Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1148
Tweet segmentation based on POS Tagging
1
T.Mounika, 2K.Deepika
1
M.Tech Student, Department of CSE, TallaPadmavati college of Engineering, Warangal District, Telangana, India.
2
Assiociate Professor, Department of CSE, TallaPadmavati college of Engineering, Warangal District, Telangana, India
ABSTRACT:
Twitter has become one of the most critical conversation channels with its potential imparting the most up to date and newsworthy information. considering wide use of twitter because the source of statistics, attaining an interesting tweet for user amongst a bunch of tweets is hard. A massive amount of tweets despatched per day by means of hundred tens of millions of users, statistics overload is inevitable. For extracting data in massive volume of tweets, Named Entity popularity (NER), methods on formal texts. however, many applications in records Retrieval (IR) and natural Language Processing (NLP) go through critically from the noisy and short nature of tweets.in this paper, we suggest a novel framework for tweet segmentation in a batch mode, referred to as HybridSeg through splitting tweets into meaningful segments, the semantic or context records is well preserved and without difficulty extracted by means of the downstream programs. HybridSeg unearths the foremost segmentation of a tweet through maximizing the sum of the stickiness ratings of its candidate segments. The stickiness score considers the probability of a phase being aphrase in English (i.e., global context) and the probability of a segment being a word in the batch of tweets (i.e., nearby context). For the latter, we recommend and evaluate fashions to derive neighborhood contextby considering the linguistic capabilities and term-dependency in a batch of tweets, respectively. HybridSeg is likewise designed to iteratively learn from assured segments as pseudo remarks. As an utility, we display that excessive accuracy is achieved in named entity recognition with the aid of applying segmentbased component-of-speech (POS) tagging.
key phrases: Named Entity reputation, Tweet Segmentation, Twitter move, Wikipedia.
I. introduction
Twitter, as a latest type of social mediahaving first-rate increase in latest yr. Many public and private quarter have been described to monitor Twitter movement to acquire and apprehend users’ opinion approximately groups. but, because of very largevolume of tweets published every day, it is practically infeasible and pointless to display and listen the entire Twitter move [1]. consequently, targeted Twitter streams are regularly monitored as a substitute each circulate contains tweets that possibly satisfy some facts wishes of the tracking organisation tweeter is most famous media for sharing and changing data on local and worldwide level. targeted Twitter stream is usually form by
cleansing tweets with user-described choice standards depends on want of records. section-based totally illustration is powerful over phrase-based totally illustration inside the responsibilities of named entity popularity
and event detection.the worldwide
contextobtain from internet pages or
Wikipedia so this allows to discover the
meaningful segments in tweets.
Localcontexts, having local linguistic
collocation and local capabilities [2]. observe that tweets from plenty of licensed bills of
institute, information corporations and
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1149 generated with the aid of Twitter’s thousands
and thousands of users, Named Entity recognition(NER), NER may be especially described as identifying and categorizing definite type of statistics (i.e. place, man or woman, organization names, datetime and numeric expressions) in a precise form of textual content Conversely, tweets are commonly quick andnoisy [3]. Named entity is scored via ranking of the person posting. Tweeter has attracted remarkable interests from both enterprise and academia. Many private and/or public agencies have been stated to screen Twitter circulate to collect and recognize users reviews about the
organizations.although, because of the
extremely massive quantity of tweets posted each day, it is practically infeasible and pointless to concentrate and screen the whole Twitter move. therefore, focused Twitter streams are generally monitored as an alternative; every such movement carries
tweets that potentially fulfill a few
information needs of the monitoring agency. focused Twitter flow is generally built by way of filtering tweets with person-defined choice criteria relies upon at the information
needs. targeted Twitter movement is
commonly constructed with the aid of filtering tweets with predefined choice criteria (e.g., tweets published through users from a geographical area, tweets that in shape one or greater predefined keywords). due to its worthwhile commercial enterprise value of well timed facts from those tweets, it's miles imperative to apprehend tweets’ language for a large body of downstream programs, inclusive of named entity reputation (NER)
occasion detection and summarization,
opinion mining, sentiment analysis and many others.
