Low Overhead Checkpointing Protocols for
Mobile Distributed Systems: A Comparative
Study
Rachit Garg1, Praveen Kumar2
1
Singhania University, Department of Computer Science & Engineering, Pacheri Bari (Rajasthan), India
2
Meerut Institute of Engineering & Technology, Department of Computer Science & Engineering, Meerut (INDIA)-125005
rachit.gargyahoo.com
Abstract
In Mobile Distributed systems, we come across some issues like: mobility, low bandwidth of wireless channels and lack of stable storage on mobile nodes, disconnections, limited battery power and high failure rate of mobile nodes. Fault Tolerance Techniques enable systems to perform tasks in the presence of faults. The likelihood of faults grows as systems are becoming more complex and applications are requiring more resources, including execution speed, storage capacity and communication bandwidth. A checkpoint is a local state of a process saved on stable storage. In a distributed system, since the processes in the system do not share memory, a global state of the system is defined as a set of local states, one from each process. In case of a fault in distributed systems, checkpointing enables the execution of a program to be resumed from a previous consistent global state rather than resuming the execution from the beginning. In this way, the amount of useful processing lost because of the fault is significantly reduced. Checkpointing is an effective fault tolerant technique in distributed system as it avoids the domino effect and require minimum storage requirement. Most of the earlier coordinated checkpoint algorithms block their computation during checkpointing and forces minimum-process or non-blocking even though many of them may not be necessary or non-blocking minimum-process but takes useless checkpoints or reduced useless checkpoint but has higher synchronization message overhead or has high checkpoint request propagation time. In this paper, we present a survey of some checkpointing algorithms for distributed systems.
KEYWORDS
Fault tolerance, coordinated checkpointing, message logging and mobile distributed system.
1. Introduction
As the technologies of processors and networks have rapidly been developed, message passing systems consisting of networked computers can provide supercomputer like performance parallel and distributed computing environments. However, as the systems scale up, their failure probability may also be higher. Especially, if long running applications are executed on the systems, the failure probability becomes significant. Thus, the systems require techniques for supporting fault tolerance. Checkpoint is defined as a designated place in a program at which normal process is interrupted specifically to preserve the status information necessary to allow resumption of processing at a later time. A checkpoint is a local state of a process saved on stable storage. By periodically invoking the checkpointing process, one can save the status of a program at regular intervals [3], [4]. If there is a failure, one may restart computation from the last checkpoints, thereby, avoiding repeating computation from the beginning. The process of resuming computation by rolling back to a saved state is called rollback recovery. In a distributed system, since the processes in the system do not share memory, a global state of the system is defined as a set of local states, one from each process. The state of channels corresponding to a global state is the set of messages sent but not yet received [5].
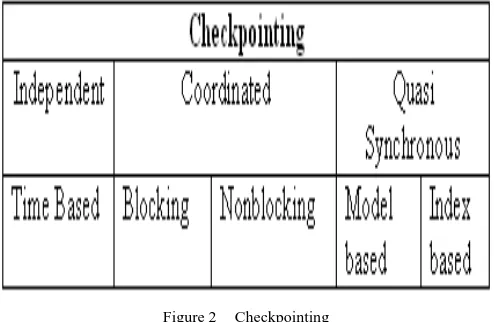
To recover from a failure, the system restarts its execution from a previous consistent global state saved on the stable storage during fault-free execution. In distributed systems, checkpointing can be independent, coordinated [3], [6] or quasi synchronous [2], as shown in figure 2. Message Logging is also used for fault tolerance in distributed systems [5]. Under the asynchronous approach, checkpoints at each process are taken independently without any synchronization among the processes. Because of absence of synchronization, there is no guarantee that a set of local checkpoints taken will be a consistent set of checkpoints. It may require cascaded rollbacks that may lead to the initial state due to domino-effect [5].
Figure 2 Checkpointing
In coordinated or synchronous Checkpointing, processes take checkpoints in such a manner that the resulting global state is consistent. Mostly it follows two-phase commit structure [3], [8]. In the first phase, processes take tentative checkpoints and in the second phase, these are made permanent. The main advantage is that only one permanent checkpoint and at most one tentative checkpoint is required to be stored. In the case of a fault, processes rollback to the last checkpointed state. It avoids the domino-effect without requiring all checkpoints to be coordinated [2], [5]. In these protocols, processes take two kinds of checkpoints, local and forced. Local checkpoints can be taken independently, while forced checkpoints are taken to guarantee the eventual progress of the recovery line and to minimize useless checkpoints. Pj is directly dependent upon Pk only if there exists m such that Pj receives m from
Pk in the current CI and Pk has not taken its permanent checkpoint after sending m. A process Pi is in the minimum set only if checkpoint initiator process is transitively dependent upon it. In minimum-process coordinated checkpointing algorithms, only a subset of interacting processes (called minimum set) are required to take checkpoints in an initiation.
