TWISTER2
Overview
1.
Task Graph
❏
Task Graph
❏
Static and Dynamic Task Graph
❏
Execution Graph
❏
Task Graph Example
2.
Task Scheduler
❏
Batch and Streaming Task Scheduling
❏
Task Schedulers for Streaming and Batch Task Graph
3.
Task Executor
❏
Streaming Sharing Task Executor
Task Graph
● The task layer provides a higher-level abstraction on top of the communication layer to hide the
underlying details of the execution and communication from the user.
● Computations are modeled as task graphs in the task layer which could be created either statically or
dynamically.
- Node in the task graph represents a task whereas an edge represents the communication link
between the vertices.
- Each node in the task graph holds the information about the input and its output.
- A task could be long-running (streaming graph) or short-running (dataflow graph without loops)
depending on the type of application.
● A task graph 'TG' generally consists of set of Task Vertices 'TV' and Task Edges (TE) which is
mathematically denoted as
Static and Dynamic Task Graphs
● The task graphs can be defined in two ways namely static and dynamic task graph.
○ Static task graph - the structure of the complete task graph is known at compile time.
○ Dynamic task graph - the structure of the task graph does not know at compile time and the
program dynamically define the structure of the task graph during run time.
● Static Task Graph in Big Data Systems
○ Apache Flink
○ Apache Heron
○ Apache Storm
● Dynamic Task Graph in Big Data Systems
● Apache Spark
Three Main Design Principles of Task Graph
●
Task Decomposition -
Identify independent tasks which can execute
concurrently.
●
Group tasks -
Group the tasks based on the dependency on other tasks.
●
Order tasks -
Order the tasks which will satisfy the constraints of other tasks.
Task Graph in Twister2
● The task graph system in Twister2 is mainly aimed to support the directed dataflow task graph which
consists of task vertices and task edges.
○ The task vertices represent the source and target task vertex
○ The task edge represent the edges to connect the task vertices
● The task graph in Twister2
○ supports iterative data processing - For example, in K-Means clustering algorithm, at the end of every iteration, data points and centroids are stored in the DataSet which will be used for the next iteration
Dataflow Task Graph
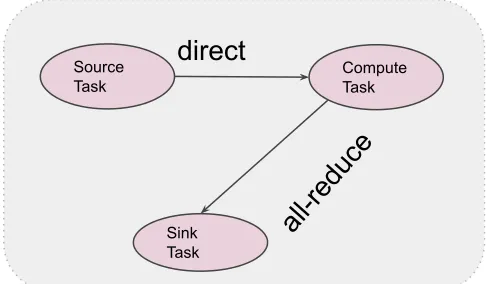
[image:8.720.50.293.169.311.2]Dataflow Task Graph - It consists of set of task vertices and task edges. It describes the details about how the data is consumed (in this example using all-reduce communication) between the task vertices. Source Task Compute Task Sink Task direct all-reduce
Fig. 1: Dataflow Task Graph
● Source Task - It extends the BaseSource and implements the Receptor interface which is given below.
● Compute Task - It implements the IFunction interface which is given below.
Connected Dataflow
Connected Dataflow - The Connected DataFlow is
mainly aimed too compose and run multiple
independent/dependent dataflow task graphs into a single
entity.
● Connected Dataflow may consists of both batch and streaming task graphs.
● A dataflow task graph consists of multiple subtasks which are arranged based on the parent-child relationship between the tasks.
● Each dataflow task graph has source, compute, and sink task tasks.
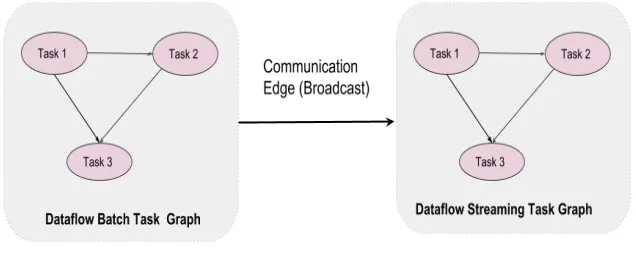
[image:9.720.393.711.114.241.2]● Different dataflow task graphs are connected through communication edges (for example: broadcast)
Dataset<Object> (Datapoints) Dataset<Object> (Centroids) Calculate Nearest Centroids Update New Centroids DataSet<Object> (New Centroids) IW orker
K-Means - Iterative Internal Dataflow Task Graph
1. The datapoints are partitioned and stored in DataSet (0th object) and centroids are stored in DataSet (1st object).
2. Then, it sends the internal dataflow graph and the task schedule plan to the task executor.
3. For every iteration, the new centroid value is calculated and the calculated value is distributed across all the task instances.