II. related work
ThisBoth tweet department and named element acknowledgment are viewed as essential subtasks in nlp. numerous cutting-edge nlp processes vigorously depend on phoneticelements, as an instance, pos labels of the encircling phrases,word upper casing, cause phrases (e.g., mr. dr), and gazetteers [1] [2]. these phonetic components, collectively
with successful controlled mastering
calculations (e.g., hid markov model (hmm) and contingent arbitrary subject (crf), accomplish incredible execution on formal content corpus. be that as it is able to, these approaches experience intense execution disintegration on tweets in view of the uproarious and brief nature of the ultimate stated. there were a notable perfect of endeavors to consolidate tweet's one of a type qualities into the commonplace nlp structures. To enhance put up labeling on tweets. Tritter et al. educate a postagger through utilising crf
model with routine and tweet-precise
components. Chestnut grouping is hooked up of their paintings to manipulate the badly framedwords. simple et al. fuse tweet-precise components such as at-notice, hash tags, urls, and emotions with the assistance of every other marking plan. in their method, theymeasure the certainty of uppercase phrases and apply phonetic standardizationto poorly formed phrases to address viable unconventional works in tweets [3] [4]. it became accounted for to conquer the slicing
side Stanford pos tagger on tweets.
Standardization of not nicely framed phrases in tweets has installation itself as a critical exploration trouble. A managed technique is applied into first understand the now not properly framed words. At that point, the right standardization of the badly shaped word is chosen in mild of numerous lexical
comparison measures. both directed
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1150 attention aspect terms from tweets using an
unmonitored methodology which is basically in light of poslabeling. every separated aspect expression is an applicant named substance. the short nature and blunders prone of Twitter has fetched new demanding situations to named entity reputation. This paper suggests a NER device for targeted Twitter movement, called TwiNER [5], to report this mission. In
conventional methods, TwiNER are
unsupervised. It doesn’t rely upon the unpredictable local linguistics features. as an alternative, it collectionsinformation stored from the arena extensive internet to shape strong international context and neighborhood context for tweets. Experimentaloutcomes showfavorable effects of TwiNER. It isshown to accomplish comparable performance the usage of the stateoftheart NER structures in reallife centered tweet streams. Twitter streams to combining an internet incident assessment device by using an unmonitored
event clustering method, and offline
measuremetrics for distinguish of beyond movements by means of a supervised SVM-classifier based vector approachSeveral important capabilities of each detected occasion dataset have been extracted by way of acting content material mining for content material analysis, spatial evaluation, and temporal analysis. In handling person generated content in micro blogs, a hard language difficulty discovered in messages is inside the informal English field (with no forbidden vocabulary), consisting of named entities, abbreviations, slang and context specific phrases in the content material; missing in enough context to grammar and spelling [6]. those growths the problems in semantic analysis of microblogs. Sharing and
changing rising activities on worldwide and local level one of the predominant challenges are figuring out the area whereevent is taking place. To apprehend locations availability of weibos we composed weibo data randomly. For better expertise the effect of posting place[4]The amassing and know-how web
records regarding a real-global entity
(together with a individual or a product) is
currently fulfilled manually via
searchengines. though, statistics about a man or woman entity can also seem in lots of web pages extracting and integrating the entity
data from the web is of exquisite
importance.[5] Tweets are sent for statistics verbal exchange and sharing. The named entities and semantic word is wellconserved in tweets. the worldwide context taken from net pages or Wikipedia allows to recognizing the meaningful segments in tweets. The technique knowing the deliberate framework that solely is predicated on international context is represented via HybridSegWeb. Tweets are notably timesensitive plenty of rising phrases inclusive of “he Dancin” can not be were given inexternal information bases. even though, thinking about a massive wide variety of tweets published inside a quick time period (e.g., an afternoon) having the phrase, “he Dancin” is easy to become aware of the phase and legitimate. We consequently investigate two localcontexts, mainly nearby collocation and nearby linguistic functions.The properly conserved linguistic capabilities in those tweets help named entity reputation with extra accuracy. each named entity is a valid section. The method utilising neighborhood linguistic functions is represented by means of HybridSegNER
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1151 IV. PROPOSED ALGORITHM
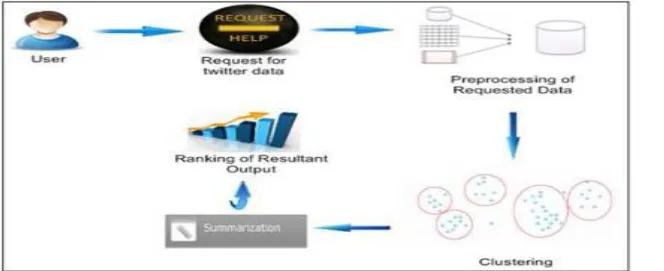
algorithm: document Summarization
input:
I1 textual content facts to which summary is important.