A checkpointing algorithm executes in parallel with the underlying computation. Therefore, the overheads introduced due to checkpointing should be minimized. Checkpointing should enable a user to recover quickly and not lose substantial computation in case of an error, which necessitates frequent checkpointing and consequently significant overhead. The number of checkpoints initiated should be such that the cost of information loss due to failure is small and the overhead due to checkpointing is not significant. These depend on the failure probability and
P0
P1
P2
m1
m2
m3
Checkpoint
the importance of computation. For example, in transaction processing system when every transaction is important and information loss is not permitted, a checkpoint may be taken after every transaction, increasing the checkpoint overhead significantly [16].
The state of a process has to be saved in stable storage so that the process can be restarted in case of an error. The state/context includes code, data, and stack segments along with the environment and the register contents. Environment has the information about the various files currently in use and the file pointers. In case of message passing systems, environment variables include those messages which are sent and not yet received. The information that is necessary to resume a computation after it is pre-empted is called the context of that computation [16].
During a failure free run, every global checkpoint incurs coordination overhead and context saving overhead in a multiprocessor system. In parallel/distributed systems, coordination among processes is needed to obtain a consistent global state. Special messages and piggybacked information with regular messages are used to obtain coordination among processes. Coordination overhead is due to special control messages and piggybacked information. The book-keeping operations necessary to maintain coordination also contribute to coordination overhead. The time taken to save the global context of a computation is defined as the context saving overhead. If stable storage is not available with every node in a multiprocessor system, the context is transferred over the network. Network transmission delay is also included in the overhead [16].
Besides its use to recover from failures, checkpointing is also used in debugging distributed programs and migrating processes in multiprocessor system. In debugging distributed programs, state changes of a process during execution are monitored at various time instances. Checkpoints assist in such monitoring. To balance the load of processors in the distributed system, processes are moved from heavily loaded processors to lightly loaded ones. Checkpointing a process periodically provides the information necessary to move it from one processor to another [16]. With checkpointing, an arbitrary temporal section of a program’s runtime can be extracted for exhaustive analysis without the need to restart the program from beginning.
An Example
In figure 3, P0 takes its tentative checkpoint and sends message mi to P1. P1 has neither taken its tentative checkpoint
nor received any checkpointing request from any other process. By the piggybacked information along with mi and
certain other data structures, P1 concludes that P0 has taken its tentative checkpoint for some new initiation.
In this case if P1 takes its checkpoint after processing mi, mi will become orphan. Therefore, P1 will take a forced
checkpoint (say induced Checkpoint) before processing mi. This checkpoint is different from tentative checkpoint as
it will be stored on the disk of MH, in case of MH. The induced checkpoint is similar to mutable checkpoint. If P1
does not receive any checkpointing request during the current initiation, P1 will discard it on commit. In this case, if
it found that P1 has not sent any message to any process since its last committed checkpoint, then P1 will process mi
without taking its induced checkpoint. Because, we can say that P1 will not be included in the minimum set in this
Message Logging
In general in a system using message logging [15] and checkpointing to provide fault tolerance each message received by a process is recorded in a message log and the state of each process is occasionally saved as a checkpoint. Each process is checkpointed individually and no coordination is required between the checkpointing of different processes. The logged messages and checkpoints are stored in some way that survives any failures that the system is intended to recover from, such as by writing them to stable storage on disk. Recovery of a failed process using these logged messages and checkpoints is based on the assumption that the execution of the process is deterministic between received input messages. That is if two processes start in the same state and receive the same sequence of input messages they must produce the same sequence of output messages and must finish in the same state. The state of a process is thus completely determined by its starting state and by the sequence of messages it has received. A failed process is restored using some previous checkpoint of the process and the log of messages received by that process after that checkpoint and before the failure, First the state of the failed process is reloaded from the checkpoint onto some available processor. The process is then allowed to begin execution and the sequences of logged messages originally received by the process after this checkpoint are replayed to it from the log. These replayed messages must be received by the process during recovery in the same order in which they were received before the failure. The recovering process then re-executes from this checkpointed state based on the same input messages in the same order and thus deterministically reaches the state it was in after this sequence of messages was originally received. During this re-execution the process will resend any messages that it sent during this same execution before the failure. These duplicate messages must be detected and ignored by their receivers or must not be allowed by the system to be transmitted again during recovery. The protocols used for message logging can be divided into two groups called pessimistic message logging and optimistic message logging according to the level of synchronization imposed by the protocol on the execution of the system. This characteristic of the message logging protocol used in a system also determines many characteristics of the checkpointing and failure recovery protocols required.