Implementation Details of Taskgraph (1)
●
ITaskGraph
- It is the main interface which is primarily responsible for creating task vertexes and task edges between
those vertexes, removing task vertexes and task edges, and others.
●
BaseDataflowTaskGraph
- Base class for the dataflow task graph which consists of methods to find out the inward and outward task edges and
incoming and outgoing task edges.
- Validates the task vertexes and creates the directed dataflow edge between the source and target task vertexes.
- Performs the validation such as duplicate names for the task, duplicate edges between same two tasks, self-loop in the
task graph, and cycles in the task graph.
●
DataflowTaskGraph
- Main class which extends the BaseDataflowTaskGraph, first it validate the task graph then store the directed edges into
Implementation Details of Taskgraph (2)
● Vertex
- It represents the characteristics of a task instance which consists of task name, task parallelism value,
and resource requirements such as cpu, ram, memory, and others.
● Edge
- It represents the communication operation to be performed between two task vertices which consists of
edge name, type of operation, operation name, and others.
● GraphBuilder
- It is mainly responsible for creating the dataflow task graph which has the methods for connecting the
task vertexes, add the configuration values, setting the parallelism, and validate the task graph.
● Operation Mode
Task Graph - Mean Calculation Example (1)
Task Graph Specification Task Graph Mean Calculation consists of
1. Datapoints Generation
2. TaskGraph Construction
3. Storing Data Points in DataSet
4. Index and Mean Value Calculation
5. Mean Value Aggregation
● TaskGraphMeanCalculationExample - receive the required job parameters to generate the
datapoints, build the task graph, and invoke the
Task Graph - Mean Calculation Example (2)
● MeanSourceTask - Calculate the source and end index of the datapoints for each worker and each
worker calculate the mean value for the assigned
datapoints. Send their respective calculated mean
values to the reduce task.
● MeanReduceTask - It receives the calculated mean value from each worker.
Task Scheduling (1)
● Task scheduling is the process of scheduling multiple task instances into the cluster resources.
● The optimal allocation of tasks decreases the overall computation time of a job and improves the
utilization of cluster resources.
● Moreover, task scheduling requires different scheduling methods for the allocation of tasks and
resources based on the architectural characteristics.
Task Scheduling (2)
● Main functional requirements of task scheduling are;
○ Scalability
○ Dynamism
○ Time and cost efficiency
○ Handling different types of processing models, data and jobs, etc.
● Major objectives of task scheduling are;
○ reducing the number of task migrations
○ allocating the number of dependent and independent tasks in a near optimal manner to;
■ decrease the overall computation time of a job
Classification of Task Scheduling (1)
● Task scheduling is broadly classified into two types;
○ Static Task Scheduling
○ Dynamic Task Scheduling
● Static task scheduling - Jobs are allocated to the nodes before the execution of a task and the processing
nodes are known at compile time.
○ Once the tasks are assigned to the appropriate resources, the execution continues to run until task
completion.
○ Reduce the scheduling overhead that occurs during the runtime and minimize the number of
nodes/processors.
● Static task scheduling examples
○ Round robin scheduling
○ Delay scheduling
Classification of Task Scheduling (2)
● Dynamic task scheduling - Dynamic task scheduling takes the scheduling decisions during the
runtime of task execution.
○ Considers resource requirement, availability of resources, interprocess and inter-node traffic,
energy efficiency, and more.
○ Supports task migration which is based on the status of the cluster resources and the
workload of an application.
● Dynamic task scheduling examples
○ resource-aware scheduling
○ energy-aware scheduling
Task Scheduling for Batch Jobs
● In general, task scheduling for batch jobs can be performed prior to processing, based on the
knowledge of input data and task information for processing in a distributed environment.
○ The resources can be statically allocated prior to the execution of a job.
● Florin Pop and Valentin Cristea explained processing of big data as a big batch process by splitting
a job into multiple tasks and running on a High Performance Computing (HPC) by distributing the
Task Scheduling for Streaming Jobs
● In general, the big data platform receives a large amount of streaming data from input data streams
such as data sensors, social networking, IoT devices and others.
