Pulling Out the Stops: Rethinking Stopword Removal for Topic Models
Alexandra Schofield Cornell University
Ithaca, NY 14850
M˚ans Magnusson Link¨oping University
Link¨oping, Sweden
David Mimno Cornell University
Ithaca, NY 14850
Abstract
It is often assumed that topic models bene-fit from the use of a manually curated stop-word list. Constructing this list is time-consuming and often subject to user judg-ments about what kinds of words are im-portant to the model and the application. Although stopword removal clearly affects which word types appear as most prob-able terms in topics, we argue that this improvement is superficial, and that topic inference benefits little from the practice of removing stopwords beyond very fre-quent terms. Removing corpus-specific stopwords after model inference is more transparent and produces similar results to removing those words prior to inference.
1 Introduction
In Latent Dirichlet allocation (LDA) (Blei et al., 2003), a common preprocessing step is the removal of stopwords, or common, contentless words in a corpus. The use of stoplists comes with several costs in both effort and persuasiveness. Constructing a good stoplist is difficult and time consuming, and often cannot be transferred to new corpora. Custom stoplists can also call into ques-tion the validity of a model: if an analyst is too aggressive in removing words, the resulting mod-els may be biased towards what the analyst views as important in a corpus. Finally, while removing stopwords appears to produce more interpretable topics, this effect may be an illusion. As topic in-terpretability is typically judged by the most fquent terms in the topic, post-hoc stopword re-moval from a model can substantially increase in-terpretability without modifying the model.
In this paper, we analyze the consequence of removing stopwords for topic modeling in terms
of model fit, coherence, and utility. We consider three configurations: models trained and presented with stopwords intact, models with stopwords re-movedbeforetraining, and models with stopwords removed after training. We find that there are benefits in model quality when stopwords are re-moved. However, stopword removal does not ap-pear to consistently improve the model’s ability to learn topics over the other terms, but rather to remove dense high-probability terms that can slow inference and skew the word type probabil-ity distribution. We conclude that beyond high-probability terms, the effects of stoplists on train-ing are limited, and that removtrain-ing unwanted terms after training should be sufficient.
2 Stopwords in Topic Models
The assumption behind stopword removal is that, with stopwords present, we will not be able to learn as high-quality a language model. In the corpora we have selected, a preset list of approxi-mately 500 stopword types accounted for 40-50% of the corpus. If these words are expected to be uncorrelated with any topics, we would expect stopwords to only hinder inference of meaningful topics. LDA may sometimes partially accommo-date separating out stopwords without explicitly removing them. Wallach et al. (2009a) show that a parsimonious asymmetric Dirichlet prior inferred forθ, can allow model inference to isolate stop-words into fewer low-quality topics, leaving the remaining topics largely unaffected.
topics, but the latter set of extremely frequent terms may overwhelm the model and reduce how well the model fits contentful terms.
We identify three plausible hypotheses about the effect of stopwords in topic model training.
1. Stopwords harm inference. Noise from fre-quent words prevents the algorithm from rec-ognizing patterns in content-bearing words.
2. Stopwords have no effect on inference.
Noise from frequent words does not alter in-ference on non-stopwords.
3. Stopwords improve inference. Frequent words echo and reinforce patterns in content-bearing words.
We assess through a variety of experiments how well each of these hypotheses hold in practice.
3 Evaluation Methods
We aim to study the effects of removing stopwords on topic quality and keyword generation. To do this, we evaluate topic models as language mod-els, document summarization tools, and features for learning new models over data.
3.1 Existing Methods
A standard measurement of topic model quality is based upon evaluating the likelihood of a held-out portion of the modeled corpus being generated by the inferred topic model (Wallach et al., 2009b). Though directly computing a document’s proba-bility in an LDA model is intractable, we can es-timate it using left-to-right estimation (Wallach et al., 2009b). However, this metric has two draw-backs: one, that it provides little information about individual topics, and two, that it does not cor-relate well with actual human perception of topic quality (Chang et al., 2009).
Work demonstrating that topic likelihood and human evaluations of topic coherence differ (Chang et al., 2009) has led to several metrics to evaluate a topic’s coherence. These typically use co-occurrence statistics for frequent types in the topic, such as topic coherence (Mimno et al., 2011) and normalized pointwise mutual informa-tion (NPMI) (Aletras and Stevenson, 2013; Lau et al., 2014). We use NPMI in our evaluations.
3.2 New Methods
Topic-document mutual information The hy-potheses described in Section 2 focus on differ-ences between the topic distribution of stopwords in a given document and the topic distribution of content-bearing words in that document. One way to assess this effect in a model is to study the mutual information between documents and top-ics. Using the topic assignments of tokens inferred via Gibbs sampling, we can examine the mutual information between the document-topic distribu-tion and the topic assignment of the token. We compare theMI(d, k)before and after stopword removal to measure the effect of removal on the posterior. If there is no semantic information in a set of tokens (such as stopwords) theMI(d, k) should be close to 0. If the stopwords have a neg-ative effect on inference (hypothesis 1) removing these words before inference (pre-removal) should result in a higher MI(d, k) than removing them afterwards (post-removal). The opposite should be true if stopword improve inference (hypothesis 3).