I2. N - for generating top N common phrases.
Output:
O1 synopsis for the specific textual content statistics
O2. Compression Ratio
O3. Retention share
Steps:
1. information Pre-processing
1. a Extract facts
1. b get rid of prevent phrase
2. Generate T
ermFrequency list
2. a acquire the N recurrent phrases
three. For all N-frequent phrases
3. a acquire the semantic like phrases for the fields, put in it to the recurrent termslist
4. Produce Sentences from unique facts
5. If the sentence includes time period found in recurrent termslist then positioned inside the sentence to synopsissentencelist.
6. Compute Compression Ratio and Retention proportion
V. conclusion
Tweet segmentation assist to stay the semantic that means of tweets, which
consequently blessings in masses
ofdownstream
programs, e.g., named entity reputation. segment-primarily based known as entity recognition strategies obtain lots higher
correctness than the wordbased
alternative.thru our system, we showcase that close by phonetic additives are
moresolid than time period reliance in managing the division process. This coming across opens open doors for apparatuses
created for formal content to be related to tweets that are established to be a fantastic deal greater uproarious than formal
content material. Tweet division protects the semantic importance of tweets, which in this manner blessings numerous
downstream applications, e.g. named
substance acknowledgment. We distinguish from this paper toenhance component
fine by way of considering greater
community factors.
REFERENCES
[1]C. LI, J. WENG, Q. HE, Y. YAO, A. DATTA, A. SUN, AND B.-S. LEE,
“TWINER: NAMED ENTITY
RECOGNITIONIN TARGETED TWITTER STREAM,” IN SIGIR,2012, PP. 721–730. [2]C. Li, A. Sun, J. Weng, and Q. He, “Exploiting hybrid contexts for tweet segmentation,” in SIGIR, Volume No. 3 , 2013, pp. 523–532.
[3]A. Ritter, S. Clark, Mausam, and O. Etzioni, “Named entity recognition in tweets: An experimental study,” in EMNLP,2011, pp. 1524–
1534.
[4]X. Liu, S. Zhang, F. Wei, and M. Zhou, “Recognizing named entities in tweets,”in ACL, 2011, pp. 359–367.
[5]X. Liu, X. Zhou, Z. Fu, F. Wei, and M. Zhou, “Exacting social events for tweets using a factor graph,” in AAAI, Volume No. 2 , 2012.\
[6]A. Cui, M. Zhang, Y. Liu, S. Ma, and K. Zhang, “Discover breaking events with popular hashtags in twitter,” in CIKM, 2012, pp. 1794–1798.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 1152
[8]X. Meng, F. Wei, X. Liu, M. Zhou, S. Li, and H. Wang, “Entitycentric topic-oriented opinion summarization in twitter,” in KDD, 2012, pp. 379–387.
[9]Z. Luo, M.Osborne, and T. Wang, “Opinion retrieval in twitter,” in ICWSM, 2012, pp. 202-215
T.MounikaCurrently doing M.Tech in
Computer Science & Engineering at TallaPadmavati
college of Engineering, Kazipet, Warangal, India.
Research interests includes Tweet segementation based
on POS Tagging, Social networking etc .,
K.Deepika Currently working as an
Associate Professor in CSE Department at
TallaPadmavati college of Engineering ,Kazipet,