Pessimistic Message Logging
Pessimistic Message Logging [15] ensures that if a process fails all messages received by it since its last checkpoint, are logged regardless of when the failure occurs. Failure recovery in a system using pessimistic message logging is straightforward. A failed process is always restarted from its most recent checkpoint and all messages received by that process after the checkpoint are replayed to it from the log in the same order in which they were received before the failure Based on these messages the process deterministically re-executes from the state restored from its checkpoint to the state it was in at the time of the failure.
Optimistic Message Logging
In contrast to pessimistic protocols [15]optimistic message logging protocols operate asynchronously. The receiver of a message is not blocked and messages are logged after receipt. For example by grouping several messages and writing them to stable storage in a single operation. However the current state of a process can only be recovered if all messages received by the process since its last checkpoint have been logged and thus some execution of a failed process may be lost if the logging has not been completed before a failure occurs. These protocols are called optimistic because they assume that the logging of each message received by a process will be completed before the process fails. As with pessimistic message logging each failed process is then recovered individually and no process other than those that failed are rolled back during recovery.
Causal Message Logging
logging ones. Second, each process logs a determinant of each received message and ones piggybacked on it in the volatile memory. Therefore, causal message logging protocols have the advantage of optimistic message logging ones. Some causal logging protocols prevent live processes from continuing executing during recovery in case of concurrently multiple failures or require some synchronous logging to the stable storage while recovery is on going, which may reduce the speed of the computation of the entire system. Elnozahy’s protocol solves the problems. However, it requires a central recovery leader, which may be a performance bottleneck. Moreover it results in nontrivial election overhead and if the leader has filed continuously before it completes its recovery procedure, the other recovering processes should continue being blocked. Additionally, if it were integrated with asynchronous checkpointing, it could result in inconsistency problems in case of concurrently multiple failures.
2. System Model and Background
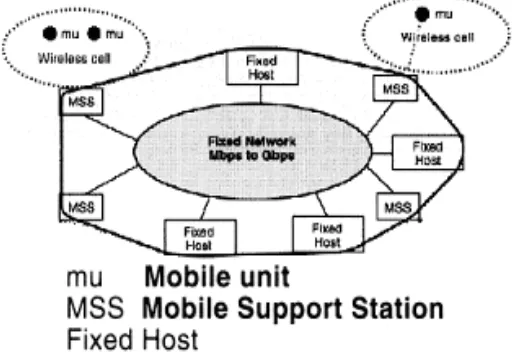
A distributed system is a collection of processes that communicate with each other by exchanging messages. A distributed system consists of a collection of autonomous computers, connected through a network and distribution middleware, which enables computers to co-ordinate their activities and to share the resources of the system, so that users perceive the systems as a single, integrated computing facility. Recent years have witnessed rapid development of mobile communications. In the future, we will expect more and more people will use some portable units such as notebooks or personal data assistants. A mobile distributed computing system is a distributed system where some of the processes are running on mobile hosts (MHs). The term “mobile” implies able to move while retaining its network connections. A host that can move while retaining its network connections is an MH. An MH communicates with other nodes of the system via a special node called mobile support station (MSS) [1], [2], [6], [7]. An MH can directly communicate with an MSS (and vice versa) only if the MH is physically located within the cell serviced by the MSS. A cell is a geographical area around an MSS in which it can support an MH. An MH can change its geographical position freely from one cell to another or even to an area covered by no cell. At any given instant of time, an MH may logically belong to only one cell; its current cell defines the MH’s location, and the MH is considered local to the MSS providing wireless coverage in the cell. An MSS has both wired and wireless links and acts as an interface between the static network and a part of the mobile network. Static network connects all MSSs. A static node that has no support to MH can be considered as an MSS with no MH. Critical applications are required to execute fault-tolerantly on such systems [1], [2], [5], [20]. The system model (as shown in figure 4) for supporting host mobility consists of two distinct sets of entities: a large number of MHs and relatively fewer numbers of MSSs. All fixed hosts and the communication path between them constitute the static/fixed network. The fixed network connects islands of wireless cells, each comprising of an MSS and the local MHs. The static network provides reliable, sequenced delivery of messages between any two MSSs, with arbitrary message latency. Similarly, the wireless network within a cell ensures FIFO delivery of messages between an MSS and a local MH, i.e., there exists a FIFO channel from an MH to its local MSS, and another FIFO channel from the MSS to the MH. If an MH did not leave the cell, then every message sent to it from the local MSS would be received in the sequence in which they are sent [1], [2], [6], [7].