Classification with key terms A metric of the quality of representative terms for a topic is their ability to identify documents with a high propor-tion of that topic. Inspired by the approach of Dredze et al. (2008), we use classification of doc-uments by topic to assess the quality of key terms as representative topic features. We train multino-mial Na¨ıve Bayes models with the token counts of top representative terms as features and the most present topic of each document as labels.
4 Experiments
(a) Pre- and post removal (b) Effect on non-stopword tokens
Figure 1: Mutual information on the NYT corpus,MI(d, k), as a function of the number of stopwords removed (ordered by number of tokens). Removing stopwords before training leads to a slightly higher MI, but the effect on non-stopword tokens is small.
MALLET (McCallum, 2002). We inferred LDA topic models of 10, 50, and 200 topics with 1000 iterations of Gibbs sampling using hyperparameter optimization (Wallach et al., 2009a). Topics were trained on versions of the corpora with and with-out stopwords, with an additional model inferred by recomputing the document-topic distributions
θand topic-word distributionsφafter removing all stopwords from the inferred topic assignments of models trained with stopwords. This allows us to compare models with no stopwords removed (con-trol), stopwords removed before training (pre), and stopwords removed after training (post) all with the same effective corpus. Metrics are averaged over 10 models per treatment.
We train several types of topic models on New York Times (NYT) data. Our standard treatment defines a document as one full article, but we ad-ditionally train models on a segmented version of the corpus (NYT-S) where each article is broken into 100-word segments. In addition, we include models with unoptimized hyperparameters (NYT-U), set as�kαk = 5andβ = 0.01.
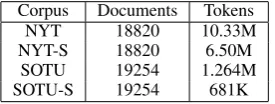
Corpus Documents Tokens
NYT 18820 10.33M
NYT-S 18820 6.50M
SOTU 19254 1.264M
SOTU-S 19254 681K
Table 1: Details of the New York Times (NYT) and State of the Union (SOTU) corpora used for topic modeling. We experiment a fixed English stoplist of 524 words to remove stopwords (-S). We use the full SOTU corpus for training.
4.1 Mutual Information
In Figure 1, we examine topic-document mutual information for different sized sets of stopwords removed before and after training the model. By removing stopwords before training, we obtain a slightly higher MI(d, k) than removing stop-words after training, in support of hypothesis 1 in Section 2. However, this difference is relatively small compared to including more stopwords or changing the number of topics.
If we focus on terms besides stopwords, we can see that the effect of removing stopwords is rela-tively small. There is some difference in removing the most common stopwords, but extending a stop-list has diminishing returns, supporting hypothesis 2 in Section 2.
4.2 Log Likelihood
In order to better evaluate the effect of stopword removal on improving model training, we com-pare the inferred log-likelihood of models trained on our 1% New York Times sample on our larger 5% testing sample. As seen in Table 2, the choice of when to remove stopwords has little effect. On
Topics pre post
[image:3.595.115.253.631.683.2] [image:3.595.316.511.641.683.2]pre 1 num art museum work show artists works artist paintings exhibition gallery painting arts american collection2 num beloved paid family notice wife deaths husband late loving memorial funeral devoted service services 3 life love world story sense young man makes good style full real beautiful dark turns
[image:4.595.308.520.182.236.2]post 1 num art museum show artists work works exhibition gallery artist paintings arts painting american collection2 family president board passing love friend paid member notice jewish beloved chairman miss condolences deaths 3 book life story man books young love written world characters character work writing james author
Table 3: Example topics from 50-topic New York Times models with stopwords removed before and after training. Post-removal topics look similar but lack some more common terms found with pre-removal.
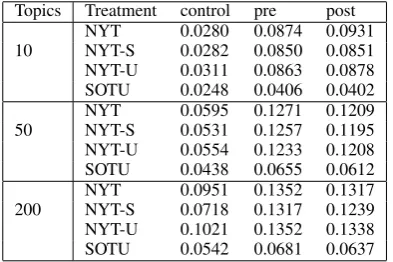
Topics Treatment control pre post 10 NYTNYT-S 0.02800.0282 0.08740.0850 0.09310.0851
NYT-U 0.0311 0.0863 0.0878 SOTU 0.0248 0.0406 0.0402
50 NYTNYT-S 0.05950.0531 0.12710.1257 0.12090.1195 NYT-U 0.0554 0.1233 0.1208 SOTU 0.0438 0.0655 0.0612 200 NYTNYT-S 0.09510.0718 0.13520.1317 0.13170.1239 NYT-U 0.1021 0.1352 0.1338 SOTU 0.0542 0.0681 0.0637
Table 4: The average NPMI scores for New York Times and State of the Union data. Surprisingly, with 10 topics, post-removal of stopwords often produces better coherence.
the New York Times held-out dataset, the effect of post-removing stopwords after training is statis-tically indistinguishable from pre-removing them. This supports hypothesis 2 in Section 2, that stop-words are not actually significantly affecting the model inference process for other terms.