● The task scheduling for streaming is considerably more difficult than batch jobs due to the continuous
and dynamic nature of input data streams that requires unlimited processing time.
○ Difficult to store such large amounts of streaming data hence, it should be processed
immediately which requires a lot of computation cycles and memory resources
○ Scheduling for streaming mainly focus on minimizing latency.
○ Streaming task components communicate each other should be scheduled in close network
Task Scheduling in Big Data Tools or Platforms (1)
●
Apache Hadoop
○ Implemented with the default scheduling policy of FIFO which schedules the jobs coming first and
gets higher priority than the later one that leads to starvation of jobs.
●
Apache Spark
○ Implemented both the static and dynamic task scheduling algorithms for those RDDs.
○ The fair scheduling policy in Spark group the jobs into pools and assign weights into each pool.
○ The dynamic resource allocation policy allocates the resources to the jobs based on the workload of
the cluster resources in a dynamic manner.
●
Apache Mesos
○ It is implemented with a fine-grained Dominant Resource Fairness (DRF) algorithm that allocates the
sharing of resources across the applications running on the platform.
○ It decides a number of resources to be allocated to each framework and provides the resource
Task Scheduling in Big Data Tools or Platforms (2)
●
Apache Flink
○ It is implemented with an immediate scheduling and queued scheduling algorithm
●
Apache Storm
○ Default round-robin scheduling for the placement of streaming tasks on the execution nodes.
○ Doesn’t consider the availability of the resource or the applications resource requirement that leads
to under-utilization or over-utilization of the resources.
●
Apache Heron
○ Implemented with Round Robin and First Fit Bin Decreasing packing plan algorithms for scheduling
the streaming applications in the big data processing.
○ By default, Apache Heron doesn't consider the resource requirement and the resource availability
Task Scheduling in Twister2
● In Twister2, a job or an application is represented as a dataflow programming model in which tasks
are organized in a graph structure.
● Scheduling these tasks is one of the key active research areas which mainly aims to place the tasks
on available resources.
● It is essential to effectively schedule the tasks, in a manner that minimizes task completion time and
increases utilization of resources.
● It considers both the soft (CPU, disk) and hard (RAM) constraints and serializes the task schedule
Task System Architecture in Twister2
Taskgraph Generation
Twister2 support two types of taskgraph generation namely:
1. Implicit Specification - The user could use the TSet to generate the taskgraph in an implicit
manner. In this case, task graph is is hidden to the user as shown below.
2. Explicit Specification - The user could directly use the Task Graph API to generate the task graph
Scheduling Model in Twister2
The scheduling model in twister2 comprises of;
● Job model
○ Provides the abstraction of jobs (consists of multiple tasks) and its requirements
○ Handles different type of jobs namely batch, streaming, MPI, and microservices.
● Resource model
○ Describes the characteristics and performances of data centers, hosts, rack, and network links.
● Scheduling policy/algorithm
○ Specific goals such as optimization of total computational time or utilization of cluster resources
● Performance metrics
○ Evaluate the performance improvements gained by the proposed task scheduling model
● Programming model
Task Scheduler in Twister2
●
The task scheduler in twister2 is designed to handle both streaming and batch
tasks.
●
It is implemented with three types of task schedulers namely
○ Round Robin Task Scheduler
○ First Fit Task Scheduler
Round Robin Task Scheduler
● RoundRobin Task Scheduler allocates the task instances of the task graph in a round robin fashion.
● It generates the task schedule plan which consists of the workers (container plan) and the allocation of
task instances (task instance plan) on those workers.
● The size of the worker (memory, disk, and cpu) and the task instances (memory, disk, and cpu) allocated to
the worker are homogeneous in nature as shown in Fig. 5.
First Fit Task Scheduler
● FirstFit Task Scheduler allocates the task instances of the task graph in a heuristic manner. The main
objective of the task scheduler is to reduce the total number of workers.
● It generates the task schedule plan which consists of the workers (container plan) and the allocation of
task instances (task instance plan) on those workers.
● The size of the container (memory, disk, and cpu) and the task instances (memory, disk, and cpu) are
heterogeneous in nature as shown in Fig.6.
Data Locality Aware Task Scheduler (1)
● Data Locality Aware Task Scheduler allocates the task instances of the task graph based on the
locality of data.
● It calculates the distance between the worker nodes and the data nodes and allocate the task
instances to the worker nodes which are closer to the data nodes i.e. it takes lesser time to
transfer/access the input data file.