Message communication from an MH MH1 to another MH MH2 occurs as follows. MH1 first sends the message to its local MSS MSS1 using the wireless link. MSS1 forwards it to MSS2, the local MSS of MH2, via the fixed network. MSS2 then transmits it to MH2 over its wireless network. However, the location of MH2 may not be known to MSS1, therefore, MSS1 may require to first determining the location of MH2. This is essentially the problem faced by network layer routing protocols [11], [18]. Mobile Hosts often disconnect from the rest of the network. In our model, disconnection is distinct from failure. Disconnections are elective or volunteer by nature, so a mobile host informs the system prior to its occurrence and executes an application-specific disconnection protocol if necessary [2]. Disconnection can be voluntary on involuntary. We use the term “disconnection” to always imply a voluntary disconnection. We refer to an abrupt or involuntary disconnection as a failure.
Other Aspects of Mobile Hosts
The mobile hosts have several aspects that make them different from fixed hosts. Any approach for adding fault-tolerance to mobile environments should consider these distinct features:
Location is not fixed
When the user moves from one place to another, Mobility can also cause wireless connections to be lost or degraded. The check point protocol can store the processes states in a well known site or in a computer near the current location of the mobile host. Also the check point protocol has to keep track of the places where processes states were saved.
Disconnection
Network failure is a greater concern in mobile computing when a mobile host goes outside the transmitting range of the emitter, then the host becomes disconnected. At that stage the host is not able to send or receive any messages. During such a situation any protocol that need to exchange messages to coordinate checkpoint creation or the roll back recovery will not work correctly. During disconnection, the mobile host will not receive any information that is stored in the remote site.
Limited Amount of Power
Batteries in mobile host have lower power storage. Disk accesses and network transmission are major sources of power consumption. To minimize power consumption the checkpoint protocol should avoid sending extra messages and make a small number of accesses to Disk.
Low Bandwidth
Wireless networks deliver lower bandwidth than wired networks Network bandwidth is divided among the users sharing a cell. Improving network capacity means installing more wireless cells to service a user population. There are two ways for this: Firstly overlap the cells on different wavelengths and secondly reduce transmission ranges so that more cells fit in a given area. In the first case, as the scalability is limited because electro-magnetic spectrum is scarce for public consumption. Secondly, as more cells fit into the given area, it may decrease signal corruption due to less environment has few objects to interact with.
Variable High Bandwidth
Variable traffic load often causes variation in bandwidth on the networks. Much greater variation lies in the network bandwidth when we compare mobile computing design to a traditional design. In contrast to a fixed computers which stay connected to a single network where a mobile computer may encounter many heterogeneous connections at once.
3 Summary of Related Works
In Kumar-et al [20] proposed a non-blocking checkpointing algorithm based on keeping track of direct dependencies of processes. Each process maintains a direct dependency vector. In their scheme, initiator process collects the direct dependency vectors of all processes, computes minimum set, and sends the checkpoint request along with the minimum set to relevant processes. This reduces the time to take the checkpoints. If new dependencies are created during checkpointing process, those are updated and updated minimum set is formed.
are logged by the receiving processor. Upon failure, all processors rollback to their checkpoints and replay messages from their logs.
Silva and Silva [21] proposed all process coordinated checkpointing protocol for distributed systems. The non- intrusiveness during checkpointing is achieved by piggybacking monotonically increasing checkpoint number along with computational message. When a process receives a computation message with the higher checkpoint number, it takes its checkpoint before processing the message. When it actually gets the checkpoint request from the initiator, it ignores the same. If each process of the distributed programs is allowed to initiate checkpoint operation, the network may be flooded with control messages and processes might waste their time making unnecessary checkpoints. In order to avoid this. Silva and silva give the key to initiate checkpoint algorithm to one process. The checkpoint event is triggered periodically by a local timer mechanism. When this timer expires, the initiator process checkpoints the state of processes running in its machine and forces all the others to take checkpoint by sending a broadcast message. The interval between adjacent checkpoints is called the checkpoint interval.