4.3 Coherence
We report the average NPMI scores for the New York Times and State of the Union data in Table 4. While removing stopwords from the top keys for coherence evaluation improves model coher-ence over the control, again, the choice of when the stopwords are removed from the vocabulary seems to have very little effect. Especially for only 10 topics, coherence of models where stopwords were removed after training can slightly outper-form models with pre-removal. This finding sup-ports hypothesis 2 over hypothesis 1 in Section 2: though removal of stopwords before training im-proves automatically-evaluated coherence, when
they are removed has little impact.
4.4 Classification with Key Terms
We use the 15 most probable words from each 50-topic model on New York Times sample data to train a logistic regression classifier to
recog-control pre post
[image:4.595.85.282.183.314.2]NYT 47.1±0.3% 69.4±0.2% 69.9±0.2% NYT-S 47.1±0.2% 54.0±0.2% 53.3±0.1% NYT-U 62.6±0.3% 69.8±0.2% 69.8±0.2% SOTU 43.8±0.3% 48.7±0.2% 48.8±0.2%
Table 5: Classification results using top terms of 50-topic models on NYT and SOTU data. Remov-ing stopwords is often equally effective before and after training.
nize the most prominent topic for each document. We use 10-fold cross validation to compute accu-racy, which we report in Table 5. Unsurprisingly, removing stopwords at some stage improves the classification accuracy of key terms. However, we note that removing terms before training is signif-icantly better only for one of the four treatments (NYT-S) and is actually significantly worse than removing after for the standard NYT setting. This again supports hypothesis 2 in Section 2: remov-ing the stopwords before trainremov-ing does not alter the distinctiveness of topics based on high-probability terms.
Examples of topics in Table 3 provide some depth to understanding these results. Topic 1 is nearly identical across the two treatments, while topic 3 uses terms clearly from reviews when stop-words are removed before that seem to be lost when stopwords are removed afterwards. Anec-dotally, common content words appear not to be modeled as well when stopwords are present.
5 Conclusion
Our results demonstrate that, as per our second hypothesis, removing stopwordsafter training is generally just as effective as removing them be-fore. Rather than leading the model to infer more coherent topics by removing words that we expect to have no content, removing stopwords appears to simply reduce the amount of probability mass and smoothing of the model caused by frequent non-topic-specific terms.
stoplist to remove rarer contentless words provides relatively little utility to training a model. To ob-tain the benefit of a stoplist, it suffices to remove the most frequent, obvious stopwords from a cor-pus without developing a specific stoplist for the problem setting. If these methods are not suf-ficient, we find that post-hoc stopword removal can significantly improve coherence while avoid-ing many of the efficiency and epistemological bias issues of iterative stoplist curation. We be-lieve this result will be beneficial for researchers in other fields navigating the pragmatics of using topic models for their own investigations.
6 Acknowledgments
This work was supported by the Department of Defense (DoD) through the National Defense Sci-ence & Engineering Graduate Fellowship (ND-SEG) Program and a fellowship from the Alfred P. Sloan Foundation.
References
Nikolaos Aletras and Mark Stevenson. 2013. Evaluat-ing topic coherence usEvaluat-ing distributional semantics. InProceedings of the 10th International Conference on Computational Semantics (IWCS 2013) – Long Papers, pages 13–22, Potsdam, Germany, March. Association for Computational Linguistics.
David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet allocation. The Journal of Machine Learning Research, 3:993–1022, March. Jonathan Chang, Sean Gerrish, Chong Wang, Jordan L.
Boyd-Graber, and David M. Blei. 2009. Reading tea leaves: How humans interpret topic models. In Y. Bengio, D. Schuurmans, J. D. Lafferty, C. K. I. Williams, and A. Culotta, editors,Advances in Neu-ral Information Processing Systems 22, pages 288– 296. Curran Associates, Inc.
Mark Dredze, Hanna M. Wallach, Danny Puller, and Fernando Pereira. 2008. Generating summary key-words for emails using topics. InProceedings of the 13th International Conference on Intelligent User Interfaces, IUI ’08, pages 199–206, New York, NY, USA. ACM.
Jey Han Lau, David Newman, and Timothy Baldwin. 2014. Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. InProceedings of the 14th Conference of the Euro-pean Chapter of the Association for Computational Linguistics, pages 530–539, Gothenburg, Sweden, April. Association for Computational Linguistics. Andrew K. McCallum. 2002. MALLET: a
ma-chine learning for language toolkit. Available at: http://mallet.cs.umass.edu.
David Mimno, Hanna Wallach, Edmund Talley, Miriam Leenders, and Andrew McCallum. 2011. Optimizing semantic coherence in topic models. In
Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 262–272, Edinburgh, Scotland, UK., July. Associ-ation for ComputAssoci-ational Linguistics.
Evan Sandhaus. 2008. The New York Times anno-tated corpus. Linguistic Data Consortium, DVD: LDC2009T19.
Hanna M. Wallach, David M. Mimno, and Andrew Mc-Callum. 2009a. Rethinking LDA: Why priors mat-ter. In Y. Bengio, D. Schuurmans, J. D. Lafferty, C. K. I. Williams, and A. Culotta, editors,Advances in Neural Information Processing Systems 22, pages 1973–1981. Curran Associates, Inc.