● The data transfer time is calculated based on the network parameters such as bandwidth, latency, and
size of the input file.
● It generates the task schedule plan which consists of the workers (container plan) and the allocation of
task instances (task instance plan) on those workers as shown in Fig. 7.
Data Locality Aware Task Scheduler (2)
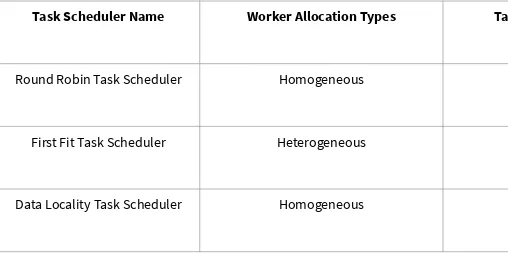
Task Scheduler Worker Allocation and Task Instance Types
Task Scheduler Name Worker Allocation Types Task Instance Types
Round Robin Task Scheduler Homogeneous Homogeneous
First Fit Task Scheduler Heterogeneous Heterogeneous
[image:34.720.33.541.77.330.2]Data Locality Task Scheduler Homogeneous Homogeneous
Task Execution
● A process model or a hybrid model with threads can be used for execution which is based on the
system specification.
● It is important to handle both I/O and task execution within a single execution module so that the
framework can achieve the best possible performance by overlapping I/O and computations.
● The execution is responsible for managing the scheduled tasks and activating them with data
coming from the message layer.
● Unlike in MPI based applications where threads are created equal to the number of CPU cores, big
Task Executor in Twister2
● Task Executor is the component which is responsible for executing the tasks that are submitted
through the task scheduler in each worker
○ It uses threads to execute a given task plan.
○ It allows to run one or more executors run on each worker node
○ It will queue the tasks and execute the tasks based on the submitted order.
● The task executor will receive the tasks as serialized objects and it will deserialize the objects before
processing them.
● A thread pool will be maintained by the task executors to manage the core in an optimal manner.
○ The size of the thread pool will be determined by the number of cores that are available to the
Types of Task Executors in Twister2
● Task Executor is implemented with two types of executors namely
○ Batch Sharing Task Executor
○ Streaming Sharing Task Executor
● Task Executor invokes the appropriate task executors based on the type of the task graph.
● Batch Sharing Task Executor terminate after the computation ends whereas Streaming Sharing Task
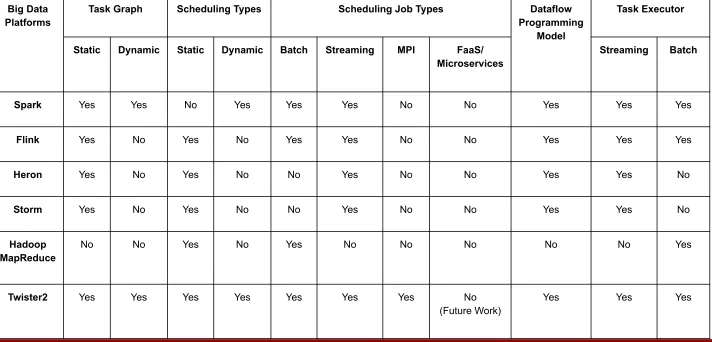
Big Data Platforms
Task Graph Scheduling Types Scheduling Job Types Dataflow
Programming Model
Task Executor
Static Dynamic Static Dynamic Batch Streaming MPI FaaS/
Microservices
Streaming Batch
Spark Yes Yes No Yes Yes Yes No No Yes Yes Yes
Flink Yes No Yes No Yes Yes No No Yes Yes Yes
Heron Yes No Yes No No Yes No No Yes Yes No
Storm Yes No Yes No No Yes No No Yes Yes No
Hadoop MapReduce
No No Yes No Yes No No No No No Yes
Twister2 Yes Yes Yes Yes Yes Yes Yes No
(Future Work)
[image:39.720.8.720.46.388.2]Yes Yes Yes
Conclusion
● Task Graph is defined to support both the streaming and batch jobs, in which vertices represent the
tasks and the edges represent the communication/data dependencies between the vertices.
● Task scheduling in Big data is one of the active research areas which plays a major role in the
completion of Big data processing and effectively utilize the cluster resources.
● Task scheduler in Twister2 has the common task scheduling model has the ability to schedule both
streaming and batch task graphs.
● Task Executor in Twister2 is implemented with Batch Sharing Task Executor and Streaming Sharing