Koo- Toueg’s [17] proposed a minimum process blocking checkpointing algorithm for distributed systems. The algorithm consists of two phases. During the first phase, the checkpoint initiator identities all processes with which it has communicated since the last checkpoint and sends them a request. Upon receiving the request, each process in turn identifies all process it has communicated with since the last checkpoint and sends them a request, and so on, until no more processes can be identified. During the second phase, all processes identified in the first phase take a checkpoint. The result is a consistent checkpoint that involves only the participate processes. In this protocol, after a process takes a checkpoint, it can not send any message until the second phase terminates successfully, although, receiving messages after the checkpoint is permissible.
Venkatesan [22], [23], [24] proposed the following approach execute an algorithm to record an intermental snapshot since the most recent snapshot was taken and combine it with the most recent snapshot to obtain the latest snapshot of the system. The algorithm works as follows snapshots are assigned version numbers and all messages carry this version number. The initiator notifies all the processes the version number of the new snapshot by sending init snap messages along the spanning tree edges. A process follows the “marker sending rule” when it receives this notification or when it receives a regular message with a new version number. The “marker sending rules” is modified so that the process sends regular message along with only those channels on which it has sent computation messages since the previous snapshot and the process waits for ack messages in response to these regular message. When a leaf process in the spanning tree receives the entire ack message it expects. It sends a snap completed message its parent process. When a non-leaf process in the spanning tree receives all the ack messages it expects, as well as a snap completed message from each of its child processes. It sends a snap completed message to its parent process. The algorithm terminates when the initiator has received all the ack messages expects as well as a snap completed message from each of it child processes.
Garg., R and Kumar, P [26] proposed a nonblocking coordinated checkpointing algorithm for mobile computing systems, which requires only a minimum number of processes to take permanent checkpoints. They reduce the message complexity as compared to the Cao-Singhal algorithm, while keeping the number of useless checkpoints unchanged. They also address the related issues like: failures during checkpointing, disconnections, concurrent initiations of the algorithm and maintaining exact dependencies among processes. Finally, they presented an optimization technique, which significantly reduces the number of useless checkpoints at the cost of minor increase in the message complexity. In coordinated checkpointing, if a single process fails to take its tentative checkpoint; all the checkpoint efforts were aborted. They try to reduce this effort by taking soft checkpoints in the first phase at Mobile Hosts. They have proposed a nonblocking coordinated checkpointing protocol for mobile distributed systems, where only minimum number of processes takes permanent checkpoints. They have reduced the message complexity as compared to Cao-Singhal algorithm, while keeping the number of useless checkpoints unchanged. The proposed algorithm was designed to impose low memory and computation overheads on MHs and low communication overheads on wireless channels. An MH can remain disconnected for an arbitrary period of time without affecting checkpointing activity. They address the issues like: failures during checkpointing, disconnections, maintaining exact dependencies among processes, and concurrent initiations. They also try to minimize the loss of checkpointing effort if some process fails to take its checkpoint in the first phase but it will increase the synchronization overhead.
reliable stable storage on mobile nodes. They addressed the problem of fault tolerant computing in mobile distributed systems.
Kumar P, and Garg R [28] proposed a hybrid checkpointing algorithm, wherein, an allprocess coordinated checkpoint was taken after the execution of minimum-process coordinated checkpointing algorithm for a fixed number of times. In minimum-process checkpointing, they try to reduce the number of useless checkpoints and blocking of processes. They have proposed a probabilistic approach to reduce the number of useless checkpoints. Thus, the proposed protocol was simultaneously able to reduce the useless checkpoints and blocking of processes at very less cost of maintaining and collecting dependencies and piggybacking checkpoint sequence numbers onto normal messages. Concurrent initiations of the proposed protocol do not cause its concurrent executions. They try to reduce the loss of checkpointing effort when any process fails to take its checkpoint in coordination with others.
