08 3.45M
[image:8.595.95.503.62.164.2]Gen 1 15.36 397.63k 21.10 295.69k 19.45 311.76k 25.73 262.45k 10 15.39 529.46k 20.83 384.55k 19.24 419.33k 25.79 344.67k Back 1 15.30 410.92k 21.43 314.95k 19.74 362.22k 25.69 294.90k 10 15.42 563.80k 21.53 420.15k 19.51 497.51k 25.63 388.87k Back + future 1 15.49 384.69k 21.63 296.30k 19.97 340.70k 25.82 268.38k 10 15.55 579.12k 21.74 429.33k 19.97 513.41k 25.41 390.23k
Table 1: Results of translation evaluation in 100k corpus
[image:8.595.81.279.203.288.2]de-en es-en fr-en ja-en TM(en) 1.85M 1.67M 1.54M 1.80M TM(other) 1.86M 1.86M 1.83M 2.03M LM(en) 55.6M 55.6M 55.6M 27.8M Dev(en) 65.5k 65.5k 65.5k 67.3k Dev(other) 62.7k 68.1k 72.5k 73.0k Test(en) 61.9k 61.9k 61.9k 310k Test(other) 61.3k 65.5k 70.5k 333k
Table 2: The number of words in training data
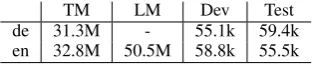
TM LM Dev Test
de 31.3M - 55.1k 59.4k en 32.8M 50.5M 58.8k 55.5k
Table 3: The number of words in training data
We use GIZA++ and Moses default parameters for training. Decoding was carried out using the cdec decoder (?). Feature weights were tuned on the de-velopment data by running MIRA (Chiang, 2012) for 20 iterations with 16 parallel. For other param-eters, we used cdec’s default values. The numbers reported here are the average of three tuning runs (Hopkins and May, 2011).
Table 1 lists the results measured using BLEU (Papineni et al., 2002).The term Sample denotes the combination size for each model. The term SIZE in the table denotes the number of the ex-tracted grammar types composed of Hiero rules and phrase pairs. The numbers in italic denotes the score of Back, significantly improved from the score of 1 sampled combinated Gen. The numbers in bold denotes the score of Back + future, significantly improved from the score of 1 sampled combinated Back. All significance test are performed using Clark et al. (2011) un-der p-value of0.05. Back performed better than Gen on Spanish-English and French-English lan-guage pairs. Note that the gains were achieved with the comparable grammar size. When com-paring German-English and Japanese-English lan-guage pairs, there are no significant differences between Back and Gen. The combination of our
Back with future score during slice sampling (+fu-ture) achieved further gains over the slice sam-pling without future scores, and slightly decrese the grammar size, compared to Back. However, there are still no significant difference between Back+future and Gen on German-English and Japanese-English language pairs. Sample combi-nation has no or slight gain on BLEU score, in spite of the increase in grammar size. From the results, using last one sample as a grammar is suf-ficient for translation quality. The performance of the Bayesian model did not match with that for the GIZA++ pipeline heuristic approach. In general, complex model, such as Gen and Back, demands larger corpus size for training, and the evaluation on such smaller corpus may not be a fair com-parison, since the sampling approach can rely on only sampled derivations. Thus, we evaluate these methods on large size corpus in the next section.
6.2 Comparison with Heuristic Extraction As reported in (Koehn et al., 2003; DeNero et al., 2006), the comparison against heuristic ex-traction is a challenging task. We compare the Back+future and a baseline extracted from grow-diag-final alignments of GIZA++ using Moses with Hiero options. We use GIZA++ and Moses default parameters for training. In addition, we present heuristic extraction from the last 1 sample of Back+future in +Exhaustive.
We used the full europarl-v7 German-English corpus as presented in Table 3. The experimen-tal set up was similar to that in Section 6.1 with the following exceptions; Slice sampling parame-ter awas set to 0.05. Mini-batch size was set to 1024 and sampling was performed 5 iterations.6
The translation model was extracted by last 1 iter-ations.
Table 4 lists the results7. Our Back+future can
6Inference took 5 days.
[image:8.595.103.260.322.354.2]Model BLEU SIZE ∗ GIZA++ Model 4 27.21 73.24M (×14.0) GIZA++ Model 3 26.78 59.26M (×11.3) Back + future 26.83 5.25M (×1.0) Back + future + exhasustive 26.73 90.42M (×17.2)
Table 4: Results of translation evaluation in de-en full size corpus.
Gen ginXkamera/ silver X camera en/ salt
Back + future gin en kamera/ silver salt camera
Table 5: Example of a grammar
decrease the grammar size against GIZA++ with comparable BLEU score. Surprisingly, exhaustive extraction had no gains, probably because of the word alignment in each Hiero rules relied on the IBM Model 1.