Kumar P, and Garg R [29] have witnessed rapid development of mobile communications and become part of everyday life for most people. They proposed a hybrid checkpointing algorithm, where they tried to reduce the loss of checkpointing effort when any process fails to take its checkpoint in coordination with others. They reduced the size of checkpoint sequence number piggybacked on each computation message.
Garg, R., and Kumar P [30]they discussed various issues related to the checkpointing for distributed systems and mobile computing environments. They present a survey of some checkpointing algorithms for distributed systems. The main aim of improving the earlier extensions of the Chandy & Lamport (1985) algorithms was to minimize the overhead of coordination between processes in a multiprocessor system. More recent published work discussed in this paper attempts to minimise the context-saving overhead.
Xu and Netzer [18] introduced the notion of Zig/Zag paths; a generalization of Lamport’s happened before relation and shown that notation of Zig/Zag path captures exactly the conditions for a set of checkpoints to belong to the same consistent global snapshot. They had shown that a set of checkpoints can belong to the same consistent global snapshot if no Zigzag path exists from a checkpoint to any other.
Hélary’s snapshot algorithm [12] uses the concept of message waves. A wave is a flow of control messages such that every process in the system is visited exactly once by a wave control message and at least one process in the system can determine when this flow of control message terminates. A wave is initiated after the previous wave terminates. Wave sequences may be implemented by various traversal structures such as a ring. A process begins recording the local snapshot when it is visited by the wave control message.
Kumar al [19] proposed an all process non intrusive checkpointing protocol for distributed systems. Where just one but is piggy backed onto normal messages. This is done by incurring extra overhead of vector transfer during checkpointing.
Higaki-Takizawa [13] proposed a hybrid checkpointing protocol for mobile computing system. It is a hybrid of independent and coordinated checkpointing. The mobile Hosts take the checkpoint independently whereas the fixed stations take the coordinated checkpoint. The messages sent and received by MHs are stored in corresponding MSS. The algorithm has two defects. First, using independent checkpoint protocol may cause the domino effect. Second, coordinated and independent checkpointing protocols perform independently in mobile support stations and mobile hosts, and do not negotiate with each other. Therefore, it is difficult to obtain consistent global checkpoints.
Alvisi et. Al. [3] developed a message logging protocol that introduces no additional blocking to the application and does not create orphan states. This protocol only sends the application messages and their acknowledgements. Their protocol does not use any more messages in a failure-=free run than a message delivery protocol for a system in which transient link failures can occur but processes do not crash. This scheme may make application messages arbitrarily larger, but it is claimed that average amount of overhead is small. The major limitation of this scheme is that it can only with stand a sequence of process crash, process recovery pairs. If process P sends messages to process Q and both P and Q simultaneously crash, then orphan states may be created and Q may find itself trying to reconstruct a message for which there exists only a receive sequence number.
Elnozahy and Zwaenepoel [11] proposed a message logging protocol which uses coordinated checkpoint with message logging. The combination of message logging and coordinated checkpoint offers several advantages including improved failure free performance; bounded recovery time simplified garbage collection and reduced complexity.
Johnson and Zwaenepoel [10] proposed sender based message logging for deterministic systems where each message is logged in volatile memory on the machine from which the message is sent. The message log is then asynchronously written to stable storage without delaying the computation as part of the sender’s periodic checkpoint Johnson and Zwaenepoel [14] used optimistic message logging and checkpointing to determine the maximum recoverable state, where every received message is logged.
are called anti-messages of one another. All messages sent explicitly by user programs have a positive (+) sign; and their anti-messages have a negative sign (-). Whenever a message and its anti-message occur in the same queue, they immediately annihilate one another. Thus the result of enqueueing a message may be to shorten the queue by one message rather than lengthen it by one.
Lalit Kumar Awasthi and P.Kumar proposed algorithm is based on keeping track of direct dependencies of processes. Initiator MSS collects the direct dependency vectors of all processes, computes the tentative minimum set (minimum set or its subset), and sends the checkpoint request along with the tentative minimum set to all MSSs. This step is taken to reduce the time to collect the coordinated checkpoint. It will also reduce the number of useless checkpoints and the blocking of the processes. Suppose, during the execution of the checkpointing algorithm, Pi
takes its checkpoint and sends m to Pj. Pj receives m such that it has not taken its checkpoint for the current initiation and it does not know whether it will get the checkpoint request. If Pj takes its checkpoint after processing
m, m will become orphan. In order to avoid such orphan messages, they propose the following technique. If Pj has sent at least one message to a process, say Pk and Pk is in the tentative minimum set, there is a good probability that
Pj will get the checkpoint request. Therefore, Pj takes its induced checkpoint before processing m. An induced checkpoint is similar to the mutable checkpoint. In this case, most probably, Pj will get the checkpoint request and its induced checkpoint will be converted into permanent one. There is a less probability that Pj will not get the checkpoint request and its induced checkpoint will be discarded. Alternatively, if there is not a good probability that
Pj will get the checkpoint request, Pj buffers m till it takes its checkpoint or receives the commit message. They have tried to minimise the number of useless checkpoints and blocking of the process by using the probabilistic approach and buffering selective messages at the receiver end. Exact dependencies among processes are maintained. It abolishes the useless checkpoint requests and reduces the number of duplicate checkpoint requests.
Biswas, S., and Neogy, S.[31], proposed a new checkpointing and failure recovery algorithm for mobile computing system. Mobile hosts save checkpoints based on mobility and movement patterns. Movement patterns considered here are of three types – i) Intercell movement pattern ii) combination movement pattern ii) Intracell movement pattern. Mobile hosts save checkpoints when number of hand-off exceeds a predefined hand-off threshold value. Disconnection was a frequent phenomenon and was of two types: i) planned disconnection ii) unplanned disconnection. Hence mobile hosts save two types of checkpoints - i) permanent checkpoint based on hand-off threshold value covering unplanned disconnection ii) migration checkpoint covering planned disconnection. Hand-off threshold was a function mobility rate, movement pattern, message passing frequency and failure rate.
They proposed checkpointing algorithm which was in comparison with other relevant works because it was designed based not only on mobility and hand-off of MHs but movement patterns were also considered. Unike others, MHs moving within a cell was checkpointed exclusively. Hence, their checkpointing scheme was stronger from the point of view of failure recovery. Disconnection of MHs was a frequent phenomenon which may delay checkpointing. Hence the concept of migration checkpoint was introduced before planned disconnection so that checkpointing can be completed without any dealy resulting enhanced fault tolerance in the proposed scheme.
3. CONCLUSION
Distributed mobile systems pose new challenging problems in designing fault tolerant systems because of the dynamics of mobility and limited bandwidth available on wireless links. Traditional fault tolerance techniques cannot be applied to these systems. As the checkpointing scheme saves the status of system at some intermediate points (Checkpoints) and a rollback to the latest saved state is done at the occurrence of a failure. Therefore, it reduces the rollback portion through at the cost of additional overheads for checkpoints. In this paper we have reviewed and compared different checkpointing schemes, independent, coordinated and communication induced checkpointing, Message Logging and other logging techniques. More general approaches showing the effect of the checkpointing protocols on mobile distributed systems may also be considered for further study.
References
[1]Acharya A. and Badrinath B. R., “Checkpointing Distributed Applications on Mobile Computers,” Proceedings of the 3rd International Conference on Parallel and Distributed Information Systems, pp. 73-80, September 1994.
[2]Acharya A., “Structuring Distributed Algorithms and Services for networks with Mobile Hosts”, Ph.D. Thesis, Rutgers University, 1995. [3]Alvisi, Lorenzo and Marzullo, Keith,“ Message Logging: Pessimistic, Optimistic, Causal, and Optimal”, IEEE Transactions on Software Engineering, Vol. 24, No. 2, February 1998, pp. 149-159.
[4]L. Alvisi, Hoppe, B., Marzullo, K., “Nonblocking and Orphan-Free message Logging Protocol,” Proc. of 23rd Fault Tolerant Computing Symp., pp. 145-154, June 1993.
[6]G. Barigazzi and L. Strigni, “ Application-Transparent Setting of Recovery Points”, Digest of Papers Fault Tolerant Computing Systems-13, pp. 48-55, 1983.
[7]Badrinath B. R, Acharya A., T. Imielinski “Structuring Distributed Algorithms for Mobile Hosts”, Proc. 14th Int. Conf. Distributed Computing Systems, June 1994.
[8]Chandy K. M. and Lamport L., “Distributed Snapshots: Determining Global State of Distributed Systems,” ACM Transaction on Computing Systems, vol. 3, No. 1, pp. 63-75, February 1985.
[9]David R. Jefferson, “Virtual Time”, ACM Transactions on Programming Languages and Systems, Vol. 7, NO.3, pp 404-425, July 1985. [10] Elnozahy and Zwaenepoel W, “ Manetho: Transparent Roll-back Recovery with Low-overhead, Limited Rollback and Fast Output Commit,” IEEE Trans. Computers, vol. 41, no. 5, pp. 526-531, May 1992.