7 Analysis
Intuitively, the use of the hierarchical back-off in-creases the Hiero grammar size, since the phrases of all the granularities in the derivation trees are incorporated in the grammar. In contrast, our hier-archical back-off model achieved gains in transla-tion quality without increasing the size of the ex-tracted grammar when compared to the previous generative model. The major differences were the use of the minimal phrase pairs used in the previ-ous work in which only minimal phrase pairs in the leaves of derivation trees were included in the model. As a result, larger phrase pairs were forced to be constructed from those minimal rules. On the other hand, our back-off model could directly ex-press phrase pairs of multiple granularities. In par-ticular, a complex noun may be composed of sev-eral Hiero rules in the previous model, but it can be directly expressed by a single phrase pair in our model. Table 5 gives an example of a Japanese-English phrase pair which is represented by two Hiero rules in the previous model; it is directly ex-pressed by a single phrase pair in our model.
The BLEU score of Back+future was higher than the generative baseline with comparable grammar size. We observed that a very different word alignment was sampled in every training it-eration; the tendency was very frequent for func-tion words. Our future score for inferring the slice variables may take into account the context in a sentence better than those without the future score.
class informations. Model 3 and our Back-off model dose not use any word class informations.
As a result, Back+future infers better models by avoiding over pruning spans.
The BLEU score of our back-off model did not achieve gains over the heuristic baselines. The de-tail analysis of the learned Hiero grammar’s CRP tables reveals that the grammar is very sparse and may have little generalization capacity. The ex-pansion of back-off process and the use of word classes will solve the sparsity and increase the translation quality.
8 Conclusion
We proposed a hierarchical back-off model for Hiero grammar. Our back-off model achieved higher or equal translation quality against a previ-ous Bayesian model under BLEU score on variprevi-ous language pairs;German/French/Spanish/Japanese-English. In addition to the hierarchical back-off model, we also proposed a two-step slice sampling approach. We showed that the two-step slice sam-pling approach can avoid over-pruning by incor-porating a future score for estimating slice vari-ables, which led to increase in translation quality through the experiments. The joint use of hierar-chical back-off model and two step slice sampling approach achieved comparable translation quality on a full size Germany-English language pair in Europarl v7 corpus with with significantly smaller grammar size; 10% less than that for he heuristic baseline.
For future work, we plan to embed a back-off feature to decoder which is computed for all the phrase pairs constructed in a derivation during the decoding process. We will reflect the change of a probability as a statefull feature for decoding step.
References
Phil Blunsom and Trevor Cohn. 2010. Inducing syn-chronous grammars with slice sampling. InHuman Language Technologies: The 2010 Annual Confer-ence of the North American Chapter of the Associa-tion for ComputaAssocia-tional Linguistics, pages 238–241, Los Angeles, California, June. Association for Com-putational Linguistics.
Chris Callison-Burch, Philipp Koehn, Christof Monz, Kay Peterson, Mark Przybocki, and Omar F Zaidan. 2010. Findings of the 2010 joint workshop on sta-tistical machine translation and metrics for machine translation. InProceedings of the Joint Fifth Work-shop on Statistical Machine Translation and Met-ricsMATR, pages 17–53. Association for Computa-tional Linguistics.
David Chiang. 2007. Hierarchical phrase-based trans-lation. computational linguistics, 33(2):201–228. David Chiang. 2012. Hope and fear for discriminative
training of statistical translation models. The Jour-nal of Machine Learning Research, 13(1):1159– 1187.
Tagyoung Chung, Licheng Fang, Daniel Gildea, and Daniel ˇStefankoviˇc. 2014. Sampling tree frag-ments from forests. Computational Linguistics, 40(1):203–229.
Jonathan H. Clark, Chris Dyer, Alon Lavie, and Noah A. Smith. 2011. Better hypothesis testing for statistical machine translation: Controlling for op-timizer instability. InProceedings of the 49th An-nual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 176–181, Portland, Oregon, USA, June. Association for Computational Linguistics.
Martin Cmejrek and Bowen Zhou. 2010. Two meth-ods for extending hierarchical rules from the bilin-gual chart parsing. In Coling 2010: Posters, pages 180–188, Beijing, China, August. Coling 2010 Or-ganizing Committee.
Trevor Cohn and Gholamreza Haffari. 2013. An infi-nite hierarchical bayesian model of phrasal transla-tion. InProceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Vol-ume 1: Long Papers), pages 780–790, Sofia, Bul-garia, August. Association for Computational Lin-guistics.
John DeNero, Dan Gillick, James Zhang, and Dan Klein. 2006. Why generative phrase models under-perform surface heuristics. In Proceedings on the Workshop on Statistical Machine Translation, pages 31–38, New York City, June. Association for Com-putational Linguistics.
John DeNero, Alexandre Bouchard-Cˆot´e, and Dan Klein. 2008. Sampling alignment structure un-der a Bayesian translation model. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, pages 314–323, Hon-olulu, Hawaii, October. Association for Computa-tional Linguistics.
Chris Dyer, Adam Lopez, Juri Ganitkevitch, Jonathan Weese, Ferhan Ture, Phil Blunsom, Hendra Seti-awan, Vladimir Eidelman, and Philip Resnik. 2010. cdec: A decoder, alignment, and learning framework for finite-state and context-free translation models.