[11] Elnozahy and Zwaenepoel W, “ On the Use and Implementation of Message Logging,” 24th int’l Symp. Fault Tolerant Computing, pp. 298-307, IEEE Computer Society, June 1994.
[12] Hélary J. M., Mostefaoui A. and Raynal M., “Communication-Induced Determination of Consistent Snapshots,” Proceedings of the 28th International Symposium on Fault-Tolerant Computing, pp. 208-217, June 1998.
[13] Higaki H. and Takizawa M., “Checkpoint-recovery Protocol for Reliable Mobile Systems,” Trans. of Information processing Japan, vol. 40, no.1, pp. 236-244, Jan. 1999.
[14] Johnson, D.B., Zwaenepoel, W., “Recovery in Distributed Systems using optimistic message logging and checkpointing. In 7th ACM Symposium on Principles of Distributed Computing, pp 171-181, 1988.
[15] D. Johnson, “Distributed System Fault Tolerance Using Message Logging and Checkpointing,” Ph.D. Thesis, Rice Univ., Dec. 1989. [16] Kalaiselvi, S., Rajaraman, V., “A Survey of Checkpointing Algorithms for Parallel and Distributed Systems”, Sadhna, Vol. 25, Part 5, October 2000, pp. 489-510.
[17] Koo R. and Toueg S., “Checkpointing and Roll-Back Recovery for Distributed Systems,” IEEE Trans. on Software Engineering, vol. 13, no. 1, pp. 23-31, January 1987.
[18] Netzer, R.H. and Xu,J ,“Necessary and Sufficient Conditions for Consistent Global Snapshots”, IEEE Trans. Parallel and Distributed Systems 6,2, pp 165-169, 1995.
[19] Parveen Kumar, Lalit Kumar, R K Chauhan, V K Gupta “A Non-Intrusive Minimum Process Synchronous Checkpointing Protocol for Mobile Distributed Systems” Proceedings of IEEE ICPWC-2005, January 2005.
[20] Parveen Kumar, Lalit Kumar, R K Chauhan, “Synchronous Checkpointing Protocols for Mobile Distributed Systems: A Comparative Study”, International Journal of information and computing science, Volume 8, No.2, 2005, pp 14-21.
[21]Silva, L.M. and J.G. Silva, “Global checkpointing for distributed programs”, Proc. 11th symp. Reliable Distributed Systems, pp. 155-62, Oct. 1992.
[22] S. Venketasan and T.Y. Juang, “Efficient Algorithms for Optimistic Crash recovery”, Distributed Computing, vol. 8, no. 2, pp. 105-114, June 1994.
[23] S. Venketasan, “Message-Optimal Incremental Snapshots”, Computer and Software Engineering, vol.1, no.3, pp. 211-231, 1993. [24] S. Venketasan, “ Optimistic Crash recovery Without Rolling back Non-Faulty Processors”, Information Sciences, 1993.
[25]Parveen Kumar, “A Low-Cost Hybrid Coordinated Checkpointing Protocol for mobile distributed systems”, Mobile Information Systems, pp 13-32, Vol. 4, No. 1, 2007.
[26] Garg., R and Kumar, P., ”A Nonblocking Coordinated Checkpointing Algorithm for Mobile Computing Systems, International Journal of Computer Science Issues, Vol. 7, Issue 3, No 3, May 2010
[27] Garg., R and Kumar, P., ” A Review of Fault Tolerant Checkpointing Protocols for Mobile Computing Systems”, International Journal of Computer Applications, Volume 3 – No.2, June 2010.
[28]Kumar P, and Garg R., “Soft-Checkpointing Based Coordinated Checkpointing Protocol for Mobile Distributed Systems”, International Journal of Computer Science Issues, Vol. 7, Issue 3, No 5, May 2010.
[29] Kumar P, and Garg R., “An Efficient Synchronous Checkpointing Protocol for Mobile Distributed Systems”, Global Journal of Computer Science and Technology, Vol. 10 Issue 5 June/July 2010, Accepted.
[30] Garg, R., and Kumar P., “A Review of Checkpointing Fault Tolerance Techniques in Distributed Mobile Systems”, International Journal on Computer Science and Engineering, June/July 2010, Accepted.