InProceedings of the ACL 2010 System Demonstra-tions, pages 7–12, Uppsala, Sweden, July. Associa-tion for ComputaAssocia-tional Linguistics.
Isao Goto, Ka Po Chow, Bin Lu, Eiichiro Sumita, and Benjamin K Tsou. 2013. Overview of the patent machine translation task at the ntcir-10 workshop. InProceedings of the 10th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies: Information Retrieval, Question Answering and Cross-Lingual Information Access, NTCIR-10. Mark Hopkins and Jonathan May. 2011. Tuning as
ranking. InProceedings of the 2011 Conference on Empirical Methods in Natural Language Process-ing, pages 1352–1362, Edinburgh, Scotland, UK., July. Association for Computational Linguistics. Howard Johnson, Joel Martin, George Foster, and
Roland Kuhn. 2007. Improving translation qual-ity by discarding most of the phrasetable. In Pro-ceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Com-putational Natural Language Learning (EMNLP-CoNLL), pages 967–975, Prague, Czech Republic, June. Association for Computational Linguistics. Philipp Koehn, Franz Josef Och, and Daniel Marcu.
2003. Statistical phrase-based translation. In
Proceedings of the 2003 Conference of the North American Chapter of the Association for Computa-tional Linguistics on Human Language Technology-Volume 1, pages 48–54. Association for Computa-tional Linguistics.
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, et al. 2007. Moses: Open source toolkit for statistical machine translation. In Pro-ceedings of the 45th annual meeting of the ACL on interactive poster and demonstration sessions, pages 177–180. Association for Computational Linguis-tics.
Abby Levenberg, Chris Dyer, and Phil Blunsom. 2012. A bayesian model for learning scfgs with discon-tiguous rules. InProceedings of the 2012 Joint Con-ference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 223–232, Jeju Island, Korea, July. Association for Computational Linguistics.
Wang Ling, Jo˜ao Grac¸a, Isabel Trancoso, and Alan Black. 2012. Entropy-based pruning for phrase-based machine translation. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 962–971, Jeju Island, Korea, July. Association for Computational Linguistics.
on Empirical Methods in Natural Language Pro-cessing, pages 133–139. Association for Computa-tional Linguistics, July.
Radford M Neal. 2003. Slice sampling. Annals of statistics, pages 705–741.
Graham Neubig, Taro Watanabe, Eiichiro Sumita, Shinsuke Mori, and Tatsuya Kawahara. 2011. An unsupervised model for joint phrase alignment and extraction. InProceedings of the 49th Annual Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics: Human Language Technologies, pages 632– 641, Portland, Oregon, USA, June. Association for Computational Linguistics.
Franz Josef Och and Hermann Ney. 2003. A sys-tematic comparison of various statistical alignment models. Computational Linguistics, 29(1):19–51. Franz Josef Och. 2003. Minimum error rate
train-ing in statistical machine translation. In Proceed-ings of the 41st Annual Meeting of the Association for Computational Linguistics, pages 160–167, Sap-poro, Japan, July. Association for Computational Linguistics.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of 40th Annual Meeting of the Association for Com-putational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July. Association for Computa-tional Linguistics.
Xiaochang Peng and Daniel Gildea. 2014. Type-based mcmc for sampling tree fragments from forests. In Proceedings of the 2014 Conference on Em-pirical Methods in Natural Language Processing (EMNLP), pages 1735–1745, Doha, Qatar, October. Association for Computational Linguistics.
Jim Pitman and Marc Yor. 1997. The two-parameter poisson-dirichlet distribution derived from a stable subordinator. The Annals of Probability, pages 855– 900.
Andreas Stolcke et al. 2002. Srilm-an extensible lan-guage modeling toolkit. InINTERSPEECH. Yee Whye Teh. 2006. A hierarchical bayesian
lan-guage model based on pitman-yor processes. In
Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics, pages 985–992, Sydney, Australia, July. Asso-ciation for Computational Linguistics.
Jurgen Van Gael, Yunus Saatci, Yee Whye Teh, and Zoubin Ghahramani. 2008. Beam sampling for the infinite hidden markov model. InProceedings of the 25th international conference on Machine learning, pages 1088–1095. ACM.
Dekai Wu. 1997. Stochastic inversion transduction grammars and bilingual parsing of parallel corpora.
Computational linguistics, 23(3):377–403.
Xinyan Xiao, Deyi Xiong, Yang Liu, Qun Liu, and Shouxun Lin. 2012. Unsupervised discrimina-tive induction of synchronous grammar for machine translation. InProceedings of COLING 2012, pages 2883–2898, Mumbai, India, December. The COL-ING 2012 Organizing Committee.
Richard Zens, Daisy Stanton, and Peng Xu. 2012. A systematic comparison of phrase table pruning tech-niques. In Proceedings of the 2012 Joint Confer-ence on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 972–983, Jeju Island, Korea, July. Association for Computational Linguistics.